
- 1鸿蒙OpenHarmony【轻量系统编写“Hello World”程序】 (基于Hi3861开发板)
- 2a commit git 参数是什么意思_git commit 规范
- 3[笔记]计算机基础 3 CSAPP Lab2-BombLab_csapplab心得
- 4C++11 call_once/once_flag 使用_std::once_flag 重置方法
- 5TensorFlow和keras安装教程_keras tensorflow
- 6RK3588 Android13 鼠标风格自定义动态切换
- 7百度搜索中台海量数据管理的云原生和智能化实践
- 8Python 调用.NET类库_pythonnet
- 9STM32内部flash闪存的总结_stm32 flash存储
- 10Android 蓝牙4.0 startScan()方法搜索不到设备
详解Transformer中的Encoder_transformer模型encoder使用
赞
踩
一.Transformer架构
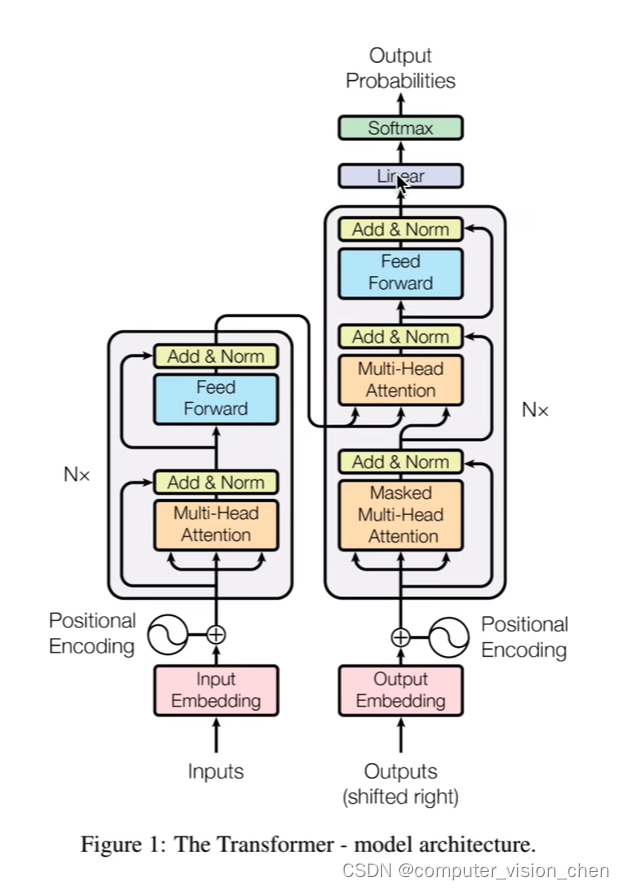
左半边是Encoder,右半边是Decoder。
二.Vision Transformer
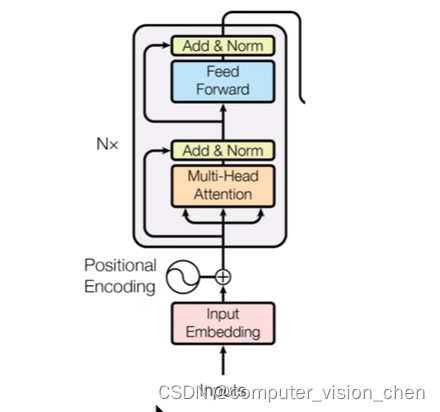
Vision Transformer取了Transformer的左半边。包含
- Input Embedding
- Positional Encoding
- 多头注意力机制 + Add & Norm
- (前馈网络)Feed Forward + Add & Norm
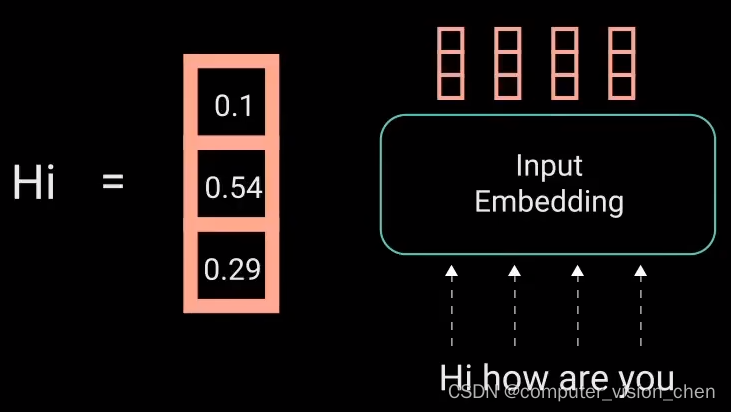
2.1 Input Embedding
2.2 Positional Encoding
- 为什么需要位置编码?
