
- 1多模态是什么意思,在生活工业中有哪些应用?_多模态是什么意思?
- 2python-pytorch基础之加载bert模型获取字向量_pytorch加载本地bert模型
- 3Android自定义View基础--Paint设置PorterDuffXfermode图形混合模式实现遮罩效果,例如头像展示_android view遮罩 mpaint.setxfermode
- 4gcc流程及鲜有人知的参数_-fvolatile
- 5使用vim编写golang_vim中编译go语言文件的命令
- 6Ubuntu16.04+python3+Spyder+qt5(python3)的安装
- 7R语言使用caret包的confusionMatrix函数计算混淆矩阵、基于混淆矩阵的信息手动编写函数计算f1指标_r语言 f1 score
- 8有道词典笔3新增功能扫读和点读是怎么集成的?_词典笔是什么原理
- 9【8个Python数据清洗代码,拿来即用】_python进行文本清洗时的去除噪声的代码
- 10任意文件上传下载漏洞_nginx防止php文件被下载
[玩转AIGC]sentencepiece训练一个Tokenizer(分词器)_the sentencepiece tokenizer that you are convertin
赞
踩
一、前言
前面我们介绍了一种字符编码方式【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
这种方式是对一个一个字符编码,丢失了很多信息比如“机器学习训练”,会被编码为“机”,“器”,“学”,“习”,“训”,“练”,单独一个字符,丢失了关联性。对于英文句子,比如:Let’s do tokenization!,基于字符分割如下图:
 当然,我们也可以基于其它类型进行分割,比如说基于空格,或者基于punctuation
当然,我们也可以基于其它类型进行分割,比如说基于空格,或者基于punctuation

但这种分割方式分割不了beginning,应该beginning是由begin跟后缀ning组成的,再比如annoyingly实际可分割为annoying加上后缀ly。
再比如想将“机器学习训练”分割为“机器/学习/训练”,那么该怎么办呢,这里可以用谷歌开源的工具sentencepiece(当然了,github仓库说明了这不是 Google 官方产品),接下来我们来看看怎么安装使用。
建议可以先把:如何训练一个中英翻译模型这个栏目的文章看一看,对于理解LLM是会有所帮助的,因为在transformer还未诞生之前可谓是LSTM(RNN)的天下,后人思想受前人思想的启发,提前了解收货会更大。
1)仓库代码:
github:sentencepiece
2)SentencePiece介绍:
SentencePiece 是一种无监督文本分词器和去分词器,主要用于基于神经网络的文本生成系统,其中词汇量大小在神经模型训练之前预先确定。 SentencePiece 通过扩展原始句子的直接训练来实现子词单元(例如,字节对编码 (BPE) (byte-pair-encoding (BPE) [ Sennrich et al.]))和一元语言模型(unigram language model Kudo.))。 SentencePiece 允许我们制作一个纯粹的端到端系统,不依赖于特定于语言的预处理/后处理。
二、安装
ubuntu安装依赖
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
- 1
安装sentencepiece
1)命令安装(超级推荐)
# 用于训练的
sudo apt install sentencepiece -y
# 用于python推理调用的
pip3 install sentencepiece
- 1
- 2
- 3
- 4
2)除此之外,还可以选择编译安装:
% git clone https://github.com/google/sentencepiece.git
% cd sentencepiece
% mkdir build
% cd build
% cmake ..
