- 1Source tree 忽略文件_sourcetree忽略文件
- 2Kafka精进 | Producer端核心参数及调优建议_参数 避免生产消息过程中的消息乱序
- 3MPU9250 九轴 EKF扩展卡尔曼滤波数据融合算法 使用扩展卡尔曼滤波(EKF)将数据融合
- 4To install them, you can run: npm install --save core-js/modules/esnext.set.difference.v2.js core-js
- 5Android应用程序和其设计思想--转载----做记录_android软件设计思想先进嘛
- 6前端html基础知识看这一篇就够了(小白必看,超详细)_html前端学习
- 7JAVA 自定义注解+AOP_java自定义注解实现aop
- 8★文件上传漏洞与Upload-labs靶场分析实战_上传漏洞靶场
- 9LSTM 循环神经网络原理深度解读与网络结构精细剖析_lstm 神经网络
- 10Element-UI对Table表格的简单封装_封装element中的table表格
Java日常开发的12个坑,你踩过几个?进阶学习资料!
赞
踩
第一个 分布式:限流
1.1 ZooKeeper+Nginx面试常备题(附答案)
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
-
ZooKeeper 是什么?
-
ZooKeeper 提供了什么?
-
Zookeeper 文件系统
-
四种类型的 znode
-
Zookeeper 通知机制
-
Zookeeper 做了什么?
-
zk 的命名服务(文件系统)
-
zk 的配置管理(文件系统、通知机制)
-
Zookeeper 集群管理(文件系统、通知机制)
-
Zookeeper 分布式锁(文件系统、通知机制)
-
获取分布式锁的流程
-
Zookeeper 队列管理(文件系统、通知机制)
-
Zookeeper 数据复制
-
Zookeeper 工作原理
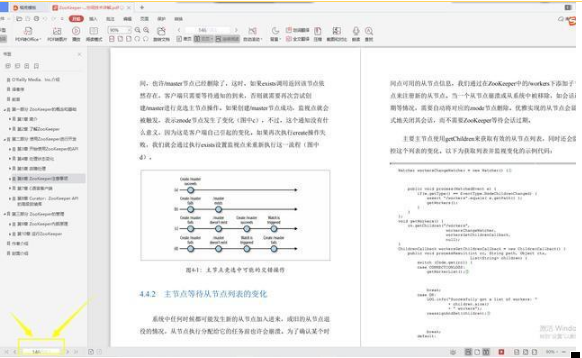
-
zookeeper 是如何保证事务的顺序一致性的?
-
Zookeeper 下 Server 工作状态
-
zookeeper 是如何选取主 leader 的?
-
分布式通知和协调
-
机器中为什么会有 leader?
-
zk 节点宕机如何处理?
-
Zookeeper 同步流程
-
zookeeper 负载均衡和 nginx 负载均衡区别
-
zookeeper watch 机制
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等
-
请解释一下什么是 Nginx?
-
请列举 x Nginx 的一些特性。
-
请列举 x Nginx 和 和 Apache 之间的不同点
-
请解释 x Nginx 如何处理 P HTTP 请求。
-
在 x Nginx 中,如何使用未定义的服务器名称来阻止处理请求?
-
使用 “ 反向代理服务器 ”
-
请列举 x Nginx 服务器的最佳用途。
-
请解释 x Nginx 服务器上的 r Master 和 和 r Worker 进程分别是什么?
-
请解释你如何通过不同于 0 80 的端口开启 Nginx?
-
请解释是否有可能将 x Nginx 的错误替换为 2 502 错误?
-
在 x Nginx 中,解释如何在 L URL 中保留双斜线? ?
-
请解释 e ngx_http_upstream_module 的作用是什么?
-
请解释什么是 K C10K 问题?
-
请陈述 s stub_status 和 和 r sub_filter 指令的作用是什么?
-
解释 x Nginx 是否支持将请求压缩到上游?
-
解释如何在 x Nginx 中获得当前的时间?
-
用 x Nginx 服务器解释s -s 的目的是什么?
-
解释如何在 x Nginx 服务器上添加模块?
