
- 1计算机二级vfp有填空么,计算机二级VFP备考建议|文末有资源
- 2k8s入门到实战(五)—— k8s存储卷详细介绍
- 3sed命令n,N,d,D,p,P,h,H,g,G,x解析_sed n
- 4JAVA二维数组的概述、定义格式、遍历、求和、杨辉三角、参数传递、数组加密_二维数组的定义java11
- 5Java 4-6、优化启动配置,properties改为yml_java根据环境启动切换yml文件
- 6分享一下在微信小程序上怎么实现投票功能_小程序内嵌投票怎么弄
- 7python:遍历文件夹下的文件_python遍历文件夹所有文件
- 83588板子部署yoloV5_rk3588非量化部署yolo
- 9Android使用iText7生成PDF文件_android com.itextpdf
- 10java安卓模拟器和电脑通信_Android 模拟器(JAVA)与C++ socket 通讯 分享
Pytorch入门
赞
踩
1.摘要
本篇博客参考Pytorch官方教程中文版和《Drive Into Deep Learning》Pytorch版对Pytorch和深度学习的基础知识进行总结,以便加深理解和记忆
2.概述
1)简介:Pytorch是一个基于Torch的Python开源机器学习库,主要由Facebookd人工智能小组开发
2)前身:Torch是Pytorch的前身,是一个具有大量机器学习算法支持的科学计算框架,特点是灵活,基于Lua开发
3)特点(优点)
①具有GPU加速的张量计算(和Numpy类似的张量操作库)
②支持动态神经网络,包含自动求导系统的深度神经网络(一些主流框架都不支持,如TensorFlow、Caffe都是命令式的编程语言,首先需要静态地构建一个神经网络,训练间无法/难以改变网络的结构。但是Pytorch通过反向求导技术,可以零延迟地任意改变神经网络的行为,且实习速度快)
③语言更简洁,底层代码更易看懂 ④命令式体验 ⑤自定义扩展
4)不足
①全面性有待提高:不支持快速傅里叶、沿维翻转张量和检查无穷与非数值张量等
②对于移动端、嵌入式部署和高性能服务器端的部署的表现有待提升
3.安装
1)安装Anaconda
2)安装CUDA(英伟达GPU加速)
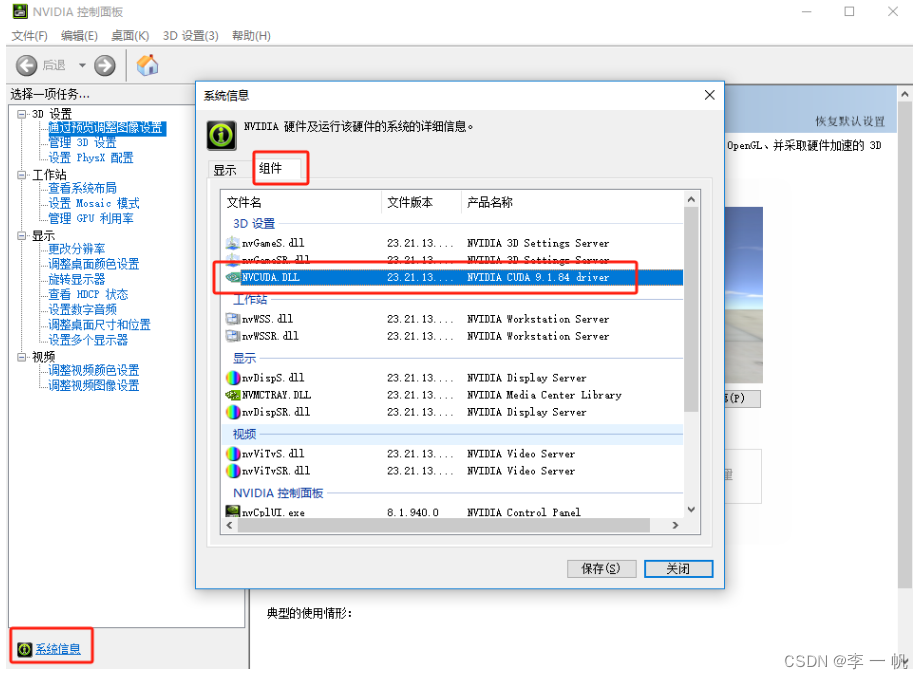
①查看适合本机的CUDA版本
- 打开nvidia控制面板(桌面右键的快捷图标 | 任务栏右下角 | 应用查找)
- 点击系统信息(控制面板左下角)
- 点击组件即可查看(3D设置中的NVCUDA64.DLL对应的产品名称)
②CUDA toolkit的下载与安装(GPU加速工具包)
-
进入CUDA toolkit的下载页,选择对应版本和系统的可执行文件下载,随后双击可执行文件
-
选择临时&安装目录:第一次目录选择临时解压目录(临时目录解压安装后自动删除),第二次目录选择解压目录(推荐默认,注意不要将这两个目录设置为同一个)
-
选择安装组件内容:精简安装会下载全部默认推荐的组件,会覆盖原有驱动;这里选择自定义选择:全部选择或仅选择第一项CUDA。另外会根据机器上已安依赖情况,对子项进行微调
-
选择安装位置:默认推荐
-
安装成功后,配置系统环境变量(一般为自动配置)
CUDA_PATH:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
DriverData:C:\Windows\System32\Drivers\DriverData
NVCUDASAMPLES_ROOT:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0
NVCUDASAMPLES11_0_ROOT:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0
NVTOOLSEXT_PATH:C:\Program Files\NVIDIA Corporation\NvToolsExt\
- 1
- 2
- 3
- 4
- 5
- 验证安装是否成功
# 查看版本
nvcc --version
nvcc -V
# 查看CUDA设置的环境变量
set cuda
- 1
- 2
- 3
- 4
- 5
③cuDNN的下载与安装(CUDA的深度学习扩展包,用于对CUDA toolkit进行补充和替换)
- 进入cuDNN的下载页,cuDNN下载前需要先注册一个账号
- 根据本机适用的CUDA版本和系统类型选择压缩包
- 将压缩包中的三个文件夹复制到CUDA的安装目录(
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0),系统会自动替换重名文件并补充扩展文件 - 配置环境变量
# 在系统环境变量中的Path中添加选项
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\libnvvp
- 1
- 2
- 3
- 4
- 5
- 验证是否安装成功
# 进入到demo套件目录
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\demo_suite
# 分别运行测试程序
bandwidthTest.exe # RESULT = PASS
deviceQuery.exe # RESULT = PASS
- 1
- 2
- 3
- 4
- 5
3)安装Pytorch(这个过程需要在网络比较好的情况下进行)
-
适用conda创建Pytorch环境,选择Python版本为3.6-3.8(最新Python版本可能不被Pytorch支持)
-
进入到Pytorch的官方下载页选择对应系统、Python版本、CUDA版本,复制下载命令到conda的pytorch环境中
-
验证安装情况
# 编写python脚本,引入pytorch依赖,并输出
import torch
print(torch)
- 1
- 2
- 3
3.科学计算
3.1张量
import torch # 1.torch.Tensor: 构造张量 # 1.1构造一个5x3张量,不初始化 x = torch.empty(5, 3) print(x) # 1.2构造一个随机初始化的张量 x = torch.rand(5, 3) print(x) # 1.3构造一个指定数据类型为long的零张量 x = torch.zeros(5, 3, dtype=torch.long) print(x) # 1.4构造一个直接使用具体数值的张量 x = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]]) print(x) # 1.5基于已存在张量创建一个新张量 x = x.new_ones(5, 3, dtype=torch.double) print(x) y = torch.randn_like(x, dtype=torch.float) print(y) # 2.torch.Size:获取张量的维度(该类型是一个元组因而支持元组操作) print(x.size()) print(torch.Size([5, 3])) # 3.张量运算 # 3.1加法 re = torch.add(x, y) print(re) re = x.add_(y) print(re) # 3.2索引操作:标准的Numpy方法(所有行,第一列) print(x[:, 1]) # 3.3torch.view:改变张量大小/形状 x = torch.randn(4, 4) y = x.view(16) z = x.view(-1, 8) print(x.size(), y.size(), z.size()) # 3.4获取张量某一元素的值 print(x[0, 0].item()) # 4.tensor.clamp(夹子)对Tensor中的元素进行过滤,常用于梯度裁剪(gradient clipping),即在梯度离散或梯度爆炸/消失时对梯度进行处理,使其限制在一个区间内 a = torch.rand(2, 3)*10 print('a\n', a) # 对于a中的小于2的会将值取为2,对于大于5的也会将值改为5;在2和5之间的则不变 a = a.clamp(2, 5) print('a\n', a)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
3.2张量乘法
-
mul:张量维度相同,对应元素相乘(点乘)
①tensor.mul(tensor) ≌ tensor * tensor
②torch.mul(input, other, *, out=None) → Tensor:input (Tensor) ,other (Tensor or Number)
-
mm:张量(矩阵)乘法
①tensor.mm(tensor) ≌ tensor @ tensor
②torch.mm(input,mat2,*,out=None) → Tensor
-
matmul:根据张量形状执行不同的计算
3.3自动微分
autogard是Pytorch所有神经网络的核心,它为张量Tensor上的所有操作提供自动微分,是一个由运行定义的框架
1)开启对张量和的追踪
在pytorch的计算中,张量Tensor和函数Function是重要的概念,其中Tensor表示了被计算的数据,Function表示具体的计算函数,Tensor和Function相互连接生成一个非循环图,它表示和存储完整的计算历史。
关于对张量计算的信息默认是不开启的,需要通过手动开启,计算类型保存在张量的.grad_fn属性中,梯度积累在.grad属性中
import torch
# requires_grad默认为True,设置张量的该属性开启则会记录计算信息
x = torch.ones(2,2,requires_grad=True)
x.requires_grad_(True)
print(x) # 用户手动创建的tensor,grad_fn属性为None
y = x + 2
print(y) # AddBackward0
z = y * y * 3
print(z) # MulBackward0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2)停止对输入张量的追踪
①为何停止?
神经网络的训练有时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整或只训练部分分支网络,并不让其梯度对主网络的参数造成影响,这时则可以在分支处切断对张量的追踪
②detach
import torch
# 开启操作记录和梯度累积
x = torch.ones(2, 2, requires_grad=True)
print(x)
# detach返回一个新的Tensor,该张量的requires_grad变为False,从记录中分离,但仍指向原变量的存放位置,两张量使用同一内存,一个修改也会影响另一个,即便再将y的requires_grad重设为True,它也不会再累积梯度。反向传播时到此detach处截断,梯度不再向前进行传播
y = x.detach()
print(x)
print(y.requires_grad)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
③with torch.no_grad()
追踪Tensor的操作和梯度可以在训练模型时很有用,但评估阶段时不需要梯度,用with torch.no_grad():包装起来的代码块可以停止追踪张量
3)pytorch实现反向传播中求导的方法
pytorch通过动态图机制,训练模型时每次迭代会创建一个新的计算图,计算图即代表变量之间的关系。其中计算图的每个叶子结点即是输入层变量,根结点则是输出的标量。
pytorch在利用计算图求导的过程中,为了避免困难,每个根节点都是一个标量(即多个输入对应一个输出),不允许Tensor对Tensor进行多对多的求导
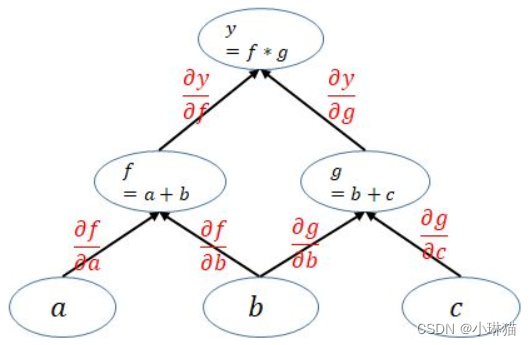
# 多输出O求导需要传入一个和输出张量同形的权重矩阵I,将多输出矩阵逐元素与权重矩阵对应元素相乘相加得到单一输出:Σ O_i * I_i
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
y = x + 2
print(y)
z = y * y * 3
print(z)
out = z
# 反向求导
out.backward(torch.tensor([[1, 0], [0, 0]]))
# 输出梯度: d(out) / dx
print(x.grad)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
# 单输出(标量)可以直接进行求导
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
y = x + 2
print(y)
z = y * y * 3
print(z)
out = z.mean()
print(out)
out.backward()
print(x.grad)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
pytorch的动态图为节省内存,在每轮迭代(backward)后计算图就被释放,因此如果需要在一个状态下进行多次反向求导则需要进行额外的配置:
# 1.保留backward后的中间参数,让计算图不被立即释放
out.backward(retain_graph=True)
# 2.创建计算图,两者实际作用相同
out.backward(create_graph=True)
- 1
- 2
- 3
- 4
4.构建神经网络
Pytorch通过torch.nn包(nerus net)中的模块来构建神经网络
41构建LeNet5示例
通过torch.nn.Module来构建自定义模型,nn包中包含了许多常用的Module(Sequence);Layer,包括2D|3D卷积层、线性层等
torch.nn.functional中包含了许多常用的激活函数/池化层用于对线性模块进行非线性变换
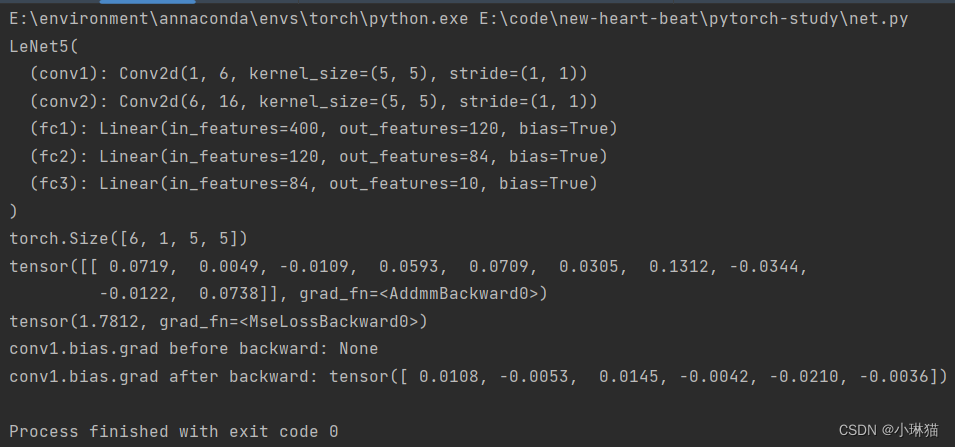
# LeNet5 with MNIST in pytorch """ ①卷积输入层:32×32的灰度图像 ②卷积层1:6个5×5×1的卷积核进行valid卷积,卷积后的结果:宽28(32-5+1)、高(32-5+1)、深度6 ③池化层1:6个2×2的矩阵进行valid最大池化,池化后的结果:14×14×6 ④卷积层2:16个5×5×6的卷积核进行valid卷积,卷积后的结果:10×10×16 ⑤池化层2:16个2×2的矩阵进行valid最大池化,池化后的结果:5×5×16 ⑥全连接输入层:将卷积池化输出的张量拉伸为1维向量,作为全连接层的输入,5×5×16=400 ⑥全连接隐藏层1:120个隐藏单元 ⑦全连接隐藏层2:84个单元 ⑧输出层:10个输出单元 ———————————————— 版权声明:本文为CSDN博主「小琳猫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_44930244/article/details/128129500 """ import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # 定义网络结构 class LeNet5(nn.Module): # 定义网络结构 def __init__(self): super(LeNet5, self).__init__() # 输入图像通道:1 输出通道:6 卷积核:5×5 self.conv1 = nn.Conv2d(1, 6, 5) # 输入通道:5 输出通道:16 卷积核:5×5 self.conv2 = nn.Conv2d(6, 16, 5) # 全连接线性层1:5×5×16=400个输入变量(二维图像平铺),120个隐藏单元(输出个数) self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接线性层2:120个输入变量,84个输出变量 self.fc2 = nn.Linear(120, 84) # 全连接线性层3(输出层):84个输入变量,10个输出变量(对应10个阿拉伯数字) self.fc3 = nn.Linear(84, 10) # 定义每层向前传播时对应的[激活函数|池化层|...] def forward(self, x): # conv1 后的2×2最大池化层 x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # conv2 后的2×2最大池化层,若滤波器是一个方阵,则可以仅填一个形 x = F.max_pool2d(F.relu(self.conv2(x)), 2) # 两个卷积层后,调用自定义计算平铺后长度的函数,对图像进行平铺,注意这里直接对应上面的x,不与构造函数中的层对应 x = x.view(-1, self.num_flat_features(x)) # MLP1层后的relu函数 x = F.relu(self.fc1(x)) # MLP2层后的relu函数 x = F.relu(self.fc2(x)) # 输出即为MLP3输出层的结果(注意这里没有用softmax函数) x = self.fc3(x) return x # 自定义计算平铺后长度的函数 def num_flat_features(self, x): size = x.size()[1:] num_features = 1 for s in size: num_features *= s return num_features if __name__ == '__main__': net = LeNet5() # 打印模型结构 print(net) # 打印模型参数 params = list(net.parameters()) # 打印模型各层参数 # print(params) # 打印某层参数个数 print(params[0].size()) # 模拟输入数据,实际导入MNIST数据集需要将图片大小resize为32×32 # 1样例,1通道,32 × 32的四维张量 input_layer = torch.randn(1, 1, 32, 32, requires_grad=True) # 将输入放入模型计算输出 out = net(input_layer) print(out) # 模拟输出数据 target = torch.randn(10) target = target.view(1, -1) # 选择MSE损失函数计算损失,注意这里的写法,一个类的实例化返回了一个新的函数! loss = nn.MSELoss()(out, target) print(loss) # 跟随requires_grad的足迹在反向传播的过程中显示计算操作 # print(loss.grad_fn) # MSELoss # print(loss.grad_fn.next_functions[0][0]) # Linear # print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU # 反向传播 net.zero_grad() # 清空现存的梯度 print('conv1.bias.grad before backward:', net.conv1.bias.grad) loss.backward() print('conv1.bias.grad after backward:', net.conv1.bias.grad) # 优化器 optimizer = optim.SGD(net.parameters(), lr=0.01) optimizer.zero_grad() # 参数更新 optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
4.2LeNet5图像分类器
