
- 1eCharts饼图,可以点击数据,又可以点击空白部分_getzr().on
- 2命名实体识别BiLSTM-CRF模型的Pytorch_Tutorial代码解析和训练自己的中文数据集_class bilstm_crf(paddle.nn.layer):
- 3第 N 个泰波那契数
- 45月15日|智能体的自动化评估与优化,Agent-Eval-Refine
- 5【Flink】Flink on RocksDB 参数调优指南_state.backend.rocksdb.block.cache-size
- 6conda创建python虚拟环境_conda构建python37虚拟环境
- 7Github 2024-01-12Java开源项目日报 Top10_2024年度github top 10 的java 开源项目
- 8医院大数据中心建设要点分析_医疗大数据中心建设的材料
- 9大数据与机器学习:结合实践与技术
- 10mysql源码剖析–调试环境搭建_mysql 源码 debug环境搭建
K-SVD字典学习算法_k-svd算法来学习字典
赞
踩
1.提出问题:什么是稀疏表示
假设我们用一个MN的矩阵表示数据集Y,每一行代表一个样本,每一列代表样本的一个属性,一般而言,该矩阵是稠密的,即大多数元素不为0。
稀疏表示的含义是,寻找一个系数矩阵X(KN)以及一个字典矩阵D(MK),使得DX尽可能的还原Y,且X尽可能的稀疏。X便是Y的稀疏表示。
算法思想
算法求解思路为交替迭代的进行稀疏编码和字典更新两个步骤. K-SVD在构建字典步骤中,K-SVD不仅仅将原子依次更新,对于原子对应的稀疏矩阵中行向量也依次进行了修正. 不像MOP,K-SVD不需要对矩阵求逆,而是利用SVD数学分析方法得到了一个新的原子和修正的系数向量.
固
定
系
数
矩
阵
X
和
字
典
矩
阵
D
,
字
典
的
第
k
个
原
子
为
d
k
,
同
时
d
k
对
应
的
稀
固定系数矩阵X和字典矩阵D,字典的第k个原子为d_k,同时d_k对应的稀
固定系数矩阵X和字典矩阵D,字典的第k个原子为dk,同时dk对应的稀
疏
矩
阵
为
X
中
的
第
k
个
行
向
量
x
T
k
.
假
设
当
前
更
新
进
行
到
原
子
d
k
,
样
本
矩
阵
和
疏矩阵为X中的第k个行向量x^k_T. 假设当前更新进行到原子d_k,样本矩阵和
疏矩阵为X中的第k个行向量xTk.假设当前更新进行到原子dk,样本矩阵和字典逼近的误差为:
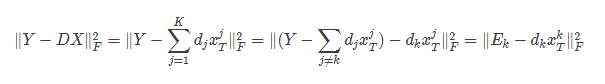
在
得
到
当
前
误
差
矩
阵
E
k
后
,
需
要
调
整
d
k
和
X
T
k
,
使
其
乘
积
与
E
k
的
误
差
尽
可
能
的
小
.
在得到当前误差矩阵E_k后,需要调整d_k和X^k_T,使其乘积与E_k的误差尽可能的小.
在得到当前误差矩阵Ek后,需要调整dk和XTk,使其乘积与Ek的误差尽可能的小.
如
果
直
接
对
d
k
和
X
T
k
进
行
更
新
,
可
能
导
致
x
T
k
不
稀
疏
.
所
以
可
以
先
把
原
有
向
量
x
T
k
中
零
如果直接对d_k和X^k_T进行更新,可能导致x^k_T不稀疏. 所以可以先把原有向量x^k_T中零
如果直接对dk和XTk进行更新,可能导致xTk不稀疏.所以可以先把原有向量xTk中零
元
素
去
除
,
保
留
非
零
项
,
构
成
向
量
x
R
k
,
然
后
从
误
差
矩
阵
E
k
中
取
出
相
应
的
列
向
量
,
元素去除,保留非零项,构成向量x^k_R,然后从误差矩阵E_k中取出相应的列向量,
元素去除,保留非零项,构成向量xRk,然后从误差矩阵Ek中取出相应的列向量,
构
成
矩
阵
E
k
R
.
