
DL/ML/RL/TL/FL机器学习框架总结
赞
踩
前言
本文总结了DL/深度学习、ML/机器学习、DML/分布式机器学习、AutoML/自动化机器学习、RL/强化学习、MLaaS/机器学习及服务、SR/语音识别领域的机器学习框架,可作为学习、研究、研发的参考资料。
1.DL/深度学习框架
PyTorch
PyTorch是一个开源的Python机器学习库,基于Torch,用于计算机视觉、自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。


PyTorch:https://github.com/pytorch/pytorch
PyTorch Examples:https://github.com/pytorch/examples
PyTorch Tutorials:https://github.com/pytorch/tutorials
PyTorch 官网:https://pytorch.org/
Pytorch Doc:https://pytorch.org/docs/versions.html
PyTorch Doc Stable:https://pytorch.org/docs/stable/index.html
PyTorch 中文教程:https://pytorch.apachecn.org/
TensorFlow
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。 Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)。TensorFlow支持多种客户端语言下的安装和运行。截至版本1.12.0,绑定完成并支持版本兼容运行的语言为C和Python,其它试验性绑定完成的语言为JavaScript、C++、Java、Go和Swift,依然处于开发阶段的包括C#、Haskell、Julia、Ruby、Rust和Scala。

TensorFlow API:https://www.tensorflow.org/api_docs
TensorFlow Guide Core:https://www.tensorflow.org/guide/core
TensorFlow 2.0 Tutorials:https://www.tensorflow.org/tutorials/quickstart/beginner?hl=zh-cn
TensorFlow 官网:https://www.tensorflow.org/?hl=zh-cn
TensorFlow 概述:https://www.tensorflow.org/overview?hl=zh-cn
TensorFlow 简介:https://www.tensorflow.org/learn?hl=zh-cn
TensorFlow 教程:https://www.tensorflow.org/tutorials?hl=zh-cn
TensorFlow Github:https://github.com/tensorflow/tensorflow
Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。 Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件。

Keras 官网:https://keras.io/
Keras TensorFlow Guide:https://www.tensorflow.org/guide/keras?hl=zh-cn
Keras Wiki:https://en.wikipedia.org/wiki/Keras
Keras Github:https://github.com/keras-team/keras
Keras CV:https://github.com/keras-team/keras-cv
Keras Tuner:https://github.com/keras-team/keras-tuner
Keras NLP:https://github.com/keras-team/keras-nlp
PaddlePaddle
PaddlePaddle作为国内首个自主研发的深度学习平台,自2016年起正式向专业社区开源,是一个技术先进、功能丰富的产业平台,涵盖核心深度学习框架、基础模型库、终端- 端到端开发套件、工具和组件以及服务平台。 PaddlePaddle源于工业实践,执着于工业化。已广泛应用于制造业、农业、企业服务等多个行业,服务超过800万开发者、22万家企业,生成80万个模型。
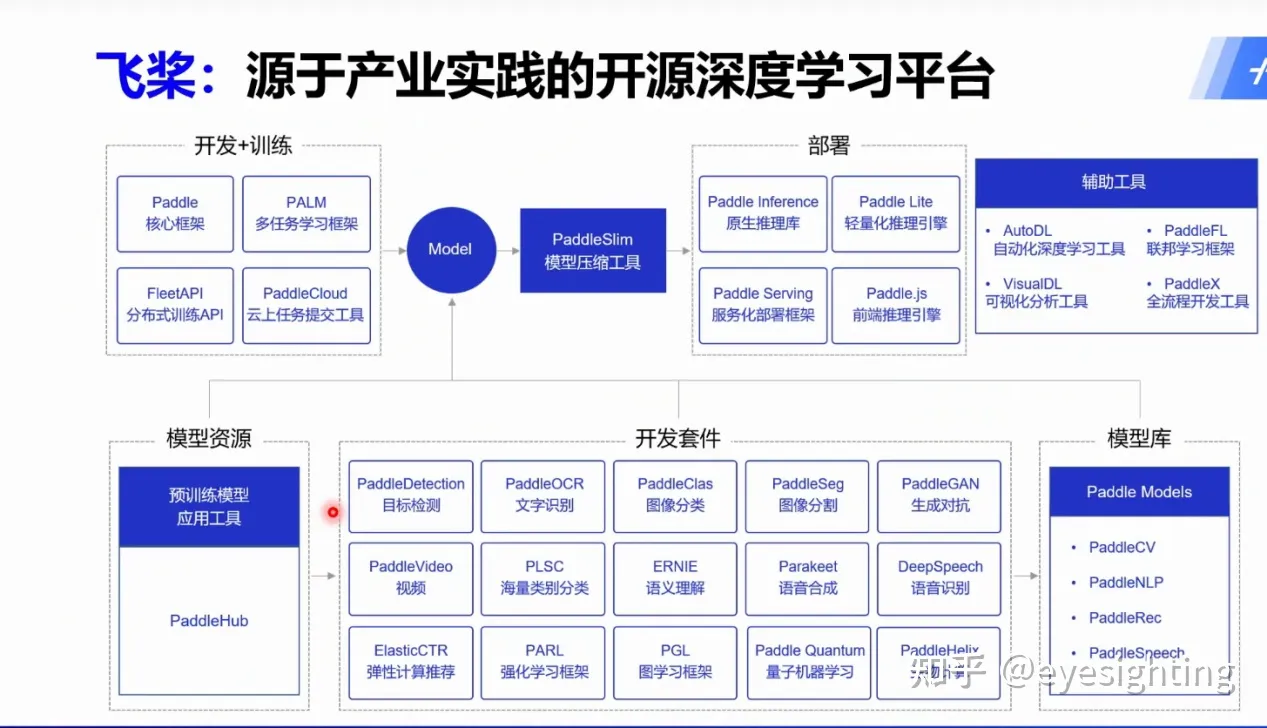
Paddle 官网:https://www.paddlepaddle.org.cn/
Paddle 论文:https://ieeexplore.ieee.org/document/10074745/
Paddle API:https://www.paddlepaddle.org.cn/documentation/docs/en/api/index_en.html
Paddle Guide:https://www.paddlepaddle.org.cn/documentation/docs/en/guides/index_en.html
Paddle Tutorials:https://www.paddlepaddle.org.cn/tutorials/projectdetail/5603475
Paddle Models:https://aistudio.baidu.com/modelsoverview?lang=en
Caffe
Caffe是一个清晰而高效的深度学习框架,其作者是博士毕业于UC Berkeley的 Yangqing Jia编写。
Caffe:https://github.com/BVLC/caffe
Caffe 官网:https://caffe.berkeleyvision.org/
Caffe 安装:https://caffe.berkeleyvision.org/installation.html
Caffe 教程:https://caffe.berkeleyvision.org/tutorial/
Caffe 模型:https://caffe.berkeleyvision.org/model_zoo.html
Caffe2
Caffe2 是一个兼具表现力、速度和模块性的深度学习框架,是 Caffe 的实验性重构,能以更灵活的方式组织计算。由 FaceBook 开源,该框架可以用在 iOS、Android 和树莓派上训练和部署模型。
Caffe2:https://github.com/facebookarchive/caffe2
Caffe2 官网:https://caffe2.ai/
Caffe2 安装:https://caffe2.ai/docs/getting-started.html?platform=windows&configuration=compile
Caffe2 对比:https://caffe2.ai/docs/caffe-migration.html
Caffe2 教程:https://caffe2.ai/docs/tutorials.html
Caffe2 介绍:https://developer.nvidia.com/caffe2
MegEngine
开源深度学习框架旷视天元(MegEngine)是旷视自主研发的国产工业级深度学习框架,是旷视新一代AI生产力平台Brain++的最核心组件,在2020年3月正式向全球开发者开源。MegEngine凭借其训练推理一体、超低硬件门槛和全平台高效推理3大核心优势,能够帮助企业与开发者大幅节省产品从实验室原型到工业部署的流程,真正实现小时级的转化能力。


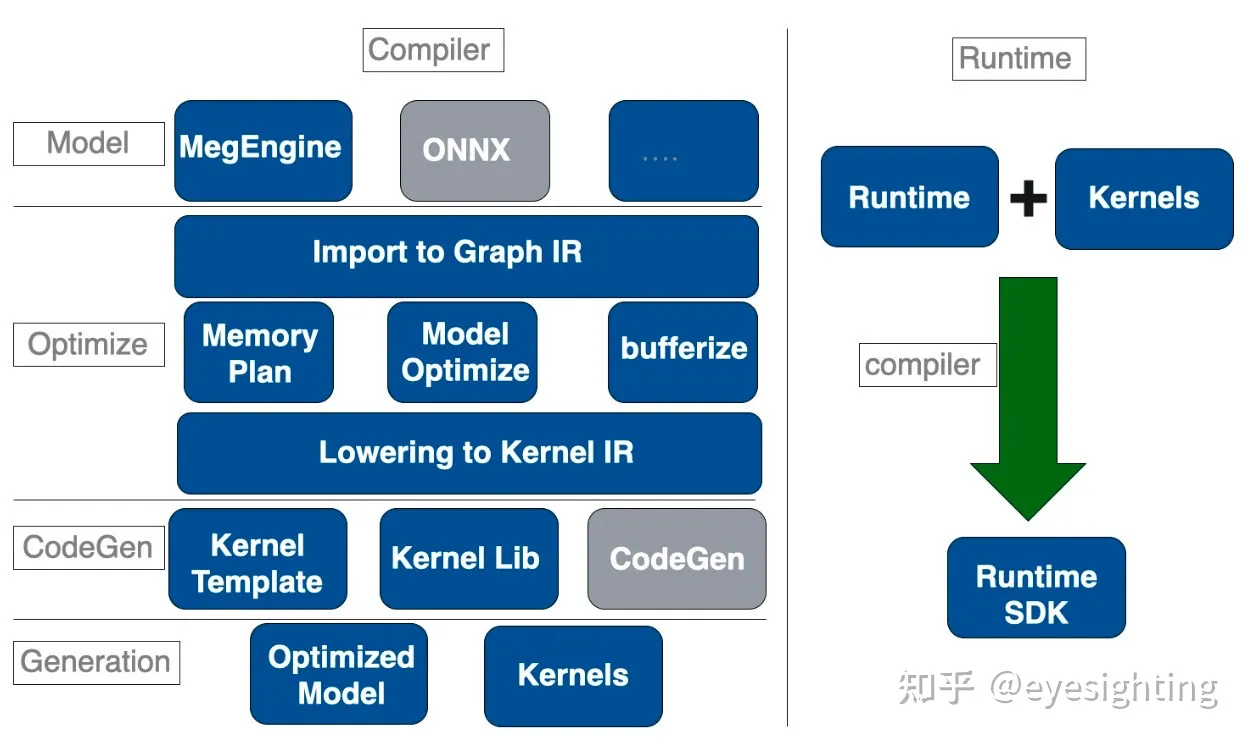
MegEngine:https://github.com/MegEngine
MegEngine 官网:https://www.megengine.org.cn/
MegEngine Doc:https://www.megengine.org.cn/doc/stable/en/
MindSpore
MindSpore是由华为于2019年8月推出的新一代全场景AI计算框架,2020年3月28日,华为宣布MindSpore正式开源。MindSpore着重提升易用性并降低AI开发者的开发门槛,MindSpore原生适应每个场景包括端、边缘和云,并能够在按需协同的基础上,通过实现AI算法即代码,使开发态变得更加友好,显著减少模型开发时间,降低模型开发门槛。通过MindSpore自身的技术创新及MindSpore与华为昇腾AI处理器的协同优化,实现了运行态的高效,大大提高了计算性能;MindSpore也支持GPU、CPU等其它处理器。

