
- 1动力电池系统介绍(十)——电压采样_bms采集精度测试
- 2安全可信 | 安全与高效兼得?天翼云EasyCoding敏捷开发平台来了!
- 3java常见算法篇【完整版】_java 算法
- 4如何写.bat批处理文件_写一个批处理文件(.bat),将系统属性信息保存在c盘根目录的mysysteminfo.txt文件中
- 5Linux 下使用tar.gz安装mysql5.7_mysql-5.7.43-linux-glibc2.12-x86_64.tar.gz
- 6ChatGLM-6B+LangChain实战_langchain+chatglm
- 7Leetcode 126. Word Ladder II_a transformation sequence from word beginword to w
- 8编译系统包Settings_单编settings
- 9CSerialPort教程4.3.x (5) - CSerialPort在cmake中的使用_vs安装cserialport库
- 10在Amazon SageMaker平台使用HuggingFace Diffusers快速部署Stable Diffusion模型
llama-factory SFT系列教程 (一),大模型 API 部署与使用
赞
踩
背景
本来今天没有计划学 llama-factory,逐步跟着github的文档走,发现这框架确实挺方便,逐渐掌握了一些。
最近想使用 SFT 微调大模型,llama-factory 是使用非常广泛的大模型微调框架;
简介
基于 llama_factory 微调 qwen/Qwen-7B,qwen/Qwen-7B-Chat
我使用的是 qwen/Qwen-7B,如果追求对话效果qwen/Qwen-7B-Chat的效果会好一点;
本系列的主要工作如下:
- 大模型 api 部署;直接部署开源大模型体验一下;
- 增加自定义数据集;为实现SFT准备数据;
- 大模型 lora 微调;
- 原始模型 + 微调后的lora插件,完成 api 部署;
使用 llama_factory 的 API 部署有 vllm加速推理;
文章目录:
- llama-factory SFT系列教程 (一),大模型 API 部署与使用
- llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
- llama-factory SFT系列教程 (三),chatglm3-6B 命名实体识别实战
难点
可能遇到的一些难点:
llama_factory 默认从 Huggingface下载模型,要改为从modelscope下载模型权重;
前置条件
llama_factory 装包
git clone https://github.com/hiyouga/LLaMA-Factory.git
# conda create -n llama_factory python=3.10
# conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
- 1
- 2
- 3
- 4
- 5
If you have trouble with downloading models and datasets from Hugging Face, you can use ModelScope.
export USE_MODELSCOPE_HUB=1 # `set USE_MODELSCOPE_HUB=1` for Windows
- 1
linux 在 ~/.bashrc 中 添加 export USE_MODELSCOPE_HUB=1, source .bashrc 激活,达到重启电脑也生效;
1. 大模型 api 部署
虽然我执行了这条语句 export USE_MODELSCOPE_HUB=1 以为切换到 modelscope的下载源了;
但是 填写模型名称 --model_name_or_path qwen/Qwen-7B,还是会从 huggingface下载模型权重;于是我填写本地绝对路径的方式;
下载模型权重:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B')
model_dir
- 1
- 2
- 3
- 4
输出模型的下载地址如下:
/mnt/workspace/.cache/modelscope/qwen/Qwen-7B
切换目录到刚才从github下载的 llama-factory 文件夹
cd LLaMA-Factory
- 1
执行 API 部署脚本,本文选择 api 而不是网页,因为API的用途更广,可供python程序调用,而网页只能与用户交互。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 python src/api_demo.py \
--model_name_or_path /mnt/workspace/.cache/modelscope/qwen/Qwen-7B \
--template qwen
--infer_backend vllm
--vllm_enforce_eager
- 1
- 2
- 3
- 4
- 5
可以注意到 LLaMA-Factory 在模型推理时,使用了 vllm 加速;
不出意外的话,经过一段时间的模型权重加载,看到下述图片展示的状态时,那么 API 便部署成功了;

现在如何给 API 接口传参呢?是不是有点不知所措!
不用急,在图片的红框中,笔者已经给大家标出来了,http://localhost:8000/docs便是API 的接口文档说明;
有同学会说:“我使用的云端服务器,而且还没有公网 ip,我该那怎么访问这个文档呢?”
