
- 1输入参数的数目不足 matlab_干货|利用MATLAB实现FMCW MIMO雷达的超分辨测角
- 2CROSSFORMER: A VERSATILE VISION TRANSFORMER BASED ON CROSS-SCALE ATTENTION 论文阅读笔记
- 3Javascript-力扣-hot100-49. 字母异位词分组
- 4AI/DM相关conference ddl(更新中)_iclr2024
- 5[深度学习][转载]Msnhnet一款优秀轻量的用于推理pytorch模型的框架
- 6我给Chat GPT写了个记忆系统_chat gpt 会话长记忆
- 7企业如何设计和实施有效的网络安全演练?
- 8重磅!459页《用Python进行深度学习》电子书及源码下载!_《使用 python 进行深度学习》pdf 百度云
- 9python&anconda系列:【ChatGLM2-6B】运行问题、【ChatGLM2-6B】环境部署_chatglm2运行时没有回复
- 10SINE: 一种基于扩散模型的单图像编辑解决方案_微调文本到图像扩散模型过拟合的问题
StarRocks 安装与配置_starrocks启动参数
赞
踩


大数据技术AI
Flink/Spark/Hadoop/数仓,数据分析、面试,源码解读等干货学习资料
109篇原创内容
公众号
1、StarRocks简介
下载地址:https://www.starrocks.com/zh-CN/download
特点:

使用场景:
1.1 StarRocks介绍
-
StarRocks是新一代极速全场景MPP数据库
-
StraRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果,在业界实践的基础上,进一步改进优化、升级架构,并增添了众多全新功能,形成了全新的企业级产品。
-
StarRocks致力于构建极速统一分析体验,满足企业用户的多种数据分析场景,支持多种数据模型(明细模型、聚合模型、更新模型),多种导入方式(批量和实时),可整合和接入多种现有系统(Spark、Flink、Hive、 ElasticSearch)。
-
StarRocks兼容MySQL协议,可使用MySQL客户端和常用BI工具对接StarRocks来进行数据分析。
-
StarRocks采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持10PB级别的数据分析; 支持MPP框架,并行加速计算; 支持多副本,具有弹性容错能力。
-
StarRocks采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;使用向量化执行方式,充分挖掘多核CPU的并行计算能力,从而显著提升查询性能。
1.2 StarRocks适合什么场景
StarRocks可以满足企业级用户的多种分析需求,包括OLAP多维分析、定制报表、实时数据分析和Ad-hoc数据分析等。具体的业务场景包括:
-
OLAP多维分析
-
用户行为分析
-
用户画像、标签分析、圈人
-
高维业务指标报表
-
自助式报表平台
-
业务问题探查分析
-
跨主题业务分析
-
财务报表
-
系统监控分析
-
实时数据分析
-
