
热门标签
热门文章
- 1如何讲好ppt演讲技巧(4篇)
- 2FastJson中JSONObject的全面用法与常用方法详解_fastjson jsonobject
- 3用人工智能写论文查重率高吗?_人工智能生成文章查重有多少
- 4求助 git config --add safe directory // 文件目录_git add safe
- 5全网最系统、最清晰 深入微服务架构——Docker和K8s详解
- 6为什么 OpenCV 计算的视频 FPS 是错的_opencv/modules/videoio/src/cap_ffmpeg_impl.hpp:233
- 7基于SpringBoot+Vue+uniapp的房屋租赁平台的详细设计和实现(源码+lw+部署文档+讲解等)_uniapp租房源码
- 8Android10 API 29引入开源项目常见问题以及解决方法_android sdk "android api 29 platform" is missing
- 9Linux网络服务部署yum仓库与NFS网络文件服务_yum install nfs-utils
- 10STM32智能语音学习笔记day03_syn6288e
当前位置: article > 正文
Hadoop 伪分布式搭建(超详细)_hadoop伪分布式localhost
作者:Monodyee | 2024-05-06 14:12:20
赞
踩
hadoop伪分布式localhost
Hadoop伪分布式搭建
虚拟机准备阶段操作
本文是基于CentOS 7 系统搭建
相关资源下载
链接:https://pan.baidu.com/s/1FW228OfyURxEgnXW0qqpmA 密码:18uc
安全设置
防火墙相关指令
# 查看防火墙状态
firewall-cmd --state
# 停止防火墙
[root@localhost ~]# systemctl stop firewalld.service
# 禁止防火墙开机自启
[root@localhost ~]# systemctl disable firewalld.service
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
关闭关闭selinux
[root@localhost ~]# vi /etc/selinux/config
- 1
将 SELINUX=enforcing改为 SELINUX=disabled
IP设置
查看机器IP
[root@localhost ~]# ifconfig
ip 为192.168.78.100
- 1
- 2
修改主机名
[root@localhost ~]# vi /etc/hostname
- 1
修改IP及主机名映射
[root@localhost ~]# vi /etc/hosts
192.168.78.100 CentOS
- 1
- 2
SSH免密登陆
[root@localhost ~]# ssh-keygen -t rsa # 生产密钥
# 连续三次回车
# 将密钥发送给需要登陆本机的机器,这里只有一台机器 所以发给自己
[root@localhost ~]# ssh-copy-id root@CentOS
# 测试ssh
[root@localhost ~]# ssh root@CentOS
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Hadoop伪分布式搭建
-
创建 install文件夹
[root@localhost ~]# mkdir /opt/install/
JDK配置
这里选用JDK8
解压
[root@localhost ~]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/install/
- 1
配置环境变量
[root@localhost jdk1.8.0_144]# vi /etc/profile
# 加入配置 加入位置如下图所示
export JAVA_HOME=/opt/install/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
# 保存后刷新环境变量
[root@localhost jdk1.8.0_144]# source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7

# 刷新完 执行命令验证JDK是否安装成功
[root@localhost jdk1.8.0_144]# java -version
- 1
- 2
成功界面

Hadoop配置
解压文件
[root@localhost ~]# tar -zxvf hadoop-2.9.2.tar.gz -C /opt/install/
- 1
修改配置文件
[root@localhost ~]# cd /opt/install/hadoop-2.9.2/etc/hadoop
- 1
-
hadoop-env.sh
export JAVA_HOME=/opt/install/jdk1.8.0_144

-
core-site.xml
<!-- 用于设置namenode并且作为Java程序的访问入口 --> <property> <name>fs.defaultFS</name> <value>hdfs://CentOS:8020</value> </property> <!-- 存储NameNode持久化的数据,DataNode块数据 --> <!-- 手工创建$HADOOP_HOME/data/tmp --> <property> <name>hadoop.tmp.dir</name> <value>/opt/install/hadoop-2.9.2/data/tmp</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

-
hdfs-site.xml
<property> <name>dfs.replication</name> <value>3</value> </property>- 1
- 2
- 3
- 4
<property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.namenode.http.address</name> <value>CentOS:50070</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

