
- 1虚拟化技术发展编年史_vmware5.5那一年
- 2html-video:计算视频是否完整播放 / 计算视频完播率
- 3【Docker学习笔记 四】深入理解Docker镜像组成原理
- 4Vue快速上手笔记_youshou66
- 5云队友丨陆奇:在未来,究竟哪种职业创造财富的机会最大?
- 6host文件被锁死无法修改怎么办?解锁host文件修改新方法_hosts被锁怎么办
- 7绝对零基础的C语言科班作业②数据(数据类型和常量变量)_c语言中值不变的数据对象称为
- 8基于networkx聚类技术—复杂网络社团检测(附完整版代码)_networkx集成的社区检测算法
- 9Docker命令及软件安装_mysql_random_root_password=yes
- 10linux中uname命令的用法_uname -a命令详解
Python 并发编程实战,多线程、多进程加速程序运行_python并发计算模拟使用多个进程或线程同时进行复杂的数学计算。
赞
踩
为什么使用并发
场景一:一个网络爬虫,按顺序爬取花了1小时,采用并发下载减少到20分钟
场景二:一个APP应用,优化前每次打开页面需要3秒,采用异步并发提升到每次200毫秒
- 引入并发,就是为了提升程序运行速度
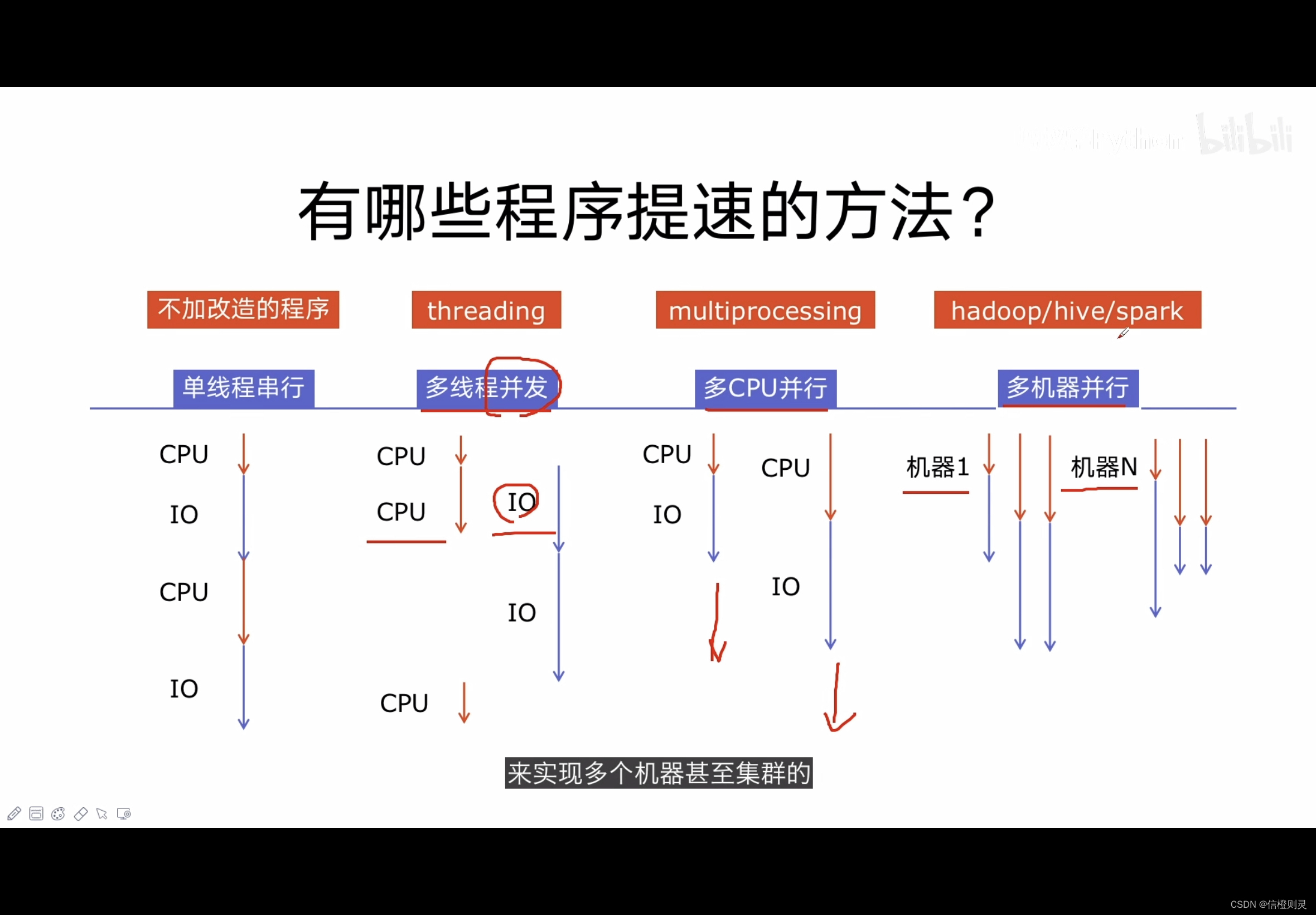
Python对于并发编程的支持:
-
多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴的等待IO完成
-
多进程:multiprocessing,利用多核CPU的能力,实现真正的并行执行任务
-
异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
-
使用Lock对共享资源加锁,防止冲突访问。【比如多线程往同一文件中执行写入】
-
使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
-
使用线程池Pool/进程池Pool,简化线程、进程的任务提交、等待结束、获取结果
-
使用subprocess启动外部程序的进程,并进行输入输出交互
比如:写好的exe程序,通过这个模块可以调起exe并跟他进行输入输出的交互,实现交互式的进程通信。
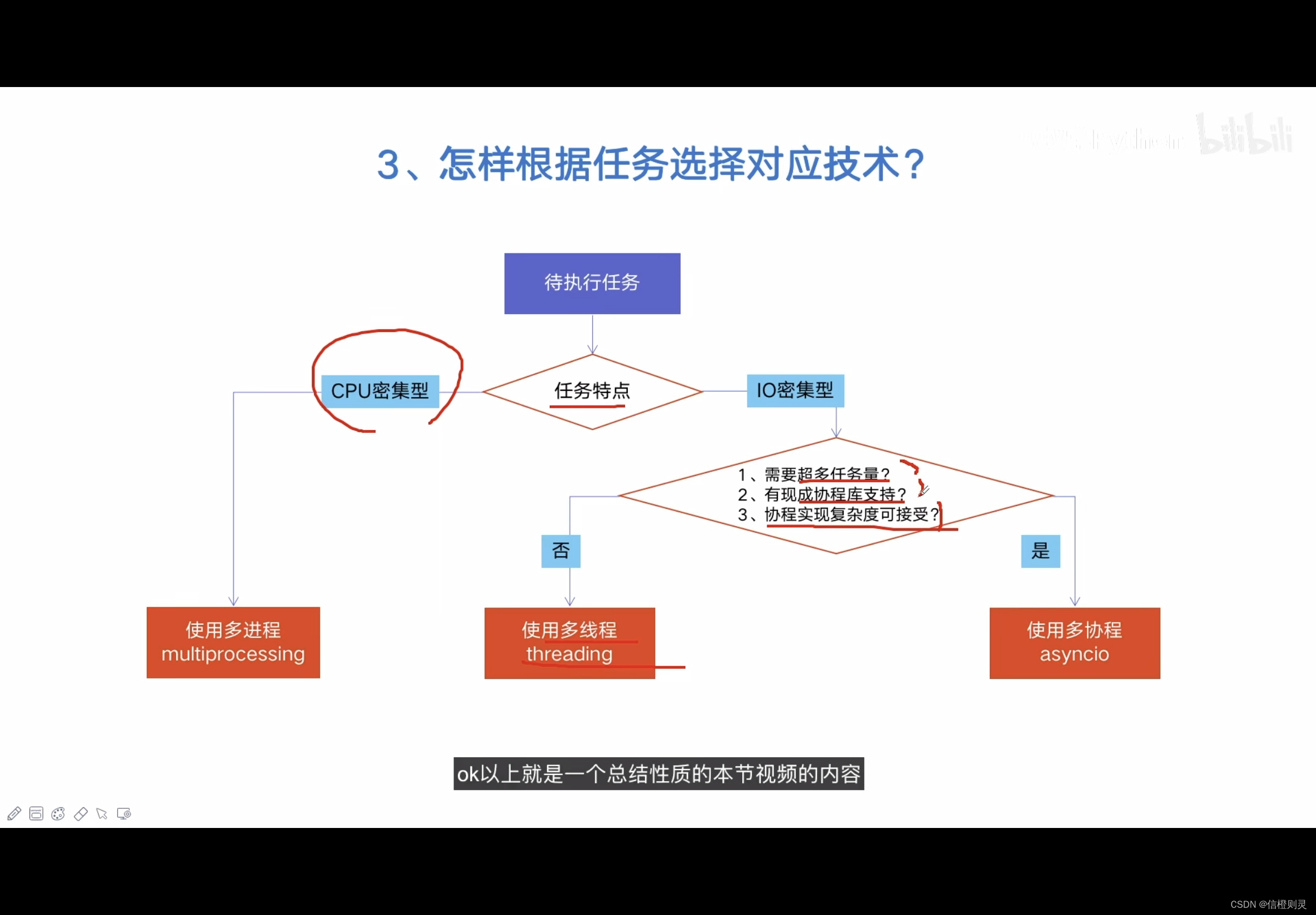
怎么选择多线程、多进程、多协程
Python并发编程的三种方式:
