
- 1Android 开发中的SSL pinning_ssl pinning 抓包
- 2python-flask结合bootstrap实现网页小工具实例-半小时速通版
- 3大数据编程实验二:熟悉常用的HDFS操作_熟悉常用的hdfs操作。
- 4java使用字节流对文件进行读写操作_java字节流读取文件
- 5SAP ABAP 业务对象 BUS6038 AssetDownPayment 资产:预付款 BAPI 清单和相关 TCODE_sap downpayment
- 6实用图像视频修复工具:完善细节、提高分辨率 | 开源日报 No.225
- 7ChatGPT怎样用?批量生产短视频攻略_chart gpt短视频
- 8OpenCV实例(八)车牌字符识别技术(三)汉字识别_opencv汉字识别
- 9【多个ssh连接github】_github多个sshkey
- 10sql server 2012导出mdb文件或者.accdb文件扩展名_sqlserver导出mdb文件
异步联邦学习①-FedASMU
赞
踩
FedASMU: Efficient Asynchronous Federated Learning with Dynamic Staleness-aware Model Update
摘要
作为一种处理分布式数据的有前途的方法,联合学习近年来取得了重大进展。FL通过利用分散在多个边缘设备中的原始数据来实现协作模型训练。然而,数据通常是非依赖和同分布的,即统计异质性,边缘设备在计算和通信能力方面存在显著差异,即系统异质性。统计异质性导致精度严重下降,而系统异质性显著延长了训练过程。为了解决异构性问题,我们提出了一个异步陈旧感知模型更新FL框架,即FedASMU,它有两种新的方法。首先,我们提出了一种异步FL系统模型,该模型在服务器上使用更新的局部模型和全局模型之间的动态模型聚合方法,以获得更高的精度和高效性。然后,我们提出了一种自适应的局部模型调整方法,通过将新的全局模型与设备上的局部模型聚合来进一步提高精度。对6个模型和5个公共数据集的广泛实验表明,FedASMU在准确性(提高0.60%至23.90%)和效率(提高3.54%至97.98%)方面显著优于基线方法。
贡献:
在本文中,我们提出了一个具有过时感知模型更新的异步联合学习框架(FedASMU)。为了解决系统的异构性,我们设计了一个异步FL系统,并提出了一种动态调整方法来更新基于过时性和局部损失的局部模型和全局模型的重要性,以获得更高的精度和效率。我们使设备能够自适应地聚合新的全局模型,以减少局部模型的陈旧性。我们将本文的主要贡献总结如下:
•我们提出了一种新的异步FL系统模型,该模型在服务器上采用动态模型聚合方法,根据过时性和局部损失的影响调整更新的局部模型和全局模型的重要性,以获得更高的准确性和高效性。
•我们在设备上提出了一种自适应的局部模型调整方法,将新的全局模型集成到局部模型中,以减少老化,获得卓越的精度。模型调整包括选择适当时隙来检索全局模型的强化学习(RL)方法和调整局部模型聚合的动态方法。
系统模型:
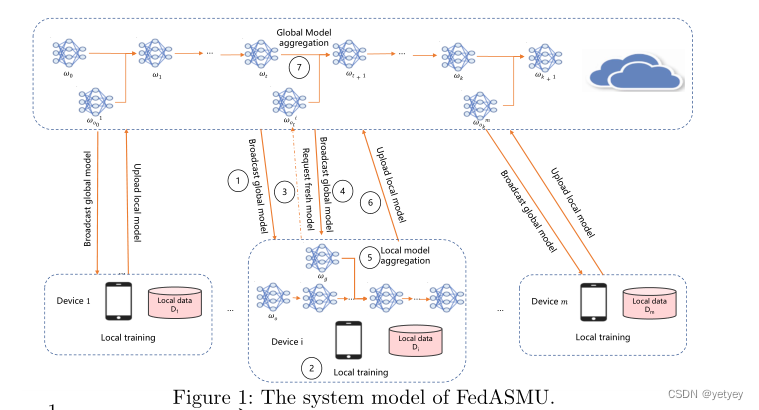
服务器以恒定的时间周期T触发m’设备的本地训练。培训过程由多轮全球培训组成。在训练开始时,全局模型的版本为0。然后,在每个全局回合之后,全局模型的版本增加1。每个全局回合由7个步骤组成。
①服务器触发m′(m′≤m)个设备,并向每个设备广播全局模型wo。m’设备是随机选择的可用设备。
②每个设备使用其本地数据集执行本地训练。
③在本地训练过程中,设备i请求新的全局模型以减少局部训练的陈旧性,因为全局模型可以同时更新。
④服务器将全局模型wg发送到设备,
⑤如果wg比wo新,即g>o。在接收到新的全局模型之后,设备将全局模型和最新的局部模型聚合为新模型,并使用新模型继续进行本地训练。
⑥当本地训练完成时,设备i将本地模型上传到服务器。
⑦最后,服务器将最新的全局模型wt与上传的模型聚合。当聚合全局模型wt和上传的局部模型
