
- 1省钱!NewBing硬核新玩法;手把手教你训练AI模特;用AI替代同事的指南;B站最易上手AI绘画教程 | ShowMeAI日报_ai绘画教程bilibili
- 2一口气说出 Redis 16 个常见使用场景_redis使用场景
- 3动态规划-思考解决动态规划问题_你的公司老板给了你一张n×n个格子组成的动态规划
- 4B样条曲线优化各种路径规划算法,matlab栅格地图。_b样条优化
- 5three.js流动线_threejs流动线
- 6自然语言处理工具包:NLTKspaCy
- 7超星高级语言程序设计实验作业 (实验01顺序程序设计)_分别输入三个浮点数代表a、b、c的值;如果c的值为0,直接输出-1,否则计算并输出多项
- 8笔记本wifi与台式机、内网服务器共网、共享wifi详细教程_服务器没有网,怎么共享笔记本网络
- 9核函数kernal
- 10Android~获取WiFi MAC地址和IP方法汇总_android 获取本机wlan mac地址
自然语言处理: 第三十章Hugging face使用指南之——trainer
赞
踩
原文连接: Trainer (huggingface.co)
最近在用HF的transformer库自己做训练,所以用着了transformers.Trainer,这里记录下用法
基本参数
class transformers.Trainer(
model: Union = None,
args: TrainingArguments = None,
data_collator: Optional = None,
train_dataset: Union = None,
eval_dataset: Union = None,
tokenizer: Optional = None,
model_init: Optional = None,
compute_metrics: Optional = None,
callbacks: Optional = None,
optimizers: Tuple = (None, None),
preprocess_logits_for_metrics: Optional = None )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
model
mode : 可以是一个集成了 transformers.PreTrainedMode 或者torch.nn.module的模型,官方提到trainer对 transformers.PreTrainedModel进行了优化,建议使用。transformers.PreTrainedModel,用于可以通过自己继承这个父类来实现huggingface的model自定义,自定义的过程和torch非常相似,这部分放到huggingface的自定义里讲。
而model_init_则是这么个东西,说白了就是一个返回上述model的函数
def model_init():
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None
)
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
args
args:超参数的定义,这部分也是trainer的重要功能,大部分训练相关的参数都是这里设置的,非常的方便,
具体可以参考hf: Trainer (huggingface.co)
-
output_dir (
str) – 我们的模型训练过程中可能产生的文件存放的路径,包括了模型文件,checkpoint,log文件等 -
overwrite_output_dir (
bool, optional, defaults toFalse) – 设置为true则自动覆写output dir下的文件,如果output_dir指向 model的checkpoint(检查点,即保存某个epochs或者steps下的模型以及相关配置文件),则自动从这个checkpoint文件读取模型从这个点开始重新训练; -
do_train(这三个参数和trainer没什么关系,可以不用, 因为仅仅是作为某个超参数项用于后续自己写python XX py脚本的时候方便用的 :)
-
do_eval(同上)
-
do_predict(同上)
-
evaluation_strategy (
strorIntervalStrategy, optional, defaults to"no") –
The evaluation strategy to adopt during training. Possible values are:"no": No evaluation is done during training."steps": Evaluation is done (and logged) everyeval_steps."epoch": Evaluation is done at the end of each epoch.
这里的evaluation_strategy用来设定eval的方式,用steps比较方便,因为可以通过后面的eval steps来控制eval的频率,每个epoch的话感觉太费时间了。
- prediction_loss_only (
bool, optional, defaults to False) – When performing evaluation and generating predictions, only returns the loss.
