
- 1mysql中函数random_random()函数怎么使用 - min
- 2netlink_kernel_create
- 3STM32F103C8T6的MODBUS-RTU通讯(485通讯)_stm32 modbus
- 4122个经典SOTA模型、447个算法实现资源,我们帮你一文汇总了
- 5c语言动态规划dp(不定时间更新)
- 6加密算法(二)——MD5,Base64,DES,RSA加密算法解析_md5和base64加密与解密的算法特点
- 7基于单片机内部的ADC知识系统总结_单片机adc
- 8Dijkstra算法堆/优先队列优化_迪杰斯特拉算法堆优化
- 9HDFS的Java API操作_hdfs的java apl 操作
- 10Flink基础概念及算子_flink 算子
关于中文LLaMA2的一些不错的工作
赞
踩
深度学习自然语言处理 分享
知乎:黄文灏
北京智源AI研究院 技术负责人
LLaMA2放出来以后,中文开源社区就开始了如火如荼的本地化工作。LLaMA2模型放出来当天就出现了一堆占坑的工作,点进去一看都是空repo。不过好在大家效率极高,卷的飞起。这两天,把几个相关工作都玩了一下,整体来看都还是不错的。LLaMA2很强的英文基础能力,加上很少的中文数据和不友好的tokenizer给了做中文SFT和中文continue pretraining的同学们很大的机会,同时给from scratch训练的一些玩家会带来不小的挑战。下面记录几个用过感觉还不错的工作。
进NLP群—>加入NLP交流群
Chinese-LLaMA2-7b from LinkSoul
和这个工作[1]的几位作者很熟,也给他们打过不少call。不过他们的手速还是震惊到我了。当大家都在开repo占坑的时候,作者的千万数据instruction tuning就已经完成了,在LLaMA2开源当天其实就玩到了这个支持中文的model,而且中文能力正经不错。
同时,团队非常落地,没有执着于刷榜和pr,而是相继推出了非常实用的docker一键部署、4bit量化、API服务,用户社区也是非常积极,很多问题都能第一时间得到解答。
作者的主要贡献是通过instruction tuning的方法使模型具备了很好的指令跟随的能力,同时通过大量的中文指令数据的训练,模型的中文能力得到的很好的提高。和Alpaca,Vicuna等工作不同,作者使用将近1000w条指令数据进行指令微调,将提高中文能力和指令微调两个任务统一完成。而且1000w条指令数据全部开源!稍微有点资源的人都可以用这样的方式去试一试。地址这里[2]。
仔细查看开源指令数据集可以看到作者合并了大量开源的指令微调数据集,同时对格式做了很好的处理。而且仔细看代码,会发现作者用了System Message的方法进行微调。微调时中英数据集比例保持了差不多1:1的关系。这些细节上都可以看出作者对指令微调有很深的理解,工作做的非常细致,值得所有其他做指令微调的团队学习。
用OpenCompass简单测了一下MMLU和CMMLU,整体表现还是OK的。

有点遗憾的是作者没有扩充中文词表并做continue pre-training,所以没有很好的解决LLaMA2的中文tokenizer性能不佳的问题。
另外有一个值得思考的问题是,有没有可能通过指令微调的方式让模型增加知识,把中文最重要的知识通过指令的方式喂给模型。同时配上例如Flan这样的英文指令数据。模型可以用大量的指令微调数据同时进行知识学习和指令学习。COIG-PC[3]数据集里面基于各类中文NLP任务整理了几亿条指令数据,应该是可以完成这一任务的。
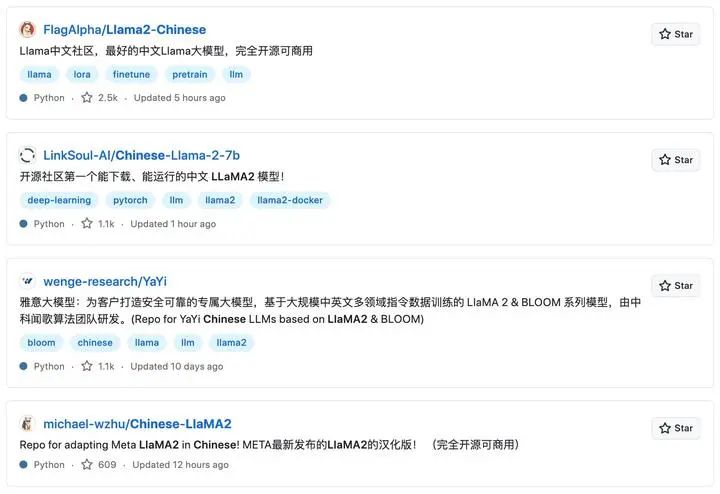
Llama2-Chinese-7B from FlagAlpha
名字和第一个也太相似了,我好几次都傻傻分不清楚。这个是Github上目前看LLaMA2汉化star最高的repo,社区运营也做得非常出色。不过,看了一下整个repo,大量都是LLaMA2原始模型下载和评测的内容,感觉像是个资源整合站,很多汉化工作的细节讲的不是很清楚。