% make -j $(nproc)
% sudo make install
% sudo ldconfig -v
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3)或者vcpkg编译安装
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install sentencepiece
- 1
- 2
- 3
- 4
- 5
安装好了之后就可开始尝试进行训练一个模型了。
三、自己训练一个tokenizer
用于训练的txt文件自己去找一个即可,我这边找的是斗破某陆小说。
这里要注意XXX.txt文本的编码格式,建议采用utf-8格式,对于windows下的ANSI,ubuntu下打开会乱码,且训练出来的模型是会有问题,所以先打开XXX.txt看看文本是不是乱码的。
乱码是真的乱,如下:
 确保XXX.txt文件没问题了,那么就可以进行训练了
确保XXX.txt文件没问题了,那么就可以进行训练了
在命令窗口输入以下命令:
spm_train --input=dpcq.txt -model_prefix=./tokenizer
- 1
–input:输入的txt文件,这里的文件是dpcq.txt
-model_prefix:模型输出路径与名称,这里的名称是tokenizer
训练完成可以看到以下两个文件:

tokenizer.model:是训练出来的模型
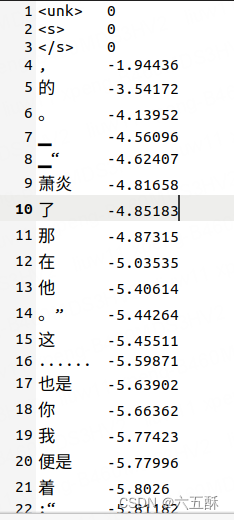
tokenizer.vocab:为所分割的词汇,这个文件可以打开来看看:
四、模型运行
训练出来的模型,我们来跑跑看效果怎样:
from sentencepiece import SentencePieceProcessor
model_path = "tokenizer.model"
sp_model = SentencePieceProcessor(model_file=model_path)
mm = sp_model.EncodeAsPieces("虽说这些年大陆之上已是没有了他的身影,但那传说,却依然是口口相传,炎帝之名,响彻着斗气大陆的每一个角落。")
print(mm)
- 1
- 2
- 3
- 4
- 5

五、拓展
有了上面的基础了,这里我们来进行一个拓展,这个拓展是基于llama2模型的。
github链接:
先git下来
git clone https://github.com/karpathy/llama2.c.git
- 1
下载后要训练自己的模型,命令如下:
# 下载数据集
python tinystories.py download
# 数据集标记化处理
python tinystories.py pretokenize
# 训练
python train.py
- 1
- 2
- 3
- 4
- 5
- 6
我们这里主要是来看tokenize,python tinystories.py pretokenize这个命令是调用了tokenizer.py,我们来看相应的代码:
# Taken from llama code and lightly modified # Copyright (c) Meta Platforms, Inc. and affiliates. # This software may be used and distributed according to the terms of the Llama 2 Community License Agreement. import os from logging import getLogger from typing import List from sentencepiece import SentencePieceProcessor TOKENIZER_MODEL = "tokenizer.model" # the llama sentencepiece tokenizer model TOKENIZER_BIN = "tokenizer.bin" # binary version of the tokenizer for inference in C class Tokenizer: def __init__(self): model_path = TOKENIZER_MODEL assert os.path.isfile(model_path), model_path self.sp_model = SentencePieceProcessor(model_file=model_path) #print(f"Loaded SentencePiece model from {model_path}") # BOS / EOS token IDs self.n_words: int = self.sp_model.vocab_size() self.bos_id: int = self.sp_model.bos_id() self.eos_id: int = self.sp_model.eos_id() self.pad_id: int = self.sp_model.pad_id() #print(f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}") assert self.sp_model.vocab_size() == self.sp_model.get_piece_size() def encode(self, s: str, bos: bool, eos: bool) -> List[int]: assert type(s) is str t = self.sp_model.encode(s) if bos: t = [self.bos_id] + t if eos: t = t + [self.eos_id] return t def decode(self, t: List[int]) -> str: return self.sp_model.decode(t) def export(self): tokens = [] for i in range(self.n_words): # decode the token and light postprocessing t = self.sp_model.id_to_piece(i) if i == self.bos_id: t = '\n<s>\n' elif i == self.eos_id: t = '\n</s>\n' elif len(t) == 6 and t.startswith('<0x') and t.endswith('>'): t = chr(int(t[3:5], 16)) # e.g. make '<0x01>' into '\x01' t = t.replace('▁', ' ') # sentencepiece uses this as the whitespace tokens.append(t) with open(TOKENIZER_BIN, 'wb') as f: for token in tokens: bytes = token.encode('utf-8') f.write((len(bytes)).to_bytes(4, 'little')) # write length of bytes f.write(bytes) # write token bytes if __name__ == "__main__": t = Tokenizer() t.export()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
可以看到代码主要是调用了模型TOKENIZER_MODEL = "tokenizer.model"来对训练集进行训练前的编码,这个模型是来源于llama的,我们按照上面的方法来调用看看分割效果:
from sentencepiece import SentencePieceProcessor
model_path = "tokenizer.model"
sp_model = SentencePieceProcessor(model_file=model_path)
mm = sp_model.EncodeAsPieces("The line of code you provided is using the Hugging Face tokenizers library to encode a piece of text. The encode method is being called with the bos=True parameter, which adds a special \"beginning of sequence\" (BOS) token to the beginning of the encoded sequence.")