对4.1中的LeNet5模型进行调整,以实现对CIFAR10图像数据集的分类,与5.1相比增加了以下内容:
1)如何加载数据
- 朴素方式
先用标准/第三方库将数据加载为Numpy的Ndarray格式,再将该格式转为torch.Tensor格式
①图像:Pillow,OpenCV
②语音:scipy,librosa
③文本:Python、Cython,NLTK、SpaCy
- Pytorch数据加载器
Pytorch自身提供了数据加载的模块,对于CV领域,Pytorch提供了一个叫torchvission的包,可以通过torchvision.datasets来加载如Imagenet、CIFAR10、MNIST等公共数据集;还可以通过torch.utils.data.DataLoader装载数据集
2)如何使用GPU[并行]加速
3)如何多轮batch训练模型并利用测试集对模型进行评估
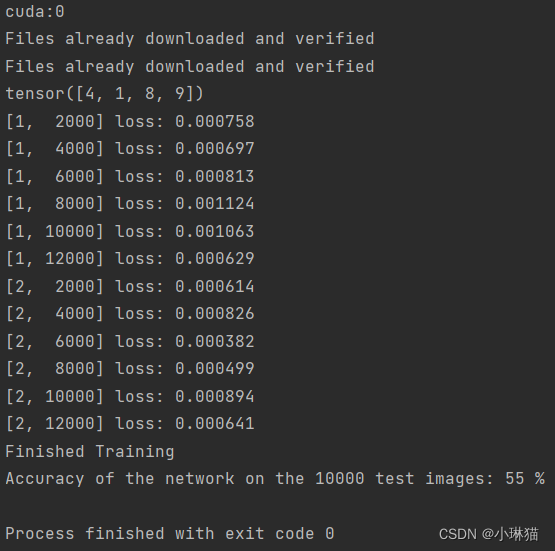
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim class LeNet5(nn.Module): """-----1.模型构建:使用LeNet5模型,注意将输入通道改为3色通道-----""" # 定义网络结构 def __init__(self): super(LeNet5, self).__init__() # 输入图像通道:3 输出通道:6 卷积核:5×5 self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道:5 输出通道:16 卷积核:5×5 self.conv2 = nn.Conv2d(6, 16, 5) # 全连接线性层1:5×5×16=400个输入变量(二维图像平铺),120个隐藏单元(输出个数) self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接线性层2:120个输入变量,84个输出变量 self.fc2 = nn.Linear(120, 84) # 全连接线性层3(输出层):84个输入变量,10个输出变量(对应10个阿拉伯数字) self.fc3 = nn.Linear(84, 10) # 定义每层向前传播时对应的[激活函数|池化层|...] def forward(self, x): # conv1 后的2×2最大池化层 x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # conv2 后的2×2最大池化层,若滤波器是一个方阵,则可以仅填一个形 x = F.max_pool2d(F.relu(self.conv2(x)), 2) # 两个卷积层后,调用自定义计算平铺后长度的函数,对图像进行平铺,注意这里直接对应上面的x,不与构造函数中的层对应 x = x.view(-1, self.num_flat_features(x)) # MLP1层后的relu函数 x = F.relu(self.fc1(x)) # MLP2层后的relu函数 x = F.relu(self.fc2(x)) # 输出即为MLP3输出层的结果(注意这里没有用softmax函数) x = self.fc3(x) return x # 自定义计算平铺后长度的函数 def num_flat_features(self, x): size = x.size()[1:] num_features = 1 for s in size: num_features *= s return num_features if __name__ == '__main__': """---------------2.GPU环境准备---------------""" device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) """---------------3.数据集准备与加载------------""" # DataNormalization:数据归一化。 # 通过torchvision加载的数据集输出范围在[0,1]区间的PILImage,归一化为[-1,1]之间的张量 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # 下载数据集到本地 train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # 加载数据集 train_loader = torch.utils.data.DataLoader(train_set, batch_size=4, shuffle=True) test_loader = torch.utils.data.DataLoader(test_set, batch_size=4, shuffle=True) # 定义标签元组 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 显示训练集图像数据 trainIter = iter(train_loader) images, label = trainIter.__next__() print(label) images = torchvision.utils.make_grid(images) images = images / 2 + 0.5 np_image = images.numpy() plt.imshow(np.transpose(np_image, (1, 2, 0))) plt.show() """------------4.实例化网络、定义损失函数和优化器------------""" net = LeNet5() # Pytorch默认只使用一个GPU,可以通过DataParallel将模型自动并行在多GPU上 if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") net = nn.DataParallel(net) # 将网络送至预先选择的环境 net.to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) """------------5.训练网络------------""" for epoch in range(2): running_loss = 0.0 for i, data in enumerate(train_loader, 0): inputs, labels = data # 每一batch都要把输入送至预选设备 inputs, labels = inputs.to(device), labels.to(device) # 优化器的梯度累积每轮置0 optimizer.zero_grad() # 前向传播,损失计算,反向传播,优化器更新参数 outputs = net(inputs) # print("Outside: input size", inputs.size(), # "output_size", outputs.size()) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 记录阶段性损失累积 running_loss += loss.item() # 每2000个batch打印一次损失累积 if i % 2000 == 1999: print('[%d, %5d] loss: %.6f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 print('Finished Training') """------------6.模型评估------------""" correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data # 每一batch都要把输入送至预选设备 images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
输入图像示例:

4.3导入、处理图像数据
①导入数据集:简单导入方式;继承torch.utils.data.Dataset构建数据集类
②对图像数据进行数据增强:通过skimage.transform自定义图像处理类;使用torchvision.transforms提供的图像处理类;最后通过torchvision.transforms.Compose(dataset,[transfrom...])对数据集进行相应的处理
③通过torch.utils.data.DataLoader对数据集进行装载(分片、打乱顺序、并行处理)
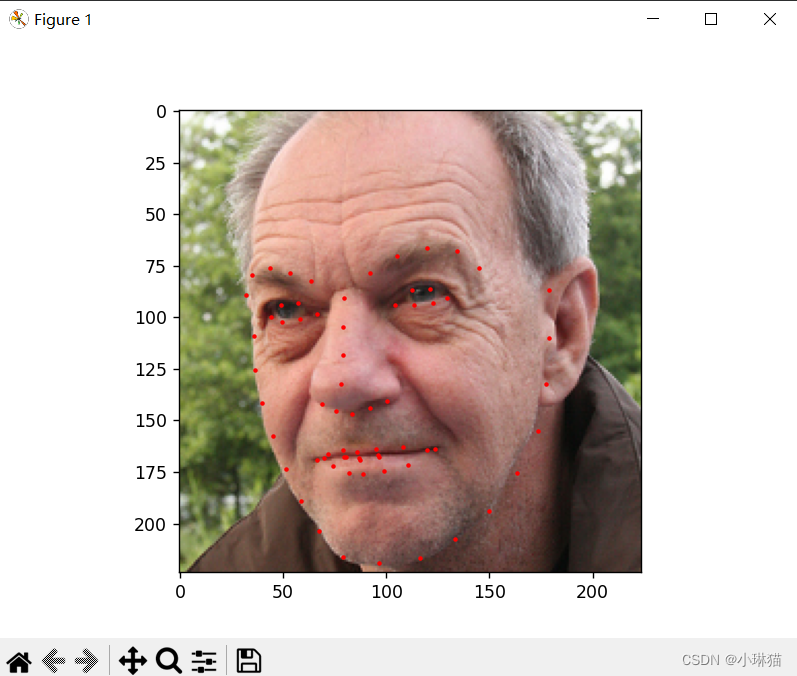
1)示例1:自定义数据集类;自定义图像数据处理类;通过DataLoader加载
""" dataset: download:https://download.pytorch.org/tutorial/faces.zip position:./data/faces/ origin:面部姿态的数据集,实际为imagenet数据集标注为face的图片当中在 dlib 面部检测 (dlib’s pose estimation) 表现良好的图片 description:csv文件中包含了图片与多个标注点(x,y)的映射 """ import os import torch import numpy as np # 用于张量等科学计算 import pandas as pd # 用于更容易地进行csv解析 import torchvision.transforms as transforms # 用于对图像进行数据增强 from matplotlib import pyplot as plt # 数据可视化、图像显示工具 from skimage import io, transform # 用于图像的IO和变换 from torch.utils.data import Dataset # 表示数据集的抽象类 from torch.utils.data import DataLoader # 数据加载器 class FaceLandmarkDataset(Dataset): """ info:面部标记数据集 description:为了节省内存空间,为面部数据集创建一个数据集类,只有在需要用到图片的时候才读取它而不是一开始就把图片全部存进内存里 """ def __init__(self, csv_file, root_dir, transform=None): """ csv_file(string):带注释的csv文件的路径。 root_dir(string):包含所有图像的目录。 transform(callable, optional):一个样本上的可用的可选变换 """ # 导入数据 self.landmarks_frame = pd.read_csv(csv_file) self.root_dir = root_dir self.transform = transform def __len__(self): """返还数据集的尺寸""" return len(self.landmarks_frame) def __getitem__(self, idx): """获取一些索引数据""" img_name = os.path.join(self.root_dir, self.landmarks_frame.iloc[idx, 0]) image = io.imread(img_name) landmarks = self.landmarks_frame.iloc[idx, 1:] landmarks = np.array([landmarks]) landmarks = landmarks.astype('float').reshape(-1, 2) sample = {'image': image, 'landmarks': landmarks} if self.transform: sample = self.transform(sample) return sample def show_landmarks(self, idx): """显示标注的图片""" sample = self.__getitem__(idx) image = sample['image'] image = image.numpy().transpose((1, 2, 0)) landmarks = sample['landmarks'] plt.imshow(image) plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='red') # 暂停一点,以便更新绘图 plt.pause(0.001) plt.show() class Rescale(object): """ description:将样本中的图像重新缩放到给定大小 output_size(tuple或int):所需的输出大小。 如果是元组,则输出为与output_size匹配。 如果是int,则匹配较小的图像边缘到output_size保持纵横比相同。 """ def __init__(self, output_size): assert isinstance(output_size, (int, tuple)) self.output_size = output_size def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] h, w = image.shape[:2] if isinstance(self.output_size, int): if h > w: new_h, new_w = self.output_size * h / w, self.output_size else: new_h, new_w = self.output_size, self.output_size * w / h else: new_h, new_w = self.output_size new_h, new_w = int(new_h), int(new_w) img = transform.resize(image, (new_h, new_w)) # h and w are swapped for landmarks because for images, # x and y axes are axis 1 and 0 respectively landmarks = landmarks * [new_w / w, new_h / h] return {'image': img, 'landmarks': landmarks} class RandomCrop(object): """ description:随机裁剪样本中的图像 output_size(tuple或int):所需的输出大小。 如果是int,方形裁剪是。 """ def __init__(self, output_size): assert isinstance(output_size, (int, tuple)) if isinstance(output_size, int): self.output_size = (output_size, output_size) else: assert len(output_size) == 2 self.output_size = output_size def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] h, w = image.shape[:2] new_h, new_w = self.output_size top = np.random.randint(0, h - new_h) left = np.random.randint(0, w - new_w) image = image[top: top + new_h, left: left + new_w] landmarks = landmarks - [left, top] return {'image': image, 'landmarks': landmarks} class ToTensor(object): """ description:将样本中的ndarrays转换为Tensors 交换颜色轴因为: numpy包的图片是: H * W * C torch包的图片是: C * H * W """ def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] image = image.transpose((2, 0, 1)) return {'image': torch.from_numpy(image), 'landmarks': torch.from_numpy(landmarks)} if __name__ == '__main__': # 通过自定义的数据集类,导入数据集 faceLandmarkDataset = FaceLandmarkDataset(csv_file='data/faces/face_landmarks.csv', root_dir='data/faces', transform=transforms.Compose([Rescale(256), RandomCrop(224), ToTensor()])) sample = faceLandmarkDataset.__getitem__(1) faceLandmarkDataset.show_landmarks(1) # 相比于手动通过循环导入数据而言,通过DataLoader导入数据具有很多优势,批量处理数据、打乱数据、并行加载数据 dataloader = DataLoader(faceLandmarkDataset, batch_size=4, shuffle=True, num_workers=4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
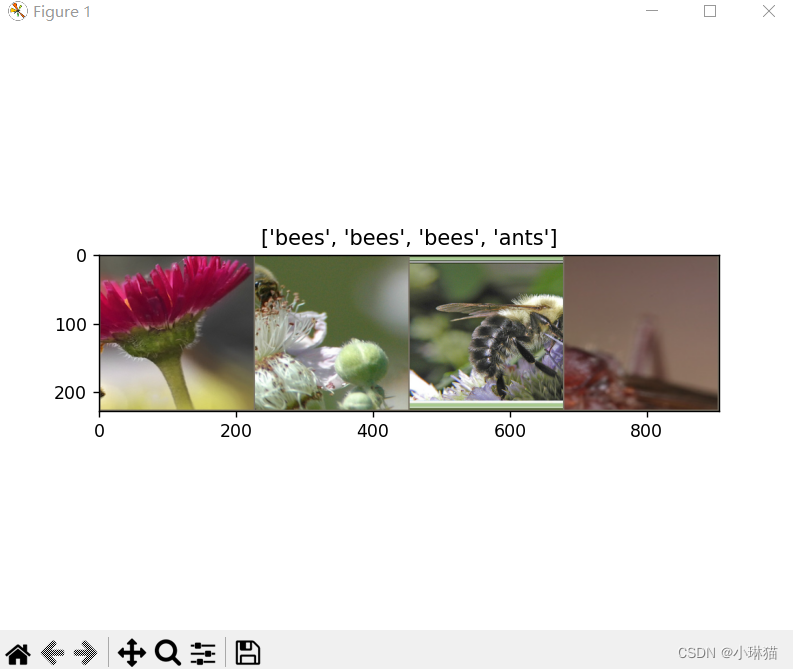
2)示例2:用ImageFolder加载分类图像数据集;用transforms自带的图像增强变换;用DataLoader装载数据集
torchvision.datasets.ImageFolder类可用于对分类图像的数据集进行方便的加载,如:/data/cat/...;/data/dog/...
