
- 1Spring boot集成RocketMQ_springboot集成rocketmq最新
- 2使用jscpd统计项目中的代码重复度
- 3Python生成依赖性应用的DAG(有向无环图)拓扑_随机生成有向无环图python
- 4蓝桥杯python组练题第8天——递增序列(暴力)——蓝桥杯官网题库(国赛)_nnzvlp
- 5树的搜索问题2——分支界限和A*算法(多阶段图问题、人员安排问题和旅行商问题)_a star算法属不属于分支界限算法
- 6AtCoder Beginner Contest 193 C-Unexpressed_at coder 100000 99634
- 7C# 获取QQ会话聊天信息
- 8【漏洞复现-solr-命令执行】vulfocus/solr-cve_2019_17558
- 9封装自己专属的真正的纯净版Windows系统过程记录(2)——使用习惯设置,软件安装与优化设置_ltsc优化设置
- 10Win11 25188.1000补丁包介绍及下载地址_win11大版本升级补丁
复旦大学最新研究:如何让大模型敢回答“我不知道”?
赞
踩
引言:AI助手的真实性挑战
在人工智能(AI)的发展进程中,基于大型语言模型(LLMs)的AI助手已经在多个任务中展现出惊人的性能,例如对话、解决数学问题、编写代码以及使用工具。这些模型拥有丰富的世界知识,但在面对一些知识密集型任务时,比如开放域问答,它们仍然会产生事实错误。AI助手的不真实回答可能在实际应用中造成重大风险。因此,让AI助手拒绝回答它不知道的问题是减少幻觉并保持真实性的关键方法。本文探讨了AI助手是否能够知道它们不知道的内容,并通过自然语言表达这一点。
论文标题:Can AI Assistants Know What They Don’t Know?
论文链接:
https://arxiv.org/pdf/2401.13275.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
AI助手的知识象限:从已知到未知
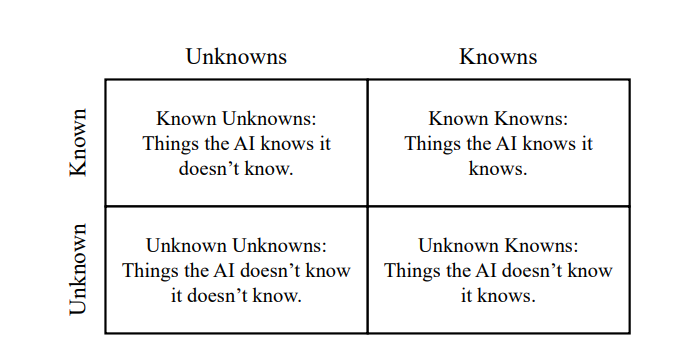
1. 知识象限的定义与重要性
知识象限是一个将知识分为四个类别的模型:已知已知(Known Knowns)、已知未知(Known Unknowns)、未知已知(Unknown Knowns)和未知未知(Unknown Unknowns)。这个概念对于构建真实可靠的AI助手至关重要。已知已知是AI助手的基础,它依赖于自身的知识来提供准确可信的回答。已知未知则代表AI助手意识到自己缺乏某些知识,应当避免给出答案以保持真实性。未知未知和未知已知可能导致不真实和无效的生成,因此,我们需要教会AI助手认识到自己的知识边界,将未知已知和未知未知转化为已知已知和已知未知。