时,局部模型的稳健性计算为τi=t−o+1。当陈旧性τi显著时,局部模型可能会将全局模型拖到先前版本,该版本对应于由于遗留信息而导致的较差精度。当陈旧性超过预定义阈值τ以满足陈旧性界时,我们丢弃上传的局部模型,以确保收敛。
动态过时感知模型聚合方法(⑦)
服务器上的动态模型更新
当服务器从设备i接收到原始版本为o的上传模型时,它根据以下公式更新当前全局模型wt:
![]() ,其中
,其中表示从设备i上传的模型在全局第t轮的重要性,这可能对聚合模型的准确性产生重大影响。将
![]() 定义的问题分解为:
定义的问题分解为: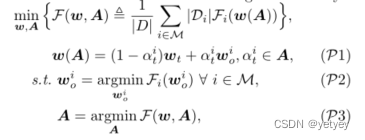 ,其中
,其中![]() 是与从设备上传的模型的重要性相对应的一组值。问题P2是局部损失函数的最小化。提出了一个动态多项式函数来表示问题P3的公式2中定义的α。
是与从设备上传的模型的重要性相对应的一组值。问题P2是局部损失函数的最小化。提出了一个动态多项式函数来表示问题P3的公式2中定义的α。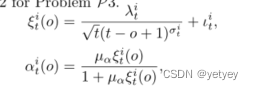 ,
,
µα表示超参数,t−o+1表示陈旧性,t表示当前全局模型的版本,o对应于设备i在局部训练之前接收的全局模型版本,λit、σit和ι是设备i在第t次全局循环中的控制参数。这三个参数根据公式3进行动态调整,以减少全局模型的损失。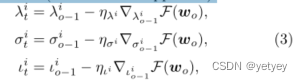 ,其中ηλi、ησi和ηιi表示动态调整的相应学习率,
,其中ηλi、ησi和ηιi表示动态调整的相应学习率,![]()
![]() 对应于损失函数的相应偏导数。
对应于损失函数的相应偏导数。
FedASMU在服务器上的模型聚合算法如算法1所示。
当执行训练的设备数量小于预定义数量时,分离的线程周期性地触发m’个设备值(第1-6行)。当服务器收到wio(第8行)时,它会验证上传的模型是否在过时范围内(第9行)。否则,服务器将忽略wio(第10行)。否则,服务器根据公式3(第12行)更新控制参数λit、σit、ιit,并根据公式2(第13行)计算αit。之后,服务器更新全局模型(第14行)。

设备上的自适应局部模型调整方法(③,⑤)
我们提出了一种自适应局部模型调整方法的局部训练过程设备来解决问题P2。
当设备i被触发执行本地训练时,它从服务器接收全局模型wo并将其作为初始本地模型wo,0。在局部训练过程中,利用随机梯度下降(SGD)方法基于公式4中定义的局部数据集Di更新局部模型。![]() ,其中,o是全局模型的版本,l表示局部历元的数量,ηi表示设备i上的学习率,而对应于基于Di的无偏采样小批量的梯度。
,其中,o是全局模型的版本,l表示局部历元的数量,ηi表示设备i上的学习率,而对应于基于Di的无偏采样小批量的梯度。
为了减少局部模型和全局模型之间的差距,我们建议在设备的局部训练过程中将新的全局模型与局部模型聚合。在局部训练期间,全局模型可以同时被集中更新。因此,使用新的全局模型进行模型聚合可以很好地缩小局部模型和全局模型之间的差距。然而,确定发送请求的时隙和聚合新的全局模型的权重是复杂的。在本节中,我们首先提出了一种强化学习(RL)方法来选择合适的时隙。然后,我们解释了动态局部模型聚合方法。
智能时隙选择
我们提出了一种基于RL的智能时隙选择器来选择合适的时隙来向服务器请求新的全局模型。为了减少通信开销,我们假设在本地训练期间只接收到一个新的全局模型。当请求提前发送时,服务器很少执行更新,最终更新的本地模型可能仍然严重过时。然而,当请求发送较晚时,本地更新无法利用来自新的全局模型的信息,这对应于较差的准确性。因此,选择合适的时隙来发送请求是有益的。
智能时隙选择器由服务器上的元模型和每个设备上的本地模型组成。元模型为每个设备生成初始时隙决策,并在设备执行第一次本地训练时更新。本地模型用初始时隙初始化,并在接下来的本地训练期间在设备内更新,以为新的全局模型请求生成个性化的适当时隙。我们开发了一种基于长短期记忆(LSTM)的网络,该网络具有用于元模型的完全连接层和用于每个局部模型的Q学习方法)。元模型和局部模型都生成每个时隙的概率。我们采用了贪婪策略来进行选择。
