
- 1操作系统 - 输入/输出(I/O)管理
- 2llama3 微调教程之 llama factory 的 安装部署与模型微调过程,模型量化和gguf转换。_llama factory适配器路径
- 3lombok使用总结
- 4repo 使用
- 5深度学习环境安装教程
- 6ESP32入门:1、VSCode+PlatformIO环境搭建(离线快速安装)_vscode安装esp32 platformio
- 7ffmpeg编程(二)
- 8送给正在迷茫的你,2024年Web前端面试宝典WebAPI部分,字节跳动+腾讯+华为+小米+阿里面试题分享
- 9正确解决JedisDataException: ERR Client sent AUTH, but no password is set异常的有效解决方法
- 10如何修改Git仓库的URL(地址)_git仓库改名后,url能不能改
机器学习(十一):Scikit-learn库的基础与使用
赞
踩
全文共15000余字,预计阅读时间约30~50分钟 | 满满干货,建议收藏!

一、介绍
1. 1 Scikit-learn的发展历程及定义
Scikit-learn的发展始于2007年,由David Cournapeau在Google Summer of Code项目中启动。项目后续得到了许多开发者的贡献,包括INRIA(法国国家信息与自动化研究所),Waikato大学和其他机构。
项目之所以取名为Scikit-Learn,也是因为该算法库是基于SciPy来进行的构建,而Scikit则是SciPy Kit(SciPy衍生的工具套件)的简称
Scikit-learn是目前机器学习领域最完整、同时也是最具影响力的算法库。它基于Numpy, Scipy和matplotlib,包含了大量的机器学习算法实现,包括分类、回归、聚类和降维等,还包含了诸多模型评估及选择的方法。Scikit-learn的API设计的非常清晰,易于使用和理解,适合于新手入门,同时也满足了专业人士在实际问题解决中的需求。
1.2 理解算法包、算法库及算法框架之间的区别和联系
算法包:包含预先编写的,针对特定问题或一系列相关问题的算法实现。算法包可以用于执行特定的任务或操作,例如数值分析、机器学习、图像处理等。使用者可以直接调用这些算法,而不需要自己从零开始编写。如表格数据分析包Pandas
算法库:算法库和算法包非常相似,通常可以互换使用。它也是包含了预先编写的,用于解决特定问题的一系列算法的集合,主要指代封装程度更高、对机器学习这一大类算法功能实现更加完整、甚至是定义了一类数据结构的代码模块,如科学计算库NumPy
算法框架:算法框架则是一个更大的概念,它提供了一个用于开发、构建和实现算法的系统,通常包含了一套标准的编程接口(API)、工具、库和规范。它的主要目的是简化和标准化开发过程,使得开发者可以更专注于实现特定的功能或算法,而不需要处理大量的基础设施问题。如机器学习算法库Scikit-Learn
通俗的理解一下:用一个餐厅的比喻来理解这三个概念:
- 算法包(Algorithm Package):就像餐厅菜单上的某个具体的菜品。每个菜品都有特定的制作方法,各种食材以特定的方式搭配,制作出特定的菜。比如你想吃鱼香肉丝,你可以直接点这道菜,而不需要告诉厨师应该怎么做。
