
- 1java 裁剪 pdf_Java PDF 切割、截取、合并工具类、转图片等
- 2通过RabbitMQ实现消息推送功能 可同时实现局域网推送和广域网推送_企业内网统一消息推送
- 3python中count函数的用法_python中countinue的用法
- 4产品经理之路:产品经理基础_产品经理发展史
- 553--FPGA Verilog DDS简易信号发生器_fpga方波信号发生器verilog
- 6奇数分频器的实现
- 7基于 DDD 的微服务设计和开发实战_ddd思想微服务开源项目
- 8百度云直链获取优化版_amjnb-m6u.site
- 9GPT系列发展及技术:GPT1到GPT3的发展,InstructGPT的RLHF流程,GPT4_instructgpt rlhf过程
- 10【监控系统】Prometheus监控组件Mysql-Exporter配置实战_mysql exporter
Linux命令大全(非常详细)从零基础入门到精通,看完这一篇就够了_linux系统基本操作命令
赞
踩
注意:为了方便代码阅读,文章代码块里把表示管理员模式的#都去掉了。这不是错误。不要搞错!!
一、基本操作命令
首先先来几个热键,非常方便,一定要记住
Tab按键—命令补齐功能
Ctrl+c按键—停掉正在运行的程序
Ctrl+d按键—相当于exit,退出
Ctrl+l按键—清屏
1.1 关机和重启
1.关机命令:shutdown
在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
正确的关机流程为:sync > shutdown > reboot > halt
例如你可以运行如下命令关机:
sync 将数据由内存同步到硬盘中。shutdown 关机指令,你可以man shutdown 来看一下帮助文档。例如你可以运行如下命令关机:shutdown –h 10 ‘This server will shutdown after 10 mins’ 这个命令告诉大家,计算机将在10分钟后关机,并且会显示在登陆用户的当前屏幕中。shutdown –h now 立马关机
shutdown –h 20:25 系统会在今天20:25关机
shutdown –h +10 十分钟后关机
shutdown –r now 系统立马重启
shutdown –r +10 系统十分钟后重启
reboot 就是重启,等同于 shutdown –r now
halt 关闭系统,等同于shutdown –h now 和 poweroff
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面是一个简单的样例。

取消定时关机命令:shutdown -c
最后总结一下,不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中。
关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6。
2.重启命令:reboot

1.2 帮助命令
–-help命令
shutdown --help:ifconfig --help:查看网卡信息
- 1
man命令(命令说明书)
man shutdown
注意:man shutdown 打开命令说明书之后,使用按键q退出
- 1
- 2
二、目录操作命令
我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 /。
其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。
首先我们需要先知道什么是绝对路径与相对路径。
-
绝对路径:
路径的写法,由根目录 / 写起,例如:/usr/share/doc 这个目录。 -
相对路径:
路径的写法,不是由/写起,例如由/usr/share/doc要到/usr/share/man底下时,可以写成:cd ../man这就是相对路径的写法啦!
2.1 目录切换 cd
命令:cd 目录
cd是Change Directory的缩写,这是用来变换工作目录的命令。
cd / 切换到根目录
cd /usr 切换到根目录下的usr目录
cd ../ 切换到上一级目录 或者 cd ..
cd ~ 切换到home目录
cd - 切换到上次访问的目录
- 1
- 2
- 3
- 4
- 5
2.2 目录查看 ls [-al]
命令:ls [-al]
语法:
ls [-aAdfFhilnrRSt] 目录名称
ls [--color={never,auto,always}] 目录名称
ls [--full-time] 目录名称
- 1
- 2
- 3
ls 查看当前目录下的所有目录和文件
ls -a 查看当前目录下的所有目录和文件(包括隐藏的文件)
ls -l 或 ll 列表查看当前目录下的所有目录和文件(列表查看,显示更多信息)
ls /dir 查看指定目录下的所有目录和文件 如:ls /usr
将家目录下的所有文件列出来(含属性与隐藏档)
ls -al ~
- 1
2.3 目录操作【增,删,改,查】
2.3.1 创建目录【增】 mkdir
如果想要创建新的目录的话,那么就使用mkdir (make directory)吧。
语法:
mkdir [-mp] 目录名称
- 1
选项与参数:
-
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~
-
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
-
微信搜索公众号:架构师指南,回复:架构师 领取资料 。
实例:请到/tmp底下尝试创建数个新目录看看:
cd /tmp
[root@www tmp] mkdir test <==创建一名为 test 的新目录
[root@www tmp] mkdir test1/test2/test3/test4
mkdir: cannot create directory `test1/test2/test3/test4':
No such file or directory <== 没办法直接创建此目录啊![root@www tmp] mkdir -p test1/test2/test3/test4
- 1
- 2
- 3
- 4
- 5
加了这个 -p 的选项,可以自行帮你创建多层目录!
实例:创建权限为 rwx–x—x 的目录。
[root@www tmp] mkdir -m 711 test2
[root@www tmp] ls -l
drwxr-xr-x 3 root root 4096 Jul 18 12:50 test
drwxr-xr-x 3 root root 4096 Jul 18 12:53 test1
drwx--x--x 2 root root 4096 Jul 18 12:54 test2
- 1
- 2
- 3
- 4
- 5
上面的权限部分,如果没有加上 -m 来强制配置属性,系统会使用默认属性。
如果我们使用 -m ,如上例我们给予 -m 711 来给予新的目录 drwx–x—x 的权限。
2.3.2 删除目录或文件【删】rm
rm [-fir] 文件或目录
- 1
选项与参数:
-
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-
-i :互动模式,在删除前会询问使用者是否动作
-
-r :递归删除啊!最常用在目录的删除了!这是非常危险的选项!!!
删除文件:
rm 文件 删除当前目录下的文件
rm -f 文件 删除当前目录的的文件(不询问)
删除目录:
rm -r aaa 递归删除当前目录下的aaa目录
rm -rf aaa 递归删除当前目录下的aaa目录(不询问)
全部删除:
rm -rf 将当前目录下的所有目录和文件全部删除
rm -rf / **【自杀命令!慎用!慎用!慎用!】**将根目录下的所有文件全部删除
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了方便大家的记忆,无论删除任何目录或文件,都直接使用 rm -rf 目录/文件/压缩包
rmdir (删除空的目录)
语法:
rmdir [-p] 目录名称
- 1
选项与参数:
- **-p :**连同上一级『空的』目录也一起删除
删除 runoob 目录
[root@www tmp] rmdir runoob
- 1
将 mkdir 实例中创建的目录(/tmp 底下)删除掉!
[root@www tmp] ls -l <==看看有多少目录存在?drwxr-xr-x 3 root root 4096 Jul 18 12:50 test
drwxr-xr-x 3 root root 4096 Jul 18 12:53 test1
drwx--x--x 2 root root 4096 Jul 18 12:54 test2
[root@www tmp] rmdir test <==可直接删除掉,没问题
[root@www tmp] rmdir test1 <==因为尚有内容,所以无法删除!rmdir: `test1': Directory not empty
[root@www tmp] rmdir -p test1/test2/test3/test4
[root@www tmp] ls -l <==您看看,底下的输出中test与test1不见了!drwx--x--x 2 root root 4096 Jul 18 12:54 test2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
利用 -p 这个选项,立刻就可以将 test1/test2/test3/test4 一次删除。
不过要注意的是,这个 rmdir 仅能删除空的目录,你可以使用 rm 命令来删除非空目录。
2.3.3 目录修改【改】mv 和 cp
mv (移动文件与目录,或修改名称)
语法:
[root@www ~] mv [-fiu] source destination
[root@www ~] mv [options] source1 source2 source3 .... directory
- 1
- 2
选项与参数:
-
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-
-u :若目标文件已经存在,且 source 比较新,才会升级 (update)
cp (复制文件或目录)
cp 即拷贝文件和目录。
语法:
[root@www ~] cp [-adfilprsu] 来源档(source) 目标档(destination)
[root@www ~] cp [options] source1 source2 source3 .... directory
- 1
- 2
选项与参数:
-
-a:相当於 -pdr 的意思,至於 pdr 请参考下列说明;(常用)
-
-d:若来源档为连结档的属性(link file),则复制连结档属性而非文件本身;
-
-f:为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
-
-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
-
-l:进行硬式连结(hard link)的连结档创建,而非复制文件本身;
-
-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);
-
-r:递归持续复制,用於目录的复制行为;(常用)
-
-s:复制成为符号连结档 (symbolic link),亦即『捷径』文件;
-
-u:若 destination 比 source 旧才升级 destination !
