
- 1利用Eigen库实现最小二乘拟合平面_eigen最小二乘拟合直线
- 2如何利用pandas对现有的excel(非CSV)进行追加数据_pandas excel append
- 3最好7B模型再易主!打败700亿LLaMA2,苹果电脑就能跑|开源免费
- 4一篇文章搞懂Docker、DockerCompose_docker和docker-compose
- 5《大学科普丛书》(第一辑)入选2020年度全国优秀科普作品名单
- 6element ui---中文官网_element ui中文官网
- 7第十四届蓝桥杯第三期模拟赛 【python】_蓝桥杯模拟赛第三期python
- 8R语言数据处理——基础篇 data.frame基本操作
- 9微信小程序事件和页面跳转_微信小程序跳转事件
- 10JS、Vue、React阻止事件冒泡及阻止默认事件_react 阻止默认行为
论文浅尝 | ChatKBQA:基于微调大语言模型的知识图谱问答框架
赞
踩

第一作者:罗浩然,北京邮电大学博士研究生,研究方向为知识图谱与大语言模型协同推理
OpenKG地址:http://openkg.cn/tool/bupt-chatkbqa
GitHub地址:https://github.com/LHRLAB/ChatKBQA
论文链接:https://arxiv.org/abs/2310.08975
动机
随着ChatGPT 的问世,属于大模型的时代就此开始。无可否认,大型语言模型(LLMs)如ChatGPT和GPT4在自然语言处理和人工智能领域中展现出了无与伦比的优势,它们凭借“大数据、大算力、强算法”的支持,不仅具有优越的文本生成能力,还拥有深度的语义理解能力。但是,尽管LLMs在这些领域中显示出强大的实力,其操作过程却如同一个不透明的黑箱,具体的决策逻辑难以被跟踪和解释。这就意味着在实际应用中,它可能无法完整、准确地呈现背后的知识体系,同时也有可能产生错误的答案。