Transformer替代的是RNN(循环神经网络),RNN本身是一种训练网络,天然包含句子之间的位置信息,Tranformer用attention替代了RNN,所以就缺乏位置信息。模型没有办法知道每个单词在句子中的相对位置和绝对位置。
- 具体实现方法是:
每个奇数时间步,使用余弦函数创建一个向量。

- 偶数时间步,使用正弦函数创建向量
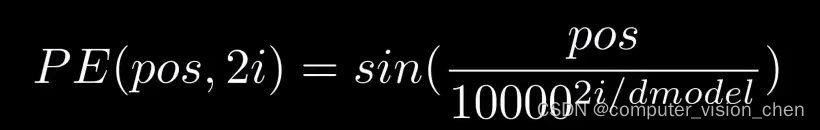
然后将这些向量添加到相应的嵌入向量中。
这样就成功了为网络提供了每个向量的信息。选用正弦和余弦函数,是因为他们有线性特性。
2.3 多头注意力机制
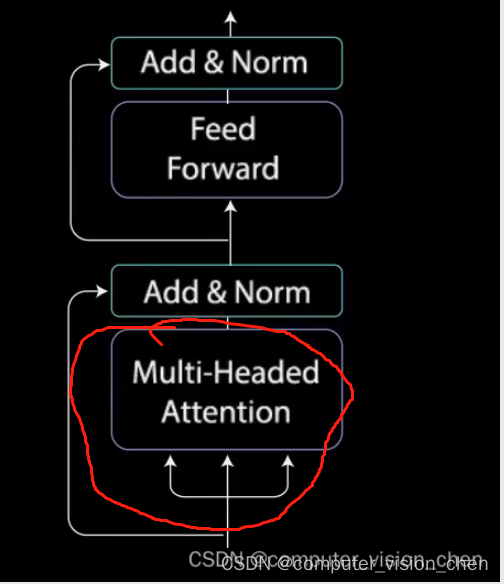
它的内部如下:
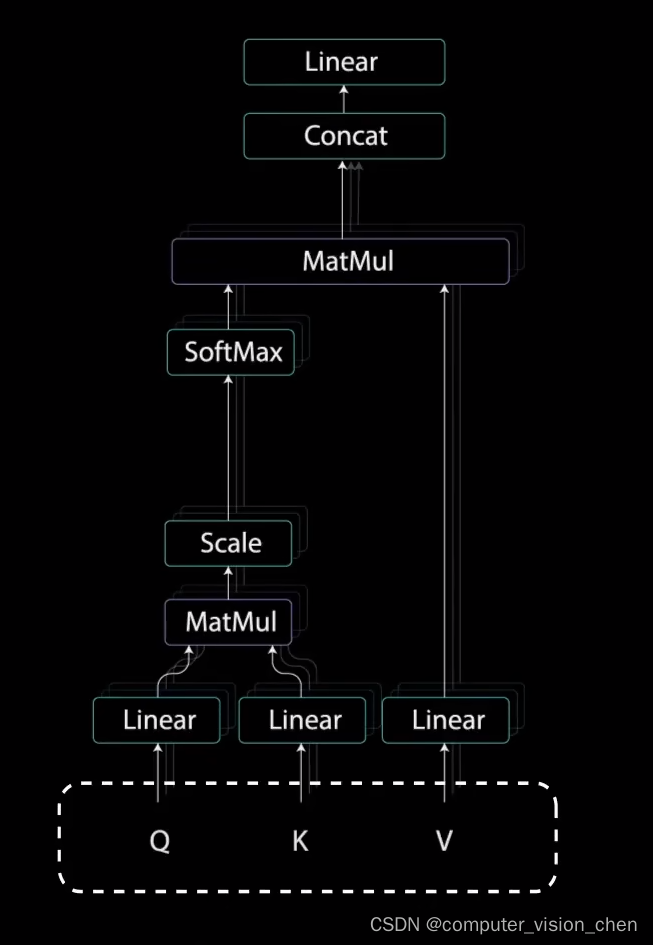