1.2 Nginx+ZooKeeper学习的笔记PDF

第一部分阐述了Apache ZooKeeper这类系统的设计目的和动机,并介绍分布式系统的一些必要背景知识
-
第1章介绍了ZooKeeper可以做什么,以及其设计如何支撑这些任务
-
第2章介绍了基本概念和基本组成模块,并通过命令行工具的具体操作介绍ZooKeeper可以做什么
第二部分阐述程序员所需要掌握的ZooKeeper库调用方法和编程技巧,虽然对系统运维人员来说也有一定价值,但也可以不选择阅读。这一部分主要以Java语言的API为主,因为Java是非常流行的开发语言,如果你之前使用其他开发语言,可以通过这一部分内容来学习基本的技术和方法调用,之后通过其他语言来实现
-
第3章介绍Java语言的API
-
第4章解释如何跟踪和处理ZooKeeper中的状态变更情况。·第5章介绍如何在系统或网络故障时复应用
-
第6章介绍为了避免故障要注意的一些繁杂却很重要的场景
-
第7章介绍C语言版的API,该章也可以作为非Java语言实现的ZooKeeper API的基础,对非Java语言的开发人员非常有帮助
-
第8章介绍一款更高层级的封装的ZooKeeper接口
第三部分主要适用于ZooKeeper的系统运维人员,尤其在第9章中即便对开发人员也很有价值
-
第9章介绍ZooKeeper的作者们在设计时所采用的方案,这些知识对运维管理非常有帮助。
-
第10章介绍如何对ZooKeeper进行配置

在第一部分的前两章中,将只探讨如何使用Nginx这一个问题。阅读这一部分的读者不需要了解C语言,就可以学习如何部署Nginx,学习如何向其中添加各种官方、第三方的功能模块,如何通过修改配置文件来更改Nginx及各模块的功能,如何修改Linux操作系统上的参数来优化服务器性能,最终向用户提供企业级的Web服务器。这一部分介绍配置项的方式,更偏重于领着对Nginx还比较陌生的读者熟悉它,通过了解几个基本Nginx模块的配置修改方式,进而使读者可以通过查询官网、第三方网站来了解如何使用所有Nginx模块的用法。
在第二部分的第3章~第7章中,都是以例子来介绍HTTP模块的开发方式的,这里有些接近于“step by step”的学习方式,我在写作这一部分时,会通过循序渐进的方式使读者能够快速上手,同时会穿插着介绍其常见用法的基本原理。
在第三部分,将开始介绍Nginx的完整框架,阅读到这里将会了解第二部分中HTTP模块为何以此种方式开发,同时将可以轻易地开发Nginx模块。这一部分并不仅仅满足于阐述Nginx架构,而是会探讨其为何如此设计,只有这样才能抛开HTTP框架、邮件代理框架,实现一种新的业务框架、一种新的模块类型。
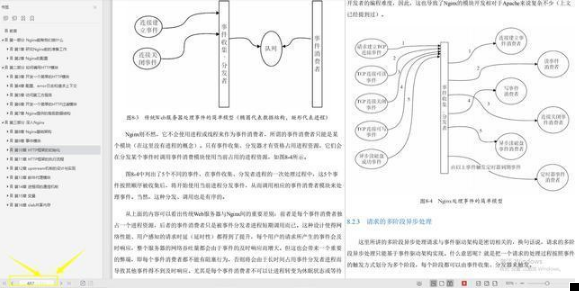
第二个 分布式:缓存
2.1 MongoDB+memcached+Redis面试常备题(附答案)
Mongodb,分布式文档存储数据库,由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个高性能,开源,无模式的文档型数据库,是当前NoSql数据库中比较热门的一种。它在许多场景下可用于替代传统的关系型数据库或键/值存储方式
-
你说的 NoSQL 数据库是什么意思?NoSQL 与 RDBMS 直接有什么区别?为什么要使用和不使用NoSQL 数据库?说一说 NoSQL 数据库的几个优点?
-
NoSQL 数据库有哪些类型?
-
MySQL 与 MongoDB 之间最基本的差别是什么?
-
你怎么比较 MongoDB、CouchDB 及 CouchBase?
-
MongoDB 成为最好 NoSQL 数据库的原因是什么?
-
32 位系统上有什么细微差别?
-
journal 回放在条目(entry)不完整时(比如恰巧有一个中途故障了)会遇到问题吗?
-
分析器在 MongoDB 中的作用是什么?
-
名字空间(namespace)是什么?
-
如果用户移除对象的属性,该属性是否从存储层中删除?
-
能否使用日志特征进行安全备份?
-
允许空值 null 吗?
-
更新操作立刻 fsync 到磁盘?
-
如何执行事务/加锁?
-
为什么我的数据文件如此庞大?
-
启用备份故障恢复需要多久?
-
什么是 master 或 primary?
-
什么是 secondary 或 slave?
-
我必须调用 getLastError 来确保写操作生效了么?
