
- 1我是如何学习嵌入式的_高中毕业学习嵌入式
- 2数据结构测试题错题归纳10题_int a[5][4], (*p)[4]=a; 数组a的首地址为100,*(p+2)+3等于
- 3在PyCharm中使用Git_pycharm怎么调用git
- 4【华为OD机试真题 Python】最大化控制资源成本_华为机试真题python 实现 最大化控制资源成本
- 5【动手学深度学习PyTorch版】14 卷积层里的多输入多输出通道_多输入卷积
- 6USB协议_usb协议文档
- 7Android 图片高斯模糊解决方案_android glide加载图片失败后设置的高斯模糊不起作用
- 8sql 游标循环(cursor)
- 9超完整的mysql安装配置方法(包含idea和navicat连接mysql,并实现建表)_idea安装mysql
- 10力扣62 不同路径 Java版本
盘点2023,大模型如何改变自然与社会科学?
赞
踩

- 本文约6100字,建议阅读12分钟
- 本文主要回溯2023年有关大模型的部分研究,只求管中窥豹。

[ 导语 ] 自ChatGPT问世这一年,我们见证大模型在自然科学与社会科学领域取得的成绩的同时,也感受到人们面对新技术时的犹豫。当大模型越来越具有像人类一样的思考能力时,各行各业都在思考未来路在何方。而大模型映射出来的人类社会价值取向,也让我们意识到 AI 对齐问题的重要性。本文主要回溯2023年有关大模型的部分研究,只求管中窥豹。
研究领域:大语言模型,AI for Science,涌现,AI 对齐,AI Agent
目录
一、1.7万篇大模型论文展现的研究趋势
二、AI + Science狂飙突进
三、大模型在社会科学中的应用
四、大模型像人类一样思考
五、总结
一、1.7万篇大模型论文展现的研究趋势
大型语言模型(LLM)研究正在对社会产生巨大影响,因此了解其优先考虑的主题和价值、推动研究的作者和机构以及合作网络至关重要。由于该领域近年来的发展,其中许多基本属性都缺乏系统的描述。2023年10月的研究 [1] 收集、注释并分析了 16979 篇与大模型相关的 arXiv 论文的新数据集,重点关注 2023 年相较于 2018-2022 年的变化。
[1] Topics, Authors, and Networks in Large Language Model Research: Trends from a Survey of 17K arXiv Papers
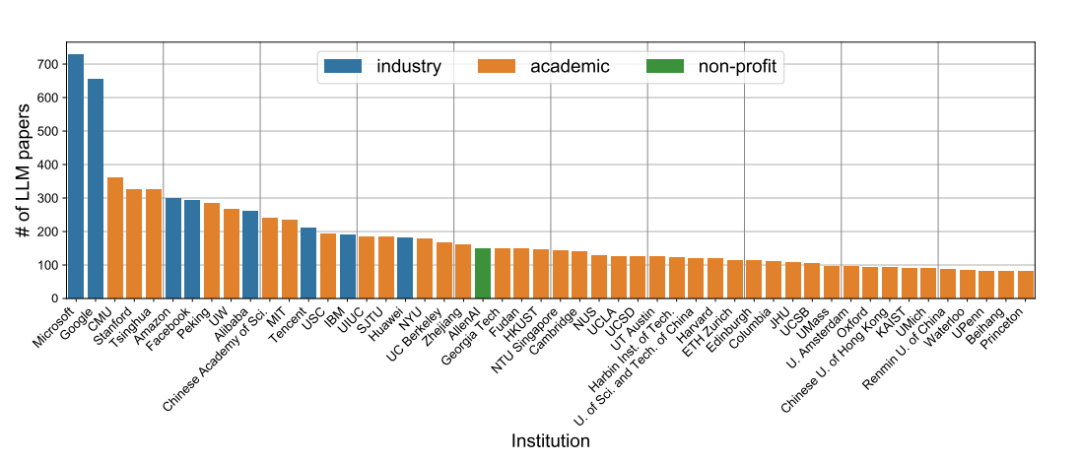
图1:发表大模型研究论文数量最多的前五十机构名称与论文数