设置为True则仅返回损失,注意这个参数比较重要,我们如果要通过trainer的custome metric来自定义模型的eval结果,比如看auc之类的,则这里要设置为False,否则custom metric会被模型忽略而仅仅输出training data的loss。
- per_device_train_batch_size (
int, optional, defaults to 8) – The batch size per GPU/TPU core/CPU for training.
trainer默认自动开启torch的多gpu模式,这里是设置每个gpu上的样本数量,一般来说,多gpu模式希望多个gpu的性能尽量接近,否则最终多gpu的速度由最慢的gpu决定,比如快gpu 跑一个batch需要5秒,跑10个batch 50秒,慢的gpu跑一个batch 500秒,则快gpu还要等慢gpu跑完一个batch然后一起更新weights,速度反而更慢了。
- per_device_eval_batch_size (
int, optional, defaults to 8) – The batch size per GPU/TPU core/CPU for evaluation.
和上面类似,只不过对eval的batch做设定。
- gradient_accumulation_steps (
int, optional, defaults to 1) –
Number of updates steps to accumulate the gradients for, before performing a backward/update pass.
显存重计算的技巧,很方便很实用,默认为1,如果设置为n,则我们forward n次,得到n个loss的累加后再更新参数。
显存重计算是典型的用时间换空间,比如我们希望跑256的大点的batch,不希望跑32这样的小batch,因为觉得小batch不稳定,会影响模型效果,但是gpu显存又无法放下256的batchsize的数据,此时我们就可以进行显存重计算,将这个参数设置为256/32=8即可。用torch实现就是forward,计算loss 8次,然后再optimizer.step()
注意,当我们设置了显存重计算的功能,则eval steps之类的参数自动进行相应的调整,比如我们设置这个参数前,256的batch,我们希望10个batch评估一次,即10个steps进行一次eval,当时改为batch size=32并且 gradient_accumulation_steps=8,则默认trainer会 8*10=80个steps 进行一次eval。
- eval_accumulation_steps (
int, optional) – Number of predictions steps to accumulate the output tensors for, before moving the results to the CPU. If left unset, the whole predictions are accumulated on GPU/TPU before being moved to the CPU (faster but requires more memory).
功能类似上面的,不赘述了。
- learning_rate (
float, optional, defaults to 5e-5) – The initial learning rate for AdamW optimizer.
学习率的初始值,默认使用AdamW的优化算法,当然也可以在自定义设置中就该为其它优化算法;
- weight_decay (
float, optional, defaults to 0) – The weight decay to apply (if not zero) to all layers except all bias and LayerNorm weights in AdamW optimizer.
这里trainer是默认不对layernorm和所有layer的biase进行weight decay的,因为模型通过大量语料学习到的知识主要是保存在weights中,这也是实际finetune bert的时候一个会用到的技巧,即分层weight decay(其实就是l2正则化),biase和layernorm的参数无所谓,但是保存了重要知识的weight我们不希望它变化太大,weight decay虽然是限制weight的大小的,但是考虑到一般良好的预训练模型的权重都比较稳定,所以也可以间接约束权重太快发生太大的变化。
- adam_beta1 (
float, optional, defaults to 0.9) – The beta1 hyperparameter for the AdamW optimizer. - adam_beta2 (
float, optional, defaults to 0.999) – The beta2 hyperparameter for the AdamW optimizer. - adam_epsilon (
float, optional, defaults to 1e-8) – The epsilon hyperparameter for the AdamW optimizer.
AdamW优化算法的超参数,具体可见adamw的原理解析:当前训练神经网络最快的方式:AdamW优化算法+超级收敛 - 知乎 (zhihu.com)
- max_grad_norm (
float, optional, defaults to 1.0) – Maximum gradient norm (for gradient clipping).
梯度裁剪功能,控制梯度的最大值,避免过大的梯度给权重带来过大的变化从而使得模型变得不稳定。
- num_train_epochs (
float, optional, defaults to 3.0) – Total number of training epochs to perform (if not an integer, will perform the decimal part percents of the last epoch before stopping training).
epochs参数无需多言;
- max_steps (
int, optional, defaults to -1) – If set to a positive number, the total number of training steps to perform. Overridesnum_train_epochs.