多头注意力机制是多个自注意力。
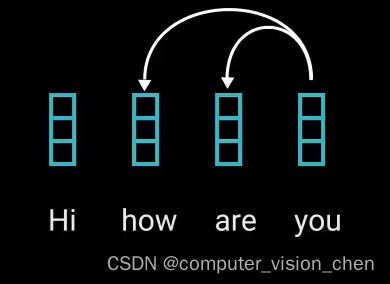
多头注意力模块运用了自注意力,自注意力机制可将输入的每个单词和其它单词关联起来。
比如:模型将You与How 和 are联系起来。
1. 自注意力机制中的Q,K,V
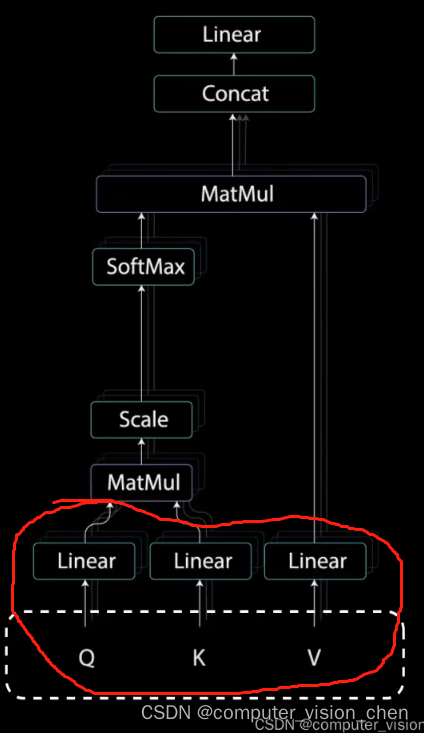
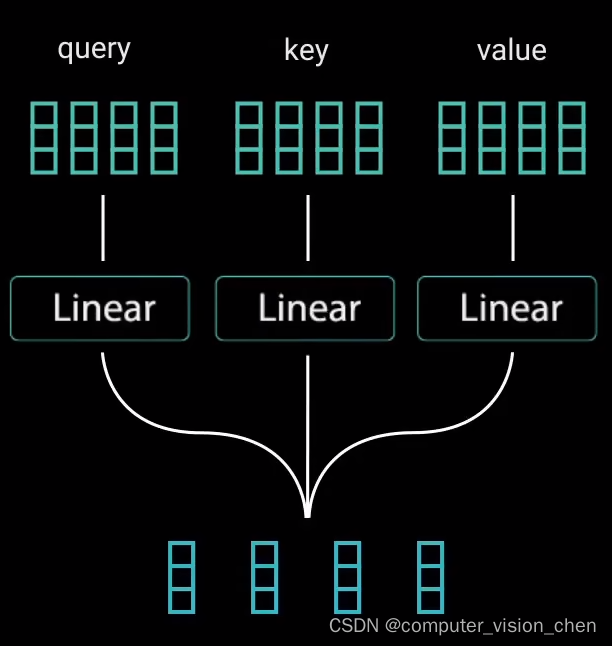
为了实现自注意力,将输入分别输入到三个不同的全连接层,来创建查询向量、键向量、值向量。
查询向量、键向量、值向量来自检索系统,
Q:例如当在youtube上输入一个查询词Q,搜索某个视频。
K:搜索引擎将你的查询值映射到一组键K中(如视频标题,视频描述)。
V:与数据库的候选视频相关联。