电商大促数据分析
-
教育行业的直播质量分析
-
物流行业的运单分析
-
金融行业绩效分析、指标计算
-
广告投放分析
-
管理驾驶舱
-
探针分析APM(Application Performance Management)
-
高并发查询
-
广告主报表分析
-
零售行业渠道人员分析
-
SaaS行业面向用户分析报表
-
Dashbroad多页面分析
-
统一分析
-
通过使用一套系统解决多维分析、高并发查询、预计算、实时分析、Adhoc查询等场景,降低系统复杂度和多技术栈开发与维护成本。
1.3 StarRocks基本概念
-
FE:FrontEnd简称FE,是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。
-
BE:BackEnd简称BE,是StarRocks的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作。
-
Broker:StarRocks中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
-
StarRocksManager:StarRocks的管理工具,提供StarRocks集群管理、在线查询、故障查询、监控报警的可视化工具。
-
Tablet:StarRocks中表的逻辑分片,也是StarRocks中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
1.4 StarRocks系统架构
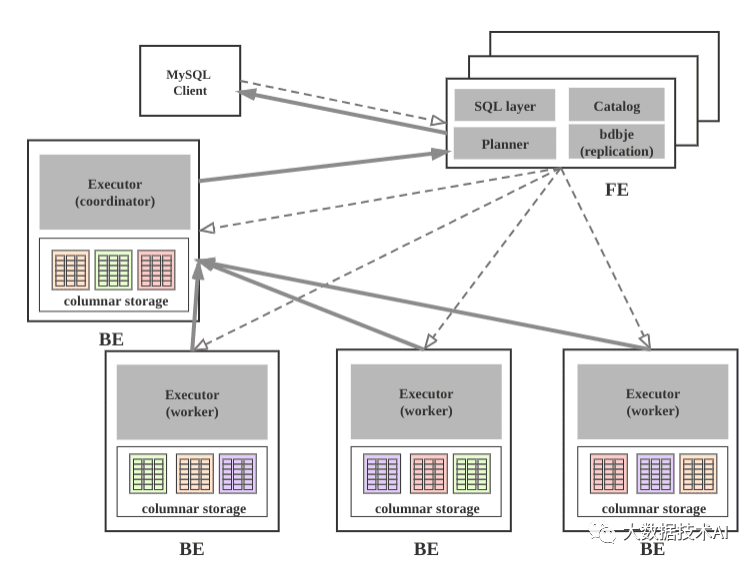
系统架构图
组件介绍
StarRocks集群由FE和BE构成, 可以使用MySQL客户端访问StarRocks集群。
FE
FE接收MySQL客户端的连接, 解析并执行SQL语句。
-
管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
-
FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。元数据的读写满足顺序一致性。FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
-
FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
-
FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
-
FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
-
FE协调数据导入, 保证数据导入的一致性。
BE
-
BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
-
BE受FE指导, 创建或删除子表。
-
BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
-
BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
-
BE后台执行compact任务, 减少查询时的读放大。
-