另一方面,知识图谱(KGs),例如Wikidata、Freebase和DBpedia,通过图谱结构,显式地呈现了大量事实性知识及其间的关联。这种结构化的方式让人们能够更直观地看到知识的连贯性和丰富性,从而在推理和问答等任务中获得更高的可解释性。但知识图谱规模庞大,创建和维护需要付出巨大努力,并且天然无法使用自然语言进行问答和查询,这无疑增加了其在实际应用中的困难度。
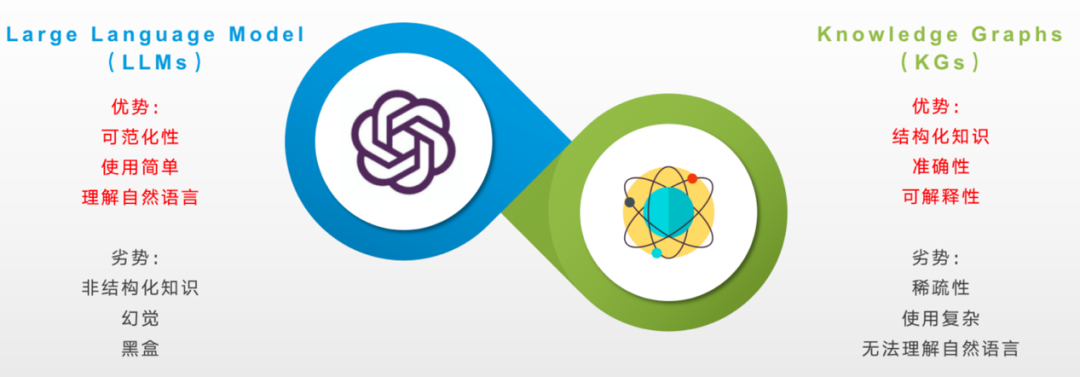
图1.大模型(LLMs)与知识图谱(KGs)优劣势对比
不难发现,大模型所缺少的可解释性以及推理过程和依据正是知识图谱的优势所在,而知识图谱的复杂性和对自然语言的陌生又是大模型旨在解决的问题,那么二者能否相结合从而达到完美互补的效果呢?在这种背景下,ChatKBQA应运而生。
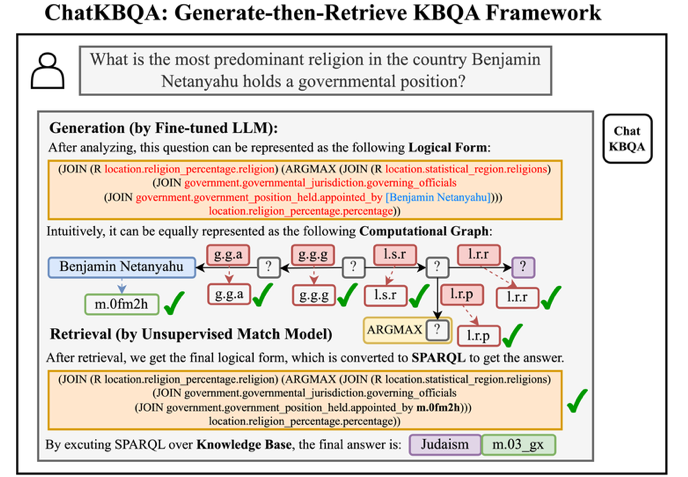
图2.ChatKBQA在给出最终答案以外还给出可解释KG推理路径
ChatKBQA在利用大模型强大的学习能力以及自然语言理解能力的同时,利用知识图谱的准确性和可解释性来弥补了大模型可能的幻觉现象以及本身的黑盒短板,将知识从大模型中解耦出来,实现可解释推理问答的LLM+KG新范式,对医疗、法律等专精垂域知识库上的可解释推理问答提供了新思路。
亮点
(1)通过提出基于大模型的生成-检索知识图谱问答框架ChatKBQA。利用生成再检索代替检索再生成的方式,解决了检索效率低、检索误导生成、KBQA任务解决方案复杂等痛点。
(2)在WebQSP和CWQ两个知识图谱问答基准benchmark上均达到目前的SOTA水平。
(3)首次利用微调大模型生成图数据库查询语言的方式,即GQoT(Graph Query of Thoughts),将图查询作为大模型思考的过程,实现LLM+KG协同驱动的可解释推理问答的新范式。
方法