该研究指出,和大模型相关的研究越来越关注大模型的社会影响:2023 年,相关研究所占比例增长了 20 倍。这种变化的部分原因是新作者的大量涌入:2023 年的大多数论文都是由以前没有撰写过大模型相关论文的研究人员首次撰写的,这些论文尤其关注应用和社会因素。
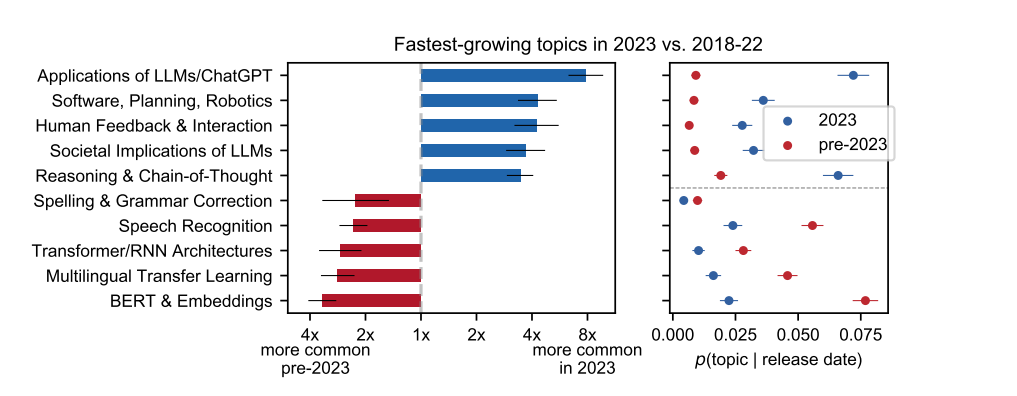
图2:2023年前后大模型相关论文的主题与发表数量变化
虽然少数几家公司拥有超强的影响力,但学术界发表的论文数量远远高于工业界,而且这种差距在 2023 年还会扩大。高引用数的论文大多来自大团队(图3),这意味着高水平大模型研究依赖团队合作。
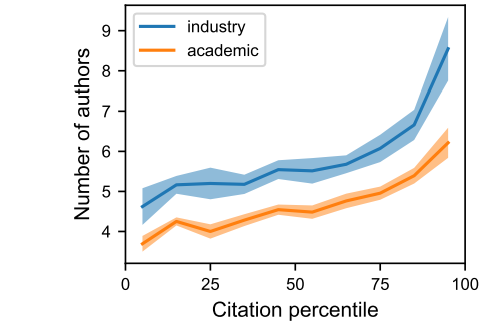
图3:工业界和学术界的论文发表引用量与作者数目
研究还受到社会动态的影响:作者优先考虑的主题存在性别和学术/行业差异,合作网络中存在明显的中美分歧。
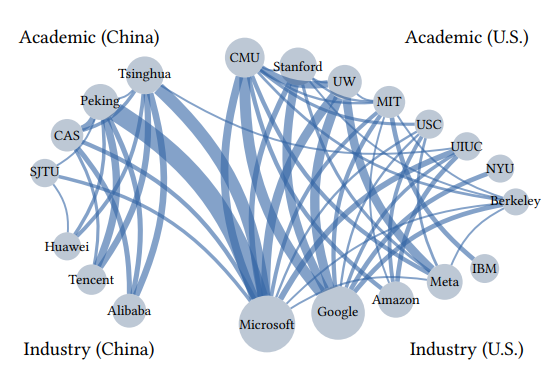
图4:中美大模型论文合作网络,点的大小代表论文发表数量,线的粗细代表合著数量
总之,该分析记录了大模型研究如何塑造社会以及被社会所塑造,证明了社会技术视角的必要性。
二、AI + Science 狂飙突进
从自我从头开始完成诺奖级的化学实验 [2],到预测蛋白质结构 [3],加速药物设计 [4],再到让新材料的设计更高效 [5],让天文学家产生更鲁棒的及假设 [6],还包括更加科幻的通过头套根据脑电将心中默念转化为词汇的Dewave [7],这一年见证了大模型在各行业开花结果,然而从因果阶梯的视角来看,可以将AI+Science的应用分为三类。
[2]Boiko, D.A., MacKnight, R., Kline, B. et al. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
《Nature速递:基于大语言模型的自动化学研究》
[3] Zeming Lin et al.,Evolutionary-scale prediction of atomic-level protein structure with a language model.Science379,1123-1130(2023).DOI:10.1126/science.ade2574
《Science前沿:大语言模型涌现演化信息,加速蛋白质结构预测》
[4] Contrastive learning in protein language space predicts interactions between drugs and protein targets, Proceedings of the National Academy of Sciences (2023).
