
- 1前端程序员辞掉朝九晚五工作成为独立开发者一年开发出6款软件的故事_程序员卖自己开发软件
- 2postman使用教程_postman设置utf 8编码
- 314:00面试,14:06就出来了,问的问题有点变态。。。
- 4常用的测试组织架构模型_企业测试结构
- 5AI - AI绘画的精准控图(ControlNet)
- 6ConvLSTM时空预测实战代码详解
- 7解决numpy.linalg.LinAlgError: singular matrix
- 8Flink 输出至 Elasticsearch
- 9HTML小游戏13 —— 仿《神庙逃亡》3D风格跑酷游戏《墓地逃亡》(附完整源码)_html神庙逃亡制作代码
- 10将网页数据读入数据库+将数据库数据读出到网页——基于python flask实现网页与数据库的交互连接【全网最全】_flask查询数据库并在网页显示
unity性能优化部分_unity 模型优化
赞
踩
【Unity技巧】Unity中的优化技术_妈妈说女孩子要自立自强的博客-CSDN博客_unity优化模型
Unity优化技巧(中) - 知乎
Unity优化技巧(下) - 知乎
一、优化方向
1、顶点优化
(1)优化几何体:尽可能减少模型中三角形的数目,尽可能重用顶点
(2)使用LOD(Level of detail)技术
unityLOD优化技术详解_丶博Liang的博客-CSDN博客_lod优化
(3)使用遮挡剔除(Occlusion culling)技术
2、像素优化
(1)像素优化的重点在于减少overdraw。overdraw指的就是一个像素被绘制了多次。关键在于控制绘制顺序。
绘制透明物体我们应该尽量从前往后绘制。从前往后绘制之所以可以减少overdraw,都是因为深度检验的功劳。
在Unity中,那些Shader中被设置为“Geometry” 队列的对象总是从前往后绘制的,而其他固定队列(如“Transparent”“Overla”等)的物体,则都是从后往前绘制的。例如,对于天空盒子来说,它几乎覆盖了所有的像素,而且我们知道它永远会在所有物体的后面,因此它的队列可以设置为“Geometry+1”。
(2)我们可以把GUI绘制和三维场景的绘制交给不同的摄像机,而其中负责三维场景的摄像机的视角范围尽量不要和GUI重叠。
(3)减少实时光照:一个场景里如果包含了三个逐像素的点光源,而且使用了逐像素的shader,那么很有可能将Draw Calls提高了三倍,同时也会增加overdraws。逐像素的光源,被这些光源照亮的物体要被再渲染一次。更糟糕的是,无论是动态批处理还是动态批处理,对于这种逐像素的pass都无法进行批处理,也就是说,它们会中断批处理。
(4)使用Lightmaps
提前把场景中的光照信息存储在一张光照纹理中,然后在运行时刻只需要根据纹理采样得到光照信息即可。
3、CPU优化
减少Draw Calls
(1)批处理(Batching):对于使用同一个材质的物体,它们之间的不同仅仅在于顶点数据的差别,即使用的网格不同而已。我们可以把这些顶点数据合并在一起,再一起发送给GPU,就可以完成一次批处理。
