
- 1HarmonyOS(鸿蒙)真机签名获取(详细教程)_harmonyos签名配置
- 2android view橡皮擦,Android视图中的橡皮擦
- 3在Linux系统上检测GPU显存和使用情况_linux 如何查看显存大小 csdn
- 43D人脸重建开源项目整理_reconstruction 项目
- 5工具分享:在线键盘测试工具_键盘延迟测试网页
- 6Linux使用openssl工具生成私钥(private.pem)和公钥(public.pem)_openssl 根据私钥创建公钥文件public_key.pem
- 7宇视门禁产品批量导入人员信息功能配置指导
- 8GaussDB拿下的安全认证CC EAL4+究竟有多难?_cc认证4级标准
- 9解读 Xend Finance:向 RWA 叙事拓展,构建更具包容性的 DeFi 体系
- 10Null与DBnull值间的转化_如何同sql查出来的null转换为dbnull
layui 树状图默认全部展开_[简话语音识别] 解码器(一)基于WFST静态图展开的VertibiBeamSearch解码算法...
赞
踩

1 背景介绍
- 语音识别技术简介
语音识别概括来说是将经由麦克风接收并采样得到的一段语音信号序列转换成一段文本序列的序列转换技术。目前业内主流大多基于统计理论的贝叶斯法则:
目前业内主流的语音识别算法框架的三个最重要的部件为:
1. HMM-DNN声学模型;
2. 语言模型;
3. 基于WFST静态图展开的VertibiBeamSearch解码算法;
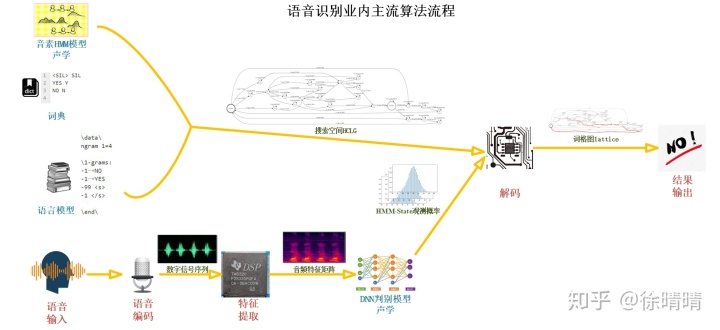
- 解码器在语音识别技术中的作用
简单来说,解码器可以看作是一个函数,代表了一种将语音音频特征矩阵输入映射为一个或多个词序列输出的映射关系:
这种映射关系其实是一系列概率乘积,这些概率由声学模型、语言模型和词典计算得出。
怎么来直观理解这种映射关系呢?
声学模型
语音音频信号虽然在时间轴上看是一堆不断跳变的数值,但其实它在另一个表示域频域内具有短时不变特性,即:若提取语音的fbank特征作为声学模型的输入,在每个短时时间窗口(为方便表述下文不严谨地称之为“时刻”)内的语音音频均可用同一个fbank特征向量
简单起见,不考虑声学模型内部的HMMDNN子结构和音素的上下文关系,假设声学模型接收每个时刻的特征向量输入,输出对应的音素概率向量
抛开发音不定长的特性影响,强制仅在前后连续的两个时刻之间存在音素跳转,跳转概率相同。那么仅引入声学模型约束的解码过程可以形象地看成从一个随时间不断动态展开的树状图中寻找最短路径的问题,图上的每条边为相应时刻声学模型输出的-log值。