import torch
from torchvision import transforms, datasets
# 定义图像增强变换
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
# 通过ImageFolder导入分类图像的数据集
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train', transform=data_transform)
# 通过DataLoader加载数据
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset, batch_size=4, shuffle=True,num_workers=4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.4自定义求导函数
上面的LeNet5示例中,通过torch.nn.functional中内置的激活函数/池化函数作为线性层的非线性变换,实际中我们可以自定义求导函数:编写继承于torch.autograd.Function的求导类,编写静态方法forard和backward来定义该函数向前/向后传播的具体行为
"""通过自定义的激活函数构建MLP""" import torch class MyReLU(torch.autograd.Function): """ 我们可以通过建立torch.autograd的子类来实现我们自定义的autograd函数, 并完成张量的正向和反向传播。 """ @staticmethod def forward(ctx, x): """ 正向传播: 输入:一个上下文对象和一个包含输入的张量(可以使用上下文对象来缓存对象,以便在反向传播中使用) 输出:包含输出的张量 """ ctx.save_for_backward(x) return x.clamp(min=0) @staticmethod def backward(ctx, grad_output): """ 反向传播: 输入:上下文对象、张量 其包含了相对于正向传播过程中产生的输出的损失的梯度。 我们可以从上下文对象中检索缓存的数据, 并且必须计算并返回与正向传播的输入相关的损失的梯度。 """ x, = ctx.saved_tensors grad_x = grad_output.clone() grad_x[x < 0] = 0 return grad_x if __name__ == '__main__': device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # N是批大小; D_in 是输入维度; # H 是隐藏层维度; D_out 是输出维度 N, D_in, H, D_out = 64, 1000, 100, 10 # 产生输入和输出的随机张量 x = torch.randn(N, D_in, device=device) y = torch.randn(N, D_out, device=device) # 产生随机权重的张量 w1 = torch.randn(D_in, H, device=device, requires_grad=True) w2 = torch.randn(H, D_out, device=device, requires_grad=True) learning_rate = 1e-6 for t in range(500): # 正向传播:使用张量上的操作来计算输出值y; # 我们通过调用 MyReLU.apply 函数来使用自定义的ReLU y_pred = MyReLU.apply(x.mm(w1)).mm(w2) # 计算并输出loss loss = (y_pred - y).pow(2).sum() print(t, loss.item()) # 使用autograd计算反向传播过程 loss.backward() with torch.no_grad(): # 用梯度下降更新权重 w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad # 在反向传播之后手动清零梯度 w1.grad.zero_() w2.grad.zero_()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
4.5动态图示例
1)静态图与动态图
静态图的优点在于框架可以提前对计算图进行优化,融合一些图的运算来提升效率,或产生一个策略将图分布到多个GPU或机器上。
静态图和动态图的一个区别是控制流,对于一些模型我们希望对每个数据点执行不同的计算,动态图为此实现则更加容易。
2)控制流与权重共享
本节给出一个动态图的简单示例,Pytorch动态图相比于Tensorflow等静态图而言实现更为简单
import random import torch class DynamicNet(torch.nn.Module): def __init__(self, D_in, H, D_out): """ 在构造函数中,我们构造了三个nn.Linear实例,它们将在前向传播时被使用。 """ super(DynamicNet, self).__init__() self.input_linear = torch.nn.Linear(D_in, H) self.middle_linear = torch.nn.Linear(H, H) self.output_linear = torch.nn.Linear(H, D_out) def forward(self, x): """ 随机选择0-3次,重用多次计算隐藏层的middle_linear模块 由于每个前向传播构建一个动态计算图,我们可以在定义模型的前向传播时使用常规Python控制流运算符,如循环或条件语句。 在定义计算图形时多次重用同一个模块是完全安全的,这是Lua Torch的一大改进,因为Lua Torch中每个模块只能使用一次。 """ h_relu = self.input_linear(x).clamp(min=0) for _ in range(random.randint(0, 3)): h_relu = self.middle_linear(h_relu).clamp(min=0) y_pred = self.output_linear(h_relu) return y_pred if __name__ == '__main__': # N是批大小;D是输入维度 # H是隐藏层维度;D_out是输出维度 N, D_in, H, D_out = 64, 1000, 100, 10 # 产生输入和输出随机张量 x = torch.randn(N, D_in) y = torch.randn(N, D_out) # 实例化上面定义的类来构造我们的模型 model = DynamicNet(D_in, H, D_out) # 构造我们的损失函数(loss function)和优化器(Optimizer)。 # 用平凡的随机梯度下降训练这个奇怪的模型是困难的,所以我们使用了momentum方法。 criterion = torch.nn.MSELoss(reduction='sum') optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9) for t in range(500): # 前向传播:通过向模型传入x计算预测的y。 y_pred = model(x) # 计算并打印损失 loss = criterion(y_pred, y) print(t, loss.item()) # 清零梯度,反向传播,更新权重 optimizer.zero_grad() loss.backward() optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
4.6.迁移学习
1)背景
工程实践中没有人会从零训练一个完整的卷积神经网络,因为很难得到一个专用的足够大的数据集,通常的做法是在一个很大的数据集(上进行预训练得到一个卷积神经网络,再将该网络的的参数作为目标任务的初始化参数(将原任务迁移至目标任务)
2)场景
①微调:使用预训练的网络(参数)来初始化自己的网络,其他训练步骤不变
②将预训练的网络看作固定的特征提取器,在预训练网络后增加一个全连接层(该层的参数随机初始化),使用自己的数据集训练,训练时只有该新增的全连接层被训练
3)示例
①微调
""" Description:迁移学习之微调ResNet18 Task:是训练一个模型来分类蚂蚁ants和蜜蜂bees Dataset:https://download.pytorch.org/tutorial/hymenoptera_data.zip """ import copy import os import time import numpy as np import torch import torchvision from matplotlib import pyplot as plt from torch import nn, optim from torch.optim import lr_scheduler from torchvision import datasets, models from torchvision.models import ResNet18_Weights from torchvision.transforms import transforms def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.show() def train_model(model, criterion, optimizer, scheduler, num_epochs=25): """ 通用基本模型训练函数 :param model: 预训练模型 :param criterion: 损失函数 :param optimizer: 优化器 :param scheduler: torch.optim.lr_scheduler 学习速率调整类的对象 :param num_epochs:训练轮数 :return:微调后的模型 """ since = time.time() # 加载(原)模型的静态权重 best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 # 最佳精度 for epoch in range(num_epochs): print('----------Epoch {}/{}------------'.format(epoch, num_epochs - 1)) # 每个epoch都有一个训练和验证阶段(注意这里如何切换训练和测试 for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 # 当前batch的损失 running_corrects = 0 # 当前batch的正确率 # 迭代数据(注意如何区别训练集和测试集数据) for x, y in dataloaders[phase]: x = x.to(device) # 输入送入设备 y = y.to(device) # 输出送入设备 optimizer.zero_grad() # 优化器梯度清零 # 前向传播:只在训练中记录历史数据(注意如何区别训练和测试阶段) with torch.set_grad_enabled(phase == 'train'): outputs = model(x) _, predicts = torch.max(outputs, 1) loss = criterion(outputs, y) # 通过损失函数计算损失 # 后向传播仅在训练阶段进行优化(参数更新) if phase == 'train': loss.backward() optimizer.step() # 计算当前batch的损失和精度 running_loss += loss.item() * x.size(0) running_corrects += torch.sum(predicts == y.data) if phase == 'train': scheduler.step() # 计算当前轮的损失和精度 epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) # 验证集记录最佳精度的权重 if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # 加载最佳模型权重 model.load_state_dict(best_model_wts) return model def visualize_model(model, num_images=6): """ :description:一个通用的展示少量预测图片的函数 :param model: :param num_images: :return: """ was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() with torch.no_grad(): for i, (x, y) in enumerate(dataloaders['val']): x = x.to(device) y = y.to(device) outputs = model(x) _, predicts = torch.max(outputs, 1) for j in range(x.size()[0]): images_so_far += 1 ax = plt.subplot(num_images // 2, 2, images_so_far) ax.axis('off') ax.set_title('predicted: {}'.format(class_names[predicts[j]])) imshow(x.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training) if __name__ == '__main__': """0.设备选择""" device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) """1.加载数据""" # 1.1数据集增强:训练集数据扩充和归一化,在验证集上仅需要归一化 data_transforms = { 'train': transforms.Compose([ # 随机裁剪一个area然后再resize transforms.RandomResizedCrop(224), # 随机水平翻转 transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } # 1.2数据导入与装载 data_dir = 'data/hymenoptera_data' image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']} dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'val']} dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']} class_names = image_datasets['train'].classes # 1.3可视化部分图像 # 获取一批训练数据 inputs, classes = next(iter(dataloaders['train'])) # 批量制作网格 out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes]) """2.DL组件定义""" # 2.1ft:fine_tuning 微调 model_ft = models.resnet18(weights=ResNet18_Weights.DEFAULT) # resnet18全连接层的输入维数 num_features = model_ft.fc.in_features # 将resnet18的全连接层调整为输出维数为2(这里对应的是二分类问题) model_ft.fc = nn.Linear(num_features, 2) # 将模型装入设备 model_ft = model_ft.to(device) # 2.2选择交叉熵损失函数 criterion = nn.CrossEntropyLoss() # 2.3选择SGD优化算法 optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # 2.4动态调整学习率:每7个epochs衰减LR通过设置gamma=0.1 exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) """3.训练和评估模型:训练模型 该过程在CPU上需要大约15-25分钟,但是在GPU上,它只需不到一分钟""" # 训练和评估模型 model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25) # 模型评估效果可视化 visualize_model(model_ft)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
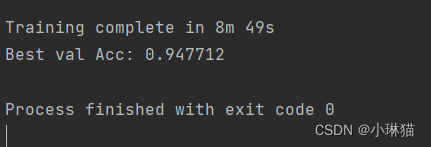
训练结果:

②固定特征提取器
