
- 1PyQt5快速入门教程1-PyQt5开发环境的搭建
- 2Arduino开发板控制无刷电机的方法_arduino控制无刷电机
- 3element-ui Form表单验证_element form表单验证
- 4OBCP第七章 OB迁移-备份恢复技术架构及操作方法_ob数据库全量备份
- 5解决:Rabbitmq 消息队列阻塞的问题_rabbitmq 发送消息阻塞
- 6值得学习!阿里P8架构师“墙裂”推荐:Java程序员必读的架构书籍
- 7C语言——预处理_c语言中预处理是什么意思
- 8python代码分析-燃爆!17行Python代码做情感分析?你也可以的
- 9第四章:SpringBoot2.3.0 打包Jar,加载yml或properties配置文件顺序_springboot哪里配置java打包之后的名称
- 10用Python写一个简单的TCP客户端和服务端_python tcp client
Lion:闭源大语言模型的对抗性蒸馏_lion: adversarial distillation of closed-source la
赞
踩
通过调整 70k 指令跟踪数据,Lion (7B) 可以实现 ChatGPT 95% 的能力!
消息
我们目前正在致力于训练更大尺寸的版本(如果可行的话,13B、33B 和 65B)。感谢您的耐心等待。
- **[2023年6月10日]**我们发布了微调过程中解决OOM的说明,请在训练过程中查看。
- **[2023年5月26日]**我们发布了模型权重。看看7B型号!
- **[2023年5月25日]**我们发布了在线演示,在这里尝试我们的模型!
- **[2023年5月23日]**我们发布了训练和推理的代码。
内容
概述

我们的对抗性蒸馏框架的高级概述,其中我们基于高级闭源 LLM 制作了一个紧凑的学生 LLM,该 LLM 服务于三个角色:教师**、裁判员和生成器**。从左到右,迭代分为三个阶段:
- 模仿阶段*,*使学生的反应与教师的反应保持一致;
- 识别硬样本的辨别阶段;
- 生成阶段,用于生成新的硬样本*,*以升级向学生模型提出的挑战。
在线演示
我们将提供最新型号供您尽可能长时间地试用。您可以向 Lion 提出一些问题,我们很高兴听到您的反馈!
演示链接(72小时后过期,因此我们会定期更新链接)

由于训练数据是英文指令示例,因此您最好用英文提问。然而,我们发现Lion在一定程度上也能理解其他语言的指令。请看下面的案例:

恢复Lion权重
我们将 Lion 权重发布为增量权重,以符合 LLaMA 模型许可证。
您可以将我们的增量添加到原始 LLaMA 权重中以获得 Lion 权重。指示:
- 按照此处的说明获取 Huggingface 格式的原始 LLaMA 权重
- 请从Hugging Face下载我们的 Delta 模型
- 使用以下脚本通过应用我们的增量来获取 Lion 权重:
python src/weight_diff.py recover --path_raw huggyllama/llama-7b --path_diff YuxinJiang/Lion --path_tuned <path_to_store_recovered_weights>
- 1
推理
对于Lion的推理和训练,请首先安装要求:
pip install -r requirements.txt
- 1
我们为Lion提供了解码脚本,它读取输入文件并为每个样本生成相应的响应,最后将它们合并到输出文件中。它可以在具有 16GB GPU 的单台机器上运行。
python src/lion_inference.py \
--model_dir <path_to_hf_converted_lion_ckpt_and_tokenizer> \
--data_dir <path_to_input_json_file> \
--output_dir <path_to_output_json_file> \
--num_gpus 1
- 1
- 2
- 3
- 4
- 5
培训流程
下面显示了我们的对抗性蒸馏框架的一种迭代。
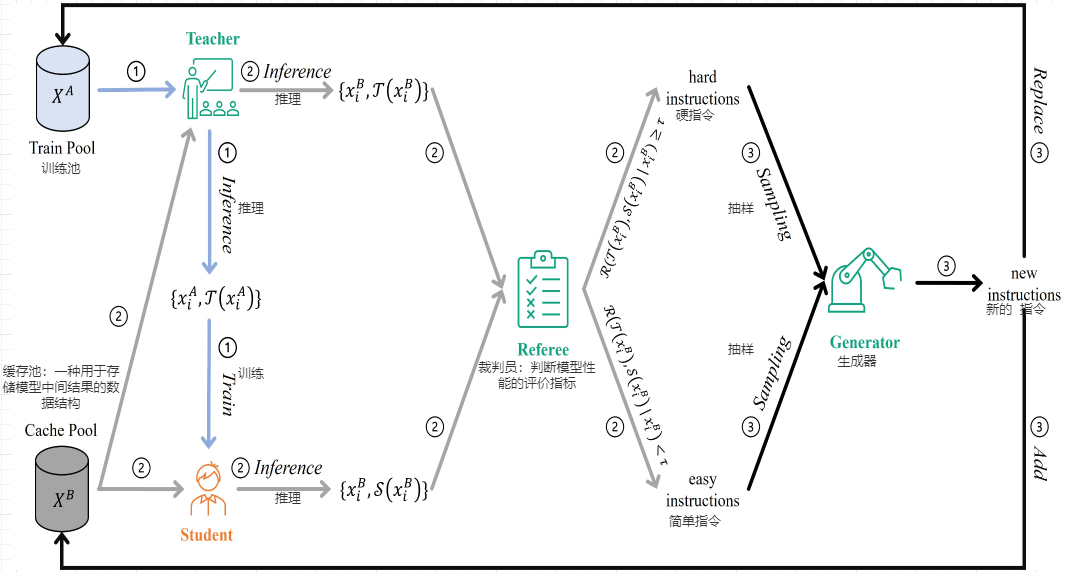
1、模仿阶段
1.1 获取老师对Train Pool的回复
python src/chatgpt_inference.py \
-q <path_to_json_file_for_the_Train_Pool> \
-o <path_to_chatgpt_inference_for_the_Train_Pool> \
--api_key <your_openai_api_key>
- 1
- 2
- 3
- 4
1.2 根据教师对训练池的反应对学生进行指令调整
微调是在具有 8 个 A100 80G GPU 的机器上进行的。
torchrun --nproc_per_node=8 --master_port=<your_random_port> src/train.py \ --model_name_or_path <path_to_hf_converted_ckpt_and_tokenizer> \ --data_path <path_to_chatgpt_inference_for_the_Train_Pool> \ --bf16 True \ --output_dir result \ --num_train_epochs 3 \ --model_max_length 1024 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 500 \ --save_total_limit 1 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --fsdp "full_shard auto_wrap" \ --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \ --tf32 True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
解决 OOM
简单来说,微调 7B 模型需要大约 7 x 8 x 2 = 112 GB 的 VRAM。上面给出的命令启用参数分片,因此任何 GPU 上都不会存储冗余模型副本。如果您想进一步减少内存占用,可以选择以下一些选项:
-
打开 FSDP 的 CPU 卸载
--fsdp "full_shard auto_wrap offload"。这可以节省 VRAM,但代价是运行时间更长。 -
根据我们的经验,DeepSpeed stage-3(带卸载)有时比带卸载的 FSDP 具有更高的内存效率。以下是使用具有 8 个 GPU 的 DeepSpeed stage-3 以及参数和优化器卸载的示例:
deepspeed src/train_deepspeed.py \ --model_name_or_path <path_to_hf_converted_ckpt_and_tokenizer> \ --data_path <path_to_chatgpt_inference_for_the_Train_Pool> \ --output_dir result \ --num_train_epochs 3 \ --model_max_length 1024 \ --per_device_train_batch_size 16 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 1 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 600 \ --save_total_limit 1 \ --learning_rate 2e-5 \ --warmup_ratio 0.03 \ --logging_steps 1 \ --lr_scheduler_type "cosine" \ --report_to "tensorboard" \ --gradient_checkpointing True \ --deepspeed srcs/configs/deepspeed_config.json \ --fp16 True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- DeepSpeed 库还提供了一些有用的函数来估计内存使用情况。
-
LoRA微调查询、键和值嵌入头的低秩切片。这可以将总内存占用量从 112GB 减少到大约 7x4=28GB。我们将来可能会发布对此的重新实现,但目前peft代码库可能是一个有用的资源。
2. 歧视阶段
2.1 获取老师对Cache Pool的响应
python src/chatgpt_inference.py \
-q <path_to_json_file_for_the_Cache_Pool> \
-o <path_to_chatgpt_inference_for_the_Cache_Pool> \
--api_key <your_openai_api_key>
- 1
- 2
- 3
- 4
2.2 获取学生对缓存池的回答
python src/lion_inference.py \
--model_dir <path_to_hf_converted_lion_ckpt_and_tokenizer> \
--data_dir <path_to_json_file_for_the_Cache_Pool> \
--output_dir <path_to_lion_inference_for_the_Cache_Pool> \
--num_gpus 8
- 1
- 2
- 3
- 4
- 5
2.3 要求裁判根据老师和学生的回答质量输出两个分数
python src/chatgpt_referee.py \
-a <path_to_chatgpt_inference_for_the_Cache_Pool> <path_to_lion_inference_for_the_Cache_Pool> \
-o <path_to_output_review_file> \
--api_key <your_openai_api_key>
- 1
- 2
- 3
- 4
2.4 区分硬指令和简单指令
python src/discrimination.py \
--review_path <path_to_output_review_file> \
--chatgpt_inference_path <path_to_chatgpt_inference_for_the_Cache_Pool> \
--lion_inference_path <path_to_lion_inference_for_the_Cache_Pool> \
--hard_save_path <path_to_identified_hard_instructions> \
--easy_save_path <path_to_identified_easy_instructions>
- 1
- 2
- 3
- 4
- 5
- 6
3. 生成阶段
3.1 生成新的硬指令
python -m src/generate_hard_instruction generate_instruction_following_data \
--seed_tasks_path <path_to_identified_hard_instructions> \
--output_dir <path_to_generated_hard_instructions> \
--num_instructions_to_generate 3000 \
--api_key <your_openai_api_key>
- 1
- 2
- 3
- 4
- 5
3.2 生成新的简单指令
python -m src/generate_easy_instruction generate_instruction_following_data \
--seed_tasks_path <path_to_identified_easy_instructions> \
--output_dir <path_to_generated_easy_instructions> \
--num_instructions_to_generate 3000 \
--api_key <your_openai_api_key>
- 1
- 2
- 3
- 4
- 5
评估
使用 GPT-4 自动评估
我们利用 GPT-4 自动评估两个模型在 80 个未见过的Vicuna 指令上的响应质量(分数从 1 到 10)。ChatGPT 已被选为参考模型来评估不同法学硕士的相对能力。相对分数以百分比形式报告,计算为分数总和的比率。
相对整体响应质量:

不同任务类别的相对响应质量:

具有对齐标准的人类评估
我们采用 Askel 等人提出的对齐标准。(2021),其中定义如果助理具有乐于助人、诚实和无害(HHH)的特点,则被认为是一致的。我们对 252 个UserOriented-Instructions进行了人工评估。为了估计获胜率,我们比较了下面每对模型之间获胜、平局和失败的频率。

引文
如果您使用此存储库中的代码,请引用我们的论文。
@article{DBLP:journals/corr/abs-2305-12870, author = {Yuxin Jiang and Chunkit Chan and Mingyang Chen and Wei Wang}, title = {Lion: Adversarial Distillation of Closed-Source Large Language Model}, journal = {CoRR}, volume = {abs/2305.12870}, year = {2023}, url = {https://doi.org/10.48550/arXiv.2305.12870}, doi = {10.48550/arXiv.2305.12870}, eprinttype = {arXiv}, eprint = {2305.12870}, timestamp = {Fri, 26 May 2023 11:29:33 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-2305-12870.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
免责声明
Xiv},
eprint = {2305.12870},
timestamp = {Fri, 26 May 2023 11:29:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2305-12870.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
## 免责声明
⚠️Lion**仅供研究使用**并获得许可。**严禁**商业用途。任何版本的Lion生成的内容都会受到随机性等不可控变量的影响,因此本项目无法保证输出的准确性。本项目对模型输出的内容不承担任何法律责任,也不承担因使用相关资源和输出结果而产生的任何损失。
- 1
- 2
- 3
- 4