词典
仅根据声学模型解码得出的phone序列并不总是可以在词典中找到相应的词语表达。而词典的引入会在上述树状图中砍掉一部分无法匹配词表中词的音素跳转路径,缩小解码器的搜索空间,加快解码速度。假设词汇表中每个词的发音均可用3个音素的音素序列的跳转关系表示,并且不存在多音词。
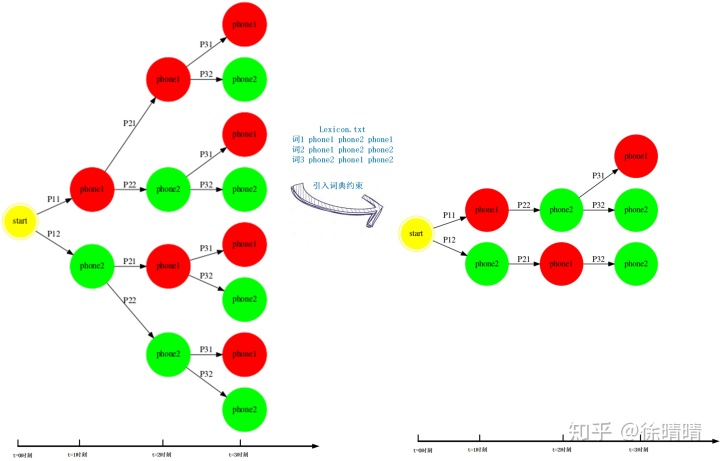
语言模型
关于这块的解释可以看我的上一篇博文,这里不再赘述。这里以包含3个词的2gram语言模型为例说明。ngram模型会去除一些grammar中没有出现过的语法,或者给不常见的grammar分配一个很低的概率,使得这种grammar不容易被解码得出。引入语言模型之后,每个时刻的phone跳转边会根据历史词信息分为不同的种类。2gram模型的引入会使解码空间包含3种跳转边,各自携带不同的信息:(1)单纯携带声学模型得分;(2)携带声学模型和1gram得分;(3)携带声学模型和2gram得分。

综上所述,声学模型、词典和语言模型共同为每一条音频构建了一个有向图,解码的过程就可以抽象为在这个有向图中搜索最短路径的问题。
- 解码器的难点
对于大词汇量连续语音识别而言,待识别的词表在万级别,若使用简单的平滑处理后2gram统计语言模型,仅语言模型就有
语音发音的不定长特性指什么?
由于每个人发音习惯的不同,每个人发出同一个音素的音频是有长有短的。甚至由于语境和情感表达的不同,同一个人发出同一个音素的音频也是有长有短的。HMM-DNN声学模型采用从左向右且带有自跳转的HMM结构来描述这种不定长特性。


2 解码器基础知识
解决内存消耗和计算量过大的问题,主要有2个解决方向:
第一,寻找适合的解码图表示方式,减少内存的占用;
第二,选择更好的搜索算法,减少计算;
- 寻找合适的解码图表示方式
动态展开图
比较直观的图表示方式就是第一部分描述的随时间不断展开的树状有向图结构。这种树状有向图其实包含了很多的冗余信息,比如t=2时刻,不同path上音素1和音素2之间的跳转路径是完全相同的。可以用一种叫做prefix-tree lexicon的技术合并这种相同路径,减小边和顶点总数。

但对于大词汇量连续语音识别来说,解码图的边数还是特别大:假设词汇表有1000个词,词的发音音素序列长度均为3,prefix-tree词典表示图中共有200条边,语言模型采用平滑的2gram模型。以一段3.015s语音音频(假设窗长为25ms,窗移为10ms,共可以划分为300个短时窗)解码为例,解码图中一共有

所以这种表示形式的解码图在实际使用的过程中不可能在初始时刻完全展开,只能在搜索过程中,到达某个触发状态时,动态地展开后续的graph。实际操作过程中,一般采用tree-copy的方式,某个时刻某个active path到达prefix-tree lexicon的叶子节点时,在这个节点处拷贝一份prefix-tree lexicon图,继续展开解码图进行搜索。

静态展开图
加权有限状态转换机WFST技术的出现,使得在大词汇量连续语音识别中使用静态展开图的成为可能。WFST技术是一种抽象的数学结构,描述的是一个输入序列和输出序列的序列映射关系:WFST接收一个输入序列,通过内部的状态跳转得到一个输出序列和对应的跳转代价cost。WFST使得序列与序列的映射关系可以用一种统一的数学语言来描述,从而可以通过WFST定义的各种数学操作来组合不同的WFST,描述各种复杂的序列映射关系。 语音识别中用到的WFST操作主要有compose复合操作,还有一些优化操作:determinize、minimize及weightpush等。