""" Description:迁移学习之固定特征提取器ResNet18 Task:是训练一个模型来分类蚂蚁ants和蜜蜂bees Dataset:https://download.pytorch.org/tutorial/hymenoptera_data.zip """ import copy import os import time import numpy as np import torch import torchvision from matplotlib import pyplot as plt from torch import nn, optim from torch.optim import lr_scheduler from torchvision import datasets, models from torchvision.models import ResNet18_Weights from torchvision.transforms import transforms def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.show() def train_model(model, criterion, optimizer, scheduler, num_epochs=25): """ 通用基本模型训练函数 :param model: 预训练模型 :param criterion: 损失函数 :param optimizer: 优化器 :param scheduler: torch.optim.lr_scheduler 学习速率调整类的对象 :param num_epochs:训练轮数 :return:微调后的模型 """ since = time.time() # 加载(原)模型的静态权重 best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 # 最佳精度 for epoch in range(num_epochs): print('----------Epoch {}/{}------------'.format(epoch, num_epochs - 1)) # 每个epoch都有一个训练和验证阶段(注意这里如何切换训练和测试 for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 # 当前batch的损失 running_corrects = 0 # 当前batch的正确率 # 迭代数据(注意如何区别训练集和测试集数据) for x, y in dataloaders[phase]: x = x.to(device) # 输入送入设备 y = y.to(device) # 输出送入设备 optimizer.zero_grad() # 优化器梯度清零 # 前向传播:只在训练中记录历史数据(注意如何区别训练和测试阶段) with torch.set_grad_enabled(phase == 'train'): outputs = model(x) _, predicts = torch.max(outputs, 1) loss = criterion(outputs, y) # 通过损失函数计算损失 # 后向传播仅在训练阶段进行优化(参数更新) if phase == 'train': loss.backward() optimizer.step() # 计算当前batch的损失和精度 running_loss += loss.item() * x.size(0) running_corrects += torch.sum(predicts == y.data) if phase == 'train': scheduler.step() # 计算当前轮的损失和精度 epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) # 验证集记录最佳精度的权重 if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # 加载最佳模型权重 model.load_state_dict(best_model_wts) return model def visualize_model(model, num_images=6): """ :description:一个通用的展示少量预测图片的函数 :param model: :param num_images: :return: """ was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() with torch.no_grad(): for i, (x, y) in enumerate(dataloaders['val']): x = x.to(device) y = y.to(device) outputs = model(x) _, predicts = torch.max(outputs, 1) for j in range(x.size()[0]): images_so_far += 1 ax = plt.subplot(num_images // 2, 2, images_so_far) ax.axis('off') ax.set_title('predicted: {}'.format(class_names[predicts[j]])) imshow(x.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training) if __name__ == '__main__': """0.设备选择""" device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) """1.加载数据""" # 1.1数据集增强:训练集数据扩充和归一化,在验证集上仅需要归一化 data_transforms = { 'train': transforms.Compose([ # 随机裁剪一个area然后再resize transforms.RandomResizedCrop(224), # 随机水平翻转 transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } # 1.2数据导入与装载 data_dir = 'data/hymenoptera_data' image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']} dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'val']} dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']} class_names = image_datasets['train'].classes # 1.3可视化部分图像 # 获取一批训练数据 inputs, classes = next(iter(dataloaders['train'])) # 批量制作网格 out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes]) """2.DL组件定义""" # 2.1ft:fine_tuning 微调 model_ffe = models.resnet18(weights=ResNet18_Weights.DEFAULT) # 设置模型的参数不进行优化调整 for param in model_ffe.parameters(): param.requires_grad = False # resnet18全连接层的输入维数 num_features = model_ffe.fc.in_features # 将resnet18的全连接层调整为输出维数为2(这里对应的是二分类问题) model_ffe.fc = nn.Linear(num_features, 2) # 将模型装入设备 model_ffe = model_ffe.to(device) # 2.2选择交叉熵损失函数 criterion = nn.CrossEntropyLoss() # 2.3选择SGD优化算法 optimizer_ft = optim.SGD(model_ffe.parameters(), lr=0.001, momentum=0.9) # 2.4动态调整学习率:每7个epochs衰减LR通过设置gamma=0.1 exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) """3.训练和评估模型:训练模型 该过程在CPU上需要大约15-25分钟,但是在GPU上,它只需不到一分钟""" # 训练和评估模型 model_ffe = train_model(model_ffe, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25) # 模型评估效果可视化 visualize_model(model_ffe) plt.ioff() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
4.7模型保存和加载
1)模型的状态字典state_dict
Pytorch将torch.nn.Module模型的可学习参数(权重和偏置)包含在模型的参数中:
# 访问模型参数
model.parameters()
- 1
- 2
state_dict是Python的字典对象,它将每一层映射到其参数张量;优化器torch.optim也有static_dict属性,它保存了优化器的状态信息以及超参数
# 注册访问模型和优化器的状态字典
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
- 1
- 2
- 3
- 4
- 5
2)保存和加载模型的state_dict
# 保存模型的状态字典:当保存好模型用来推断的时候,只需要保存模型学习到的参数,使用torch.save()函数来保存模型state_dic ,它会给模型恢复提供最大的灵活性
torch.save(model.state_dict(), PATH)
# 加载模型的状态字典
model = ModelClass(*args, **kwargs)
# model.load_state_dict函数只接受字典对象,而不是保存对象的路径,即需要先通过torch.load来加载和反序列化state_dict
model.load_state_dict(torch.load(PATH))
# 非严格加载参数:在状态字典和模型所需参数不匹配时(多或少)使用非严格加载,忽略不匹配参数项
model.load_state_dict(torch.load(PATH),strict=False)
# 运行推理之前,务必调用model.eval()去设置dropout和batch normalization层为评估模式。否则,可能导致模型推断结果不一致
model.eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3)保存和加载完整的模型
以Python的pickle模块保存模型,在PyTorch 中最常见的模型保存使.pt或者是.pth作为模型文件扩展名
优点:代码直观且简洁
缺点:序列化数据受限于某种特殊的类而且需要确切的字典结构(pickle无法保存模型类本身)
# 保存
torch.save(model, PATH)
# 加载
model = torch.load(PATH)
model.eval()
- 1
- 2
- 3
- 4
- 5
4)保存和加载Checkpoint检查点
Checkpoint检查点保存,相比于保存模型或其参数而言,从动机上讲,可看作不仅能保存用于推理的训练好的模型,还能保存未训练好还要继续训练的模型快照;从保存内容上讲,Checkpoint除了模型或其参数而言,还能保存优化器|训练轮数|损失函数等,从本质上讲它与保存state_dict并无区别,都是数据组织成字典形式进行序列化
Checkpoint常见的保存扩展名是.tar
# 保存 torch.save({ 'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss':loss, ... },PATH) # 加载 model = ModelClass(*args,**kwargs) optimizer = OptimizerClass(*args,**kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss'] # 推理:调用model.eval()去设置 dropout 和 batch normalization 为评估模式,否则可能得到不一致的推断结果 model.eval() # 恢复训练:调用model.train()以确保模型层处于训练模式 model.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5)在一个文件中保存多个模型
当保存一个模型由多个torch.nn.Modules组成时,例如GAN(对抗生成网络)、sequence-to-sequence (序列到序列模型), 或者是多个模型融合, 可以采用与保存常规检查点相同的方法。
modelA = TheModelAClass(*args, **kwargs) modelB = TheModelBClass(*args, **kwargs) optimizerA = TheOptimizerAClass(*args, **kwargs) optimizerB = TheOptimizerBClass(*args, **kwargs) checkpoint = torch.load(PATH) modelA.load_state_dict(checkpoint['modelA_state_dict']) modelB.load_state_dict(checkpoint['modelB_state_dict']) optimizerA.load_state_dict(checkpoint['optimizerA_state_dict']) optimizerB.load_state_dict(checkpoint['optimizerB_state_dict']) modelA.eval() modelB.eval() # or modelA.train() modelB.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6)通过设备保存加载模型
# 1.在模型训练时未将张量和模型放入GPU时,默认的保存和导入方式都是保存在了CPU上
# 2.保存和加载在GPU上
## 2.1模型训练时,将模型和全部张量都放入GPU中
## 2.2导入
device = torch.device("cuda")
model = ModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
# 3.保存到 CPU,加载到 GPU(模型训练不指定GPU,加载时指定GPU)
# 4.保存 torch.nn.DataParallel 模型:torch.nn.DataParallel 是一个模型封装,支持并行GPU使用。要普通保存 DataParallel 模型,请保存 model.module.state_dict() 。 这样,你就可以非常灵活地以任何方式加载模型到你想要的设备中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.8模型部署
1)为何需要部署模型
在深度学习项目的研发阶段使用如PyTorch这种eager及时的、命令式的编程方式能够使用户方便地使用熟悉的Python数据结构、控制流操作、打印等来调试模型;但是在生产环境中部署模型时,使用基于图形graph-based的模型更好,一个延迟的图型展示意味着:①可以进行优化 ②针对高度优化的硬件架构的能力 ③支持框架无关的模型导出
2)如何部署模型
TorchScript官方文档
TorchScript使用教程 - 知乎
torch.jit.trace与torch.jit.script的区别 - 腾讯云开发者社区
通过TorchScript是一个Python中静态可分析的、可优化的子集,它可以从PyTorch代码创建可序列化和可优化模型,任何TorchScript程序都可以从Python进程中保存,并加载到没有Python依赖的进程中。
PyTorch提供了将eager即时模式的PyTorch程序增量地转换为TorchScript的API,这些API在torch.jit模块中。
①跟踪模式torch.jit.trace
跟踪函数接收一个nn.Module或一个nn.Function和一组示例的输入,然后通过模块或函数运行输入示例同时跟踪遇到的计算步骤然后输出一个graph-based的函数,跟踪适合于不涉及动态控制流的函数和模块,如常用的CNN,是首选
②脚本模式torch.jit.script
脚本模式适用于涉及动态控制流的函数和模块,它并不记录控制流本身而是为控制流部分提供脚本化
③混合跟踪和脚本模式
3)C++中加载TorchScript模型
4.9模型导出为ONNX格式并在Caffe2中加载使用
torch.onnx - PyTorch master documentation
1)安装onnx
pip install onnx
- 1
2)导出模型
# 输入模型
x = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
# 导出模型
# x:模型输入,它的值不重要,只要合法即可
# export_params: 在模型中存储训练后的参数
torch_out = torch.onnx._export(torch_model, x , "{path}/{name}.onnx", export_params=True)
- 1
- 2
- 3
- 4
- 5
- 6
3)在Caffe2中加载ONNX模型
caffe2从头学-CSDN博客 Caffe2入门教程 - 知乎
4)在移动端上运行模型
4.10在Web框架中部署模型
5.视觉示例
5.1基于Mask-RCNN的行人实例分割
5.2空间变换器
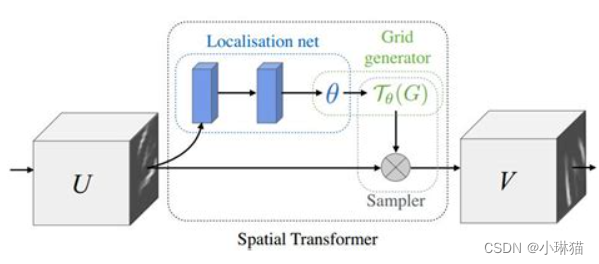
使用空间变换器网络(STN)的视觉注意机制来扩充网络,空间变换器网络关注空间变换的差异,允许神经网络学习如何在输入图像上执行空间变换, 以增强模型的几何不变性。例如,它可以裁剪感兴趣的 区域,缩放并校正图像的方向。
空间变换器网络包含以下三个主要组成部分:
- 本地网络(Localisation Network)常规CNN,其对变换参数进行回归。不会从该数据集中明确地学习转换,而是网络自动学习增强全局准确性的空间变换
- 网格生成器( Grid Genator)在输入图像中生成与输出图像中的每个像素相对应的坐标网格
- 采样器(Sampler)使用变换的参数并将其应用于输入图像
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torchvision from torchvision import datasets, transforms import matplotlib.pyplot as plt import numpy as np plt.ion() # 交互模式 """0.选择设备""" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") """1.加载数据集""" # 训练数据集 train_loader = torch.utils.data.DataLoader( datasets.MNIST(root='.', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=64, shuffle=True, num_workers=4) # 测试数据集 test_loader = torch.utils.data.DataLoader( datasets.MNIST(root='.', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=64, shuffle=True, num_workers=4) class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) # 空间变换器定位 - 网络 self.localization = nn.Sequential( nn.Conv2d(1, 8, kernel_size=7), nn.MaxPool2d(2, stride=2), nn.ReLU(True), nn.Conv2d(8, 10, kernel_size=5), nn.MaxPool2d(2, stride=2), nn.ReLU(True) ) # 3 * 2 affine矩阵的回归量 self.fc_loc = nn.Sequential( nn.Linear(10 * 3 * 3, 32), nn.ReLU(True), nn.Linear(32, 3 * 2) ) # 使用身份转换初始化权重/偏差 self.fc_loc[2].weight.data.zero_() self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float)) def stn(self, x): """空间变换器网络转发功能""" xs = self.localization(x) xs = xs.view(-1, 10 * 3 * 3) theta = self.fc_loc(xs) theta = theta.view(-1, 2, 3) grid = F.affine_grid(theta, x.size(), align_corners=True) x = F.grid_sample(x, grid, align_corners=True) return x def forward(self, x): # transform the input x = self.stn(x) # 执行一般的前进传递 x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x, dim=1) def train(epoch): """训练模型""" model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % 500 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) def test(): """测试模型""" with torch.no_grad(): model.eval() test_loss = 0 correct = 0 for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) # 累加批量损失 test_loss += F.nll_loss(output, target, reduction='sum').item() # 获取最大对数概率的索引 pred = output.max(1, keepdim=True)[1] correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n' .format(test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) def convert_image_np(inp): """Convert a Tensor to numpy image.