数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
2、部署
2.0 包目录内容
StarRocks-XX-1.0.0 ├── be # BE目录 │ ├── bin │ │ ├── start_be.sh # BE启动命令 │ │ └── stop_be.sh # BE关闭命令 │ ├── conf │ │ └── be.conf # BE配置文件 │ ├── lib │ │ ├── starrocks_be # BE可执行文件 │ │ └── meta_tool │ └── www ├── fe # FE目录 │ ├── bin │ │ ├── start_fe.sh # FE启动命令 │ │ └── stop_fe.sh # FE关闭命令 │ ├── conf │ │ └── fe.conf # FE配置文件 │ ├── lib │ │ ├── starrocks-fe.jar # FE jar包 │ │ └── *.jar # FE 依赖的jar包 │ └── webroot └── udf

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.1 部署FE
2.1.1 FE的基本配置
FE的配置文件为StarRocks-XX-1.0.0/fe/conf/fe.conf, 默认配置已经足以启动集群, 有经验的用户可以查看手册的系统配置章节, 为生产环境定制配置,为了让用户更好的理解集群的工作原理, 此处只列出基础配置。
2.1.2 环境准备
准备三台物理机, 需要以下环境支持:
-
Linux (Centos 7+)
-
Java 1.8+
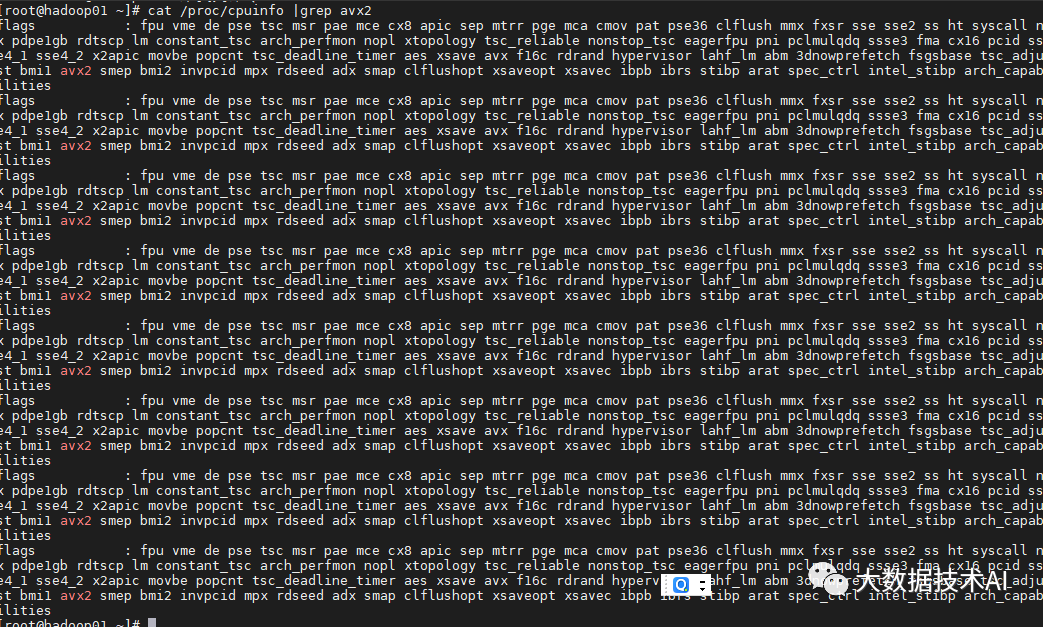
CPU需要支持AVX2指令集,cat /proc/cpuinfo |grep avx2有结果输出表明CPU支持,如果没有支持,建议更换机器,StarRocks使用向量化技术需要一定的指令集支持才能发挥效果。
将StarRocks的二进制产品包分发到目标主机的部署路径并解压,可以考虑使用新建的StarRocks用户来管理。
2.1.3 FE单实例部署
(1)解压tar包
[root@hadoop01 software]# tar -zxvf StarRocks-2.0.1.tar.gz -C /data/
- 1
(2)部署FE,修改配置文件,添加jvm参数,建议-Xmx参数设置到16G以上
[root@hadoop01 software]# cd /data/StarRocks-2.0.1/fe/conf/
[root@hadoop01 conf]# vim fe.conf
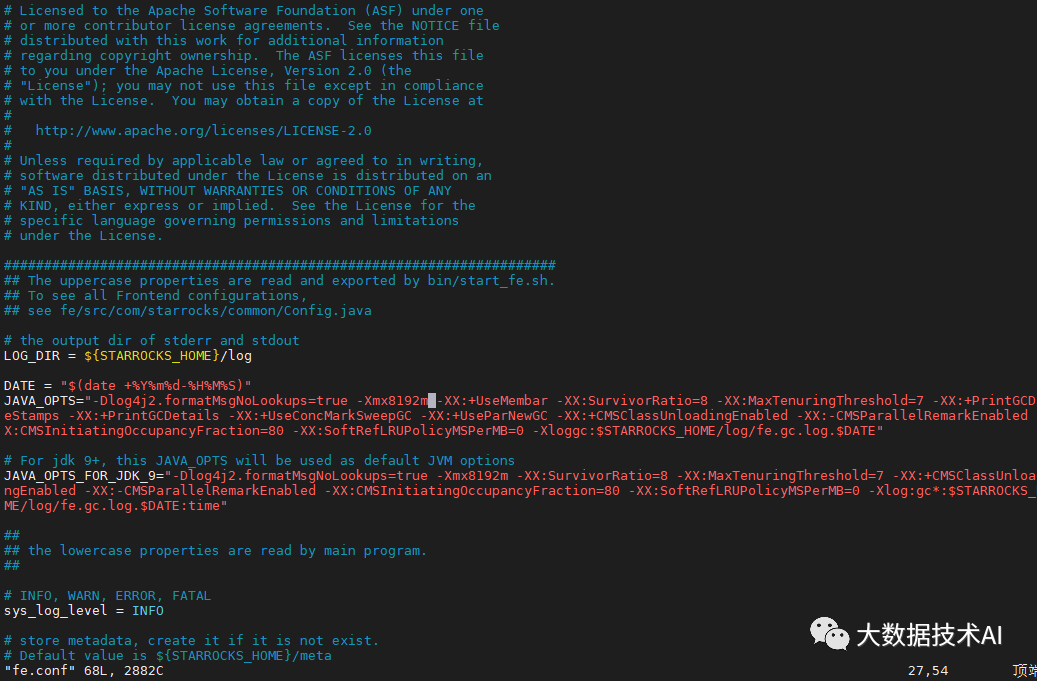
JAVA_OPTS = "-Xmx4096m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$STARROCKS_HOME/log/fe.gc.log"
- 1
- 2
- 3
- 4
(3)创建元数据目录
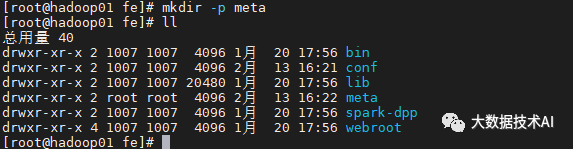
[root@hadoop01 conf]# cd ..