2. 自注意力机制中的第一个MatMul
查询和键经过点积矩阵乘法产生一个分数矩阵。分数矩阵确定了一个单词应该如何关注其它单词。
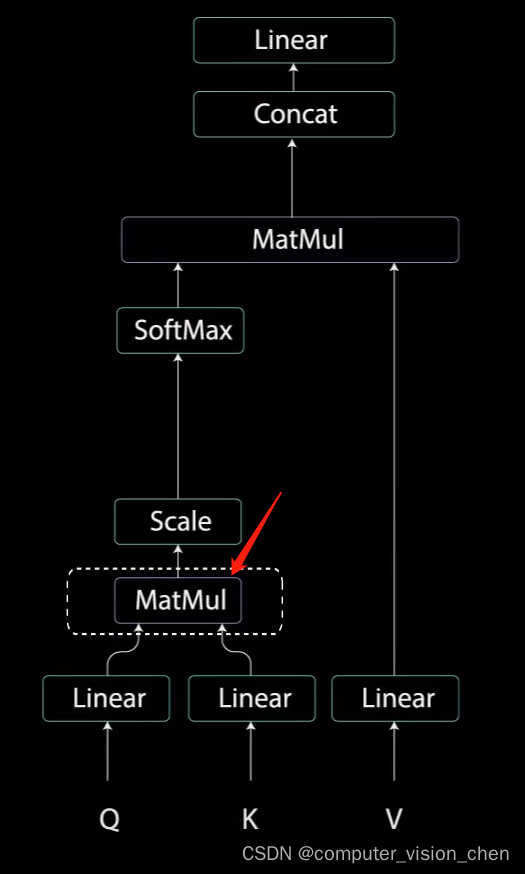
(MatMul)点乘获得分数矩阵:
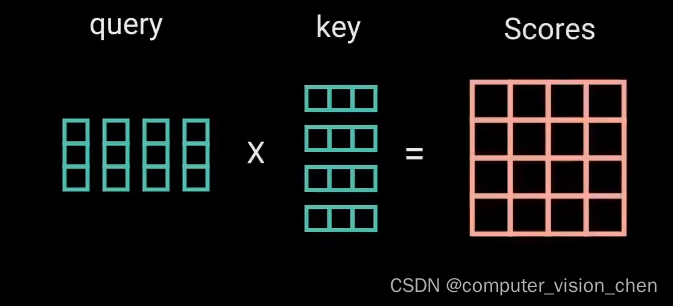
分数矩阵确定一个单词应该如何关注其它单词。

每个单词都会有一个与时间步长中的其他单词相对应的分数。分数越高,关注度越高。这就是查询如何映射到键的。
3.缩放
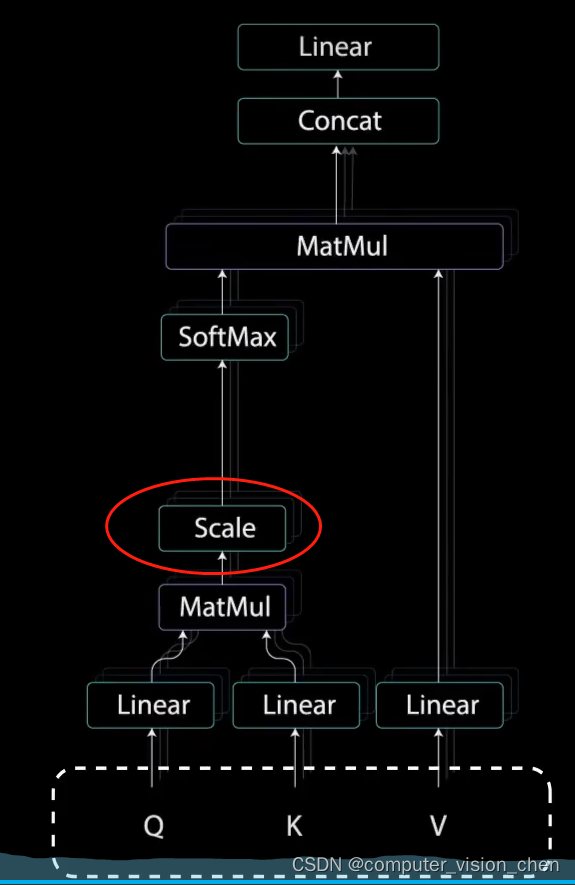

将查询和键的维度开平方将得分缩放,因为这样可以让梯度更稳定,因为乘法可能会产生爆炸效果。
4. softmax
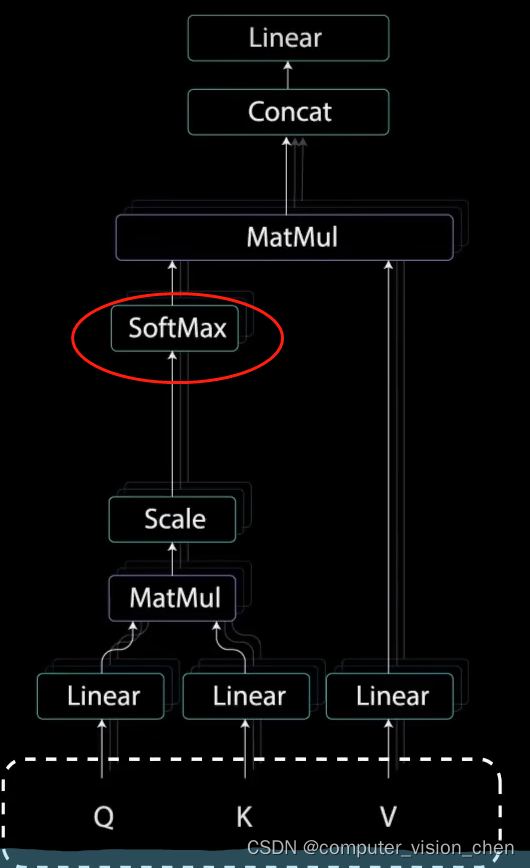
