
热门标签
热门文章
- 1微信小程序获取用户头像昵称_微信小程序获取用户头像和昵称
- 2Vue3如何关闭eslint_vue3关闭eslint
- 31、Android Studio的安装及环境配置
- 4【教程】华为鸿蒙系统连接代理后无法上网问题的解决方案_华为p20代理后没网络怎么办
- 5官网下载VMware Workstation Player 16、15、14_vmware player官网
- 6微信小程序反编译
- 7Unity Log adb 调试和Android Logcat调试(图文详细版)_unity调试查看手机工具
- 8syntax error,position at 0,name code_syntax error, position at 0, name objecttype
- 9鸿蒙HarmonyOS实战-ArkTS语言(渲染控制)_function return type inference is limited (arkts-n
- 10Spring Boot源码解读与原理分析_linkedbear
当前位置: article > 正文
Python爬虫 —— 百度翻译_python爬虫百度翻译
作者:Monodyee | 2024-04-02 15:51:20
赞
踩
python爬虫百度翻译
基本信息
爬虫测试时间:2020年7月29日
爬虫目标网站:百度翻译(https://fanyi.baidu.com/?aldtype=16047#auto/zh)
网站基本信息
键入要翻译的关键字后,页面局部刷新(依旧使用的是 AJAX)
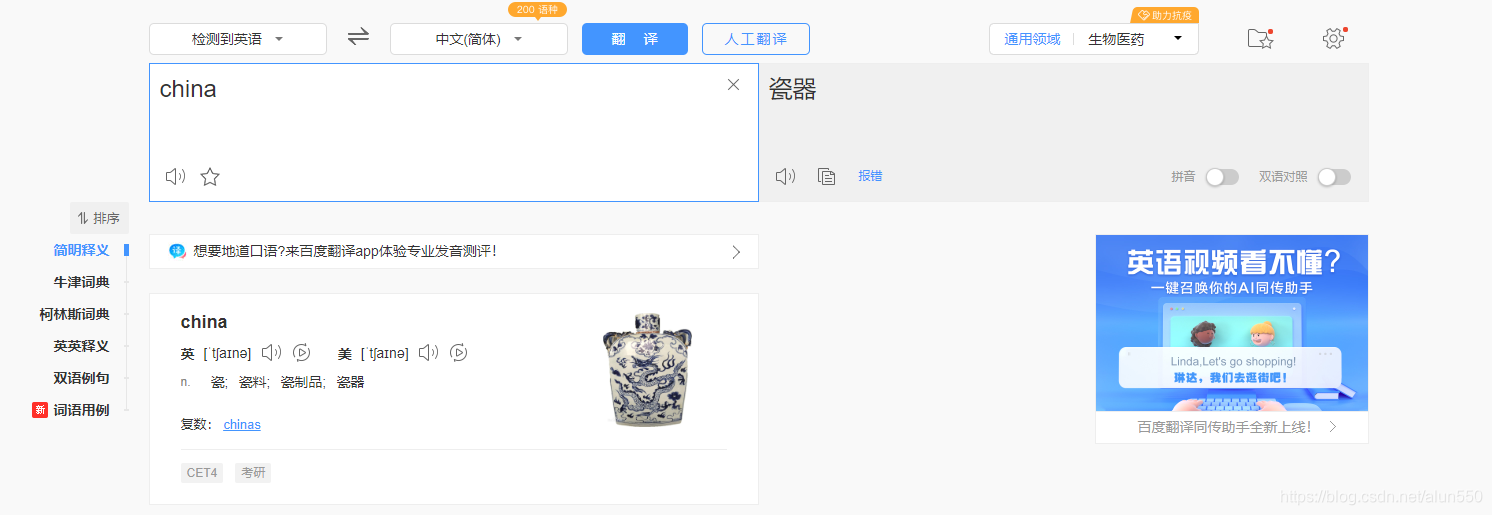
1、数据抓包,进入XHR页面获取AJAX实际的请求地址及相关参数
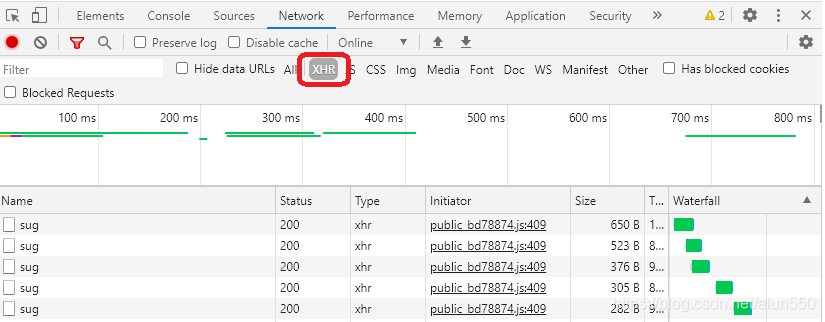
2、看几个响应,分析请求的规律
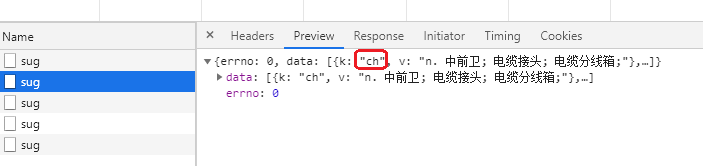
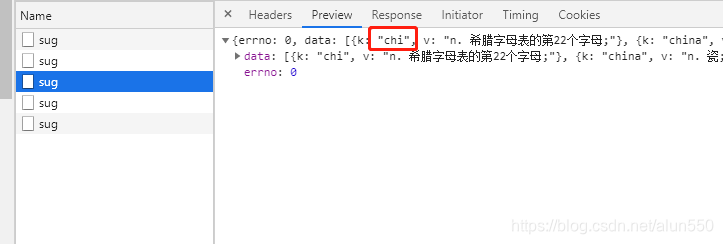
找到k是china的那个请求,可以看到 请求url、请求方式 和 返回的数据类型 都有了