[root@hadoop01 fe]# mkdir -p meta
- 1
- 2
- 3
注意:mkdir -p meta (1.19.x及以前的版本需要使用mkdir -p doris-meta)
(4)分发给hadoop02,hadoop03
[root@hadoop01 module]# scp -r StarRocks-2.0.1/ hadoop02:/data/
[root@hadoop01 module]# scp -r StarRocks-2.0.1/ hadoop03:/data/
- 1
- 2
(5)启动hadoop02 FE节点
[root@hadoop02 fe]# bin/start_fe.sh --daemon
- 1

(6)确认启动FE启动成功
-
查看日志log/fe.log确认。
-
如果FE启动失败,可能是由于端口号被占用,修改配置文件conf/fe.conf中的端口号http_port。
-
使用jps命令查看java进程确认"StarRocksFe"存在。
-
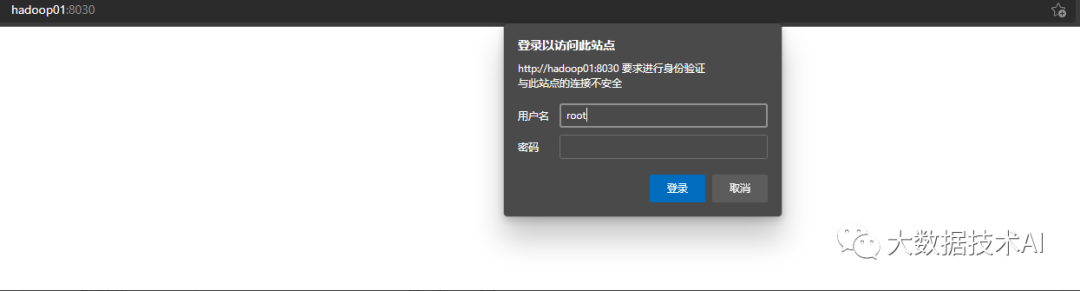
使用浏览器访问8030端口, 打开StarRocks的WebUI, 用户名为root, 密码为空。
2.1.4 使用MySQL客户端访问FE
(1)启动mysql客户端,访问FE,查看FE状况
[root@hadoop02 fe]# mysql -h hadoop02 -uroot -P9030
mysql> SHOW PROC '/frontends'\G
- 1
- 2
注意:这里默认root用户密码为空,端口为fe/conf/fe.conf中的query_port配置项,默认为9030
(2)查看FE状态
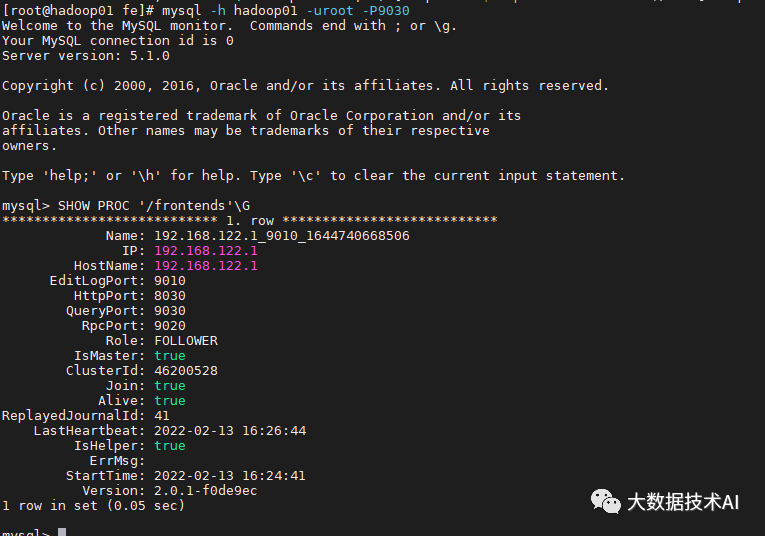
-
Role为FOLLOWER说明这是一个能参与选主的FE;
-
IsMaster为true,说明该FE当前为主节点。
如果MySQL客户端连接不成功,请查看log/fe.warn.log日志文件,确认问题。由于是初次启动,如果在操作过程中遇到任何意外问题,都可以删除并重新创建FE的元数据目录,再从头开始操作
2.1.5 FE的高可用集群部署
FE的高可用集群采用主从复制架构, 可避免FE单点故障. FE采用了类raft的bdbje协议完成选主, 日志复制和故障切换. 在FE集群中, 多实例分为两种角色: follower和observer;
-
前者为复制协议的可投票成员, 参与选主和提交日志, 一般数量为奇数(2n+1), 使用多数派(n+1)确认, 可容忍少数派(n)故障;
-
而后者属于非投票成员, 用于异步订阅复制日志, observer的状态落后于follower, 类似其他复制协议中的learner角色。
FE集群从follower中自动选出master节点, 所有更改状态操作都由master节点执行, 从FE的master节点可以读到最新的状态. 更改操作可以从非master节点发起, 继而转发给master节点执行, 非master节点记录最近一次更改操作在复制日志中的LSN, 读操作可以直接在非master节点上执行, 但需要等待非master节点的状态已经同步到最近一次更改操作的LSN, 因此读写非Master节点满足顺序一致性. Observer节点能够增加FE集群的读负载能力, 时效性要求放宽的非紧要用户可以读observer节点。