对缩放后的得分进行softmax计算,得到注意力权重,进行softmax计算后,较高的得分会得到增强,较低的得分得到抑制。

得到的是注意力权重。
5. 第二个MatMul操作
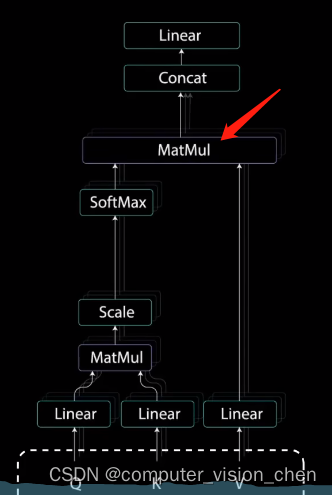
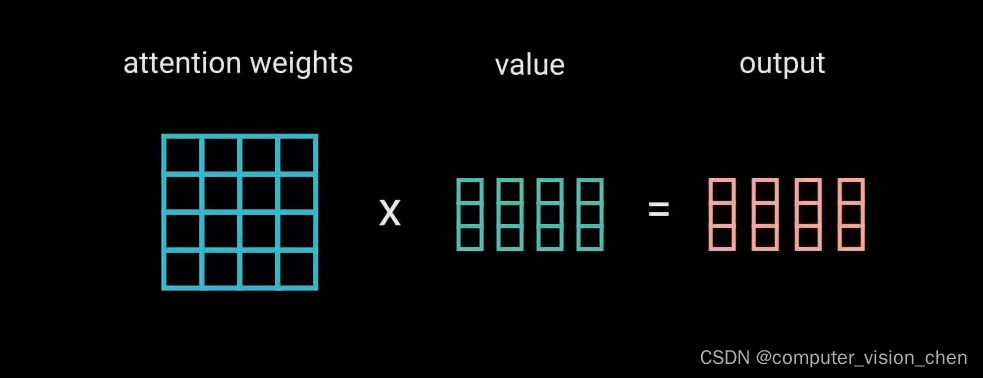
将注意力权重 和 值向量相乘。得到输出向量。
6. concat层
为了使这个计算成为多头注意力计算,在应用自注意力之前将查询、键、值分成N个向量。分割后的向量分别经过相同的自注意力,每个自注意力过程称为一个头,每个头产生一个输出向量。这些向量经过最后的线性层之前被拼接成一个向量。
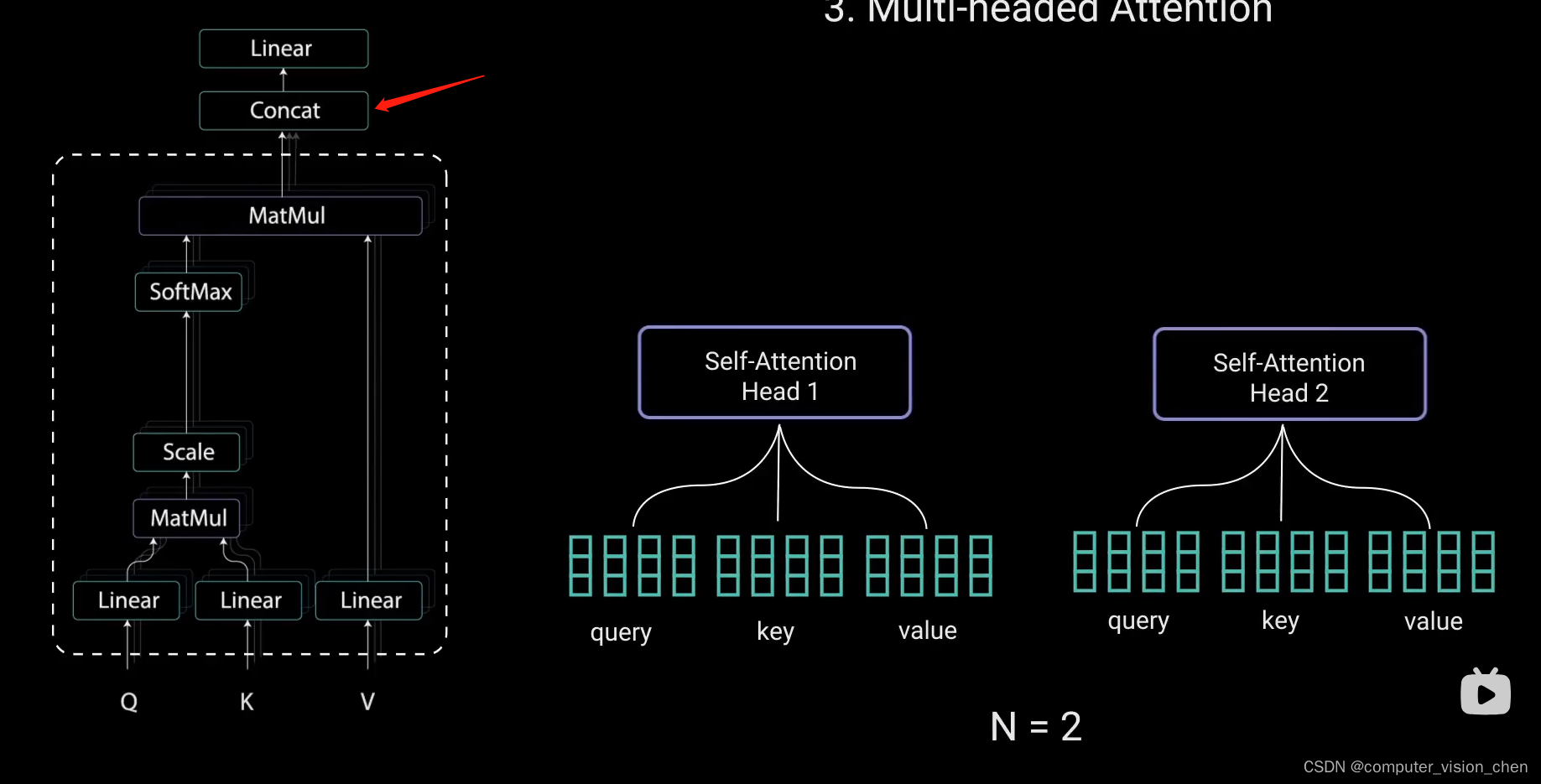