-
我应该启动一个集群分片(sharded)还是一个非集群分片的 MongoDB 环境?
-
分片(sharding)和复制(replication)是怎样工作的?
-
数据在什么时候才会扩展到多个分片(shard)里?
-
当我试图更新一个正在被迁移的块(chunk)上的文档时会发生什么?
-
如果在一个分片(shard)停止或者很慢的时候,我发起一个查询会怎样?
-
我可以把 moveChunk 目录里的旧文件删除吗?
-
我怎么查看 Mongo 正在使用的链接?
-
如果块移动操作(moveChunk)失败了,我需要手动清除部分转移的文档吗?
-
如果我在使用复制技术(replication),可以一部分使用日志(journaling)而其他部分则不使用吗?
-
当更新一个正在被迁移的块(Chunk)上的文档时会发生什么?
-
MongoDB 在 A:{B,C}上建立索引,查询 A:{B,C}和 A:{C,B}都会使用索引吗?
-
如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?
-
MongoDB 支持存储过程吗?如果支持的话,怎么用?
-
如何理解 MongoDB 中的 GridFS 机制,MongoDB 为何使用 GridFS 来存储文件?
memcached是一套分布式的快取系统,与redis相似,当初是Danga Interactive为了LiveJournal所发展的,但被许多软件(如MediaWiki)所使用。这是一套开放源代码软件,以BSD license授权协议发布
-
memcached 是怎么工作的?
-
memcached 最大的优势是什么?
-
memcached 和服务器的 local cache (比如 PHP 的 的 APC 、mmap 文件等)相比,有什么优缺点?
-
memcached 和 和 MySQL 的 的 query cache 相比,有什么优缺点?
-
memcached 的 的 cache 机制是怎样的?
-
memcached 如何实现冗余机制?
-
我需要把 memcached 中的 item 批量导出导入,怎么办?
-
memcached 如何处理容错的?
-
如何将 memcached 中 中 item 批量导入导出?
-
memcached 是如何做身份验证的?
-
memcached 的多线程是什么?如何使用它们?
-
memcached 能接受的 key 的最大长度是多少?
-
memcached 对 对 item 的过期时间有什么限制?
-
memcached 最大能存储多大的单个 item ?
-
为什么单个 item 的大小被限制在 1M byte 之内?
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
-
redis 简介
-
为什么要用 redis /为什么要用缓存(高性能、高并发)
-
为什么要用 redis 而不用 map/guava 做缓存?
-
redis 和 memcached 的区别
-
redis 常见数据结构以及使用场景分析(String、Hash、List、Set、Sorted Set)
-
redis 设置过期时间
-
redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
-
redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
-
redis 事务
-
Redis 常见异常及解决方案(缓存穿透、缓存雪崩、缓存预热、缓存降级)
-
分布式环境下常见的应用场景(分布式锁、分布式自增 ID)
-
Redis 集群模式(主从模式、哨兵模式、Cluster 集群模式)
-
如何解决 Redis 的并发竞争 Key 问题
-
如何保证缓存与数据库双写时的数据一致性?
2.2 MongoDB+memcached+Redis学习笔记


03 分布式通讯
3.1 ActiveMQ+Kafka+RabbitMQ面试常备题(附答案)
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息
-
Kafka 的设计时什么样的呢?
-
数据传输的事物定义有哪三种?
-
Kafka 判断一个节点是否还活着有那两个条件?
-
producer 是否直接将数据发送到 broker 的 leader(主节点)?
-
Kafa consumer 是否可以消费指定分区消息?
-
Kafka 消息是采用 Pull 模式,还是 Push 模式?
-
Kafka 存储在硬盘上的消息格式是什么?
-
Kafka 高效文件存储设计特点:
-
Kafka 与传统消息系统之间有三个关键区别
-
Kafka 创建 Topic 时如何将分区放置到不同的 Broker 中
-
Kafka 新建的分区会在哪个目录下创建
-
partition 的数据如何保存到硬盘
-
kafka 的 ack 机制
-
Kafka 的消费者如何消费数据
-
消费者负载均衡策略
-
数据有序
-
kafaka 生产数据时数据的分组策略
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位
-
什么是 ActiveMQ?
-
ActiveMQ 服务器宕机怎么办?
-
丢消息怎么办?
-
持久化消息非常慢
-
消息的不均匀消费
-
死信队列
-
ActiveMQ 中的消息重发时间间隔和重发次数吗?