ChatKBQA是一个使用经过微调的开源大模型的生成-然后检索的知识库问答(KBQA)框架。首先,ChatKBQA框架需要通过指令调整在KBQA数据集中的(自然语言问题,逻辑形式)对来高效微调开源大模型。微调后的大模型用于通过语义解析将新的自然语言问题转化为相应的候选逻辑形式。然后,ChatKBQA在短语级别检索这些逻辑形式中的实体和关系,并在将其转化为SPARQL后搜索可以针对知识库执行的逻辑形式。最后,通过转化获得的SPARQL用于获取最终的答案集,并实现对自然语言问题的可解释和需要知识的回答。下图给出了ChatKBQA 的整体框架描述。
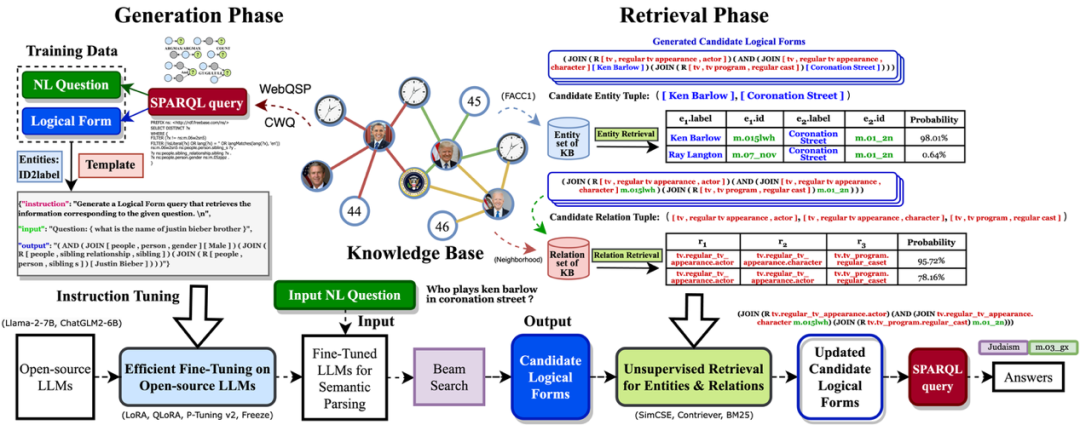
图3.ChatKBQA框架总览
(1)对大模型进行高效微调
为了构建指令微调的训练数据,ChatKBQA首先将KBQA数据集中测试集的自然语言问题对应的SPARQL查询转化为相应的逻辑形式,然后将这些逻辑形式中的实体ID(例如“m.06w2sn5”)替换为相应的实体标签(例如“[Justin Bieber]”),从而使大模型能够更好地理解实体标签,而不是无意义的实体ID。然后,我们将自然语言问题(例如“What is the name of justin bieber brother?”)和处理后的对应逻辑形式(例如“(AND (JOIN [people, person, gender] [Male]) (JOIN (R [people, sibling relationship, sibling]) (JOIN (R [people, person, siblings]) [Justin Bieber])))”)组合成“输入”和“输出”,并添加“指令”为“生成一个逻辑形式查询,检索与给定问题相对应的信息”,构成了针对开源大模型的指令微调训练数据。为了减小对具有大量参数的大模型进行微调的成本,ChatKBQA使用参数高效微调(PEFT)方法(如LoRA、QLoRA、P-tuning v2、Freeze等),仅微调少量模型参数,以实现与完全微调相当的性能。同时,ChatKBQA可以在所有上述高效微调方法以及大模型之间切换,如Llama-2-7B和ChatGLM2-6B。
(2)微调后的大模型进行逻辑形式的生成