print(mm)
- 1
- 2
- 3
- 4
- 5
- 6
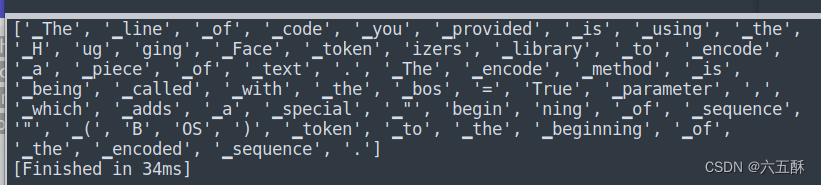 可以看到分割时候会把’beginning’分割为’begin’, ‘ning’。当然了,必要的话也可跟着上面的步骤一样自己训练一个Tokenizer模型。
可以看到分割时候会把’beginning’分割为’begin’, ‘ning’。当然了,必要的话也可跟着上面的步骤一样自己训练一个Tokenizer模型。
这一篇文章先到这里了,还是挺有意思,后面的文章我们将逐渐介绍怎么来训练自己的llama2
六、补充
在第五小节扩展那里我们没介绍数据集长什么样,数据集下载下来太大,一般来说电脑打开会卡死,所以我这边把数据集弄出来介绍一下,下面来给大家看看数据集:
{ "story": "\n\nLily and Ben are friends. They like to play in the park. One day, they see a big tree with a swing. Lily wants to try the swing. She runs to the tree and climbs on the swing.\n\"Push me, Ben!\" she says. Ben pushes her gently. Lily feels happy. She swings higher and higher. She laughs and shouts.\nBen watches Lily. He thinks she is cute. He wants to swing too. He waits for Lily to stop. But Lily does not stop. She swings faster and faster. She is having too much fun.\n\"Can I swing too, Lily?\" Ben asks. Lily does not hear him. She is too busy swinging. Ben feels sad. He walks away.\nLily swings so high that she loses her grip. She falls off the swing. She lands on the ground. She hurts her foot. She cries.\n\"Ow, ow, ow!\" she says. She looks for Ben. She wants him to help her. But Ben is not there. He is gone.\nLily feels sorry. She wishes she had shared the swing with Ben. She wishes he was there to hug her. She limps to the tree. She sees something hanging from a branch. It is Ben's hat. He left it for her.\nLily smiles. She thinks Ben is nice. She puts on his hat. She hopes he will come back. She wants to say sorry. She wants to be friends again.", "instruction": { "prompt:": "Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would understand. The story should use the verb \"hang\", the noun \"foot\" and the adjective \"cute\". The story has the following features: the story should contain at least one dialogue. Remember to only use simple words!\n\nPossible story:", "words": [ "hang", "foot", "cute" ], "features": [ "Dialogue" ] }, "summary": "Lily and Ben play in the park and Lily gets too caught up in swinging, causing Ben to leave. Lily falls off the swing and hurts herself, but Ben leaves his hat for her as a kind gesture.", "source": "GPT-4" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在代码tinystories.py中的def pretokenize()函数我们可以看到训练数据集数提取了JSON数据中的"story",也就是text = example["story"],因为我们要训练一个故事生成模型,所以提取"story"就可以了,训练时候就是一堆故事数据集,并没有把整个JSON丢进去训练,无论是训练Tokenizer还是基于Tokenizer model来训练整个模型,都要注意数据集的提取,训练中文也是如此,后面会介绍基于中文数据集的训练
参考文献:
https://huggingface.co/learn/nlp-course/zh-CN/chapter2/4?fw=tf
https://blog.csdn.net/sparkexpert/article/details/94741817