- 算法库(Algorithm Library):就像整个餐厅的菜单。菜单包含了很多菜品,不论你想吃主食、汤还是甜点,你都可以在菜单上找到。你只需要从菜单中选择你想要的菜,而不需要知道具体的做法。
- 算法框架(Algorithm Framework):就像整个餐厅的运营模式。这不仅仅包括菜单,还有餐厅的装修风格,服务员的服务态度,烹饪食物的方式,以及提供食物的时间等等。它提供了一种方便的方式,使得你可以在一个地方享受到完整的用餐体验,而不仅仅是食物本身。
所以在编程中,直接使用算法包来解决特定的问题,使用算法库可以解决一系列的问题,而使用算法框架则可以帮助我们更好地组织和构建代码,更有效地解决问题。
二、Scikit-learn官网结构
对于大多数流行的开源项目,官网都是学习的绝佳资源。而对于Scikit-Learn来说尤其是如此。哪怕是顶级开源项目盛行的当下,Scikit-Learn官网在相关内容介绍的详细和完整程度上,都是业内首屈一指的。无论是Scikit-Learn的安装、更新,还是具体算法的使用方法,甚至包括算法核心原理的论文出处以及算法使用的案例,在Scikit-Learn官网上都有详细的介绍。其官网地址:
Scikit-Learn官网,主要功能介绍如下:
- 导航栏

- 六大功能模块
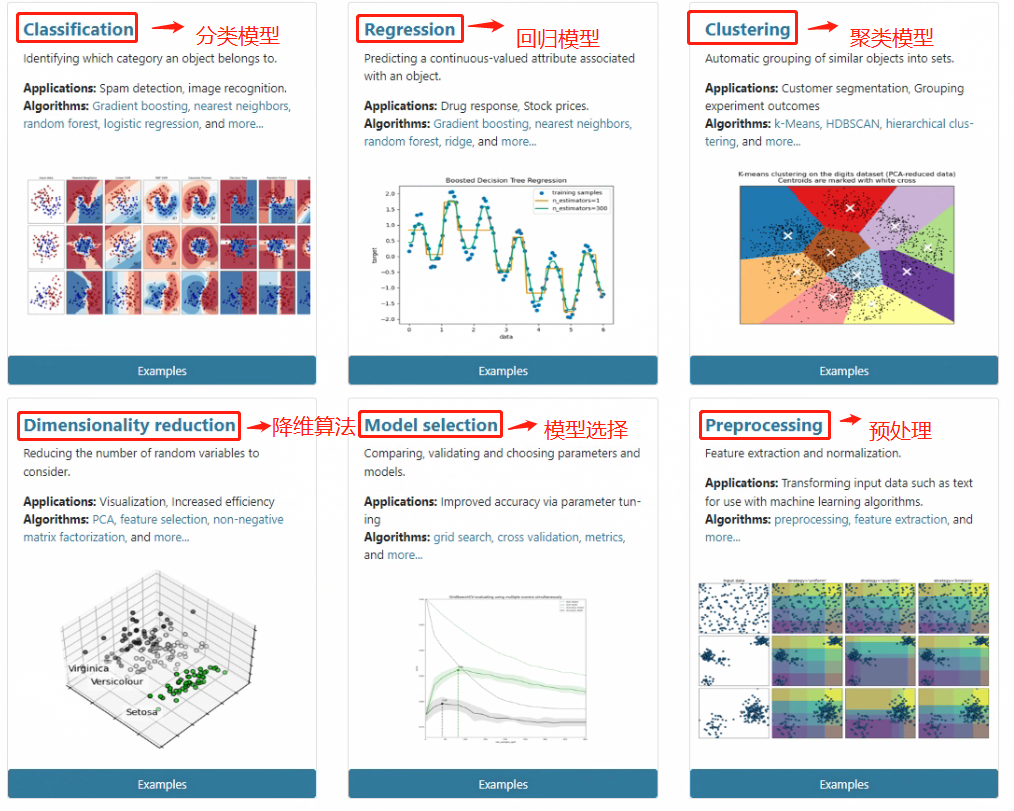
Scikit-learn将所有的评估器和函数功能分为六大类,分别是分类模型(Classification)、回归模型(Regression)、聚类模型(Clustering)、降维方法(Dimensionality reduction)、模型选择(Model selection)和数据预处理六大类。
六个功能模块的划分其实是存在很多交叉的,对于很多模型来说,既能处理分类问题、同时也能处理回归问题,而很多聚类算法同时也可以作为降维方法实用。例如线性回归对用评估器可从Regression进入进行查找,而对用模型评估指标,由于评估指标最终是指导进行模型选择的,因此模型评估指标计算的实用函数的查找应该从Model selection入口进入。
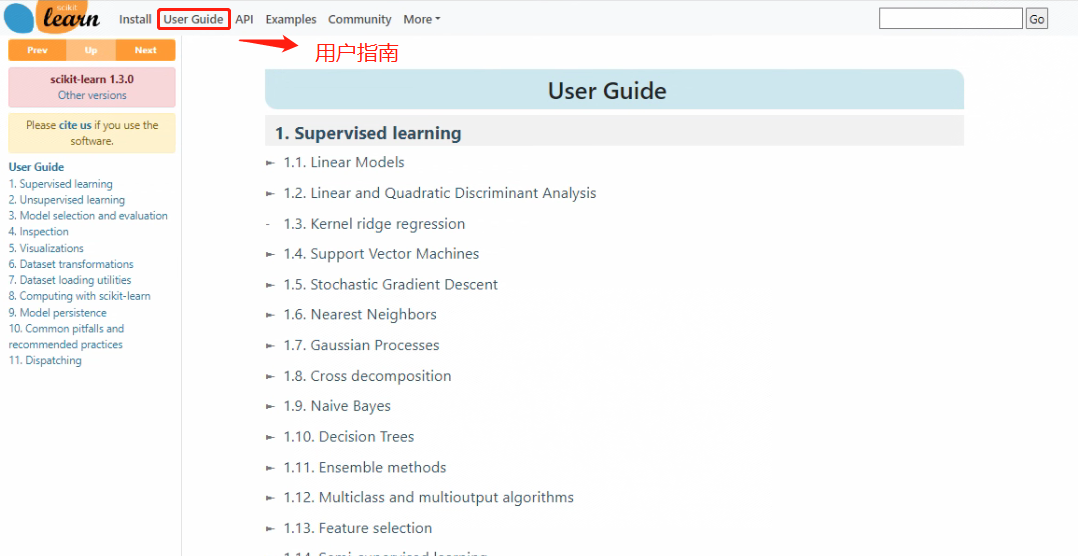
- User Guide:sklearn所有内容的合集文档
在最上方的User Guide一栏进入sklearn所有内容的合集页面,其中包含了sklearn的所有内容按照使用顺序进行的排序。如果点击左上方的Other versions,则可以下载sklearn所有版本的User Guide的PDF版本。
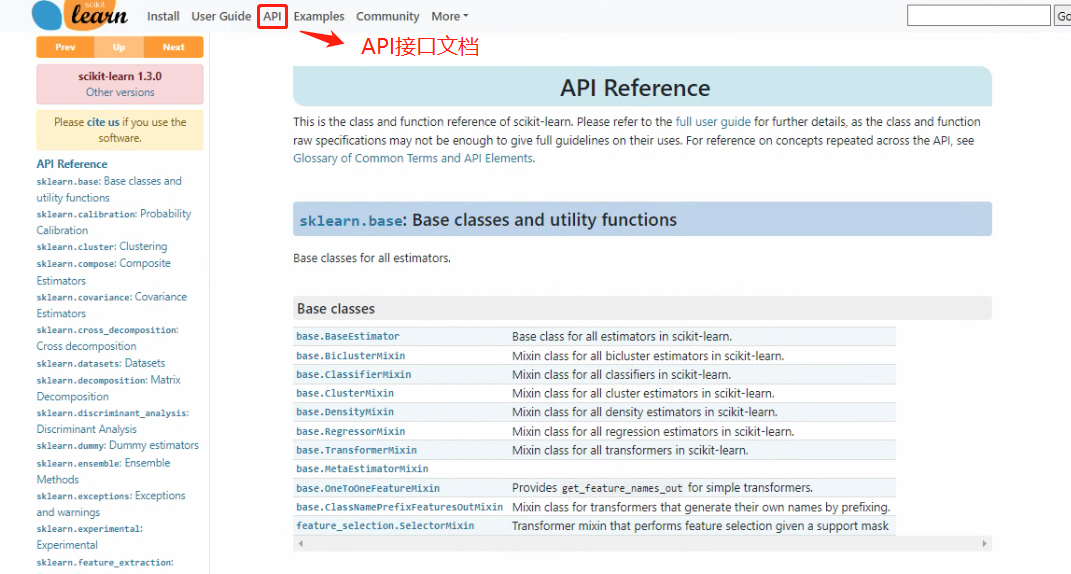
- API:按照二级模块首字母排序的接口查询文档
如果想根据评估器或实用函数的名字去查找相关API说明文档,则可以点击最上方的API一栏进入到根据二极模块首字母排序的API查询文档中。其中二级模块指的是类似包含线性回归的linear_model模块或者包含MSE的metrics模块。
三、安装与设置
3.1 Python环境的安装与配置
如果您还不知道怎么安装Python基础环境,建议您阅读此文,详解了Anaconda的下载、安装与启动,Jupyter的基本操作及其强大的Notebook编辑环境及轻松升级Python版本、维护和管理Python的第三方库,满满干货!