WFST的具体理论知识可以看下《Speech Recognition Algorithms Using Weighted Finite-State Transducers》chapter3。
声学模型、词典和语言模型表达的都是一种输入序列到输出序列的映射关系,都可以用WFST结构表示。通过compose操作,可以各层级的fst组合成一个完整的静态展开图fst,直接描述音频特征向量输入序列与词输出序列之间的映射关系。同时,由于WFST中定义了一系列的图优化操作determinize和minimize,最大程度地去除冗余信息,使得解码图的大小缩减到一个可接受的水平。
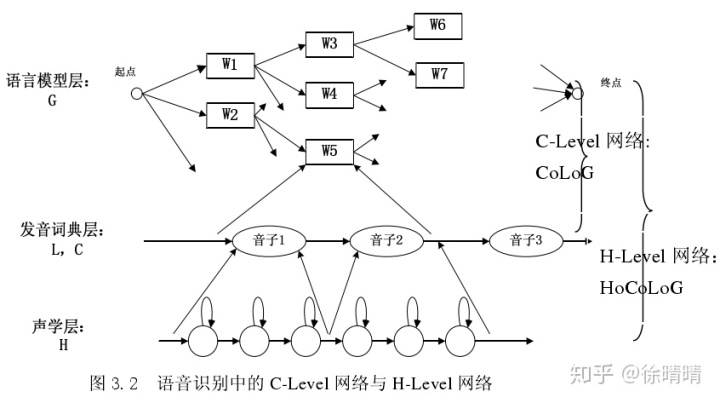
以一个简单的例子直观感受下WFST在语音识别中的用途。声学模型H.fst和音素的上下文信息C.fst后续再详细展开介绍。


语言模型的输入序列label和词典的输出序列label属于同一个词汇表集合,它们可以很方便得通过复合compose操作合并为一个大的FST,描述更复杂的音素输入序列和词输出序列的映射关系。

复合compose得到的FST其实还具有很多冗余信息,比如上图中两条路径中:arc(ian:eps) arc(i:eps) arc(x:eps)都是重复的。这种冗余信息可以通过WFST的图优化操作determinize和minimize去除。determinize操作可以合并多个path的最大公共前缀信息,而minimize可以合并最大公共后缀信息。


目前,对含有几十万的待识别词汇的连续语音识别领域而言,由WFST技术构建的解码图可做到GB级别,内存消耗是可接受的。另外由于解码图在解码之前就已经构建完成,解码过程中无需重新计算可展开的路径,节约了解码时间。因此,基于WFST静态展开的解码图取代了上述tree-copy的动态展开图,被广泛使用。但为了获得体验比较好的语音识别产品,解码图一般是GB级别的,只能部署在服务器上使用。对于内存资源不够友好的环境,静态展开图不可取,而且静态图的构建过程很费时不利于版本的更新迭代,所以动态展开图还是语音识别技术中比较重要的一部分。不过好在WFST提供了fst的动态compose技术,声学模型和词典在解码前compose成HCL,与语言模型G在解码过程中动态compose解码,降低内存的使用。因此WFST技术现在在语音识别中广泛使用。
- 选择更好的搜索算法
解码器可以表示成为一种graph search过程,可以使用深度优先和广度优先的搜索算法。
对于语音识别而言,广度优先算法也可叫做时间同步的搜索算法,一般指vertibi算法;深度优先算法也可称为时间异步的搜索算法,一般指基于A*的stack decode:
- Stack decode在每个时刻会预测未来路径的cost值,优先对结合预测的"最优可能路径"进行扩展,不需要搜索全部路径,比较快。但是由于不是很顺地随时间不断扩展,理解不够直观,操作较复杂;
- vertibi算法从初始时刻开始一点点向后搜索,同一时刻会扩展所有的path,操作比较简单。但也搜索了很多无用的路径,计算量较大。
在WFST技术用于语音识别后,解码图的规模大大减小,再结合BeamSearch技术,vertibi的计算量也能满足使用要求。所以现在解码器一般使用vertibi算法。
简单介绍下vertibi算法。
vertibi算法利用了动态规划的思想,将整个解码过程拆成从初始时刻的初始状态到某个时刻的某个状态的最优路径搜索的多个小问题,并且仅保留跳转到该状态的最优local path继续向后跳转,同时存储该路径的历史信息,减少重复运算。