多线程Thread 、 多进程 Process 、 多协程 Coroutine*[kəru:'ti:n]*
什么是CPU密集型计算、IO密集型计算
CPU密集型(CPU-bound)
bound:受限制的
CPU密集型也叫计算密集型,是指 I/O 在很短的时间内就可以完成,CPU需要大量的计算和处理,特点是CPU占用率非常高。
例如:压缩解压缩、加密解密、正则表达式搜索等等【需要大量的计算来完成】
I/O密集型(I/O-bound)
IO密集型指的是系统运作大部分的情况是CPU在等 I/O(硬盘/内存/网络等等)的读/写操作,CPU占用率非常低。
例如:文件处理程序【大量读写文件】、网络爬虫程序【网络下载】、读写数据库【网络的读取】程序
多线程、多进程、多协程的对比
多线程 Thread(threading)
优点:相比进程,线程更加轻量级并且占用的资源更少。
比如:每个线程的运行都要包含自己一些变量的存储,存储到内存区域,这就占用一些资源
缺点:
- 相比进程:多线程只能并发执行,不能同时进行多CPU(GIL)的计算。
- 相比协程:启动数目有限,有线程切换的开销【协程没有切换的开销】。
- 线程占用内存资源,协程共用线程的资源,所以肯定协程的启动数目大于线程
适用于:I/O密集型计算,同时运行的任务数目要求不多
多进程Process(multiprocessing)
优点:使用多核CPU并行运算
缺点:占用资源最多、可启动数据比线程少
适用于:CPU密集型计算
多协程Coroutine(asyncio)
优点:内存开销最少、启动数量是最多的。
缺点:支持的库有限制(aiohttp VS requests),代码实现复杂
适用于:IO密集型计算、需要超多任务运行,但有现成库支持的场景
关系总结:
一个进程中,可以启动N个线程
一个线程中,可以启动N个协程,甚至几万个协程,这些协程共用线程中的资源。
知识点:
并发:一段时间内执行多个进程
并行:一瞬间执行多个进行
怎样根据任务选择对应技术
全局解释器锁 (GIL)
Python速度慢的两大原因
相比C/C++/java,Python确实慢,所以很多公司的基础架构代码依然使用C/C++开发,想阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块。
-
原因1
Python是动态类型语言:比如Python对变量类型的自动判断
python边解释边执行:Python写好的代码需自动编译才能执行,而C等语言都是编译好之后才执行。 -
原因2【主要原因】
GIL锁:无法利用多核CPU并发执行任务。
GIL是什么?