unity进行动态批处理的条件是,物体使用同一个材质并且满足一些特定条件,顶点不能超过900,xyz缩放要统一,使用lightmap的物体不会批处理,多pass的shader会中断批处理,接受实时阴影的也不会。
静态批处理:“Static Flag”勾选上,点击Static后面的三角下拉框,我们会看到其实这一步设置了很多东西,这里我们想要的只是“Batching static”。如果在静态批处理前有一些物体共享了相同的网格(例如两个相同的箱子),那么每一个物体都会有一个该网格的复制品,即一个网格会变成多个网格被发送给GPU,缺点是占用更多内存。
(2)合并纹理(Atlas):尽可能把多张小纹理合并到一张大纹理(Atlas)中
4、带宽优化
(1)减少纹理大小,调整参数可以通过纹理的Advance面板,和优化相关的主要有“Generate Mip Maps”、“Max Size”和“Format”几个选项。
“Generate Mip Maps”会为同一张纹理创建出很多不同大小的小纹理,构成一个纹理金字塔。而在游戏中可以根据距离物体的远近,来动态选择使用哪一个纹理,因此它会需要占用更多的内存。
“Max Size”决定了纹理的长宽值,如果我们使用的纹理本身超过了这个最大值,Unity会对其进行缩小来满足这个条件。
“Format”负责纹理使用的压缩模式。通常选择这种自动模式就可以了,Unity会负责根据不同的平台来选择合适的压缩模式。
二、优化细节
1、LOD,代码只在必要时才会运行
屏幕外的角色不计算动画更新,不计算技能效果冒字血条等,屏幕外的角色休眠,只有主角才会冒字等等。
2、限帧,负载均衡
根据玩家机型进行限帧
3、算法
一些代码本身的运算。例如优化物理运算,空间换时间使用查表预计算等方式对计算提速,减少频繁索引FindGetComponentd以及各种运算
4、Unity接口
尽量少使用GetComponent,AddComponent(还会产生GC),Find等操作
OnGUI,FixedUpdate,Update等空函数也会有gc开销,因为会产生从C++到C#层调用的开销。
MainCamera是一个遍历操作Camera比较多的时候不要频繁调用。
position和rotation同时修改的时候,使用SetPositionAndRotation()方法一次性设置。
5、物理
优化方面可以通过分层减少碰撞对,尽量使用BoxCollider而不是MeshCollider,UI界面不需要点击的控件不要打开Raycaster。使用最基本的射线检测。
6、IL2CPP & C++
把Unity编译设置成IL2CPP,编译成C++版运行效率会有较大提升。
7、动画
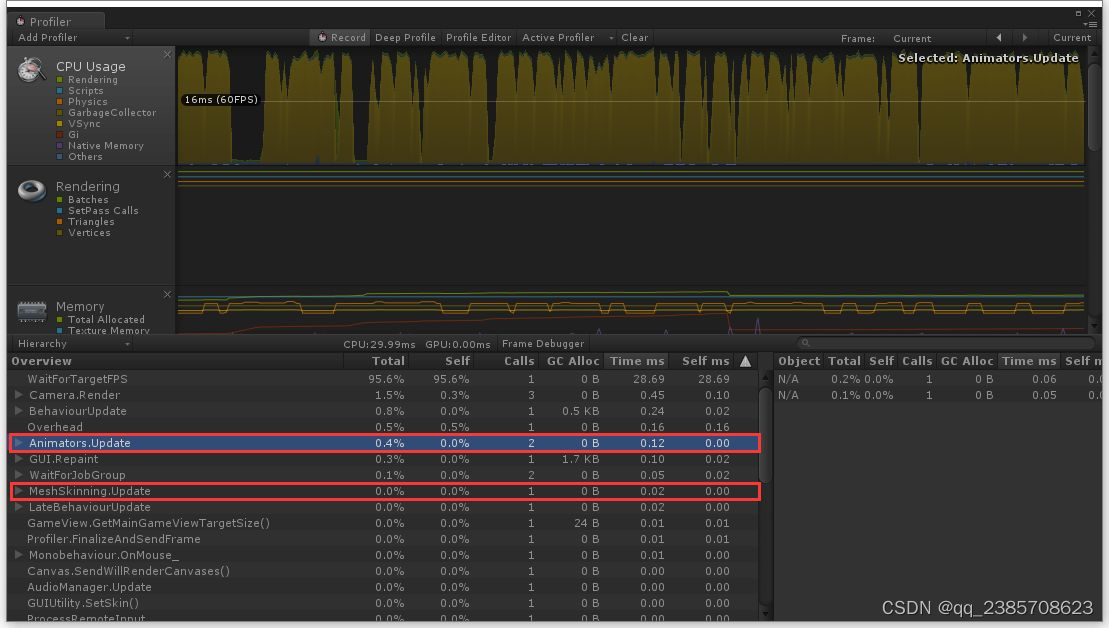
Prifile中发现Animator.Update或者MeshSkinning.Udpate开销比较大就说明动作可能需要优化
优化:
(1)打开Optimize
GameObject,可以把一些无效的节点骨骼去掉,注意如果有自定义的节点需要拖到不被优化列表里。
(2)压缩:
打开KeyframeReduction,可以压缩很多不必要的关键帧,这个值越大压缩比率越高失真越严重。
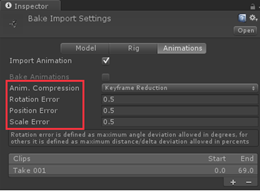
(3) BoneWeights:
顶点受骨骼影响,对要求不高的环境可能一个骨骼就够了。可以每个模型设置,也可以实时全局改变。
(4)BakeMesh:
对于同屏需要显示大量模型可以使用SkinnedMeshRenderer.BakeMesh,把动画烘成模型,这样在渲染的时候可以合并(带动画不能合并)。可以大幅减少DC,省去蒙皮计算,不过缺点是内存增大,增加DynamicBatching的CPU开销,表现会差一些。
(5)不使用Animator:
Animator的开销比Animaton比一个量级。
(6)不可见不更新设置CullCompletely
但是需要注意一些消息也会停掉如果对动画有依赖会出问题。
(7)骨骼LOD,GPU Skinning(有些设备和情况会更慢),使用Bone代替CS等等。
8、UI
UI也是个开销大头,一般会占到30%-50%。UGUI对应Profile中Canvas.BuildBatch &
Canvas.SendWillRenderCanvases开销,类似NGUI的LastUpdate,UI的优化又很多文章这里也简单列举一下。
(1)、动态静态分离:
因为UI会合并。NGUI是按Panel进行重建的、UGUI是按Canvas进行重建的,防止动态UI触发合并导致静态UI也一起合并。
(2)、预加载,常驻,即时释放:
UI按类型划分,比较大的常用的UI在创建的时候会卡顿,可以进行预加载。主城到战斗场景,在保证峰值内存的情况下,将英雄界面工会界面等常驻内存,可加快Loading速度,实测优化后提升一倍以上loading速度。其他不常用界面拆分成小界面,使用即时加载,关闭时卸载节省内存。需要注意的是,UI节点过多也会导致加载缓慢,我们曾经Loading要10秒,其中序列化UI占了一半左右的时间(贴图预先加载测试),减少UI节点数,太大了拆开。
(3)、图集
合理拆分UI图集,区分公共图集(常驻)和非公共图集。太大容易造成冗余加载,容易导致内存占用过大,导致内存显存交换开销。太小有容易导致显存碎片影响效率。规则很复杂。
(4)、内存池
UI冒字等频繁创建的UI使用内存池减少创建的时间和内存碎片。
(5)、Active/Deactive
不推荐通过Active/Deactive来频繁切换UI界面,因为会触发UI合并操作,可以通过移到屏幕外的做法或者设置Layer。但需要注意移到屏幕外还是会被合并渲染,如果是长时间不显示的还是Deactive比较好需要视情况而定。
(6)、UISprite来代替UITexture:Texture不会合并。
(7)、不移动不可见的UI不更新:例如血条名字等。
(8)、layout group, canvas group组件,任何子节点变了父节点都会用getcompent找到laygroup。这是Unity的UGUI的两大坑。
(9)、检查不需要拾取的Raycast target是否关了。
(10)、资源预加载:例如前面介绍的UI预加载,内存允许的情况下所有资源都应该预加载,结合内存池。我们游戏中所有变现逻辑,角色,怪物,道具,UI都会做预加载,并且有一套池膨胀和回收的策略。
(11)、Shader预加载。
9、GC
GC是一个非常高开销的系统调用,也是大部分卡顿的主要原因,不能完全控制。因此我们要尽量减少代码堆内存分配过量防止频繁触发GC,同时也可以在Loading或者对性能不敏感的时候主动GC。
