
- 1毕业设计:基于python图书推荐系统 协同过滤推荐算法 书籍推荐系统 Django框架(源码)✅_基于协同过滤+django的图书推荐系统可行性分析
- 2美团java一面二面HR面面经,java场景设计面试题_美团外包java
- 3如何评价GPT-4o?_azure gpt4o标准和全局标准的区别
- 4Flask实现分页显示数据_flask 分页
- 5java:使用shardingSphere访问mysql的分库分表数据
- 6Redis CRC16校验 1.原理概述
- 7ComfyUI中实现反推提示词的多种方案_clip询问机
- 8毕业设计-基于 BERT 的中文长文本分类系统_文本分类系统毕业设计
- 9AI智能体|使用扣子Coze从0到1搭建一个信息收集助手,并接入微信公众号
- 10面向小白的本地部署大模型完整教程:LangChain + Streamlit+ LLama
ICLR上新 | 强化学习、扩散模型、多模态语言模型,你想了解的前沿方向进展全都有_强化学习最新论文
赞
踩
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
今天的“科研上新”将为大家带来多篇微软亚洲研究院在 ICLR 2024 上的精选论文解读,涉及领域涵盖深度强化学习、多模态语言模型、时间序列扩散模型、无监督学习等多个前沿主题。
本期内容速览
01. 应对深度强化学习中的信号延迟问题
02. 级联强化学习
03. DyVal:首个大语言模型的动态评测协议
04. KOSMOS-2:将多模态语言模型同视觉世界连接对应
05. MG-TSD:基于引导学习过程的多粒度时间序列扩散模型
应对深度强化学习中的信号延迟问题

论文链接:https://openreview.net/forum?id=Z8UfDs4J46
近年来,深度强化学习(DRL)及其应用迅速发展,它不仅在虚拟任务(如视频游戏和模拟机器人环境)上取得了成功,也在许多具有挑战性的现实世界任务中得到了证明,例如控制托卡马克和通过人类反馈调整大语言模型。然而,导致智能体可能无法立即观察到当前环境状态或其行动无法立即影响环境的信号延迟,在深度强化学习研究中长期存在且经常被忽视。该问题广泛存在于各种实际应用中,对基于深度强化学习解决方案的有效性产生了重大影响,因此该挑战迫切需要研究进行应对。
为了解决 DRL 中的信号延迟问题,研究员们首先通过扩展马尔可夫决策过程框架来定义延迟观测马尔可夫决策过程(DOMDP),从而将信号延迟的情况纳入考虑之中。然后,研究员们在论文中阐明了 DRL 里信号延迟存在的挑战,并展示了常规 DRL 算法和部分可观测马尔可夫决策过程(POMDP)的通用方法受到延迟的严重影响。
针对这些挑战,研究员们提出了一系列新方法,旨在提高存在延迟时 DRL 算法的性能。结合理论见解和实际算法调整,研究员们扩展了传统的 actor-critic 框架,并提出了有效的策略来克服这些挑战。充分的实验结果表明,在具有较大延迟的连续机器人控制任务中,采用该论文提出的方法后,DRL 算法取得了卓越的性能,其结果与无延迟情况相比,性能损失较小。
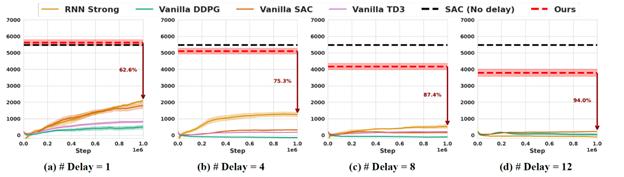
图1:该论文中的方法(红色虚线)可以在有信号延迟的情况下保持较好的效果,而其他常用的方法在有延迟的情况下表现显著下降(作为对比,黑色虚线是没有信号延迟情况下的表现)。
这项研究在解决 DRL 中一个基本挑战方面迈出了重要的一步,不仅拓宽了其在现实环境中的应用范围,也为自主系统的持续发展做出了贡献。通过开发有效应对信号延迟的方法,研究员们增强了 DRL 的实用性和可靠性,为其在非理想条件下的应用奠定了基础。
级联强化学习

论文链接:https://arxiv.org/abs/2401.08961
近年来,一种名为级联多臂老虎机(cascading bandits)[Kveton et al., 2015]的模型受到了广泛关注,在推荐系统、在线广告中应用广泛。在级联多臂老虎机中,智能体需要在众多选项中挑选一个选项列表推荐给用户,每个选项都有一个未知的吸引概率。智能体的目标则是不断优化推荐的选项列表,以最大化期望累积奖励(点击率)。
然而,现有的级联多臂老虎机模型忽略了用户状态(如用户历史行为)对推荐的影响,以及用户状态可能的改变。为了解决这一问题,微软亚洲研究院的研究员们提出了一种名为级联强化学习(cascading reinforcement learning)的模型。在该模型中,每个用户状态-选项的匹配对有一个未知的吸引概率、一个未知的状态转移分布和一个奖励。如图2所示,在每个时刻,智能体会先观察到当前的用户状态,然后推荐一个长度为 m 的选项列表。如果用户对某一选项感兴趣并点击,那么用户将转移到下一状态,智能体则会获得一个奖励。智能体的目标是最大化期望累积奖励,因此该模型能有效地将用户状态及其变化纳入推荐过程中。
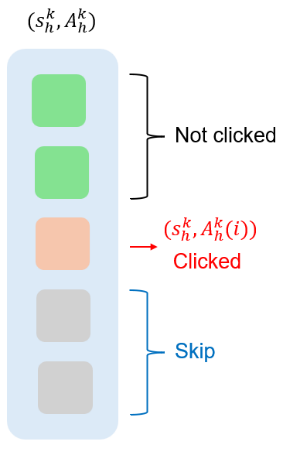
图2:级联强化学习模型
针对该模型,研究员们首先基于动态规划设计了一个快速离线求解器 BestPerm,它能够在多项式时间内计算出最优的选项列表。然后,研究员们提出了强化学习算法 CascadingVI,该算法能够达到 O ̃(H√HSNK) 的后悔度(regret)上界,这个结果只依赖于选项的个数
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