全局解释器锁(Global Interpreter Lock)
GIL使得任何时刻仅有一个线程在执行,即使在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程,所以无法发挥多核CPU的优势。
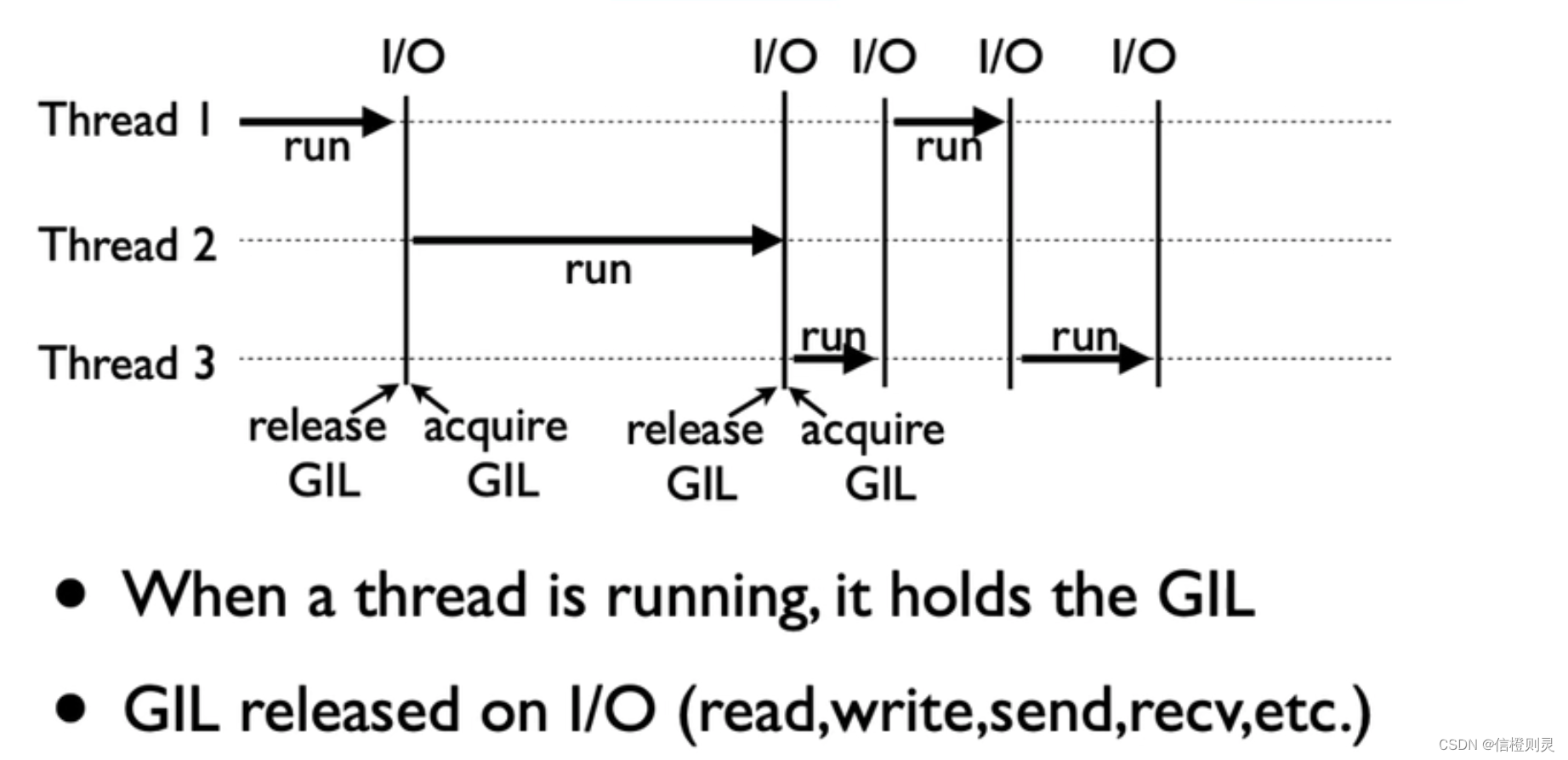
在上图中的流程:
- 当 线程1 在运行的时候,则会启动GIL
- 当 线程1 需要进行IO操作时,GIL则会释放,此时线程1切换到线程2运行,GIL再次启用。
- 当线程2 运行IO时,GIL再次释放,此时线程2切换到线程3,GIL则再次启用。
以上过程都是在线程间切换,同一时间只有一个线程在运行,当线程运行时,GIL锁将对资源进行锁定,从而简化了Python对共享资源的管理。
为什么有GIL这个东西?
为了解决多线程之间数据的完整性和状态同步问题。
原因详解
Python中对象的管理,是使用的引用计数器进行的,引用数为0则释放对象
好处: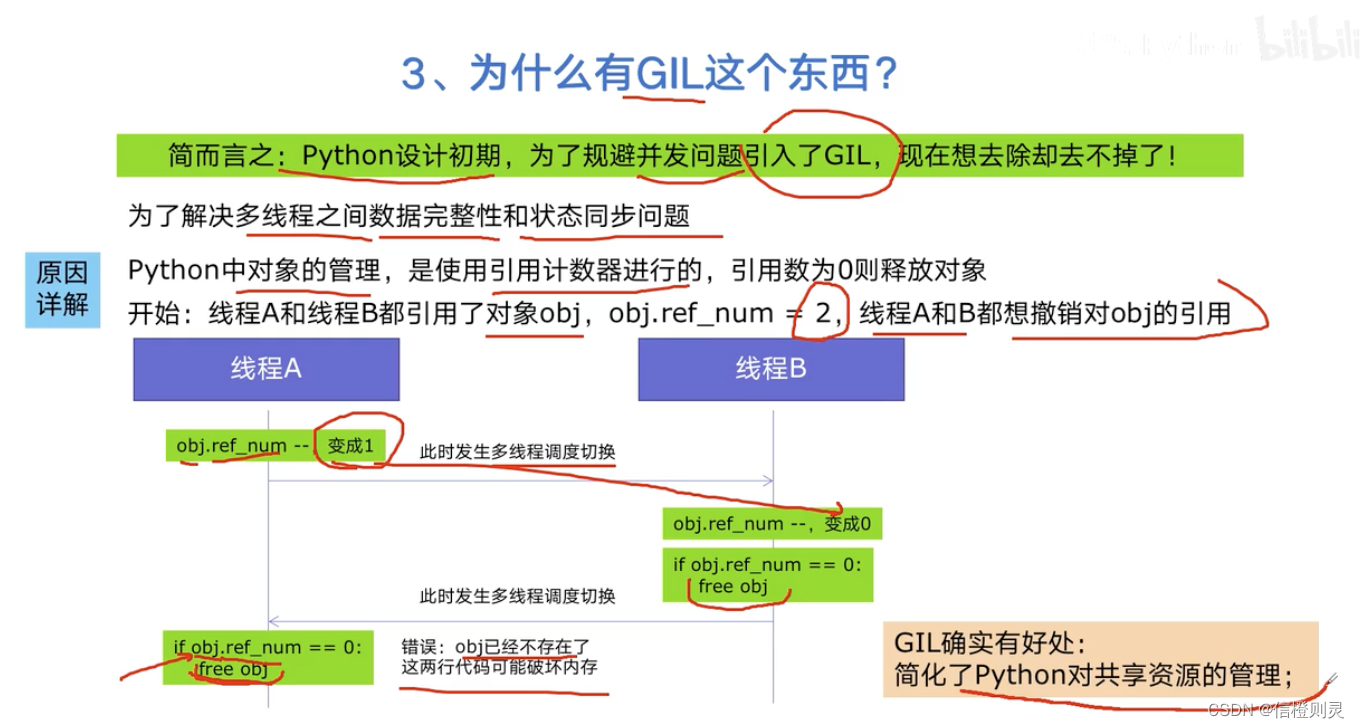
GIL简化了Python对共享资源的管理。
怎么规避GIL带来的限制?