BeamSearch怎么使用?
虽然vertibi算法只保留从初始时刻到每个状态的最优local path继续跳转,但是每个时刻仍然存在大量待跳转的状态,其中部分状态携带的active path与当前时刻的最优path路径长度差距较远,即使跳转到结束状态也不会是最终的解码结果。为了减少计算量,可以舍弃。舍弃的标准就是Beam的预设值,Beam可以为最大path数量,也可为与当前时刻最优path的路径cost的最大偏差值,具体取值需要权衡计算速度和解码精度而定。

3 基于WFST静态图的VertibiBeamSearch算法
- WFST静态解码图构建
声学模型采用HMM-DNN模型结构,输出带上下文信息的context phone。语言模型采用带回退backoff的ngram统计模型结构。
单独构建H.fst G.fst L.fst 和 C.fst
语言模型
ngram语言模型中某些grammar event会包含回退概率,在G.fst中为了减少边的数量,会以回退边的形式表示这个回退概率。
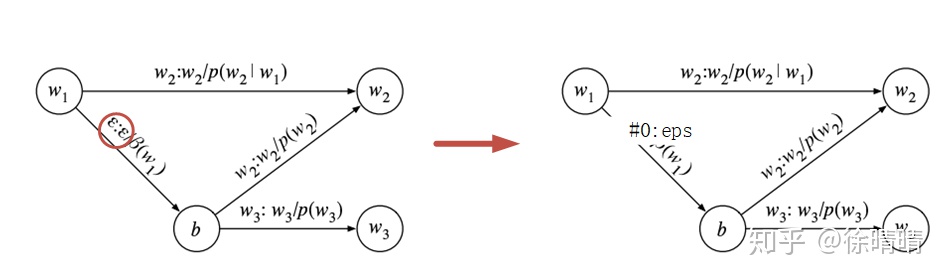
kaldi中构建语言模型的脚本是utils/format_lm.sh,里面用到的最主要的工具为arpa2fst。arpa2fst的功能:将arpa文件中的grammar信息以fst图的形式表达。
cat 2gram.arpa | /kaldi/src/lmbin/arpa2fst --disambig-symbol=#0 --read-symbol-table=words.txt - G.fst实例
- 2gram.arpa
-
- data
- ngram 1=8
- ngram 2=15
-
- 1-grams:
- -0.6283889 </s>
- -99 <s> -0.4685211
- -1.230449 不 -0.2466723
- -0.9294189 不喜欢 -0.288065
- -0.9294189 喜欢 -0.3258536
- -0.7533277 小朱 -0.4130037
- -0.9294189 小猪 -0.288065
- -0.7533277 我 -0.3258535
-
- 2-grams:
- -0.69897 <s> 不
- -0.69897 <s> 小朱
- -0.39794 <s> 我
- -0.30103 不 小猪
- -0.4771213 不喜欢 小朱
- -0.4771213 不喜欢 我
- -0.4771213 喜欢 小朱
- -0.4771213 喜欢 小猪
- -0.30103 小朱 </s>
- -0.60206 小朱 不喜欢
- -0.4771213 小猪 </s>
- -0.4771213 小猪 喜欢
- -0.60206 我 </s>
- -0.60206 我 不喜欢
- -0.60206 我 喜欢
-
- end


