
- 1【虚拟仿真】Unity3D中实现UI跟随3D模型旋转移动、UI一直面朝屏幕_unity实现ui跟随3d物体
- 2Font Awesome 找图标的正确姿势_fontawesome v6 图标名 哪里查
- 3音频格式之AAC:(2)AAC封装格式ADIF,ADTS,LATM,extradata及AAC ES存储格式
- 4一个做过的项目的小总结_做过的项目内容
- 5Unity | 渡鸦避难所-1 | 修复资源导入后呈现洋红色(Built-in 转 URP)_unity 打开场景全红,管线不匹配
- 6SSM+mysql餐厅点餐系统-计算机毕业设计源码02635_点餐系统数据库设计表
- 7STM32F103C8T6智能小车舵机超声波避障_stm32小车舵机
- 8【JavaScript】1.5 错误处理和调试
- 9YOLOV8 C++ opecv_dnn模块部署_yolov8 opencv
- 10volatile关键字特性及原理_解释一下volatile关键字的特性
python-excel处理(xlwings模块的使用)_linux xlwings依赖libreoffice
赞
踩
xlwings简要操作说明
xlwings与pandas、numpy模块有较好的交互,语法类似VBA,支持python调用vba,excel中调用python函数,可对excel进行读写操作;
局限,不同于openpyxl模块,xlwings模块对excel应用有依赖,这意味着如果在linux中,该模块无法使用。

OpenPyXL 可以读、写和编辑Excel文件,而XlsxWriter 只能读。
OpenPyXL 处理包含 VBA 宏的Excel文件时更加方便。
XlsxWriter的文档更优秀。
XlsxWriter 通常比OpenPyXL 更快,不过具体速度取决于你要写入的工作簿的大小,有时候差异并不明显。
文档链接:xlwings中文文档链接
目录
1. 对象结构:
xlwings — apps(App) — books(Book)— sheets(Sheet)— Range
模块 — 应用 — 工作簿 — 工作表 — 单元格
- 1
- 2
2. App常用语法
import xlwings as xw
# 创建应用app:
# 参数:visible:应用是否可见(True|False),add_book:是否创建新工作簿(True|False)
app = xw.App(visible=True,add_book=True)
wb = app.books.active # get新创建的工作簿(刚创建的工作簿为活动工作簿,使用active获取)
# 警告提示(True|False)
app.display_alerts = False
# 屏幕刷新(True|False)
app.screen_updating = False
# 工作表自动计算{'manual':'手动计算','automatic':'自动计算','semiautomatic':'半自动'}
app.calculation = 'manual'
# 应用计算,calculate方法同样适用于工作簿,工作表
app.calculate()
# 退出应用
app.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3. Book常用语法
import xlwings as xw
app = xw.App(visible=True,add_book=False)
- 1
- 2
3.1 新建工作簿
wb = app.books.add() # 方法1
wb = xw.Book() # 方法2,不填写参数新建工作簿
wb = xw.books.add()
- 1
- 2
- 3
3.2 打开工作簿
# file_path:工作簿文件路径
wb = app.books.open(file_path)
wb = xw.Book(file_path)
- 1
- 2
- 3
xlwings.Book(fullname = None,update_links = None,read_only = None,format = None,password = None,write_res_password = None,ignore_read_only_recommended = None,origin = None,delimiter = None,editable = None,notify = None,converter = None,add_to_mru = None,local = None,destroy_load = None,impl = None )
参数:
- fullname(str 或类似路径的对象,默认为None)–现有工作簿的完整路径或名称(包括xlsx,xlsm等)或未保存工作簿的名称。如果没有完整路径,它将在当前工作目录中查找文件。
- update_links(bool ,默认为None)–如果省略此参数,则提示用户指定如何更新链接
- read_only(bool ,默认为False)– True以只读模式打开工作簿
- format(str)–如果打开文本文件,则指定分隔符
- password (str)–打开受保护的工作簿的密码
- write_res_password(str)–写入写保留工作簿的密码
- ignore_read_only_recommended(bool ,默认为False)–设置为True使只读推荐消息静音
- origin(int)–仅适用于文本文件。指定它的起源。使用XlPlatform常数。
- delimiter (str)–如果format参数为6,则指定分隔符。
- editable(bool ,默认为False)–此选项仅适用于旧版Microsoft Excel 4.0加载项。
- notify(bool ,默认为False)–如果文件无法以读写模式打开,则在文件可用时通知用户。
- converter(int)–打开文件时尝试的第一个文件转换器的索引。
- add_to_mru(bool ,默认为False)–将此工作簿添加到最近添加的工作簿列表中。
- local(bool ,默认为False)–如果为True,则使用Excel语言保存文件,否则使用VBA语言保存文件。在macOS上不支持。
- destroy_load(int ,默认xlNormalLoad)–可以是xlNormalLoad,xlRepairFile或xlExtractData之一。在macOS上不支持。