一、重命名目录
命令:mv 当前目录 新目录
例如:mv aaa bbb 将目录aaa改为bbb
注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作
二、剪切目录
命令:mv 目录名称 目录的新位置
示例:将/usr/tmp目录下的aaa目录剪切到 /usr目录下面 mv /usr/tmp/aaa /usr
注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作
三、拷贝目录
命令:cp -r 目录名称 目录拷贝的目标位置 -r代表递归
示例:将/usr/tmp目录下的aaa目录复制到 /usr目录下面 cp /usr/tmp/aaa /usr
注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
2.3.4 搜索目录【查】find
Linux find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
find path -option [ -print ] [ -exec -ok command ] {} \;
- 1
命令:find 目录 参数 文件名称
部分参数:
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
实例
将目前目录及其子目录下所有延伸档名是 c 的文件列出来。
find . -name "*.c"
- 1
将目前目录其其下子目录中所有一般文件列出
find . -type f
- 1
将目前目录及其子目录下所有最近 20 天内更新过的文件列出
find . -ctime -20
- 1
2.4 当前目录显示 pwd
pwd (显示目前所在的目录)
pwd 是 Print Working Directory 的缩写,也就是显示目前所在目录的命令。
[root@www ~] pwd [-P]
- 1
选项与参数:
- -P :显示出确实的路径,而非使用连结 (link) 路径。
实例:单纯显示出目前的工作目录:
[root@www ~] pwd
/root <== 显示出目录啦~
- 1
- 2
实例显示出实际的工作目录,而非连结档本身的目录名而已。
[root@www ~] cd /var/mail <==注意,/var/mail是一个连结档
[root@www mail] pwd
/var/mail <==列出目前的工作目录
[root@www mail] pwd -P
/var/spool/mail <==怎么回事?有没有加 -P 差很多~
[root@www mail] ls -ld /var/mail
lrwxrwxrwx 1 root root 10 Sep 4 17:54 /var/mail -> spool/mail
# 看到这里应该知道为啥了吧?因为 /var/mail 是连结档,连结到 /var/spool/mail
# 所以,加上 pwd -P 的选项后,会不以连结档的数据显示,而是显示正确的完整路径啊!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、文件操作命令
3.1 文件操作【增,删,改,查】
3.1.1 新建文件【增】touch
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
- 1
-
参数说明:
-
a 改变档案的读取时间记录。
-
m 改变档案的修改时间记录。
-
c 假如目的档案不存在,不会建立新的档案。与 —no-create 的效果一样。
-
f 不使用,是为了与其他 unix 系统的相容性而保留。
-
r 使用参考档的时间记录,与 —file 的效果一样。
-
d 设定时间与日期,可以使用各种不同的格式。
-
t 设定档案的时间记录,格式与 date 指令相同。
-
–no-create 不会建立新档案。
-
–help 列出指令格式。
-
–version 列出版本讯息。
实例
使用指令”touch”修改文件”testfile”的时间属性为当前系统时间,输入如下命令:
$ touch testfile #修改文件的时间属性
- 1
首先,使用ls命令查看testfile文件的属性,如下所示:
$ ls -l testfile #查看文件的时间属性
#原来文件的修改时间为16:09
-rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile
- 1
- 2
- 3
执行指令”touch”修改文件属性以后,并再次查看该文件的时间属性,如下所示:
$ touch testfile #修改文件时间属性为当前系统时间
$ ls -l testfile #查看文件的时间属性
#修改后文件的时间属性为当前系统时间
-rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile
- 1
- 2
- 3
- 4
使用指令”touch”时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件”file”,输入如下命令:
$ touch file #创建一个名为“file”的新的空白文件
- 1
3.1.2 删除文件 【删】 rm
rm (移除文件或目录)
语法:
rm [-fir] 文件或目录
- 1
选项与参数:
-
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-
-i :互动模式,在删除前会询问使用者是否动作
-
-r :递归删除啊!最常用在目录的删除了!这是非常危险的选项!!!
将创建的 bashrc 删除掉!
[root@www tmp]# rm -i bashrc
rm: remove regular file `bashrc'? y
- 1
- 2
如果加上 -i 的选项就会主动询问喔,避免你删除到错误的档名!
3.1.3 修改文件【改】 vi或vim
先来个vim键盘图!
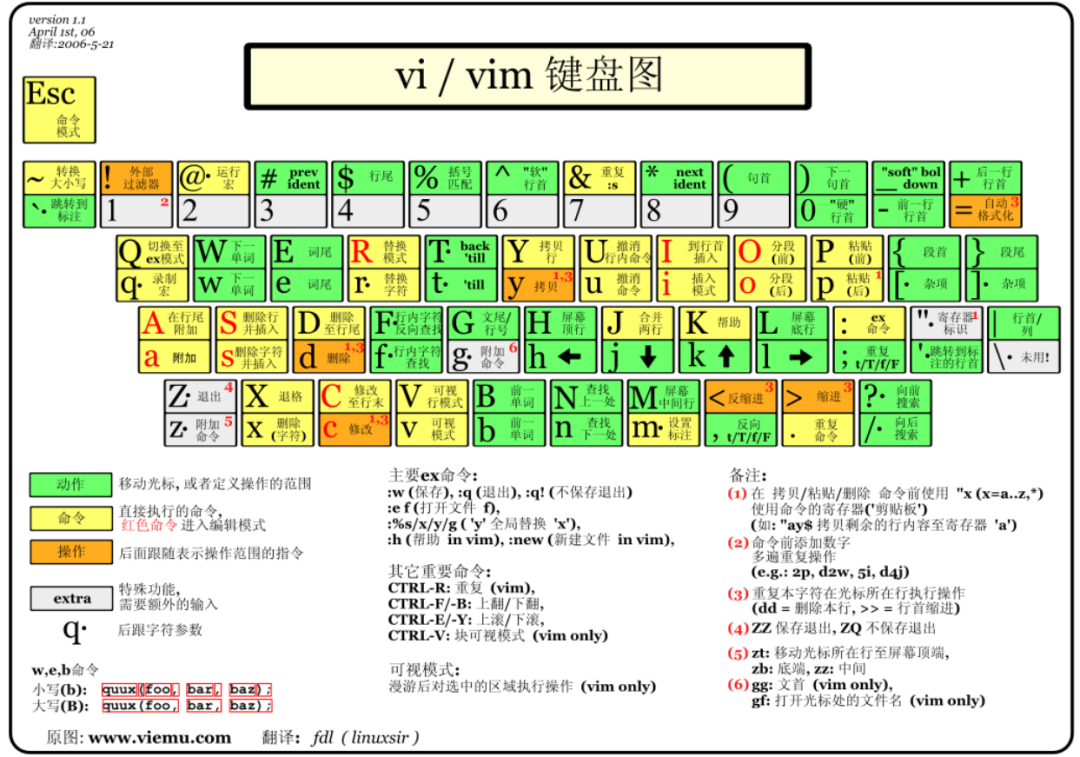
vi/vim 的使用
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),**输入模式(Insert mode)**和 底线命令模式(Last line mode)。这三种模式的作用分别是:
3.1.3.1 命令模式:
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
以下是常用的几个命令:
-
i 切换到输入模式,以输入字符。
-
x 删除当前光标所在处的字符。
-
: 切换到底线命令模式,以在最底一行输入命令。
若想要编辑文本:启动Vim,进入了命令模式,按下i,切换到输入模式。
命令模式只有一些最基本的命令,因此仍要依靠底线命令模式输入更多命令。
3.1.3.2 输入模式
在命令模式下按下i就进入了输入模式。
在输入模式中,可以使用以下按键:
-
字符按键以及Shift组合,输入字符
-
ENTER,回车键,换行
-
BACK SPACE,退格键,删除光标前一个字符
-
DEL,删除键,删除光标后一个字符
-
方向键,在文本中移动光标
-
HOME/END,移动光标到行首/行尾
-
Page Up/Page Down,上/下翻页
-
Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
-
ESC,退出输入模式,切换到命令模式
3.1.3.4 底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
-
q 退出程序
-
w 保存文件
按ESC键可随时退出底线命令模式。
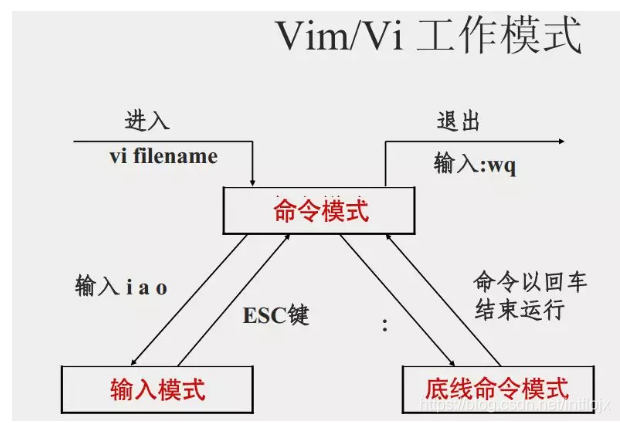
简单的说,我们可以将这三个模式想成底下的图标来表示:
打开文件
命令:vi 文件名
示例:打开当前目录下的aa.txt文件 vi aa.txt 或者 vim aa.txt
注意:使用vi编辑器打开文件后,并不能编辑,因为此时处于命令模式,点击键盘i/a/o进入编辑模式。
编辑文件
使用vi编辑器打开文件后点击按键:i ,a或者o即可进入编辑模式。
i:在光标所在字符前开始插入
a:在光标所在字符后开始插入
o:在光标所在行的下面另起一新行插入

保存或者取消编辑
保存文件:
第一步:ESC 进入命令行模式
第二步:: 进入底行模式
第三步:wq 保存并退出编辑
取消编辑:
第一步:ESC 进入命令行模式
第二步:: 进入底行模式
第三步:q! 撤销本次修改并退出编辑
3.1.4 文件的查看【查】
Linux系统中使用以下命令来查看文件的内容:
-
cat 由第一行开始显示文件内容
-
tac 从最后一行开始显示,可以看出 tac 是 cat 的倒着写!