词典
词典一般每个词都有单独的路径,词的输出标签会放在start state到发音序列的第一个phone的路径上。对于同音不同形的词语,会先对词典做消歧处理,在相同的发音序列末尾加上辅助符号#id(id=1~该发音的总词数)。

kaldi中构建语言模型的脚本是utils/format_lm.sh,里面用到的最主要的工具为arpa2fst。arpa2fst的功能:将arpa文件中的grammar信息以fst图的形式表达。
- Step1:对词典做消歧处理
- ndisambig=$(utils/add_lex_disambig.pl $unk_opt --pron-probs $tmpdir/lexiconp.txt $tmpdir/lexiconp_disambig.txt)
- Step2:构建L_disambig文本形式
- utils/lang/make_lexicon_fst.py --sil-prob=$sil_prob --sil-phone=$silphone
- --sil-disambig='#'$ndisambig $tmpdir/lexiconp_disambig.txt |
- fstcompile --isymbols=$dir/phones.txt --osymbols=$dir/words.txt
- --keep_isymbols=false --keep_osymbols=falseL_disambig.txt $dir/L.fst
- Step3:在词的出入口loop state上增加“#0:#0”自跳转边
- fstaddselfloops $dir/phones/wdisambig_phones.int $dir/phones/wdisambig_words.int $dir/L.fst |
- fstarcsort --sort_type=olabel > $dir/L_disambig.fst
实例:
- 原始词典lexicon.txt
- <unk> sil
- 我 uo3
- 不 b u4
- 喜欢 x i3 h uan1
- 不喜欢 b u4 x i3 h uan1
- 小猪 x iao3 zh u1
- 小朱 x iao3 zh u1
-
- 在lexicon.txt中增加发音概率,一般取1.0
- lexiconp.txt
- <unk> 1.0 sil
- 我 1.0 uo3
- 不 1.0 b u4
- 喜欢 1.0 x i3 h uan1
- 不喜欢 1.0 b u4 x i3 h uan1
- 小猪 1.0 x iao3 zh u1
- 小朱 1.0 x iao3 zh u1
-
- 对lexiconp.txt相应部分增加辅助符号,做消歧处理
- lexiconp_disambig.txt
- <unk> 1.0 sil
- 我 1.0 uo3
- 不 1.0 b u4 #1
- 喜欢 1.0 x i3 h uan1
- 不喜欢 1.0 b u4 x i3 h uan1
- 小猪 1.0 x iao3 zh u1 #1
- 小朱 1.0 x iao3 zh u1 #2

音素上下文信息
语音发音的时候会有协同发音现象,不同的phone序列中,音频特征会比较不一样。而声学模型主要功能是一种“模板匹配”操作,不同的音频特征映射到具有不同上下文信息的phone会导致结果不够准确。所以,一般声学模型的输出单元会采用带上下文信息的音素或者它的子单元。C.fst表示的就是带上下文的音素left_phone_right输入序列与phone输出序列之间的映射关系。

kaldi中可以用fstcomposecontext或者fstmakecontextfst这两个命令来构建C.fst:
fstcomposecontext结合了C.fst构建和C.fst LG.fst的compose过程,效率会更高些;
fstmakecontextfst单纯构建C.fst,效率低一些。
- #构建C.fst,输入为context_phone,输出为phone,disambig.list中为辅助符号
- fstmakecontextfst --context-size=2 --central-position=1 --read-disambig-syms=disambig.list 5 ilabels.int > C.fst
- #可视化的一些操作,构架三音子phone符号表
- fstmakecontextsyms phones.txt ilabels.int > context_syms.txt
- #可视化的一些操作,将二进制fst转成文本格式fst
- fstprint --isymbols=context_syms.txt --osymbols=phones.txt C.fst > C.txt
- #可视化的一些操作,画图
- fstdraw --isymbols=context_syms.txt --osymbols=phones.txt C.fst > C.txt
实例
- 音素表phones.txt
- <eps> 0
- a 1
- b 2
- #0 3
- #1 4
- 辅助符号表
- 3
- 4