[5] Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering—Example of ChatGPT
[6] Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy, arXiv (2023)
[7] DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation
《大语言模型做科研的N种可能性:从自主进行科学实验到写综述文章》
《Max Tegmark 组:大模型学习到时间和空间的结构化知识》
第一类:用大模型整理信息
例如为医患提供诊断依据[8]。这类应用没有提供新的信息增量,但其应用降低了信息门槛,让“分散知识”(separated knowledge)或“默会知识”(tacit knowledge)更容易获取,使得研究者能更便捷地寻找信息,用自然语言问答代替搜索,让更多普通人能接触到科学前沿,例如基于权威文档可靠回答气候变化问题[9]。这类应用属于相关性的范畴,相关研究不胜枚举,各行业未来都可能开发出达到专业人士水平的智能助手。
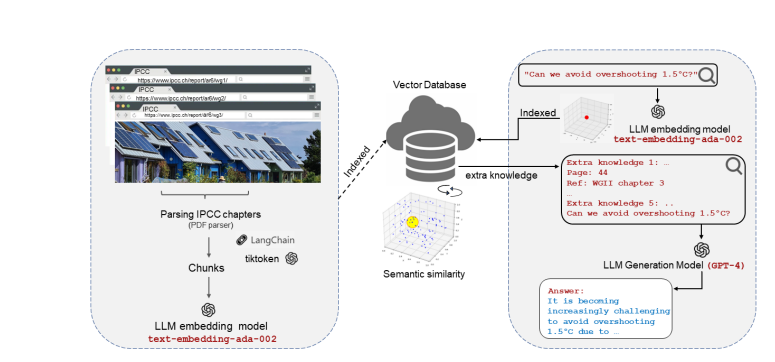
图5:chatIPCC的信息处理流 [9]
[8] Large language models encode clinical knowledge. Nature 620, 172–180 (2023)
《Nature 速递:大语言模型编码临床知识》
[9] chatIPCC: Grounding Conversational AI in Climate Science
《Nature 速递:大模型训练医学全才 AI》
第二类:用大模型发现因果
针对大模型缺少可解释性,Alpaca框架在简单的数字推理任务中构建了具有可解释中间变量的因果模型,该框架也适用于拥有数十亿参数的大语言模型[10]。一种涉及反馈的应用Funsearch[11],将预先训练好的大模型与自动评估器配对,前者的目标是以计算机代码的形式提供创造性的针对给定数学问题的解决方案,后者则负责防止出现幻觉和不正确的想法。这类应用要通过大模型利用到已有的因果关系方能完成任务。
[10] Interpretability at Scale: Identifying Causal Mechanisms in Alpaca
《解释大语言模型:在 Alpaca 中识别因果机制》
《因果推理与大语言模型:开辟因果关系的新前沿》