-
nl 显示的时候,顺道输出行号!
-
more 一页一页的显示文件内容
-
less 与 more 类似,但是比 more 更好的是,他可以往前翻页!
-
head 只看头几行
-
tail 只看尾巴几行
你可以使用 _man [命令]_来查看各个命令的使用文档,如 :man cp。
3.1.4.1 cat
由第一行开始显示文件内容
语法:
cat [-AbEnTv]
- 1
选项与参数:
-
-A :相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
-
-b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
-
-E :将结尾的断行字节 $ 显示出来;
-
-n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
-
-T :将 [tab] 按键以 ^I 显示出来;
-
-v :列出一些看不出来的特殊字符
检看 /etc/issue 这个文件的内容:
[root@www ~] cat /etc/issue
CentOS release 6.4 (Final)
Kernel \r on an \m
- 1
- 2
- 3
3.1.3.2 tac
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出 tac 是 cat 的倒着写!如:
[root@www ~] tac /etc/issue
Kernel \r on an \m
CentOS release 6.4 (Final)
- 1
- 2
- 3
- 4
3.1.3.3 nl
显示行号
语法:
nl [-bnw] 文件
- 1
选项与参数:
-
-b :指定行号指定的方式,主要有两种:
-b a :表示不论是否为空行,也同样列出行号(类似 cat -n);
-b t :如果有空行,空的那一行不要列出行号(默认值); -
-n :列出行号表示的方法,主要有三种:
-n ln :行号在荧幕的最左方显示;
-n rn :行号在自己栏位的最右方显示,且不加 0 ;
-n rz :行号在自己栏位的最右方显示,且加 0 ; -
-w :行号栏位的占用的位数。
实例一:用 nl 列出 /etc/issue 的内容
[root@www ~] nl /etc/issue
1 CentOS release 6.4 (Final)
2 Kernel \r on an \m
123
- 1
- 2
- 3
- 4
3.1.3.5 more
一页一页翻动
[root@www ~] more /etc/man_db.config
#
# Generated automatically from man.conf.in by the
# configure script.
#
# man.conf from man-1.6d
....(中间省略)....
--More--(28%) <== 重点在这一行喔!你的光标也会在这里等待你的命令
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在 more 这个程序的运行过程中,你有几个按键可以按的:
-
空白键 (space):代表向下翻一页;
-
Enter :代表向下翻『一行』;
-
/字串 :代表在这个显示的内容当中,向下搜寻『字串』这个关键字;
-
:f :立刻显示出档名以及目前显示的行数;
-
q :代表立刻离开 more ,不再显示该文件内容。
-
b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
3.1.3.6 less
一页一页翻动,以下实例输出/etc/man.config文件的内容:
[root@www ~] less /etc/man.config
#
# Generated automatically from man.conf.in by the
# configure script.
#
# man.conf from man-1.6d
....(中间省略)....
: <== 这里可以等待你输入命令!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
less运行时可以输入的命令有:
-
空白键 :向下翻动一页;
-
[pagedown]:向下翻动一页;
-
[pageup] :向上翻动一页;
-
/字串 :向下搜寻『字串』的功能;
-
?字串 :向上搜寻『字串』的功能;
-
n :重复前一个搜寻 (与 / 或 ? 有关!)
-
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
-
q :离开 less 这个程序;
3.1.3.7 head
取出文件前面几行
语法:
head [-n number] 文件
- 1
选项与参数:
- -n :后面接数字,代表显示几行的意思
[root@www ~] head /etc/man.config
- 1
默认的情况中,显示前面 10 行!若要显示前 20 行,就得要这样:
[root@www ~] head -n 20 /etc/man.config
- 1
3.1.3.8 tail
取出文件后面几行
语法:
tail [-n number] 文件
- 1
选项与参数:
-
-n :后面接数字,代表显示几行的意思
-
-f :表示持续侦测后面所接的档名,要等到按下[ctrl]-c才会结束tail的侦测
[root@www ~] tail /etc/man.config
# 默认的情况中,显示最后的十行!若要显示最后的 20 行,就得要这样:[root@www ~] tail -n 20 /etc/man.config
- 1
- 2
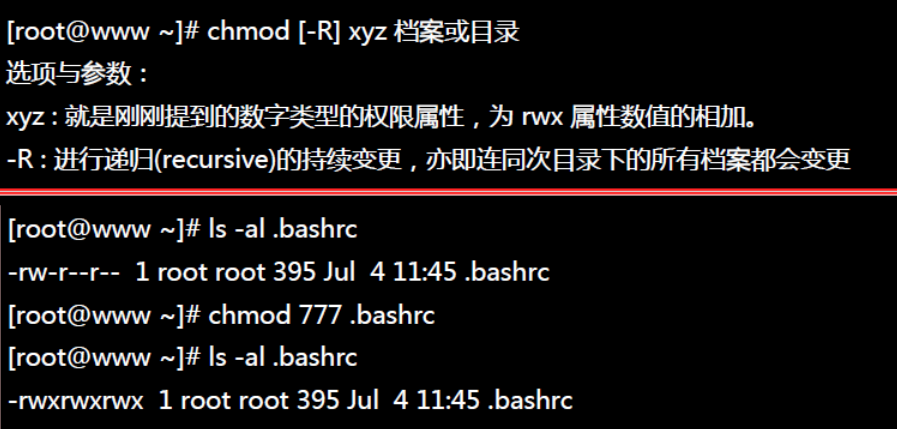
3.2 权限修改
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以藉以控制文件如何被他人所调用。
使用权限 : 所有使用者
语法
chmod [-cfvR] [--help] [--version] mode file...
- 1
参数说明
mode : 权限设定字串,格式如下 :
[ugoa...][[+-=][rwxX]...][,...]