3.2 Scikit-learn的安装
在完成Python环境的安装和配置后,可以进行Scikit-learn的安装,在官网上对应的位置如下:
Scikit-learn需要Python (>= 3.6) 和pip。
安装Scikit-learn的依赖包,包括NumPy和SciPy。如果已经安装了这些包,可以跳过此步。如果还没有,可以使用以下命令来安装:
pip install numpy scipy
- 1
接下来,可以安装Scikit-learn了。使用以下命令来安装:
pip install -U scikit-learn
- 1
这个命令将会安装或者升级Scikit-learn到最新版本。
如果使用的是Anaconda,那么安装Scikit-learn更加简单,直接使用以下命令:
conda install scikit-learn
- 1
确认Scikit-learn是否已经成功安装,可以尝试在Python环境中导入它:
import sklearn
sklearn.__version__
- 1
- 2
如果没有出现任何错误信息,那么就说明Scikit-learn已经成功安装了。
以上是基本的安装步骤,不同的操作系统和Python环境可能会有一些差异。需要根据自己的实际情况进行调整。如果在安装过程中遇到任何问题,可以查阅Scikit-learn的官方文档或者在网上搜索解决方案。
版本更新:
pip install --upgrade sklearn
- 1
四、Scikit-learn的快速入门
4.1 数据集的导入和处理
Scikit-learn提供了非常多的内置数据集,并且还提供了一些创建数据集的方法,这些数据集常用于演示各种机器学习算法的使用方法。这些数据集分为两种类型:小规模的玩具数据集(Toy Datasets)和大规模的真实世界数据集(Real-World Datasets)。
以下是几个常见的玩具数据集:
- Iris(鸢尾花):一个分类问题的数据集,包含了三种鸢尾花的四个特征,目标是根据这些特征预测鸢尾花的种类。
- Digits(手写数字):一个多分类问题的数据集,包含了手写数字的8x8像素图像,目标是识别这些图像对应的数字。
- Boston House Prices(波士顿房价):这是一个回归问题的数据集,包含了波士顿各个区域的房价和其他13个特征,目标是预测房价。
- Breast Cancer(乳腺癌):这是一个二分类问题的数据集,包含了乳腺肿瘤的30个特征,目标是预测肿瘤是良性还是恶性。
sklearn中的数据集相关功能都在datasets模块下,可以通过API文档中的datasets模块所包含的内容对所有的数据集和创建数据集的方法进行概览。

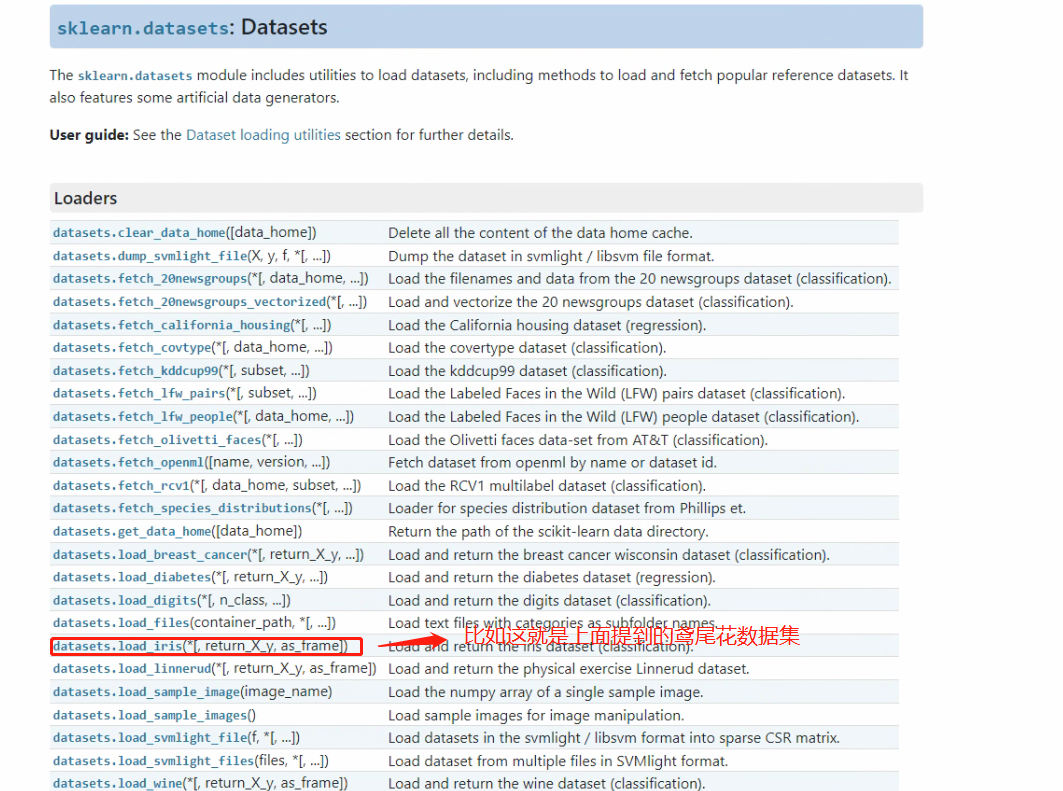
要在Scikit-learn中加载这些数据集,可以使用sklearn.datasets模块中的相关函数,例如:
from sklearn.datasets import load_iris
iris = load_iris()
- 1
- 2
- 3
这个函数会返回一个Bunch对象,包含了数据、目标和其他信息。例如,iris.data是一个包含了特征的二维数组,iris.target是一个包含了目标的一维数组。
| 名称 | 描述 |
|---|---|
| data | 数据集特征矩阵 |
| target | 数据集标签数组 |
| feature_names | 各列名称 |
| target_names | 各类别名称 |
| frame | 当生成对象是DataFrame时,返回完整的DataFrame |
对应的可以使用如下代码查看:
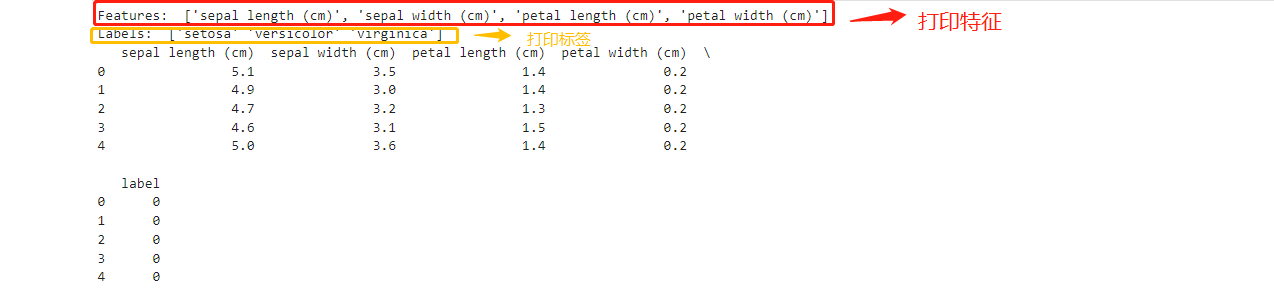
# 数据集包含四个特征
print("Features: ", iris.feature_names)
# 数据集有三种分类标签
print("Labels: ", iris.target_names)
# 将数据转换为DataFrame以便于查看
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 添加分类标签到DataFrame
iris_df['label'] = iris.target
# 显示数据的前五行
print(iris_df.head())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Scikit-learn也提供了一些真实世界的数据集,但由于规模较大,通常需要下载。这些数据集可以用于更复杂的任务和算法的测试。例如,fetch_20newsgroups函数可以下载20 Newsgroups文本数据集,用于文本分类等任务。
4.2 数据集切分