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) return inp def visualize_stn(): """在训练之后可视化空间变换器层的输出,使用STN可视化一批输入图像和相应的变换批次。""" with torch.no_grad(): # Get a batch of training data data = next(iter(test_loader))[0].to(device) input_tensor = data.cpu() transformed_input_tensor = model.stn(data).cpu() in_grid = convert_image_np( torchvision.utils.make_grid(input_tensor)) out_grid = convert_image_np( torchvision.utils.make_grid(transformed_input_tensor)) # Plot the results side-by-side f, axarr = plt.subplots(1, 2) axarr[0].imshow(in_grid) axarr[0].set_title('Dataset Images') axarr[1].imshow(out_grid) axarr[1].set_title('Transformed Images') if __name__ == '__main__': model = Net().to(device) optimizer = optim.SGD(model.parameters(), lr=0.01) for epoch in range(1, 20 + 1): train(epoch) test() # 在某些输入批处理上可视化STN转换 visualize_stn() plt.ioff() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151

5.3Neural-Transfer
图像风格迁移Neural-Transfer也称Neural-Style,该算法使用三张图片,一张输入图片,一张内容图片和一张风格图片,并将输入的图片变得与内容图片相似,且拥有风格图片的风格。
该算法的原理为:定义两个间距,一个内容间距D_C,用于衡量两张图像内容上的不同;一个风格间距D_S,用于衡量两张图像风格上的不同,然后最小化欲改变图像和内容图像、风格图像的内容间距和风格间距
"""图像风格迁移""" from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from PIL import Image import matplotlib.pyplot as plt import torchvision.transforms as transforms import torchvision.models as models import copy from torchvision.models import VGG19_Weights class ContentLoss(nn.Module): """内容损失函数""" def __init__(self, target, ): super(ContentLoss, self).__init__() # 我们从用于动态计算梯度的树中“分离”目标内容: # 这是一个声明的值,而不是变量。 # 否则标准的正向方法将引发错误。 self.target = target.detach() def forward(self, input): self.loss = F.mse_loss(input, self.target) return input def gram_matrix(input): a, b, c, d = input.size() # a=batch size(=1) # 特征映射 b=number # (c,d)=dimensions of a f. map (N=c*d) features = input.view(a * b, c * d) # resise F_XL into \hat F_XL G = torch.mm(features, features.t()) # compute the gram product # 我们通过除以每个特征映射中的元素数来“标准化”gram矩阵的值. return G.div(a * b * c * d) class StyleLoss(nn.Module): """风格损失函数""" def __init__(self, target_feature): super(StyleLoss, self).__init__() self.target = gram_matrix(target_feature).detach() def forward(self, input): G = gram_matrix(input) self.loss = F.mse_loss(G, self.target) return input def image_loader(image_name): """ 原始的PIL图片的值介于0到255之间,但被转换成torch张量时,像素值被转换成0到1之间 Caffe库中的预训练网络用来训练的张量值为0到255之间的图片 """ image = Image.open(image_name) # fake batch dimension required to fit network's input dimensions image = loader(image).unsqueeze(0) return image.to(device, torch.float) def imshow(tensors, titles=None): plt.figure() for i in range(len(tensors)): image = tensors[i].cpu().clone() # we clone the tensor to not do changes on it image = image.squeeze(0) # remove the fake batch dimension image = unloader(image) plt.subplot(1, len(tensors), i + 1) plt.imshow(image) if titles[i] is not None: plt.title(titles[i]) plt.show() class Normalization(nn.Module): """创建一个模块来规范化输入图像,以便将图像放入nn.Sequential中""" def __init__(self, mean, std): """ view the mean and std to make them [C x 1 x 1] so that they can directly work with image Tensor of shape [B x C x H x W]. B is batch size. C is number of channels. H is height and W is width. """ super(Normalization, self).__init__() self.mean = mean.clone().detach().view(-1, 1, 1) self.std = std.clone().detach().view(-1, 1, 1) def forward(self, img): # normalize img return (img - self.mean) / self.std def get_input_optimizer(input_img): # 此行显示输入是需要渐变的参数 optimizer = optim.LBFGS([input_img.requires_grad_()]) return optimizer def run_style_transfer(cnn, normalization_mean, normalization_std, content_img, style_img, input_img, num_steps=300, style_weight=1000000, content_weight=1): """Run the style transfer.""" print('Building the style transfer model..') model, style_losses, content_losses = get_style_model_and_losses(cnn, normalization_mean, normalization_std, style_img, content_img) optimizer = get_input_optimizer(input_img) print('Optimizing..') run = [0] while run[0] <= num_steps: def closure(): # 更正更新的输入图像的值 input_img.data.clamp_(0, 1) optimizer.zero_grad() model(input_img) style_score = 0 content_score = 0 for sl in style_losses: style_score += sl.loss for cl in content_losses: content_score += cl.loss style_score *= style_weight content_score *= content_weight loss = style_score + content_score loss.backward() run[0] += 1 if run[0] % 50 == 0: print("run {}:".format(run)) print('Style Loss : {:4f} Content Loss: {:4f}'.format( style_score.item(), content_score.item())) print() return style_score + content_score optimizer.step(closure) # 最后的修正...... input_img.data.clamp_(0, 1) return input_img def get_style_model_and_losses(cnn, normalization_mean, normalization_std, style_img, content_img, content_layers=['conv_4'], style_layers=['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']): """ :param cnn: :param normalization_mean: :param normalization_std: :param style_img: :param content_img: :param content_layers: 用于优化内容损失的模型层 :param style_layers: 用于优化风格损失的模型层 :return: """ cnn = copy.deepcopy(cnn) # 规范化模块 normalization = Normalization(normalization_mean, normalization_std).to(device) content_losses = [] style_losses = [] model = nn.Sequential(normalization) i = 0 for layer in cnn.children(): if isinstance(layer, nn.Conv2d): i += 1 name = 'conv_{}'.format(i) elif isinstance(layer, nn.ReLU): name = 'relu_{}'.format(i) layer = nn.ReLU(inplace=False) elif isinstance(layer, nn.MaxPool2d): name = 'pool_{}'.format(i) elif isinstance(layer, nn.BatchNorm2d): name = 'bn_{}'.format(i) else: raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__)) model.add_module(name, layer) if name in content_layers: # 加入内容损失: target = model(content_img).detach() content_loss = ContentLoss(target) model.add_module("content_loss_{}".format(i), content_loss) content_losses.append(content_loss) if name in style_layers: # 加入风格损失: target_feature = model(style_img).detach() style_loss = StyleLoss(target_feature) model.add_module("style_loss_{}".format(i), style_loss) style_losses.append(style_loss) # 现在我们在最后的内容和风格损失之后剪掉了图层 for i in range(len(model) - 1, -1, -1): if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss): break model = model[:(i + 1)] return model, style_losses, content_losses if __name__ == '__main__': """0.设备选择""" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") """1.导入内容和风格图像""" # 所需的输出图像大小 imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu loader = transforms.Compose([ transforms.Resize(imsize), # scale imported image transforms.ToTensor()]) # transform it into a torch tensor style_img = image_loader("image3.jpg") content_img = image_loader("image2.jpg") assert style_img.size() == content_img.size(), "we need to import style and content images of the same size" # 重新将图片转换成PIL格式来展示,并使用plt.imshow展示它的拷贝 unloader = transforms.ToPILImage() # reconvert into PIL image # plt.figure() # imshow(style_img, title='Style Image') # imshow(content_img, title='Content Image') """2.导入模型""" cnn = models.vgg19(weights=VGG19_Weights.IMAGENET1K_V1).features.to(device).eval() cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device) cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device) # 期望的深度层来计算样式/内容损失: # content_layers_default = ['conv_4'] # style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5'] """3.输入图像""" # 输入图像与内容图像相同2 input_img = content_img.clone() # 为输入图像增加随机白噪声 # input_img = torch.randn(content_img.data.size(), device=device) """4.风格迁移""" output = run_style_transfer(cnn, cnn_normalization_mean, cnn_normalization_std, content_img, style_img, input_img) # 结果可视化 imshow([style_img, content_img, output], ['Style Image', 'Content Image', 'Output Image'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242


5.4超高分辨率
超分辨率是一种提高图像、视频分辨率的方法,广泛用于图像处理或视频剪辑