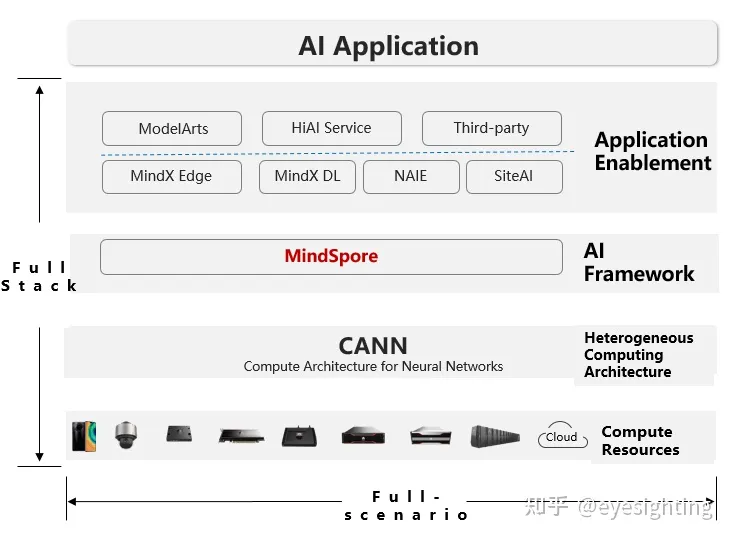


MindSpore:https://github.com/mindspore-ai
MindSpore:https://github.com/mindspore-ai/mindspore
MindSpore GraphRngine:https://github.com/mindspore-ai/graphengine
MindSpore Docs:https://github.com/mindspore-ai/docs
MindSpore Models:https://github.com/mindspore-ai/models
MindSpore Toolkits:https://github.com/mindspore-ai/toolkits
OneFlow
分布式性能(高效性)是深度学习框架的核心技术难点,OneFlow围绕性能提升和异构分布式扩展,秉持静态编译和流式并行的核心理念和架构,解决了集群层面的内存墙挑战,技术水平世界领先。
OneFlow可降低计算集群内部的通信和调度消耗,提高硬件利用率,加快模型训练速度,训练成本时间大幅缩减。官方权威评测,OneFlow在常用模型场景下全面领先国内外竞品。
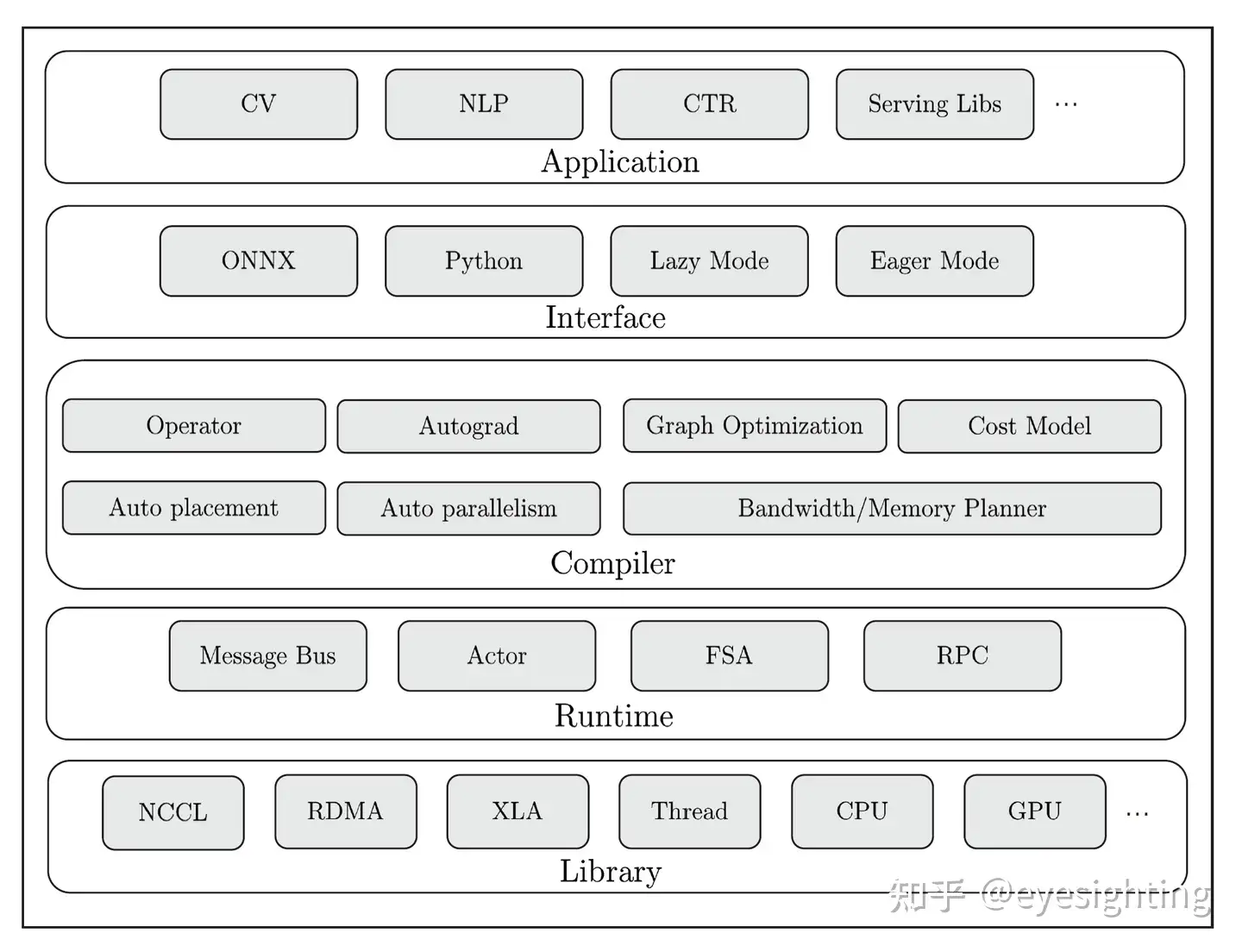
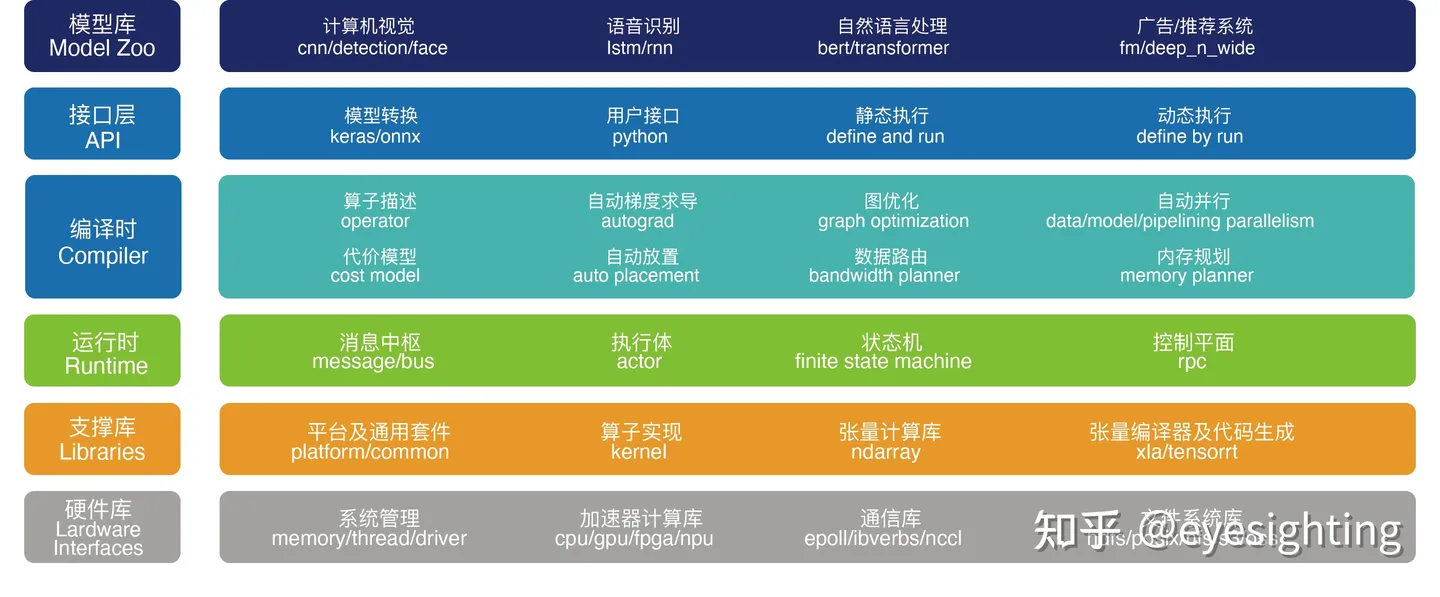
OneFlow:https://github.com/Oneflow-Inc/oneflow
OneFlow 论文:https://arxiv.org/abs/2110.15032
OneFlow Doc:https://docs.oneflow.org/en/master/index.html
OneFlow 分部署训练:https://docs.oneflow.org/en/master/parallelism/01_introduction.html
OneFlow 教程:https://docs.oneflow.org/en/master/cookies/global_tensor.html
OneFlow API:https://oneflow.readthedocs.io/en/master/
OneFlow Quick Start:https://docs.oneflow.org/en/master/basics/01_quickstart.html
ScikitLearn
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
ScikitLearn 官网:https://scikit-learn.org/
ScikitLearn Install:https://scikit-learn.org/stable/install.html
ScikitLearn UserGuide:https://scikit-learn.org/stable/user_guide.html
ScikitLearn API:https://scikit-learn.org/stable/modules/classes.html
Mathworks
Mathworks DL Toolbox:https://www.mathworks.com/products/deep-learning.html
Mathworks ONNX:https://www.mathworks.com/help/deeplearning/ref/exportonnxnetwork.html
Mathworks TensorRT:https://www.mathworks.com/help/gpucoder/ug/tensorrt-target.html
Theano
Theano是一个Python库,专门用于定义、优化、求值数学表达式,效率高,适用于多维数组。Theano是一个Python库,允许您有效地定义,优化和评估涉及多维数组的数学表达式。
Theano:https://github.com/Theano/Theano
Theano Wiki:https://en.wikipedia.org/wiki/Theano_(software)
Torch
Torch 是一个基于 Lua 编程语言的科学计算框架,主要用于深度学习研究。在 Torch 中,所有的数据都可以被表示为多维张量(tensor),并且支持自动求导。Torch 同时也提供了一些常见的深度学习模型和优化算法的实现。
Torch:http://torch.ch/
Torch:http://github.com/torch/torch7
Torch Tutorials:https://github.com/torch/tutorials
Torch Demo:https://github.com/torch/demos
Torch Start:https://torch.ch/docs/getting-started.html
MLLib
MLlib 是 Spark 的机器学习 (ML) 库。 其目标是使实用的机器学习变得可扩展且简单。 在较高层面上,它提供了以下工具:
ML算法:分类、回归、聚类、协同过滤等常见学习算法;
特征化:特征提取、变换、降维和选择;
Pipelines:用于构建、评估和调整 ML Pipelines 的工具;
持久性:保存和加载算法、模型和管道;
实用工具:线性代数、统计、数据处理等。
MLLib:https://spark.apache.org/docs/1.2.0/mllib-guide.html
MLLib:https://spark.apache.org/docs/latest/ml-guide.html
Ray
Ray 是一个为了给分布式提供通用的 API 发明出来的分布式计算框架,希望通过简单但通用的抽象编程方式,让系统自动完成所有的工作。Ray 的设计者基于这个理念让 Ray 可以跟 Python 紧密相连,能够通过很少的代码就能处理业务,而其它的并行、分布式内存管理等问题都不用担心,Ray 会根据这些资源的情况自动调度和缩放。