1个step表示处理完一个batch,功能和epochs类似,二者会冲突只能设置一个。
lr_scheduler_type (str or SchedulerType, optional, defaults to "linear") – The scheduler type to use. See the documentation of SchedulerType, for all possible values.
huggingface定义的一些lr scheduler的处理方法,关于不同的lr scheduler的理解,其实看学习率变化图就行:
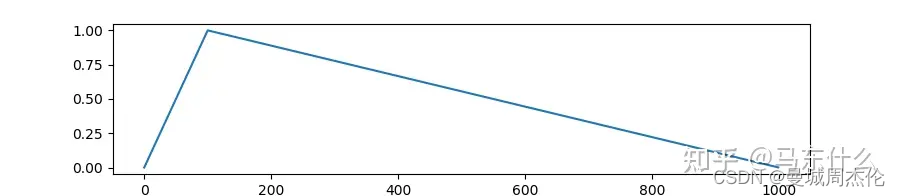
这是linear策略的学习率变化曲线。结合下面的两个参数来理解
- warmup_ratio (
float, optional, defaults to 0.0) – Ratio of total training steps used for a linear warmup from 0 tolearning_rate.
linear策略初始会从0到我们设定的初始学习率,假设我们的初始学习率为1,则模型会经过
warmup_ratio*总的steps数 次达到初始学习率
- warmup_steps (
int, optional, defaults to 0) – Number of steps used for a linear warmup from 0 tolearning_rate. Overrides any effect ofwarmup_ratio.
直接指定经过多少个steps到达初始学习率;
这里二者的默认值为0,所以我们一开始用的就是初始学习率,然后初始学习率会随着steps的数量线性下降,例如初始学习率为100,steps的数量为100,则每次会下降1的学习率。但是不会真的到0,没记错的话一般会使用一个非常小的数作为最终的学习率
- logging_dir (
str, optional) – TensorBoard log directory. Will default to runs/CURRENT_DATETIME_HOSTNAME. - logging_strategy (
strorIntervalStrategy, optional, defaults to"steps") –
The logging strategy to adopt during training. Possible values are:"no": No logging is done during training."epoch": Logging is done at the end of each epoch."steps": Logging is done everylogging_steps.
- logging_first_step (
bool, optional, defaults toFalse) – Whether to log and evaluate the firstglobal_stepor not. - logging_steps (
int, optional, defaults to 500) – Number of update steps between two logs iflogging_strategy="steps".
logging 相关参数,看注释很好理解,保存训练过程中的loss,梯度等信息,便于后期使用tensorboard这类的工具来帮助分析
- save_strategy (
strorIntervalStrategy, optional, defaults to"steps") –
The checkpoint save strategy to adopt during training. Possible values are:"no": No save is done during training."epoch": Save is done at the end of each epoch."steps": Save is done everysave_steps.
- save_steps (
int, optional, defaults to 500) – Number of updates steps before two checkpoint saves ifsave_strategy="steps". - save_total_limit (
int, optional) – If a value is passed, will limit the total amount of checkpoints. Deletes the older checkpoints inoutput_dir.
checkpoint相关,也很好理解了,注意最好设置save_total_limit=一个固定常数,因为一个model的checkpoint是保存整个完整的model的,可能一个checkpoint就是GB级别的,存太多的话费硬盘。
- no_cuda (
bool, optional, defaults toFalse) – Whether to not use CUDA even when it is available or not.
是否使用cuda。
- seed (
int, optional, defaults to 42) – Random seed that will be set at the beginning of training. To ensure reproducibility across runs, use themodel_init()function to instantiate the model if it has some randomly initialized parameters.
随机固定,保证可复现
- fp16 (
bool, optional, defaults toFalse) – Whether to use 16-bit (mixed) precision training instead of 32-bit training. - fp16_opt_level (
str, optional, defaults to ‘O1’) – Forfp16training, Apex AMP optimization level selected in [‘O0’, ‘O1’, ‘O2’, and ‘O3’]. See details on the Apex documentation. - fp16_backend (
str, optional, defaults to"auto") – The backend to use for mixed precision training. Must be one of"auto","amp"or"apex"."auto"will use AMP or APEX depending on the PyTorch version detected, while the other choices will force the requested backend. - fp16_full_eval (
bool, optional, defaults toFalse) – Whether to use full 16-bit precision evaluation instead of 32-bit. This will be faster and save memory but can harm metric values.