-
多线程 threading 机制依然是有用的,主要用于I/O密集型计算。
在I/O(read、write、send、recv等等)期间,线程会释放GIL,实现CPU和IO的并行,因此多线程用于IO密集型计算依然可以大幅度提升速度
但是多线程如果用于CPU密集型计算时,只会更加拖慢速度「多线程的切换会消耗CPU,所以将拖慢CPU的运行。」
-
使用 multiprocessing 的多进程机制实现并行计算、充分利用多核CPU的优势
总结:
- 多线程适用于IO密集型问题,当线程在处理IO问题时,将释放GIL锁,并切换至下一线程,线程的切换使用的是CPU,线程的处理使用的是IO,这样就实现了CPU和IO的并行。
- 多进程用于处理CPU密集性问题,适用于充分发挥多核CPU的优势,多进程其实变相的解决了GIL锁的弊端。
Python多线程爬取数据
Python创建多线程的方法
创建线程:
import threading
# 创建线程对象
t = threading.Thread(target=func_name, args=(arg1, arg2))
# 启动线程对象
t.start()
# 等待线程对象结束
t.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Python实现消费者生产者爬虫
多组件的Pipeline技术架构
Pipeline: 复杂的事情不会一下子做完,而是通过很多中间步骤来一步步的完成。
Processor: 处理器
- 由输入数据到输出数据,中间会经过很多处理模块「处理器」的处理。
- 生产者的生产结果,通过中间数据,传给消费者进行消费。
- 生产者以输入数据作为原料,消费者将自己的输出作为输出数据。
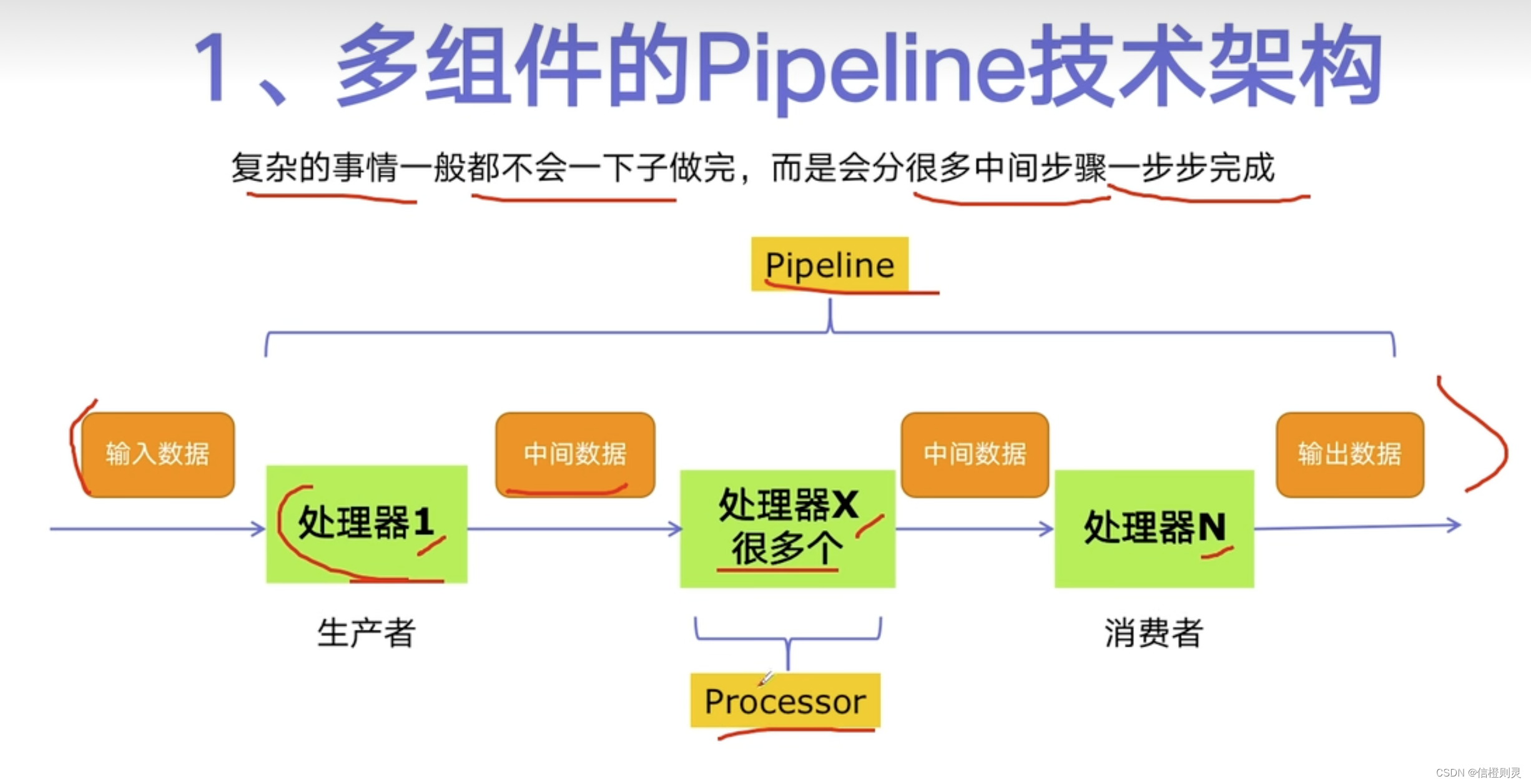
生产者消费者爬虫的架构
**优势:**生产者和消费者可以由两波人开发。并且可以配置不同系统的资源,比如线程数。
注意:生产者和消费者均是线程组
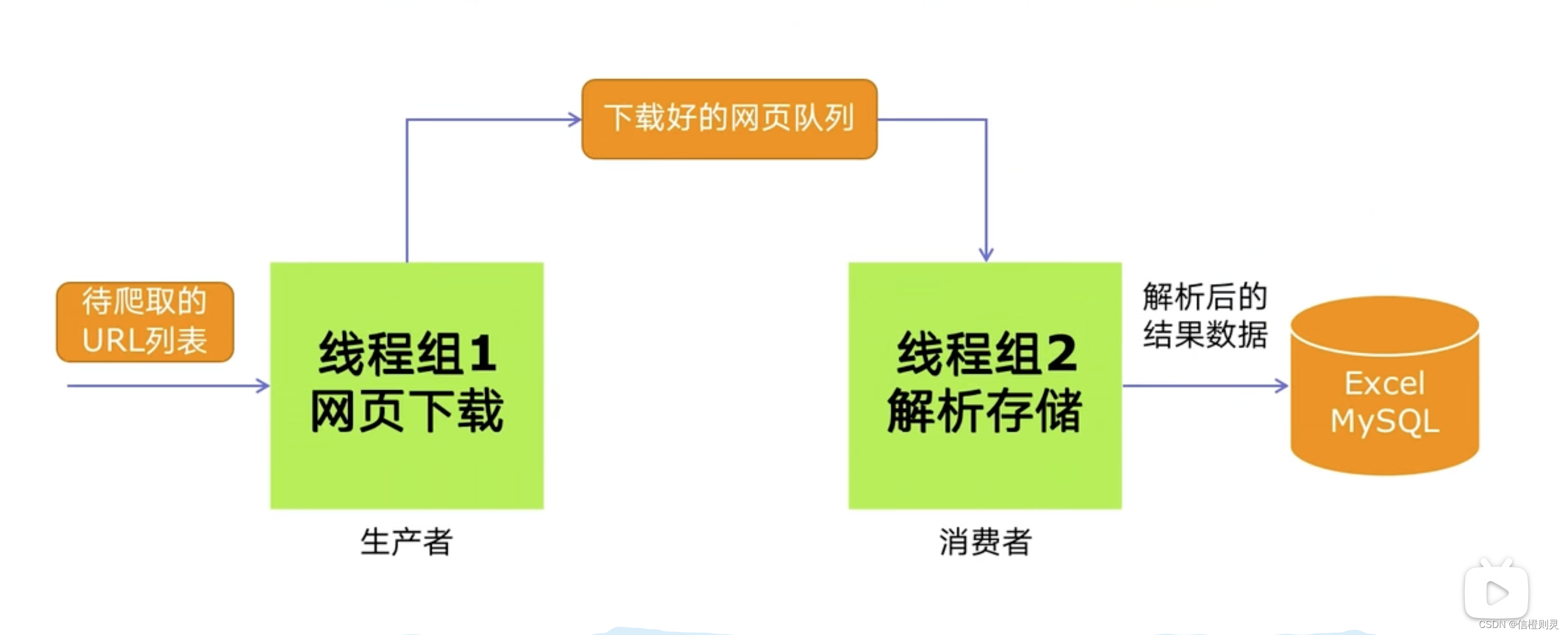
问题:
在两个线程组之间,下载好的网页队列是怎么进行交互的呢,这个时候就引入了queue
多线程数据通信 queue.Queue
queue.Queue可以用于多线程之间的、线程安全的数据通信
# 1、导入类库 import queue # 2、创建Queue q = queue.Queue() # 3、添加元素【阻塞】 # 当队列中满了之后,会卡住,直到有了空闲的位置,才会添加。 q.put(item) # 4、获取元素 # 当队列中没有数据的时候,会卡住,直到队列中填入了新的数据。 item = q.get() # 5、查询状态 # 查看元素的数量 q.qsize() # 判断是否为空 q.empty() # 判断是否已满 q.full()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
总结:
线程安全,多个线程并发同时访问数据,不会发生冲突,即不存在共享变量访问冲突问题。
Queue线程安全队列:https://www.cnblogs.com/ChanKaion/p/9708155.html
https://www.cnblogs.com/ananmy/p/15536483.html
TODO:想一下,GIL锁和queue的区别,两者均能避免发生冲突。
线程安全问题以及Lock解决方案
线程安全概念介绍
线程安全:指某个函数、函数库在多线程环境中被调用时,能够正确的处理多个线程之间的共享变量,使程序功能正确完成。
