
- 1python-机器学习常见数据集之wave,iris,wine,boston,虚拟数据集,及数据划分方法_swirski数据集
- 2黑马SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式学习笔记_黑马程序员springcloud笔记rabbitmq
- 3Linux通过wget下载civitai下载模型_civitai模型下载
- 4Go 语言 map 是并发安全的吗?_golang map并发安全
- 5mac如何彻底卸载Conda_mac 卸载conda
- 62024年泰迪杯数据挖掘B题详细思路代码文章教程_泰迪杯2024数据
- 7「 网络安全常用术语解读 」漏洞利用交换VEX详解
- 8mysql case多个关键字 使用and 或者in()_mysql case in
- 9若依框架集成sharding-jdbc_若依 sharding-jdbc
- 10Studio One 6 永久激活版+Studio One 6 注册机安装教程
图谱实战 | 多模态知识图谱构建案例
赞
踩
转载公众号 | 图谱学苑
01
背景介绍
现有的知识图谱大多是以单一的文本的形式表示,而多模态知识图谱会将文本信息和图像等其他模态的信息综合起来。
多模态知识图谱主要分为两种表现形式,其一是将多模态信息作为实体的属性,另一种是将多模态信息作为单独的实体。
多模态知识图谱目前也有较多的应用,针对知识图谱本身而言,它可以提供额外的多模态信息,以便进行连接预测等任务,而针对下游任务而言,可以据此进行视觉问答、图文匹配等。
本文将介绍四篇多模态知识图谱构建的相关论文,涉及到的方法主要分为两类,即根据多模态文档构建(GAIA、RESIN)和根据搜索引擎获取的图像构建(MMKG、Richpedia)。
02
GAIA
GAIA系统的结构如下,主要由文本知识抽取分支、视觉知识抽取分支和跨媒体知识融合模块构成。两个分支由相同的多模态文档集(比如有图片或视频又有文本的新闻)作为输入、都使用了DARPA AIDA本体中的相同类型,以便在跨媒体知识融合模块进行合并。
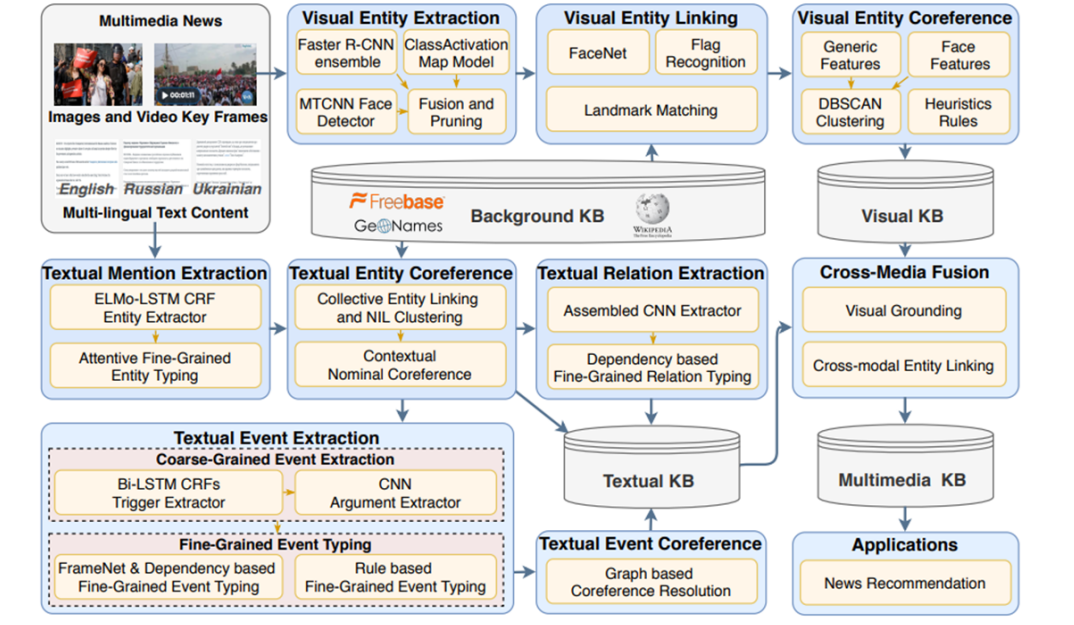
文本知识抽取分支
文本知识抽取分支由常规的文本实体抽取、关系抽取、事件抽取等模块构成。
对于可链接到同一背景知识图谱实体的提及,会添加共指信息。对于无法链接到知识图谱的提及,会使用启发式的规则将其聚成NIL簇(NIL簇是指提及同一实体但没有相应知识图谱条目的实体提及簇)。
此外,GAIA为每篇文档中的每个实体分配了一个显著性得分。如果该实体以名称的形式提及,则显著性会更高,以名词或代词的形式提及,则显著性会变低。每个文档中的所有实体的显著性得分会进行归一化处理。
视觉知识抽取分支