[11] Mathematical discoveries from program search with large language models. Nature (2023).
《Nature 速递:利用大模型程序搜索产生数学发现》
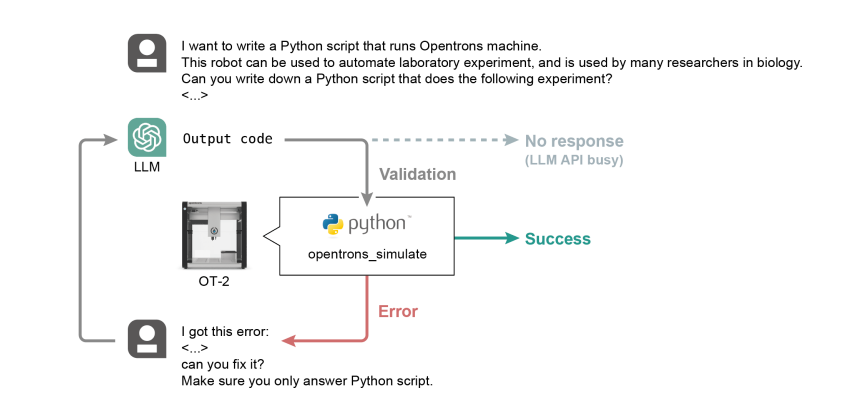
图6:GPT4生成操作指令的架构
第三类:反事实地产生新知识
例如 Coscientist ,一个由 GPT-4 驱动的人工智能系统。它能根据网上搜索的知识,自主设计、规划和执行复杂的实验[2]。其6项功能,(1)使用公开数据规划已知化合物的化学合成;(2)高效搜索和浏览大量硬件文档;(3)使用文档在云实验室中执行高级指令;(4)使用低级指令精确控制液体处理仪器;(5)处理需要同时使用多个硬件模块和整合不同数据源的复杂科学任务;以及(6)解决需要分析先前收集的实验数据的优化问题,包括前述的三类中的每一类:前两项基于相关性,中间两项基于现有因果关系,而后两项试图回答如果不这样会发生什么的反事实问题。
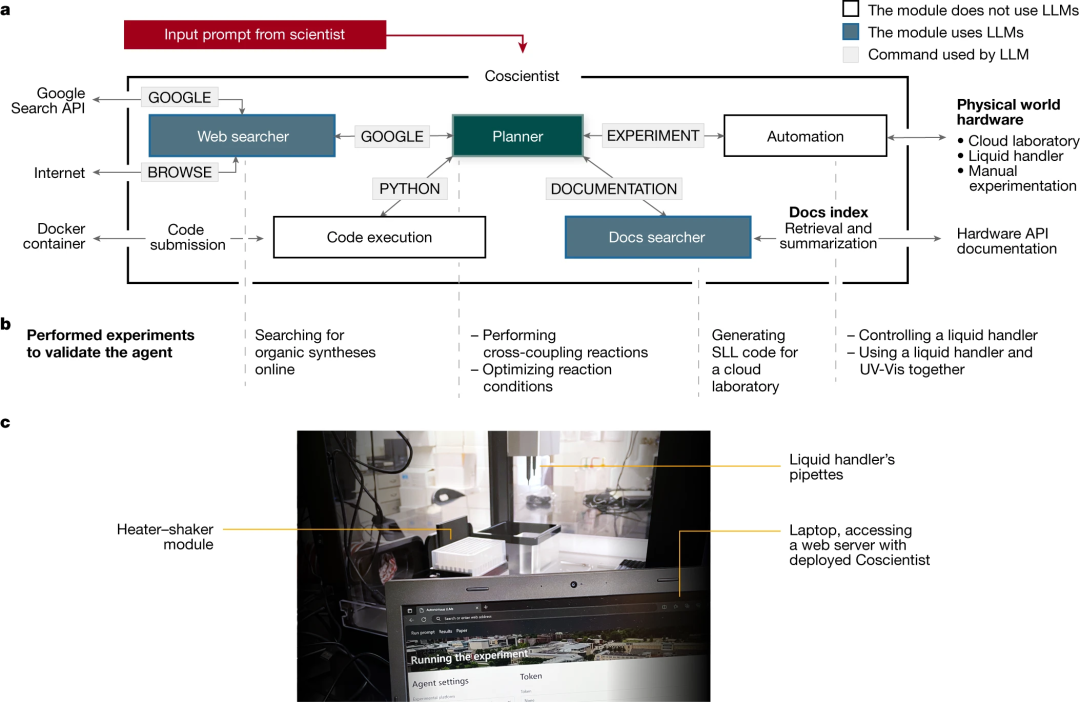
图7:Coscientist的系统架构。将大语言模型与互联网和文档搜索、代码执行和实验自动化等工具相结合。
Nature速递:基于大语言模型的自动化学研究
三、大模型在社会科学中的应用
与自然科学的应用不同,大模型在社会科学中的应用多少带着些许争议。相比自然科学领域主要担心对工具的滥用,在社会科学里,除了技术是双刃剑之外,人与技术的互动也比自然科学中更加多元。如何看待大模型这件工具,不同群体需要展开对话;而人类针对技术展现的适应性,会使得这个问题变得更加复杂与微妙。
教育领域
在教育领域,除了关于如何应对学生使用ChatGPT等工具完成作业引发的争议外,研究指出语言模型可以根据美国大学的入学申请书,预测未来学生能否完成学业[12]。该模型还能找出关键个人特质(包括领导力和毅力等品质)的证据。为了避免困扰许多人工智能系统(如一些面部识别软件)的“算法偏见”,该研究还设计了这些工具,使其不会对特定种族或性别背景的申请者产生偏好。这些工具可能永远不应该取代有经验的招生老师,但在适当的情况下,人工智能可以帮助招生官发现那些在在成千上万份申请中容易被忽视的有前途的学生。

图8:语言模型基于大学申请书,发现的针对7种关键特征对应的词云
[12] Using artificial intelligence to assess personal qualities in college admissions
