
热门标签
热门文章
- 1java项目经理面试常见问题及答案,阿里巴巴Java面试都问些什么
- 2为什么生成式AI这么火?OpenAI刚刚被曝估值已接近200亿美金
- 3ChatGPT对测试行业的影响(附GPT使用实战展示)_chatgtp对测试行业的冲击
- 4java线上问题排查之磁盘和网络查看分析(二)
- 5解决使用Keras对mobileNet进行迁移学习(fine-tining)出现的过拟合问题(验证集正确率过低)_迁移学习过拟合怎么办
- 62021/10/27 paradigm 笔记_power_pmsynchronousmachineparams的反向运算
- 7SSH原理与运用(一):远程登录_invalid operation ssh
- 8uniapp 安卓使用live-pusher实现人脸识别(拍照)功能_uniapp 安卓人脸识别
- 9python时间序列峰值检测,时间序列中的峰值检测
- 10SpringBoot整合第三方技术与MP常用功能_springboot mp
当前位置: article > 正文
【C++】哈希之布隆过滤器
作者:Monodyee | 2024-05-08 06:09:42
赞
踩
【C++】哈希之布隆过滤器
一、布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
布隆过滤器与前面学过的位图很相似,查找效率高且节省空间。但是位图有一个缺点:只能处理整型。布隆过滤器恰好弥补了这一缺陷,可以处理各种类型,最常见的是处理字符串。
位图与布隆过滤器主要区别:
- 位图是一个元素映射一个比特位
- 布隆过滤器是一个元素通过多个哈希函数映射多个比特位
二、布隆过滤器的插入
哈希函数:
布隆过滤器有多个哈希函数,这样可以映射多个位置,降低冲突概率。这里参考了3种哈希函数写法:
// BKDR struct HashFuncBKDR { size_t operator()(const string& s) { size_t hash = 0; for (auto ch : s) { hash *= 131; hash += ch; } return hash; } }; // AP struct HashFuncAP { size_t operator()(const string& s) { size_t hash = 0; for (size_t i = 0; i < s.size(); i++) { // 偶数位字符 if ((i & 1) == 0) { hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3)); } // 奇数位字符 else { hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5))); } } return hash; } }; // DJB struct HashFuncDJB { size_t operator()(const string& s) { size_t hash = 5381; for (auto ch : s) { hash = hash * 33 ^ ch; } return hash; } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
