- 1java8新特性_18_新时期与日期API_本地时间和时间戳_18may20java
- 2【Pytorch】torchtext终极安装方法及常见问题_torchtext安装
- 3rasa.core.agent - Could not load model due to No NLU or Core data for unpacked model at: '/tmp/tmpc...
- 4光标 与 输入法 之 android:imeOptions属性_代码设置 android:imeoptions="actionsearch
- 5鸿蒙开发学习教程大全:从入门到精通的全攻略_鸿蒙开发教程
- 6Linux 搭建 JumpServer 堡垒机_linux搭建jumpserver
- 7AI > 语音识别开源项目列举_ai语音识别开发
- 8数据结构——双向循环链表
- 9LTP4.2.0 哈工大分词 库python使用踩坑_安装ltp哈工大
- 10【开题报告】基于SpringBoot的社区老人健康跟踪管理系统设计与实现_基于springboot的养老服务平台的设计与实现的开题报告在,写
一文速览 | 对话生成预训练模型
赞
踩

作者 | 惠惠惠惠惠惠然
整理 | NewBeeNLP
大规模预训练言模型在生成式对话领域近年来有非常多的工作,如百度PLATO系列(PLATO[1]/PLATO-2[2]/PLATO-XL[3]),微软DialoGPT[4],谷歌Meena[5],FaceBook Blender[6]等等,得益于大规模参数和精细的模型设计,这些对话生成预训练模型(Dialogue PTMs, 本文以下简称D-PTMS)在开放域对话获得了非常好的表现。
区别于传统的生成式PTM例如GPT和BART,D-PTMs更针对于对话场景。明显的区别就是在于GPT等模型的训练数据来自于百科、新闻、小说,而D-PTMs使用的是对话数据进行训练。这篇文章主要针对这些经典模型梳理对话生成预训练模型的设计方法和基本概念。
一、对话生成预训练模型的结构设计
目前的对话生成PTM的结构大体分为三种:
基于Transformer-encoder-decoder 的结构 「Transformer-ED」 例如Google Meena以及FaceBook Blender;
Transformer的Decoder结构 「Transformer-Dec」 比如微软DialoGPT,清华智源CDial-GPT[7];
Transformer-Encoder基础上改进的UniLM-based结构,代表性的是Baidu的PLATO系列,其论文中被称为 「Unified-transformer」。
1.1 Transformer-ED
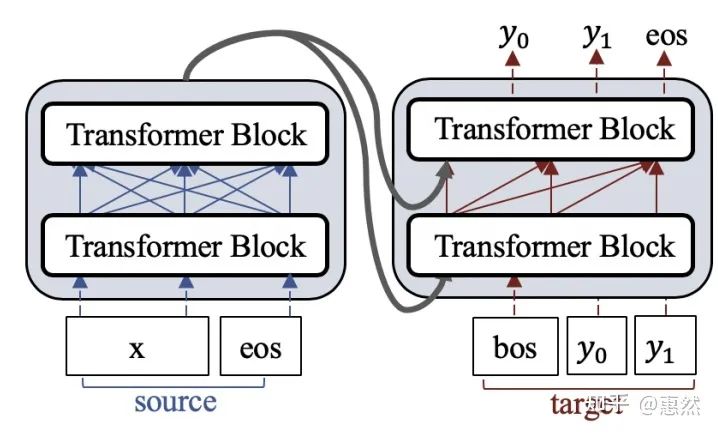
经典的Transformer结构将Encoder和Decoder进行独立,预训练时encoder将对话历史进行编码,然后将编码后的结果传给decoder以生成回复。需要注意的是encoder部分的mask是双向语言模型建模,decoder部分是单向语言模型建模。