- 1
其中:
-
u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。
-
+ 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
-
r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
其他参数说明:
-
-c : 若该文件权限确实已经更改,才显示其更改动作
-
-f : 若该文件权限无法被更改也不要显示错误讯息
-
-v : 显示权限变更的详细资料
-
-R : 对目前目录下的所有文件与子目录进行相同的权限变更(即以递回的方式逐个变更)
-
–help : 显示辅助说明
-
–version : 显示版本
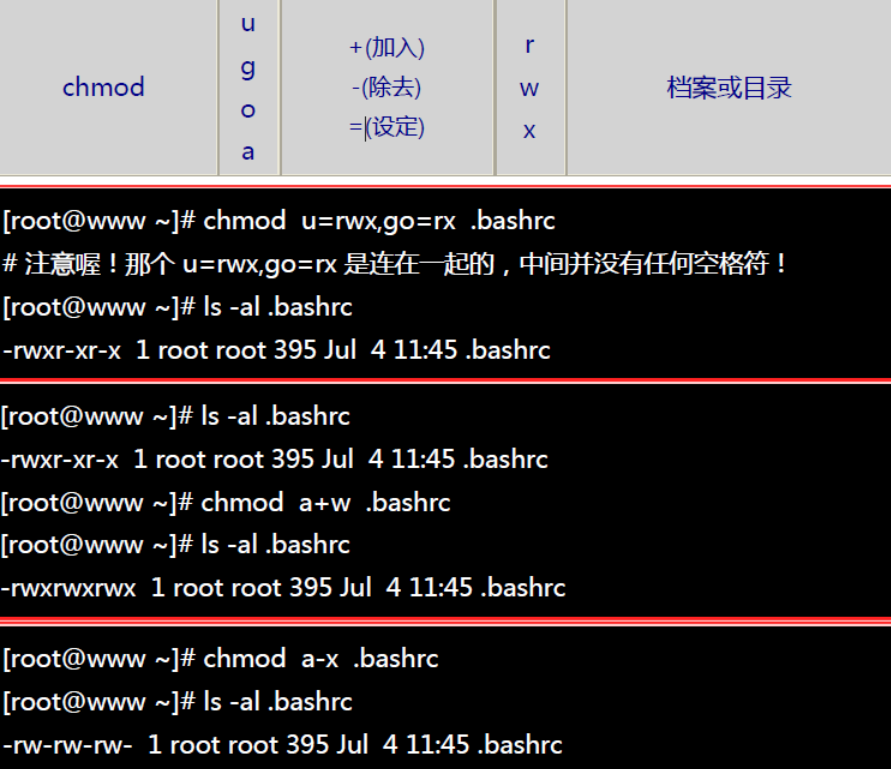
权限的设定方法有两种, 分别可以使用数字或者是符号来进行权限的变更。
数字类型改变档案权限:
符号类型改变档案权限:
四、压缩文件操作
===========
Linux 常用的压缩与解压缩命令有:tar、gzip、gunzip、bzip2、bunzip2、compress 、uncompress、 zip、 unzip、rar、unrar 等。
4.1 打包和压缩和解压
Windows的压缩文件的扩展名 .zip/.rar
linux中的打包文件:aa.tar
linux中的压缩文件:bb.gz
linux中打包并压缩的文件:.tar.gz
Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
4.1.1 tar
最常用的打包命令是 tar,使用 tar 程序打出来的包我们常称为 tar 包,tar 包文件的命令通常都是以 .tar 结尾的。生成 tar 包后,就可以用其它的程序来进行压缩了,所以首先就来讲讲 tar 命令的基本用法。
tar 命令的选项有很多(用 man tar 可以查看到),但常用的就那么几个选项,下面来举例说明一下:
tar -cf all.tar *.jpg
- 1
这条命令是将所有 .jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指定包的文件名。
tar -rf all.tar *.gif
- 1
这条命令是将所有 .gif 的文件增加到 all.tar 的包里面去,-r 是表示增加文件的意思。
tar -uf all.tar logo.gif
- 1
这条命令是更新原来 tar 包 all.tar 中 logo.gif 文件,-u 是表示更新文件的意思。
tar -tf all.tar
- 1
这条命令是列出 all.tar 包中所有文件,-t 是列出文件的意思。
tar -xf all.tar
- 1
这条命令是解出 all.tar 包中所有文件,-x 是解开的意思。
以上就是 tar 的最基本的用法。为了方便用户在打包解包的同时可以压缩或解压文件,tar 提供了一种特殊的功能。这就是 tar 可以在打包或解包的同时调用其它的压缩程序,比如调用 gzip、bzip2 等。
4.1.1.1 tar调用
gzip 是 GNU 组织开发的一个压缩程序,.gz 结尾的文件就是 gzip 压缩的结果。与 gzip 相对的解压程序是 gunzip。tar 中使用 -z 这个参数来调用gzip。下面来举例说明一下:
tar -czf all.tar.gz *.jpg
- 1
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,包名为 all.tar.gz。
tar -xzf all.tar.gz
- 1
这条命令是将上面产生的包解开。
4.1.1.2 tar 调用 bzip2
bzip2 是一个压缩能力更强的压缩程序,.bz2 结尾的文件就是 bzip2 压缩的结果。
与 bzip2 相对的解压程序是 bunzip2。tar 中使用 -j 这个参数来调用 gzip。下面来举例说明一下:
tar -cjf all.tar.bz2 *.jpg
- 1
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,包名为 all.tar.bz2
tar -xjf all.tar.bz2
- 1
这条命令是将上面产生的包解开。
4.1.1.3 tar 调用 compress
compress 也是一个压缩程序,但是好象使用 compress 的人不如 gzip 和 bzip2 的人多。.Z 结尾的文件就是 bzip2 压缩的结果。与 compress 相对的解压程序是 uncompress。tar 中使用 -Z 这个参数来调用 compress。下面来举例说明一下:
tar -cZf all.tar.Z *.jpg
- 1
这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 compress 压缩,生成一个 uncompress 压缩过的包,包名为 all.tar.Z。
tar -xZf all.tar.Z
- 1
这条命令是将上面产生的包解开。
有了上面的知识,你应该可以解开多种压缩文件了,下面对于 tar 系列的压缩文件作一个小结:
1) 对于.tar结尾的文件
tar -xf all.tar
- 1
2) 对于 .gz 结尾的文件
gzip -d all.gz
gunzip all.gz
- 1
- 2
3)对于 .tgz 或 .tar.gz 结尾的文件
tar -xzf all.tar.gz
tar -xzf all.tgz
- 1
- 2
4) 对于 .bz2 结尾的文件
bzip2 -d all.bz2
bunzip2 all.bz2
- 1
- 2
5) 对于 tar.bz2 结尾的文件
tar -xjf all.tar.bz2
- 1
6) 对于 .Z 结尾的文件
uncompress all.Z
- 1
7) 对于 .tar.Z 结尾的文件
tar -xZf all.tar.z
- 1
另外对于 Windows 下的常见压缩文件 .zip 和 .rar,Linux 也有相应的方法来解压它们:
1) 对于 .zip
linux 下提供了 zip 和 unzip 程序,zip 是压缩程序,unzip 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
zip all.zip *.jpg
- 1
这条命令是将所有 .jpg 的文件压缩成一个 zip 包:
unzip all.zip
- 1
这条命令是将 all.zip 中的所有文件解压出来。
2) 对于 .rar
要在 linux 下处理 .rar 文件,需要安装 RAR for Linux。下载地址:http://www.rarsoft.com/download.htm,下载后安装即可。
tar -xzpvf rarlinux-x64-5.6.b5.tar.gz
cd rar
make
- 1
- 2
- 3
这样就安装好了,安装后就有了 rar 和 unrar 这两个程序,rar 是压缩程序,unrar 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法:
rar a all *.jpg
- 1
这条命令是将所有 .jpg 的文件压缩成一个 rar 包,名为 all.rar,该程序会将 .rar 扩展名将自动附加到包名后。
unrar e all.rar
- 1
这条命令是将 all.rar 中的所有文件解压出来
4.2 扩展内容
tar
-c: 建立压缩档案
-x:解压
-t:查看内容 shell
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件
- 1
- 2
- 3
- 4
- 5
这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出
- 1
- 2
- 3
- 4
- 5
下面的参数 -f 是必须的:
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
- 1
# tar -cf all.tar *.jpg
这条命令是将所有 .jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指定包的文件名。
tar -rf all.tar *.gif
- 1
这条命令是将所有 .gif 的文件增加到 all.tar 的包里面去。-r 是表示增加文件的意思。
tar -uf all.tar logo.gif
- 1
这条命令是更新原来 tar 包 all.tar 中 logo.gif 文件,-u 是表示更新文件的意思。
tar -tf all.tar
- 1
这条命令是列出 all.tar 包中所有文件,-t 是列出文件的意思。
tar -xf all.tar
- 1
这条命令是解出 all.tar 包中所有文件,-x 是解开的意思。
压缩
tar –cvf jpg.tar *.jpg // 将目录里所有jpg文件打包成 tar.jpg
tar –czf jpg.tar.gz *.jpg // 将目录里所有jpg文件打包成 jpg.tar 后,并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,命名为 jpg.tar.gz
tar –cjf jpg.tar.bz2 *.jpg // 将目录里所有jpg文件打包成 jpg.tar 后,并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,命名为jpg.tar.bz2
tar –cZf jpg.tar.Z *.jpg // 将目录里所有 jpg 文件打包成 jpg.tar 后,并且将其用 compress 压缩,生成一个 umcompress 压缩过的包,命名为jpg.tar.Z
rar a jpg.rar *.jpg // rar格式的压缩,需要先下载 rar for linux
zip jpg.zip *.jpg // zip格式的压缩,需要先下载 zip for linux
- 1
- 2
- 3
- 4
- 5
- 6
解压
tar –xvf file.tar // 解压 tar 包
tar -xzvf file.tar.gz // 解压 tar.gz
tar -xjvf file.tar.bz2 // 解压 tar.bz2
tar –xZvf file.tar.Z // 解压 tar.Z
unrar e file.rar // 解压 rar
unzip file.zip // 解压 zip
- 1
- 2
- 3
- 4
- 5
- 6
总结
1、*.tar 用 tar –xvf 解压
2、*.gz 用 gzip -d或者gunzip 解压
3、*.tar.gz和*.tgz 用 tar –xzf 解压
4、*.bz2 用 bzip2 -d或者用bunzip2 解压
5、*.tar.bz2用tar –xjf 解压
6、*.Z 用 uncompress 解压
7、*.tar.Z 用tar –xZf 解压
8、*.rar 用 unrar e解压
9、*.zip 用 unzip 解压
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
五、查找命令
5.1 grep
grep命令是一种强大的文本搜索工具
使用实例:
ps -ef | grep sshd 查找指定ssh服务进程
ps -ef | grep sshd | grep -v grep 查找指定服务进程,排除gerp身
ps -ef | grep sshd -c 查找指定进程个数
- 1
- 2
- 3
从文件内容查找匹配指定字符串的行:
$ grep "被查找的字符串" 文件名
- 1
例子:在当前目录里第一级文件夹中寻找包含指定字符串的 .in 文件
grep "thermcontact" /.in
- 1
从文件内容查找与正则表达式匹配的行:
$ grep –e "正则表达式" 文件名
- 1
查找时不区分大小写:
$ grep –i "被查找的字符串" 文件名
- 1
查找匹配的行数:
$ grep -c “被查找的字符串” 文件名
从文件内容查找不匹配指定字符串的行:
$ grep –v "被查找的字符串" 文件名
- 1
5.2 find
find命令在目录结构中搜索文件,并对搜索结果执行指定的操作。
find 默认搜索当前目录及其子目录,并且不过滤任何结果(也就是返回所有文件),将它们全都显示在屏幕上。
使用实例:
find . -name "*.log" -ls 在当前目录查找以.log结尾的文件,并显示详细信息。find /root/ -perm 600 查找/root/目录下权限为600的文件
find . -type f -name "*.log" 查找当目录,以.log结尾的普通文件
find . -type d | sort 查找当前所有目录并排序
find . -size +100M 查找当前目录大于100M的文件
- 1
- 2
- 3
- 4
从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 “ERROR” 的行:
$ find / -type f -name "*.log" | xargs grep "ERROR"
- 1
例子:从当前目录开始查找所有扩展名为 .in 的文本文件,并找出包含 “thermcontact” 的行:
find . -name "*.in" | xargs grep "thermcontact"
- 1
5.3 locate
locate 让使用者可以很快速的搜寻某个路径。默认每天自动更新一次,所以使用locate 命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。如果数据库中没有查询的数据,则会报出locate: can not stat () `/var/lib/mlocate/mlocate.db’: No such file or directory该错误!updatedb即可!