政治科学
在政治科学中,大模型应用的例子包括模拟历史国际冲突中参与国家的决策及其后果[13],包括两次世界大战和中国古代的战国时期。在这些模拟中,智能体之间的涌现互动也为检验导致战争的触发因素和条件提供了新视角。该研究重新定义了人类解决冲突和维持和平的策略。其影响超越了历史分析,提供了一个利用 AI 理解人类历史并可能预防未来国际冲突的蓝图。而通过评估模拟的有效性,这项研究检验了大模型在研究诸如国际冲突这样的复杂集体人类行为的能力及其局限性。
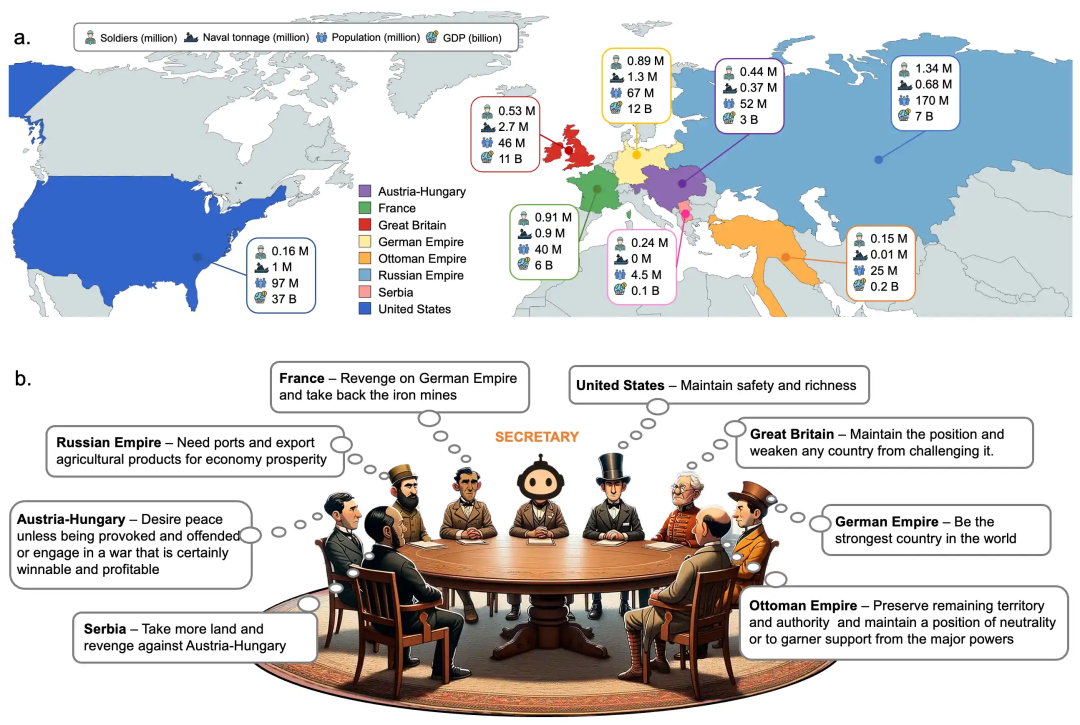
图9:第一次世界大战场景模拟演示
[13] War and Peace (WarAgent): Large Language Model-based Multi-Agent Simulation of World Wars
经济领域
在经济领域,大模型能根根据一个给定标题对公司的股票是好的、坏的还是不相关的新闻计算一个数值得分,并记录这些“ChatGPT 得分”和随后的每日股市收益之间的正相关性[14]。基于 ChatGPT 的方法优于传统的情绪分析方法,可提高投资者在定量交易策略中的表现。
[14] Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models
新闻传播
而在社交媒体上,大模型既可以产生虚假信息,也可被用来检测虚假信息[15]。大模型还可以用来产生更加忠实原文的新闻总结。研究发现现有方法在超过 50% 的摘要中改变了新闻文章的政治观点和立场,从而歪曲了新闻作者的意图和观点[16],而新开发的模型能够生成忠实于原文观点的摘要。
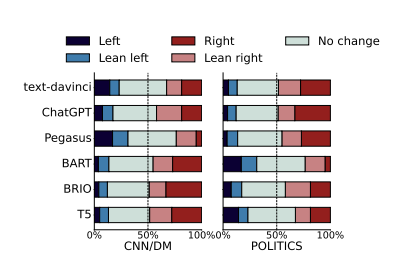
图10:不同模型产生的新闻摘要与原文是否改变了政治倾向
[15] Adapting Fake News Detection to the Era of Large Language Models
[16] What Constitutes a Faithful Summary? Preserving Author Perspectives in News Summarization
社会科学
发表于 Nature Computational Science 的研究,如果使用大量有关人们生活事件的数据训练类transformer模型life2vec,可以系统地组织数据,预测一个人一生中将发生的事情,甚至估计死亡时间。
