
docker和linux内核关系,Docker内核调优和Linux内核调优的这些区别你知道么?
赞
踩
作者:汪幸

在传统的虚拟机领域,通过调节一些系统参数来提供(高)系统性能是一种常规手段。例如,对于一个被频繁访问的服务器来说,可以通过设置net.ipv4.ip_local_port_range = 1024 65000(默认32768 61000),来允许系统开放更多的端口。
本文今天讨论的重点不放在对 Linux内核调优的讨论上来,以下链接中关于传统领域内核调优的讨论较为细致,感兴趣的读者可以学习一下:http://colobu.com/2014/09/18/linux-tcpip-tuning/ 。
本文主要通过对比 docker与 linux内核调优的不同,介绍下 docker 容器的内核调优。
Docker内核调优与 Linux内核调优的不同
Docker 允许在启动容器时指定 --sysctl 参数来设置系统参数,通过这些参数来调整系统性能,下面重点说下其与 linux 调整系统参数的不同之处。
总体来说,容器比 linux 可调整项要少,容器的可调整参数需要满足 3个条件:
1.未被 docker限制
Docker 通过一个 ValidateSysctl 函数来限制 sysctl 参数可以传入的项,源码如下:
// docker/opts/opts.go
func ValidateSysctl(val string) (string, error) { validSysctlMap := map[string]bool{ "kernel.msgmax": true, "kernel.msgmnb": true, "kernel.msgmni": true,
"kernel.sem": true,
"kernel.shmall": true,
"kernel.shmmax": true, "kernel.shmmni": true, "kernel.shm_rmid_forced": true,
}
validSysctlPrefixes := []string{
"net.",
"fs.mqueue.",
}
...
也就是说,docker 允许调整的只有上面列出的 kernel.xxx 部分,以及以 net.和 fs.mqueue为前缀的部分,如果试图调整其他项,则会报 whitelist 验证不通过错误:
root@hzwangxing01:~/tmp# docker run -it --sysctl kernel.acpi_video_flags=0 \
hub.c.163.com/public/debian:7.9 bash
invalid argument"kernel.acpi_video_flags=0"for--
sysctl: sysctl'kernel.acpi_video_flags=0'is not whitelisted
2.容器中可以看见该配置项
并不是所有宿主机上可见的配置项,在容器中都是可见的,例如 net.core.rmem_max参数(定义内核用于所有类型的连接的最大接收缓冲大小):
root@hzwangxing01:~/tmp# sysctl -a | grep rmem_max
net.core.rmem_max = 212992
root@hzwangxing01:~/tmp# docker run hub.c.163.com/public/debian:7.9 sysctl -a | grep rmem_max
root@hzwangxing01:~/tmp#
之所以在容器中不可见,与 docker无关,应该是 kernel namespace的 issue。
3.该配置项可以 namespace化
配置项无法 namespace化,指的是该配置项是全局的,无法为每个 namespace生成独立的配置。
一般来说,宿主机和容器是一对多的关系,一个无法 namespace化的配置项,调整之后会影响所有其他容器以及宿主机本身,这是我们无法接受的。
典型的例子就是由于容器共享内核的特性,导致了大多数跟 kernel相关的参数项都无法 namespace化。例如:
root@hzwangxing01:~/tmp# sysctl -a | grep pid_max
kernel.pid_max =32768
root@hzwangxing01:~/tmp# docker run -d --privileged --name test hub.c.163.com/public/debian:7.9
a43e89ee85d36e250e0886331e9d6213094f31260eb9e1539b83f0e9cfc91848
root@hzwangxing01:~/tmp# docker exec test sysctl -w kernel.pid_max=86723
kernel.pid_max = 86723
root@hzwangxing01:~/tmp# sysctl -a | grep pid_max
kernel.pid_max = 86723
从上面的例子可以看出,如果在容器中设置 kernel的 pid_max属性,相应的,宿主机的对应属性也会被修改。
对限制条件组合的详细说明
根据上面列举的三个 docker设置参数的条件,简单的画一个图再展开说明下:
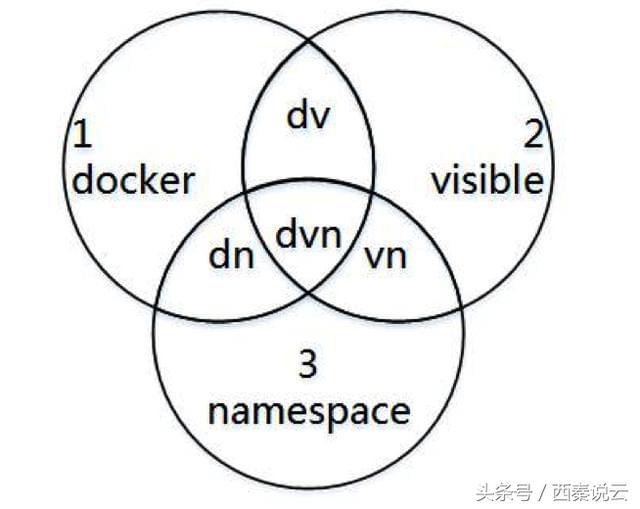
韦氏图
上图是一个简单的韦氏图:
dvn:满足3个条件的属性集,可以通过 --sysctl传入参数设置并达到预期效果
dv(只满足 d和 v,也即 d&&v&&!n):虽然别的条件满足,但无法被 namespace化的属性集,属于无法修复的,除非自己修改内核,打 patch(不推荐)
dn:在容器中不可见,无法通过 --sysctl设置,会报错相关文件找不到root@hzwangxing01:~/tmp# docker run -d --sysctl net.core.rmem_max=1024
hub.c.163.com/public/debian:7.9e2353339b7c9ef52a573d92c0136a20ab7373fc7e06345575cf5efe4cf10256a
docker: Error response from daemon: invalid header field value
"oci runtime error: container_linux.go:247: starting container process caused \"
process_linux.go:359: container init caused \\\"open /proc/sys/net/core/rmem_max: no such file or directory\\\"\"\n".
这类情况也是无法修复的。
vn:这一类是可以修复的,只需要去 docker源码中添加白名单项即可
d、v、n:鉴于无法同时满足“容器中可见”和“可 namespace化”两个条件,这三类也是不可修复的
补充说明
这里需要指出的一点是,可能有人会认为满足条件 d的是经过 docker验证的,同时支持 dvn的,很遗憾,并不是这样。
Docker明确限定的 kernel调节项以及 fs.mqueue前缀项确实是同时符合 dvn的,但是问题主要在于过于宽泛的 net前缀项,这里面就有一些表项不满足 vn,这里不再一一展开说明了。
Docker可配置项
由上面的论述可以得出一个结论,只有 dvn和 vn(需对 docker代码稍作调整)是可以配置的,所以,所有的可配置项包括 dvn+vn,也即 v&&n,其中:
v很容易获得,只需在一个运行中的容器使用 sysctl -a就可以看到所有可见配置项;在 v的基础上,找出可以 namespace化的配置项,方法其实在上面的示例中已经使用过了,这里再强调下:以 privileged权限启动一个容器(确保有权限在容器中设置配置项),在容器中使用 sysctl -w设置某个配置项为不同值,并在宿主机上确认该配置是否变更,如果未发生变更,即说明该项是满足 n的。
通过这两步,即可获得当前环境下的所有容器内核可调优配置集。