Ray:https://github.com/ray-project/ray
Ray:https://docs.ray.io/en/latest/rllib/rllib-rlmodule.html
http://ML.NET
跨平台机器学习框架。
http://ML.NET:https://dotnet.microsoft.com/en-us/apps/machinelearning-ai/ml-dotnet
http://ML.NET:https://cloud.tencent.com/developer/article/2368012
2.ML/传统机器学习框架
XGBoost
XGBoost 是一个优化的分布式梯度增强库,其设计目标是高效高效、灵活框架下实现机器学习算法。 XGBoost 提供了并行树提升(也称为 GBDT、GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要分布式环境(Kubernetes、Hadoop、SGE、Dask、Spark、PySpark)上运行,可以解决超过数十亿个示例的问题。
XGBoost:https://github.com/dmlc/xgboost
XGBoost Doc:https://xgboost.readthedocs.io/en/stable/
XGBoost 论文:https://arxiv.org/abs/1603.02754
LightGBM
LightGBM(Light Gradient Boosting Machine)是一个使用基于树的学习算法的梯度增强框架。它被设计为分布式且高效的,具有以下优点: 训练速度更快,效率更高;降低内存使用量。 更好的准确性;支持并行、分布式和 GPU 学习;能够处理大规模数据。
LightGBM:https://github.com/microsoft/LightGBM
LightGBM Doc:https://lightgbm.readthedocs.io/en/stable/
LightGBM 论文:https://proceedings.neurips.cc/paper_files/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
LibSVM
Libsvm是一个简单,易于使用,高效的支持向量机分类和回归软件。解决了C-SVM分类、nu-SVM分类、一类svm、ε - svm回归、nu-SVM回归等问题。为C-SVM分类提供了一种自动模型选择工具。
LibSVM:https://github.com/cjlin1/libsvm
LibSVM:https://www.csie.ntu.edu.tw/~cjlin/libsvm/oldfiles/index-1.0.html
LIBSVM Tools:https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/
3.RL/强化学习框架
RLlib
RLlib 是一个用于强化学习 (RL) 的开源库, 提供支持 生产级、高度分布式的 RL 工作负载,同时保持 适用于各种行业应用的统一且简单的 API。
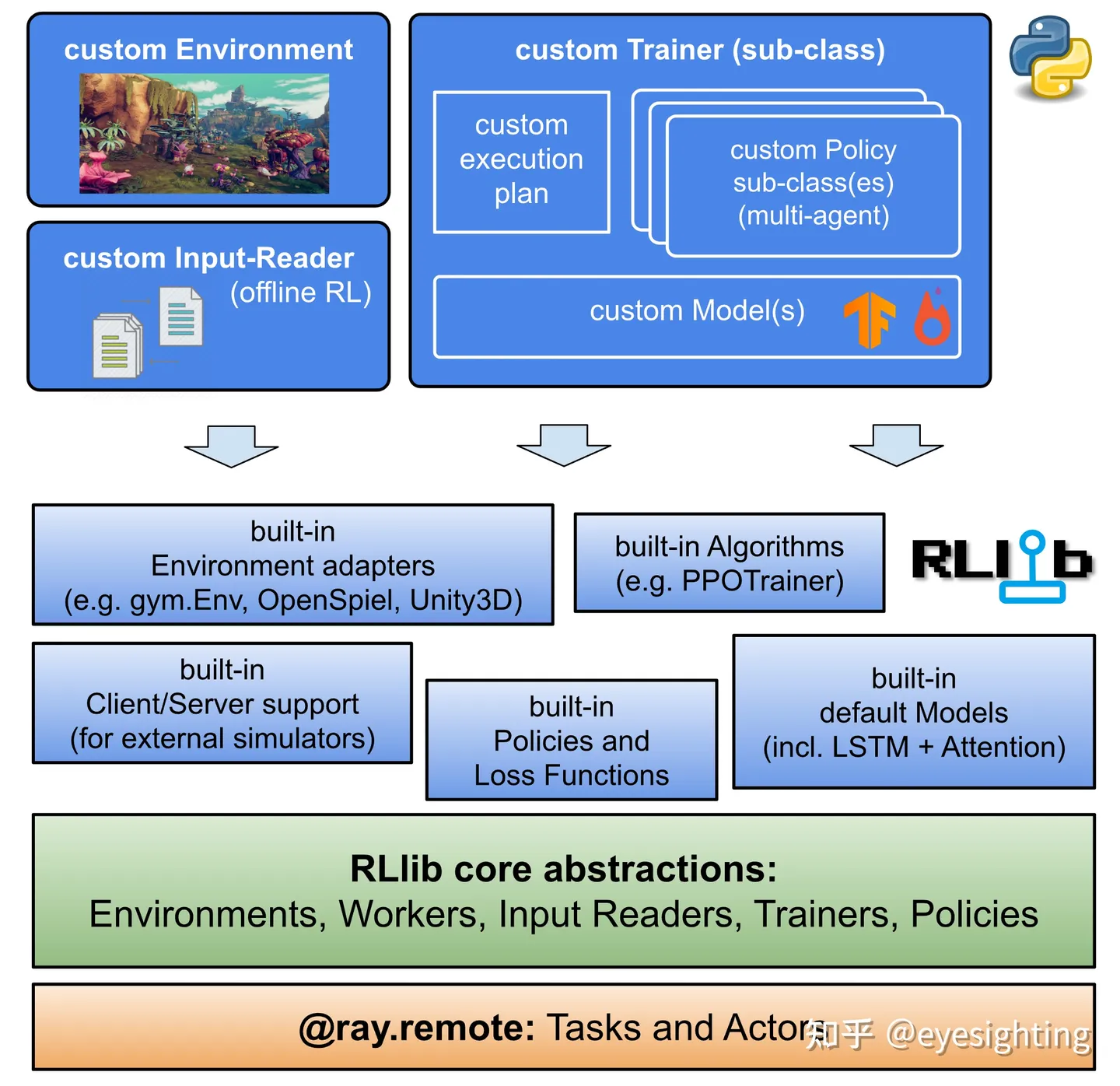
RLlib:https://docs.ray.io/en/latest/rllib/index.html
TorchRL
TorchRL 是 PyTorch 的开源强化学习 (RL) 库。 它提供了 pytorch 和 python-first、RL 的低级和高级抽象,旨在实现高效、模块化、记录 并经过正确测试。大部分都是用Python以高度模块化的方式编写的,这样研究人员就可以轻松地交换组件、转换它们或编写新的组件。


TorchRL:https://github.com/pytorch/rl
TorchRL:https://pytorch.org/rl/
TorchRL API:https://pytorch.org/rl/reference/data.html
TorchRL 论文:https://arxiv.org/abs/2306.00577
PaddleRL
PARL是一个灵活高效的强化学习框架。
PaddleRL:https://github.com/PaddlePaddle/PARL
TF-Agents
TF-Agents:一个可靠、可扩展且易于使用的 TensorFlow 库,用于上下文 Bandits 和强化学习。
TF-Agents:https://github.com/tensorflow/agents
4.TL/迁移学习框架
CCTL
协作性跨域迁移学习框架(CCTL),CCTL使用对称"同伴"网络评估源域(source domain)在目标域(target domain,需要预测的业务域)上的信息增益,并使用信息流网络调整每个源域样本的信息传递权重,这种方法可以充分利用其他域数据,同时避免负迁移。此外,利用表征增强网络用作辅助任务来保留特定领域的特征。
KDD'23 美团 | 用于跨域推荐的协同迁移学习框架:https://cloud.tencent.com/developer/article/2313757
EasyTransfer
EasyTransfer:用于 NLP 应用的简单且可扩展的深度迁移学习平台。