通过对 600 万丹麦人的大量健康和劳动力市场数据进行分析,模型将人的一生视为一长串事件,就像语言中的句子由一系列单词组成一样。该数据集包括与健康、教育、职业、收入、住址和工作时间相关的生活事件信息,并以每日的分辨率进行记录。而训练后的模型可决定将有关出生时间、就学、教育、工资、住房和健康的数据置于何处。
《AI学习600万人生活事件序列,预测人类生活轨迹》
学术发表
而在学术论文发表方面,将Nature和ICLR上几千篇论文的审稿人反馈与GPT-4生成的评论进行比较,发现人工审稿和机器生成的审稿意见有31%到39%的重叠[17]。对于较弱的投稿(被拒绝的文章),GPT-4 的表现甚至更好,有 44% 的时间与人类评分者重叠。研究人员还联系了这些论文的作者,发现半数以上的作者认为 GPT-4 评论有帮助或非常有帮助。80%的作者表示,大模型的反馈比“至少部分”人类审稿人更有帮助。该研究结果表明,大模型和人类反馈可以相互补充,尤其有助于指导那些论文需要大幅修改的作者更早地提出这些问题。不过,大模型不能代替人工的同行评审,其审查可能会过于模糊,未能提供“具体的技术改进领域”,以及在某些情况下缺乏“对模型架构和设计的深入批评”。
[17] Can large language models provide useful feedback on research papers? A large-scale empirical analysis
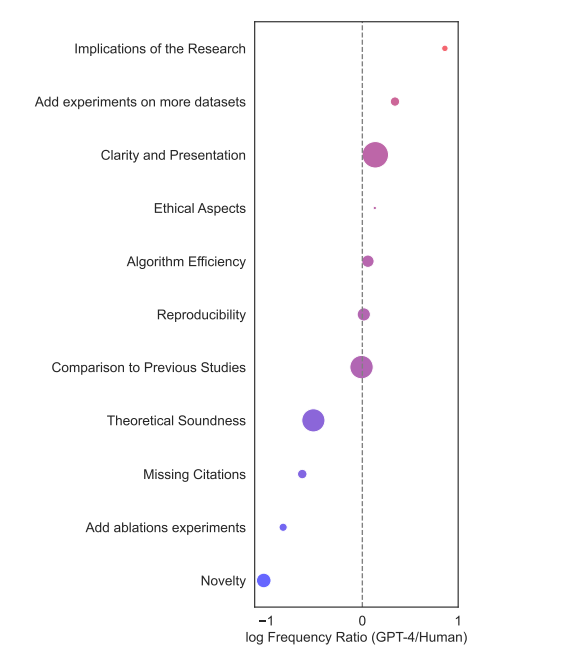
图11:GPT和人类在论文评审时关键领域的相对差异,可以看出人类关注论文的新颖性,而大模型更关注表述是否清晰
随着大模型越来越多地改变我们的生活,而且预计未来还将以更加深远的方式改变我们每个人,全球各地对人工智能的采用褒贬不一。而要想充分享受大模型带来的好处,首先要了解大模型具有的各项能力与缺陷,同时了解阻碍人们采用人工智能的心理障碍也至关重要。《自然·人类行为》上的研究指出了五项障碍:人们认为人工智能不透明,没有感情,缺乏灵活性,过于自主,非人性化。文章概述了解决这些障碍的最佳方法,并评估了其中的风险和益处。这些障碍并不全都适用于大模型应用,但值得参考。[18]
[18] Psychological factors underlying attitudes toward AI tools. Nat Hum Behav 7, 1845–1854 (2023).