经过微调,大模型已经拥有了一定的自然语言问题转化为逻辑形式的语义解析能力。因此,我们使用经过微调的大模型对测试集中的新问题进行语义解析,发现大约63%的样本已经与基准逻辑形式完全相同。当我们使用beam search时,大模型输出的候选逻辑形式列表C中,包含了约74%的样本与基准逻辑形式一致,这表明经过微调的大模型在语义解析任务的学习和解析能力方面表现出色。此外,如果我们将生成的候选逻辑形式中的实体和关系替换为“[]”(例如,“(AND (JOIN [] []) (JOIN (R []) (JOIN (R []) []))”),形成逻辑形式的骨架,那么基准逻辑形式的骨架中出现在候选骨架中的样本比例超过91%。这表明我们只需将逻辑形式中相应位置的实体和关系替换为KB中存在的实体和关系,就可以进一步提高性能。
(3)无监督的实体和关系检索
由于经过微调的LLMs对逻辑形式框架具有良好的生成能力,所以在检索阶段,我们采用一种无监督检索方法,将候选逻辑形式中的实体和关系经过短语级语义检索和替换,以获得最终的逻辑形式,可以转化为可在KB上执行的SPARQL查询。

图4.无监督的逻辑形式中实体关系检索算法
对于给定的查询,无监督检索方法(如SimCSE、Contriever、BM25)无需额外的训练,可以选择语义上与候选集最相似的前k个作为检索到的答案集。
(4)可解释的查询执行
在检索之后,我们获得了最终的候选逻辑形式列表 C′′,然后我们依次遍历 C′′ 中的逻辑形式 F 并将其转换为等效的 SPARQL 查询 q = Convert(F)。当找到可以对知识库 K 进行执行的第一个 q 时,我们执行它以获取最终的答案集 A = Execute(q|K)。通过这种方法,我们还可以基于 SPARQL 查询获得自然语言问题的完整推理路径,具有良好的可解释性。
综上,ChatKBQA提出了一种思考方式,既利用大模型执行自然语言语义解析以生成图查询,又通过调用外部知识库进行可解释的查询推理,我们将其称为“思考的图查询”(GQoT),这是一种有前途的LLM+KG组合范式,可更好地利用外部知识,提高问答的可解释性,避免LLM的幻觉。
实验