声学模型
声学模型其实包含了两个部分:预先训练好的HMM模型,以及在解码过程中由DNN模型实时计算得到的

- #kaldi utils/mkgraph.sh中构图的时候会将分成两个部分来构建Ha.fst
- #Step1:构建HMM结构
- make-h-transducer --disambig-syms-out=disambig_tid.int --transition-scale=1.0 ilabels_1_0 tree final.mdl Ha.fst #构建了一个不带self-loop的hmm.fst结构
- #Step2:在phone的相应hmmstate上增加self-loop跳转边
- add-self-loops --self-loop-scale=1.0 --disambig-syms=disambig_tid.int --reorder=true final.mdl Ha.fst H.fst

compose和优化操作
LG构建
LG的构建:除了compose操作外,还会进行一系列优化操作:确定化determinize、最小化minimize和权重前推weight push。其中det和min可以降低图的规模,weightpush可以将权重前推,在解码过程最大程度地在开始时间内锁定最优路径。
- #以/kaldi/yesno为例
- fsttablecompose L_disambig.fst G.fst | #复合操作
- fstdeterminizestar --use-log=true | #确定化操作
- fstminimizeencoded | #最小化操作
- fstpushspecial > LG.fst #权重前推


CLG构建
- #为了提高效率,kaldi中将C.fst的构建和CLG复合过程一起完成
- fstcomposecontext --context-size=$N --central-position=$P
- --read-disambig-syms=$lang/phones/disambig.int
- --write-disambig-syms=$lang/tmp/disambig_ilabels_${N}_${P}.int
- ilabels_$N_$P $lang/tmp/LG.fst $lang/tmp/CLG.fst
HCLG构建
HCLG的构建除了复合和优化操作外,还有去除辅助符号和多余的eps:eps路径;此外,为了构出更紧凑的HCLG,在最后一步中才会在相应hmmstate上加上自跳转边。
- #Step1:构建不带自跳转边的hmm结构Ha.fst
- make-h-transducer --disambig-syms-out=disambig_tid.int --transition-scale=1.0 ilabels_1_0 tree final.mdl Ha.fst
- fsttablecompose $dir/Ha.fst "$clg" | fstdeterminizestar --use-log=true | #compose操作
- fstrmsymbols $dir/disambig_tid.int | #去除辅助符号
- fstrmepslocal | #去除冗余的eps:eps跳转边
- fstminimizeencoded > $dir/HCLGa.fst #最小化操作
- #Step3:在HCLGa.fst的相应hmmstate节点上加上自跳转边
- add-self-loops --self-loop-scale=1.0 --reorder=true final.mdl $dir/HCLGa.fst > $dir/HCLG.fst

