
- 1jeecgboot前台表格加载以及添加的执行流程_jeecglistmixin
- 2gitlab的使用总结(一)——git命令_gitlab pull的作用
- 3我是如何从功能测试成功转型自动化测试人员的?_如何从功能测试转为中级测试员
- 4字节跳动测试岗面试记:二面被按地上血虐,所幸Offer已到手..._字节二面
- 5计算机网络:CSMA/CA协议
- 6微管理——给你一个技术团队,你该怎么管_《微管理:给你一个技术团队,你该怎么管》电子版
- 7【可视化大屏开发】19. 加餐-百度地图API实现导航加线路热力图
- 8基于TextCNN的微博评论情感分类研究_如何训练textcnn模型对微博文本情感分析
- 9Ubuntu18.04melodic安装Arbotix出现failed to connect to github.com443:拒绝连接_ubuntu下载arbotix
- 10微服务相关
CDH中Notebook的一些问题解决_hadoop notebook
赞
踩
目录:
1、重要事项说明
2、Notebook的配置
3、livy的配置
4、livy的版本问题
5、spark的版本问题
6、其余问题
7、页面展示
8、参考文章
1、重要事项说明
1、cdh5.14默认的python版本为2.6.6, 一定要升级到2.7,方法如下:https://blog.csdn.net/silentwolfyh/article/details/82839713
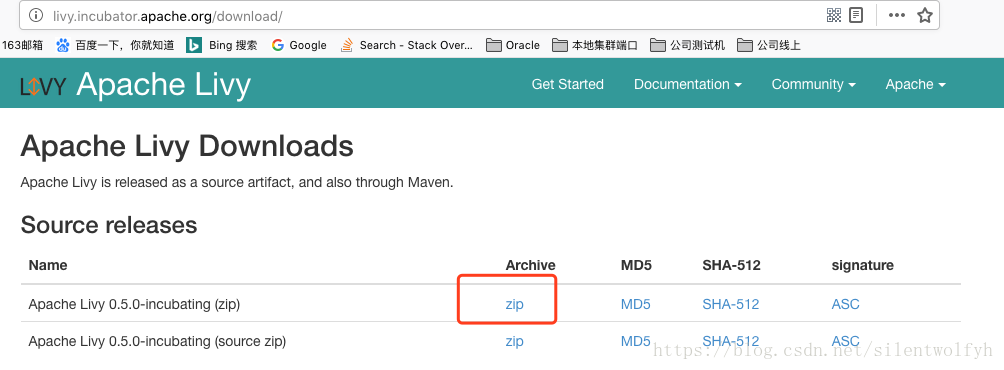
2、livy的livy-server-0.2.0和livy-server-0.3.0版本不行,需要升级到 livy-0.5.0-incubating-bin版本.
下载路径:http://livy.incubator.apache.org/download/ 点击zip进入apache下载页面

3、spark2.10版本会和 livy-0.5.0-incubating-bin有冲突,所以要换成spark1.6的版本.
4、环境变量尽量不要写到" ~/.bash_profile "中, 要写到 " /etc/profile ", 这个问题很严重. 我同事在hdfs用户和root用户的变量有很多问题,后来我统一了.
5、livy启动要使用hdfs的用户,命令如下:
1)将livy-0.5.0-incubating-bin.zip解压到/opt下面
2)给livy-0.5.0-incubating-bin目录hdfs用户权限和hdfs组权限
chown hdfs -R livy-0.5.0-incubating-bin
chgrp hdfs -R livy-0.5.0-incubating-bin
- 1
- 2
使用【hdfs】用户启动livy
nohup ./livy-server &

2、Notebook的配置
CDH的hue的 hue_safety_valve.ini 配置如下:
[desktop] app_blacklist= [spark] server_url=http://IP:8998/ languages='[{"name": "Scala", "type": "scala"},{"name": "PySpark", "type": "pyspark"},{"name": "Python", "type": "python"},{"name": "Impala SQL", "type": "impala"},{"name": "Hive SQL", "type": "hive"},{"name": "Text", "type": "text"}]' [notebook] show_notebooks=true enable_batch_execute=true enable_query_builder=true enable_query_scheduling=false [[interpreters]] [[[hive]]] # The name of the snippet. name=Hive # The backend connection to use to communicate with the server. interface=hiveserver2 [[[impala]]] name=Impala interface=hiveserver2 [[[spark]]] name=Scala interface=livy [[[pyspark]]] name=PySpark interface=livy

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
3、livy的配置
livy-env.sh的配置如下,在结尾添加如下:
路径在:/opt/livy-0.5.0-incubating-bin/conf
export SPARK_HOME=/export/servers/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/lib/spark
export HADOOP_CONF_DIR=/etc/hadoop/conf
export JAVA_HOME=/export/servers/jdk1.7.0_71
export SPARK_CONF_DIR=/etc/spark/conf
export PYSPARK_PYTHON=/usr/bin/python
- 1
- 2
- 3
- 4
- 5
路径在:/opt/livy-0.5.0-incubating-bin/conf
livy.conf的配置如下,在结尾添加如下:
livy.repl.enableHiveContext = true
livy.impersonation.enabled = true
livy.server.session.timeout = 1h
livy.server.session.factory = yarn/local
- 1
- 2
- 3
- 4
4、livy的版本问题
错误定位:
在livy的livy-server启动脚本打印出来的日志.