"""超过分辨率模型""" import numpy as np import torch import torch.nn as nn import torch.nn.init as init from torch.utils import model_zoo import cv2 class SuperResolutionNet(nn.Module): def __init__(self, upscale_factor, inplace=False): super(SuperResolutionNet, self).__init__() self.relu = nn.ReLU(inplace=inplace) self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2)) self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1)) self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1)) self.conv4 = nn.Conv2d(32, upscale_factor ** 2, (3, 3), (1, 1), (1, 1)) self.pixel_shuffle = nn.PixelShuffle(upscale_factor) self._initialize_weights() def forward(self, x): x = self.relu(self.conv1(x)) x = self.relu(self.conv2(x)) x = self.relu(self.conv3(x)) x = self.pixel_shuffle(self.conv4(x)) return x def _initialize_weights(self): init.orthogonal_(self.conv1.weight, init.calculate_gain('relu')) init.orthogonal_(self.conv2.weight, init.calculate_gain('relu')) init.orthogonal_(self.conv3.weight, init.calculate_gain('relu')) init.orthogonal_(self.conv4.weight) if __name__ == '__main__': """1.创建super-resolution模型""" torch_model = SuperResolutionNet(upscale_factor=3) # 加载预先训练好的模型权重 del_url = 'https://s3.amazonaws.com/pytorch/test_data/export/superres_epoch100-44c6958e.pth' batch_size = 1 # 使用预训练的权重初始化模型 map_location = lambda storage, loc: storage if torch.cuda.is_available(): map_location = None torch_model.load_state_dict(model_zoo.load_url(del_url, map_location=map_location)) # 将训练模式设置为false torch_model.train(False) input_image = cv2.imread('image1.jpg', cv2.IMREAD_GRAYSCALE) saved_input_image = np.array(input_image) input_image = torch.from_numpy(input_image) # 扩维 input_image = input_image.unsqueeze(0).unsqueeze(0) input_image = input_image.type(torch.float32) # 超分辨率转换 output_image = torch_model(input_image) # 降维 output_image = output_image.type(torch.int8).detach().numpy() output_image = output_image.squeeze(0).squeeze(0) # 结果可视化并保存 # cv2.imshow('1', saved_input_image) # cv2.imshow('2', output_image) # cv2.waitKey(0) cv2.imwrite('input_grey.jpg', saved_input_image) cv2.imwrite('output_grey.jpg', output_image)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63


5.5对抗学习
对抗性机器学习 Adversarial Learning 攻击和防御
1)威胁模型
通常对抗学习的总体目标是向输入数据添加最少量的扰动以引起期望的错误分类。根据不同的目标和对攻击者知识的假设有多种类别的对抗性学习模型。
按照对攻击者知识的假设,可分为:
①白盒模型:假定攻击者具有对模型的全部知识和访问权限(体系结构、输入输出、权重偏置)
②黑盒模型:假定攻击者只能访问模型的输入和输出
按照目标类型,可分为:
①错误分类:攻击者只希望输出错误分类,而无需考虑对应输入被判别为何种分类
②源/目标错误分类:攻击者想要更改最初属于特定源类的图像,使其被归类为特定目标类
2)FGSM
快速梯度标志攻击FGSM(Fast Gradient Sign Attack)是迄今为止最早和最受欢迎的对抗性攻击之一,它是一种简单但有效的对抗样本生成算法,属于白盒模型和错误分类。它旨在利用模型学习的方式来攻击神经网络,即通过调整输入数据在反向传播中最大化损失函数
""" :description:对抗性学习:生成对抗示例 :pre_trained_model_download:https://drive.google.com/drive/folders/1fn83DF14tWmit0RTKWRhPq5uVXt73e0h?usp=sharing """ from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F from torchvision import datasets, transforms import numpy as np import matplotlib.pyplot as plt # epsilon越大大, 动就越明显,对降低模型精度方面的攻击越有效 # 0表示原始测试集上的模型性能,epsilon ∈ [0,1] epsilons = [0, .05, .1, .15, .2, .25, .3] # 预训练模型参数地址 pretrained_model = "data/lenet_mnist_model.pth" # 使用GPU use_cuda = True class Net(nn.Module): """定义被攻击的模型:LeNet模型""" def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x, dim=1) def fgsm_attack(image, epsilon, data_grad): """FGSM算法攻击代码""" # 收集数据梯度的元素符号 sign_data_grad = data_grad.sign() # 通过调整输入图像的每个像素来创建扰动图像 perturbed_image = image + epsilon * sign_data_grad # 添加剪切以维持[0,1]范围 perturbed_image = torch.clamp(perturbed_image, 0, 1) # 返回被扰动的图像 return perturbed_image def test(model, device, test_loader, epsilon): """测试函数:每次调用此测试函数都会对 MNIST 测试集执行完整的测试步骤,并报告最终的准确性""" # 精度计数器 correct = 0 adv_examples = [] # 循环遍历测试集中的所有示例 for data, target in test_loader: # 把数据和标签发送到设备 data, target = data.to(device), target.to(device) # 设置张量的requires_grad属性,这对于攻击很关键 data.requires_grad = True # 通过模型前向传递数据 output = model(data) init_pred = output.max(1, keepdim=True)[1] # 如果初始预测是错误的,不打断攻击,继续 if init_pred.item() != target.item(): continue # 计算损失 loss = F.nll_loss(output, target) # 将所有现有的渐变归零 model.zero_grad() # 计算后向传递模型的梯度 loss.backward() # 收集datagrad data_grad = data.grad.data # 唤醒FGSM进行攻击 perturbed_data = fgsm_attack(data, epsilon, data_grad) # 重新分类受扰乱的图像 output = model(perturbed_data) # 检查是否成功 final_pred = output.max(1, keepdim=True)[1] if final_pred.item() == target.item(): correct += 1 # 保存0 epsilon示例的特例 if (epsilon == 0) and (len(adv_examples) < 5): adv_ex = perturbed_data.squeeze().detach().cpu().numpy() adv_examples.append((init_pred.item(), final_pred.item(), adv_ex)) else: # 稍后保存一些用于可视化的示例 if len(adv_examples) < 5: adv_ex = perturbed_data.squeeze().detach().cpu().numpy() adv_examples.append((init_pred.item(), final_pred.item(), adv_ex)) # 计算这个epsilon的最终准确度 final_acc = correct / float(len(test_loader)) print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc)) # 返回准确性和对抗性示例 return final_acc, adv_examples if __name__ == '__main__': """0.设备选择""" device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu") """1.加载数据集""" test_loader = torch.utils.data.DataLoader( datasets.MNIST('./', train=False, download=True, transform=transforms.Compose([ transforms.ToTensor(), ])), batch_size=1, shuffle=True) """2.网络定义并加载参数""" model = Net().to(device) model.load_state_dict(torch.load(pretrained_model, map_location='cpu')) # 在评估模式下设置模型。在这种情况下,这适用于Dropout图层 model.eval() """3.运行攻击""" accuracies = [] examples = [] # 对每个epsilon运行测试 for eps in epsilons: acc, ex = test(model, device, test_loader, eps) accuracies.append(acc) examples.append(ex) """ 4.结果可视化:精度与 epsilon 图 随着 epsilon 的增加,我们期望测试精度降低。 这是因为较大的 epsilons 意味着我们朝着最 大化损失的方向迈出更大的一步 """ plt.figure(figsize=(5, 5)) plt.plot(epsilons, accuracies, "*-") plt.yticks(np.arange(0, 1.1, step=0.1)) plt.xticks(np.arange(0, .35, step=0.05)) plt.title("Accuracy vs Epsilon") plt.xlabel("Epsilon") plt.ylabel("Accuracy") plt.show() """ 5.样本对抗性示例 随着 epsilon 增加,测试精度降低,但同时扰动也在变得更容易察觉。 实际上,攻击者必须考虑权衡 准确度降级和可感知性 """ # 在每个epsilon上绘制几个对抗样本的例子 cnt = 0 plt.figure(figsize=(8, 10)) for i in range(len(epsilons)): for j in range(len(examples[i])): cnt += 1 plt.subplot(len(epsilons), len(examples[0]), cnt) plt.xticks([], []) plt.yticks([], []) if j == 0: plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14) orig, adv, ex = examples[i][j] plt.title("{} -> {}".format(orig, adv)) plt.imshow(ex, cmap="gray") plt.tight_layout() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
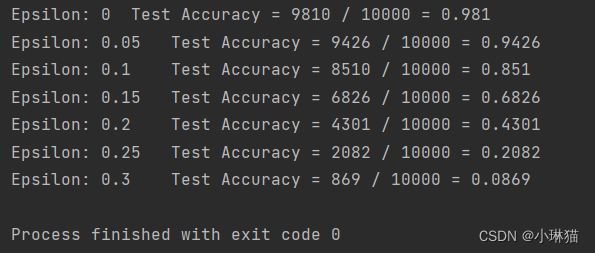
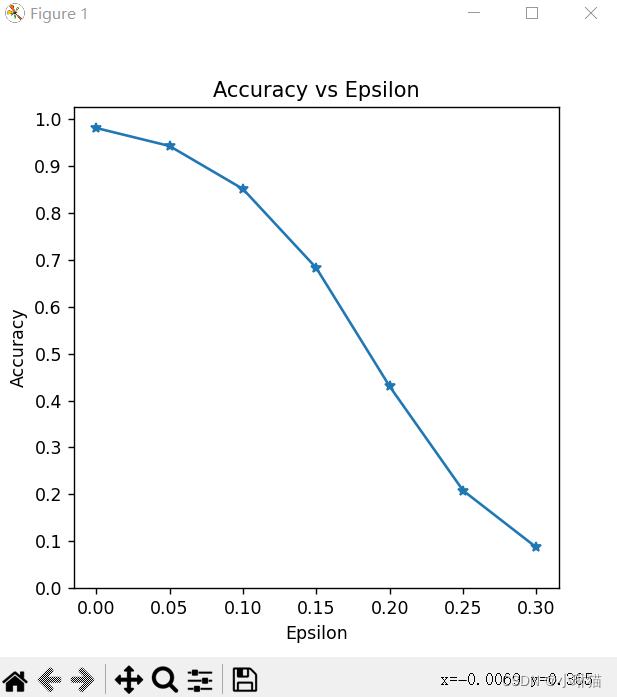

5.6生成对抗网络
1)生成对抗网络
生成对抗网络GAN(Generative Adversarial Networks)是用深度学习模型去捕获数据生成分布的框架,使我们可以从一个分布的数据中生成新的数据。GANs是有Ian Goodfellow 于2014年提出,并且首次在论文Generative Adversarial Nets中描述。
2)组成与原理
GAN由两个不同的模型组成:
①生成器:产生看起来像训练图像的“假”图像
②判别器:查看图像并输出它是否是真实的训练图像或来自生成器的伪图像
在训练期间,生成器不断尝试生成越来越好的“假数据”来超越判别器, 而判别器则是为了更好地检测并准确地对真实和假图像进行分类。这个平衡是当生成器产生的“假数据”看起来像是来自训练数据,而判别器总是猜测生成器输出图像为真或假的概率为50%
3)形式化描述
设x表示代表一张图像的数据;D(x)是判别器网络,它输出x是来自训练数据还是生成器的概率,可被认为是传统的二元分类器
设z表示从标准正态分布中采样的潜在空间向量,G(z)表示将潜在空间向量映射到数据空间的生成器函数,生成器的目标是估计训练数据的生成分布,以便可以产生假数据。
D(G(z))则表示生成器G的输出是训练集的概率。
D试图最大化它正确分类真实数据和假数据的logD(x)概率,G试图最小化D预测其为假数据的概率log(1-G(x)),因而GAN的损失函数为:
l
o
s
s
=
m
i
n
G
m
a
x
D
V
(
D
,
G
)
=
E
x
~
P
d
a
t
a
(
x
)
l
o
g
D
(
x
)
+
E
z
~
P
z
(
z
)
l
o
g
[
1
−
D
(
G
(
z
)
)
]
loss = min_Gmax_DV(D,G)=E_{x ~ P_{data}^{(x)}} logD(x) + E_{z ~ P_{z}^{(z)}} log[1-D(G(z))]
loss=minGmaxDV(D,G)=Ex~Pdata(x)logD(x)+Ez~Pz(z)log[1−D(G(z))]
该损失函数的最优解为:
P
g
=
P
d
a
t
a
P_g = P_{data}
Pg=Pdata,即判别器猜测的概率为0.5
4)DCGAN
DCGAN是对GAN的直接扩展,它与GAN的区别在于它分别在判别器和生成器中明确地使用了卷积
""" :description:深度卷积生成对抗网络 :dataset:img_align_celeba.zip,将解压后的数据集放在data/celeba下 :dataset_download:https://drive.google.com/drive/folders/0B7EVK8r0v71pTUZsaXdaSnZBZzg?resourcekey=0-rJlzl934LzC-Xp28GeIBzQ """ from __future__ import print_function import random import torch.nn as nn import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML """超参数配置""" # 为再现性设置随机seem manualSeed = 999 print("Random Seed: ", manualSeed) # 要新结果 # manualSeed = random.randint(1, 10000) random.seed(manualSeed) torch.manual_seed(manualSeed) # 数据集的根目录 dataroot = "data/celeba" # 加载数据的工作线程数 workers = 2 batch_size = 128 image_size = 64 # 通道数 nc = 3 # 潜在向量z的大小 nz = 100 # 生成器中特征图的大小 ngf = 64 # 判别器中的特征映射的大小 ndf = 64 # 训练epochs的大小 num_epochs = 50 # 优化器的学习速率 lr = 0.0002 # 适用于Adam优化器的Beta1超级参数 beta1 = 0.5 # 可用的GPU数量。使用0表示CPU模式 ngpu = 1 def weights_init(m): """权重初始化:所有模型权重应从正态分布中随机初始化""" classname = m.__class__.__name__ if classname.find('Conv') != -1: nn.init.normal_(m.weight.data, 0.0, 0.02) elif classname.find('BatchNorm') != -1: nn.init.normal_(m.weight.data, 1.0, 0.02) nn.init.constant_(m.bias.data, 0) class Generator(nn.Module): """生成器""" def __init__(self, ngpu): super(Generator, self).__init__() self.ngpu = ngpu self.main = nn.Sequential( # 输入是Z,进入卷积 nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False), nn.BatchNorm2d(ngf * 8), nn.ReLU(True), # state size. (ngf*8) x 4 x 4 nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 4), nn.ReLU(True), # state size. (ngf*4) x 8 x 8 nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 2), nn.ReLU(True), # state size. (ngf*2) x 16 x 16 nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf), nn.ReLU(True), # state size. (ngf) x 32 x 32 nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False), nn.Tanh() # state size. (nc) x 64 x 64 ) def forward(self, input): return self.main(input) class Discriminator(nn.Module): """判别器""" def __init__(self, ngpu): super(Discriminator, self).