笔者:直接点击便可访问,该文档做了内网穿透;
比如,我点击后,弹出了如下页面:https://dsw-gateway-cn-beijing.data.aliyun.com/dsw-70173/proxy/8000/docs
该 API 的文档页面如下图所示:
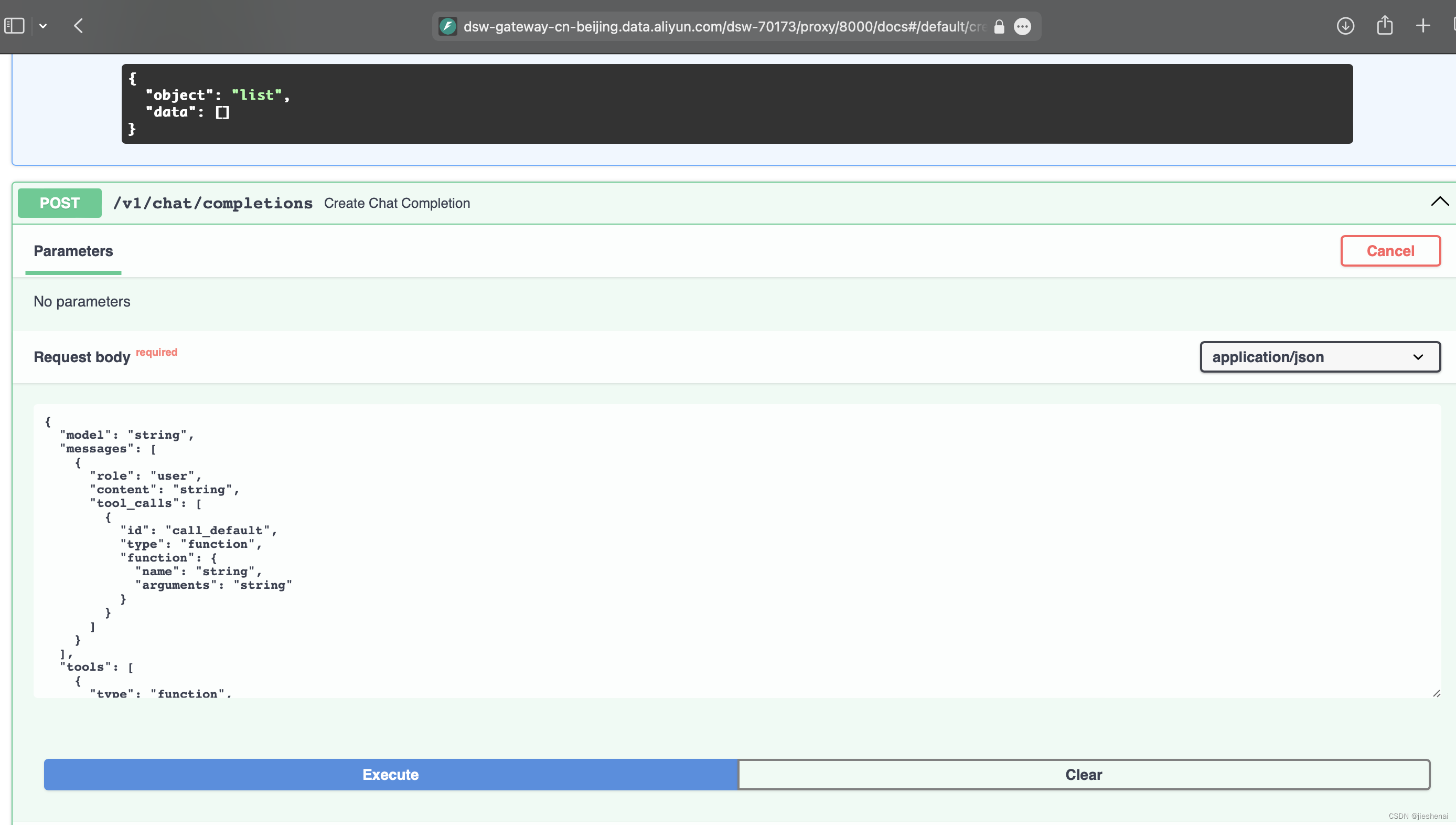
下述是官方给的请求体参数
{ "model": "string", "messages": [ { "role": "user", "content": "string", "tool_calls": [ { "id": "call_default", "type": "function", "function": { "name": "string", "arguments": "string" } } ] } ], "tools": [ { "type": "function", "function": { "name": "string", "description": "string", "parameters": {} } } ], "do_sample": true, "temperature": 0, "top_p": 0, "n": 1, "max_tokens": 0, "stream": false }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
笔者把下述的请求保存在 1.sh 文件中,因为下述请求体太长了,在sh文件中进行编辑方便一点;
curl -X 'POST' \ 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "string", "messages": [ { "role": "user", "content": "你能帮我做一些什么事情?", "tool_calls": [ { "id": "call_default", "type": "function", "function": { "name": "string", "arguments": "string" } } ] } ], "tools": [ { "type": "function", "function": { "name": "string", "description": "string", "parameters": {} } } ], "do_sample": true, "temperature": 0, "top_p": 0, "n": 1, "max_tokens": 128, "stream": false }'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
执行 bash 1.sh 便可获得大模型生成的回答了;

在 API 文档中,还有其他的接口,请读者自行探索。
下一步阅读
llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
包含如下内容:
- 增加自定义数据集;为实现SFT准备数据;
- 大模型 lora 微调;
- 原始模型 + 微调后的lora插件,完成 api 部署;