3.3 工作簿保存
wb.save()
wb.save(path=None) # 或者指定path参数保存到其他路径,如果没保存为脚本所在路径
- 1
- 2
3.4 其他:获取名称、激活、关闭
# get指定名称的工作簿
wb = xw.books['工作簿名称']
# 激活为当前工作簿
wb.activate()
# 返回工作簿的绝对路径
wb.fullname
# 工作簿名称
wb.name
# 关闭工作簿
wb.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. Sheet常用语法
4.1 工作表引用
引用工作表的前提:工作簿被打开
import xlwings as xw
wb = xw.books['工作簿名字']
sheet = wb.sheets['工作表名字']
sheet = wb.sheets[0] # 也可以使用数字索引,从0开始,类似于vba的worksheets(1)
sheet = wb.sheets('工作表名字') # 也可以使用熟悉的vba圆括号引用
# 从左往右,第二张sheet,圆括号序列从1开始,方括号从0开始
sheet = wb.sheets(2)
sheet = xw.sheets.active # 当前活动工作表,sheets是工作表集合
sheet = wb.sheets.active
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.2 新建|删除工作表
# 新建工作表表
# 参数:name:新建工作表名称;before创建的工作表位置在哪个工作表前面;after:创建位置在哪个工作表后面;
# before和after参数可以传入数字,也可以传入已有的工作表名称,传入数字n表示从左往右第n个sheet位置
# before和after参数不传,创建sheet默认在当前活动工作表左侧
sheet = xw.sheets.add(name=None,before=None,after=None)
wb.sheets.add(name='新工作表4',before='新工作表')
# 删除工作表
wb.sheets("新工作表4").delete()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.3 其他:激活,删除、工作表名称、行列删除
# 激活为活动工作簿 sheet.activate() # 清除工作表的内容和格式 sheet.clear() # 清除工作表内容,不清除样式 sheet.clear_contents() # 工作表名称 sheet_name = sheet.name # 删除工作表 sheet.delete() # 工作表计算 sheet.calculate() # 工作表的使用范围,等价与vba的usedrange sheeet.used_range # 删除第一行 sheet.api.rows(1).delete # 第一行插入一行 sheet.api.rows(1).insert # 删除第一列,a列 sheet.api.columns(1).delete # 删除b-e列 sheet.api.columns('b:e').delete # 第三列c列,插入一列 sheet.api.columns(3).insert sheet.api.columns('c").insert # 工作表隐藏,bool类型,True or False sheet.visible = True

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.4 自动匹配工作表列、行宽度
sheet.autofit(轴=无)
'''
若要自动调整行,请使用以下内容之一:rows或r
若要自动装配列,请使用以下内容之一:columns或c
若要自动调整行和列,请不提供参数。
'''
import xlwings as xw
wb = xw.Book()
wb.sheets['Sheet1'].autofit('c')
wb.sheets['Sheet1'].autofit('r')
wb.sheets['Sheet1'].autofit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5. Range常用语法
5.1 单元格引用
import xlwings as xw rng = xw.books['工作簿名称'].sheets['工作表名称'].range('a1') # 第一个应用第一个工作簿第一张sheet的第一个单元格 xw.apps[0].books[0].sheets[0].range('a1') xw.apps[0].books[0].sheets[0].range(1,1) # 使用row+column定位,坐标从1开始 # 引用活动sheet的单元格,直接接xw,Range首字母大写 rng = xw.Range('a1') # a1 rng = xw.Range(1,1) # a1,行列用tuple进行引用,圆括号从1开始 rng = xw.Range((1,1),(3,3)) # a1:a3 # 也可以工作表对象接方括号引用单元格 sheet = xw.books['工作簿'].sheets['工作表名称'] rng = sheet['a1'] # a1单元格 rng = sheet['a1:b5'] # a1:b5单元格 rng = sheet[0,1] # b1单元格,也可以根据行列索引,从0开始为 rng = sheet[:10,:10] # a1:j10 # 单元格邻近范围 rng = sheet[0,0].current_region #a1单元格邻近区域=vba:currentregion # 返回excel:ctrl键+方向键跳转单元格对象:上:up,下:down,左:left,右:right # 等同于vba:end语法:xlup,xldown,xltoleft,xltoright rng = sheet[0,0].end('down') # 清理单元格格式 Range.ClearFormats
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5.2 数据的读取