__init__() self.ngpu = ngpu self.main = nn.Sequential( # input is (nc) x 64 x 64 nn.Conv2d(nc, ndf, 4, 2, 1, bias=False), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf) x 32 x 32 nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 2), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*2) x 16 x 16 nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 4), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*4) x 8 x 8 nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 8), nn.LeakyReLU(0.2, inplace=True), # state size. (ndf*8) x 4 x 4 nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), nn.Sigmoid()) def forward(self, input): return self.main(input) if __name__ == '__main__': """0.设备选择""" device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu") """1.加载数据集""" # 创建数据集 dataset = dset.ImageFolder(root=dataroot, transform=transforms.Compose([ transforms.Resize(image_size), transforms.CenterCrop(image_size), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])) # 创建加载器 dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers) # 绘制部分我们的输入图像 real_batch = next(iter(dataloader)) plt.figure(figsize=(8, 8)) plt.axis("off") plt.title("Training Images") plt.imshow( np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(), (1, 2, 0))) """2.模型准备""" # 创建生成器 netG = Generator(ngpu).to(device) # 生成器参数初始化 netG.apply(weights_init) # print(netG) # 创建判别器 netD = Discriminator(ngpu).to(device) netD.apply(weights_init) # print(netD) """3.损失函数、优化器准备""" # 初始化BCELoss函数 criterion = nn.BCELoss() # 创建一批潜在的向量,我们将用它来可视化生成器的进程 fixed_noise = torch.randn(64, nz, 1, 1, device=device) # 在训练期间建立真假标签的惯例 real_label = 1 fake_label = 0 # 为 G 和 D 设置 Adam 优化器 optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999)) optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999)) """4.模型训练""" # Lists to keep track of progress img_list = [] G_losses = [] D_losses = [] iters = 0 print("Starting Training Loop...") for epoch in range(num_epochs): for i, data in enumerate(dataloader, 0): """第一步:训练判别器:maximize log(D(x)) + log(1 - D(G(z)))""" # 训练所有真实数据 netD.zero_grad() # Format batch real_cpu = data[0].to(device) b_size = real_cpu.size(0) label = torch.full((b_size,), real_label, device=device) # Forward pass real batch through D output = netD(real_cpu).view(-1) # Calculate loss on all-real batch label = label.type(torch.float32) errD_real = criterion(output, label) # Calculate gradients for D in backward pass errD_real.backward() D_x = output.mean().item() # 训练所有生成数据 # Generate batch of latent vectors noise = torch.randn(b_size, nz, 1, 1, device=device) # Generate fake image batch with G fake = netG(noise) label.fill_(fake_label) # Classify all fake batch with D output = netD(fake.detach()).view(-1) # Calculate D's loss on the all-fake batch errD_fake = criterion(output, label) # Calculate the gradients for this batch errD_fake.backward() D_G_z1 = output.mean().item() # Add the gradients from the all-real and all-fake batches errD = errD_real + errD_fake # Update D optimizerD.step() """第二步:训练生成器:maximize log(D(G(z)))""" netG.zero_grad() # fake labels are real for generator cost label.fill_(real_label) # Since we just updated D, perform another forward pass of all-fake batch through D output = netD(fake).view(-1) # Calculate G's loss based on this output errG = criterion(output, label) # Calculate gradients for G errG.backward() D_G_z2 = output.mean().item() # Update G optimizerG.step() # Output training stats if i % 50 == 0: print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): % .4f / % .4f' % (epoch, num_epochs, i, len(dataloader), errD.item(), errG.item(), D_x, D_G_z1, D_G_z2)) # Save Losses for plotting later G_losses.append(errG.item()) D_losses.append(errD.item()) # Check how the generator is doing by saving G's output on fixed_noise if (iters % 500 == 0) or ((epoch == num_epochs - 1) and (i == len(dataloader) - 1)): with torch.no_grad(): fake = netG(fixed_noise).detach().cpu() img_list.append(vutils.make_grid(fake, padding=2, normalize=True)) iters += 1 """5.可视化训练结果""" # D&G的损失与训练迭代的关系图 plt.figure(figsize=(10, 5)) plt.title("Generator and Discriminator Loss During Training") plt.plot(G_losses, label="G") plt.plot(D_losses, label="D") plt.xlabel("iterations") plt.ylabel("Loss") plt.legend() plt.show() # G的过程可视化 fig = plt.figure(figsize=(8, 8)) plt.axis("off") ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list] ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True) HTML(ani.to_jshtml()) # 真实图像 vs 伪图像 # 从数据加载器中获取一批真实图像 real_batch = next(iter(dataloader)) # 绘制真实图像 plt.figure(figsize=(15, 15)) plt.subplot(1, 2, 1) plt.axis("off") plt.title("Real Images") plt.imshow( np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(), (1, 2, 0))) # 在最后一个epoch中绘制伪图像 plt.subplot(1, 2, 2) plt.axis("off") plt.title("Fake Images") plt.imshow(np.transpose(img_list[-1], (1, 2, 0))) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
6.Drive Into Deep Learning
6.1.序
1)如何推广某种计算技术:任何⼀种计算技术要想发挥其全部影响⼒,都必须得到充分的理解、充分的⽂档记录,并得到成熟的、维护 良好的⼯具的⽀持。关键思想应该被清楚地提炼出来,尽可能减少需要让新的从业者跟上时代的⼊⻔时间。 成熟的库应该⾃动化常⻅的任务,⽰例代码应该使从业者可以轻松地修改、应⽤和扩展常⻅的应⽤程序,以满⾜他们的需求。以动态⽹⻚应⽤为例,许多公司,如亚⻢逊,在20世纪90年代开发了成功的数据库驱动⽹⻚应⽤程序,在过去的10年⾥,这项技术在帮助创造性企业家⽅⾯的潜⼒已经得到了更⼤程度的发挥, 部分原因是开发了功能强⼤、⽂档完整的框架。
2)深度学习的可解释性:⽬前,某些直觉只能通过试错、⼩幅调整代码并观察结果来发展。理想情况下,⼀个优雅的数学理论可能会精确地告诉我们如何调整代码以达到期望的结果。不幸的是,这种优雅的理论⽬前还没有出现。尽管我们尽了最⼤努⼒,但仍然缺乏对各种技术的正式解释,这既是因为描述这些模型的数学可能⾮常困难,也是因为对这些主题的认真研究最近才进⼊⾼潮。
3)机器学习
机器学习科学家的目标:发现模式
①学习:训练模型,实际是发现正确的参数集,通过数据确定程序行为(用数据编程)
②一般来说,训练数据越多(正确的数据、不均衡的数据集),模型越强大,因为减少了对预先设想假设的依赖
③任务(实现很多任务的自动化并不屈从于人类所能考虑到的逻辑)
-
搜索:信息检索领域,输出一个或一组项,并按相关性分数进行排序
-
推荐系统:向用户进行个性化推荐
-
强化学习:
与离线学习不同,强化学习要与环境进行互动,“智能代理、预测模型”(环境记得我们以前做过什么吗?环境是否有助于我们建模?环境是否要打败模型?环境是否重要?环境是否变化 → 分布偏移),模型从与环境交互中获得奖励。任何监督问题都可以转为学习问题,强化学习还可以解决许多监督学习无法解决的问题。
当环境可被完全观察到时:马尔可夫决策过程;当状态不依赖于之前的操作时:上下文赌博机;当没有状态时,只有一组最初未知回报的可用动作时:多臂赌博机
④起源:⼈类⻓期以来就有分析数据和预测未来结果的愿望,⽽自然科学⼤部分都植根于此;数学家对估计也有敏锐的直觉;罗纳德·费舍尔的统计理论和遗传学贡献、香农的信息论、图灵的计算理论(机器能思考么?)、唐纳德·赫布的《行为的组织》(神经元通过积极强化学习,赫布学习)
4)深度学习
①机器学习和统计的关注点从线性模型和核方法转为深度学习
②新的发展:容量控制方法dropout(在整个神经网络中应用噪声注入)、注意力机制:解决了如何在不增加学习参数的情况下增加系统的记忆性和复杂性(可学习的指针结构,存储指向翻译过程的中间状态的指针)、多段统计(存储器网络、神经编程器-解释器,描述用于推理的迭代方法)、生成对抗网络(传统模型:找到合适的概率分布和参数估计)、并行和分布式训练
③深度学习框架:
- 第一代:Caffe、Torch、Theano
- 第二代:TensorFlow、CNTK、Caffe和Apache MXNet
- 第三代(命令式):Pytorch、MXNet
④传统的人工设计的特征工程,特征提取器,劳动密集、管道末端的浅层模型 → 端到端的、统一的、自动调整的滤波器、接受次优解、经验主义的表示学习
6.2.多层感知机
1)泛化
永远不能准确地计算泛化误差,因为无限多的数据样本是一个虚构的对象,只能用独立的测试集来估计泛化误差
几乎所有现实的应用都涉及到一些违背独立同分布假设的情况
2)模型复杂度
很难比较本质上不同大类模型(决策树、神经网络)之间的复杂性。能够轻松解释任意事实的模型是复杂的,而表达能力有限但仍能很好地解释数据的模型可能更有现实用途。如果一个理论能拟合数据,且有具体的测试可以证明它是错的,那么它就是好的。因为所有的统计估计都是事后归纳。
3)泛化方法:权重衰减、限制特征数量、范数(L2岭回归、L1套索回归)、暂退法Dropout(只在训练时有效torch.nn.Dropout)、扰动的健壮性(模型的简单性和平滑性)
4)数值稳定性:避免梯度消失和爆炸;打破对称性(关键在于参数的随机初始化)
5)参数初始化:默认初始化、Xavier初始化(对于每一层,输出的方差不受输入数量的影响,任何梯度的方差不受输出数量的影响)
6)环境和分布偏移
问题:数据最初从哪里来?当数据分布突然改变时,模型在部署中会出现灾难性的失败。通过基于模型的决策引入环境,环境改变时可能会破坏模型。
分布偏移的类型:①协变量偏移(输入分布改变但标签函数没变,如训练输入真实猫狗图片,推理输入卡通猫狗图片,输入分布发生改变);②标签偏移(输入分布不变但标签函数改变,如标签函数为穿皮鞋的人比穿布鞋的人有钱,随着环境变化,真实标签为穿布鞋的人比穿皮鞋的人有钱);③概念偏移(描述现实的概念随着环境变化而改变,如不同地区对“软饮”概念不同)
分布偏移纠正:①根据来自正确分布与来自错误分布的概率比作为每个样本的权重来纠正协变量偏移;②根据标签似然比作为每个样本的权重来纠正标签偏移;③概念偏移纠正很难用原则性方式解决,但通常概念的变化是缓慢的,使用新数据更新当前网络,而不是从头训练
非平稳分布:当分布变换缓慢且模型没有得到充分更新时
7)学习分类:批量学习;在线学习(batch=1)、老虎机(参数调整有限离散而非无线连续)、控制(PID控制器算法、环境模型)、强化学习(在静止环境中一直有效的相同策略,在环境改变的情况下可能不会始终有效)
8)机器学习中的公平、责任和透明度
当部署机器学习系统时,不仅仅是在优化一个预测模型,而通常是在提供一个会被用来(部分或完全)进行自动化决策的工具。从预测到决策不仅提出了新的技术要求,也提出了伦理问题。
6.3.卷积神经网络
1)一些概念
现代卷积神经网络的设计得益于生物学、群论和一系列的补充实验
互相关运算:所谓的卷积层进行的运算并非是严格的卷积而是互相关运算
特征映射:输出的卷积层有时被称为特征映射,它可以被视为一个输入映射到下一层的空间维度的转换器
感受野:前向传播期间可能影响x计算的所有元素
多层卷积时容易造成边缘像素的丢失,这是使用填充的动机之一
2)现代卷积神经网络:AlexNet;VGG;NiN(网络中的网络:在每个像素通道上分别使用多层感知机);GoogLeNet(含并行连结的网络、Inception模块);ResNet;DenseNet
3)批量规范化(Batch Normalization,BN)
BN可持续加速深层网络的收敛速度,因而能训练100层以上的网络。
动机:在数据预处理中,标准化可以与优化器配合良好,对参数的量级进行统一;训练时中间层变量可能有更广的变化范围,BN提出非正式的假设:变量分布中的这种偏移可能阻碍网络的收敛;更深层的网络很复杂,容易过拟合,这时正则化变得更重要。
公式:其中,r为偏移系数,b为偏移量
B
N
(
x
)
=
r
⊙
x
−
均值
(
x
)
标准差
(
x
)
+
b
BN(x) = r ⊙ \frac{x- 均值(x)}{标准差(x)} + b
BN(x)=r⊙标准差(x)x−均值(x)+b
训练时,BN基于小批量;预测时,BN基于整个数据集计算均值和标准差,二者的功能不同
争议:批量标准化被认为可使优化更加平滑,作者假设:批量标准化减少了内部协变量偏移,但此处该协变量偏移与严格定义的概念不同,且只是一种不明确的直觉
6.4.注意力机制
1)生物学启发
灵长类动物的视觉系统接收了超过大脑能够完全处理的程度,然而并非所有刺激的影响都是相等的。意识的聚集和专注能使灵长类动物在复杂的视觉环境中将注意力引向感兴趣的物体。
经济学研究稀缺资源分配,人们正处于“注意力经济”时代,即人类的注意力被视为可交换的、有限的、有价值且稀缺的商品。注意力是稀缺的,而环境中干扰注意力的信息却不少。人类祖先已经从经验(数据)中认识到“并非所有感官的输入都是一样的“
“美国心理学之父”威廉·詹姆斯提出了关于人注意力的双组件框架,受试者基于非自主提示和自主提示有选择地引导注意力,自主性的和非自主性的注意力提示解释了人类的注意力的方式
2)注意力机制