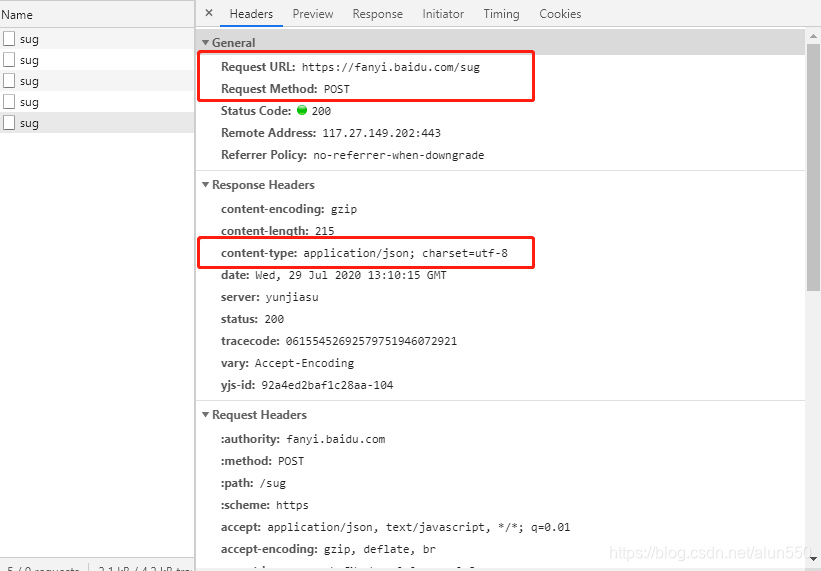
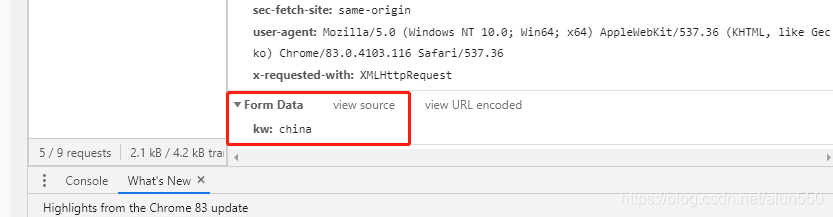
继续往下看,post传出的是什么样的数据。最下方可以看到传出数据的形式为 key —> kw, value —> china
3、编写个代码测试一下(此步可跳过,下面代码为不完全版本,只是为了引导思路)
import requests from bs4 import BeautifulSoup import os baseurl = 'https://fanyi.baidu.com/sug' ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' \ ' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' para = { 'query': 'python' } data = { 'kw': 'dog' } res = requests.post(baseurl, headers={'User-Agent': ua}, data=data) saveDir = './爬虫数据存储/百度翻译' saveData = '百度翻译' extName = 'json' if res.status_code == 200: print(res.text) if not os.path.exists(saveDir): os.mkdir(saveDir) with open(os.path.join(saveDir, saveData + '.' + extName), 'w', encoding='utf-8') as f: f.write(res.text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
可以看到返回的数据如下:
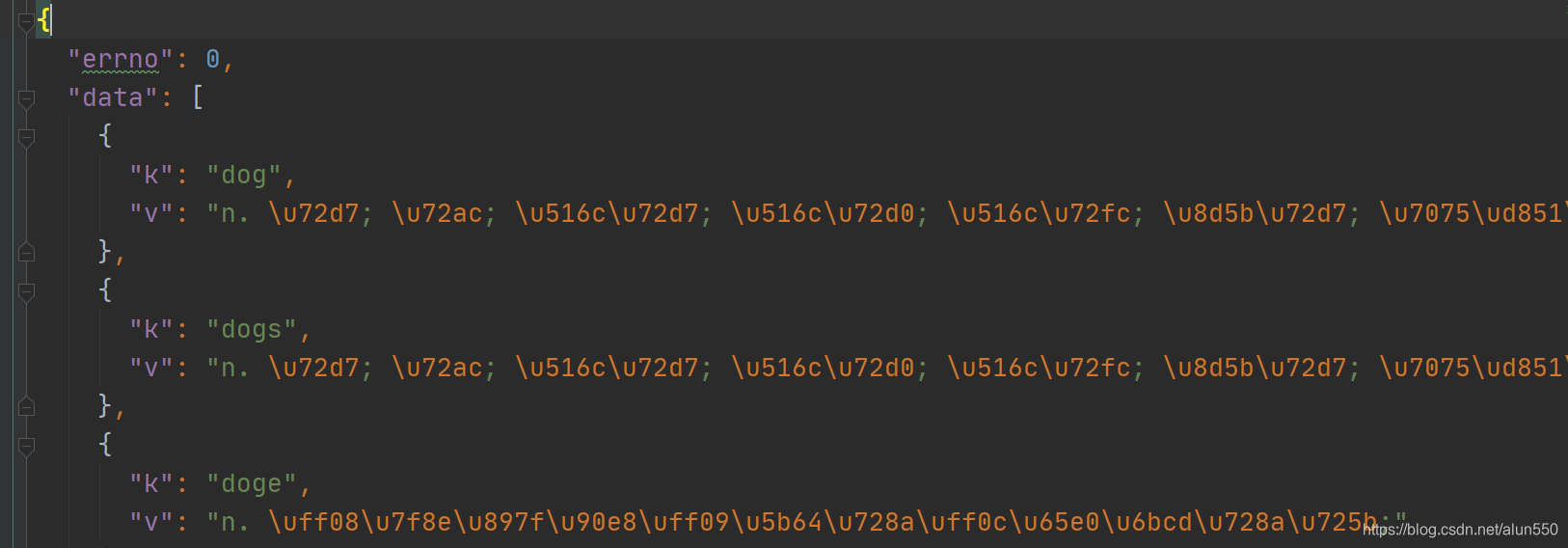
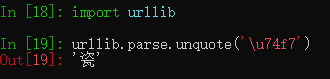
上图中的 v 都是 \uxxx的形式,使用urllib解析字符,可以看到返回的结果就是翻译的结果
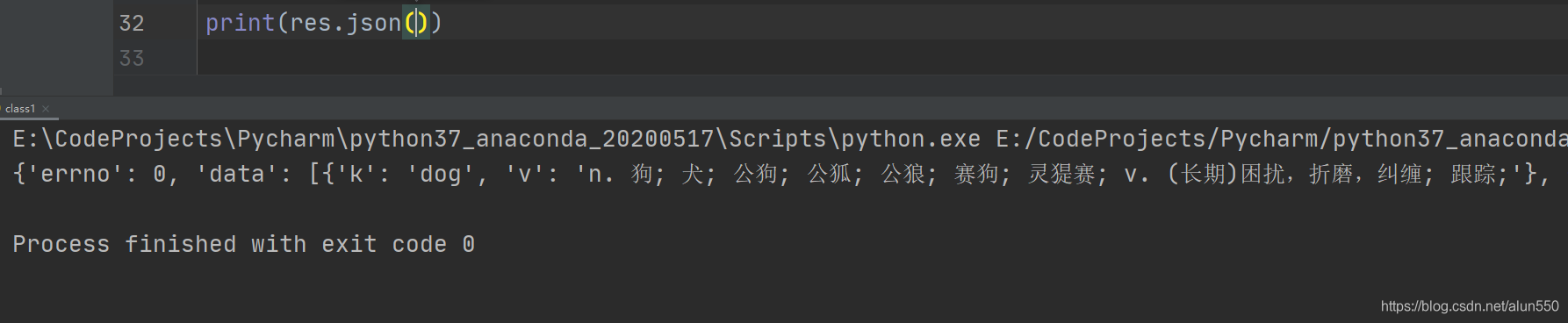
4、一个一个的解析这些字符也很麻烦,此处既然返回的直接试json数据,则调用 requests.json() 直接将响应的json字符串 读入为 python 字典,可以看到结果数据已经成功被解析了
5、整体代码如下:
import requests from bs4 import BeautifulSoup import os import json baseurl = 'https://fanyi.baidu.com/sug' ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' \ ' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' para = { 'query': 'python' } data = { 'kw': 'dog' } res = requests.post(baseurl, headers={'User-Agent': ua}, data=data) saveDir = './爬虫数据存储/百度翻译' saveData = '百度翻译' extName = 'json' if res.status_code == 200: print(res.text) if not os.path.exists(saveDir): os.mkdir(saveDir) with open(os.path.join(saveDir, saveData + '.' + extName), 'w', encoding='utf-8') as f: # 注意此处使用json.dumps() 一定要把属性 ensure_ascii 设置为 False,否则中文无法正常解码 f.write(json.dumps(res.json(), ensure_ascii=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
6、将上述代码按需封装,在辅以gui则可实现“自己的”翻译器了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/352919
推荐阅读
相关标签