- VertibiBeamSearch解码算法
简单的VertibiBeamSearch解码算法可以抽象为以下步骤:
- Step1:初始化,保存初始状态信息;
- Step2:在FST中进行非空输入跳转,在搜索路径上加上相应时刻的声学模型cost,
- 对当前时刻可跳转到的所有nextstate计算经过该state的最优路径并保留其历史信息;
- Step3:在FST中进行空输入跳转,
- 对当前时刻可跳转到的所有nextstate计算经过该state的最优路径并保留其历史信息;
- Step4:根据Beam值裁剪当前时刻的保留下来的所有路径,仅保留最有可能继续跳转的一些active paths;
- Step5:对每个时刻重复Step2~Step4操作,直至最后一个时间窗;
- Step6:检查最后时刻所有active paths的最后一个state是否为结束状态,舍弃未到结束状态的path,并为path加上final_cost;
- Step7:计算最后时刻保留下来的active paths中的最短路径;
- Step8:回溯该路径携带的历史信息,输出解码结果。
实际中识别过程中,由于还要做一些纠错等后处理操作,一般都要保留lattice。lattice中包含了结果路径经过原HCLG中的每个状态点及经过Beam裁剪后保留下来的arc。
kaldi解码器(lattice-faster-decode)代码简介
解码过程采用令牌Token的形式保留历史信息,以及接下去的跳转信息。Token与解码图中的state是一一对应的。
重要的数据结构有两个:令牌Token和Token之间的连接ForwardLink。
- //Token
- struct BackpointerToken {
- //从初始时刻到现在经过这state的所有路径中最短路径的total cost值
- BaseFloat tot_cost;
- //从初始时刻到现在经过这state的最短路径的cost值与该时刻最优local path的cost差值
- //一般在lattice裁剪的时候才会用到
- BaseFloat extra_cost;
- //该Token对应的state可扩展到的连接
- ForwardLinkT *links;
- //某时刻的所有Token会保存为一个链表,next指向该时刻Token链表的下一个Token
- BackpointerToken *next;
- //经过该Token的最优local路径的上一时刻Token
- Token *backpointer;
- };
-
- //ForwardLink
- struct ForwardLink {
- using Label = fst::StdArc::Label;
- //link连接的下一Token
- Token *next_tok;
- //link的输入输出标签ilabel/olabel
- Label ilabel; // ilabel on arc
- Label olabel; // olabel on arc
- //解码图HCLG上该link对应的cost值
- BaseFloat graph_cost; // graph cost of traversing arc (contains LM, etc.)
- //该link输入ilabel表示的substate对应的声学模型得分
- BaseFloat acoustic_cost; // acoustic cost (pre-scaled) of traversing arc
- //该link的起始Token跟下一时刻Token的所有连接都存储为链表,next为链表中的nextlink
- ForwardLink *next;
- };
解码的过程Decode包括初始化、流式解码和结尾处理三个部分。
- template <typename FST, typename Token>
- bool LatticeFasterDecoderTpl<FST, Token>::Decode(DecodableInterface *decodable) {
-
- //InitDecoding函数功能:
- // 初始状态设置
- // 1.在解码开始或解码过程中需要重新开始的时刻,清除内部变量保存的历史信息;
- // 2.获取解码图HCLG中的起始state和该state的所有<eps>_input边连接的nextstate;
- InitDecoding();
-
- //AdvanceDecoding函数功能:
- // 随音频的不断输入,流式解码
- // 1.某时刻,在HCLG中进行非<eps>_input跳转,进行Beam裁剪,
- // 并保留active_token的声学模型得分、graph边长、输入输出label等历史信息;
- // 2.某时刻,在HCLG中进行<eps>_input跳转,进行Beam裁剪,
- // 并保留active_token的graph边长、输入输出label等历史信息;
- // 3.在达到设置的prune间隔时,根据预设的lattice_beam裁剪active Tokens和相应ForwardLink,
- // 减少内存占用;
- AdvanceDecoding(decodable);
-
- //FinalizeDecoding函数功能:
- // 音频结尾时,处理final状态
- // 1.解码结束时,为最后时刻的active Tokens加上HCLG上相应state的final cost;
- // 2.获取解码图HCLG中的起始state和该state的所有<eps>_input边连接的nextstate;
- // 3.根据预设的lattice_beam裁剪active Tokens和相应ForwardLink;
- FinalizeDecoding();
- }
InitDecoding代码简介
- template <typename FST, typename Token>
- void LatticeFasterDecoderTpl<FST, Token>::InitDecoding() {
- // Step1:清除变量保存的所有历史信息
- DeleteElems(toks_.Clear());
- cost_offsets_.clear();
- ClearActiveTokens(); //清除所有active token及相应Link的内存占用
- warned_ = false;
- num_toks_ = 0;
- decoding_finalized_ = false;
- final_costs_.clear();
-
- // Step2:获取解码图HCLG中的START state,作为t=0时刻Token
- StateId start_state = fst_->Start();
- KALDI_ASSERT(start_state != fst::kNoStateId);
- active_toks_.resize(1);
- Token *start_tok = new Token(0.0, 0.0, NULL, NULL, NULL);
- active_toks_[0].toks = start_tok;
- toks_.Insert(start_state, start_tok);
- num_toks_++;
-
- // Step3:解码图START state存在<eps>_input跳转边,获取所有graph_cost<beam值的nextstate,
- // 并存入t=0时刻的active Token链表中,同时保留它们之间的连接关系。
- ProcessNonemitting(config_.beam);
- }
AdvanceDecoing代码简介
- template <typename FST, typename Token>
- void LatticeFasterDecoderTpl<FST, Token>::AdvanceDecoding(DecodableInterface *decodable,
- int32 max_num_frames) {
- //Step1: 等待DNN声学模型部分计算完成
- int32 num_frames_ready = decodable->NumFramesReady();
- int32 target_frames_decoded = num_frames_ready;
- if (max_num_frames >= 0)
- target_frames_decoded = std::min(target_frames_decoded,
- NumFramesDecoded() + max_num_frames);
-
- //Step2: 对每个chunk进行解码
- while (NumFramesDecoded() < target_frames_decoded) {
- //Step2.1:达到prune间隔周期时,修剪与当前时刻最优路径cost值相差大于
- // 预设lattice_beam值的active路径上的token及forwardlink,释放内存
- if (NumFramesDecoded() % config_.prune_interval == 0) {
- PruneActiveTokens(config_.lattice_beam * config_.prune_scale);
- }
-
- //Step2.2:解码图上的非<eps> input跳转,在跳转路径上加上相应声学模型得分
- // 1.根据上一时刻的active Tokens, 根据预设的最大最小active token数量及beam值
- // 计算应用于当前时刻BeamSearch的adaptive_beam值;
- // 2.计算当前时刻加上声学模型得分后跳转得到的最优local path;
- // 3.将上一时刻满足cur_cutoff(=cur_min_cost + adaptive_beam)条件的active_token
- // 进行解码图上的非eps_input跳转,保留满足next_cutoff(=next_min_cost + adaptive_beam)的
- // link,并存入当前时刻的active_token列表中
- BaseFloat cost_cutoff = ProcessEmitting(decodable);
-
- //Step2.3:解码图上的<eps> input跳转
- // 将当前时刻满足cur_cutoff(=cur_min_cost + adaptive_beam)条件的active_token进行解码图上的
- // eps_input跳转,保留满足cur_cutoff的link,并存入当前时刻的active_token列表中
- ProcessNonemitting(cost_cutoff);
- }
- }