EasyTransfer:https://github.com/alibaba/EasyTransfer
简单易用高性能一文了解开源迁移学习框架EasyTransfer:https://zhuanlan.zhihu.com/p/268060180
阿里云开源的业界首个面向NLP场景深度迁移学习框架EasyTransfer:https://www.wonmay.com/newsitem/278530943
NVTLT
NVIDIA TAO Toolkit 是一个基于 TensorFlow 和 PyTorch 构建的低代码 AI 工具包, 通过抽象来简化和加速模型训练过程 人工智能模型和深度学习框架的复杂性。与陶, 用户可以从 NGC 100 多个预先训练的视觉 AI 模型中选择一个, 无需编写一行代码即可对自己的数据集进行微调和自定义。 TAO 的输出是经过训练的 ONNX 格式的模型,可以部署 在任何支持 ONNX 的平台上。
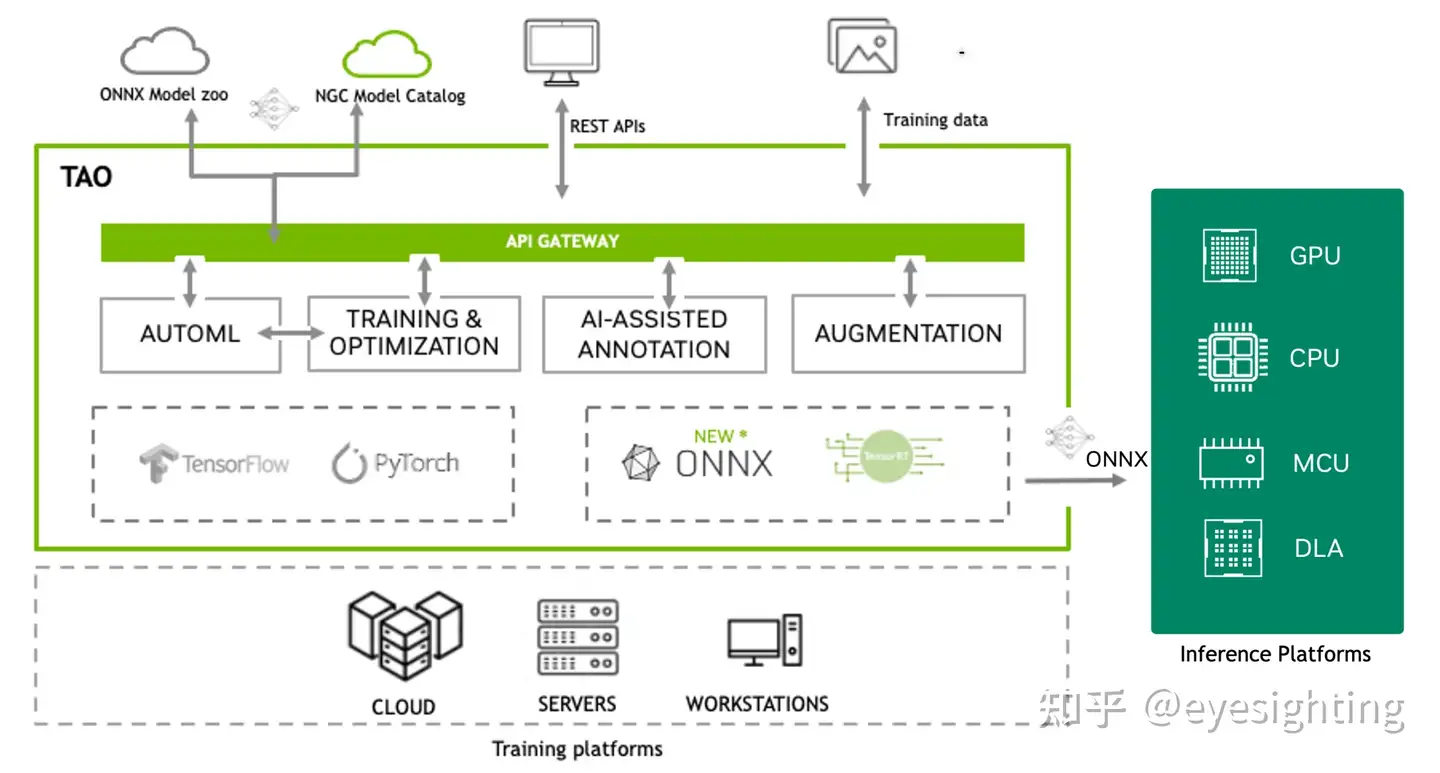
NVTLT 手册:https://docs.nvidia.com/metropolis/TLT/tlt-user-guide/
NVTLT 框架:https://docs.nvidia.com/tao/tao-toolkit/text/overview.html#tlt-computer-vision-workflow-overview
英伟达迁移学习矿机TLT:https://medium.com/@Smartcow_ai/nvidia-transfer-learning-toolkit-a-comprehensive-guide-75148d1ac1b
5.FL/联邦学习框架
FATE
FATE(Federated AI Technology Enabler)是全球首个工业级联邦学习开源框架,使企业和机构能够在数据上进行协作,同时保护数据安全和隐私。 它实现基于同态加密和多方计算(MPC)的安全计算协议。 为了支持各种联邦学习场景,FATE现在提供了多种联邦学习算法,包括逻辑回归、基于树的算法、深度学习和迁移学习。
FATE:https://github.com/FederatedAI/FATE
PaddleFL
PaddleFL是一个基于PaddlePaddle的开源联邦学习框架。研究人员可以使用 PaddleFL 轻松复制和比较不同的联邦学习算法。开发人员还可以从 PaddleFL 中受益,因为可以轻松地在大规模分布式集群中部署联邦学习系统。 PaddleFL中将提供多种联邦学习策略,应用于计算机视觉、自然语言处理、推荐等领域。将提供传统机器学习训练策略(例如多任务学习、迁移学习)在联邦学习环境中的应用。
基于PaddlePaddle的大规模分布式训练和Kubernetes上训练作业的弹性调度,PaddleFL可以基于全栈开源软件轻松部署。
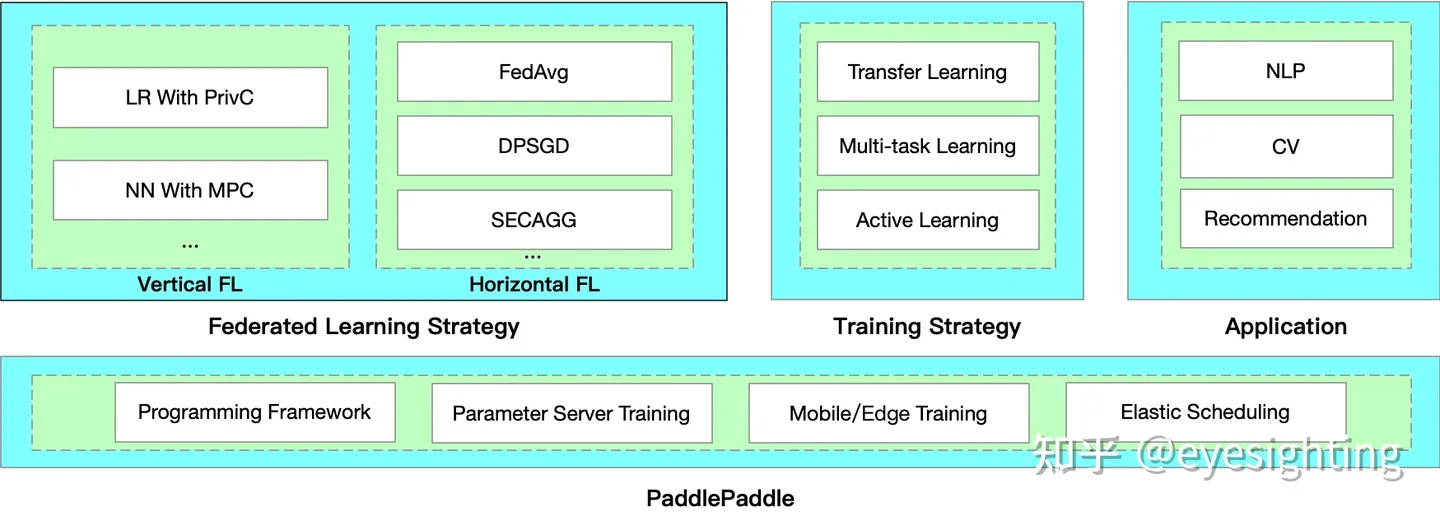
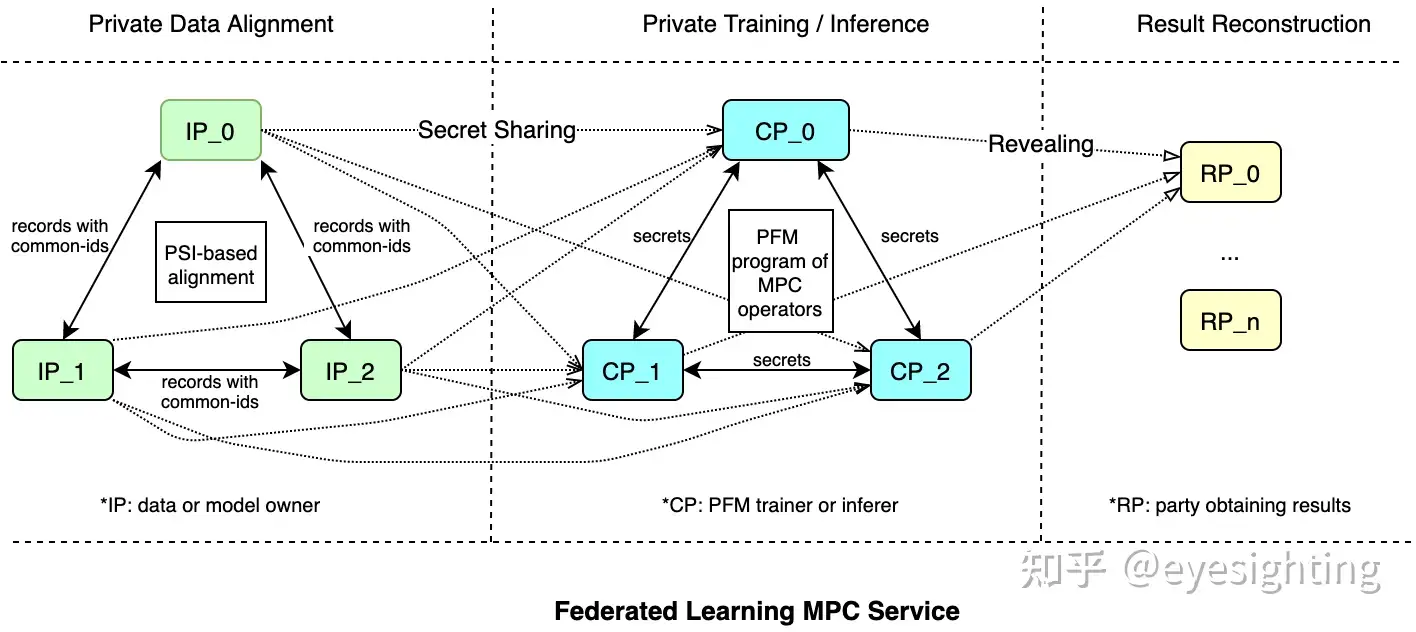