这样的结构设计主要会带来两种问题,首先,解码器堆叠在编码器输出上。使得微调过程在更新编码器参数时效率较低;其次有部分工作UNILMv2[8]指出在Transformer-ED架构中的显式编码器可能是冗余的,编码步骤可以直接合并到解码器中,从而允许更直接地更新参数。
1.2 Transformer-Dec
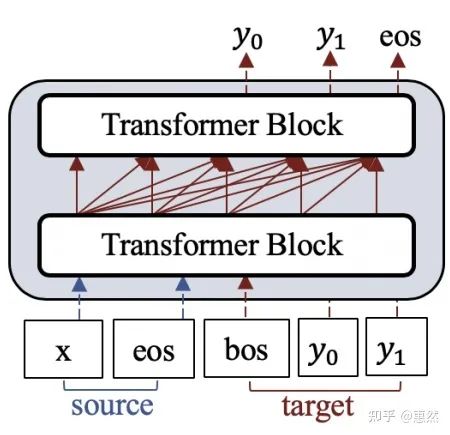
以Transformer-Dec为基本结构的模型具有代表性的是GPT系列模型,以其为结构的D-PTMs使用同样的结构,将对话历史使用单向语言模型进行编码,然后预测回答。由于GPT作为生成模型的效果非常好,以这样的思路将该结构应用在对话数据上是很直观的想法。
但由于单向语言模型的设计导致编码过程中对context的编码也是单向的,而在NLU过程中,双向语言模型一般效果更好。所以后来就产生了以PLATO为代表,集NLU和NLG为一体的unified-transformer结构。
1.3 Unified-transformer
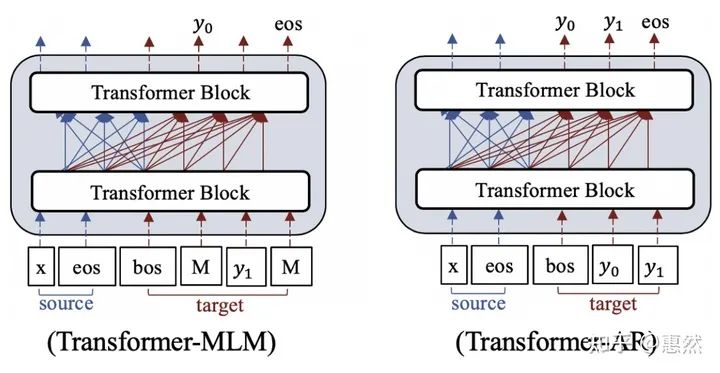
Unified-transformer的结构灵感来自UniLM[9],一种统一NLU和NLG两个任务的模型:用双向语言模型编码context,单向语言模型编码target。这种掩码方式就可以解决Transformer-Dec结构的模型在理解对话context时不能使用双向语言模型的问题。按照不同的预训练任务,该结构的模型又可以分为上图Transformer-MLM和Transformer-AR两种类别。
1.4 不同结构的模型对比

有工作Open-Domain Dialogue Generation Based on Pre-trained Language Models[10]将以上四种结构的模型在相同的数据集上进行实验,论文中将以上的四种模型按顺序称为Trans-ED, Trans-Dec, Trans-MLM, Trans-AR。
实验中主要使用三种数据集:Twitter[11], Ubuntu[12], Reddit[13] 为了评估模型在不同大小数据集上的实验效果,作者比较了用全部数据集训练和使用100k数据集训练的不同效果。并且使用自动评估和人工评估两种方法评估。
表格中上方数据为全部数据的训练结果,下方数据是100k数据的训练结果
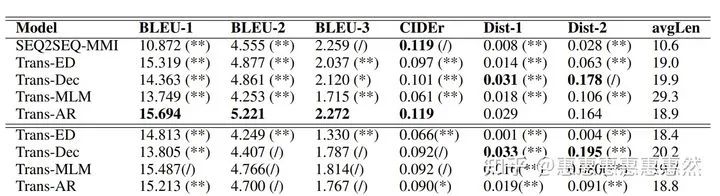
自动评测标准下,大数据集下Trans-AR和Trans-Dec的最终结果较好,而小数据集下Trans-AR的实验效果一般。作者分析可能是Trans-AR使用了BERT这样的MLM-PTM初始化导致的pretrain-finetune不一致所以产生效果下降。
人工标准下,Trans-Dec和Trans-AR有时会重复产生输入的句子,而Trans-MLM不会。此外Trans-Dec的生成结果更具有多样性,作者认为可能是source端的单向attention不会从双向对模型进行约束。
而无论在人工和自动的评测结果下,Trans-ED的结果都不理想。
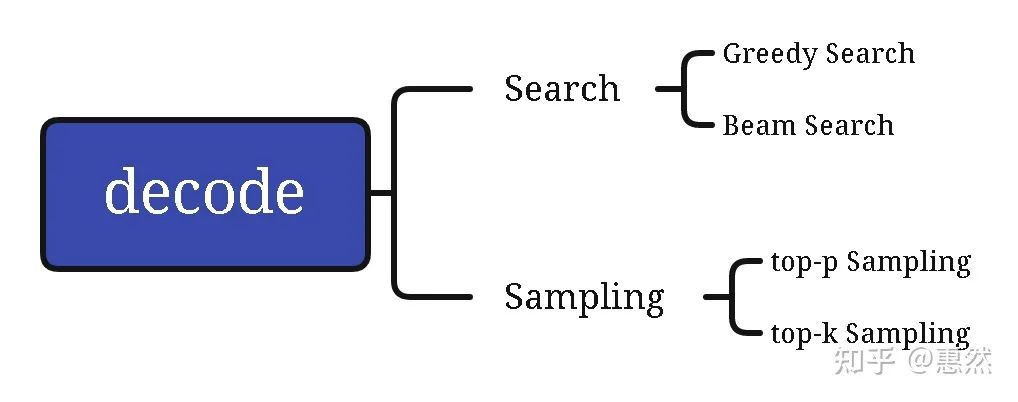
二、decode 方法的选择
decode方法大致分为Search和Sampling的两大类