-
mapred-site.xml
首先拷贝一个mapred-site.xml[root@localhost hadoop]# cp mapred-site.xml.template mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>- 1
- 2
- 3
- 4

-
yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle

-
slaves
这里配置DataNode的主机名伪分布式情况下这里NameNode也充当DataNodeCentOS
配置Hadoop环境变量
[root@localhost hadoop-2.9.2]# vim /etc/profile
# 加入
export HADOOP_HOME=/opt/install/hadoop-2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2
- 3
- 4

# 刷新环境变量
[root@localhost hadoop-2.9.2]# source /etc/profile
- 1
- 2
验证环境变量是否配置成功
[root@localhost hadoop-2.9.2]# hadoop version
- 1

格式化NameNode
目的作用:格式化hdfs系统,并且生成存储数据块的目录
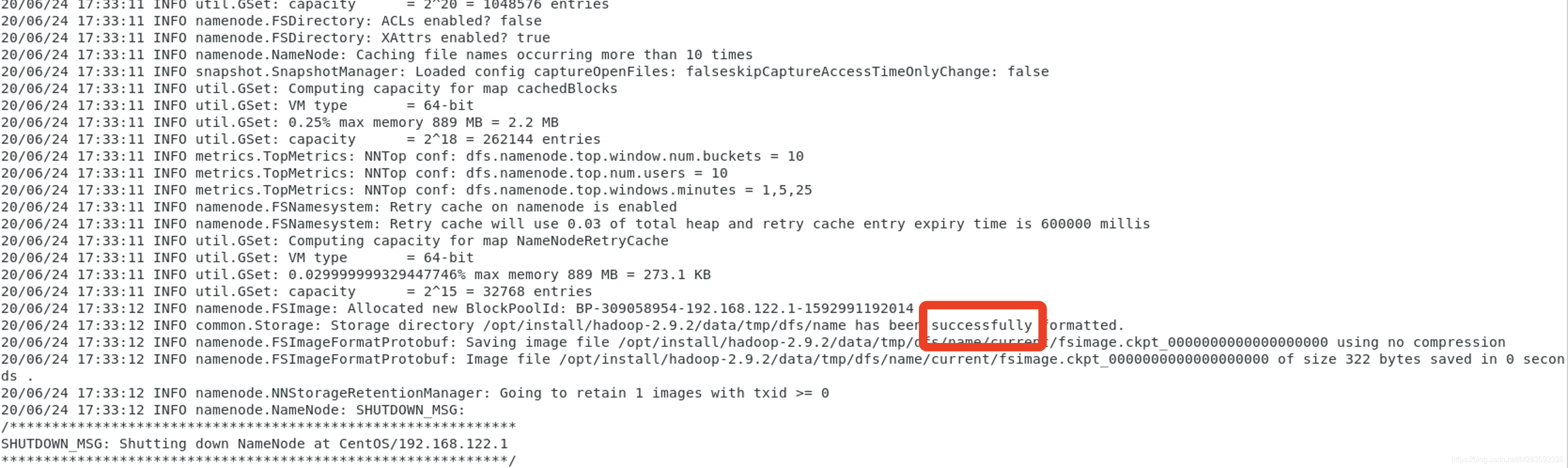
[root@localhost hadoop-2.9.2]# hadoop namenode -format