# 获取单元格的值,单元格的value属性
val = sheet.range('a1').value
ls = sheet.range("a1:a2").value # 一维列表
ls = sheet.range("a1:b2").value # 二维列表
- 1
- 2
- 3
- 4
5.3 单元格值默认读取格式
默认情况下,带有数字的单元格被读取为float,带有日期单元格被读取为datetime.datetime,空单元格转化为None;数据读取可以通过option操作指定格式读取
import datetime
sheet[1,1].value = 1
sheet[1,1].value
# 输出是1.0
sheet[1,1].options(numbers=int).value
# 输出是1
# 指定日期格式为datetime.date
sheet[2,1].options(dates=datetime.date).value
# 指定空单元格为'NA'
sheet[2,1].options(empty='NA').value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.4 单元格数据写入
# 单个值 sheet.range('a1').value = 1 # 写入一维列表 sheet.range("a1:c1").value = [1,2,3] #option:设置transpose参数转置下 sheet.range("a1:a3").options(transpose=True).value = [1,2,3] sheet.range("a1:a3").value = [1,2,3] # 写入二维列表 sheet.range('A1').options(expand='table').value=[[1,2],[3,4]] sheet.range('A1').value=[[1,2],[3,4]] # 也可以直接这样写 ''' 尽量减少与excel交互次数有助于提升写入速度 sheet.range('A1').value = [[1,2],[3,4]] 比sheet.range('A1').value = [1, 2] 和sheet.range('A2').value = [3, 4]会更快 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.5 expand:动态选择Range维度
可以通过单元格的expand或者options的expand属性动态获取excel中单元格维度;两者再使用区别是,使用expand方法,只有在访问范围的值才会计算;options方法会随着单元格值范围扩增而相应的范围增大,区别示例如下:
expand参数值除了’table’,还可以使用‘right’:向右延伸,‘down’:向下延伸;
sheet = xw.sheets.add(name='工作表名称')
sheet.range('a1').value = [[1,2],[3,4]]
# 使用options方法
rng1 = sheet.range('a1').options(expand='table')
# 使用expand方法
rng2 = sheet.range('a1').expand('table') # 默认是table,‘table’参数也可以不填
# 现在新增一行数据
sheet.range('a3').value = [5,6]
print(rng1.value)
# [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]]
print(rng2.value)
# [[1.0, 2.0], [3.0, 4.0]] 使用的expand方法,范围没有扩散
print(sheet.range('a1').options(expand='table').value)
# [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]],再次expand方法访问,值范围扩散
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.6 其他方法
# 引用当前活动工作表的单元格 rng=xw.Range('A1') # 加入超链接 rng.add_hyperlink(r'www.baidu.com','百度',‘提示:点击即链接到百度') # 取得当前range的地址 rng.address rng.get_address() # 清除range的内容 rng.clear_contents() # 清除格式和内容 rng.clear() # 取得range的背景色,以元组形式返回RGB值 rng.color # 设置range的颜色 rng.color=(255,255,255) # 清除range的背景色 rng.color=None # 获得range的第一列列标 rng.column # range的第一行行标 rng.row # 返回range中单元格的数据 rng.count # 获取公式或者输入公式 rng.formula='=SUM(B1:B5)' # 数组公式 rng.formula_array # 获得单元格的绝对地址 rng.get_address(row_absolute=True, column_absolute=True,include_sheetname=False, external=False) # 获得列宽,column_width必须在以下范围内:0 <= column_width <= 255 rng.column_width # 返回range的总宽度 rng.width # 获得range的超链接 rng.hyperlink # 获得range中右下角最后一个单元格 rng.last_cell # range平移 rng.offset(row_offset=0,column_offset=0) # range进行resize改变range的大小 rng.resize(row_size=None,column_size=None) # 行的高度,所有行一样高返回行高,不一样返回None rng.row_height # 返回range的总高度 rng.height # 返回range的行数和列数 rng.shape # 返回range所在的sheet rng.sheet # 返回range的所有行 rng.rows # range的第一行 rng.rows[0] # range的总行数 rng.rows.count # 返回range的所有列 rng.columns # 返回range的第一列 rng.columns[0] # 返回range的列数 rng.columns.count # 所有range的大小自适应 rng.autofit() # 所有列宽度自适应 rng.columns.autofit() # 所有行宽度自适应 rng.rows.autofit() # 从指定的Range对象创建一个合并的单元格。 # cross(bool ,默认为False)– True,将指定范围的每一行中的单元格合并为单独的合并单元格。 rng.api.merge(cross = False) # 返回一个Range对象,该对象表示包含指定单元格的合并Range。如果指定的单元格不在合并范围内,则此属性返回指定的单元格。 # 合并单元格拆分 rng.api.unmerge() # 单元格的格式 rng.number_format = '0.00%'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
6. 转化器
6.1 字典转化
字典转化可以将excel两列数据读取为字典,如果是两行数据,使用transpose转置下;
sheet.range('a1').value = [['a',1],['b',2]]
sheet.range('a1:b2').options(dict).value
# {'a': 1.0, 'b': 2.0}
sheet.range('a4').value = [['a','b'],[1,2]]
sheet.range('a4:b5').options(dict,transpose=True).value
# {'a': 1.0, 'b': 2.0}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
excel工作表值如下:
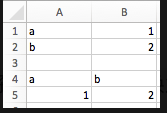
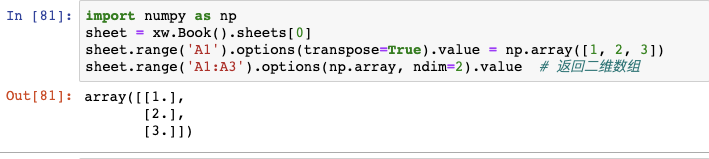
6.2 numpy转化
相关参数:
ndim=None(维度,:1维也可以设置为2转化成二维array),dtype=None(可指定数据类型)
import numpy as np
sheet = xw.Book().sheets[0]
sheet.range('A1').options(transpose=True).value = np.array([1, 2, 3])
sheet.range('A1:A3').options(np.array, ndim=2).value # 返回二维数组
- 1
- 2
- 3
- 4
6.3 Pandas Series与DataFrame转化器
相关参数:
ndim=None,index=1(多列,是否使用第一列为索引),header=True(表头),dtype=None;
DataFrame的表头可以设置为1,2,1等价于True,2表示二维表头;index:0等价与False,1等价于True,第一列设置为索引
# 写入两列数据
sheet.range('a1').values = [['name','age'],['张三',18],['李四',20],['王五',35]]
# index=0,第一列不为索引,读取结果为DataFrom
df = sheet.range('a1').options(pd.Series,expand='table',index=0).value
# index=1,第一列设置为索引,输出为Series
s = sheet.range('a1').options(pd.Series,expand='table',index=1).value
# 写入,不需要索引,index设置为False,保留表头,header=True
sheet.range('d1').options(pd.DataFrame,index=False,header=True).value = df
# 读取为DataFrame
df = sheet.range('a1').options(pd.DataFrame,expand='table',index=0).value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

7. python调用执行VBA代码
第一步:excel文件‘test.xlsm’:vbe窗口创建一个函数,也可以是模块,另见Book.macro;
部分python不好操作的,我们也可以事先在excel文件里植入vba模块代码,结合xlwings一起使用;
Function sum(a,b)
sum = a + b
End Function
- 1
- 2
- 3
第二步:访问调用vba代码
app = xw.App()
app.books.open('test.xlsm')
sum = app.macro('sum')
sum(10,20)
# return: 30
- 1
- 2
- 3
- 4
- 5
8. VBA调用python
xlwings在Windows中提供了访问底层 pywin32 对象的接口,在macOS中提供了访问appscript 对象的接口。
在Windows中,sheet[“A1”].api会返回一个pywin32 对象;在macOS中返回的是appscript 对象。
不同对象,同样一个方法函数名可能不同
在Windows中,大部分时候可以直接在api对象上使用VBA 方法或属性。如果要使用方法,那么一定要在Python 代码中加上圆括号:sheet["A1"].api.ClearFormats()。如果在macOS中操作,因为appscript的语法难以捉摸,处理起来会复杂写。清除单元格格式sheet["A1"].api.clear_formats()。
可以通过内核判断是在macos还是win系统环境下
import sys
if sys.platform.startswith("darwin"):
sheet["A10"].api.clear_formats()
elif sys.platform.startswith("win"):
sheet["A10"].api.ClearFormats()
- 1
- 2
- 3
- 4
- 5