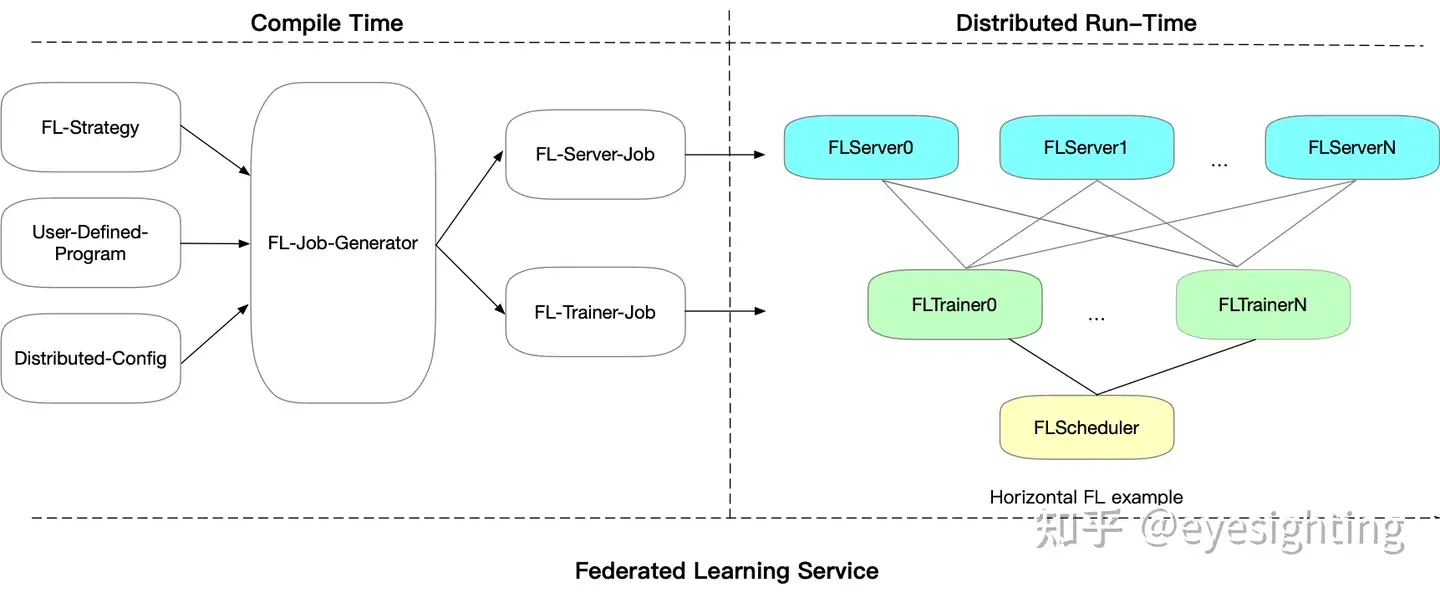
PaddleFL:https://github.com/PaddlePaddle/PaddleFL
PaddleFL:https://paddlefl.readthedocs.io/en/latest/introduction.html
PaddleFL:https://github.com/PaddlePaddle/PaddleFL/blob/master/docs/source/examples/md/dpsgd-example.md
FedLearner
Fedlearner 是协作机器学习框架,可以对机构之间分布的数据进行联合建模。
FedLearner:https://github.com/bytedance/fedlearner
浅谈字节最新开源联邦机器学习平台Fedlearner:https://zhuanlan.zhihu.com/p/281586278
FedML
FEDML 开源:一个统一且可扩展的机器学习库,用于在任何地方、任何规模运行训练和部署。
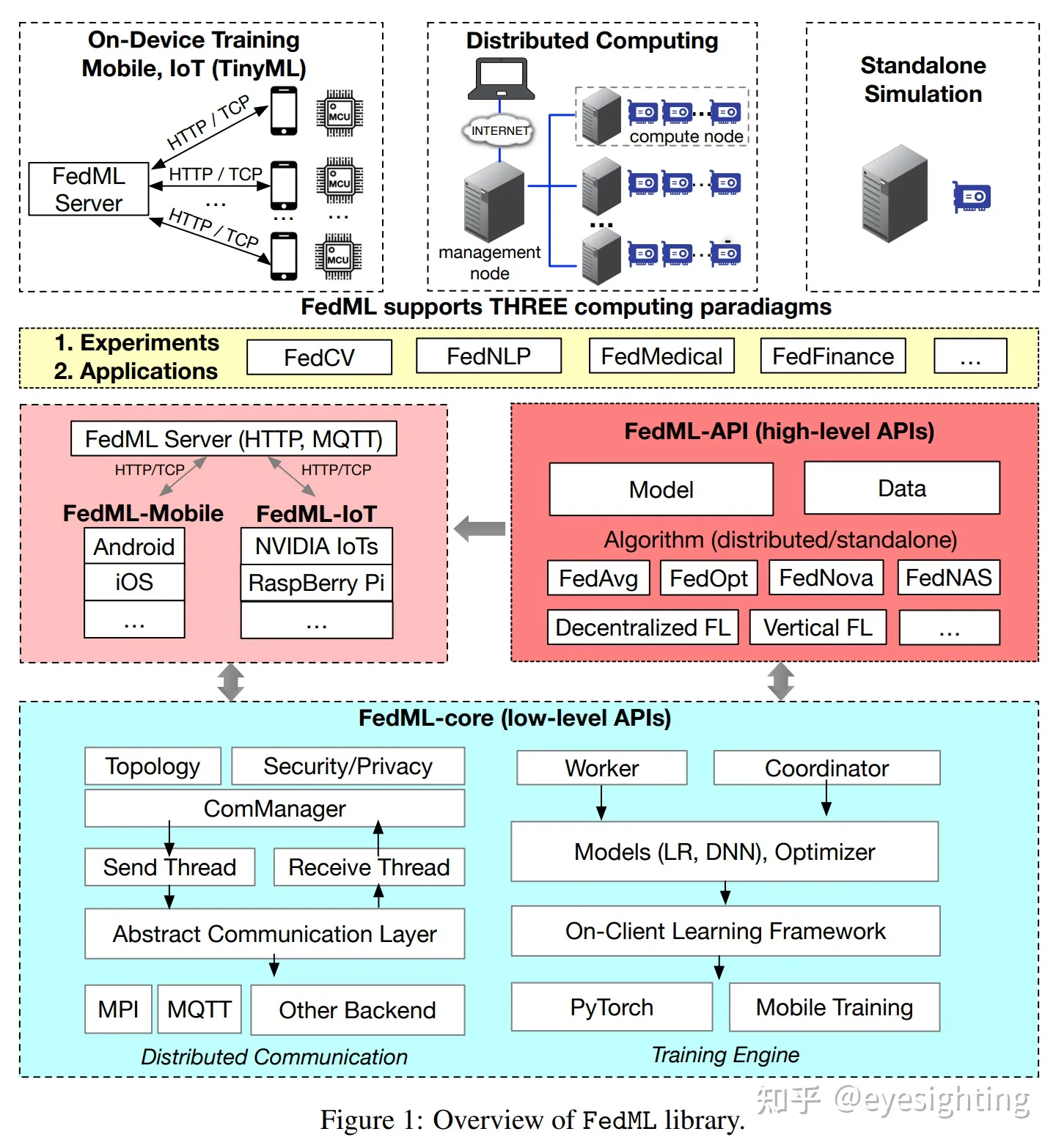
FedML:https://www.fedml.ai/
FedML:https://github.com/FedML-AI/FedML
FedML 论文:https://arxiv.org/abs/2007.13518
TensorFlowFL
放研究和实验 联邦学习(FL), 一种机器学习方法,其中共享的全局模型在不同的环境中进行训练 许多参与的客户将训练数据保存在本地。例如, FL已用于训练 移动键盘的预测模型 无需将敏感的输入数据上传到服务器。
TFF 使开发人员能够使用包含的联合学习算法 他们的模型和数据,以及尝试新颖的算法。这 TFF提供的构建块也可用于实现非学习 计算,例如对分散数据的聚合分析。
TensorFlowFL:https://www.tensorflow.org/federated?hl=zh-cn
TensorFlowFL:https://www.tensorflow.org/federated/federated_learning?hl=zh-cn
TensorFlowFL:https://github.com/tensorflow/federated
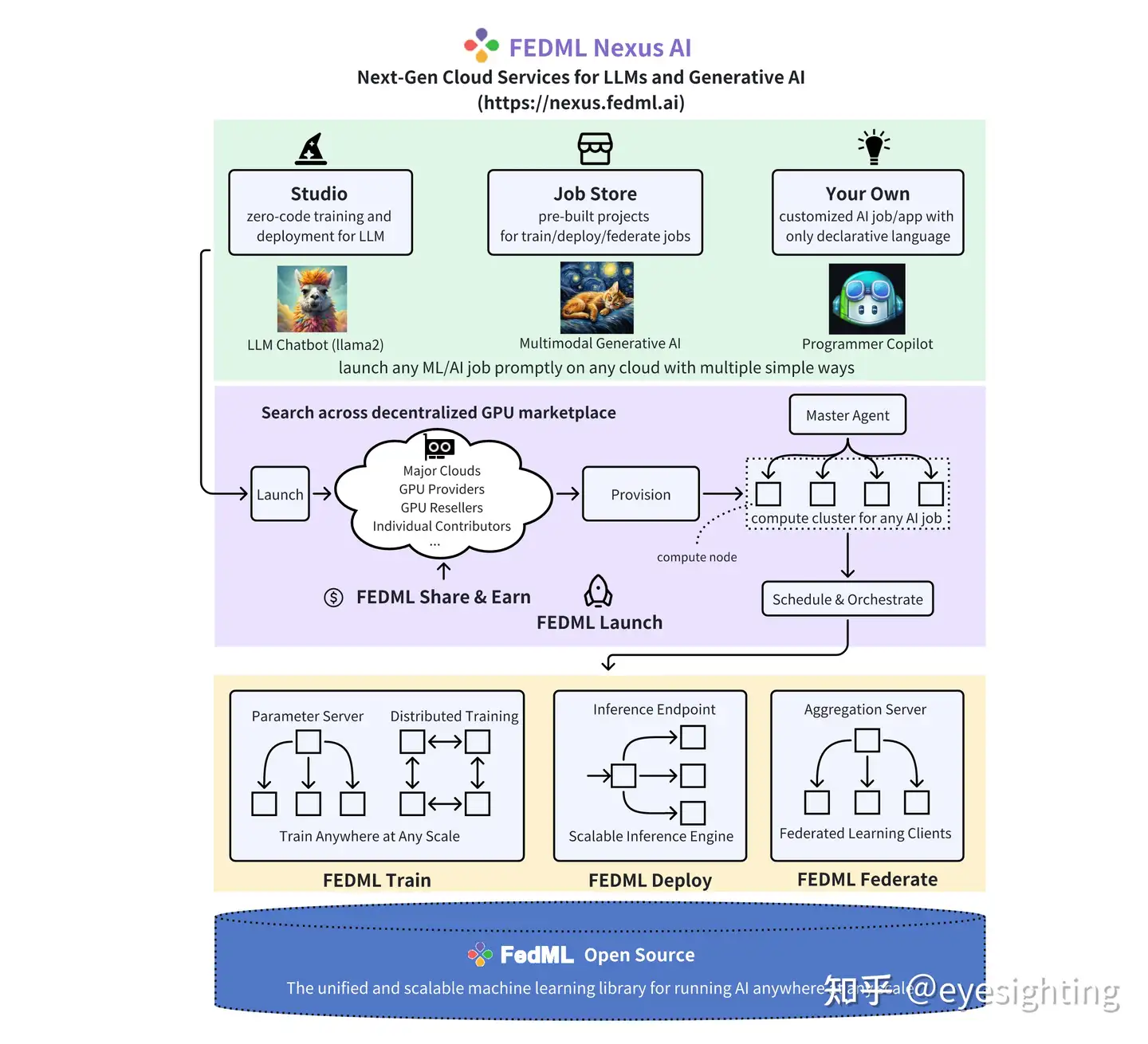
Flower
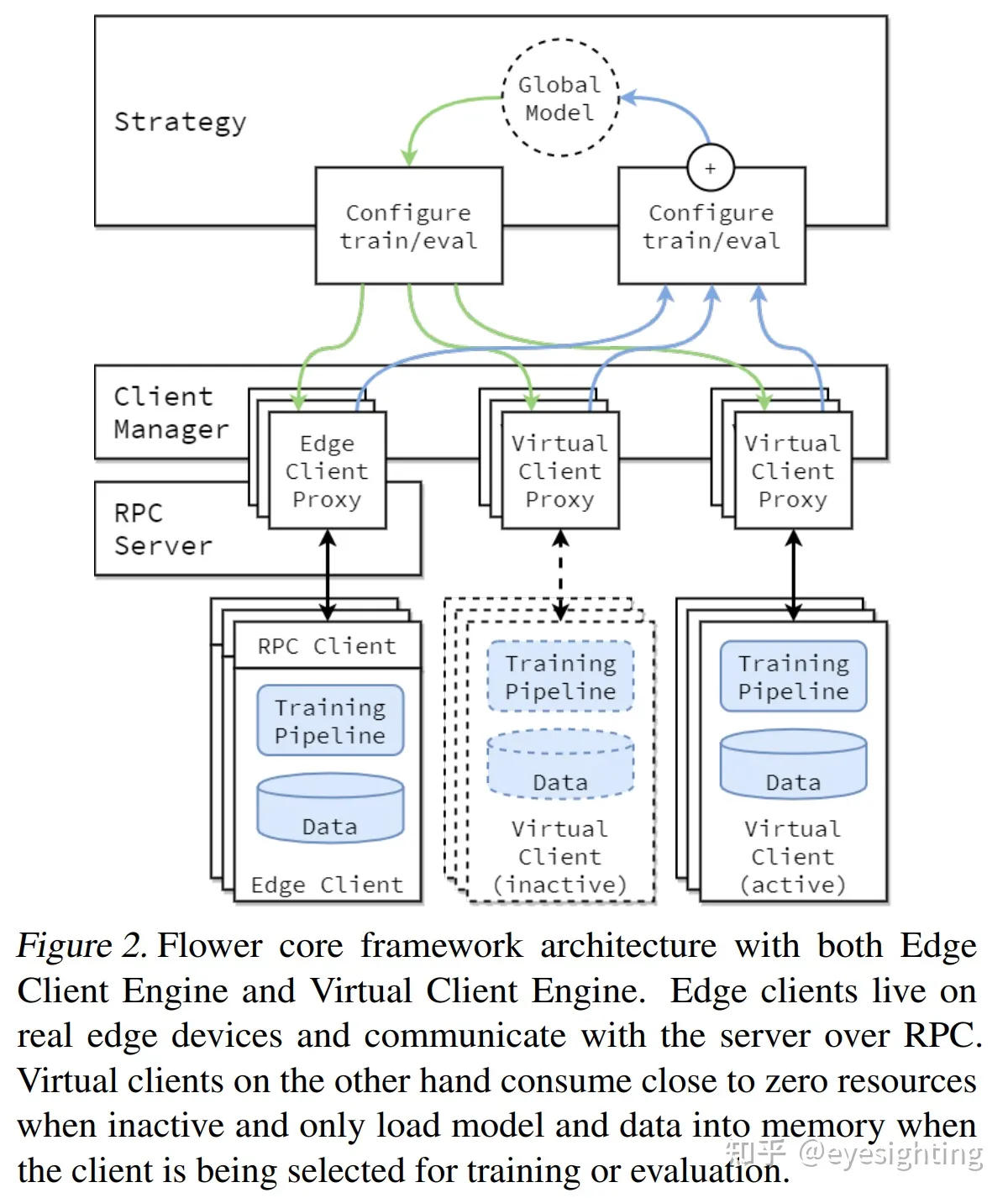
Flower:https://github.com/adap/flower
Flower 论文:https://arxiv.org/abs/2007.14390
联邦学习框架Flower:https://zhuanlan.zhihu.com/p/460566694
OpenFL
开放联合学习 (OpenFL) 是用于联合学习的 Python 3 框架。 OpenFL 被设计为_灵活_、_可扩展_和_易于学习_数据科学家工具。