混合精度训练相关参数,可以支持amp和apex的后端,关于混合精度的话题还是比较大的,后续研究完混合精度训练的一些注意事项已经apex的原理再单独写一篇总结一下混合精度训练以及apex的用法。
- local_rank (
int, optional, defaults to -1) – Rank of the process during distributed training.
trainer默认是用torch.distributed的api来做多卡训练的,因此可以直接支持多机多卡,单机多卡,单机单卡,如果要强制仅使用指定gpu,则通过os cuda visible设置可见gpu即可。
需要注意的是 torch的gpu的id是基于速度的,即速度越快的gpu其gpu id越小,gpu id=0对应最快的gpu,这和nvdia-smi的设定是不同的,PyTorch 代码中 GPU 编号与 nvidia-smi 命令中的 GPU 编号不一致问题解决方法_nvidia-smi查看的gpu数量与实际不符-CSDN博客
简单的做法是通过torch.get_device_name的方式获取当前gpu的名字然后对照,另外上面的链接提到的方法也比较方便。
- tpu_num_cores (
int, optional) – When training on TPU, the number of TPU cores (automatically passed by launcher script). - debug (
bool, optional, defaults toFalse) – When training on TPU, whether to print debug metrics or not.
tpu设置相关。
dataloader_num_workers (int, optional, defaults to 0) – Number of subprocesses to use for data loading (PyTorch only). 0 means that the data will be loaded in the main process.
- dataloader_drop_last (
bool, optional, defaults toFalse) – Whether to drop the last incomplete batch (if the length of the dataset is not divisible by the batch size) or not.
是否drop最后一批不满batch size的数据,最好设置为false,不要浪费数据。注意,trainer内部封装了dataloader,但是穿的数据参数使用的是dataset(没试过dataloader能不能直接用,但是考虑到trainer很方便的动态padding的方式,我还是用dataset来整),num_workers不用介绍了很简单了。
- eval_steps (
int, optional) – Number of update steps between two evaluations ifevaluation_strategy="steps". Will default to the same value aslogging_stepsif not set.
很好理解了,不赘述
- past_index (
int, optional, defaults to -1) – Some models like TransformerXL or :docXLNet <../model_doc/xlnet>can make use of the past hidden states for their predictions. If this argument is set to a positive int, theTrainerwill use the corresponding output (usually index 2) as the past state and feed it to the model at the next training step under the keyword argumentmems.
看注释很好理解了。
- run_name (
str, optional) – A descriptor for the run. Typically used for wandb logging.
运行名,和wandb的分析工具有关
- disable_tqdm (
bool, optional) – Whether or not to disable the tqdm progress bars and table of metrics produced byNotebookTrainingTrackerin Jupyter Notebooks. Will default toTrueif the logging level is set to warn or lower (default),Falseotherwise.
trainer训练的过程会显示progressbar通过这里来关闭,不建议关闭,不好看。。。
- remove_unused_columns (
bool, optional, defaults toTrue) –
If usingdatasets.Datasetdatasets, whether or not to automatically remove the columns unused by the model forward method.
(Note that this behavior is not implemented for<a href="https://link.zhihu.com/?target=https%3A//huggingface.co/transformers/main_classes/trainer.html%23transformers.TFTrainer" class=" wrap external" target="_blank" rel="nofollow noreferrer" data-za-detail-view-id="1043">TFTrainer</a>yet.)
自动删除模型forward的时候不需要的输出,因为 trainer的dataset的return需要返回包含input ids,等这类和model相关的keys,所以这里会有这么个参数,需要注意dataset的设置里要返回字典,这个字典的key要和model的forward的数据的名字对应上。
- label_names (
List[str], optional) –
The list of keys in your dictionary of inputs that correspond to the labels.