注意力汇聚(attention pooling):将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向,输出为中间特征表示
查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚;注意力汇聚有选择地聚合了值(感官输入)生成最终的输出。
3)Nadaraya-Waston核回归
相比于基于平均的汇聚,注意力汇聚实际是一种通过评分函数评价查询
(
x
,
x
i
)
(x,x_i)
(x,xi)关联度作为注意力权重的加权汇聚
f
(
x
)
=
∑
i
=
1
n
α
(
x
,
x
i
)
y
i
通用形式
=
∑
i
=
1
n
K
(
x
−
x
i
)
∑
j
=
1
n
K
(
x
−
x
j
)
y
i
核汇聚
f(x) = \sum^n_{i=1} α(x,x_i)y_i \;\;\;\;\;\;通用形式 \\ = \sum^n_{i=1} \frac {K(x-x_i)}{\sum_{j=1}^n K(x-x_j)} y_i \;\;\;\;\;\;核汇聚
f(x)=i=1∑nα(x,xi)yi通用形式=i=1∑n∑j=1nK(x−xj)K(x−xi)yi核汇聚
函数
α
(
x
,
x
i
)
α(x,x_i)
α(x,xi)是评价测试输入
x
x
x与训练输入
x
i
x_i
xi的评分函数,计算结果作为注意力权重,
y
i
y_i
yi是
x
i
x_i
xi训练输入映射的输出标签,K为核函数
如果查询 x x x更接近于键 x i x_i xi,那么分配给这个键对应值 y i y_i yi的注意力权重就会越大,也就是“获得了更多的注意力”

Nadaraya-Waston核回归采用高斯核(作为注意力评分函数),是一个非参数的注意力汇聚模型,具有一致性:如果有足够多的数据,此模型会收敛到最优结果
学习参数可以很容易地集成到注意力汇聚中,与非参数的注意力汇聚模型相比,带参数的模型加入可学习的参数后,曲线会在注意力权重较大的区域变得更加不平滑
4)注意力评分函数
注意力评分函数α将查询和键映射为一个标量,再经过softmax得到与键对应的值的概率分布(注意力权重),选择不同的注意力评分函数α会导致不同的注意力汇聚操作
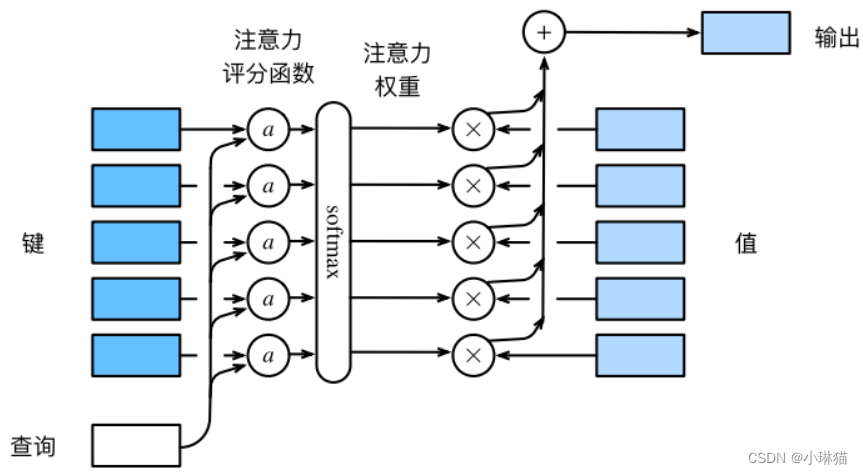
5)常用模块
- 遮掩softmax:某些情况下,并非所有的值都应该被纳入到注意力汇聚中,如输入序列的长度不定,指定有效序列长度,超出有效长度的位置都被置为0
- 加性注意力:解决查询和键是不同的向量
- 缩放点积注意力:使用点积得到计算效率更高的评分函数(需要查询和键有相同的长度)
- Bahdanau注意力:无需严格对齐限制的可微注意力模型(在RNN基础上)
6)Transformer
相比于之前仍然依赖循环神经网络实现输入表示的自注意力模型,Transformer模型完全基于注意力机制,没有任何卷积层和循环神经网络层
- 多头注意力
模型基于相同的注意力机制学习到不同的行为,将不同的行为作为知识组合起来(使用查询、键、值组成不同的子空间表示),捕获序列内各种范围的依赖关系(如短距离依赖和长距离依赖)

- 自注意力(self-attention,也称内部注意力intra-attention)
1)查询、键和值来自于同一组输入
2)对比CNN、RNN、自注意力

| 计算复杂度 | 顺序操作 | 最大路径长度 |
|---|---|---|
| O ( k n d 2 ) O(knd^2) O(knd2) | O ( 1 ) O(1) O(1) | O ( n / k ) O(n/k) O(n/k) |
| O ( n d 2 ) O(nd^2) O(nd2) | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) |
| O ( n 2 d ) O(n^2d) O(n2d) | O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
卷积神经⽹络和⾃注意⼒都拥有并⾏计算的优势,⽽且⾃注意⼒的最⼤路径⻓度最短。但是因为 其计算复杂度是关于序列⻓度的⼆次⽅,所以在很⻓的序列中计算会⾮常慢。
- 位置编码
⾃注意⼒为并⾏计算放弃了顺序操作。为了使⽤序列的顺序信息,通过在输⼊表⽰中添加位置编码(positional encoding)来注⼊绝对的或相对的位置信息。
1)绝对位置信息:正弦函数、余弦函数(三角函数在编码维度上降低频率,浮点数的输出比二进制表示更节省空间)
2)相对位置信息:对于任何确定的位置偏移b,位置b+i的位置编码可以线性投影到i处的位置编码
-
基于位置的前馈网络:基于位置的前馈⽹络对序列中的所有位置的表⽰进⾏变换时使⽤的是同⼀个多层感知机
-
残差连接和层规范化
-
模型
是编码器-解码器架构的一个实例,基于自注意力模块的叠加。
编码器:由多个相同的层叠加⽽成,每个层都有两个⼦层(⼦层表⽰为sublayer):
①第⼀个⼦层是多头⾃注意⼒(multi-head self-attention)汇聚
②第⼆个⼦层是基于位置的前馈⽹络(positionwise feed-forward network)
在计算编码器的⾃注意⼒时,查询、键和值都来⾃前⼀个编码器层的输出。每个⼦层都采⽤了残差连接(residual connection)
解码器:子层中也使⽤了残差连接和层规范化。除了编码器中描述的两个⼦层之外,解码器还在这两⼦层之间插⼊了第三个⼦层,称为编码器-解码器注意⼒(encoderdecoder attention)层:在编码器-解码器注意⼒中,查询来⾃前⼀个解码器层的输出,⽽键和值来⾃整个编码器的输出
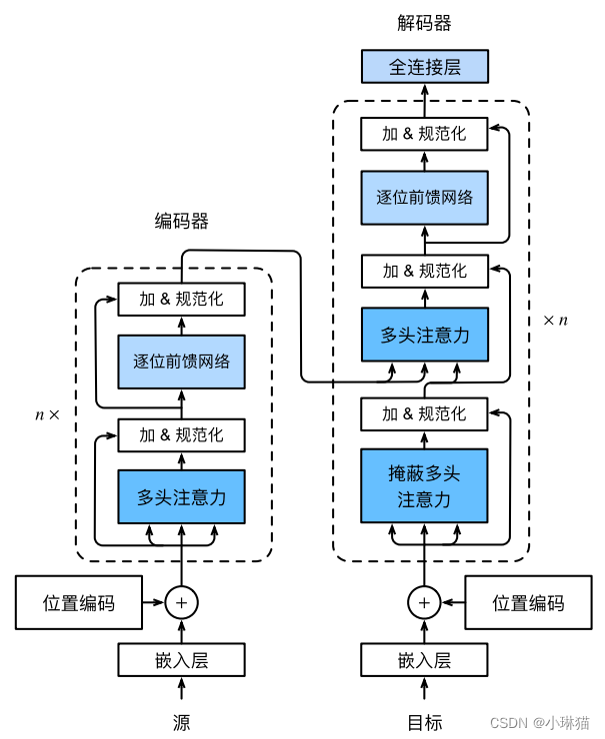
6.5.优化算法
优化算法的性能直接影响模型的训练效率;了解不同优化算法的原理及其超参数的作用能方便实验时有针对性的调参,以提高性能
优化和深度学习的本质目标不同,前者关注最小化目标,后者关注在有限训练集下寻找合适的模型
凸优化;梯度下降;收敛性分析;向量化和缓存
随机梯度下降的“统计效率”与大批量一次处理数据的“计算效率之间”存在权衡,小批量随机梯度下降提供了两全其美的答案
常用优化算法:AdaGrad、RMSProp、Adadelta、Adam、Yogi
学习率调度器:
①学习率大小:如果学习率太⼤,优化就会发散;太⼩,训练就会需要过⻓时间,或者最终只能得到次优的结果
②学习率的衰减速率:如果学习率持续过⾼,可能最终会在最⼩值附近弹跳,从⽽⽆法达到最优解
③初始化:预热(warmup):预热期期间学习率将增加⾄初始最⼤值,然后冷却直到优化过程结束。为了简单起⻅,通常使⽤线性递增
④周期性学习率调整
具体学习率调度器:单因子调度器FactorScheduler、多因子调度器MultiStepLR、余弦调度器CosineScheduler
6.6.计算性能
1)编译器和解释器
①命令式编程(对应解释器,Chainer、Pytorch):编程灵活方便,便于调试;但效率不高(缺少优化)
②符号式编程(对应编译器,Theano、TensorFlow、Keras、CNTK):定义计算流程 → 将流程编译成可执行程序 → 给定输入调用可执行程序运行 允许优化(计算过程优化、变量存储优化)、便于移植
③混合式编程(PyTorch torchscript)
# 转换模型,将命令式变为符号式,便于模型优化,加快推理速度
net = torch.jit.script(net)
# 序列化,将模型或模型参数保存到磁盘,允许训练好的模型部署到其他设备上
net.save('net')
- 1
- 2
- 3
- 4
2)异步计算
MXNet和TensorFlow采用异步模型来提高性能,PyTorch使用自己的调度器来实现性能权衡
Pytorch:计算命令的产生由前端(与用户直接交互、多种语言)发送,计算命令由后端C++程序实际执行。这是两个线程,后端线程管理任务队列并必须能够跟踪计算图中各个步骤之间的依赖关系,任务执行后将计算结果返回给前端。

3)自动并行
深度学习框架(MxNet、飞桨、PyTorch)在后端自动构建计算图,利用计算图,系统可以了解所有依赖关系,并选择性地并行执行多个不相互依赖的任务以提高速度
# 1.基于GPU的并行计算 x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0]) x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1]) def run(x): return [x.mm(x) for _ in range(50)] # 1.1两台GPU同步计算 run(x_gpu1) # # torch.cuda.synchronize()函数将会等待⼀个CUDA设备上的所有流中的所有核⼼的计算完成。函数接受⼀个device参数,代表是哪个设备需要同步。如果device参数是None(默认值),它将使⽤current_device()找出的当前设备。 torch.cuda.synchronize(devices[0]) run(x_gpu2) torch.cuda.synchronize(devices[1]) # 1.2两台GPU并行计算 run(x_gpu1) run(x_gpu2) torch.cuda.synchronize() # 2.并⾏通信 # 通常需要在不同的设备之间移动数据,⽐如在CPU和GPU之间,或者在不同的GPU之间。将计算和移动两个过程分开的效率不高,更高效率的方式是边计算边移动,在计算未完成时将已计算结果进行移动 # 在PyTorch中,to()和copy_()等函数都允许显式的non_blocking参数,这允许在不需要同步时调⽤⽅可以绕过同步。设置non_blocking=True以模拟这个场景。 y = run(x_gpu1) y_cpu = copy_to_cpu(y, True) torch.cuda.synchronize()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4)硬件
5)多GPU训练
①三种方式:在多个GPU之间拆分网络(每个GPU处理网络的某几层);拆分层内工作(将一层的几个通道分给不同GPU);跨多GPU进行数据拆分
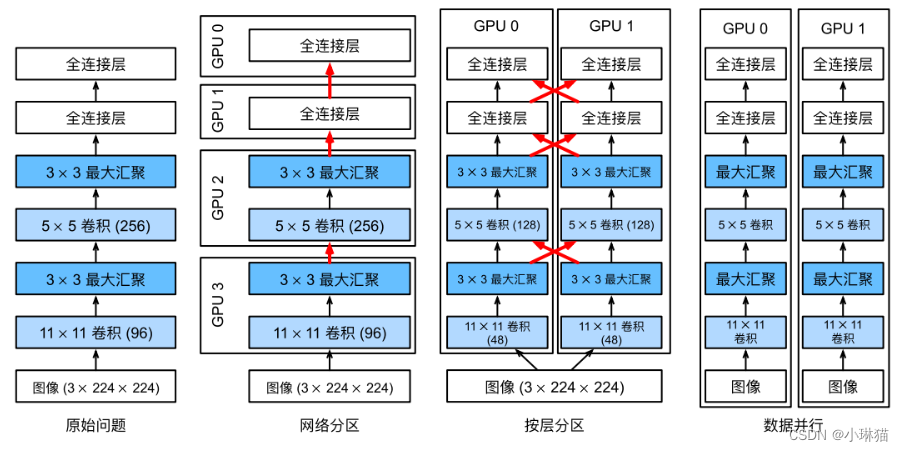
②数据并行
虽然每个GPU上的参数值都是相同且同步的,但是每个GPU都 将独⽴地维护⼀组完整的模型参数
- 在任何⼀次训练迭代中,给定的随机的⼩批量样本都将被分成k个部分,并均匀地分配到GPU上
- 每个GPU根据分配给它的⼩批量⼦集,计算模型参数的损失和梯度
- 将k个GPU中的局部梯度聚合,以获得当前⼩批量的随机梯度
- 聚合梯度被重新分发到每个GPU中
- 每个GPU使⽤这个⼩批量随机梯度,来更新它所维护的完整的模型参数集
net = torch.nn.DataParallel(net, device_ids=devices)
- 1
6)参数服务器
①参数服务器的核⼼思想⾸先是由 (Smola and Narayanamurthy, 2010)在分布式隐变量模型的背景下引⼊的
若多个GPU在不同的服务器上时,参数和梯度的分发与收集工作(多机训练)也变得更加困难,不同的互联方式存在很大区别
- 在每台机器上读取⼀组(不同的)批量数据,在多个GPU之间分割数据并传输到GPU的显存中。基于每 个GPU上的批量数据分别计算预测和梯度。
- 来⾃⼀台机器上的所有的本地GPU的梯度聚合在⼀个GPU上(或者在不同的GPU上聚合梯度的某些部 分)。
- 每台机器的梯度被发送到其本地CPU中
- 所有的CPU将梯度发送到中央参数服务器中,由该服务器聚合所有梯度
- 然后使⽤聚合后的梯度来更新参数,并将更新后的参数⼴播回各个CPU中
- 更新后的参数信息发送到本地⼀个(或多个)GPU中
- 所有GPU上的参数更新完成
在实际场景中进行GPU数据并行训练时,会采用5)中介绍的变体,即梯度的聚合在单个CPU/GPU上完成,再进行广播,进行梯度聚合的设备被称为参数服务器。不同的交换参数的策略会带来不同的结果
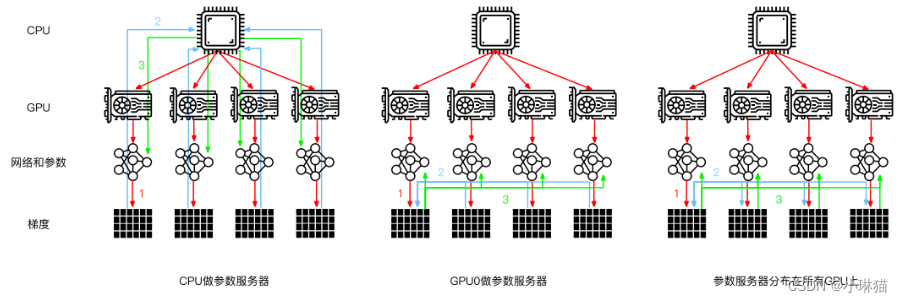
中央的参数服务器成为了瓶颈,确保多台机器只 在没有不合理延迟的情况下⼯作是相当困难的

②键值存储
公共抽象即重 新定义具有更新语义的键-值存储(key-value store)的抽象。在GPU节点上定义新的梯度计算,其关键在于它是一个交换归约(commutative reduction),即它把许多向量变换成⼀个向量,⽽运算顺序在完成向量变换时并不重要。优点在于它不需要为何时接收哪个梯度进⾏细粒度的控制,且这个操作在不同的i之间是独⽴的。
- push(key,value)将特定的梯度值从⼯作节点发送到公共存储,在那⾥通过某种⽅式(例如,相加) 来聚合值
- pull(key,value)从公共存储中取得某种⽅式(例如,组合来⾃所有⼯作节点的梯度)的聚合值
③为了进一步提高效率,可以将梯度的计算和同步准备同时进行,可参考Horovod
④现代深度学习的硬件同步问题会遇到大量的制定网络连接的问题。环同步(Ring Synchronization)
6.7.目标检测
1)边界框 bounding box:描述对象的空间位置。表示法:左上、右下坐标;中心点坐标和框的宽高度
2)锚框 anchor box:目标检测算法的采样区域,用于判断该区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框
3)生成锚框的一种方法:以图像的宽高为基准,设置一定的缩放比例,以每个像素点为中心,为其生成多个不同大小的锚框
4)交并比(IOU):杰卡德系数,可以衡量两集合之间的相似性,给定集合A、B, J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ ∈ [ 0 , 1 ] J(A,B)= \frac {|A ∩ B|} {|A ∪ B|} ∈ [0,1] J(A,B)=∣A∪B∣∣A∩B∣∈[0,1]
将任何边框的像素区域看作一组像素,用交并比衡量锚框和真实边界框之间、不同锚框之间的相似度
5)类别与偏移量预测
在训练集中将锚框看作一个训练样本,预测锚框的类别和偏移量(根据分配的真实边界框),并根据预测的偏移量调整其位置得到预测的边界框
①将真实边界框分配给锚框
- 给定图像,设锚框为: A 1 , A 2 , . . . , A m A_1,A_2,...,A_m A1,A2,...,Am,真实边界框为: B 1 , B 2 , . . . , B n B_1,B_2,...,B_n B1,B2,...,Bn, m ≥ n m≥n m≥n,定义矩阵 X ∈ R m × n , X i , j X ∈ R^{m × n},X_{i,j} X∈Rm×n,Xi,j为 I O U = J ( A i , B j ) IOU=J(A_i,B_j) IOU=J(Ai,Bj)
- 在矩阵X中找到最大的元素 X i , j X_{i,j} Xi,j,将真实边界框 B j B_j Bj分配给 A i A_i Ai(正类锚框),并丢弃i行、j列
- 重复上述步骤,直到n维列元素全部被丢弃
- 遍历剩下的m-n个锚框,对于任何锚框 A i A_i Ai,在X的第i行找到最大的元素,并判断其对应的IOU是否大于指定阈值,大于则将其列对应的真实边界框 B j B_j Bj分配给锚框 A i A_i Ai(正类锚框),否则标记为背景(负类锚框)
②根据配分的真实边界框为锚框指定类别和偏移量
③使用非极大值抑制预测边界框(non-maximun suppression,NMS):可以简化许多相似的围绕着同一目标的有明显重叠的预测边界框(基本思想就是找出与每个真实边界框对应的最大置信度的锚框)
6)多尺度目标检测
①多尺度锚框:在图像上均匀生成锚框,不同尺度(图像尺寸的缩放)下生成不同数量和大小的锚框。较小的锚框可以采样更多区域,较大的锚框可以采样更小的区域

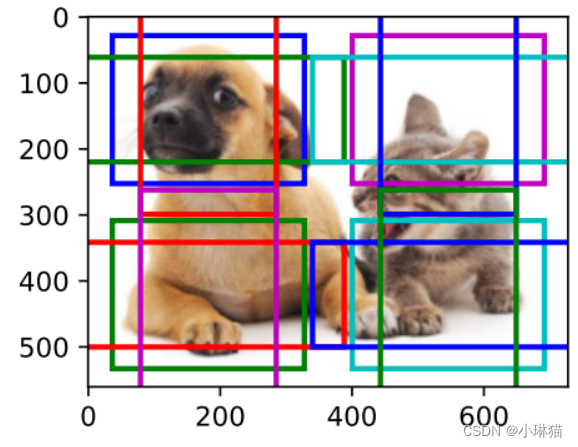
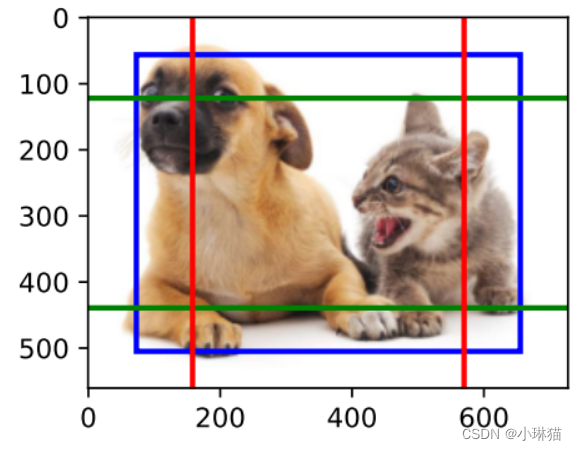
②多尺度:通过深度学习,在多个层次上的图像分层进行多尺度目标检测
单发多框检测SSD(去除分类层的基础网络用于提取特征,如VGG、ResNet),后跟几个多尺度特征块,损失函数根据对类别和偏移量的预测计算得出

③区域卷积神经网络系列(region-based CNN,R-CNN):Fast R-CNN、Faster R-CNN、Mask R-CNN
6.8.语义分割
1)概念
①语义分割:如何将图像分割成属于不同语义类别的区域,它识别并理解图像中每一像素的内容,语义区域的标准和预测像素级问题
②图像分割:通常利⽤图像中像素之间的相关性将图像划分为若⼲组成区域,它在训练时不需要有关图像像素的标签信息,在预测时也⽆法保证分割出的区域具有我们希望得到的语义。
③实例分割:同时检测并分割,研究如何识别图像中各个⽬标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的⽬标实例。
④Pascal VOC2012 语义分割数据集
由于语义分割的输⼊图像和标签在像素上⼀⼀对应,输⼊图像会被随机裁剪为固定尺寸而不是缩放
2)转置卷积
通常的卷积会减少下采样输入图像的空间维度,像素级分类的语义分割中需要使输入和输出图像的空间维度相同
①转置卷积:可以增加上采样中间层特征图的空间维度,用于逆转下采样导致的空间尺寸的减小
输入图像矩阵逐像素与卷积核相乘,得到与卷积核相同大小的中间输出,各中间输出相加得到最后的输出(与通过卷积核“减少”输⼊元素的常规卷积相⽐,转置卷积通过卷积核“⼴播”输⼊元素,从⽽产⽣⼤于输⼊的输出)
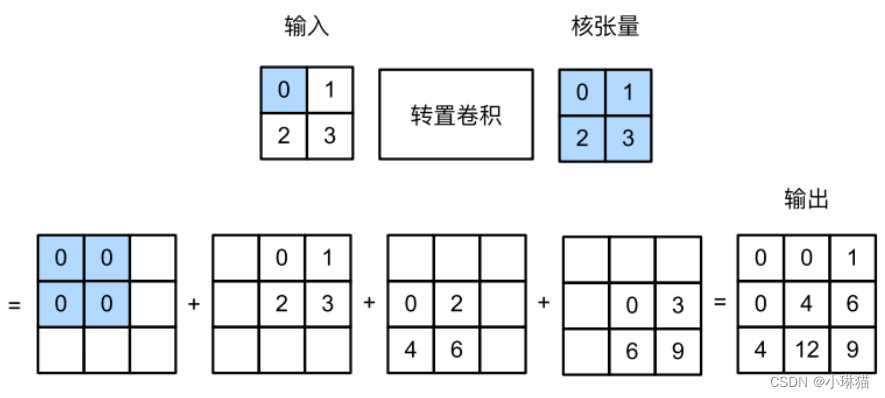
②填充:不同于普通卷积应用于输入图像的填充,转置卷积的填充应用于输出图像,如当高和宽两侧的填充数为1时,转置卷积后的输出中删除最前和最后的一行、列
③步幅:

tconv = torch.nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
- 1
④与矩阵变换的关系:抽象来看,给定输⼊向量x和权重矩阵W,卷积的前向传播函数可以通过将其输⼊与权重矩阵相乘并输出向量 y = W x y = Wx y=Wx来实现。由于反向传播遵循链式法则和 ∇ x y = W ⊤ ∇xy = W^⊤ ∇xy=W⊤,卷积的反向传播函数可以通过将其输⼊与转置 的权重矩阵W⊤相乘来实现。因此,转置卷积层能够交换卷积层的正向传播函数和反向传播函数:它的正向 传播和反向传播函数将输⼊向量分别与W⊤和W相乘。
3)全卷积神经网络(fully convolution network,FCN)
采⽤卷积神经⽹络实现了从图像像素到像素类别的变换,全卷积⽹络将中间层特征图的⾼和宽变换回输⼊图像的尺⼨,这是通过转置卷积(transposed convolution)实现的。
输出的类别预测与输⼊图像在 像素级别上具有⼀⼀对应关系:通道维的输出即该位置对应像素的类别预测。语义分割的损失函数与图像分类的损失函数没有本质区别,需要在损失函数中指定通道维
使用卷积神经⽹络抽取图像特征 → 通过1×1卷积层将通道数变换为类别个数 → 通过转置卷积层将特征图的⾼和宽变换为输⼊图像的尺⼨ → 模型输出与输⼊图像的⾼和宽相同,且最终输出通道包含了该空间位置像素的类别预测
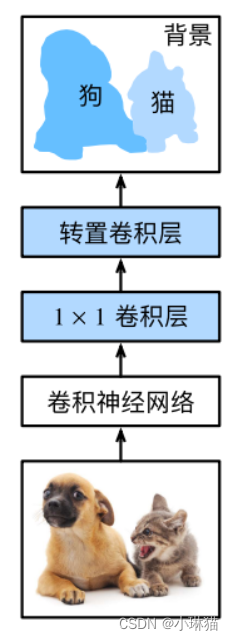
4)双线性插值(bilinear interpolation)
可以实现图像的放大,即上采样(upsampling),可以通过转置卷积层实现
- 将输出图像的坐标(x, y)映射到输⼊图像的坐标(x ′ , y′ )上。例如,根据输⼊与输出的尺⼨之⽐来射。请 注意,映射后的x′和y′是实数
- 在输⼊图像上找到离坐标(x ′ , y′ )最近的4个像素
- 输出图像在坐标(x, y)上的像素依据输⼊图像上这4个像素及其与(x ′ , y′ )的相对距离来计算