视觉知识抽取分支通过目标检测等模型生成检测框,以此进行实体抽取。特别地,GAIA单独使用人脸检测器MTCNN,并将结果作为额外的人物实体。
视觉实体连接过程中,模型尝试将每个实体与背景知识图谱中的实体联系起来。为每种粗粒度实体类型开发了不同的模型。对于人类型的实体,训练了一个FaceNet模型。对于位置、设施和组织实体,使用了预训练好的DELF模型。为了识别地缘政治实体,训练了CNN识别国旗,并将其归入预定的国家实体列表。如果在图像中检测到了国旗,会应用一套启发式规则,在知识图谱中创建某些实体与检测到的国家之间的国籍隶属关系。例如,一个手持乌克兰国旗的人将隶属于乌克兰。
视觉实体共指消解的过程中,使用聚类算法将检测框的内容聚成NIL簇,对于链接到同一真实世界实体的检测框,也添加共指信息。
跨媒体知识融合模块
使用视觉定位的方法来实现文本和视觉知识图谱的合并。GAIA将文本中的每个实体的提及与其周围图像进行比较,得出每张图片的相关性得分,以及每张图片中相关性热图。对于相关性足够高的图像,对热图进行阈值化处理,以获得一个检测框,将该检测框内容匹配到已知的视觉实体上。如果找不到对应的实体,就以此创建一个新的视觉实体。最后,将对应的文本实体和视觉实体连接起来。
评估
对系统中每个单独模块的评估结果如下:
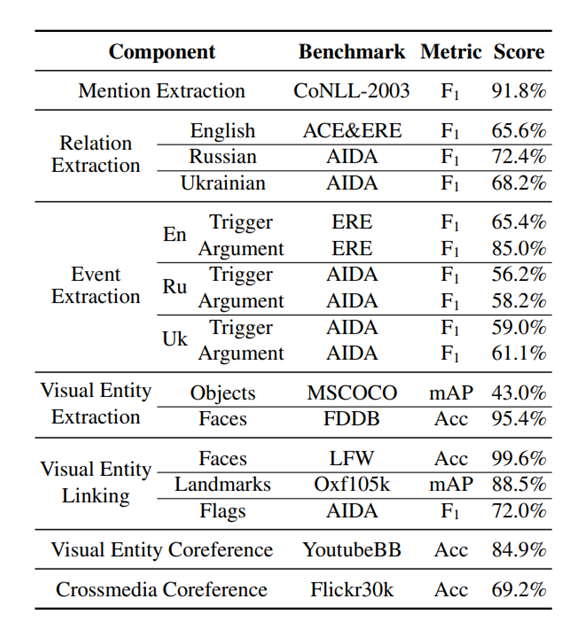
为了衡量端到端的效果,GAIA参加了TAC SMKBP 2019评估,系统根据语料库构建多模态知识图谱,并根据构造的知识图谱中对类查询和图查询的响应情况对系统性能进行了评估,结果如下:

03
Resin
Resin系统结构如下,与GAIA类似,也有文本分支和视觉分支,Resin通过视觉和文本共指实现两个分支的合并。此外,通过模式匹配模块将构造的知识图谱与模式库中合适的模式融合。
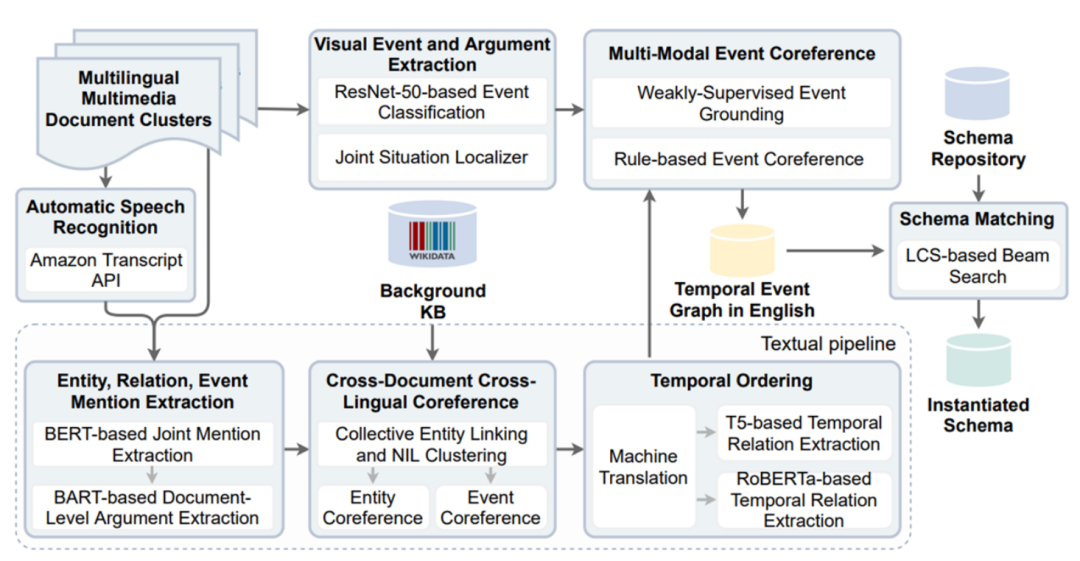
文本通道
对于多模态文档当中的语音,Resin使用Amazon Transcribe API将其转换为文本,后续当作文本信息处理。使用OneIE对文本进行句子级别的实体、关系、事件联合抽取,然后将实体提及链接到WikiData。由于事件抽取中,很多信息是跨句子的,所以文章还开发了文档级事件抽取模型,并把两个模型的结果合并作为最终输出。
对于抽取出的事件,Resin会根据文本中的前后关键词或者明确的日期和时间提及,对文档中的所有事件提及对进行先后排序。
视觉通道
视觉事件和论元的抽取由事件分类和论元抽取模型构成,对于视频数据,以秒进行采样,并将其作为单个图像处理。
视觉和文本共指
对于检测到事件的视频帧,训练弱监督的模型找到与之相似的句子。然后采用基于规则的方法来确定视觉事件提及和文本事件提及是否共指,其标准为:
•它们的事件类型相匹配。
•不同模态中同一论据角色的实体类型没有矛盾。
•视频帧和句子具有较高的语义相似性得分。