yum -y install mlocate 如果是精简版CentOS系统需要安装locate命令
使用实例:
updatedb
locate /etc/sh 搜索etc目录下所有以sh开头的文件
locate pwd 查找和pwd相关的所有文件
- 1
- 2
- 3
5.4 whereis
whereis命令是定位可执行文件、源代码文件、帮助文件在文件系统中的位置。这些文件的属性应属于原始代码,二进制文件,或是帮助文件。
使用实例:
whereis ls 将和ls文件相关的文件都查找出来
- 1
5.5 which
which命令的作用是在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
使用实例:
which pwd 查找pwd命令所在路径
which java 查找path中java的路径
- 1
- 2
六、su、sudo
6.1 su
Linux su命令用于变更为其他使用者的身份,除 root 外,需要键入该使用者的密码。
使用权限:所有使用者。
语法
su [-fmp] [-c command] [-s shell] [--help] [--version] [-] [USER [ARG]]
- 1
参数说明:
-
-f 或 —fast 不必读启动档(如 csh.cshrc 等),仅用于 csh 或 tcsh
-
-m -p 或 —preserve-environment 执行 su 时不改变环境变数
-
-c command 或 —command=command 变更为帐号为 USER 的使用者并执行指令(command)后再变回原来使用者
-
-s shell 或 —shell=shell 指定要执行的 shell (bash csh tcsh 等),预设值为 /etc/passwd 内的该使用者(USER) shell
-
–help 显示说明文件
-
–version 显示版本资讯
-
- -l 或 —login 这个参数加了之后,就好像是重新 login 为该使用者一样,大部份环境变数(HOME SHELL USER等等)都是以该使用者(USER)为主,并且工作目录也会改变,如果没有指定 USER ,内定是 root
-
USER 欲变更的使用者帐号
-
ARG 传入新的 shell 参数
实例
变更帐号为 root 并在执行 ls 指令后退出变回原使用者
su -c ls root
- 1
变更帐号为 root 并传入 -f 参数给新执行的 shell
su root -f
- 1
变更帐号为 clsung 并改变工作目录至 clsung 的家目录(home dir)
su - clsung
- 1
切换用户
hnlinux@runoob.com:~$ whoami //显示当前用户
hnlinux
hnlinux@runoob.com:~$ pwd //显示当前目录
/home/hnlinux
hnlinux@runoob.com:~$ su root //切换到root用户
密码:root@runoob.com:/home/hnlinux# whoami
root
root@runoob.com:/home/hnlinux# pwd
/home/hnlinux
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
切换用户,改变环境变量
hnlinux@runoob.com:~$ whoami //显示当前用户
hnlinux
hnlinux@runoob.com:~$ pwd //显示当前目录
/home/hnlinux
hnlinux@runoob.com:~$ su - root //切换到root用户
密码:root@runoob.com:/home/hnlinux# whoami
root
root@runoob.com:/home/hnlinux# pwd //显示当前目录
/root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
su用于用户之间的切换。但是切换前的用户依然保持登录状态。如果是root 向普通或虚拟用户切换不需要密码,反之普通用户切换到其它任何用户都需要密码验证。
su test:切换到test用户,但是路径还是/root目录
su - test : 切换到test用户,路径变成了/home/test
su : 切换到root用户,但是路径还是原来的路径
su - : 切换到root用户,并且路径是/root
su不足:如果某个用户需要使用root权限、则必须要把root密码告诉此用户。退出返回之前的用户:exit
- 1
- 2
- 3
- 4
- 5
6.2 sudo
sudo是为所有想使用root权限的普通用户设计的。可以让普通用户具有临时使用root权限的权利。只需输入自己账户的密码即可。
进入sudo配置文件命令:
vi /etc/sudoer或者visudo
- 1
案例:
允许hadoop用户以root身份执行各种应用命令,需要输入hadoop用户的密码。
hadoop ALL=(ALL) ALL
案例:
只允许hadoop用户以root身份执行ls 、cat命令,并且执行时候免输入密码。
配置文件中:
hadoop ALL=NOPASSWD: /bin/ls, /bin/cat
su root -f
- 1
变更帐号为 clsung 并改变工作目录至 clsung 的家目录(home dir)
su - clsung
- 1
切换用户
hnlinux@runoob.com:~$ whoami //显示当前用户
hnlinux
hnlinux@runoob.com:~$ pwd //显示当前目录
/home/hnlinux
hnlinux@runoob.com:~$ su root //切换到root用户
密码:root@runoob.com:/home/hnlinux# whoami
root
root@runoob.com:/home/hnlinux# pwd
/home/hnlinux
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
切换用户,改变环境变量
hnlinux@runoob.com:~$ whoami //显示当前用户
hnlinux
hnlinux@runoob.com:~$ pwd //显示当前目录
/home/hnlinux
hnlinux@runoob.com:~$ su - root //切换到root用户
密码:root@runoob.com:/home/hnlinux# whoami
root
root@runoob.com:/home/hnlinux# pwd //显示当前目录
/root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
su用于用户之间的切换。但是切换前的用户依然保持登录状态。如果是root 向普通或虚拟用户切换不需要密码,反之普通用户切换到其它任何用户都需要密码验证。
su test:切换到test用户,但是路径还是/root目录
su - test : 切换到test用户,路径变成了/home/test
su : 切换到root用户,但是路径还是原来的路径
su - : 切换到root用户,并且路径是/root
su不足:如果某个用户需要使用root权限、则必须要把root密码告诉此用户。退出返回之前的用户:exit
- 1
- 2
- 3
- 4
- 5
七、下载与安装 yum
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
7.1 yum 语法
yum [options] [command] [package ...]