FE节点之间的时钟相差不能超过5s, 使用NTP协议校准时间。
一台机器上只可以部署单个FE节点。所有FE节点的http_port需要相同。
配置如下:
(1)添加其他FE节点,角色也分为FOLLOWER,OBSERVER
使用MySQL客户端连接已有的FE, 添加新实例的信息,信息包括角色、ip、port:
mysql> ALTER SYSTEM ADD FOLLOWER "hadoop03:9010";
mysql> ALTER SYSTEM ADD OBSERVER "hadoop02:9010";
- 1
- 2
(2)启动hadoop03,hadoop01 FE节点,第一次启动需指定–helper参数,后续再启动无需指定此参数
[root@hadoop03 fe]# bin/start_fe.sh --helper hadoop01:9010 --daemon
[root@hadoop01 fe]# bin/start_fe.sh --helper hadoop01:9010 --daemon
- 1
- 2
FE节点之间需要两两互联才能完成复制协议选主, 投票,日志提交和复制等功能。FE节点首次启动时,需要指定现有集群中的一个节点作为helper节点, 从该节点获得集群的所有FE节点的配置信息,才能建立通信连接,因此首次启动需要指定–helper参数:
当FE再次启动时,无须指定–helper参数,因为FE已经将其他FE的配置信息存储于本地目录, 因此可直接启动:
./bin/start_fe.sh --daemon
- 1
(3)全部启动完毕后,再使用mysql客户端查看FE的状况,alive全显示true则无问题
mysql> SHOW PROC '/frontends'\G
- 1
节点的Alive显示为true则说明添加节点成功
(4)节点的Alive显示为true则说明添加节点成功
alter system drop follower "fe_host:edit_log_port";
alter system drop observer "fe_host:edit_log_port";
- 1
- 2
2.2 部署BE
2.2.1 单点部署
(1)部署BE,用户可以使用命令直接将BE添加到集群中,一般至少布置3个BE,每个BE实例添加步骤相同
[root@hadoop02 module]# cd StarRocks-2.0.1/be/
[root@hadoop02 be]# mkdir -p storage
- 1
- 2
- 3
(2)使用mysql客户端添加hadoop02对应be节点
mysql> ALTER SYSTEM ADD BACKEND "hadoop02:9050";
- 1
这里IP地址为和priority_networks设置匹配的IP,portheartbeat_service_port,默认为9050
如出现错误,需要删除BE节点,应用下列命令:
alter system decommission backend "be_host:be_heartbeat_service_port";