ERROR repl.PythonInterpreter: Process has died with 1
- 1
解决办法:
换成: livy-0.5.0-incubating-bin.zip的版本
5、spark的版本问题
错误定位:
解决办法:
换成:spark1.6.0
18/10/24 17:28:56 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.1.0.cloudera3 /_/ Using Python version 2.7.10 (default, Oct 23 2018 13:12:58) SparkSession available as 'spark'. >>> >>> from pyspark.sql import HiveContext >>> sqlContext.sql("select * from dwd.dwd_t1_branch_lt_a limit 100").show() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/pyspark/sql/context.py", line 384, in sql return self.sparkSession.sql(sqlQuery) File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/pyspark/sql/session.py", line 545, in sql return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped) File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__ File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/pyspark/sql/utils.py", line 63, in deco return f(*a, **kw) File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value py4j.protocol.Py4JJavaError: An error occurred while calling o47.sql. : java.util.ServiceConfigurationError: org.apache.spark.sql.sources.DataSourceRegister: Provider org.apache.spark.sql.hive.orc.DefaultSource could not be instantiated at java.util.ServiceLoader.fail(ServiceLoader.java:232) at java.util.ServiceLoader.access$100(ServiceLoader.java:185) at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:384) at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:404) at java.util.ServiceLoader$1.next(ServiceLoader.java:480) at scala.collection.convert.Wrappers$JIteratorWrapper.next(Wrappers.scala:43) at scala.collection.Iterator$class.foreach(Iterator.scala:893) at scala.collection.AbstractIterator.foreach(Iterator.scala:1336) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.filterImpl(TraversableLike.scala:247) at scala.collection.TraversableLike$class.filter(TraversableLike.scala:259) at scala.collection.AbstractTraversable.filter(Traversable.scala:104) at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:575) at org.apache.spark.sql.execution.datasources.DataSource.providingClass$lzycompute(DataSource.scala:86) at org.apache.spark.sql.execution.datasources.DataSource.providingClass(DataSource.scala:86) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:325) at org.apache.spark.sql.hive.HiveMetastoreCatalog$$anonfun$8$$anonfun$9.apply(HiveMetastoreCatalog.scala:293) at org.apache.spark.sql.hive.HiveMetastoreCatalog$$anonfun$8$$anonfun$9.apply(HiveMetastoreCatalog.scala:283) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.hive.HiveMetastoreCatalog$$anonfun$8.apply(HiveMetastoreCatalog.scala:283) at org.apache.spark.sql.hive.HiveMetastoreCatalog$$anonfun$8.apply(HiveMetastoreCatalog.scala:275) at org.apache.spark.sql.hive.HiveMetastoreCatalog.withTableCreationLock(HiveMetastoreCatalog.scala:69) at org.apache.spark.sql.hive.HiveMetastoreCatalog.org$apache$spark$sql$hive$HiveMetastoreCatalog$$convertToLogicalRelation(HiveMetastoreCatalog.scala:275) at org.apache.spark.sql.hive.HiveMetastoreCatalog$ParquetConversions$.org$apache$spark$sql$hive$HiveMetastoreCatalog$ParquetConversions$$convertToParquetRelation(HiveMetastoreCatalog.scala:371) at org.apache.spark.sql.hive.HiveMetastoreCatalog$ParquetConversions$$anonfun$apply$1.applyOrElse(HiveMetastoreCatalog.scala:388) at org.apache.spark.sql.hive.HiveMetastoreCatalog$ParquetConversions$$anonfun$apply$1.applyOrElse(HiveMetastoreCatalog.scala:379) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:290) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:290) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:289) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:307) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:307) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$3.apply(TreeNode.scala:287) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:307) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:287) at