- 1
-
**options:**可选,选项包括-h(帮助),-y(当安装过程提示选择全部为”yes”),-q(不显示安装的过程)等等。
-
**command:**要进行的操作。
-
package操作的对象。
7.2 yum常用命令
-
1.列出所有可更新的软件清单命令:yum check-update
-
2.更新所有软件命令:yum update
-
3.仅安装指定的软件命令:yum install
-
4.仅更新指定的软件命令:yum update
-
5.列出所有可安裝的软件清单命令:yum list
-
6.删除软件包命令:yum remove
-
7.查找软件包 命令:yum search
-
8.清除缓存命令:
-
yum clean packages: 清除缓存目录下的软件包
-
yum clean headers: 清除缓存目录下的 headers
-
yum clean oldheaders: 清除缓存目录下旧的 headers
-
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软件包及旧的headers
实例 1
安装 pam-devel
[root@www ~] yum install pam-devel
Setting up Install Process
Parsing package install arguments
Resolving Dependencies <==先检查软件的属性相依问题
--> Running transaction check
---> Package pam-devel.i386 0:0.99.6.2-4.el5 set to be updated
--> Processing Dependency: pam = 0.99.6.2-4.el5 for package: pam-devel
--> Running transaction check
---> Package pam.i386 0:0.99.6.2-4.el5 set to be updated
filelists.xml.gz 100% |=========================| 1.6 MB 00:05
filelists.xml.gz 100% |=========================| 138 kB 00:00
-> Finished Dependency Resolution
……(省略)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
实例 2
移除 pam-devel
[root@www ~] yum remove pam-devel Setting up Remove Process Resolving Dependencies <==同样的,先解决属性相依的问题 --> Running transaction check ---> Package pam-devel.i386 0:0.99.6.2-4.el5 set to be erased --> Finished Dependency Resolution Dependencies Resolved ============================================================================= Package Arch Version Repository Size ============================================================================= Removing: pam-devel i386 0.99.6.2-4.el5 installed 495 k Transaction Summary ============================================================================= Install 0 Package(s) Update 0 Package(s) Remove 1 Package(s) <==还好,并没有属性相依的问题,单纯移除一个软件 Is this ok [y/N]: y Downloading Packages: Running rpm_check_debug Running Transaction Test Finished Transaction Test Transaction Test Succeeded Running Transaction Erasing : pam-devel ######################### [1/1] Removed: pam-devel.i386 0:0.99.6.2-4.el5 Complete!

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
实例 3
利用 yum 的功能,找出以 pam 为开头的软件名称有哪些?
[root@www ~] yum list pam*
Installed Packages
pam.i386 0.99.6.2-3.27.el5 installed
pam_ccreds.i386 3-5 installed
pam_krb5.i386 2.2.14-1 installed
pam_passwdqc.i386 1.0.2-1.2.2 installed
pam_pkcs11.i386 0.5.3-23 installed
pam_smb.i386 1.1.7-7.2.1 installed
Available Packages <==底下则是『可升级』的或『未安装』的
pam.i386 0.99.6.2-4.el5 base
pam-devel.i386 0.99.6.2-4.el5 base
pam_krb5.i386 2.2.14-10 base
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
7.3 国内 yum 源
网易(163)yum源是国内最好的yum源之一 ,无论是速度还是软件版本,都非常的不错。
将yum源设置为163 yum,可以提升软件包安装和更新的速度,同时避免一些常见软件版本无法找到。
安装步骤
首先备份/etc/yum.repos.d/CentOS-Base.repo
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
1
- 1
- 2
下载对应版本 repo 文件, 放入 /etc/yum.repos.d/ (操作前请做好相应备份)
-
CentOS5 :http://mirrors.163.com/.help/CentOS5-Base-163.repo
-
CentOS6 :http://mirrors.163.com/.help/CentOS6-Base-163.repo
-
CentOS7 :http://mirrors.163.com/.help/CentOS7-Base-163.repo
wget http://mirrors.163.com/.help/CentOS6-Base-163.repo
mv CentOS6-Base-163.repo CentOS-Base.repo
- 1
- 2
运行以下命令生成缓存
yum clean all
yum makecache
- 1
- 2
除了网易之外,国内还有其他不错的 yum 源,比如中科大和搜狐。
中科大的 yum 源,安装方法查看:https://lug.ustc.edu.cn/wiki/mirrors/help/centos
sohu 的 yum 源安装方法查看: http://mirrors.sohu.com/help/centos.htm
八. Linux 三剑客(awk,sed,grep)
awk、sed、grep更适合的方向:
-
grep 更适合单纯的查找或匹配文本
-
sed 更适合编辑匹配到的文本
-
awk 更适合格式化文本,对文本进行较复杂格式处理
8.1 awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
- 1
- 2
- 3
选项参数说明:
-
-F fs or —field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 -
-v var=value or —asign var=value
赋值一个用户定义变量。 -
-f scripfile or —file scriptfile
从脚本文件中读取awk命令。 -
-mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 -
-W compact or —compat, -W traditional or —traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 -
-W copyleft or —copyleft, -W copyright or —copyright
打印简短的版权信息。 -
-W help or —help, -W usage or —usage
打印全部awk选项和每个选项的简短说明。 -
-W lint or —lint
打印不能向传统unix平台移植的结构的警告。 -
-W lint-old or —lint-old
打印关于不能向传统unix平台移植的结构的警告。 -
-W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符 和 =不能代替^ 和 ^=;fflush无效。 -
-W re-interval or —re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -
-W source program-text or —source program-text
使用program-text作为源代码,可与-f命令混用。 -
-W version or —version
打印bug报告信息的版本。
基本用法
log.txt文本内容如下:
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
- 1
- 2
- 3
- 4
用法一:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号
- 1
实例:
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
# 格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
用法二:
awk -F #-F相当于内置变量FS, 指定分割字符
- 1
实例:
# 使用","分割 $ awk -F, '{print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 或者使用内建变量 $ awk 'BEGIN{FS=","} {print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割 $ awk -F '[ ,]' '{print $1,$2,$5}' log.txt --------------------------------------------- 2 this test 3 Are awk This's a 10 There apple
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
用法三:
awk -v # 设置变量
- 1
实例:
$ awk -va=1 '{print $1,$1+a}' log.txt
---------------------------------------------
2 3
3 4
This's 1
10 11
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
---------------------------------------------
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
用法四:
awk -f {awk脚本} {文件名}
- 1
实例:
$ awk -f cal.awk log.txt
- 1
运算符
| 运算符 | 描述 |
|
|
| — | — | — | — |
| = += -= = /= %= ^= *= | 赋值 |
|
|
| ?: | C条件表达式 |
|
|
| \ | \ |
| 逻辑或 |
| && | 逻辑与 |
|
|
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
|
|
| < <= > >= != == | 关系运算符 |
|
|
| 空格 | 连接 |
|
|
| + - | 加,减 |
|
|
| * / % | 乘,除与求余 |
|
|
| + - ! | 一元加,减和逻辑非 |
|
|
| ^ * | 求幂 |
|
|
| ++ – | 增加或减少,作为前缀或后缀 |
|
|
| $ | 字段引用 |
|
|
| in | 数组成员 |
|
|
过滤第一列大于2的行
$ awk '$1>2' log.txt #命令
#输出
3 Are you like awk
This's a test
10 There are orange,apple,mongo
12345
- 1
- 2
- 3
- 4
- 5
- 6
过滤第一列等于2的行
$ awk '$1==2 {print $1,$3}' log.txt #命令
#输出
2 is
123
- 1
- 2
- 3
- 4
过滤第一列大于2并且第二列等于’Are’的行
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令
#输出
3 Are you
123
- 1
- 2
- 3
- 4
内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
$ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt FILENAME ARGC FNR FS NF NR OFS ORS RS --------------------------------------------- log.txt 2 1 5 1 log.txt 2 2 5 2 log.txt 2 3 3 3 log.txt 2 4 4 4 $ awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt FILENAME ARGC FNR FS NF NR OFS ORS RS --------------------------------------------- log.txt 2 1 ' 1 1 log.txt 2 2 ' 1 2 log.txt 2 3 ' 2 3 log.txt 2 4 ' 1 4 # 输出顺序号 NR, 匹配文本行号 $ awk '{print NR,FNR,$1,$2,$3}' log.txt --------------------------------------------- 1 1 2 this is 2 2 3 Are you 3 3 This's a test 4 4 10 There are # 指定输出分割符 $ awk '{print $1,$2,$5}' OFS=" $ " log.txt --------------------------------------------- 2 $ this $ test 3 $ Are $ awk This's $ a $ 10 $ There $
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
使用正则,字符串匹配
# 输出第二列包含 "th",并打印第二列与第四列
$ awk '$2 ~ /th/ {print $2,$4}' log.txt
---------------------------------------------
this a
- 1
- 2
- 3
- 4
~ 表示模式开始。// 中是模式。
# 输出包含 "re" 的行
$ awk '/re/ ' log.txt
---------------------------------------------
3 Are you like awk
10 There are orange,apple,mongo
- 1
- 2
- 3
- 4
- 5
忽略大小写
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt
---------------------------------------------
2 this is a test
This's a test
- 1
- 2
- 3
- 4
模式取反
$ awk '$2 !~ /th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
$ awk '!/th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
awk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
-
BEGIN{ 这里面放的是执行前的语句 }
-
END {这里面放的是处理完所有的行后要执行的语句 }
-
{这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
- 1
- 2
- 3
- 4
- 5
- 6
我们的 awk 脚本如下:
$ cat cal.awk #!/bin/awk -f #运行前 BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n" printf "---------------------------------------------\n" } #运行中 { math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5 } #运行后 END { printf "---------------------------------------------\n" printf " TOTAL:%10d %8d %8d \n", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR } 123456789101112131415161718192021222324
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
我们来看一下执行结果:
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
另外一些实例
AWK 的 hello world 程序为:
BEGIN { print "Hello, world!" }
- 1
计算文件大小
$ ls -l *.txt | awk '{sum+=$5} END {print sum}'
--------------------------------------------------
666581
- 1
- 2
- 3
从文件中找出长度大于 80 的行:
awk 'length>80' log.txt
- 1
打印九九乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
- 1
8.2 sed
Linux sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
- 1
参数说明:
-
-e<script>或--expression=<script>以选项中指定的script来处理输入的文本文件。 -
-f
或–file=以选项中指定的script文件来处理输入的文本文件。
-
-h或–help 显示帮助。
-
-n或–quiet或–silent 仅显示script处理后的结果。
-
-V或–version 显示版本信息。
动作说明:
-
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
-
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
-
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
-
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
-
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
-
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
实例
在testfile文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 4a\newLine testfile
- 1
首先查看testfile中的内容如下:
$ cat testfile #查看testfile 中的内容
HELLO LINUX!