理论上,每个头都会学到不同的东西。从而为编码器模型提供更多的表达能力。
7.多头注意力机制总结
多头注意力是一个模块,用于计算输入的注意力权重,并生成一个带有编码信息的输出向量,指示序列中每个词应该如何关注其它所有词。
8.多头注意力机制后的Add & Norm
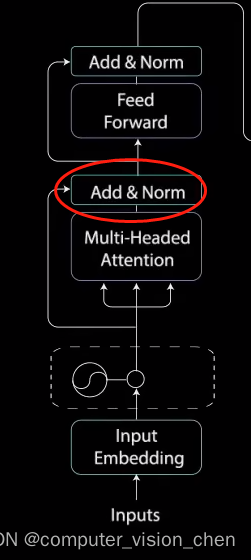
接下来,使用残差连接,将多头注意力机制输出向量,加到原始输入上。
2.4 前馈网络 + Add & Norm
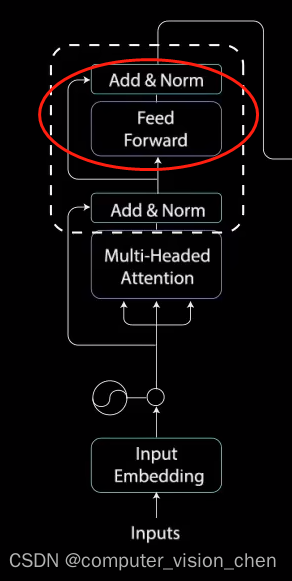
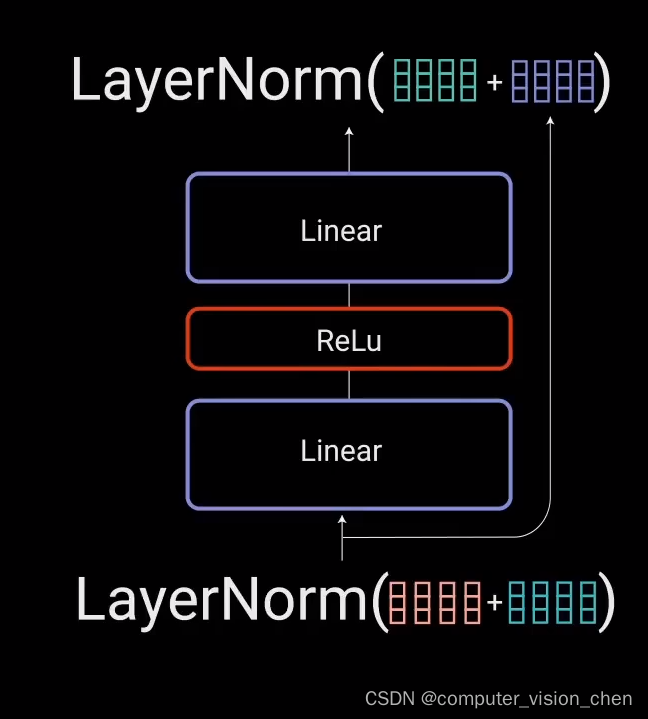
残差连接的输出经过层归一化(LayerNorm)。归一化后的残差输出被送入点对点前馈网络进行进一步处理。点对点前馈网络是几个线性层,中间有ReLu激活函数。