OpenFL:https://github.com/securefederatedai/openfl
OpenFL 论文:https://arxiv.org/abs/2105.06413
MindSporeFL
MindSpore Federated是MindSpore的开源联邦学习工具,用户数据本地存储的情况下,可实现全场景智能应用。联邦学习是一种密码分布式机器学习技术,用于解决数据孤岛问题,跨多方或多资源计算节点执行高效、安全、可靠的机器学习。支持机器学习的各个参与者在不直接共享本地数据的情况下共同构建AI模型,包括但不限于广告推荐、分类、检测等主流深度学习模型,主要应用于金融、医疗、推荐等领域。
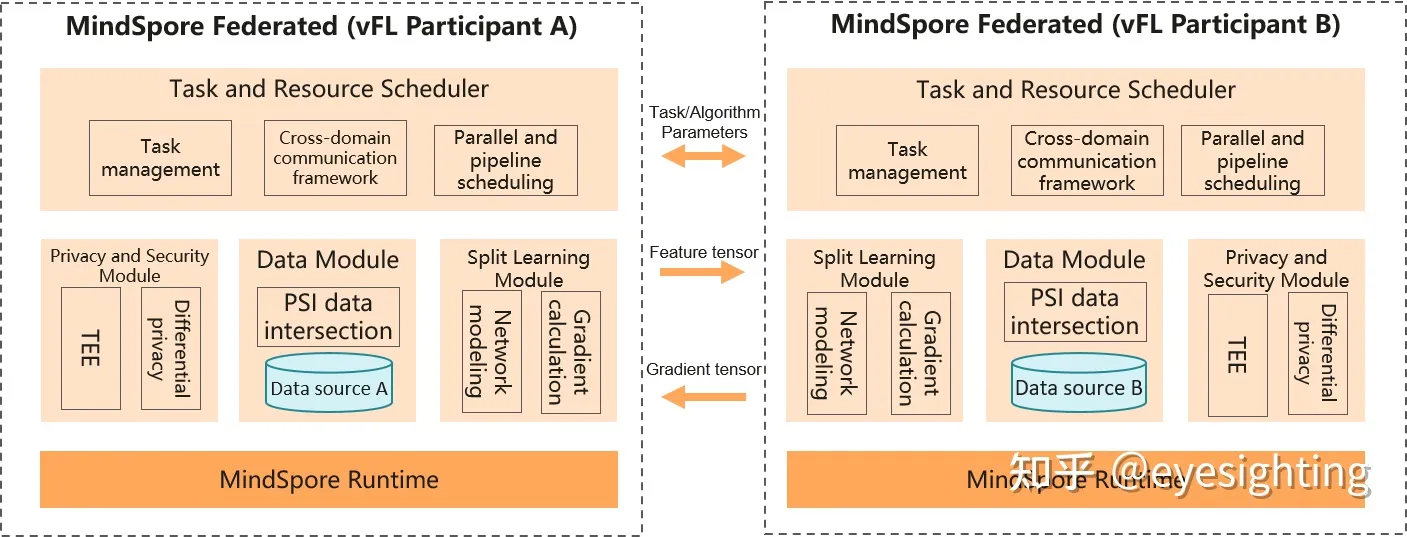
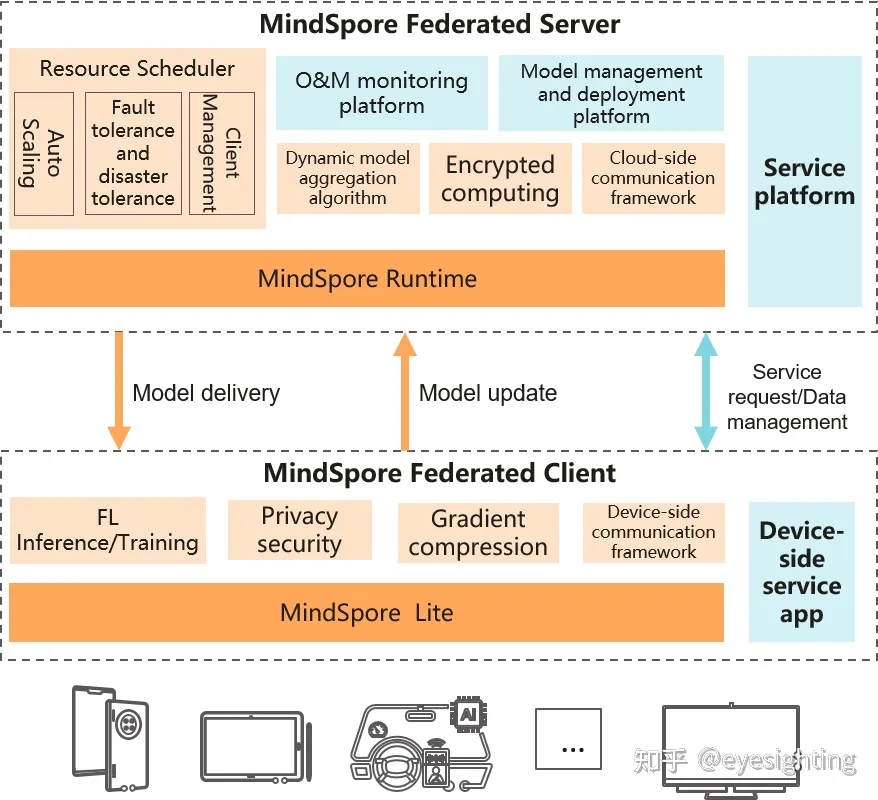
MindSporeFL:https://www.mindspore.cn/federated/docs/en/master/index.html
MindSporeFL:https://www.mindspore.cn/federated/docs/en/r1.6/deploy_federated_server.html
MindSporeFL 代码:https://gitee.com/mindspore/federated
APPFL
高级隐私保护联邦学习 (APPFL) 是一个开源软件框架,允许研究社区实施、测试和验证隐私保护联邦学习 (PPFL) 的各种想法。 通过这个框架,开发人员和/或用户可以:在具有差异隐私的去中心化数据上训练用户定义的神经网络模型;使用 MPI 模拟在高性能计算 (HPC) 架构上的各种 PPFL 算法;以即插即用的方式实现用户定义的 PPFL 算法。这些算法组件包括联邦学习 (FL) 算法、隐私技术、通信协议、要训练的 FL 模型和数据。
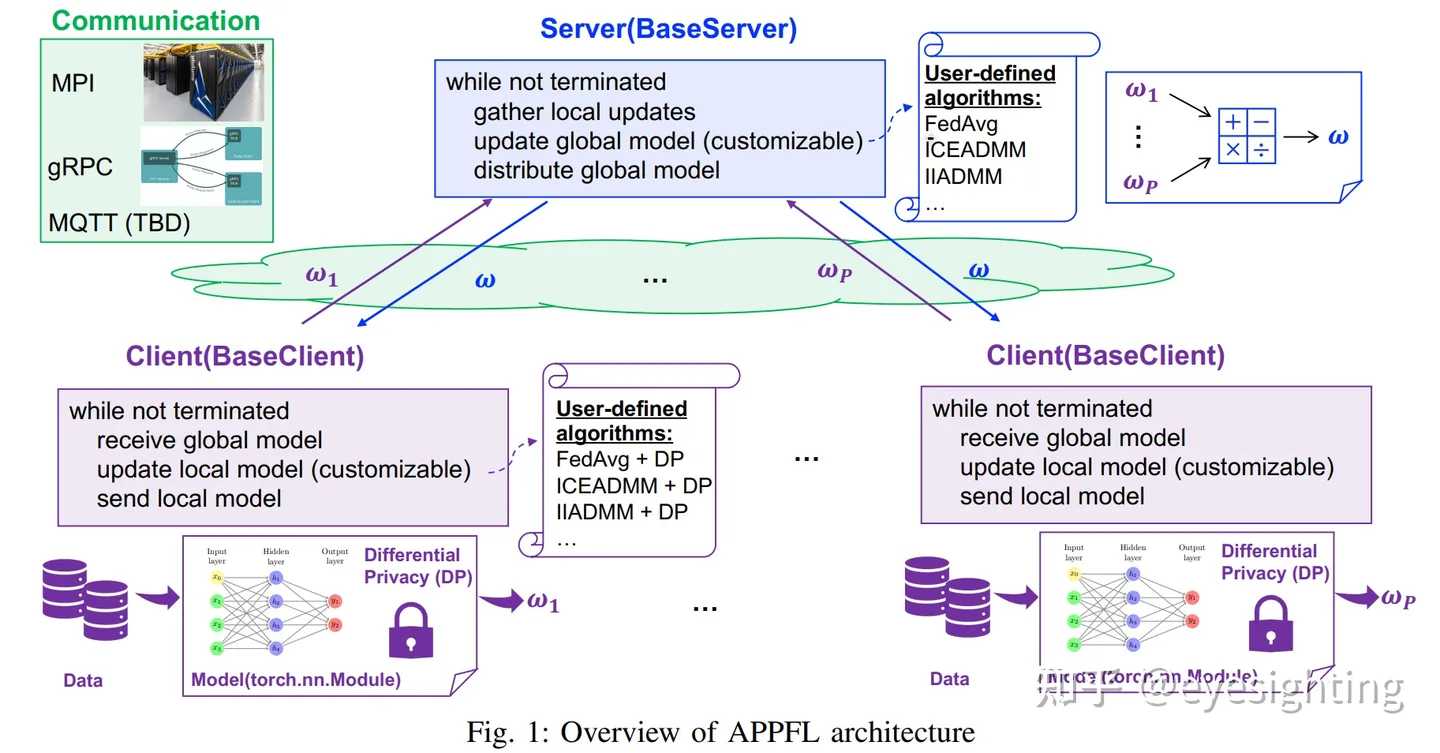