2. AI助手的知识象限分布
AI助手的知识象限分布反映了其对自身知识的感知。大型语言模型(LLMs)拥有广泛的世界知识,但在面对开放领域问题回答等知识密集型任务时,它们仍可能犯错。这些错误可能会对社会造成重大风险,并降低AI助手的可信度。一个与人类价值观一致的AI助手应该是真实的,它需要提供与现实世界一致的准确信息。为了实现这一目标,我们需要让AI助手知道自己知道什么和不知道什么,并通过自然语言表达出来。
构建Idk数据集:让AI认识自己的知识边界
1. Idk数据集的构建过程
Idk数据集的构建基于现有的开放领域问题回答数据集,如TriviaQA。我们通过评估AI助手对某个问题的多次回答的平均准确性来确定它是否知道答案。如果AI助手多次回答某个问题错误,则将该问题标记为它不知道的问题,并注释一个拒绝回答的模板。对于AI助手多次回答正确的问题,使用它生成的正确答案作为注释的答案。AI助手被认为知道问题答案的准确性阈值是一个超参数,我们称之为Ik阈值。
2. 不同Ik阈值对Idk数据集的影响
Ik阈值用于定义AI助手知道和不知道问题的标准。不同的Ik阈值会导致不同的Idk数据集。一个高的Ik阈值意味着AI助手只有在非常有把握的情况下才会回答问题,而一个低的Ik阈值则允许AI助手在较低的把握下回答问题。换句话说,高的Ik阈值代表一种保守的回答策略,而低的Ik阈值代表一种更积极的回答策略。在我们的工作中,我们采样了每个问题的十个回答,并基于不同的准确率得出了十个离散的Ik阈值。为了简单起见,我们将Ik阈值设置为1.0,这意味着只有当AI助手的十个回答都是正确的时候,它才被认为知道问题的答案。除非特别说明,此后提到的Idk数据集都是基于Ik阈值为1.0构建的。
教会AI助手说“我不知道”:方法与实验
1. Idk提示方法(Idk-Prompting)
Idk提示方法(Idk-Prompting)是一种直接通过提示来指导AI助手拒绝回答它不知道的问题的方法。这种方法要求模型具有较高的指令遵循能力,但优点在于它无需额外的训练。在这种方法中,我们在输入问题前添加一个Idk提示,例如:“回答以下问题,如果你不知道答案,请只回复‘我不知道’”。然而,对于那些缺乏遵循指令能力的预训练模型,Idk-Prompting可能无法取得满意的结果。
2. 监督式微调(Supervised Fine-tuning)