数据集:所有实验都在两个标准的KBQA数据集上进行:WebQuestionsSP (WebQSP) ,其中包含4,737个自然语言问题和SPARQL查询,以及ComplexWebQuestions (CWQ),其中包含34,689个自然语言问题和SPARQL查询。这两个数据集都基于Freebase知识库。
基线模型:我们将ChatKBQA与众多KBQA基线方法进行比较,包括KV-Mem ,STAGG,GRAFT-Net ,UHop,Topic Units,TextRay等KBQA方法。
评估指标:与以前的研究一样,我们使用F1分数、Hits@1和准确度(Acc)来表示所有答案和单个排名最高答案的覆盖率,以及精确匹配准确度。
超参数和环境:我们在WebQSP上对LLMs进行了100个epoch的微调,在CWQ上进行了10个epoch的微调,batch size为4,学习率为5e-5。所有实验都在一块NVIDIA A40 GPU(48GB)上完成,结果是从五次随机种子实验中取平均值得出的。
我们回答以下研究问题(RQs):
(RQ1)KBQA实验结果
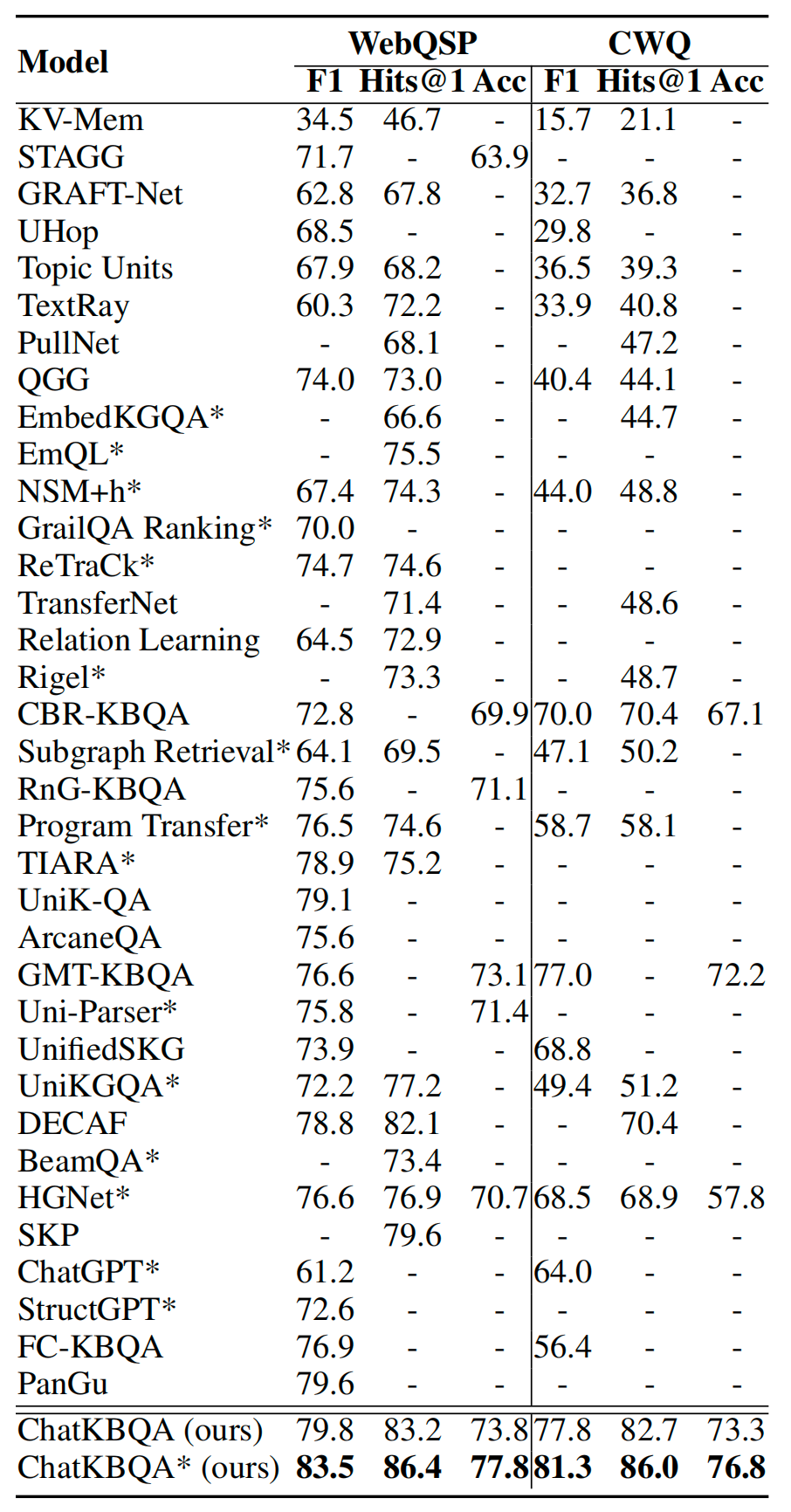
图5.ChatKBQA在CWQ数据集上与其他基线的KBQA结果比较,*表示使用oracle实体链接
在KBQA任务中,上表列出了我们提出的generate-then-retrieve ChatKBQA框架的实验结果,采用了最佳设置,使用Llama-2-7B进行LoRA微调,beam search大小设置为15,以及SimCSE用于无监督检索,以及其他基线模型。我们可以看到,ChatKBQA在WebQSP和CWQ数据集上都明显优于所有现有的KBQA方法。与先前的最佳结果相比,ChatKBQA的F1分数、Hits@1和准确率分别提高了约4个百分点、4个百分点和4个百分点在WebQSP上,CWQ上分别提高了约3个百分点、15个百分点和4个百分点,这反映出ChatKBQA在KBQA任务上具有出色的性能,达到了最新的SOTA性能水平。
(RQ2)消融实验