这个工作[4]最不一样的点就是做了continue pretraining,而且用的数据也算是比较丰富的,应该是能够大幅提升模型的中文知识水平。
不过,作者没有介绍continue pretraining的时候有没有配相应的英文数据,中英数据的配比大概是多少,如果配比不佳的话很有可能影响模型的英文能力。同样遗憾的是作者做了continue pretraining却没有括词表,LLaMA2原来的tokenizer对1个中文字大约是用3个token来表示,对输入的context window和输出的output_length都是很大的影响。
最后,有一个不是很明确的是,该工作的PR稿写的是用200B token 从头预训练。我的理解是continue pretraining,不知道是我理解有误还是表述不准确。
整体来说,能在10天左右的时间完成13B模型在200B数据上的continue pretraing,同时维护一个十分活跃的社区是非常值得欣赏的一件事情。
Yayi from Wenge
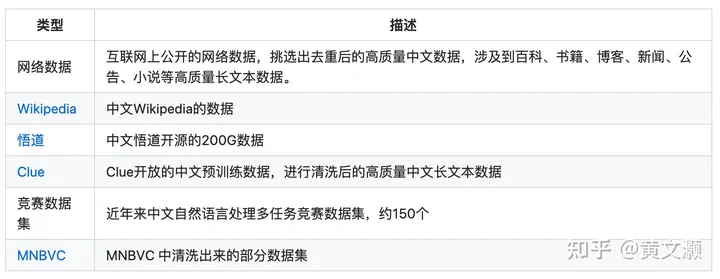
从介绍[5](介绍真的是少)来看,用了百万级领域指令微调数据,但只开放了5w(差评)。
看了下评测,安全性有上升,但是MMLU下降了,估计是微调的时候没有第一个工作做得细致,可以学习一下。
Linly[6]
这个是一个老项目了。相信玩LLaMA和Falcon汉化的应该都看过他们的工作。扩词表,中英增量预训练,中英指令微调,该做的都做了。从评测上看,英文能力保持的还不错,中文能力还是有显著提升的,LLaMA2也比LLaMA和Falcon有了一些提升。这个路径是最稳妥的路径,但是个人感觉数据配比上中文还是过多了点(准确地说是英文配的太少了),可能再调调会有更好的结果。这个是一个老项目了。相信玩LLaMA和Falcon汉化的应该都看过他们的工作。扩词表,中英增量预训练,中英指令微调,该做的都做了。从评测上看,英文能力保持的还不错,中文能力还是有显著提升的,LLaMA2也比LLaMA和Falcon有了一些提升。这个路径是最稳妥的路径,但是个人感觉数据配比上中文还是过多了点(准确地说是英文配的太少了),可能再调调会有更好的结果。
对未来的期待
其实对LLaMA2的汉化本来就没有抱太大期。不过,大家卷的速度的确让我很惊讶。而且还是有一些有趣的事情的。比如:
已知LLaMA2对于from scratch做中文大模型的像ChatGLM,Baichun,Intern-LM没什么多大提升。对于做continue pretraining和instruction tuning的同学,LLaMA2给了大家一个不错的基座,对大家有不少的提升。很好奇,两者能不能做到很接近。
以及前面提到的很想看看有没有可能通过超大规模的指令微调补充中文知识,我的理解只要补充知识类的就可以,中文cc可能都不是很必须。
7B和13B的看烦了,谁能做个70B的汉化,看看涌现的翻译能力对汉化的影响到底怎样。
原文链接:
https://zhuanlan.zhihu.com/p/647388816

进NLP群—>加入NLP交流群
参考资料
[1]
LinkSoul: https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
[2]instruction_merge_set: https://huggingface.co/datasets/LinkSoul/instruction_merge_set
[3]COIG-PC: https://huggingface.co/datasets/BAAI/COIG-PC
[4]FlagAlpha: https://github.com/FlagAlpha/Llama2-Chinese
[5]Wenge: https://github.com/wenge-research/YaYi
[6]Linly: https://github.com/CVI-SZU/Linly