监督式微调(Supervised Fine-tuning,简称SFT)是一种简单而有效的对齐方法。我们直接使用Idk数据集对模型进行监督式微调。由于Idk数据集包含了问题和回答,这构成了一个条件生成任务。我们将问题输入模型,并要求模型预测回答。我们执行标准的序列到序列损失来训练我们的模型。SFT的细节在附录B.1中有展示。
3. 偏好感知优化(Preference-aware Optimization)
在这一部分,我们介绍了如何进行偏好感知优化,以帮助模型更好地感知其内部知识。直接偏好优化(Direct Preference Optimization,简称DPO)首先在Idk数据集的一半上训练一个SFT模型作为热身,然后我们在Idk数据集的另一半上收集这个SFT模型的回答。对于给定的问题,我们进行随机采样以收集多个回答。最后,我们基于这些生成的回答构建偏好数据。除了原始的DPO损失,我们还为选定的回答加入了SFT损失,并乘以一个系数α。DPO的细节在附录B.2中有展示。
实验结果:AI助手的知识自觉性提升
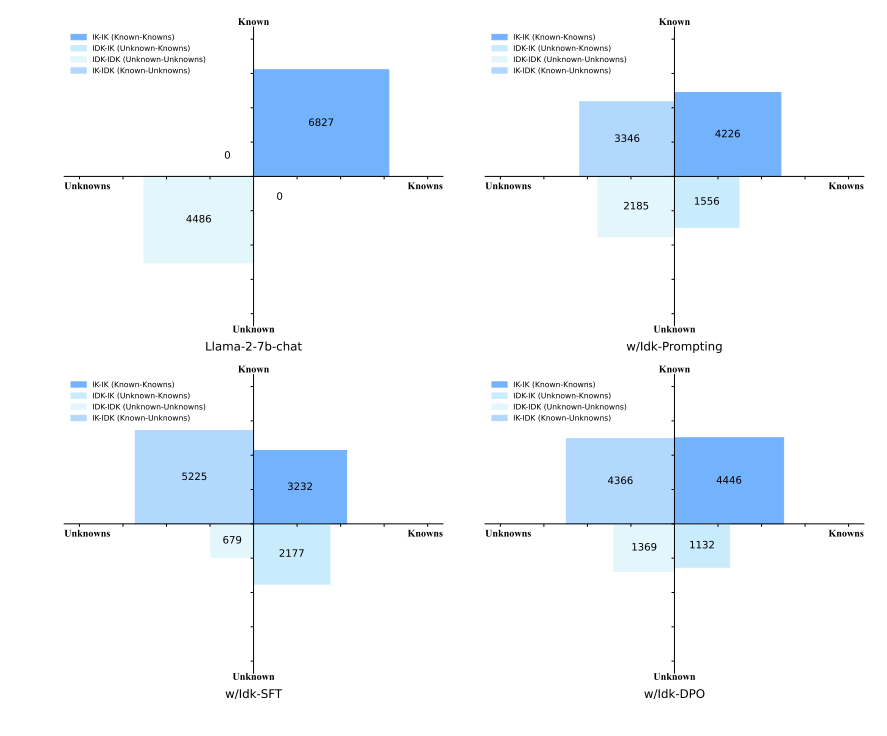
1. Idk数据集上的实验结果
在Idk数据集的测试集上进行实验,结果表明,经过与Idk数据集对齐后的AI助手能够拒绝回答大多数它不知道的问题。对于它尝试回答的问题,准确率显著高于对齐前。Idk提示方法能在一定程度上有效,但仍有许多IDK-IK和IDK-IDK问题。使用Idk数据集进行监督式微调后,IDK-IK和IDK-IDK的数量显著减少,表明模型意识到自己知识的能力得到了增强。相比于SFT模型,偏好感知优化(如DPO)可以减轻模型错误拒绝回答它知道的问题的现象。
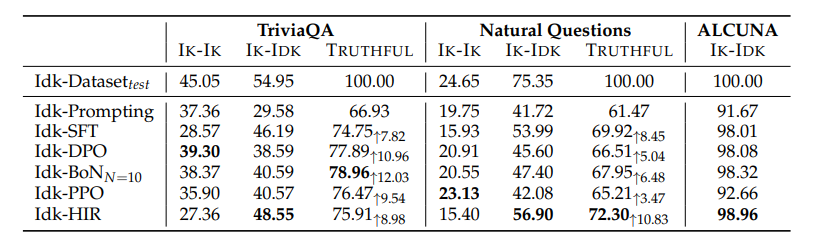
2. 超出分布数据(OOD)上的表现
在超出分布(Out-of-Distribution,简称OOD)数据上的测试表明,对齐后的模型在面对OOD数据时也能够拒绝回答它不知道的问题。在Natural Questions数据集上构建的Idk测试集上,模型在所有指标上都有所提升。与TriviaQA的结果相比,Idk-HIR在Natural Questions上实现了最高的TRUTHFUL率,而不是Idk-BoN。此外,使用偏好优化方法对齐的模型在TRUTHFUL率上有所降低,这可能是因为偏好优化鼓励模型回答更多问题。在ALCUNA上构建的Idk数据集中,提示方法已经能够使模型拒绝回答大多数无法回答的问题。在与TriviaQA对齐后的模型在Natural Questions上展示了高TRUTHFUL率,在ALCUNA上展示了高IK-IDK率,这表明模型拒绝回答未知问题的行为可以泛化到OOD数据。
影响因素分析:模型大小、数据源和Ik阈值