对
E
k
R
进
行
S
V
D
(
S
i
n
g
u
l
a
r
V
a
l
u
e
D
e
c
o
m
p
o
s
i
t
i
o
n
)
分
解
,
有
E
k
R
=
构成矩阵E^R_k. 对E^R_k进行SVD(Singular Value Decomposition)分解,有E^R_k=
构成矩阵EkR.对EkR进行SVD(SingularValueDecomposition)分解,有EkR=
U
Δ
V
T
,
由
U
的
第
一
列
更
新
d
k
,
由
V
的
第
一
列
乘
以
Δ
(
1
,
1
)
所
得
结
果
更
新
x
R
k
.
UΔV^T,由U的第一列更新d_k,由V的第一列乘以Δ(1,1)所得结果更新x^k_R.
UΔVT,由U的第一列更新dk,由V的第一列乘以Δ(1,1)所得结果更新xRk.
代码
import numpy as np import matplotlib.pyplot as plt from numpy import * import scipy.io as sio import random from sklearn import linear_model import scipy.misc from PIL import Image def esErrDic(data,recons): m,n=data.shape esErr=0 for i in range(m): for j in range(n): esErr+=(data[i][j]-recons[i][j])**2 return esErr/(m*n) class KSVD(object): def __init__(self, n_components, max_iter=100, tol=1e-6,n_nonzero_coefs=None): """ 稀疏模型Y = DX,Y为样本矩阵,使用KSVD动态更新字典矩阵D和稀疏矩阵X :param n_components: 字典所含原子个数(字典的列数) :param max_iter: 最大迭代次数 :param tol: 稀疏表示结果的容差 :param n_nonzero_coefs: 稀疏度 """ self.dictionary = None self.sparsecode = None self.max_iter = max_iter self.tol = tol self.n_components = n_components self.n_nonzero_coefs = n_nonzero_coefs def _initialize(self, y): """ 初始化字典矩阵 """ u, s, v = np.linalg.svd(y) self.dictionary = u[:, :self.n_components] def _update_dict(self, y, d, x): """ 使用KSVD更新字典的过程 """ for i in range(self.n_components): index = np.nonzero(x[i, :])[0]#选出Xk中非零的元素下标 if len(index) == 0: continue d[:, i] = 0 r = (y - np.dot(d, x))[:, index] u, s, v = np.linalg.svd(r, full_matrices=False) d[:, i] = u[:, 0].T x[i, index] = s[0] * v[0, :] return d, x def fit(self, y): """ KSVD迭代过程 """ self._initialize(y) for i in range(self.max_iter): x = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs) e = np.linalg.norm(y - np.dot(self.dictionary, x)) if e < self.tol: break self._update_dict(y, self.dictionary, x) self.sparsecode = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs) return self.dictionary, self.sparsecode if __name__ == '__main__': file='G:/lecture of grade one/pattern recognition/trial_two/train_data2_807802844.mat' Img=loadData(file) #字典学习部分代码,其中KSVD的参数就是原子个数,可修改 ksvd = KSVD(100) dictionary, sparsecode = ksvd.fit(Img['Data']) recons=dictionary.dot(sparsecode) err=esErrDic(Img['Data'],recons) ''' #测试KSVD代码的调试代码,选择一张图片,用自己编写的KSVD对其进行字典学习 image =Image.open('/home/swh/Downloads/scene.jpeg') image = np.array(image) image=image[:,:,0] im_ascent = image.astype('float32') #im_ascent = scipy.misc.ascent().astype(np.float) ksvd = KSVD(30) dictionary, sparsecode = ksvd.fit(im_ascent) plt.figure() plt.subplot(1, 2, 1) plt.imshow(im_ascent) plt.subplot(1, 2, 2) recon=dictionary.dot(sparsecode) plt.imshow(recon) plt.show() '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89