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多公开标准(如 COBAR的 IIOP ,或者是 SOAP 等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的 MSMQ ,IBM 的 Websphere MQ 等),因此,在 2006 年的 6 月,Cisco 、Redhat、iMatix 等联合制定了 AMQP 的公开标准。
-
RabbitMQ 中的 broker 是指什么?cluster 又是指什么?
-
什么是元数据?元数据分为哪些类型?包括哪些内容?与 cluster 相关的元数据有哪些?元数据是如何保存的?元数据在 cluster 中是如何分布的?
-
RAM node 和 disk node 的区别?
-
RabbitMQ 上的一个 queue 中存放的 message 是否有数量限制?
-
RabbitMQ 概念里的 channel、exchange 和 queue 这些东东是逻辑概念,还是对应着进程实体?这些东东分别起什么作用?
-
vhost 是什么?起什么作用?
-
在单 node 系统和多 node 构成的 cluster 系统中声明 queue、exchange ,以及进行 binding 会有什么不同?
-
客户端连接到 cluster 中的任意 node 上是否都能正常工作?
-
cluster 中 node 的失效会对 consumer 产生什么影响?若是在 cluster 中创建了mirrored queue ,这时 node 失效会对 consumer 产生什么影响?
-
能够在地理上分开的不同数据中心使用 RabbitMQ cluster 么?
-
为什么 heavy RPC 的使用场景下不建议采用 disk node ?
-
向不存在的 exchange 发 publish 消息会发生什么?向不存在的 queue 执行consume 动作会发生什么?
-
routing_key 和 binding_key 的最大长度是多少?
-
RabbitMQ 允许发送的 message 最大可达多大?
-
什么情况下 producer 不主动创建 queue 是安全的?
-
“dead letter”queue 的用途?
-
为什么说保证 message 被可靠持久化的条件是 queue 和 exchange 具有durable 属性,同时 message 具有 persistent 属性才行?
-
什么情况下会出现 blackholed 问题?
-
如何防止出现 blackholed 问题?
-
Consumer Cancellation Notification 机制用于什么场景?
-
Basic.Reject 的用法是什么?
-
为什么不应该对所有的 message 都使用持久化机制?
-
RabbitMQ 中的 cluster、mirrored queue,以及 warrens 机制分别用于解决什么问题?存在哪些问题?
3.2 ActiveMQ+Kafka+RabbitMQ学习笔记PDF


总结
面试难免让人焦虑不安。经历过的人都懂的。但是如果你提前预测面试官要问你的问题并想出得体的回答方式,就会容易很多。
此外,都说“面试造火箭,工作拧螺丝”,那对于准备面试的朋友,你只需懂一个字:刷!
给我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”
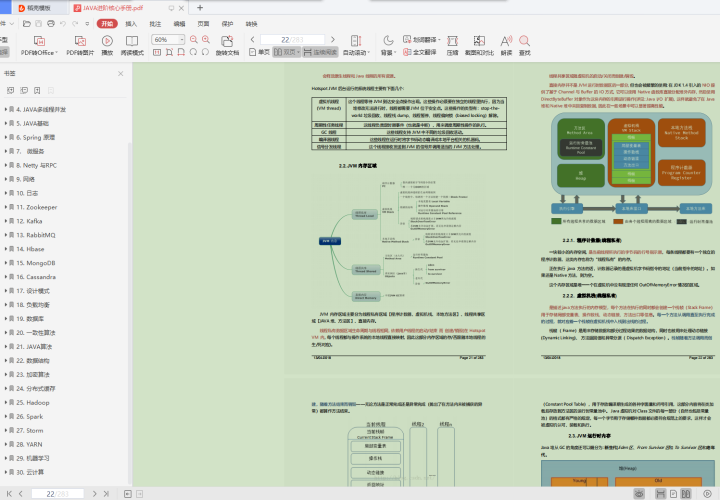
且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。
我刷刷刷刷,使劲儿刷刷刷刷刷!今天既是来谈面试的,那就必须得来整点面试真题,这不花了我整28天,做了份“Java一线大厂高岗面试题解析合集:JAVA基础-中级-高级面试+SSM框架+分布式+性能调优+微服务+并发编程+网络+设计模式+数据结构与算法等”
[外链图片转存中…(img-wv7knOF2-1625202530044)]
且除了单纯的刷题,也得需准备一本【JAVA进阶核心知识手册】:JVM、JAVA集合、JAVA多线程并发、JAVA基础、Spring 原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB、Cassandra、设计模式、负载均衡、数据库、一致性算法、JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算,用来查漏补缺最好不过。