布隆过滤器的长度与插入的元素个数有关,有人推导了一个公式:
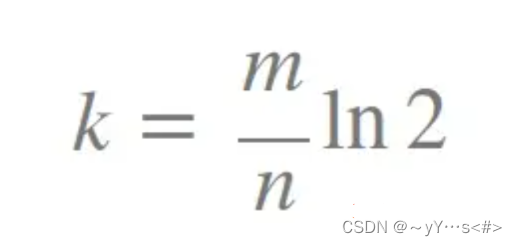
k为哈希函数的个数,这里有3个哈希函数,m为布隆过滤器的长度,n为插入元素的个数,ln2的大小约为0.69,推导出:4.34 * n = m,简化一下m与n的关系为:5n = m
private:
static const size_t M = 5 * N;
bitset<M> _bs;
- 1
- 2
- 3
插入元素时,不同的哈希函数计算出该元素的不同的映射位置,然后将要映射的位置标记为存在,即比特位为1
//插入
void Set(const K& key)
{
size_t hash1 = HashFuncBKDR()(key) % M;
size_t hash2 = HashFuncAP()(key) % M;
size_t hash3 = HashFuncDJB()(key) % M;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
三、布隆过滤器的查找
这里先来对比一下位图与布隆过滤器的查找位置冲突问题:
- 查找A元素,A元素原来不在,B元素在,B元素映射的比特位与A元素映射的比特位重合,即冲突,查找结果为在,因为是B元素的,有误判
- 查找A元素,A元素原来不在,B元素也不在,A映射的比特位为0,查找结果为不在,没有误判
位图:

布隆过滤器:
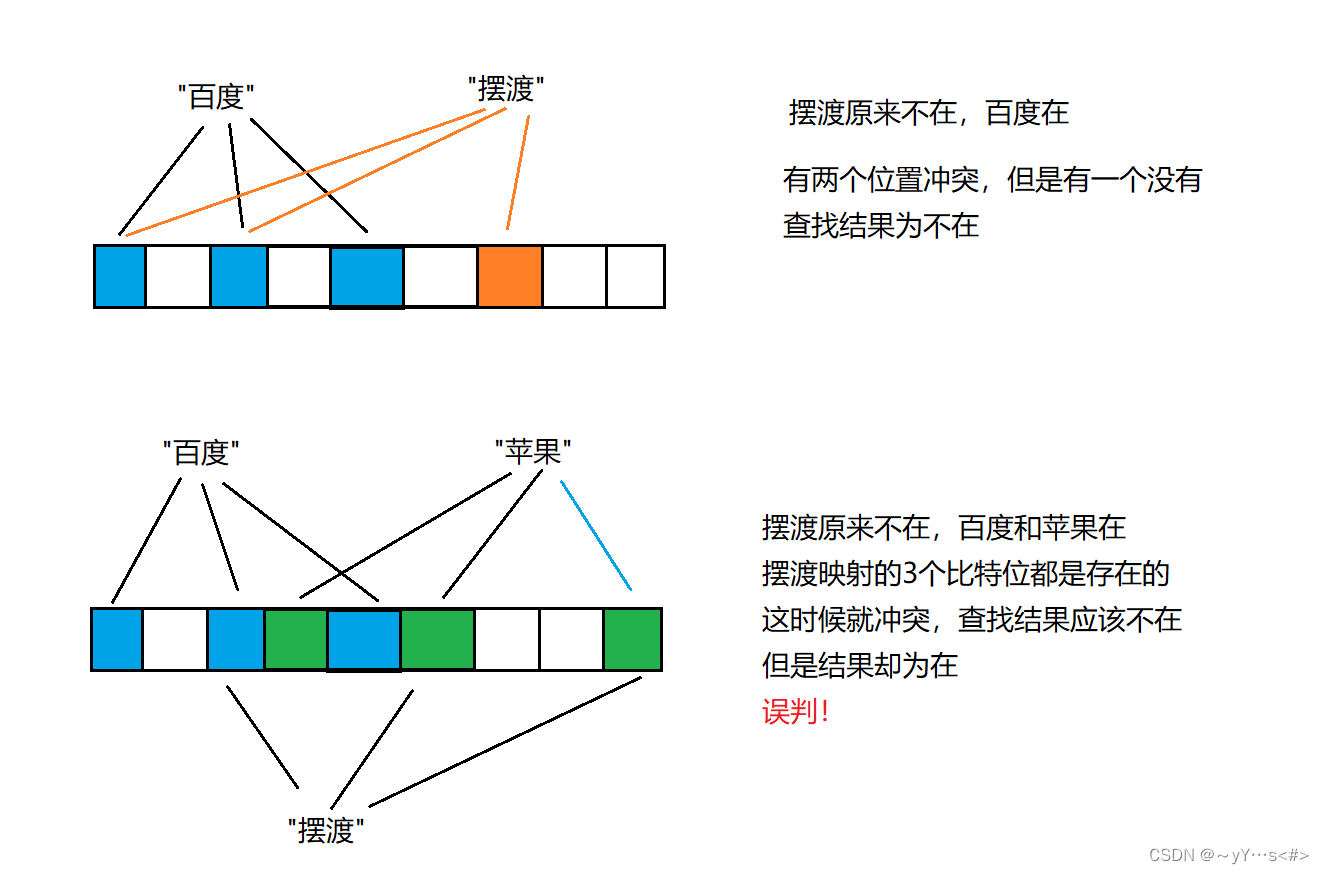
代码:
//查找
bool Test(const K& key)
{
size_t hash1 = HashFuncBKDR()(key) % M;
if (!_bs.test(hash1))
return false;
size_t hash2 = HashFuncAP()(key) % M;
if (!_bs.test(hash2))
return false;
size_t hash3 = HashFuncDJB()(key) % M;
if (!_bs.test(hash3))
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
总结:
- 查找一个元素,计算出来的哈希值对应的比特位只要有一个为0,确定该元素就是不在的;否则可能在。
- 有些哈希函数是存在误判的,所以布隆过滤器只是在一定程度上降低了哈希冲突的概率,但还是避免不了哈希冲突
四、布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。 比如:删除图中"百度"元素,如果直接将该元素所对应的二进制比特位置0,“苹果”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
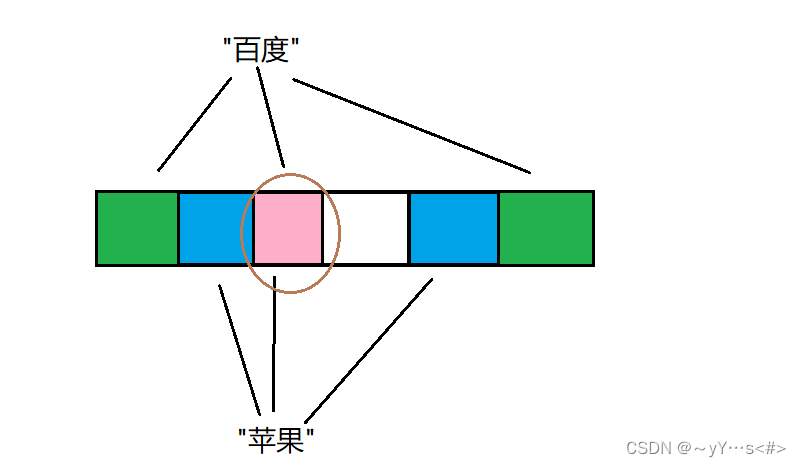
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
五、优缺点比较
布隆过滤器:
- 优点:节省空间,效率高,可以处理各种类型
- 缺点:不支持删除,存在误判
位图:
- 优点:节省空间,效率高
- 缺点:只能处理整型
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/553203
推荐阅读
相关标签