APPFL 代码:https://github.com/APPFL/APPFL
APPFL 论文:https://arxiv.org/abs/2202.03672
FedLearn
京东数科自研联邦学习平台Fedlearn亮相,多场景解决方案助力产业数字化增长:http://www.kejihui.org/3585
论文:https://arxiv.org/abs/2008.06197
名称:Federated Doubly Stochastic Kernel Learning for Vertically Partitioned Data
6.AutoML/自动机器学习框架
AutoSklearn
auto-sklearn 是一个自动化机器学习工具包,可直接替代 scikit-learn 估计器。

AutoSklearn:https://automl.github.io/auto-sklearn/master/
AutoSklearn:https://www.automl.org/automl-for-x/tabular-data/auto-sklearn/
AutoSklearn:https://github.com/automl/auto-sklearn
Auto-Sklearn 2.0 论文:https://arxiv.org/abs/2007.04074
AutoKeras
AutoKeras:基于 Keras 的 AutoML 系统。 它由德克萨斯 A&M 大学的DATA Lab开发。 AutoKeras 的目标是让每个人都能使用机器学习。
AutoKeras:https://autokeras.com/
AutoKeras:https://autokeras.com/tutorial/overview/
AutoKeras 论文:https://arxiv.org/abs/1806.10282
Google AutoML
Google AutoML:https://cloud.google.com/automl?hl=zh_cn
Google Cloud AutoML:https://www.run.ai/guides/automl/google-automl
AutoGluon
AutoGluon 可自动执行机器学习任务,使您能够在应用程序中轻松实现强大的预测性能。
只需几行代码,您就可以在图像、文本、时间序列和表格数据上训练和部署高精度机器学习和深度学习模型。
AutoGluon:https://github.com/autogluon/autogluon
AutoGluon 文档:https://auto.gluon.ai/stable/index.html
AutoPyTorch
Auto-PyTorch 将机器学习用户从算法选择和 超参数调整。它利用了贝叶斯算法的最新优势 优化、学习_和集成构建。
AutoPyTorch:https://automl.github.io/Auto-PyTorch/development/
AutoPyTorch介绍:https://www.automl.org/automl-for-x/tabular-data/autopytorch/
AutoPyTorch:https://automl.github.io/Auto-PyTorch/development/manual.html
MLBox
MLBox 是一个强大的自动化机器学习 Python 库。它提供以下功能: 快速读取和分布式数据预处理/清理/格式化;高度稳健的功能选择和泄漏检测;高维空间精准超参数优化;最先进的分类和回归预测模型(深度学习、Stacking、LightGBM...);通过模型解释进行预测;
MLBox:https://mlbox.readthedocs.io/en/latest/
MLBox:https://github.com/AxeldeRomblay/MLBox
TransmogrifAI
TransmogrifAI(发音为 trăns-mŏgˈrə-fī)是一个用 Scala 编写的 AutoML 库,运行在 Apache Spark 之上。它的开发重点是通过机器学习自动化以及强制编译时类型安全、模块化和重用的 API 来提高机器学习开发人员的生产力。 通过自动化,它可以达到接近手动调整模型的精度,同时时间缩短了近 100 倍。
TransmogrifAI:https://github.com/salesforce/TransmogrifAI
TransmogrifAI:https://transmogrif.ai/
AutoWEAK
AutoWEAK:https://www.automl.org/automl-for-x/tabular-data/autoweka/
AutoWEAK:https://github.com/automl/autoweka
AutoWEAK2.0:https://www.cs.ubc.ca/labs/algorithms/Projects/autoweka/papers/16-599.pdf
7.DML/分布式机器框架
TensorFlowSpark
将 TensorFlow 深度学习框架的显着功能与 Apache Spark 和 Apache Hadoop,TensorFlowOnSpark 支持分布式 在 GPU 和 CPU 服务器集群上进行深度学习。它支持分布式 TensorFlow 训练和 对 Spark 集群进行推理,目标是尽量减少数量 在计算机上运行现有 TensorFlow 程序所需的代码更改 共享网格。

TensorFlowSpark:https://github.com/yahoo/TensorFlowOnSpark
TensorFlowSpark:https://yahoo.github.io/TensorFlowOnSpark/
Horovod
Horovod 是一个适用于 TensorFlow、Keras、PyTorch 和 Apache MXNet 的分布式深度学习训练框架。 Horovod 的目标是让分布式深度学习变得快速且易于使用。
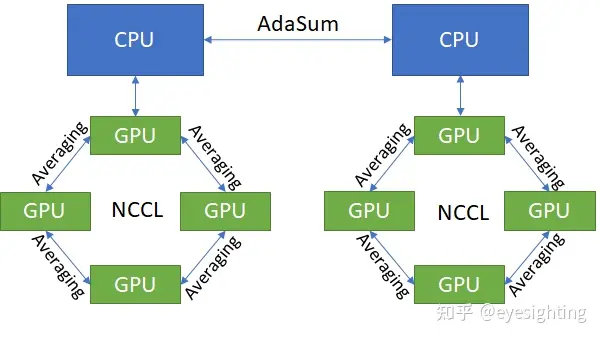
Horovod:https://github.com/horovod/horovod
分布式训练服务框架基本原理与架构解析:https://www.changping.me/2022/04/17/ai-distributed-training-framework-1/
Multiverso
Multiverso 是一个基于参数服务器的框架,用于在大量机器的大数据上训练机器学习模型。它目前是一个标准的C++库,提供了一系列友好的编程接口,并扩展支持Python和Lua程序的调用。有了这样简单易用的API,机器学习研究人员和从业者无需担心分布式模型存储和运行、进程间和线程间通信、多线程管理等系统常规问题。 开发者能够专注于核心机器学习逻辑:数据、模型和训练。
Multiverso:https://github.com/microsoft/Multiverso
BytePS
BytePS是一个高性能、通用的分布式训练框架。它支持 TensorFlow、Keras、PyTorch 和 MXNet,并且可以在 TCP 或 RDMA 网络上运行。BytePS 的性能大幅优于现有的开源分布式训练框架。例如,在 BERT-large 训练中,BytePS 可以使用 256 个 GPU 实现约 90% 的扩展效率(见下文),远高于 Horovod+ NCCL。在某些场景下,BytePS相比Horovod+NCCL可以使训练速度提高一倍。

BytePS 论文:https://www.usenix.org/conference/osdi20/presentation/jiang
BytePS 代码:https://github.com/bytedance/byteps
BytePS 演讲稿:https://www.usenix.org/sites/default/files/conference/protected-files/osdi20_slides_jiang.pdf
GTL
GraphLearn-for-PyTorch(GLT) 是 PyTorch 的图形学习库,它使 分布式 GNN 训练和推理简单高效。它利用了 GPU 的强大功能可加速图形采样并利用 UVA 来减少 顶点和边的特征的转换和复制。对于大比例尺的图, 它支持在多个GPU或多台机器上进行分布式训练 快速分布式采样和特征查找。
GTL 文档:https://graphlearn-torch.readthedocs.io/en/latest/index.html
GTL 代码:https://github.com/alibaba/graphlearn-for-pytorch
DDP
PyTorch分布式数据并行入门:https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
什么是分布式数据并行 (DDP):https://pytorch.org/tutorials/beginner/ddp_series_theory.html
PyTorch DDP系列第一篇:入门教程:https://zhuanlan.zhihu.com/p/178402798
8.MLaaS/机器学习即服务
DLAMI
AWS Deep Learning AMI(DLAMI)为机器学习从业者和研究人员提供一组精心策划的安全框架、依赖项和工具,以加速 Amazon EC2 中的深度学习。亚马逊机器映像(AMI)专为 Amazon Linux 和 Ubuntu 构建,预配置了 TensorFlow、PyTorch、NVIDIA CUDA 驱动程序和库、Intel MKL、Elastic Fabric Adapter(EFA)和 AWS OFI NCCL 插件,可以快速地大规模部署和运行这些框架和工具。

DLAMI:https://aws.amazon.com/cn/machine-learning/amis/
Deep Learning Container:https://aws.amazon.com/cn/machine-learning/containers/
AzureML
Azure 机器学习 使用企业级 AI 服务实现端到端机器学习生命周期。

AzureML:https://azure.microsoft.com/en-us/products/machine-learning
VertexAI
Vertex AI 提供构建和使用生成式 AI 所需的一切,包括 AI 解决方案、Search and Conversation、100 多种基础模型,以及统一的 AI 平台。
VertexAI:https://cloud.google.com/vertex-ai/
NGC
NVIDIA NGC™ 是企业服务、软件、管理工具以及对端到端 AI 和数字孪生工作流程支持的门户。通过完全托管的服务将您的解决方案更快地推向市场,或者利用性能优化的软件在您首选的云、本地和边缘系统上构建和部署解决方案。NGC 提供一系列云服务,包括NVIDIA NeMo、BioNemo< a i=4> 和 Riva Studio 用于生成 AI、药物发现和语音 AI 解决方案,以及 NGC私人注册表,用于安全共享专有人工智能软件。
NGC 目录 提供对 GPU 加速软件的访问,该软件通过性能优化的容器、预训练的 AI 加速端到端工作流程模型和行业特定的 SDK,可以部署在本地、云端或边缘。
NGC:https://www.nvidia.com/en-us/gpu-cloud/
Watson
IBM watsonx™ AI 和数据平台包括三个核心组件和一组 AI 助手,旨在帮助您利用可信数据在整个企业中扩展和加速 AI 的影响。 核心组件包括:新的基础模型、生成式 AI 和机器学习工作室;基于开放数据 Lakehouse 架构构建的适合用途的数据存储;以及一个工具包,用于加速以责任、透明度和可解释性构建的人工智能工作流程。
Watson:https://www.ibm.com/artificial-intelligence
WatsonX:https://www.ibm.com/watsonx
ModelArts
ModelArts是面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
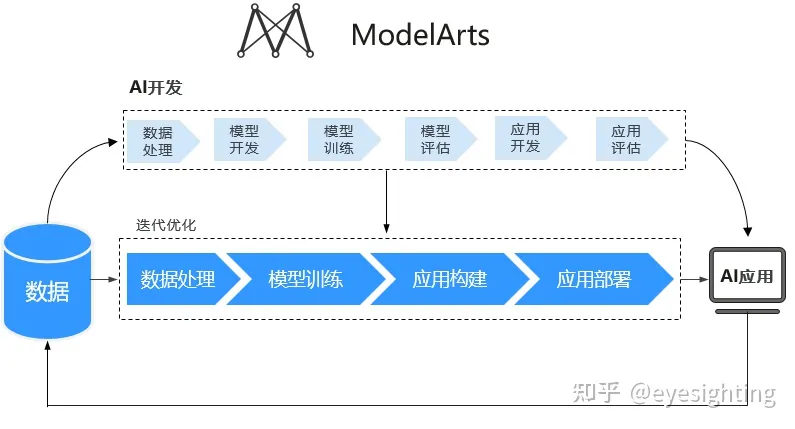
ModelArts:https://support.huaweicloud.com/modelarts/index.html
MLStudio:https://support.huaweicloud.com/devtool-modelarts/devtool-modelarts_0023.html
BML
全功能AI开发平台BML为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用。
BML:https://cloud.baidu.com/doc/BML/index.html
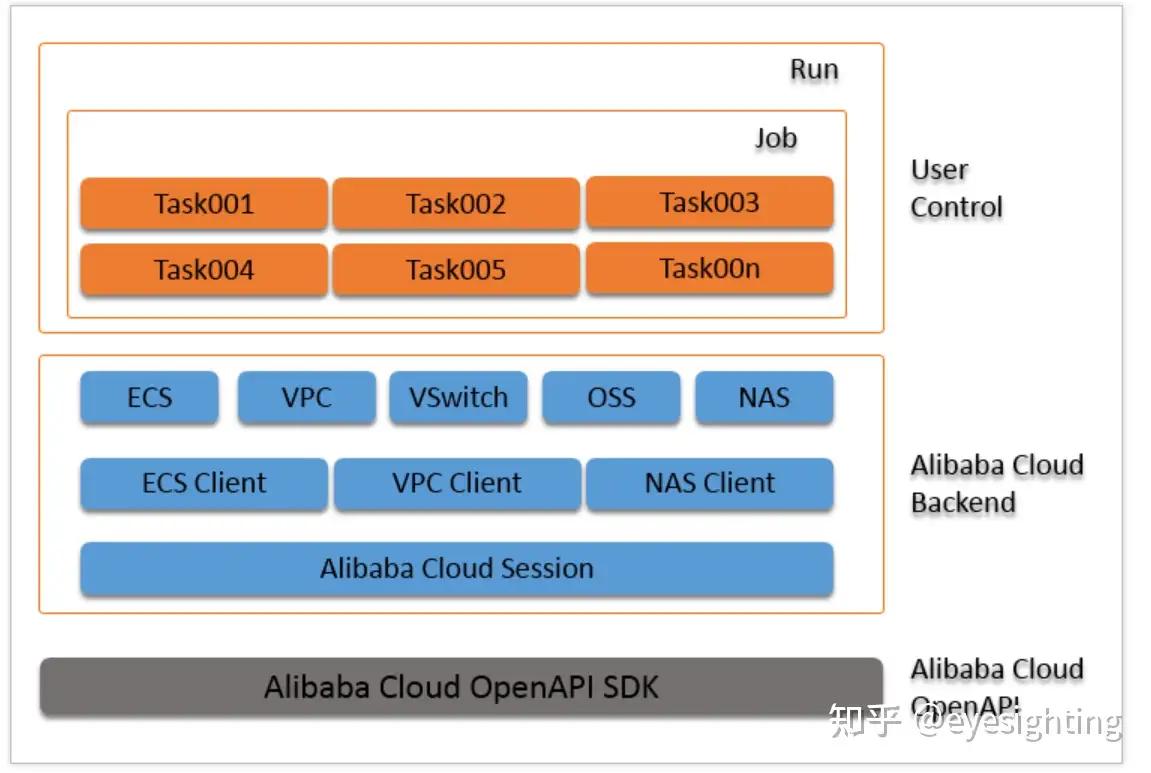
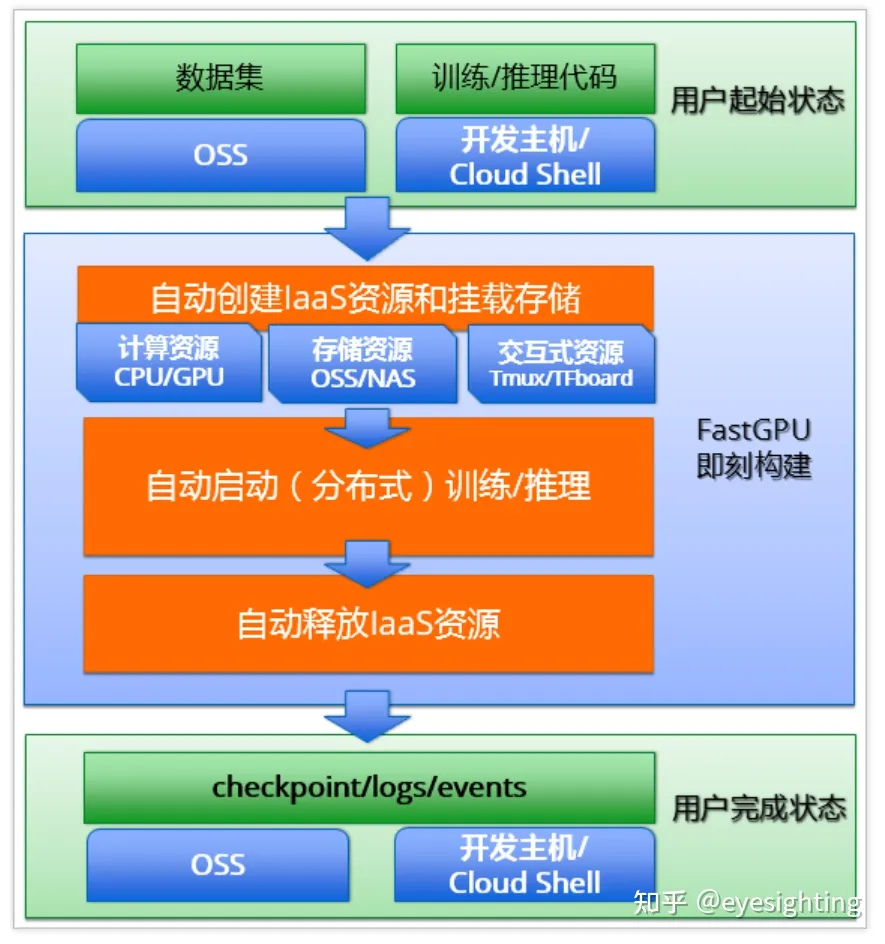
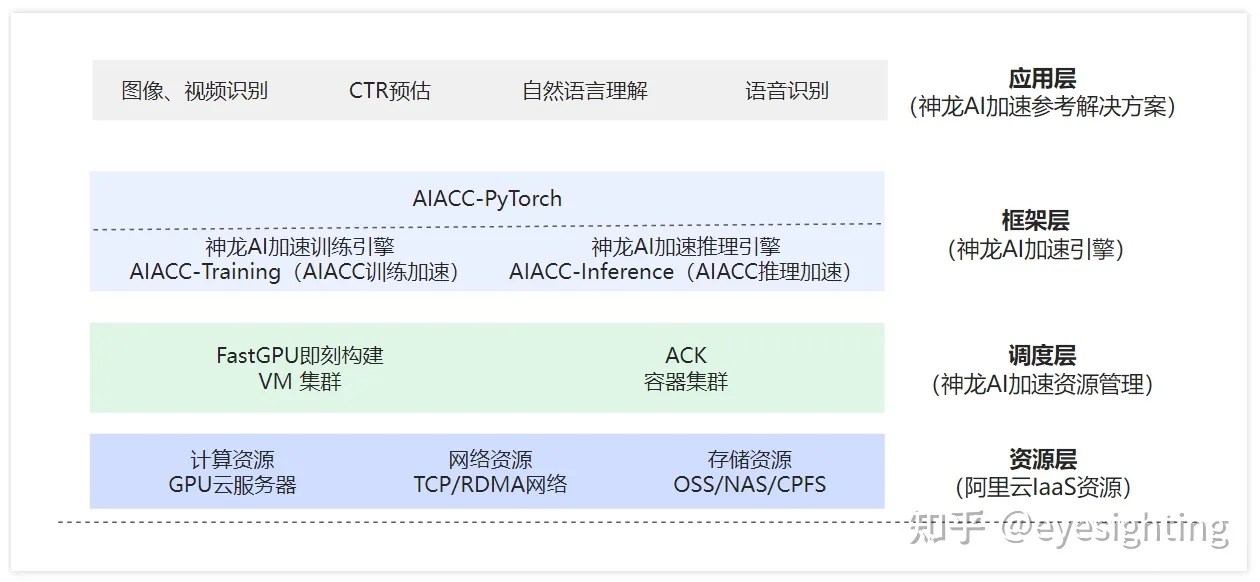
DeepGPU
神行工具包(DeepGPU)是阿里云专门为GPU云服务器搭配的GPU计算服务增强工具集合,开发者可以基于IaaS产品快速构建企业级服务能力。GPU云服务器搭配神行工具包(DeepGPU)中的组件可以帮助开发者更方便、更高效地使用阿里云的云上GPU资源。
包含:神龙AI加速引擎AIACC;AI分布式训练通信优化库AIACC-ACSpeed;计算优化编译器AIACC-AGSpeed;集群极速部署工具FastGPUGPU;容器共享技术cGPU。