模式匹配
模式匹配模块旨在从模式库中找到与抽取出的事件、实体、关系最匹配的模式。
首先,Resin根据IE图(即抽取出的结果)和模式库中的模式图的时间先后关系对事件进行拓扑排序。然后,对于每一个IE图-模式图对,采用类似最长公共子序列方法来找到最佳匹配。匹配模块对最长公共子序列算法进行了扩展,算法先对事件进行匹配,然后贪婪地匹配事件的论元和关系,最后根据事件、论元和关系的匹配程度进行评分,将匹配度最高的IE图和模式图合并,形成最终的实例化模式。
评估
对系统中每个单独模块的评估结果如下:
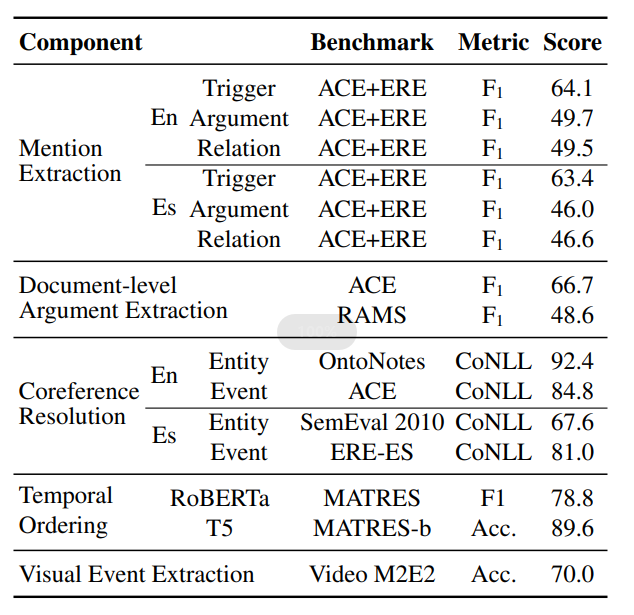
文章在LDC2020E39上评估了系统的端到端的效果,DARPA program’s phrase 1对其中约25%的系统输出结果进行人工评估,约70%的事件抽取是正确的。
04
MMKG
MMKG当中,以维基百科URI作为查询字符串,从搜索引擎爬取图片,将其作为实体的一种属性。
图像筛选
为了控制爬取结果的质量,对于每个实体,存储20张搜索结果中排名最高的图片,并过滤掉小于224像素的图片,以及长宽比大于2.5的图片。此外,还删除了损坏的、低质量的和重复的图像。
05
Richpedia
Richpedia从Wikidata收集30638个关于城市、景点和名人的实体,并从Wikipedia和搜索引擎上收集并筛选图像,并使用基于规则的方法添加图片实体的属性和图片实体之间的关系。
图像实体的属性和关系
在Richpedia中,图片是作为一个单独的实体的,主要构建如下类型的三元组:
图像实体是某一文本实体的图片:
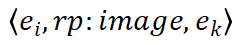
图像实体的属性(如图像大小)是什么:
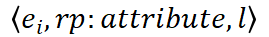
图像实体之间的关系:
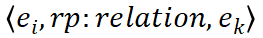
图像筛选
Richpedia希望知识图谱中的理想图像实体不仅和对应文本实体高度相关,而且多样。
Richpedia从Wikipedia和搜索引擎上收集图像后,用vgg16提取图像的特征向量,再用PCA进行降维,以得到图像的特征。在特征上应用k-means滤除噪声图像:把簇内图像少于5个的簇过滤掉,用两个特征向量夹角的余弦值代表相似度,对于每个图像簇:选择视觉得分最高的图像作为第一张图像,选与第一张图像相似度最低的作为第二张图像,以此类推。
图像关系发现
依据维基百科相关的超链接和文本发现图像相关的语义关系:在图像描述中,认为维基百科超链接可以代表链接词条中的图像,把发现的超链接之间的关系视作图像实体之间的关系。
评估
为了图像筛选后的质量,文章标注了10000张图像,并将其与模型的结果进行比较。精确度为94%,召回率为86%。。