为了验证ChatKBQA的生成和检索阶段的有效性,我们分别对这两个阶段进行了分离的消融分析。在生成阶段,我们使用了训练数据的20%、40%、60%和80%与完整训练集进行的模型微调相比的效果。如下图(左)所示,随着训练数据量的增加,KBQA的效果也越来越好,证明了微调的有效性。在检索阶段,为了分别验证实体检索(ER)和关系检索(RR),我们从框架中分别去除了ER或RR,并得到了三个简化的变体(ChatKBQA w/o ER,ChatKBQA w/o RR和ChatKBQA w/o ER, RR),然后以不同的beam size进行比较。如下图(右)所示,增加beam size显著提高了效果,ER和RR都对结果有贡献,其中ER的贡献高于RR,因为ChatKBQA w/o RR比ChatKBQA w/o ER要好。
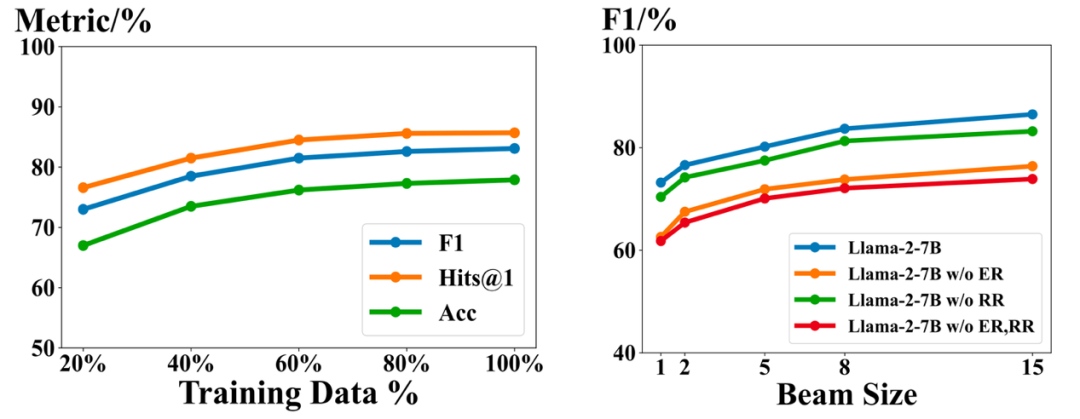
图6.ChatKBQA生成阶段的消融研究(左),ChatKBQA检索阶段的消融研究(右)
(RQ3)生成-检索还是检索-生成
为了验证我们提出的基于大模型的生成然后检索方法是否优于以前的检索然后生成方法,我们采用了在DECAF中设计的指令获取的知识片段,并分别将Top1、Top2、Top5和Top10的检索结果添加到指令中,然后与不进行检索的Llama-2-7B的微调进行比较。如下表所示,我们发现在逻辑形式生成方面,不进行检索优于进行检索,这体现在提取匹配比率(EM)、经过束搜索后的匹配比率(BM)和骨架匹配比率(SM)方面。这是因为检索得到的信息会包含错误的干扰信息,增加指令的最大标记数量,从而导致大模型对原始问题的灾难性遗忘,增加了训练的难度。同时,我们观察到,没有进行检索的Llama-2-7B微调实现了74.7%的BM和91.1%的SM,表现出色,这是因为大模型已经学到了实体和关系的良好模式,为生成后的检索提供了基础。
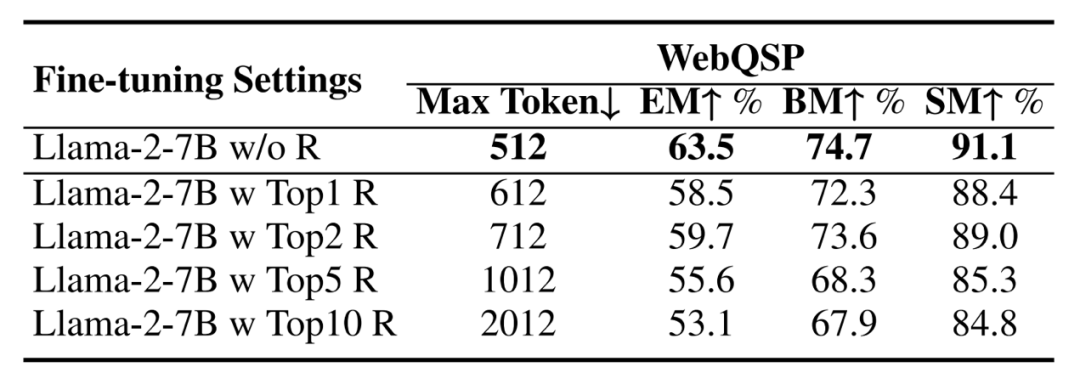
图7.比较在ChatKBQA中微调Llama-2-7B进行逻辑形式生成之前是否使用检索结果