FinalDecoding代码简介
- template <typename FST, typename Token>
- void LatticeFasterDecoderTpl<FST, Token>::FinalizeDecoding() {
-
- // Step1: 解码到达音频结尾处时,为最后时刻的Token加上解码图上的final_prob,获取最优路径的
- // 获取最优路径的长度min_cost,修剪掉与min_cost差值大于lattice_beam值的Tokens和links
- int32 final_frame_plus_one = NumFramesDecoded();
- int32 num_toks_begin = num_toks_;
- PruneForwardLinksFinal();
-
- // Step2: 从后向前,修剪掉与最优路径总长min_cost差值大于lattice_beam值的Tokens和links
- for (int32 f = final_frame_plus_one - 1; f >= 0; f--) {
- bool b1, b2; // values not used.
- BaseFloat dontcare = 0.0; // delta of zero means we must always update
- PruneForwardLinks(f, &b1, &b2, dontcare);
- PruneTokensForFrame(f + 1);
- }
- PruneTokensForFrame(0);
- KALDI_VLOG(4) << "pruned tokens from " << num_toks_begin
- << " to " << num_toks_;
- }
解码器涉及的知识点很多,虽然基于WFST的解码器目前最常用,但也要具体问题具体分析,其他算法也不会完全过时。本文简单介绍了解码器的由来和它的发展,以及基于WFST解码器的一些知识点,有兴趣了解的同学可以翻阅相关资料进一步学习。
以上内容除了WFST理论介绍中的部分图片引用自《Speech Recognition Algorithms Using Weighted Finite-State Transducers》,其他文件包括图片和公式都是原创,转载需求请联系微信:xqqnuaa2013
https://u.wechat.com/ELU4TLK9vhfplwqxF2nlykA (二维码自动识别)
参考资料
[1]《Speech Recognition Algorithms Using Weighted Finite-State Transducers》Takaaki Hori
[2]《A COMPARISON OF TE CHNIQUES FOR LANGUAGE MODEL INTEGRATION IN ENCODER-DECODER SPEECH RECOGNITION》Shubham Toshniwal
[3] kaldi中hashlist阅读总结_u013677156的专栏-CSDN博客
[4]kaldi代码