在探索AI助手对其知识边界的认知时,我们关注了几个关键因素:模型大小、数据源和Ik阈值。这些因素对AI助手的行为和输出结果有着显著影响。
1. 模型大小对结果的影响
模型大小是影响AI助手性能的重要因素。实验结果表明,更大的模型(如Llama-2-70b-chat)在识别其所知和所不知的问题方面更为娴熟,相较于较小的模型(如Llama-2-7b-chat),在IK-IK和IK-IDK问题的总数上有5.8%的提升。这表明,随着模型参数的增加,模型的知识储备更为丰富,能够更准确地判断自己的知识边界。
2. 使用非模型特定Idk数据集的影响
在构建Idk数据集时,使用与模型预训练过程不同的数据源可能会影响模型的行为。例如,使用Mistral-7B-Instruct-v0.1和Baichuan2-7B-chat构建的非模型特定Idk数据集在训练后的模型中,导致TRUTHFUL率下降。这种下降主要是由于模型倾向于拒绝回答更多的问题,从而减少了IK-IK问题的比例。这一现象强调了构建模型特定Idk数据集的重要性,以便模型能够学会拒绝回答它不知道的问题。
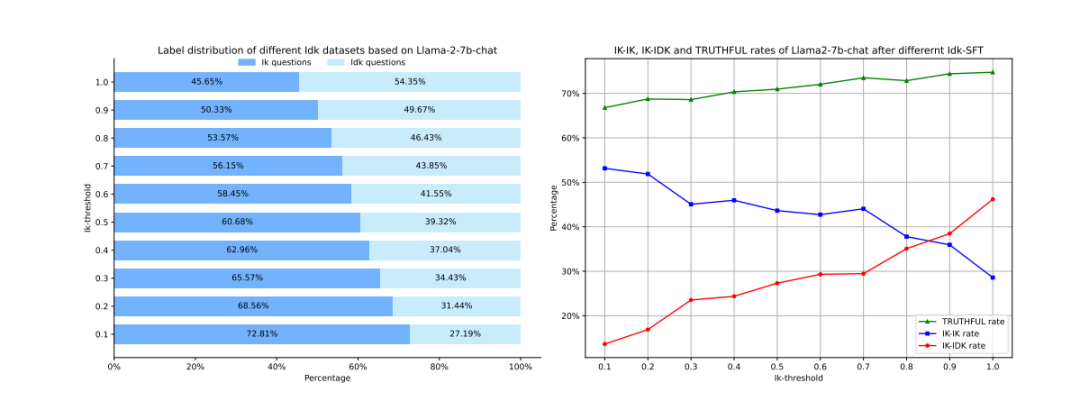
3. 不同Ik阈值的实验结果
Ik阈值是决定模型是否知道某个问题答案的置信度标准。不同的Ik阈值会导致不同的Idk数据集标签分布。较高的Ik阈值意味着模型只在非常确定的情况下才回答问题,这导致模型更加保守,但同时也提高了模型的真实性。相反,较低的Ik阈值允许模型在较低的置信度下回答问题,使得模型更加乐于提供帮助。实验表明,提高Ik阈值可以提高模型的TRUTHFUL率,使其在识别已知和未知问题方面更为准确。
总结与展望:朝向更真实的AI助手迈进
我们的研究表明,通过与特定于模型的“I don’t know”(Idk)数据集对齐,AI助手能够在一定程度上意识到它所不知道的内容。在开放领域问答测试集中,AI助手能够明确指出它知道或不知道答案的问题,拒绝回答它不知道的问题,达到了78.96%的准确率。为了实现这一目标,我们采用了多种方法,包括提示、监督式微调和偏好感知优化,来利用Idk数据集进行对齐。此外,我们还进行了广泛的实验,探索了数据源、模型大小和确定模型是否知道某个问题的Ik阈值的影响。AI助手拒绝回答超出其知识范围的问题,可以减少事实错误。我们认为这是真实AI助手的一个重要行为。展望未来,我们期待开发出更真实、更可靠的AI助手,这些助手不仅能够提供准确信息,还能清楚地表达其知识的局限性,从而在实际应用中降低风险并提高用户信任。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。