(RQ4)在生成阶段与ChatGPT以及T5的比较
为了说明为什么ChatKBQA选择对开源的生成型大模型进行微调,例如Llama-27B和ChatGLM2-6B,我们分别将生成逻辑形式的大模型替换为ChatGPT、GPT-4、T5和Flan-T5,观察它们的提取匹配(EM)和不使用束搜索的骨架匹配(SM)结果。如下图所示,尽管ChatGPT和GPT-4具有大量的参数,但由于它们不是开源的,无法进行良好的逻辑形式生成。而T5和Flan-T5在经过微调后可以很好地捕获骨架,但EM仅约为10%,远不如Llama-2-7B的63%,因此不能保证后续的无监督实体和关系检索。经过微调的开源大模型,如Llama-2-7B和ChatGLM2-6B,展现出比T5和ChatGPT更强的语义解析能力,可以在EM和SM方面生成质量更高的逻辑形式。
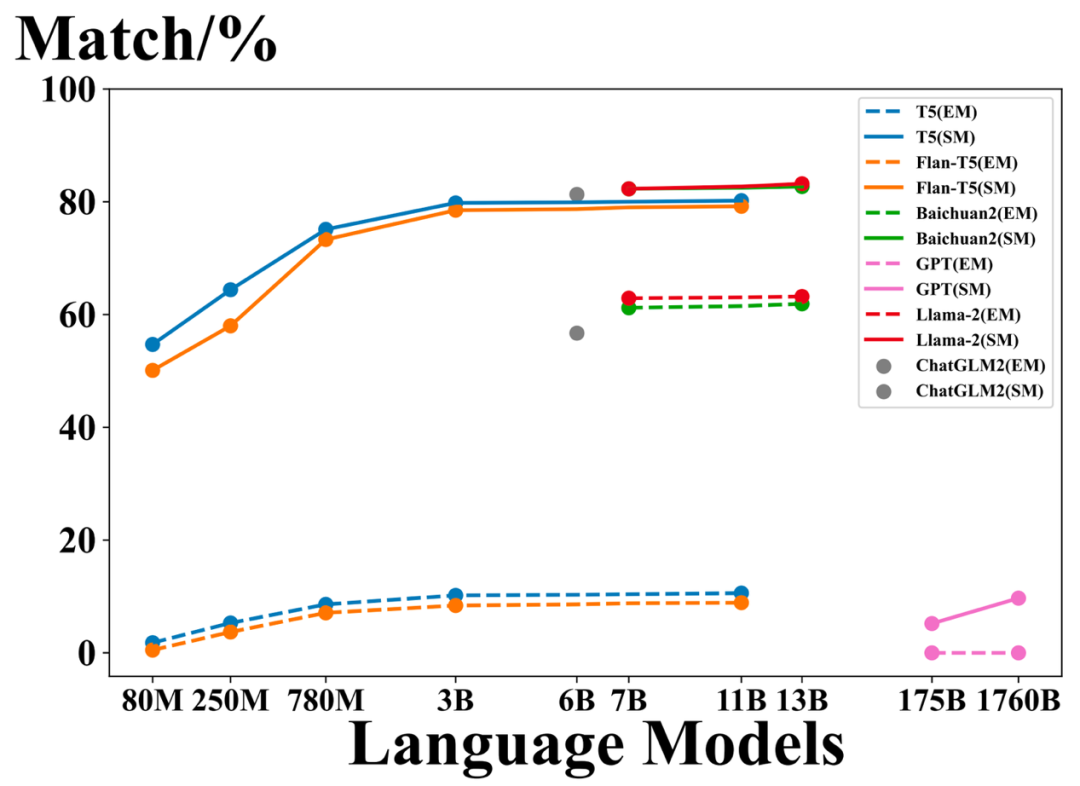
图8.ChatKBQA生成阶段与其他语言模型的比较
(RQ5)检索阶段的效率分析
为了体现生成-然后检索方法如何提高检索效率,我们将逻辑形式生成(AG-R)后的实体检索(ER)和关系检索(RR)与传统从自然语言问题中的检索(NL-R)进行了比较。我们将检索的效率定义为要检索的文本与一组检索答案之间的平均相似度,该相似度范围在[0,1]之间,由不同的检索模型进行评分。需要注意的是,BM25需要进行评分,然后通过映射函数映射到[0,1]范围的相似度。
如下图所示,所有三种检索方法(SimCSE,Contriever和BM25)都认为AG-R比NL-R更有效,对ER和RR来说差距更为显著。这是因为NL-R仍然需要确定实体或关系的位置,而在AG-R中,LLM生成了逻辑形式后,这一步骤已经完成。此外,通常来说,生成的逻辑形式中的关系种类比实体少,而逻辑形式通常可以被直接且准确地预测,而在自然语言问题中,关系通常以隐式方式表示,这使得AG-R在RR上相对于NL-R的效率情况完全不同,这加强了生成-然后检索方法的优势。