在Scikit-learn中,通常将原始数据集切分为训练集和测试集,这样做可以评估模型在未见过的数据上的性能。数据集切分的目的是为了更好的进行模型性能评估,而更好的进行模型性能评估则是为了更好的进行模型挑选,Scikit-learn提供了train_test_split函数来帮助完成这一任务,train_test_split在model_selection模块下。
可以这样调用并使用它:
from sklearn.model_selection import train_test_split
# 假设X是特征,y是目标
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- 1
- 2
- 3
- 4
train_test_split函数的主要参数有:
X, y:需要被切分的数据。test_size:代表测试集的比例。在上面的例子中,我们将20%的数据用作测试集。random_state:随机种子,可以确保每次运行代码时数据的切分方式相同。
在代码上,可以使用?的方式来查看函数的详细信息:
# 查阅该函数的帮助文档
train_test_split?
- 1
- 2
这里面有两个参数需要关注一下:
- 随机数种子的设置,random_state取值不同,切分结果就会各有不同
stratify参数是控制训练集和测试集不同类别样本所占比例的参数,若希望切分后的训练集和测试集中0、1两类的比例和原始数据相同(1:1),则可另stratify=y。
4.3 数值数据的标准化
Scikit-learn中的预处理模块sklearn.preprocessing提供了许多实用的特征缩放功能,包括数据归一化(Normalization)和标准化(Standardization)。这两种技术都用于改变特征的尺度,以便在训练机器学习模型时保证它们在相同的范围内。
此处需要注意一点:从功能上划分,Scikit-learn中的归一化其实是分为标准化(Standardization)和归一化(Normalization)两类。Z-Score标准化和0-1标准化,都属于Standardization的范畴,Normalization则特指针对单个样本(一行数据)利用其范数进行放缩的过程。
-
数据归一化:归一化通常意味着将数据缩放到[0, 1]的范围内,或者使得所有数据的范围都在[-1, 1]之间。可以使用Scikit-learn的
MinMaxScaler来实现。from sklearn.preprocessing import MinMaxScaler X = np.arange(30).reshape(5, 6) X_train, X_test = train_test_split(X) scaler = MinMaxScaler() X_train_normalized = scaler.fit_transform(X_train) X_test_normalized = scaler.transform(X_test) X_test_normalized- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这段代码首先创建了一个MinMaxScaler对象,然后使用fit_transform方法对训练数据进行拟合和转换,最后使用transform方法对测试数据进行转换。
- 数据标准化:标准化则是将数据缩放,使得它们的均值为0,标准差为1。这可以通过Scikit-learn的
StandardScaler来实现。
X = np.arange(30).reshape(5, 6)
X_train, X_test = train_test_split(X)
scaler = StandardScaler()
X_train_standardized = scaler.fit_transform(X_train)
# 利用训练集的均值和方差对测试集进行标准化处理
X_test_standardized = scaler.transform(X_test)
X_test_standardized
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
需要解释的一个点:为什么对训练集要使用fit_transform,而对测试级只使用transform?**
这是因为:在机器学习中,训练集和测试集应当是分开处理的。具体地说,应当在训练集上训练模型,而测试集应当模拟真实世界中模型未曾见过的数据,以此来评估模型的真实性能。因此,任何形式的预处理(包括特征缩放)都应当只以训练集的数据为基准来完成。
当在训练集上调用fit_transform方法时,fit方法会计算训练集数据的均值和标准差,然后transform方法会使用这些计算出的参数(均值和标准差)来对训练集进行标准化。
然后,当在测试集上调用transform方法时,Scikit-learn会使用之前在训练集上计算得到的均值和标准差来进行标准化。这样做的原因是,假设测试集是模型未曾见过的新数据,因此,不能使用测试集数据的任何信息(包括它的均值和标准差)来影响模型。换句话说,必须假设在预处理阶段,测试集数据是不可见的。