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全。
Lock用于解决线程安全问题

do something为对共享空间进行操作,通过加锁的操作,对共享数据进行限制,防止出现线程不安全。
实例代码演示问题 以及解决方案
import threading lock = threading.Lock() class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): with lock: if account.balance >= amount: print(threading.current_thread().name, "取钱成功") account.balance -= amount print(threading.current_thread().name, "余额为:", account.balance) else: print(threading.current_thread().name, "余额不足", account.balance) if __name__ == '__main__': account =Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
线程池 ThreadPoolExecutor
线程池的原理
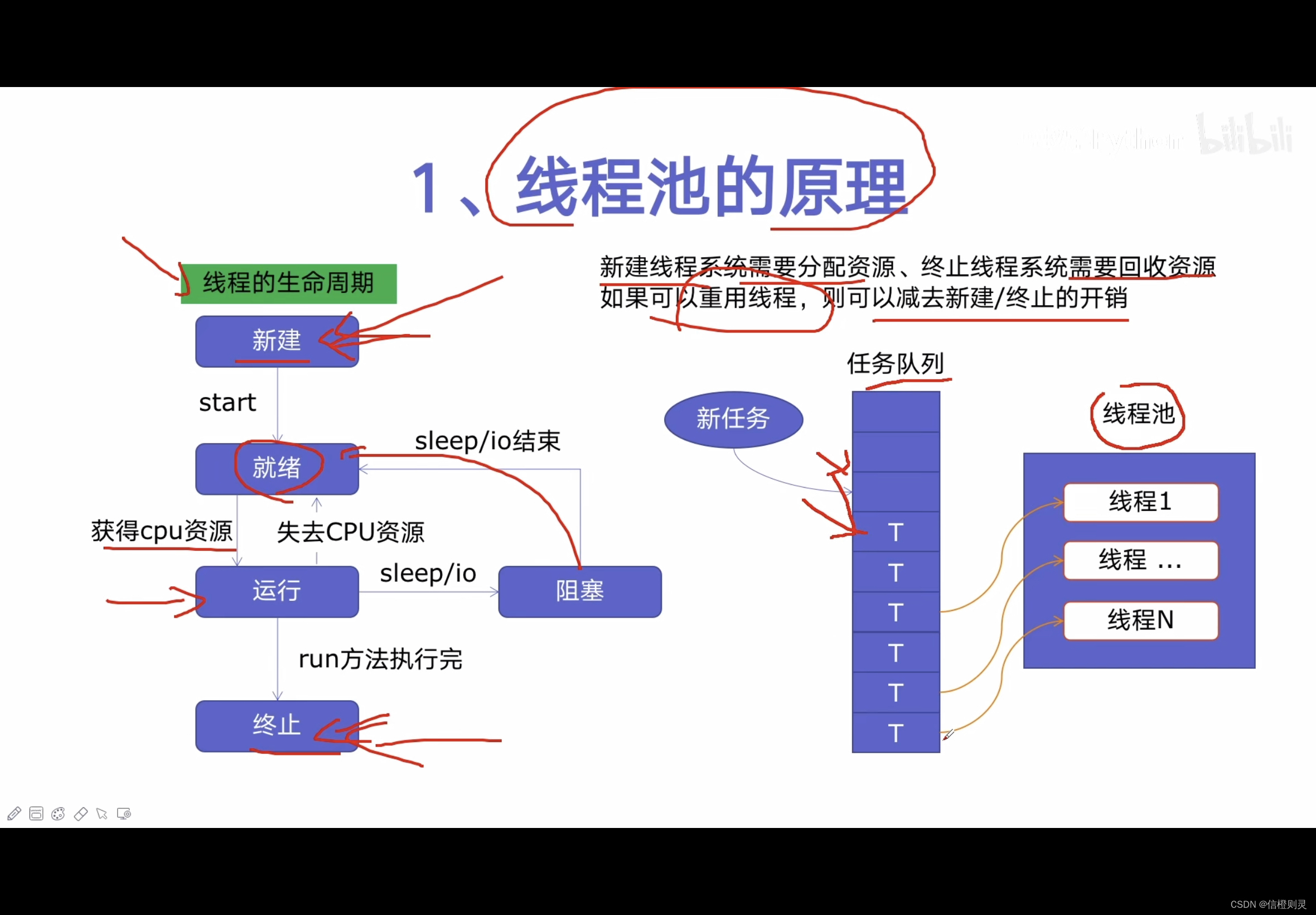
线程的生命周期:
-
线程新建时,线程为完全不动的状态,【新建线程系统需要分配资源、终止线程系统需要回收资源。】
-
当执行start方法时,线程进入就绪的状态。
-
当系统对线程进行调度时,线程运行【获的CPU资源】
-
在运行时,可能会失去CPU再次进入就绪的状态,也可能因为sleep/io操作,进入阻塞状态,当阻塞状态完毕后,则进入就绪状态
-
当线程完成或者被终止时,则进入终止状态
线程池的原理:
由于线程的创建和终止会对资源进行分配和回收的操作,但如果能重用线程,则可以减去新建/终止的开销
线程池的流转
由线程池和任务队列共同实现
- 当一个新任务来的时候,会在任务队列中排队,
- 线程池中创建好的线程去任务队列中获取任务进行处理。-
- 当线程池中的某个线程完成了任务后,会去任务队列中再取任务,如果任务队列中没有任务的话,线程也不会销毁,而是等待任务的到来
线程池的好处
1、提升性能:减去了大量新建、终止线程的开销,重用了线程资源
2、使用场景:适合处理突发性大量请求或需要大量线程来完成的任务, 同时任务的处理时间要较短。
3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大使相应变慢等问题。
4、代码优势:使用线程池的语法比自己新建线程的运法更加简洁。
ThreadPoolExecutor的使用方法
with concurrent.futures.ThreadPoolExecutor() as pool:
# 注意map方法,传入的是urls,路由的数组
results = pool.map(func_name, urls)
# 通过遍历results,查看入参对应的运行的结果
for result in results:
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
map函数:注意map中的参数是一个iter数据。并且map的结果和入参的顺序是对应的。
with concurrent.futures.ThreadPoolExecutor() as pool:
# 注意:submit传入的参数是单个的url
futures = [pool.submit(func_name, url) for url in urls]
# 遍历方法一:
for future in futures:
print(future.result())
# 遍历方法二:
for future in concurrent.futures.as_completed(futures):
print(future.result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
submit方法:
as_completed与直接遍历futures相比,它的顺序是不定的,哪个futures中的future「任务」先完成,就先返回对应的result。
使用线程池改造爬虫程序
import concurrent.futures import requests from bs4 import BeautifulSoup cookies = { '__gads': 'ID=01a33c16f7342abf:T=1654248825:S=ALNI_MaoNrGKUrixqn6rBSNxxNgXsVorgQ', '.AspNetCore.Antiforgery.b8-pDmTq1XM': 'CfDJ8NfDHj8mnYFAmPyhfXwJojeJJpPjLQQlBtV8bozRp64t8x_KK-2i8q5LmmXtv5iYCRxB0V8KhixTpWgIbUJ9tMtP_xT_5YuEArBNySWRZfHYT2UzQLy1RGgx4Nq3L2F-d6EakliEsk_oaBJK-pQB1yg', '_ga': 'GA1.2.2002706462.1666545482', 'Hm_lvt_866c9be12d4a814454792b1fd0fed295': '1664855714,1665306405,1665930146,1666691225', '_gid': 'GA1.2.513431899.1667368433', '__gpi': 'UID=00000b6c30fd6c87:T=1666682723:RT=1667368433:S=ALNI_Ma6hg_8pHw6BGE-QqB8Ug7ucEFxtQ', '_gat_gtag_UA_476124_1': '1', 'Hm_lpvt_866c9be12d4a814454792b1fd0fed295': '1667381756', } headers = { 'authority': 'www.cnblogs.com', 'accept': 'text/plain, */*; q=0.01', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8', 'content-type': 'application/json; charset=UTF-8', 'origin': 'https://www.cnblogs.com', 'referer': 'https://www.cnblogs.com/', 'sec-ch-ua': '"Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', } def crawl(index): print("index:", index) json_data = { 'CategoryType': 'SiteHome', 'ParentCategoryId': 0, 'CategoryId': 808, 'PageIndex': index, 'TotalPostCount': 4000, 