残差连接有助于网络训练,因为它允许梯度直接流过网络。
使用层归一化来稳定网络,显著减少所需训练时间。
最后:
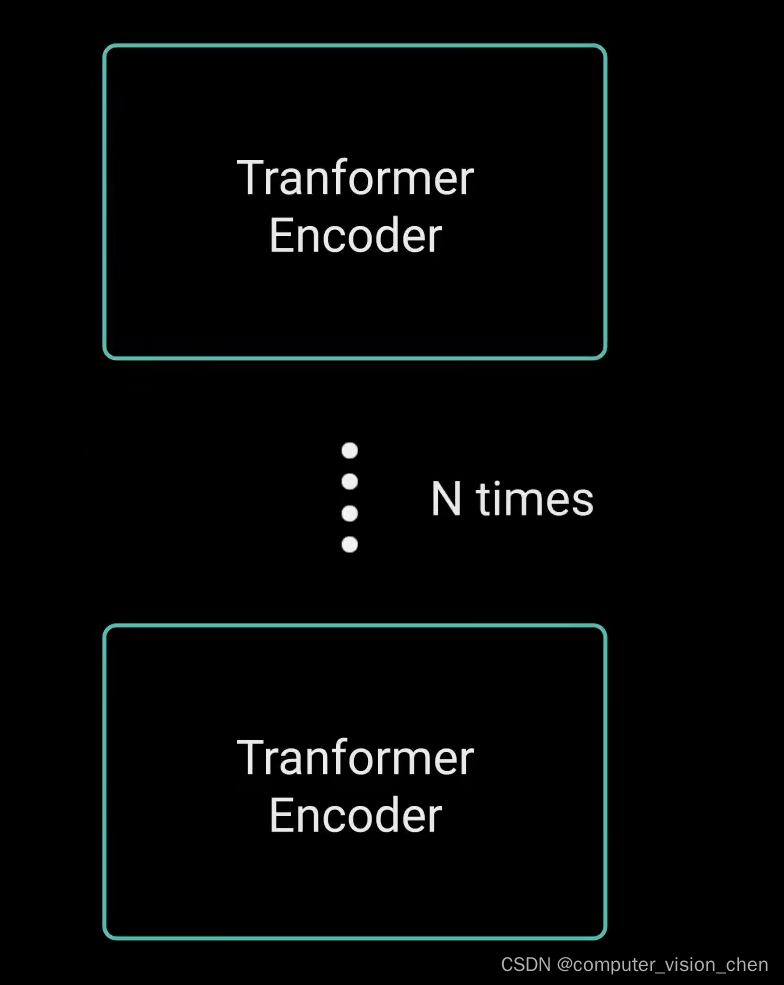
可将编码器堆叠n次,以进一步编码信息。其中每一层都有机会学习不同的注意力表示。从而有可能提高transformer网络的预测能力。
参考
超强动画,一步一步深入浅出解释Transformer原理!
https://www.bilibili.com/video/BV1ih4y1J7rx/?spm_id_from=333.999.top_right_bar_window_history.content.click&vd_source=ebc47f36e62b223817b8e0edff181613

