
- 1GPT-3:自然语言处理的预训练模型
- 2Django--基于Python的Web应用框架_apps.py是什么
- 3大数据-flink - java使用 flink 1.7/1.10版本_flink-connector-kafka版本
- 4JAVA这门语言 如何从刚毕业的小菜鸟进阶成月薪15K以上的工程师_java刚毕业待遇
- 5最新微信小程序渗透测试指北(附案例)_微信小程序怎么渗透测试(2),2024年最新金三银四软件测试高级工程师面试题整理
- 6FreeSSL申请免费域名证书_freessl申请证书
- 7Spring Boot中处理404错误的解决方案_springboot 404处理
- 8鸿蒙基础知识-自定义组件_鸿蒙自定义组件的组件化特点
- 9Git多人协作开发流程
- 10我的MBTI测试报告_mbiti报告
Spring AI ETL 流水线_tika-document-reader
赞
踩

先纠正 Spring AI 使用本地 Ollama Embeddings 中的一个错误,当启动 Ollama 之后,Windows会有托盘图标,此时已经启动了 Ollama 的服务,访问 Embedding 时不需要运行
ollama run gemma,只有访问 chat 时才需要启动一个大模型。
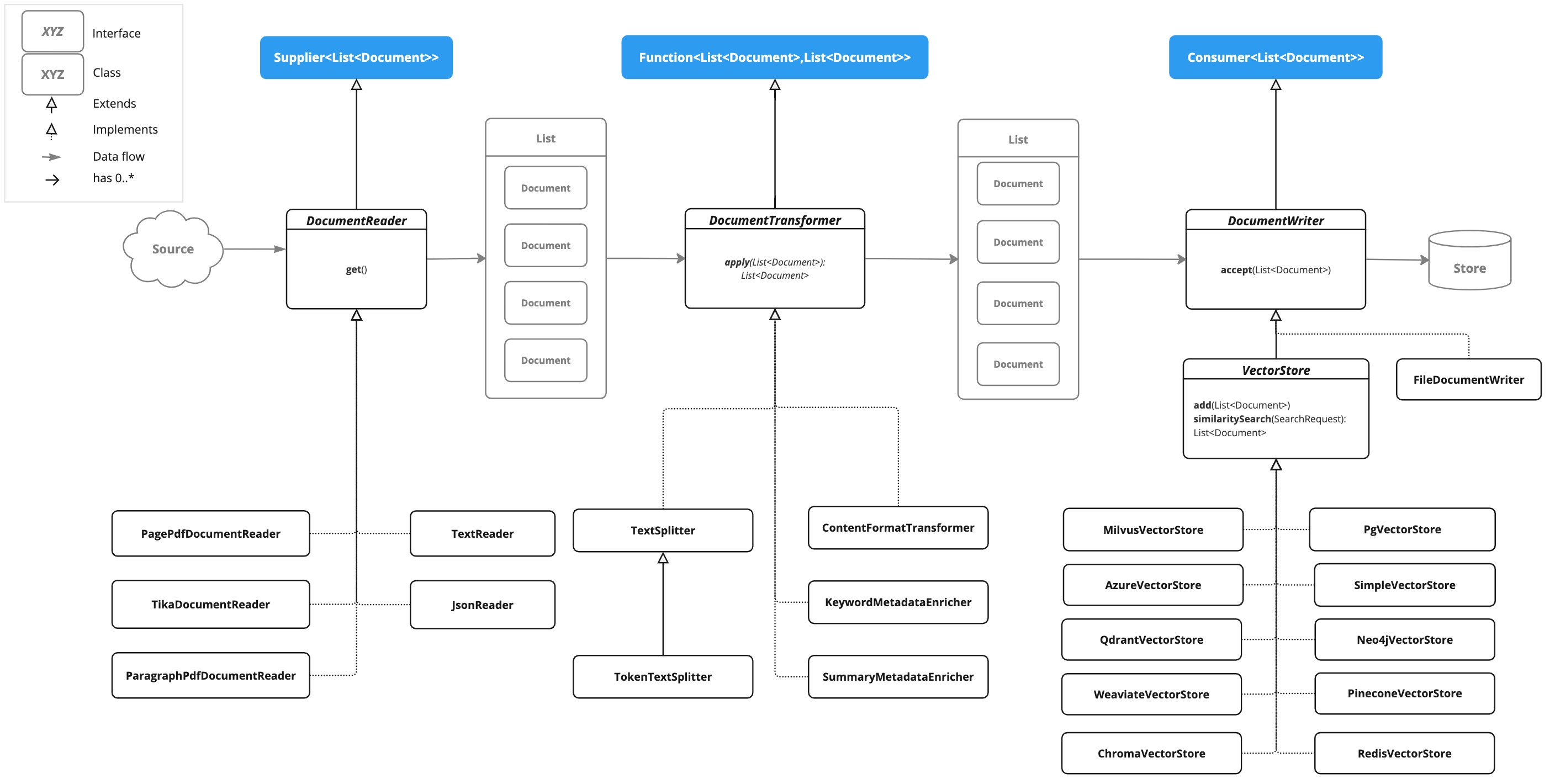
Spring AI 提供的 ETL 流水线比较全面,使用很简单。提取、转换和加载 (ETL) 框架是检索增强生成 (RAG) 用例中数据处理的支柱。ETL 管道协调从原始数据源到结构化向量存储的流程,确保数据采用最佳格式,以便 AI 模型进行检索。
Extract - 提取 - DocumentReader
spring-ai-core 中提供了 TextReader 和 JsonReader,这两个可以读取文本或者JSON中指定的key作为文档(Document)。
在 spring-ai-pdf-document-reader 中提供了 PagePdfDocumentReader(按页读) 和 ParagraphPdfDocumentReader(按目录读,注意,并非所有 PDF 文档都包含 PDF 目录)两个实现,可以用来读取PDF文件。
在 spring-ai-tika-document-reader 中提供了一个比较万能的 TikaDocumentReader,支持读取 PDF、DOC/DOCX、PPT/PPTX 和 HTML等格式(支持格式很多,详情看 https://tika.apache.org/2.9.0/formats.html )。
Transform - 转换 - DocumentTransformer
- ContentFormatTransformer 内容格式转换器:确保所有文档的内容格式统一。
- KeywordMetadataEnricher 关键字MetadataEnricher:使用基本关键字元数据扩充文档。
- SummaryMetadataEnricher 摘要元数据丰富:使用摘要元数据丰富文档,以增强检索能力。
- TokenTextSplitter:拆分文档,同时保留令牌级完整性。
这里面有意思的是 KeywordMetadataEnricher 和 SummaryMetadataEnricher,这两个通过提示词模板让 AI 给出上下文(前面提取内容)的关键字和总结内容:
public static final String KEYWORDS_TEMPLATE = """
{context_str}. Give %s unique keywords for this
document. Format as comma separated. Keywords: """;
public static final String DEFAULT_SUMMARY_EXTRACT_TEMPLATE = """
Here is the content of the section:
{context_str}
Summarize the key topics and entities of the section.
Summary: """;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Load - 加载 - DocumentWriter
ETL最后的阶段就是存储文档,提供了两个实现,一个是 FileDocumentWriter,将文档保存到文件中。另一个就是前面用过的 VectorStore,存储向量数据。
这里的ETL和Spring AI Embeddings 和 Vector 入门 相比多了一个文档的来源,文档的来源除了PDF等文件外,还可以是 Spring AI 应用 - 智能记者 中网页查询的结果,还可以是数据库查询的结果,ES查询的结果。