在局部训练过程中,我们将奖励定义为模型聚合前和聚合后的损失值之间的差异。例如,在将新的全局模型与l*个局部历元之后发送的请求聚合之前,![]() 的损失值为
的损失值为![]() ,在聚合之后为
,在聚合之后为![]() 。那么,奖励R是
。那么,奖励R是![]() 。一旦进行了初始聚合,我们就用公式5更新了LSTM模型。
。一旦进行了初始聚合,我们就用公式5更新了LSTM模型。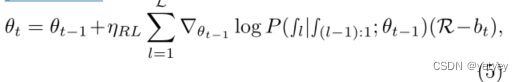 其中,θt表示第t次元模型更新后元模型中的参数,ηRL表示RL训练过程的学习率,L是局部历元的最大数量,ŞL对应于第L个局部历元后发送请求(1)或不发送请求(0)的决定,bt是减少模型偏差的基值。该模型使用一些历史数据进行预训练,并在每个设备上的FedASMU训练过程中动态更新。Q学习方法管理设备i上的决策和奖励之间的映射Hi,该映射用历史值和奖励的加权平均值更新,如公式6所示。
其中,θt表示第t次元模型更新后元模型中的参数,ηRL表示RL训练过程的学习率,L是局部历元的最大数量,ŞL对应于第L个局部历元后发送请求(1)或不发送请求(0)的决定,bt是减少模型偏差的基值。该模型使用一些历史数据进行预训练,并在每个设备上的FedASMU训练过程中动态更新。Q学习方法管理设备i上的决策和奖励之间的映射Hi,该映射用历史值和奖励的加权平均值更新,如公式6所示。 其中ati−1表示操作,l*ti−1表示在内发送请求的本地历元数,第(ti−1)个局部模型的聚集,ξ和ψ是超参数。动作在动作空间内,即
其中ati−1表示操作,l*ti−1表示在内发送请求的本地历元数,第(ti−1)个局部模型的聚集,ξ和ψ是超参数。动作在动作空间内,即![]() ,其中add表示将1个历元添加到l
,其中add表示将1个历元添加到l![]() ,stay表示与同一历元保持一致
,stay表示与同一历元保持一致![]() ;minus表示从l*ti-1中删除1个历基(
;minus表示从l*ti-1中删除1个历基(![]() 。
。
动态局部模型聚合
当接收到新的全局模型wg时,设备i利用公式7对其当前局部模型![]() 执行局部模型聚合。
执行局部模型聚合。![]()
其中,![]() 是第(ti−1)个局部全局模型聚合时设备i上的新全局模型的权重。公式7不同于公式1,因为接收到的新全局模型对应于更高的全局版本。我们利用公式8来计算
是第(ti−1)个局部全局模型聚合时设备i上的新全局模型的权重。公式7不同于公式1,因为接收到的新全局模型对应于更高的全局版本。我们利用公式8来计算![]() 。
。
式中µβ为超参数,γiti−1和υiti−2为控制参数,根据公式9进行动态调整。
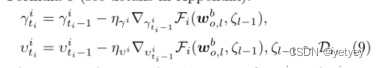 其中
其中![]() 是
是![]() 的学习率。
的学习率。
FedASMU在设备上的模型更新算法如算法2所示。首先,当t=1时基于θt−1或当t̸=1时基于![]() (第1行)生成用于发送对新的全局模型的请求的历元编号l*(时隙)。在第l个本地历元中,设备向服务器发送请求(第5行),并等待新的全局模型(第6行)。在收到新的全局模型(第8行)后,我们利用公式8来更新
(第1行)生成用于发送对新的全局模型的请求的历元编号l*(时隙)。在第l个本地历元中,设备向服务器发送请求(第5行),并等待新的全局模型(第6行)。在收到新的全局模型(第8行)后,我们利用公式8来更新(第9行),公式7来更新
(第一行10),公式9来更新
和
(一行11),奖励值(第12行),bt−1,ρ是超参数(第13行),θt当t=1时,或
当t̸=1时(第14行)。
最后,更新本地模型(第16行)。

结论:提出了一种新的异步状态感知模型更新FL框架,即FedASMU,该框架具有异步系统模型和两种新方法,即服务器上的动态模型聚合方法和设备上的自适应局部模型调整方法。