- 1
格式化成功后如图显示
Hadoop起停命令
start-all.sh
stop-all.sh
- 1
- 2
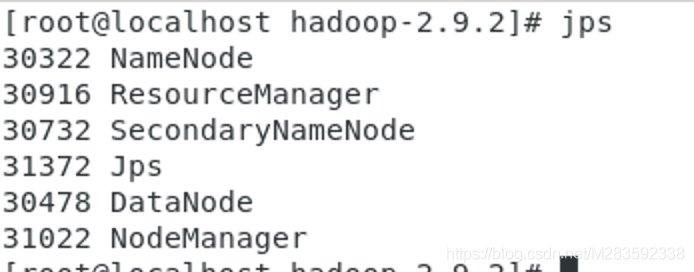
启动成后 jps查看进程
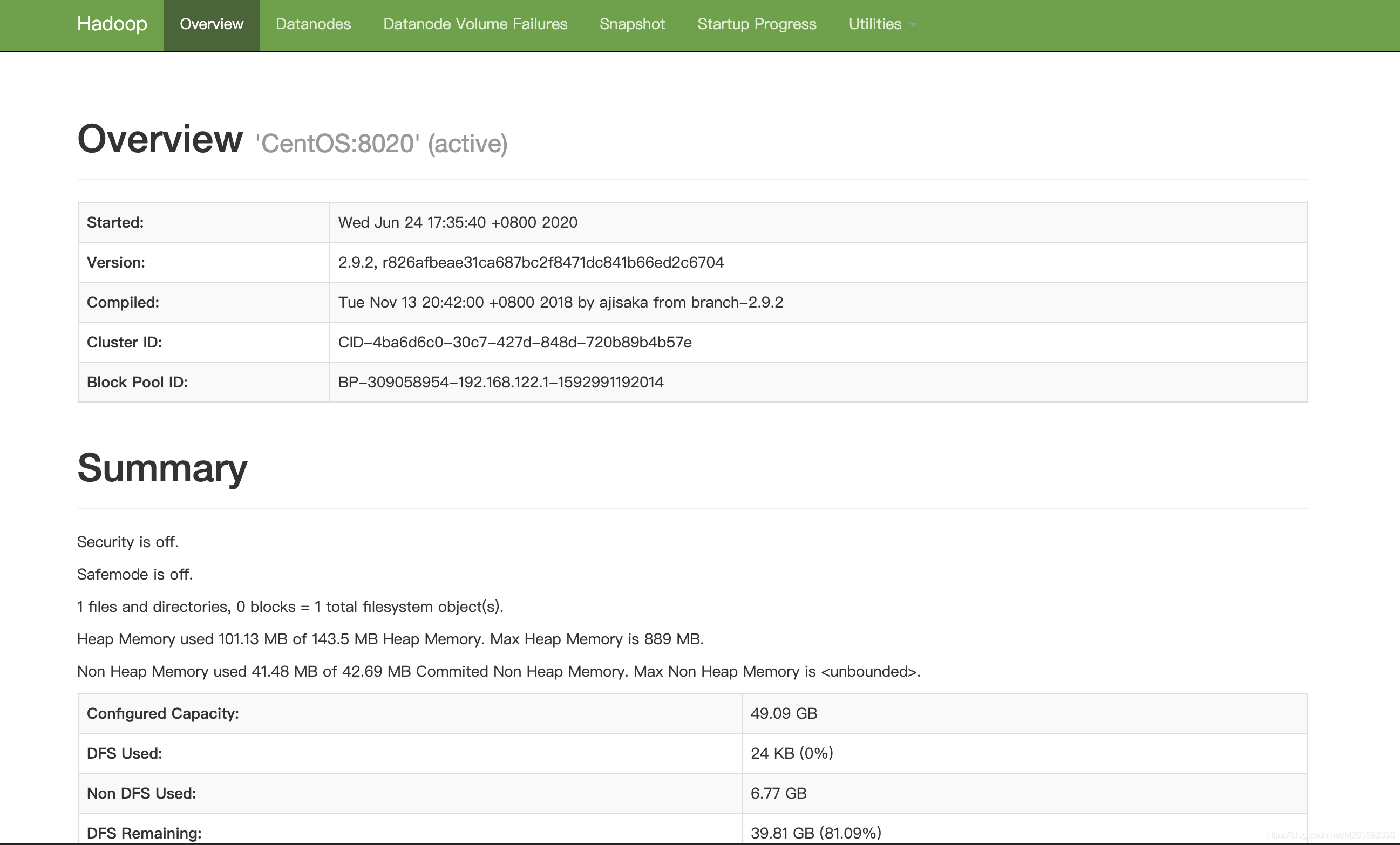
查看WebUI界面
http://CentOS:50070 访问 hdfs
http://CentOS:8088 访问 yarn

Hadoop 3.0以上看这里
在Hadoop3.0后会有一些身份的配置,如果照上面配置 启动后会抛出以下异常:
Starting namenodes on [namenode]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [datanode1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
此时需要去hadoop的sbin目录下做一下小改动
在start-dfs.sh 和 stop-dfs.sh 中 新增!!!:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
在start-yarn.sh 和 stop-yarn.sh 中 新增!!!:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
修改完保存重启可解决
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/544598
推荐阅读
相关标签