Will eventually default to["labels"]except if the model used is one of theXxxForQuestionAnsweringin which case it will default to["start_positions",``"end_positions"]. 模型的label参数设定,默认就好,注意dataset返回labels的时候keys用labels就行。 - load_best_model_at_end (
bool, optional, defaults toFalse) –
Whether or not to load the best model found during training at the end of training.
Note
When set toTrue, the parameterssave_strategyandsave_stepswill be ignored and the model will be saved after each evaluation. 注释写的比较清楚了,不过没关系,模型的eval的输出print的结果不受影响 - metric_for_best_model (
str, optional) –
Use in conjunction withload_best_model_at_endto specify the metric to use to compare two different models. Must be the name of a metric returned by the evaluation with or without the prefix"eval_". Will default to"loss"if unspecified andload_best_model_at_end=True(to use the evaluation loss).
If you set this value,greater_is_betterwill default toTrue. Don’t forget to set it toFalseif your metric is better when lower. - greater_is_better (
bool, optional) –
Use in conjunction withload_best_model_at_endandmetric_for_best_modelto specify if better models should have a greater metric or not. Will default to:Trueifmetric_for_best_modelis set to a value that isn’t"loss"or"eval_loss".Falseifmetric_for_best_modelis not set, or set to"loss"or"eval_loss".
eval相关,注释也写的比较清楚了,因为我们可能涉及到auc这里的自定义eval metric,所以自定义metric的函数里最终必须返回字典,比如{‘AUC’,roc_auc_score(y_true,y_pred},然后metric for best model设置为 AUC即可。
- ignore_data_skip (
bool, optional, defaults toFalse) – When resuming training, whether or not to skip the epochs and batches to get the data loading at the same stage as in the previous training. If set toTrue, the training will begin faster (as that skipping step can take a long time) but will not yield the same results as the interrupted training would have.
比如batch为256,一个epochs有10个batch,加入我们训练到第5个batch,即0.5个epochs的时候退出了,那么可以通过将该参数设置为True,从第5个batch重新开始训练
- sharded_ddp (
bool,stror list ofShardedDDPOption, optional, defaults toFalse) –
Use Sharded DDP training from FairScale (in distributed training only). This is an experimental feature.
A list of options along the following:"simple": to use first instance of sharded DDP released by fairscale (ShardedDDP) similar to ZeRO-2."zero_dp_2": to use the second instance of sharded DPP released by fairscale (FullyShardedDDP) in Zero-2 mode (withreshard_after_forward=False)."zero_dp_3": to use the second instance of sharded DPP released by fairscale (FullyShardedDDP) in Zero-3 mode (withreshard_after_forward=True)."offload": to add ZeRO-offload (only compatible with"zero_dp_2"and"zero_dp_3").
If a string is passed, it will be split on space. If a bool is passed, it will be converted to an empty list for False and ["simple"] for True.
shareddpp,简单来说通过一些策略来加快多gpu的速度,因为这部分比较多,后续放到torch的性能优化里来讲(transformer的trainer设计和pytorch lightning的非常相似,二者的这些优化策略基本一毛一样)Sharded:在相同显存的情况下使pytorch模型的大小参数加倍_ddp_sharded-CSDN博客
deepspeed (str or dict, optional) – Use Deepspeed. This is an experimental feature and its API may evolve in the future. The value is either the location of DeepSpeed json config file (e.g., ds_config.json) or an already loaded json file as a dict”
感觉看trainer的设计基本上能把torch的许多优化方法和训练技巧都理解一遍了。
- label_smoothing_factor (
float, optional, defaults to 0.0) – The label smoothing factor to use. Zero means no label smoothing, otherwise the underlying onehot-encoded labels are changed from 0s and 1s tolabel_smoothing_factor/num_labelsand1``-``label_smoothing_factor``+``label_smoothing_factor/num_labelsrespectively.
label smooth功能,直接对标签下手,而不再去做 label smooth loss这种麻烦的工作了,但是也正因为直接修改了分类的标签,我们计算metric的时候,对于auc这种方法,需要自己在自定义的metric里把标签反推回去,否则会报错。
- adafactor (
bool, optional, defaults toFalse) – Whether or not to use the AdamW.