'ItemListActionName': 'AggSitePostList', } response = requests.post('https://www.cnblogs.com/AggSite/AggSitePostList', cookies=cookies, headers=headers, json=json_data) return response.text def parse(html): soup = BeautifulSoup(html, 'html.parser') links = soup.find_all("a", class_='post-item-title') return [(link['href'], link.get_text()) for link in links] # craw with concurrent.futures.ThreadPoolExecutor() as pool: htmls = pool.map(crawl, range(1, 50)) # 此处使用map方法,为了将将url和返回的数据关联起来。使用zip方法 htmls = zip(range(1, 50), htmls) # # for url, html in htmls: # print(url, len(html)) # parse with concurrent.futures.ThreadPoolExecutor() as pool: futures = {} for url, html in htmls: # submit 一个个的提交,可以通过字典将future和url对应起来 future = pool.submit(parse, html) futures[future] = url # for future, url in futures.items(): # print(f"url为:{url}", f"结果为{future.result()}") for future in concurrent.futures.as_completed(futures): url = futures[future] print(f"url为:{url}", f"结果为{future.result()}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
在web服务中,使用线程池加速
web服务的架构及特点
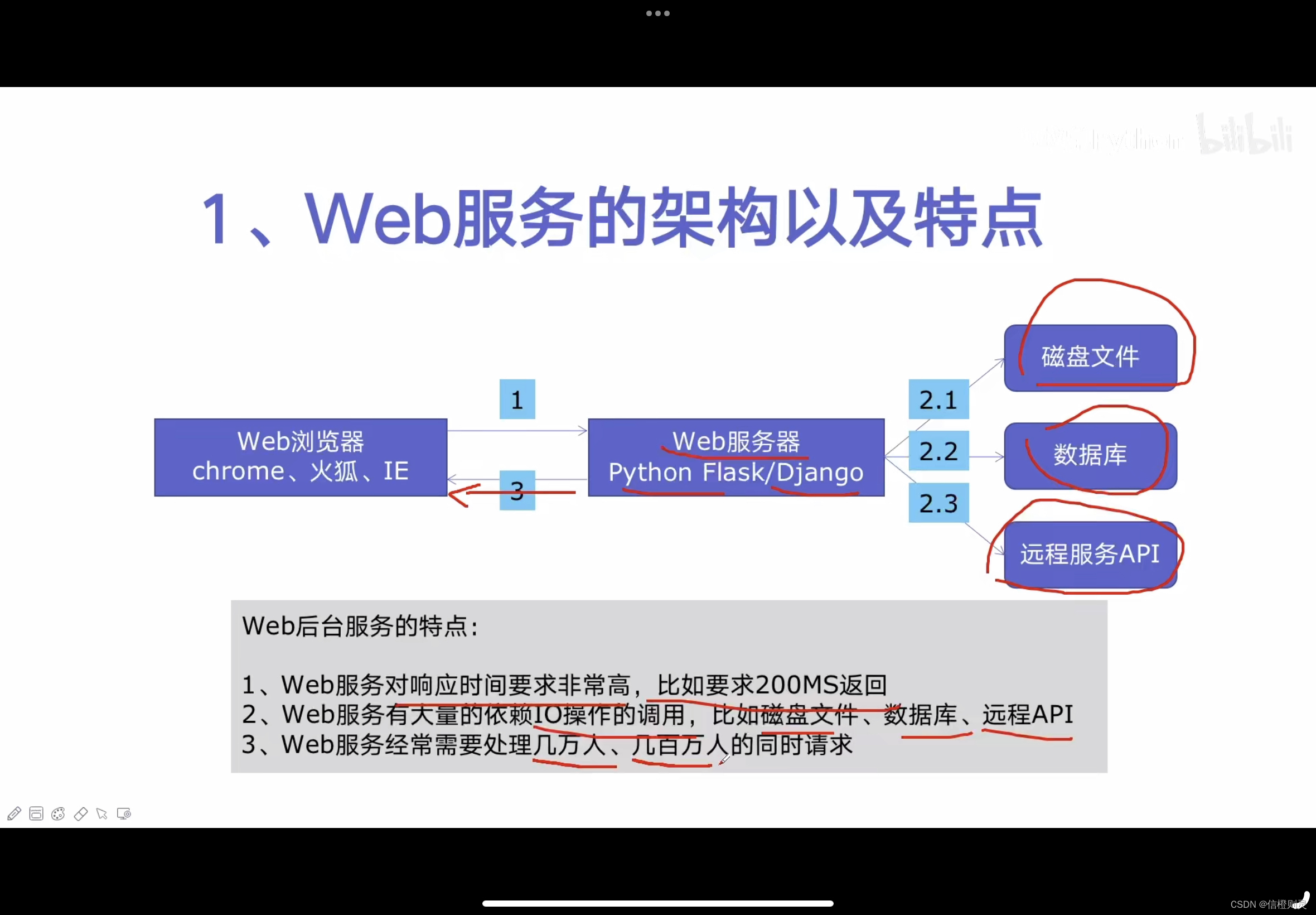
使用线程池ThreadPoolExecutor加速
1、由于web服务需要处理几万人的请求,所以肯定不能创建销毁线程,此时需要线程池,实现对线程的重用
线程池的线程数目不会无限创建(导致系统挂掉), 具有防御功能
2、方便磁盘文件、数据库、远程API和IO的调用,实现并发执行。
用Flask实现Web服务并实现加速
import json import time import flask from concurrent.futures import thread app = flask.Flask(__name__) pool = thread.ThreadPoolExecutor() def read_file(): time.sleep(0.1) return "read file" def read_api(): time.sleep(0.2) return "read api" def read_db(): time.sleep(0.3) return "read db" @app.route('/') def index(): result_file = pool.submit(read_file) result_api = pool.submit(read_api) result_db = pool.submit(read_db) return json.dumps({ "result_file": result_file.result(), "result_api": result_api.result(), "result_db": result_db.result(), }) pass if __name__ == '__main__': app.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
使用多进程,multiprocessing加速程序的运行
有了多线程threading,为什么使用多进程multiprocessing
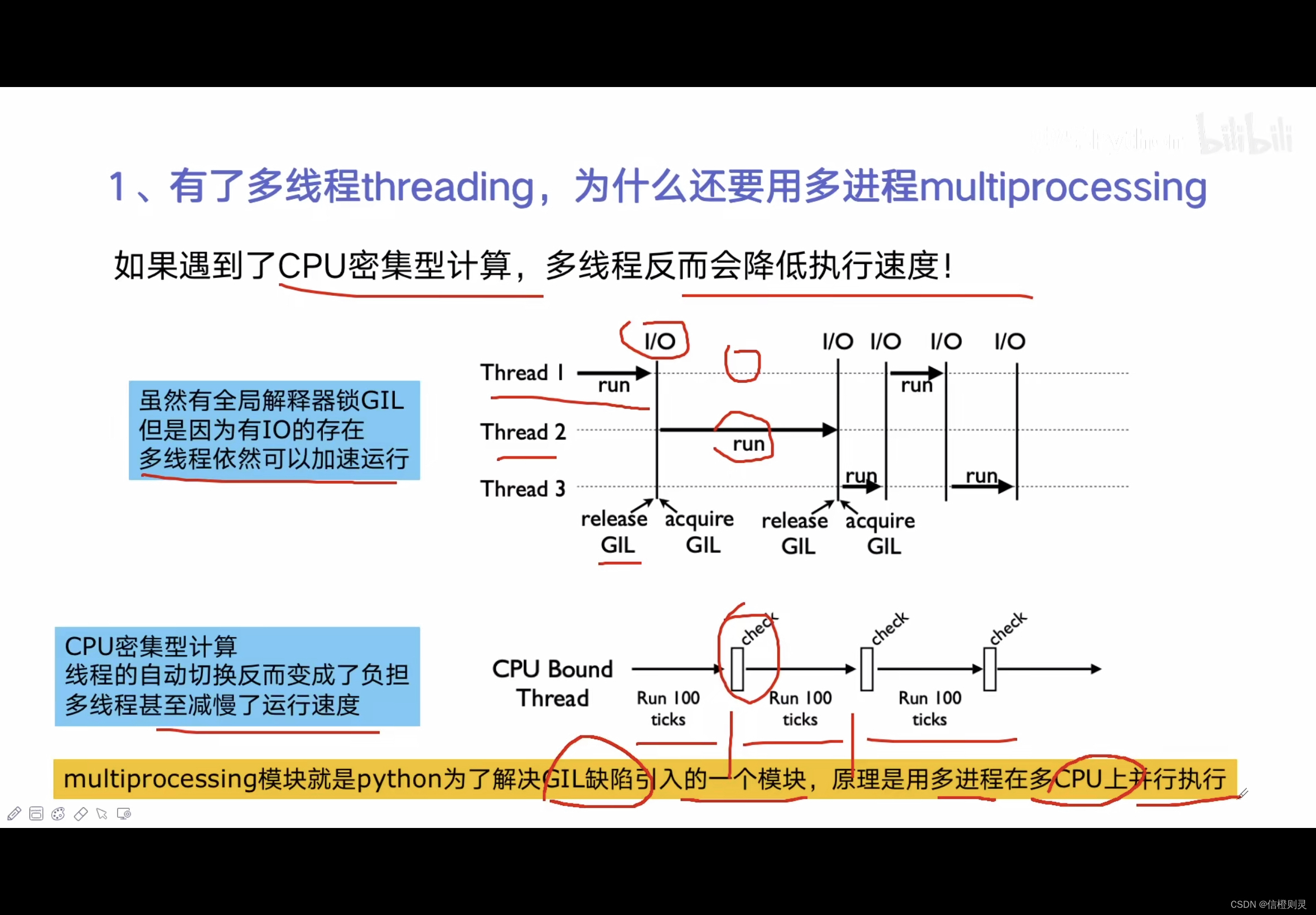
多进程multiprocessing知识梳理

代码实战:单线程、多线程、多进程对比cpu密集计算速度
由于GIL的存在,多线程比单线程计算的还慢,而多进程可以明显加快执行速度。
# 判断素数,CPU密集型计算。 import math import time from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor PRIMES = [112272535095293] * 100 def is_primes(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False sqrt_n = int(math.floor(math.sqrt(n))) for i in range(3, sqrt_n + 1, 2): if n % i == 0: return False return True def single_thread(): for i in PRIMES: is_primes(i) def multi_thread(): with ThreadPoolExecutor() as pool: pool.map(is_primes, PRIMES) def multi_process(): with ProcessPoolExecutor() as pool: pool.map(is_primes, PRIMES) if __name__ == '__main__': start = time.time() single_thread() print(f"single_thread, cost: {time.time() - start}, seconds") start = time.time() multi_thread() print(f"multi_thread, cost: {time.time() - start}, seconds") start = time.time() multi_process() print(f"multi_process, cost: {time.time() - start}, seconds")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
queue和lock和GIL,这三个的实际应用场景。
queue:生产者消费者模式
Lock:安全锁,防止冲突
参考文章
【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行
Python语法-多进程、多线程、协程(异步IO)


