
热门标签
热门文章
- 1CentOS 7配置hadoop和hbase伪分布式模式保姆级教程(近乎零基础跟着配也能配对)
- 2pytorch学习笔记之pytorch入门_pytorch生成随机矩阵
- 3K-means算法实战项目(Python实现)(对比简化版)_mderank
- 4NLP实践——Llama-2 多轮对话prompt构建_llama prompt
- 5二零二三充能必读 | 1024程序员狂欢节 —— 掌握前沿技术,探索未知领域
- 6中国计算机学会CCF推荐国际学术会议和期刊目录-人工智能_igarss会议是ccf几类
- 7视频直播系统开发中的数据库创建方案
- 8AI作画,国风油画风随心定制~ Stable Diffusion模型使用,三步就上手_openvino stable diffusion
- 9【NLP】近期必读ICLR 2021相关论文
- 10结构风险最小和VC维理论的解释_向量机构风险最小化的含义和合理性
当前位置: article > 正文
多头自注意力机制Pytorch实现_多头注意力机制pytorch
作者:Monodyee | 2024-04-05 10:27:45
赞
踩
多头注意力机制pytorch
注意力机制广泛存在于现在的深度学习网络结构中,使用得到能够提升模型的学习效果。本文讲使用Pytorch实现多头自注意力模块。
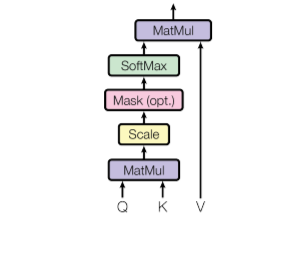
一个典型的自注意力模块由Q、K、V三个矩阵的运算组成,Q、K、V三个矩阵都由原特征矩阵变换而来,所以本质上来说是对自身的运算。

而多头注意力机制则是单头注意力机制的进化版,把每次attention运算分组(头)进行,能够从多个维度提炼特征信息。具体原理可以参看相关的科普文章,下面是Pytorch实现。
import torch.nn as nn class MHSA(nn.Module): def __init__(self, num_heads, dim): super().__init__() # Q, K, V 转换矩阵,这里假设输入和输出的特征维度相同 self.q = nn.Linear(dim, dim) self.k = nn.Linear(dim, dim) self.v = nn.Linear(dim, dim) self.num_heads = num_heads def forward(self, x): B, N, C = x.shape # 生成转换矩阵并分多头 q = self.q(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3) k = self.k(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3) v = self.k(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3) # 点积得到attention score attn = q @ k.transpose(2, 3) * (x.shape[-1] ** -0.5) attn = attn.softmax(dim=-1) # 乘上attention score并输出 v = (attn @ v).permute(0, 2, 1, 3).reshape(B, N, C) return v

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/365048
推荐阅读
相关标签