四、大模型像人类一样思考
当大模型的规模增加,会表现出全新的能力,该现象称为涌现能力。其中有些能力并不像上述的自动完成化学实验一样涉及专业知识,而是需要让大模型能够像人一样思考。
《ChatGPT 为啥那么牛?语言模型足够大就会涌现出新能力》
具有经济理性
例如[19]通过指导 GPT 在风险、时间、社交和食物偏好四个领域做出预算决策,来研究 GPT 是否具有经济理性。该研究通过评估 GPT 的决策与经典显性偏好理论中效用最大化的一致性来衡量经济理性。研究发现,GPT 的决策在每个领域都基本合理,其合理性得分高于平行实验和文献中的人类受试者。此外,GPT 的估计偏好参数与人类受试者略有不同,表现出较低的异质性。这些结果表明,大模型具有做出正确决策的潜力,因此有必要进一步了解它们的能力、局限性和内在机制。
[19] The emergence of economic rationality of GPT
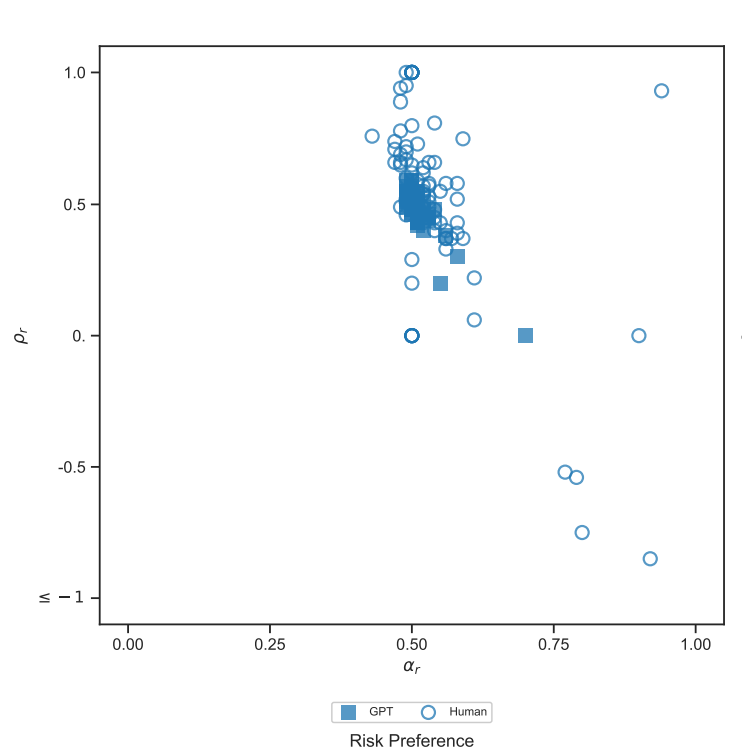
图12:风险偏好上大模型与人的偏好对比
博弈行为
博弈论作为一种分析工具,在社会科学研究中经常被用来分析人类行为。由于大语言模型(LLMs)的行为与人类高度一致,一个有前途的研究方向是在博弈实验中使用 LLMs 作为人类的替代品,从而实现社会科学研究。[20] 选择了三个经典博弈(独裁者博弈、剪刀石头布和环网博弈)来分析大模型在这三个方面的理性程度。实验结果表明,即使是目前最先进的 GPT-4,在博弈论方面与人类相比也有很大差距。
[20] Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis
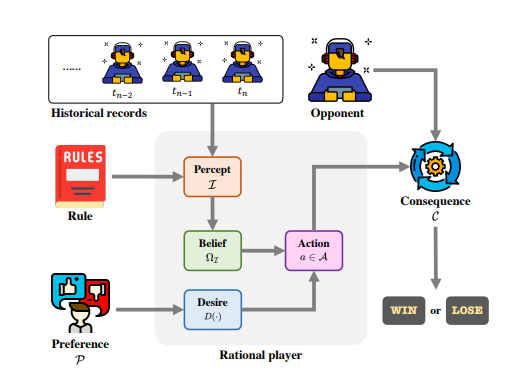
图13:大模型博弈研究的流程图
AI Agent 社交互动
除了在单个任务上的能力外,大模型agent之间的互动,还可涌现出类似人类社交网络的特征,例如无标度网络[21]。该研究指出当将大语言模型整合进基于主体的模型时,必须确保这些模型不仅能在特定情况下复制出真实的类人反应,还能准确地代表主体相互作用情境下,潜在人类行为的整体概率分布。
[21] Emergence of Scale free Networks in Social Interactions among Large Language Models
《前沿进展:大模型agent的社交互动涌现出无标度网络》
《多主体智能综述:社会互动启发的人工智能进化》
图14:基于大语言模型的生成式主体网络生长
偏见与道德观念
例如大模型的数据来源若包含了偏见,那训练出的模型也会是有偏见的。[22]基于来自 70 多个国家的大型文本库训练语言模型,关注代表职业-家庭、数学-自由艺术和科学-艺术属性的单词集。研究发现,在经济较发达和个人主义较强的国家,关于职业、数学和科学的性别偏见都较强,被称为“性别平等悖论”(gender equality paradox)。这项研究指出,用于训练人工智能的在线文本语料库中存在的性别刻板印象可能会强化人工智能模型中的这些刻板印象。
[22] Gender stereotypes embedded in natural language are stronger in more economically developed and individualistic countries. https://academic.oup.com/pnasnexus/article/2/11/pgad355/7429364