是否使用adafactor优化算法。具体算法原理可谷歌or百度
- group_by_length (
bool, optional, defaults toFalse) – Whether or not to group together samples of roughly the same length in the training dataset (to minimize padding applied and be more efficient). Only useful if applying dynamic padding.
trainer的一个非常好用的功能,即动态padding,对序列进行分bucket的处理,即将长度差不多的输入分为一组,用于后续的padding,注意padding的功能不是这个参数决定的,而是根据data collator来实现的,后面会提到。当然我们也完全可以自己手动做动态padding的处理,这里需要用到 dataloader中的collate_fn的参数来定义。
- length_column_name (
str, optional, defaults to"length") – Column name for precomputed lengths. If the column exists, grouping by length will use these values rather than computing them on train startup. Ignored unlessgroup_by_lengthisTrueand the dataset is an instance ofDataset. - report_to (
strorList[str], optional, defaults to"all") – The list of integrations to report the results and logs to. Supported platforms are"azure_ml","comet_ml","mlflow","tensorboard"and"wandb". Use"all"to report to all integrations installed,"none"for no integrations.
注释比较简单不赘述。
- ddp_find_unused_parameters (
bool, optional) – When using distributed training, the value of the flagfind_unused_parameterspassed toDistributedDataParallel. Will default toFalseif gradient checkpointing is used,Trueotherwise.
DistributedDataParallel中的find_unused_parameters
- dataloader_pin_memory (
bool, optional, defaults toTrue)) – Whether you want to pin memory in data loaders or not. Will default toTrue.
这里简单科普下pin_memory,通常情况下,数据在内存中要么以锁页的方式存在,要么保存在虚拟内存(磁盘)中,设置为True后,数据直接保存在锁页内存中,后续直接传入cuda;否则需要先从虚拟内存中传入锁页内存中,再传入cuda,这样就比较耗时了,但是对于内存的大小要求比较高。
- skip_memory_metrics (
bool, optional, defaults toFalse)) – Whether to skip adding of memory profiler reports to metrics. Defaults toFalse.
是否将内存使用情况保存到metrics中去,基本没用过。。。
data_collator
data_collator (DataCollator,optional) – The function to use to form a batch from a list of elements of train_datasetor eval_dataset. Will default to default_data_collator()if no tokenizeris provided, an instance of DataCollatorWithPadding()otherwise.
data_collator是huggingface自定义的数据处理函数。
这里定义了很多很方便的数据预处理函数,比如mlm任务对应的mask方法,会自动帮你进行mask并且返回mask后的结果以及对应的label便于直接训练。
比较可贵的是,这里实现了大部分常见的策略,包括了普通mask和全词mask,并且,这些函数在底层都是放到data loader的collate fn部分的,这也意味着我们可以自己定义一个dataload然后将这些函数直接通过transformers.data.data_collator.XXXX函数传入collate_fn参数从而方便快速地实现数据的准备,参考Pytorch collate_fn用法 - 三年一梦 - 博客园 (cnblogs.com)
collate fn是一个很好用的功能,因为dataloader默认是不支持长度不同的batch的,但是通过collate fn可以很方便地打破这个限制,前面提到的动态padding就可以通过这里来实现从而节约大量的内存。
不过可惜的是,trainer不支持简单的一个自定义function作为data collator,但也没事,
我们可以自己仿照官方transformers/src/transformers/data/data_collator.py at 66446909b236c17498276857fa88e23d2c91d004 · huggingface/transformers (github.com)的实现写一个自定义的个性化的方法,语法非常简单按照上述的范式来就可以,同时自定义还有一个好处就是可以打破官方实现data collator只能使用pretrain tokenize的限制,我们可以使用自定义的tokenize甚至不适用tokenize,看官方的这些function的功能就知道了,就是一个对batch数据做处理的小程序。
compute_metrics
- compute_metrics (
Callable[[EvalPrediction],``Dict], optional) – The function that will be used to compute metrics at evaluation. Must take a EvalPrediction and return a dictionary string to metric values.