总的来说,在预处理数据时,训练集应当使用fit_transform方法,而测试集应当只使用transform方法,这样可以保证不会在预处理阶段就“泄露”测试集的信息。
4.4 数值数据的归一化
在Scikit-learn中,preprocessing.normalize是另一种类型的"归一化"。
preprocessing.normalize的功能是按照向量空间模型(Vector Space Model)对特征向量进行转换,使得每个特征向量的欧几里得长度(L2范数)等于1,或者每个元素的绝对值之和(L1范数)等于1。换句话说:和标准化不同,Scikit-learn中的归一化特指将单个样本(一行数据)放缩为单位范数(1范数或者2范数为单位范数)的过程,该操作常见于核方法或者衡量样本之间相似性的过程中。
假设向量
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2, ..., x_n]^T
x=[x1,x2,...,xn]T,则向量x的1-范数的基本计算公式为:
∣
∣
x
∣
∣
1
=
∣
x
1
∣
+
∣
x
2
∣
+
.
.
.
+
∣
x
n
∣
(1)
||x||_1 = |x_1|+|x_2|+...+|x_n| \tag{1}
∣∣x∣∣1=∣x1∣+∣x2∣+...+∣xn∣(1)
在数学中,范数(Norm)是一个函数,其将向量映射为非负值。直观上,范数可以理解为向量的“长度”或“大小”。
即各分量的绝对值之和。而向量x的2-范数计算公式为:
∣ ∣ x ∣ ∣ 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + . . . + ∣ x n ∣ 2 ) (2) ||x||_2=\sqrt{(|x_1|^2+|x_2|^2+...+|x_n|^2)} \tag{2} ∣∣x∣∣2=(∣x1∣2+∣x2∣2+...+∣xn∣2) (2)
即各分量的平方和再开平方。
而Scikit-learn中的Normalization过程,实际上就是将每一行数据视作一个向量,然后用每一行数据去除以该行数据的1-范数或者2-范数。具体除以哪个范数,以preprocessing.normalize函数中输入的norm参数为准。
from sklearn.preprocessing import normalize
import numpy as np
# 创建一个numpy数组
X = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
# 对数据进行归一化处理,使用默认的L2范数
X_normalized = normalize(X, norm='l2')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在上面的代码中,每一行的特征向量被归一化为单位范数(长度为1)。这就意味着每一个样本的所有特征值的平方和为1。也可以通过设置norm参数为’l1’,来进行L1范数归一化,使得每个样本的所有特征值的绝对值和为1。
4.4 核心对象类型:评估器(estimator)
许多功能强大的第三方库都定义了自己的核心对象类型,这些对象类型实际上都是源码中定义的特定类的实例。例如,NumPy的核心是数组(Array),Pandas的核心是DataFrame,PyTorch的核心则是张量(Tensor)。这些对象类型为数据分析和机器学习提供了强大的工具。
对于Scikit-learn来说,它的核心对象类型是评估器(Estimator)。可以将评估器看作是一种封装了各种机器学习模型的工具。在Scikit-learn中进行模型训练的过程,其核心就是围绕着这些评估器展开的。
总的来说,这些不同库的核心对象类型都为处理特定任务提供了便捷,使得可以更加专注于问题的解决,而不需要深入底层去处理复杂的细节。"
围绕评估器的使用也基本分为两步,其一是实例化该对象,其二则是围绕某数据进行模型训练。
4.5 高级特性-管道(Pipeline)
在Scikit-learn中,Pipeline是一种方便地将多个步骤组织在一起的工具,常常用于包含多个步骤的数据预处理和建模过程。Pipeline在确保步骤顺序执行,代码整洁,并在进行交叉验证时防止数据泄露方面有很大的优势。
Pipeline工作流程类似于生产线,每个步骤都是独立的,但所有的步骤都依次串联起来,上一步的输出作为下一步的输入。一个典型的Pipeline可能包括数据的缩放(如归一化或标准化)、特征选择、降维以及最后的模型训练等步骤。
直接来看下代码:
from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split # 加载糖尿病数据集 diabetes = load_diabetes() X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, random_state=0) # 创建一个Pipeline pipe = Pipeline([ ('scaler', StandardScaler()), # 第一步是标准化 ('regressor', LinearRegression()) # 第二步是线性回归 ]) # 使用Pipeline进行训练 pipe.fit(X_train, y_train) # 使用Pipeline进行预测 y_pred = pipe.predict(X_test) y_pred

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在这个例子中,创建了一个Pipeline,它包含两个步骤:一个是StandardScaler,用于对数据进行标准化处理;另一个是LinearRegression,用于进行回归预测。然后在训练集上调用fit方法,Pipeline会依次对每个步骤进行训练(也就是说,它首先在数据上进行标准化,然后使用标准化的数据训练回归模型)。当在测试集上调用predict方法时,Pipeline会依次对每个步骤进行预测(即先进行标准化,然后使用训练好的回归模型进行预测)。
4.6 模型保存
模型保存(model persistence)是一种将训练好的机器学习模型保存到磁盘,然后在以后的时间点(可能是在不同的环境中)加载和使用的技术。这是非常有用的,因为通常训练一个好的模型可能需要大量的时间和计算资源。一旦模型被训练,我们可能希望在未来重新使用它,而不是每次需要时都重新训练。
在Scikit-learn中,可以使用Python的内置库pickle,或者joblib库(一种特别针对大数据的pickle)来实现模型保存和加载。
直接上代码:演示如何使用joblib保存和加载模型:
pythonCopy codefrom sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris from joblib import dump, load # 加载iris数据集并训练一个随机森林分类器 iris = load_iris() clf = RandomForestClassifier() clf.fit(iris.data, iris.target) # 将模型保存到磁盘 dump(clf, 'randomforest_model.joblib') # 在需要的时候加载模型 clf_loaded = load('randomforest_model.joblib') # 使用加载的模型进行预测 y_pred = clf_loaded.predict(iris.data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
以上代码中,dump函数将模型保存到指定的文件中,而load函数则从文件中加载模型。注意,保存和加载模型的代码通常不会在同一脚本或同一会话中运行,这里只是为了演示。
如果模型包含了大量的numpy数组(例如,神经网络或随机森林等模型),使用joblib可能比使用pickle更高效。因此,Scikit-learn官方文档推荐使用joblib来保存和加载模型。
五、实操:使用Scikit-learn实现线性回归建模
5.1 建模流程
- Step 1:准备数据,生成1000个基本规律满足 y = 2 x 1 − x 2 + 1 y=2x_1-x_2+1 y=2x1−x2+1分布回归类数据集
# 科学计算模块 import numpy as np import pandas as pd # 绘图模块 import matplotlib as mpl import matplotlib.pyplot as plt # 回归数据创建函数 def arrayGenReg(num_examples = 1000, w = [2, -1, 1], bias = True, delta = 0.01, deg = 1): """回归类数据集创建函数。 :param num_examples: 创建数据集的数据量 :param w: 包括截距的(如果存在)特征系数向量 :param bias:是否需要截距 :param delta:扰动项取值 :param deg:方程最高项次数 :return: 生成的特征张和标签张量 """ if bias == True: num_inputs = len(w)-1 # 数据集特征个数 features_true = np.random.randn(num_examples, num_inputs) # 原始特征 w_true = np.array(w[:-1]).reshape(-1, 1) # 自变量系数 b_true = np.array(w[-1]) # 截距 labels_true = np.power(features_true, deg).dot(w_true) + b_true # 严格满足人造规律的标签 features = np.concatenate((features_true, np.ones_like(labels_true)), axis=1) # 加上全为1的一列之后的特征 else: num_inputs = len(w) features = np.random.randn(num_examples, num_inputs) w_true = np.array(w).reshape(-1, 1) labels_true = np.power(features, deg).dot(w_true) labels = labels_true + np.random.normal(size = labels_true.shape) * delta return features, labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这段代码的目的是创建一个回归类数据集。它定义了一个函数arrayGenReg,用于生成具有特定规律的回归类数据集。该函数根据给定的参数生成特征和标签数据,并可以选择是否添加截距项。特征数据根据正态分布随机生成,而标签数据根据设定的规律进行计算,并添加了服从正态分布的扰动项。这个函数的目的是方便生成用于回归问题的人工数据集。
- Step 2 : 根据函数生成特征和标签数据。
# 设置随机数种子
np.random.seed(24)
# 扰动项取值为0.01
features, labels = arrayGenReg(delta=0.01)
- 1
- 2
- 3
- 4
- 5
在这一步中,通过使用np.random.seed(24)设置了随机数种子为24。这样做的目的是确保接下来的随机生成过程可重复,即每次运行代码都会得到相同的随机数序列。然后,调用arrayGenReg函数生成回归类数据集的特征和标签。在这个例子中,将扰动项的取值设置为0.01,即delta=0.01。
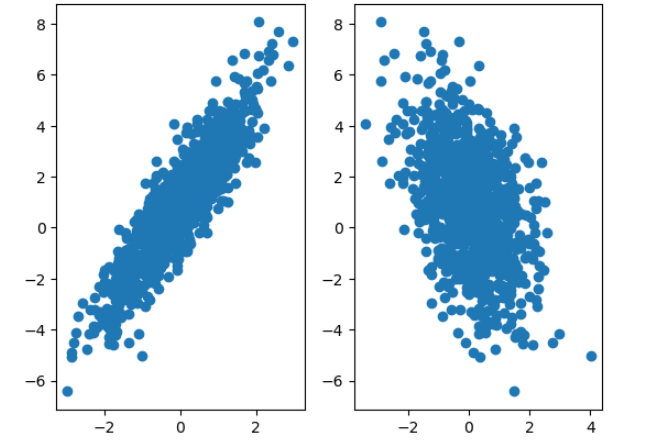
- Step3 : 绘制两个子图,观察数据集在不同特征维度上的分布情况
# 可视化数据分布
plt.subplot(121)
plt.plot(features[:, 0], labels, 'o')
plt.subplot(122)
plt.plot(features[:, 1], labels, 'o')
- 1
- 2
- 3
- 4
- 5
分别绘制特征矩阵features的第一列(features[:, 0])、第二列(features[:, 1])与标签列labels之间的关系。
- Step 4:调用Scikit-learn中的线性回归评估器
首先,从Scikit-learn库中导入线性回归评估器,使用LinearRegression评估器进行线性回归建模。
from sklearn.linear_model import LinearRegression
- 1
然后,创建一个线性回归模型对象,被赋值给名为model的变量。
model = LinearRegression()
- 1
接下来,从之前生成的数据集中提取特征矩阵和标签,特征矩阵选取了前两个特征(features[:, :2]),并将其赋值给X变量。将标签数组赋值给y变量。
codeX = features[:, :2] # 特征矩阵,选择前两个特征
y = labels # 标签数组
- 1
- 2
最后,通过调用评估器中的fit()方法对模型进行训练:
model.fit(X, y)
- 1
通过这些步骤,线性回归模型将被训练并学习数据集中的模式和关联。
在机器学习中,评估器(Estimator)是用于学习数据模式和进行预测的对象。线性回归评估器(LinearRegression)是一种用于拟合线性模型的评估器。
实例化评估器是为了创建一个可供使用的评估器对象。通过实例化,可以设置评估器的参数和属性,以便进行后续的训练和预测操作。在这段代码中,通过使用LinearRegression()创建了一个线性回归评估器的实例,并将其赋值给model变量。
fit()方法是评估器的一个重要方法,用于对模型进行训练。在训练过程中,评估器根据提供的特征矩阵和标签数据,通过最小化损失函数来调整模型的参数,使其能够更好地拟合数据。通过训练过程,模型能够学习特征与标签之间的关系,并建立一个预测模型。
综上所述,通过实例化评估器、提供特征矩阵和标签数据,以及调用fit()方法来进行模型训练,才能够使用评估器拟合数据,并得到一个能够预测未知样本的线性回归模型。
- Step 5: 查看模型训练参数
print("自变量参数:", model.coef_)
print("模型截距:", model.intercept_)
- 1
- 2