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
- 1
- 2
- 3
- 4
- 5
使用sed命令后,输出结果如下:
$ sed -e 4a\newline testfile #使用sed 在第四行后添加新字符串
HELLO LINUX! #testfile文件原有的内容
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
newline
- 1
- 2
- 3
- 4
- 5
- 6
以行为单位的新增/删除
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~] nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
.....(后面省略).....
- 1
- 2
- 3
- 4
- 5
sed 的动作为 ‘2,5d’ ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行罗~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 ‘’ 两个单引号括住喔!
只要删除第 2 行
nl /etc/passwd | sed '2d'
- 1
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
- 1
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@www ~] nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
- 1
- 2
- 3
- 4
- 5
- 6
那如果是要在第二行前
nl /etc/passwd | sed '2i drink tea'
- 1
如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or … 与 drink beer?
[root@www ~] nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
每一行之间都必须要以反斜杠『 \ 』来进行新行的添加喔!所以,上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。
以行为单位的替换与显示
将第2-5行的内容取代成为『No 2-5 number』呢?
[root@www ~] nl /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
.....(后面省略).....
- 1
- 2
- 3
- 4
- 5
透过这个方法我们就能够将数据整行取代了!
仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~] nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
- 1
- 2
- 3
- 4
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。
数据的搜寻并显示
搜索 /etc/passwd有root关键字的行
nl /etc/passwd | sed '/root/p'
1 root:x:0:0:root:/root:/bin/bash
1 root:x:0:0:root:/root:/bin/bash
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
3 bin:x:2:2:bin:/bin:/bin/sh
4 sys:x:3:3:sys:/dev:/bin/sh
5 sync:x:4:65534:sync:/bin:/bin/sync
....下面忽略
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果root找到,除了输出所有行,还会输出匹配行。
使用-n的时候将只打印包含模板的行。
nl /etc/passwd | sed -n '/root/p'
1 root:x:0:0:root:/root:/bin/bash
- 1
- 2
数据的搜寻并删除
删除/etc/passwd所有包含root的行,其他行输出
nl /etc/passwd | sed '/root/d'
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
3 bin:x:2:2:bin:/bin:/bin/sh
....下面忽略
#第一行的匹配root已经删除了
- 1
- 2
- 3
- 4
- 5
数据的搜寻并执行命令
搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}'
1 root:x:0:0:root:/root:/bin/blueshell
- 1
- 2
最后的q是退出。
数据的搜寻并替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代。基本上 sed 的搜寻与替代的与 vi 相当的类似!他有点像这样:
sed 's/要被取代的字串/新的字串/g'
- 1
先观察原始信息,利用 /sbin/ifconfig 查询 IP
[root@www ~] /sbin/ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
.....(以下省略).....
- 1
- 2
- 3
- 4
- 5
- 6
本机的ip是192.168.1.100。
将 IP 前面的部分予以删除
[root@www ~] /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g'
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
- 1
- 2
接下来则是删除后续的部分,亦即:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
将 IP 后面的部分予以删除
[root@www ~] /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
192.168.1.100
- 1
- 2
多点编辑
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1 root:x:0:0:root:/root:/bin/blueshell
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
- 1
- 2
- 3
-e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。
直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向!不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试!我们还是使用文件 regular_express.txt 文件来测试看看吧!
regular_express.txt 文件内容如下:
[root@www ~] cat regular_express.txt
runoob.
google.
taobao.
facebook.
zhihu-
weibo-
- 1
- 2
- 3
- 4
- 5
- 6
- 7
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~] sed -i 's/\.$/\!/g' regular_express.txt
[root@www ~] cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
:q:q
利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test:
[root@www ~] sed -i '$a # This is a test' regular_express.txt
[root@www ~] cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
# This is a test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test!
sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订!
追加行的说明:
sed -e 4a\newline testfile
- 1
a 动作是在匹配的行之后追加字符串,追加的字符串中可以包含换行符(实现追加多行的情况)。
追加一行的话前后都不需要添加换行符 \n,只有追加多行时在行与行之间才需要添加换行符(最后一行最后也无需添加,添加的话会多出一个空行)。
man sed 信息:
Append text, which has each embedded newline preceded by a backslash.
- 1
例如:
4 行之后添加一行:
sed -e '4 a newline' testfile
- 1
4 行之后追加 2 行:
sed -e '4 a newline\nnewline2' testfile
- 1
4 行之后追加 3 行(2 行文字和 1 行空行)
sed -e '4 a newline\nnewline2\n' testfile
- 1
4 行之后追加 1 行空行:
#错误:sed -e '4 a \n' testfile
sed -e '4 a \ ' testfile 实际上
- 1
- 2
实际上是插入了一个含有一个空格的行,插入一个完全为空的空行没有找到方法(不过应该没有这个需求吧,都要插入行了插入空行干嘛呢?)
添加空行:
# 可以添加一个完全为空的空行
sed '4 a \\'
# 可以添加两个完全为空的空行
sed '4 a \\n'
- 1
- 2
- 3
- 4
- 5
8.3 grep
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
- 1
参数:
-
-a 或 —text : 不要忽略二进制的数据。
-
-A<显示行数> 或 —after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
-b 或 —byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-
-B<显示行数> 或 —before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-
-c 或 —count : 计算符合样式的列数。
-
-C<显示行数> 或 —context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
-d <动作> 或 —directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-
-e<范本样式> 或 —regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-
-E 或 —extended-regexp : 将样式为延伸的正则表达式来使用。
-
-f<规则文件> 或 —file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-
-F 或 —fixed-regexp : 将样式视为固定字符串的列表。
-
-G 或 —basic-regexp : 将样式视为普通的表示法来使用。
-
-h 或 —no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-
-H 或 —with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-
-i 或 —ignore-case : 忽略字符大小写的差别。
-
-l 或 —file-with-matches : 列出文件内容符合指定的样式的文件名称。
-
-L 或 —files-without-match : 列出文件内容不符合指定的样式的文件名称。
-
-n 或 —line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-
-o 或 —only-matching : 只显示匹配PATTERN 部分。
-
-q 或 —quiet或–silent : 不显示任何信息。
-
-r 或 —recursive : 此参数的效果和指定”-d recurse”参数相同。
-
-s 或 —no-messages : 不显示错误信息。
-
-v 或 —revert-match : 显示不包含匹配文本的所有行。
-
-V 或 —version : 显示版本信息。
-
-w 或 —word-regexp : 只显示全字符合的列。
-
-x —line-regexp : 只显示全列符合的列。
-
-y : 此参数的效果和指定”-i”参数相同。
实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
- 1
结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
- 1
- 2
- 3
- 4
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串”update”的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi
- 1
输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过”-v”参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*
- 1
结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行
testfile1:helLinux!
testfile1:Linis a free Unix-type operating system.
testfile1:Lin
testfile_1:HELLO LINUX!
testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
testfile_1:THIS IS A LINUX TESTFILE!
testfile_2:HELLO LINUX!