参考文献
[1]Zhu, X., Li, Z., Wang, X., Jiang, X., Sun, P., Wang, X., ... & Yuan, N. J. (2022). Multi-modal knowledge graph construction and application: A survey. IEEE Transactions on Knowledge and Data Engineering.
[2]Li, M., Zareian, A., Lin, Y., Pan, X., Whitehead, S., Chen, B., ... & Freedman, M. (2020, July). Gaia: A fine-grained multimedia knowledge extraction system. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (pp. 77-86).
[3]Wen, H., Lin, Y., Lai, T., Pan, X., Li, S., Lin, X., ... & Ji, H. (2021, June). Resin: A dockerized schema-guided cross-document cross-lingual cross-media information extraction and event tracking system. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations (pp. 133-143).
[4]Liu, Y., Li, H., Garcia-Duran, A., Niepert, M., Onoro-Rubio, D., & Rosenblum, D. S. (2019). MMKG: multi-modal knowledge graphs. In The Semantic Web: 16th International Conference, ESWC 2019, Portorož, Slovenia, June 2–6, 2019, Proceedings 16 (pp. 459-474). Springer International Publishing.
[5]Wang, M., Wang, H., Qi, G., & Zheng, Q. (2020). Richpedia: a large-scale, comprehensive multi-modal knowledge graph. Big Data Research, 22, 100159.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