DeepGPU:https://help.aliyun.com/zh/egs/what-is-deepspeed/?spm=a2c4g.11186623.0.0.20b66dfeyiUwYl
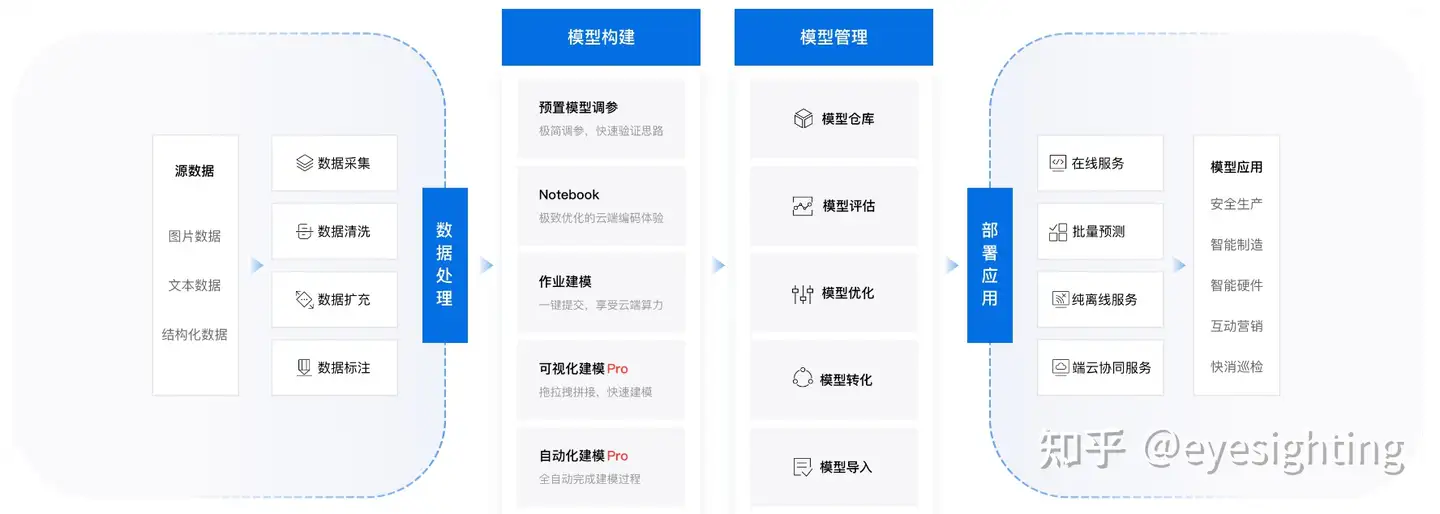
PAI
阿里云人工智能平台 PAI(Platform of Artificial Intelligence)面向企业客户及开发者,提供轻量化、高性价比的云原生人工智能,涵盖DSW交互式建模、Designer拖拽式可视化建模、DLC分布式训练到EAS模型在线部署的全流程,支持百亿特征、千亿样本规模加速训练,百余种落地场景,全面提升人工智能工程效率。
PAI:https://www.alibabacloud.com/help/zh/pai/
AutoML:https://www.alibabacloud.com/help/zh/pai/use-automl-for-automatic-parameter-tuning
TI-ML
智能钛机器学习(TI Machine Learning,TI-ML)是基于腾讯云强大计算能力的一站式机器学习生态服务平台。能够对各种数据源、组件、算法、模型和评估模块进行组合,使得算法工程师和数据科学家在其之上能够方便地进行模型训练、评估和预测。智能钛机器学习具有可视化操作界面的 TI-ONE 和具有命令行操作界面的 TI-Accelerator(TI-A),能够满足用户不同的使用习惯。在部署方面,除公有云方式外,TI 也支持私有化部署。
TI-ML:http://www.baiemai.com/product/TI.htm
BigML
BigML提供了各种基本的机器学习资源,可以组合在一起来解决复杂的机器学习任务。 开发者可以通过BigML主控板访问这些资源,这是一个直观的基于Web的界面,也可以通过REST API 或大量的 程序库和工具以编程方式访问。
BigML:https://bigml.com/
9.SR/语音识别框架
Kaldi
Kaldi 语音识别工具包项目于 2009 年在约翰霍普金斯大学启动,旨在开发技术以减少语音识别所需的成本和时间构建语音识别系统。虽然 Kaldi 项目最初专注于对新语言和领域的 ASR 支持,但其规模和功能已稳步增长,并使数百名研究人员能够参与推动该领域的发展。现在,Kaldi 已成为社区中事实上的语音识别工具包,帮助实现数百万人每天使用的语音服务。
Kaldi:https://github.com/kaldi-asr/kaldi
Kaldi 官网:https://kaldi-asr.org/
论文ExKaldi-RT:https://arxiv.org/abs/2104.01384
PyTorch-Kaldi:Pytorch-kaldi 语音识别工具包:https://ieeexplore.ieee.org/document/8683713
FlashLight
Flashlight 是一个快速、灵活的机器学习库,完全用 C++ 编写 来自 Facebook AI Research 以及 Torch、TensorFlow、Eigen 和 深度演讲。其核心特点包括: 完全内部可修改性,包括用于张量计算的内部 API。 占用空间小,核心速度低于 10 MB,C++ 代码数为 20k 行。 高性能默认设置,通过现代 C++ 通过 ArrayFire 进行即时内核编译 张量库。 C++ 的原生支持和简单的可扩展性使 Flashlight 成为一个强大的研究框架,可以快速迭代新的实验设置和算法,而且不会牺牲性能。
FlashLight:https://github.com/flashlight/flashlight
Sphinx
Sphinx是卡内基梅隆大学的开源大型之一 词汇,独立于说话者的连续语音识别引擎。
Sphinix:https://github.com/cmusphinx/pocketsphinx
Sphinix:https://github.com/cmusphinx/sphinx4
Sphinix:https://sourceforge.net/projects/cmusphinx/
总结
基础软件非常重要;掌握PyTorch是基础;大厂都是搞平台搞生态的。
作者:eyesighting
来源:https://zhuanlan.zhihu.com/p/672806570