- 1
(3)添加完毕后,启动hadoop02 BE节点
[root@hadoop02 be]# bin/start_be.sh --daemon
- 1
(4)查看BE状况,也是同样alive为true是正常运行
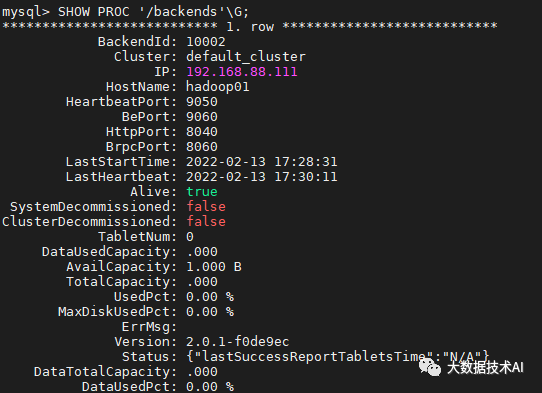
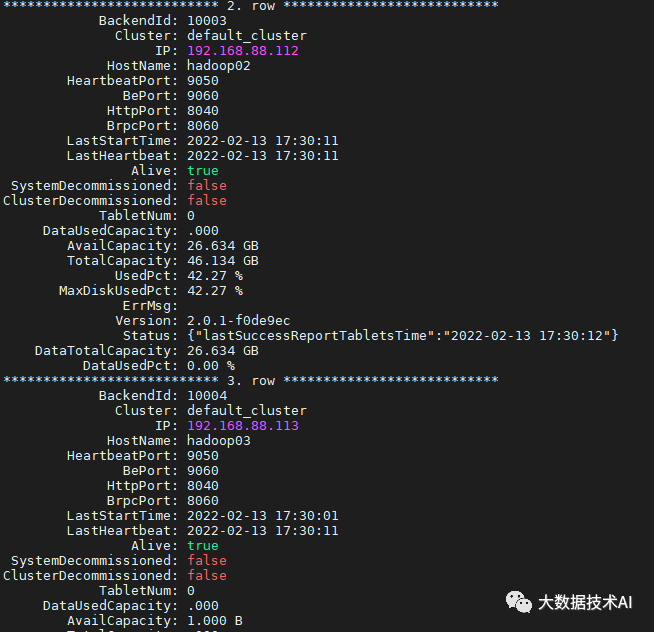
mysql> SHOW PROC '/backends'\G
- 1
2.2.2 BE集群部署
(1)同样步骤在hadoop03,hadoop01部署BE,并添加节点
[root@hadoop03 module]# cd StarRocks-2.0.1/be/
[root@hadoop03 be]# mkdir -p storage
[root@hadoop01 module]# cd StarRocks-2.0.1/be/
[root@hadoop01 be]# mkdir -p storage
mysql> ALTER SYSTEM ADD BACKEND "hadoop03:9050";
mysql> ALTER SYSTEM ADD BACKEND "hadoop01:9050";
[root@hadoop03 be]# bin/start_be.sh --daemon
[root@hadoop01 be]# bin/start_be.sh --daemon
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3 部署Broker
(1)部署Broker,此角色主要用于后续Broker load使用,启动安装目录的Broker服务
[root@hadoop02 StarRocks-2.0.1]# cd apache_hdfs_broker/
[root@hadoop02 apache_hdfs_broker]# bin/start_broker.sh --daemon
[root@hadoop03 StarRocks-2.0.1]# cd apache_hdfs_broker/
[root@hadoop03 apache_hdfs_broker]# bin/start_broker.sh --daemon
[root@hadoop01 StarRocks-2.0.1]# cd apache_hdfs_broker/
[root@hadoop01 apache_hdfs_broker]# bin/start_broker.sh --daemon
- 1
- 2
- 3
- 4
- 5
- 6
(2)使用mysql添加对应节点
mysql> ALTER SYSTEM ADD BROKER broker1 "hadoop02:8000";
mysql> ALTER SYSTEM ADD BROKER broker2 "hadoop03:8000";
mysql> ALTER SYSTEM ADD BROKER broker3 "hadoop01:8000";
- 1
- 2
- 3
(3)查看状态
mysql> SHOW PROC "/brokers"\G
- 1