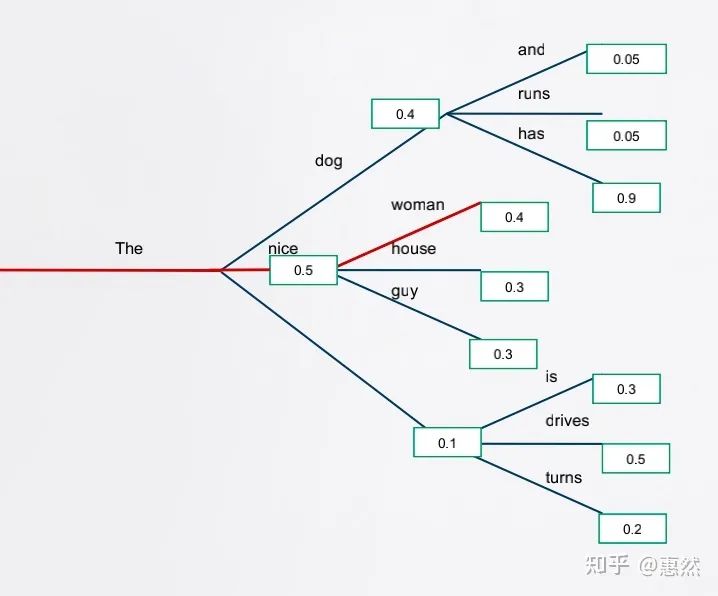
2.1 Greedy-Search
每一步选择预测得分最高的token,这种方法明显的问题是模型会因为当前步较低的得分而忽略掉后面高分的选择。比如说路径"The dog has",这条路径会因为"dog"0.4的分数而忽略掉"has"0.9的分数 这样的局部最优算法容易生成通用无意义的答案,以及前后重复的结果。
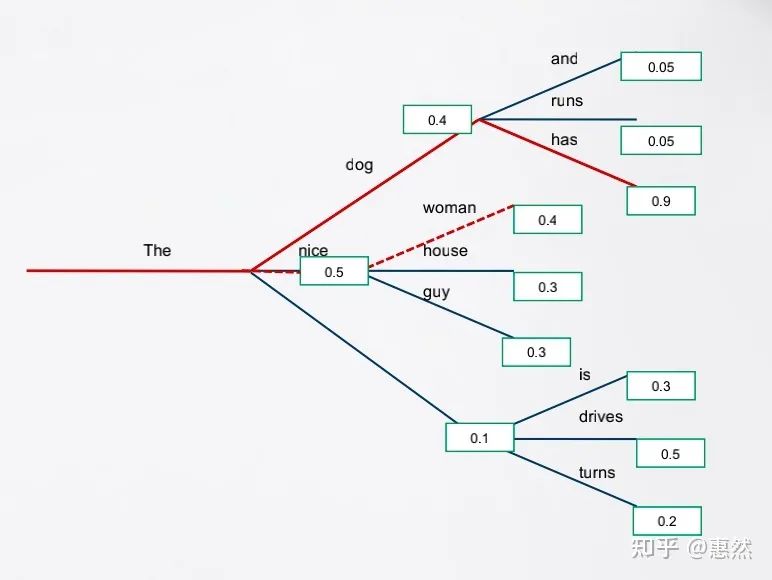
2.2 Beam-Search
beam search的核心思想是在每一步深度扩展的时候,通过设置beam size剪掉一些质量比较差的节点,保留一些质量比较高的节点。比如说下图中设置beam size=2,这时在第一步推理时保留"dog"和"nice"两个分数较高的选择。在第二步推理时,这种搜索方式就会找到比greedy search的结果"The nice woman "分数0.4更高的"The dog has"0.9。虽然beam search通常可以找到比greedy search分数更高的sequence,但仍有可能存在潜在方案被丢弃的问题。
2.3 Top-k Sampling
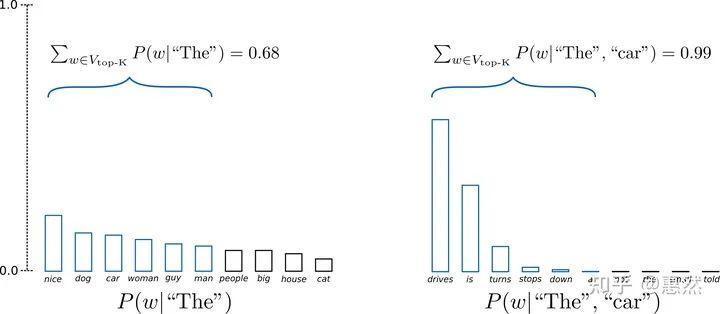
从概率值前top-k中进行随机采样。GPT-2就是采用这样的decode方式,这种方法的生成结果多样性较好,随机性较强,生成的结果大多通顺。但也容易存在采样到低概率单词的情况,可能导致生成质量不佳。
2.4 Top-p Sampling
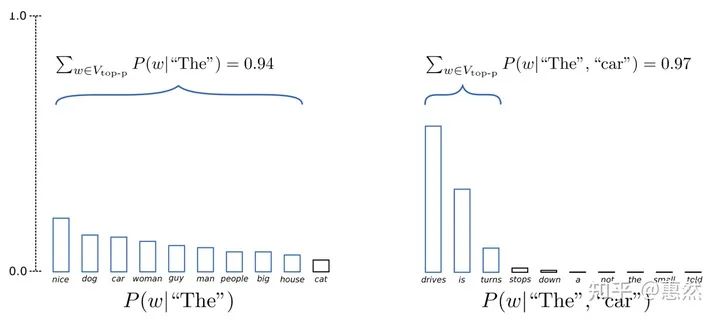
设置一定的概率阈值,选择概率大于该阈值的结果作为候选,在其中进行随机采样。整体来说top-p的采样方式比top-k不容易采取到低概率的token,所以生成的结果会更加通顺。
在选用search或sampling方法decode得到了一系列可能的回复之后,一般还会再加入回复选择策略,例如RCE Rank以及MMI Rank。
「RCE Rank」
训练context与response相关性判断模型,根据相关性得分来对候选response进行选择排序,防止随机采样引入的不合理answer.
「MMI Rank (maximum mutual information rank)」
MMI Rank最早在微软的DialoGPT中被使用,它是一个基于GPT2的生成模型:采用预训练的backward模型(context 和response逆序拼贴)来预测给定response的context。计算Dialogue Model生成的所有候选response相对于context的loss,选择loss最小的作为最终的结果。DialoGPT的作者认为,最大化反馈模型概率惩罚了那些"温和"的回复,这是由于频繁的和重复的回复可以与许多可能context关联,因此得到的概率都比较低。
三、评估标准
D-PTMs的评估标准有自动评估指标和人工评估两个大类。其中自动评估指标可作为模型快速迭代参考,不需要人工参与,但自动指标与真实效果存在一定的gap。人工指标主观性较强,且需要人工团队。
3.1 自动评估指标
「评估word-overlap的指标」:
衡量word-overlap实际上是机器翻译任务中的常用指标,核心思想是比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。常用的指标如BLEU-ngram,以及基于它的系列改进ROUGE、NIST、METEOR
「评估文本生成多样性的指标」
常用指标是Distinct-ngram,
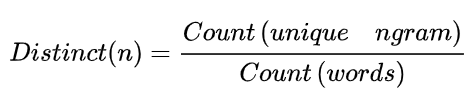
Count(unique ngram)表示回复中不重复的ngram数量,Count(word)表示回复中ngram词语的总数量。值越大表示生成的多样性越高。
「基于语言模型的评估」
例如perplexity,perplexity是语言模型中的指标,用于评价语言模型的好坏,即估算一句话出现的概率,看一句话是否通顺。google Meena的论文中表示ppl分数与其构建的人工评估体系得分SSA有明显的负相关,与人工评估的gap比较小。
3.2 人工评估指标
目前几家公司都为自己的对话生成预训练模型设计了人工评估的体系。
「Google Meena - SSA」
Sensibleness:回复合理,复符合逻辑,保持一致性;
Specficity:回复内容具体,不能是万能答复;
Average:两者平均;
「ACUTE(Facebook Blender)」
ACUTE-Eval:两个chatbot同时与同一个人聊,判断哪个聊得更好;
Self-Chat ACUTE-Eval:两个chatbot自己与自己聊,人工判断哪个聊得更好;
「Chinese evaluation(Baidu Plato)」
Coherence:回复内容的上下文相关性;
Informativeness:回复内容是否包含信息量;
Engagingness:回复内容的新颖性;
Humanness:回复内容是否人性化,跟人类回复的相似性;
「DialoGPT(Microsoft)」
relevance: 回复内容的上下文相关性;
informativeness: 回复内容是否包含信息量;
human-likeness: 回复内容是否人性化,跟人类回复的相似性;
四、数据集
4.1 预训练数据集
为了减少通用预训练模型与对话场景下的预训练模型的偏差,首先会在如下的大型数据集上进行继续训练。(DialoGPT和Meena的实验表示在预训练模型上继续训练比从头开始训练的要效果更好)。这样大规模的对话数据并不好获得,所以一般是从Reddit,Weibo这样的论坛数据的帖子评论等去解析获得“树状”的对话数据。且由于这样的论坛数据噪声很大,在使用前需要设计一些过滤条件进行清洗。
「EN」
Reddit comments - DialoGPT, PLATO,Blender
Social Media Conversation - Meena
Twitter - PLATO
「ZH」
Chinese Social Media -PLATO
WDC-Dialogue dataset - EVA[14]
LCCC conversations - CDial-GPT
4.2 个性化对话生成数据集
预训练数据量虽然很大,但是不是直接的双向对话数据,是一种群体讨论(group discussion),虽然包含很多有用的内容,但是即使在过滤之后,仍然有很多噪音. 相比一下,更小,更干净,更集中的任务可以提高具体的能力。