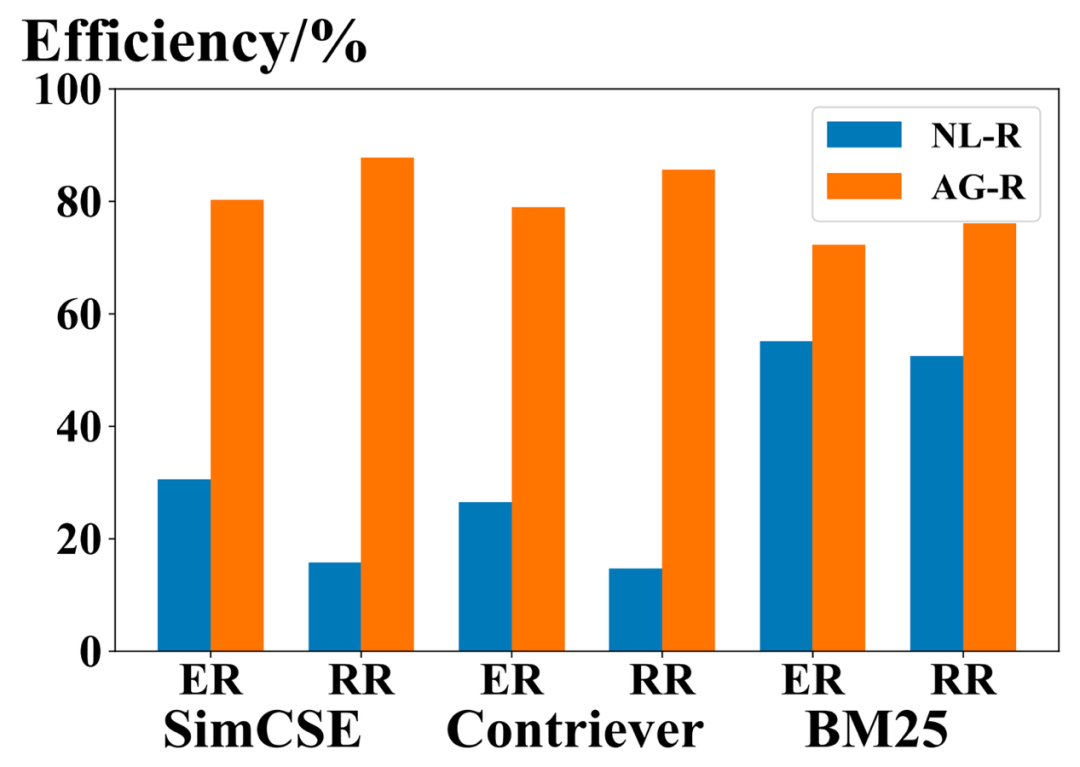
图9.ChatKBQA检索阶段在自然语言问题上(NL-R)与在生成逻辑形式上(AG-R)做检索的效率比较
(RQ6)即插即用的特性
ChatKBQA是一个基于LLMs的KBQA框架,具有即插即用特性,可以灵活替换三个部分:大模型、高效微调方法和无监督检索方法。我们选择Llama-2-13B作为大模型,LoRA作为调整方法,以及SimCSE作为检索方法的基本变种,并将所有变种的beam size设置为8,以在单个A40 GPU上进行比较。我们测试了多种大模型例如Baichuan2-7B、Baichuan2-13B、ChatGLM2-6B、Llama-2-7B,微调方法部分的QLoRA、P-Tuning v2、Freeze,以及检索方法部分的Contriever和BM25。由于ChatKBQA具有即插即用的特性,随着大模型和调整以及检索方法的升级,KBQA任务将变得更好地解决,具有良好的灵活性和可扩展性。
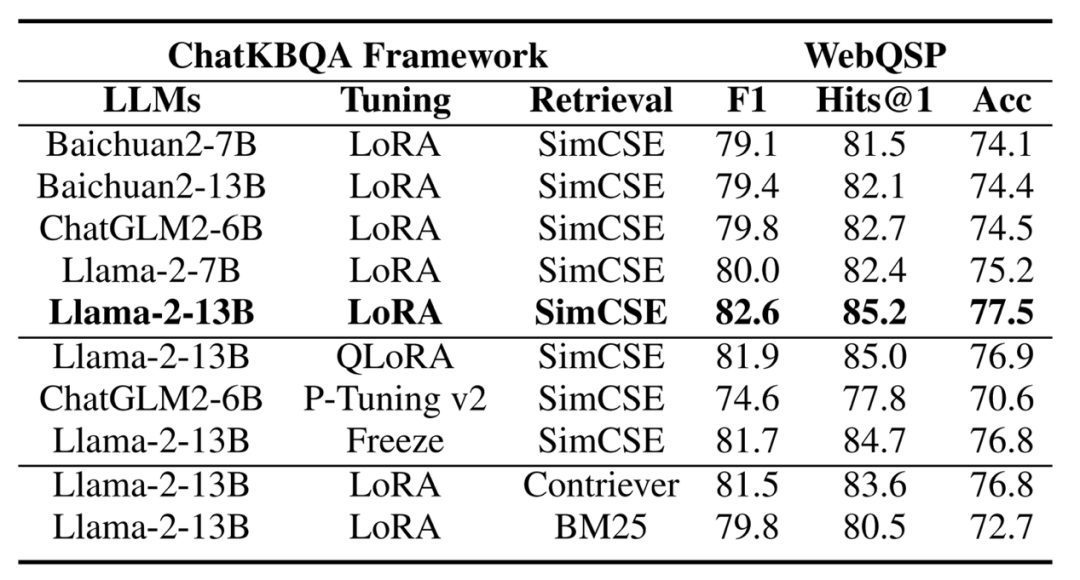
图10.ChatKBQA框架分别替换llm、调优方法和无监督检索方法的即插即用性能比较,beam大小均设为8
总结
在这项工作中,我们提出了ChatKBQA,这是一个基于生成-检索的框架,用于知识库问答(KBQA),充分利用了现代经过微调的大型语言模型(LLMs)的强大能力。通过将重点放在检索之前的逻辑形式生成上,我们的方法与传统方法有了显著的不同,解决了检索效率低和检索错误对经过微调的开源大模型和无监督检索方法的语义解析的误导性影响等固有挑战。我们的实验结果基于两个标准的KBQA基准数据集,WebQSP和CWQ,证实ChatKBQA在KBQA领域取得了新的最佳表现。此外,我们的框架的简单性和灵活性,特别是其即插即用的特性,使其成为将大模型与知识图集成以进行更具解释性和知识要求的问答任务的有前途的方向。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