这里是自定义测试metric的地方,语法也很简单:
def compute_metrics(p: EvalPrediction) -> Dict:
preds,labels=p
preds = np.argmax(preds, axis=-1)
#print('shape:', preds.shape, '\n')
precision, recall, f1, _ = precision_recall_fscore_support(lables.flatten(), preds.flatten(), average='weighted', zero_division=0)
return {
'accuracy': (preds == p.label_ids).mean(),
'f1': f1,
'precision': precision,
'recall': recall
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其他参数
- train_dataset (
torch.utils.data.dataset.Dataset, optional) – The dataset to use for training. If it is andatasets.Dataset, columns not accepted by themodel.forward()method are automatically removed. - eval_dataset (
torch.utils.data.dataset.Dataset, optional) – The dataset to use for evaluation. If it is andatasets.Dataset, columns not accepted by themodel.forward()method are automatically removed. - tokenizer (
PreTrainedTokenizerBase, optional) – The tokenizer used to preprocess the data. If provided, will be used to automatically pad the inputs the maximum length when batching inputs, and it will be saved along the model to make it easier to rerun an interrupted training or reuse the fine-tuned model. - model_init (
Callable[[],``PreTrainedModel], optional) –
A function that instantiates the model to be used. If provided, each call to train() will start from a new instance of the model as given by this function.
The function may have zero argument, or a single one containing the optuna/Ray Tune trial object, to be able to choose different architectures according to hyper parameters (such as layer count, sizes of inner layers, dropout probabilities etc).
这些都很简单了不废话了,这里要求传入的是dataset不是dataloader需要注意。
- callbacks (List of Callbacks, optional) –
A list of callbacks to customize the training loop. Will add those to the list of default callbacks detailed in here.
If you want to remove one of the default callbacks used, use the Trainer.remove_callback()) method. - callback和keras中的callback的设计类似,自定义的方法 也类似,不过官方提供了最常用的earlystopping功能,我们只要from transformers import EarlyStoppingCallback然后放到这个参数下即可,早停的metric根据我们的metric_for_best_model 来设置。
- optimizers (
Tuple[torch.optim.Optimizer,``torch.optim.lr_scheduler.LambdaLR, optional) – A tuple containing the optimizer and the scheduler to use. Will default to an instance of AdamW on your model and a scheduler given by get_linear_schedule_with_warmup controlled byargs.
通过这里可以比较迅速方便地自定义其它地optimizer和lr scheduler,支持torch和torch式地其它优化器。
例子
下面是我自己关于一个情感分类训练时的代码,主要设置了几个关键参数就可以,其他根据需要可以参考前文。
# 设置训练参数
training_args = TrainingArguments(
output_dir='./results', # 输出目录
num_train_epochs = 100, # 训练轮数
per_device_train_batch_size = 128, # 每个设备的训练批次大小
per_device_eval_batch_size = 128 ,
warmup_steps=500, # 预热步数
weight_decay=0.001, # 权重衰减
logging_dir='./logs', # 日志输出目录
logging_steps=10, # 日志记录步数
learning_rate = 1e-04,
do_train = True,
do_eval = True,
seed = 2024,
)
def compute_metrics(eval_pred):
preds,labels= eval_pred
preds = np.argmax(preds, axis=-1)
labels = np.argmax(labels, axis=-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels.flatten(), preds.flatten(), average='weighted', zero_division=0)
acc = np.sum(preds == labels) / len(preds)
return {
'accuracy': acc ,
'f1': f1,
'precision': precision,
'recall': recall,
'confusion_matrix' : confusion_matrix( labels ,preds)
}
# 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
参考文献