「ConAI2」 dataset 个性化和与吸引能力 - Blender
14K对话,基于PersonaChat,模拟场景初次见面了解对方性格。
「Empathetic Dialogues」 同理心 - Blender
150K对话,一个说话人在说自己的情况,另一个人适时表达同情
「Wizard of Wikipedia」 知识 - Blender
250 主题下的194k对话,深度谈论某一个主题并给出专业化的回复。
「Blended Skill Talk」 技能混合 - Blender
将以上三个模型产生的回复做出选择,选出最合适的一个
「Daily Dialog」 - PLATO
从英文学习者的对话网站上进行爬取,并标注了情感和意图
「DSTC7-AVSD」 - PLATO、DialoGPT
端到端对话建模任务,其中的目标是通过注入基于外部知识的信息来产生获得比闲聊更好的对话回复。
「Persona-Chat」 - PLATO
提供了手动注释的对话,也提供了相应的人物角色配置(背景知识),其中两个参与者自然地聊天,并试图了解对方。
以上是我在初步了解对话生成预训练模型时的知识梳理。欢迎交流!如有问题敬请斧正!
本文参考资料
[1]
PLATO: https://aclanthology.org/2020.acl-main.9/
[2]PLATO-2: https://arxiv.org/abs/2006.16779
[3]PLATO-XL: https://arxiv.org/pdf/2109.09519.pdf
[4]DialoGPT: https://arxiv.org/pdf/1911.00536.pdf
[5]Meena: https://arxiv.org/pdf/2001.09977.pdf
[6]FaceBook Blender: https://arxiv.org/pdf/2004.13637.pdf
[7]CDial-GPT: https://arxiv.org/pdf/2008.03946.pdf
[8]UNILMv2: http://proceedings.mlr.press/v119/bao20a/bao20a.pdf
[9]UniLM: https://arxiv.org/pdf/1905.03197.pdf
[10]Open-Domain Dialogue Generation Based on Pre-trained Language Models: https://arxiv.org/pdf/2010.12780.pdf
[11]Twitter: https://github.com/Marsan-Ma-zz/chat
[12]Ubuntu: https://github.com/rkadlec/ubuntu-ranking-dataset
[13]Reddit: https://github.com/nouhadziri/THRED
[14]EVA: https://arxiv.org/pdf/2108.01547.pdf
- END -


NLP的“第四范式”之Prompt Learning总结:44篇论文逐一梳理