org.apache.spark.sql.hive.HiveMetastoreCatalog$ParquetConversions$.apply(HiveMetastoreCatalog.scala:379) at org.apache.spark.sql.hive.HiveMetastoreCatalog$ParquetConversions$.apply(HiveMetastoreCatalog.scala:358) at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:85) at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:82) at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124) at scala.collection.immutable.List.foldLeft(List.scala:84) at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:82) at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:74) at scala.collection.immutable.List.foreach(List.scala:381) at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:74) at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:64) at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:62) at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:48) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:63) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:600) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.VerifyError: Bad return type Exception Details: Location: org/apache/spark/sql/hive/orc/DefaultSource.createRelation(Lorg/apache/spark/sql/SQLContext;[Ljava/lang/String;Lscala/Option;Lscala/Option;Lscala/collection/immutable/Map;)Lorg/apache/spark/sql/sources/HadoopFsRelation; @35: areturn Reason: Type 'org/apache/spark/sql/hive/orc/OrcRelation' (current frame, stack[0]) is not assignable to 'org/apache/spark/sql/sources/HadoopFsRelation' (from method signature) Current Frame: bci: @35 flags: { } locals: { 'org/apache/spark/sql/hive/orc/DefaultSource', 'org/apache/spark/sql/SQLContext', '[Ljava/lang/String;', 'scala/Option', 'scala/Option', 'scala/collection/immutable/Map' } stack: { 'org/apache/spark/sql/hive/orc/OrcRelation' } Bytecode: 0x0000000: b200 1c2b c100 1ebb 000e 592a b700 22b6 0x0000010: 0026 bb00 2859 2c2d b200 2d19 0419 052b 0x0000020: b700 30b0 at java.lang.Class.getDeclaredConstructors0(Native Method) at java.lang.Class.privateGetDeclaredConstructors(Class.java:2671) at java.lang.Class.getConstructor0(Class.java:3075) at java.lang.Class.newInstance(Class.java:412) at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:380) ... 72 more >>> ^C Traceback (most recent call last): File "/export/servers/cloudera/parcels/SPARK2-2.1.0.cloudera3-1.cdh5.13.3.p0.569822/lib/spark2/python/pyspark/context.py", line 240, in signal_handler raise KeyboardInterrupt() KeyboardInterrupt >>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
6、一些其余的问题
1、livy报连不上8032端口的异常
解决方案:
找到正确的yarn-site hdfs-site core-site(可以在/etc/yarn/conf/yarn-conf下找到)拷贝到/etc/hadoop/conf下
- 1
2、Cannot run program “/etc/hadoop/conf.cloudera.yarn/topology.py” (in directory “/opt/livy-0.5.0-incubating-bin/bin”): error=2, No such file or directory
解决方案:修改/etc/hadoop/conf下core-site.xml
<property>
<name>net.topology.script.file.name</name>
<value><!--/etc/hadoop/conf.cloudera.yarn/topology.py--></value>
</property>
<property>
- 1
- 2
- 3
- 4
- 5
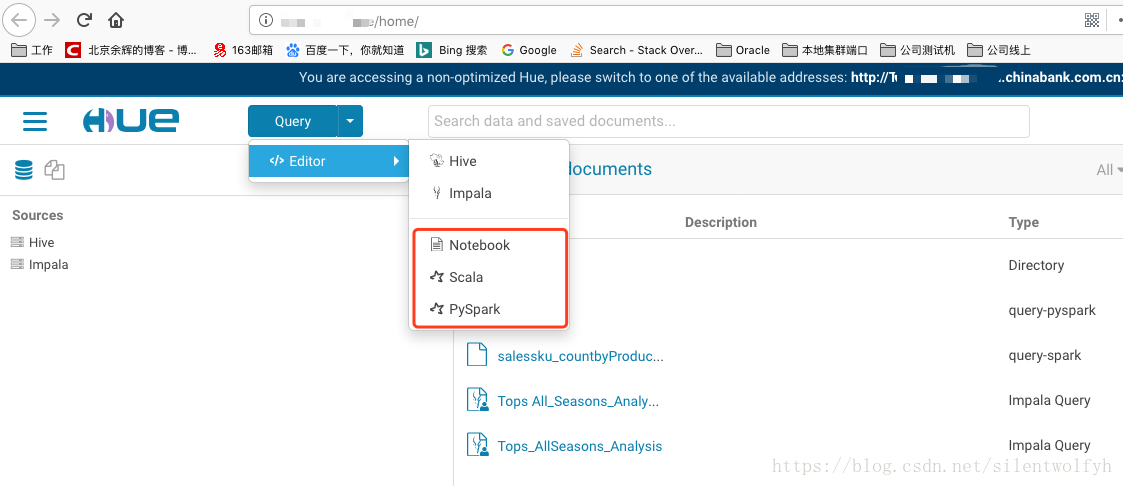
7、页面展示
配置前和配置后的对比图

7、参考文章
Run Hue Spark Notebook on Cloudera
https://blogs.msdn.microsoft.com/pliu/2016/06/18/run-hue-spark-notebook-on-cloudera/?replytocom=65#respond
https://blogs.msdn.microsoft.com/pliu/2016/06/19/run-jupyter-notebook-on-cloudera/
https://stackoverflow.com/questions/42160297/livy-pyspark-python-session-error-in-jypyter-with-spark-magic-error-repl-pytho
https://stackoverflow.com/questions/52297013/when-trying-to-use-pyspark-with-livy-i-get-pyspark-gateway-secret-error