testfile_2:Linux is a free unix-type opterating system.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
题外话
初入计算机行业的人或者大学计算机相关专业毕业生,很多因缺少实战经验,就业处处碰壁。下面我们来看两组数据:
-
2023届全国高校毕业生预计达到1158万人,就业形势严峻;
-
国家网络安全宣传周公布的数据显示,到2027年我国网络安全人员缺口将达327万。
一方面是每年应届毕业生就业形势严峻,一方面是网络安全人才百万缺口。
6月9日,麦可思研究2023年版就业蓝皮书(包括《2023年中国本科生就业报告》《2023年中国高职生就业报告》)正式发布。
2022届大学毕业生月收入较高的前10个专业
本科计算机类、高职自动化类专业月收入较高。2022届本科计算机类、高职自动化类专业月收入分别为6863元、5339元。其中,本科计算机类专业起薪与2021届基本持平,高职自动化类月收入增长明显,2022届反超铁道运输类专业(5295元)排在第一位。
具体看专业,2022届本科月收入较高的专业是信息安全(7579元)。对比2018届,电子科学与技术、自动化等与人工智能相关的本科专业表现不俗,较五年前起薪涨幅均达到了19%。数据科学与大数据技术虽是近年新增专业但表现亮眼,已跻身2022届本科毕业生毕业半年后月收入较高专业前三。五年前唯一进入本科高薪榜前10的人文社科类专业——法语已退出前10之列。

“没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。
网络安全行业特点
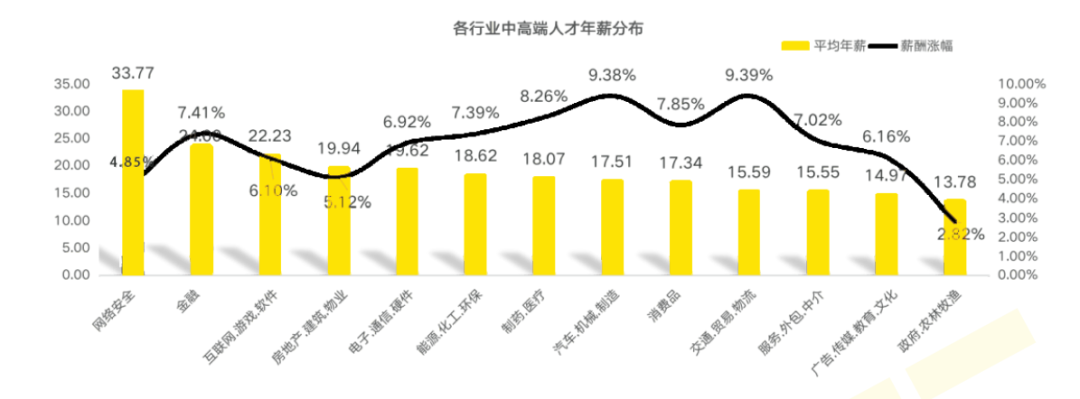
1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万!
2、人才缺口大,就业机会多
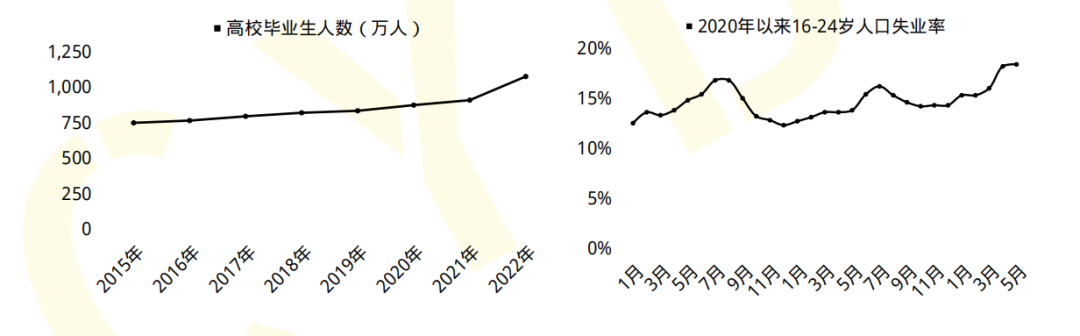
2019年9月18日《中华人民共和国中央人民政府》官方网站发表:我国网络空间安全人才 需求140万人,而全国各大学校每年培养的人员不到1.5W人。猎聘网《2021年上半年网络安全报告》预测2027年网安人才需求300W,现在从事网络安全行业的从业人员只有10W人。
行业发展空间大,岗位非常多
网络安全行业产业以来,随即新增加了几十个网络安全行业岗位︰网络安全专家、网络安全分析师、安全咨询师、网络安全工程师、安全架构师、安全运维工程师、渗透工程师、信息安全管理员、数据安全工程师、网络安全运营工程师、网络安全应急响应工程师、数据鉴定师、网络安全产品经理、网络安全服务工程师、网络安全培训师、网络安全审计员、威胁情报分析工程师、灾难恢复专业人员、实战攻防专业人员…
职业增值潜力大
网络安全专业具有很强的技术特性,尤其是掌握工作中的核心网络架构、安全技术,在职业发展上具有不可替代的竞争优势。
随着个人能力的不断提升,所从事工作的职业价值也会随着自身经验的丰富以及项目运作的成熟,升值空间一路看涨,这也是为什么受大家欢迎的主要原因。
从某种程度来讲,在网络安全领域,跟医生职业一样,越老越吃香,因为技术愈加成熟,自然工作会受到重视,升职加薪则是水到渠成之事。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
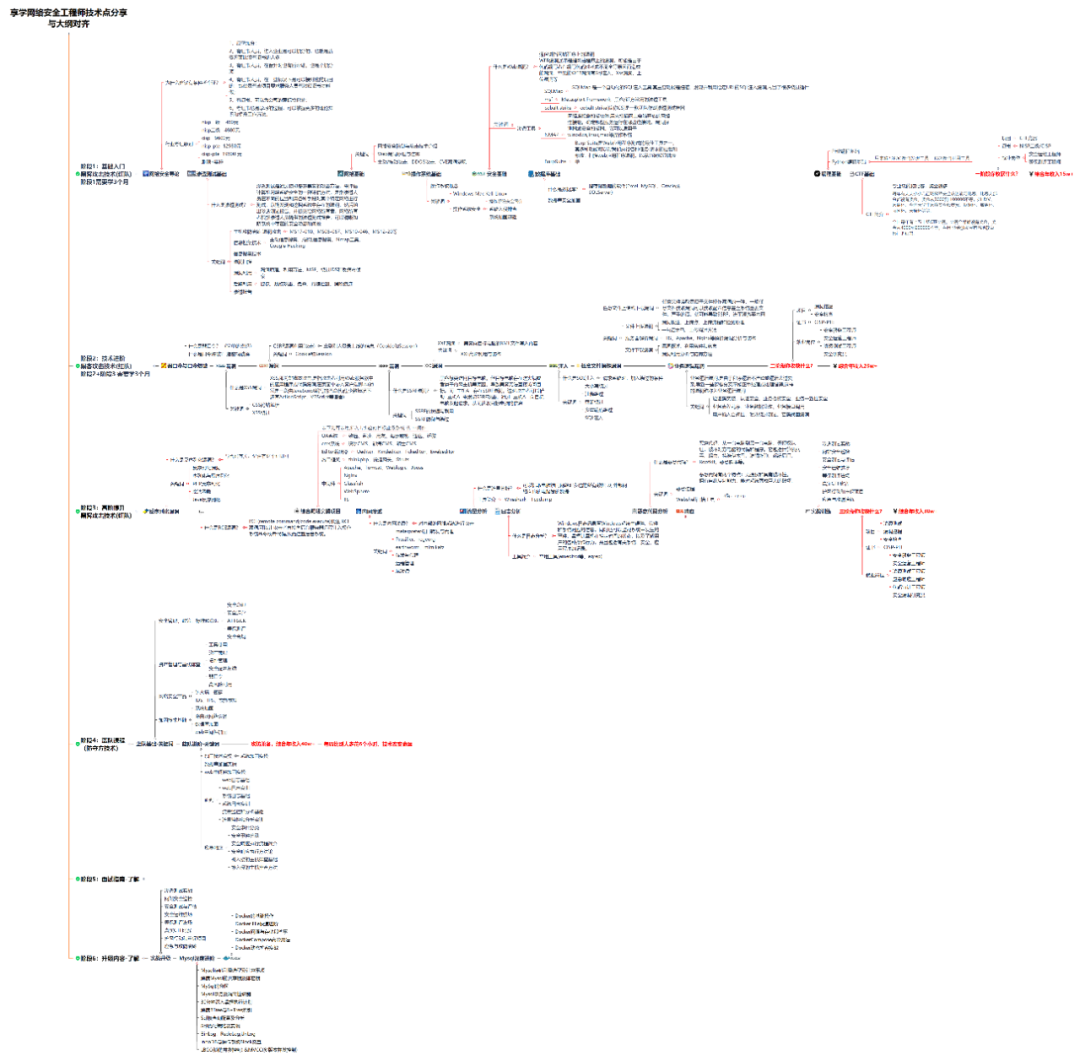
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