返回参数如下:

- Step 6: 结果解读
自变量参数:模型学习到的自变量参数为 [[1.99961892, -0.99985281]],接近于基本规律中的 [2, -1]。这表示模型能够很好地学习到数据生成的规律,并对特征之间的关系进行准确建模。
模型截距:模型学习到的截距为 [0.99970541],接近于基本规律中的 1。这意味着即使没有特征输入时,模型预测的输出值仍接近于1。
因此,根据模型的自变量参数和截距结果,可以得出结论:线性回归模型成功地学习到了基本规律中的特征之间的关系,并能够对未知样本进行准确的预测。
- Step 7: 使用MSE做模型评估
可以使用Scikit-learn库中的均方误差(Mean Squared Error,MSE)计算函数,计算了预测值和真实标签之间的均方误差。
# 在metrics模块下导入MSE计算函数
from sklearn.metrics import mean_squared_error
# 输入数据,进行计算
mean_squared_error(model.predict(X), y)
- 1
- 2
- 3
- 4
- 5
至此就完成了调用Scikit-learn的线性回归模型进行建模的流程
5.2 什么是超参数
重要:你必须要知道的概念:超参数
超参数,指的是无法通过数学过程进行最优值求解、但却能够很大程度上影响模型形式和建模结果的因素,例如线性回归中,方程中自变量系数和截距项的取值是通过最小二乘法或者梯度下降算法求出的最优解,而是否带入带入截距项、是否对数据进行归一化等,这些因素同样会影响模型形态和建模结果,但却是“人工判断”然后做出决定的选项,而这些就是所谓的超参数。
而Scikit-learn中,对每个评估器进行超参数设置的时机就在评估器类实例化的过程中。可以查看LinearRegression评估器的相关说明,其中Parameters部分就是当前模型超参数的相关说明:

在上述Step 4过程中,直接使用的是:
model = LinearRegression()
- 1
这是因为使用的都是默认的参数,这些超参数可以在实例化过程中进行设置和修改,例如可以创建一个不包含截距项的线性方程模型:
model1 = LinearRegression(fit_intercept=False)
model1.get_params()
- 1
- 2

对于一个已经实例化好的评估器,可以通过get_params来获取其建模所用的参数
在实例化模型的过程中必须谨慎的选择模型超参数,以达到最终模型训练的预期。不同的模型,有不同的超参数,这也是在后面学习建模过程中非常重要的一点。
5.3 如何在官网中找到模型操作文档
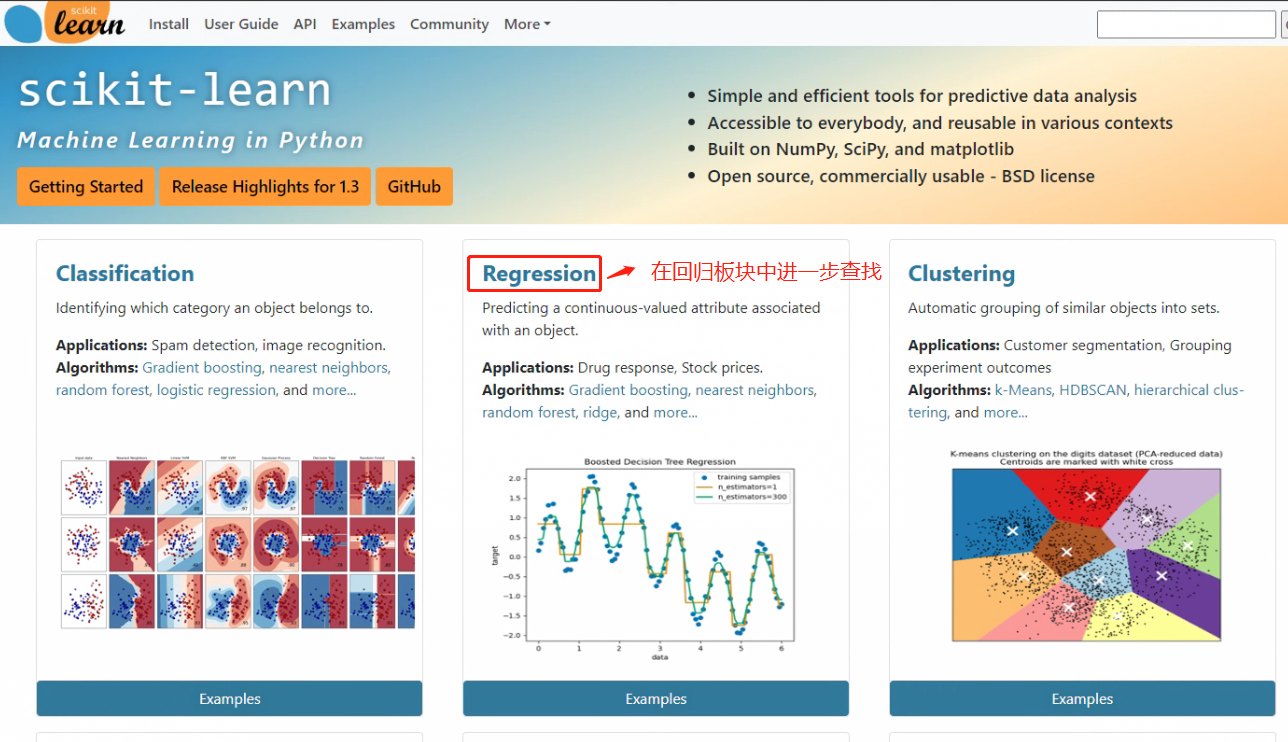
在官网中找到相关评估器(模型)说明,对于理解模型的原理及使用方法等是非常重要的。以LinearRegression评估器为例:
实现线性回归参数计算的方法有很多种,可以通过最小二乘法进行一步到位的参数求解,同时也能够通过梯度下降进行迭代求解,如果要详细了解训练过程的参数求解方法,就需要回到官网中查阅评估器的相关说明。首先我们已经知道了。
LinearRegression是一个回归类模型,所以肯定在sklearn官网说明Regression板块中。
点进去就可以看到,在该模块的1.1.1.Ordinary Least Squares中,就是关于LinearRegression评估器的相关说明。对于任何一个评估器(算法模型),说明文档会先介绍算法的基础原理、算法公式(往往就是损失函数计算表达式)以及一个简单的例子,必要时还会补充算法提出的相关论文链接,带领用户快速入门。
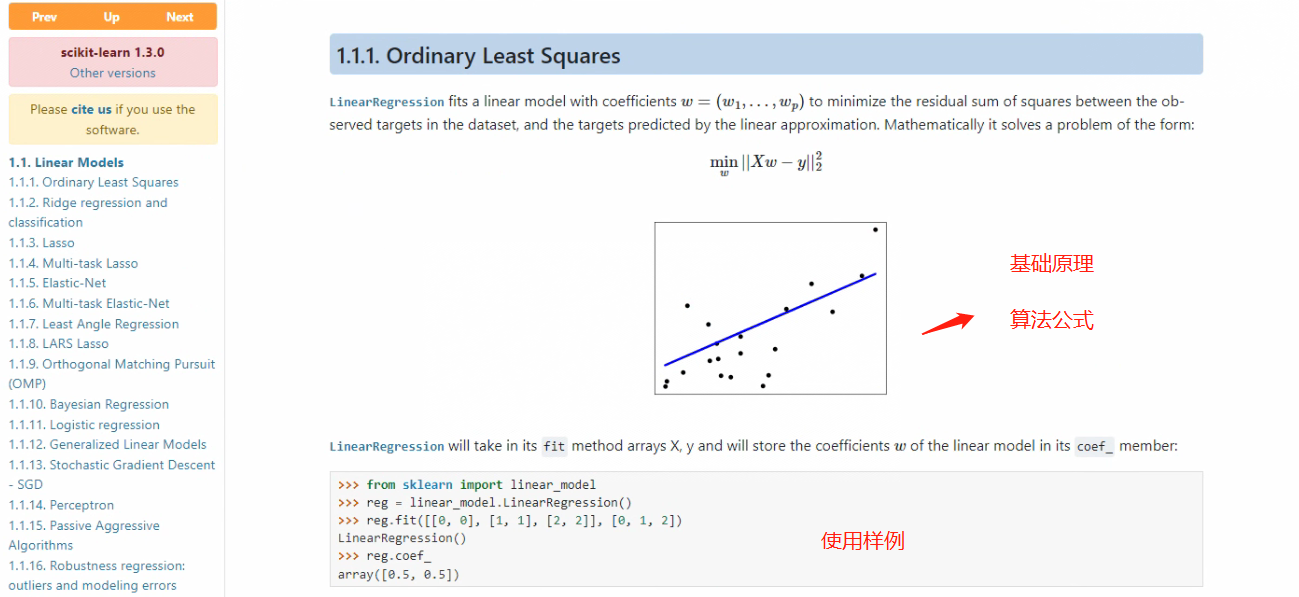
还会对算法的某些特性进行探讨(往往都是在使用过程中需要注意的问题),例如对于普通最小二乘法,最大的问题还是在于特征矩阵出现严重多重共线性时,预测结果会出现较大的误差。然后,说明文档会例举一个该算法的完整使用过程,也就是穿插在说明文档中的example。再然后,说明文档会讨论几个在模型使用过程中经常会比较关注的点,对于线性回归,此处列举了两个常见问题,其一是非负最小二乘如何实现,以及最小二乘法的计算复杂度。

Scikit-learn官网说明文档非常细致并且非常完整,当使用其他模型,按照相同的方式进行学习、检索,就能充分理解模型的原理和使用。
六、总结
本文详细解释了Scikit-learn的一些基础用法,包括它的定义、安装、核心对象类型(评估器)和关键特性(如数据预处理,数据集切分,数据标准化和归一化),并学习了如何实现线性回归模型,包括了解超参数的概念,以及如何保存和加载模型,希望通过本文,能帮助大家对Scikit-learn有一个更深入的认识。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。
谢谢您的支持,期待与您共同成长!