随着大模型的应用,人们会担心缺少道德观念。[23]指出大模型表现出几种以西方为中心的价值观偏差;它们高估了非西方国家人们的保守程度,对非西方国家性别的表述不够准确,并将老年人群描绘成拥有更传统的价值观。上述结果凸显了大模型的价值偏差问题,表明需要以社会科学为依据的技术解决方案来解决大模型的价值多元化问题。
[23] Assessing LLMs for Moral Value Pluralism
价值对齐
接下来看看大模型的短板及其改进措施。针对大模型的幻觉问题,已有多种检测工具。人们对智能助手的另一担心,是其缺少共情能力。对此,SoulChat[24]通过提示词让大模型的回复更加具有同情心。而针对大模型缺少批判性思维的问题,[25]提出的Evoke通过引入独立的大模型作为审阅者对当前提示词进行评分,审阅者带来的提示词迭代确保了提示语在每次迭代中都能得到完善。考虑到大模型训练可能包含不安全的信息,[26]提出的方案可以让大模型忘掉私有训练数据中不安全的部分,从而避免数据泄露或工具滥用。以上的例子还有很多,针对大模型在日常应用中展现的问题,学界和工业界已提出并将会在未来提出更多评价体系及解决方案。
[24] SoulChat: Improving LLMs' Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations
[25] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt
[26] Learning and Forgetting Unsafe Examples in Large Language Models
数字世界中的大模型Agent:机遇与风险
万字长文详解:大模型时代AI价值对齐的问题、对策和展望
集智×安远AI :OpenAI风波背后,如何&谁来确保AGI安全?
人机共生的大模型伦理与价值观挑战|集智俱乐部20周年AIS²年会
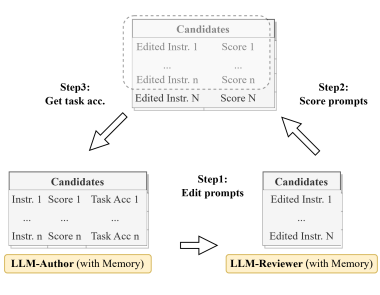
图16:Evoke的提示词生成-评估迭代示意
五、总结
尽管大语言模型表现出近似人类的理解能力,但 AI 系统真的可以像人类一样理解语言吗?机器理解的模式必须和人类理解相同吗?对这些问题的讨论[27],指出进一步拓展人工智能与自然科学的交叉研究,有望拓展多学科的审视角度,总结不同方法的优势边界,应对交叉认知理念的融合挑战。
[27] Mitchell M, Krakauer D C. The debate over understanding in AI’s large language models[J]. PNAS, 2023
《圣塔菲学者:AI 大语言模型真的理解人类语言吗?》
回顾大模型的众多应用后,可以找到其依赖的底层技术,主要有两项,一是AutoGPT提供的根据目标自行做出决策,从而自动利用思维链以执行复杂任务;二是引入反馈和评价,像对抗神经网络那样,让一个或多个大模型生成解法(可能对应不同模态),另一个大模型评估通过迭代(整合)以优化解法。
大模型涌现的类比能力,特定任务展现的抽象模式归纳能力,在大多数情况下都能与人类能力相匹配甚至超越人类[28]。在讨论大模型究竟是奇点降临的前奏,亦或只是风口时,要关注的不仅是大模型在自然科学中能完成什么任务,还要考虑其在社会领域引起的反响,这也是本文关注的重点。而基于大模型对人类自身的认知,则是帮助我们在未来更好地做好大模型监督者不可或缺的基础。
[28] Emergent analogical reasoning in large language models. Nature Human Behaviour, 2023
- 编辑:于腾凯
- 校对:林亦霖