(1)、使用StringBuilder代替string减少GC开销,不要使用富文本改变Text组件的颜色直接通过修改Text组件颜色来改。
(2)、类对象的内存池。所有频繁反复创建删除的都应该使用。两个用途,减少加载创建释放的时间,减少内存碎片降低GC的频率。
(3)、Unity接口:AddComponent,OnGUI,UI合并频率,delegate,等(一些Foreach,协程等Unity已经优化)
(4)、插件的GC优化:对行为树,FMODStudio等一些插件的源码进行了修改减少GC
三、GPU优化
(1)、DrawCall的优化一般都是材质mesh合并,所以放到了GPU的部分。渲染一次拥有一个网格并携带一种材质的物体便会使用一次Draw Call。可以理解为调用一次DC就换一种画笔在画板上画一个物体。
(2)、面数
整个场景少于10个DC,由美术或插件合并输出。静态合并会增加Loading时间和内存,动态合并也会增加内存和合并CPU开销。
(3)、LOD
对GPU的优化也可以通过LOD进行,可以通过模型LOD,骨骼LOD,粒子LOD,材质LOD的方式,地形LOD等等,例如不同配置开启不同的效果,开启后处理等。
(4)、遮挡
遮挡剔除:顾名思义就是被遮挡看不见的地方不渲染,例如墙后的物体。遮挡剔除可以CPU计算也可以GPU计算。
UI遮挡:例如全屏UI可以隐藏背景,节省电量。
场景拆分:我们因为是俯视角,能遮挡的东西很少,只是采取了场景分割。
(5)、半透明
半透明开销巨大,还会破化渲染管线的优化,使用alpha通道的贴图压缩也很困难,(特别是IOS上的PVR格式Alpha像素压缩之后损失巨大,ETC,DDS,PVR等格式Alpha一个通道的压缩比就等于其他3个通道了)。
少用/减小面积:尽量少用,要用尽量减少占用屏幕的面积,减少像素填充率。
(6)、粒子
减小屏幕覆盖面积、避免使用Alpha、合并材质和mesh、LOD=根据机型或者距离降低粒子发射器的个数和效果、序列帧:对一些俯视角游戏使用序列帧做特效也能大幅提升效率。
(7)、其它
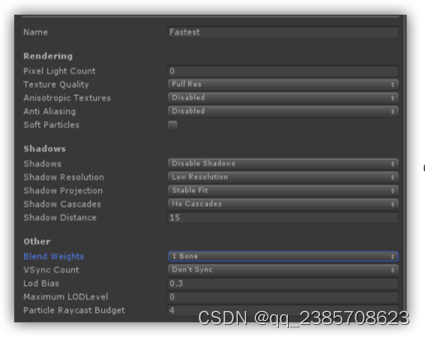
- 渲染设置:阴影,雾,抗拒齿,垂直同步,各项异性,多线程渲染,GPU计算骨架,顶点受骨骼影响,软粒子等等。每个项目要求不同。
- 降低渲染的分辨率:缩小Framebuff分辨率,减少ps开销和内存显存,但是会模糊,王者荣耀等很多主流游戏在Android上都降了分辨率。
- 智能动态调节:根据玩家配置和游戏环境实时调整配置,低配设备或者战斗降低配置进行限帧,高配插电或者低开销场景,动态提升配置,提高限帧。有一篇文档有更详细的介绍。
- 后处理:Unity里可以通过看Graphics.Blit性能了解后处理的开销。后处理一般是像素级别的计算,手机设备上分辨率有普遍比pc高,使用的时候更需要注意。
- 不使用多维子材质材质。
四、内存优化
1、压缩贴图ETC/PVR:贴图是占用资源最大的部分。我对3D贴图基本上都会压缩,2DUI贴图部分压缩。在Android上尽量使用ETC格式,IOS上使用pvr格式,非半透有1/8的压缩比。这两种压缩格式类似DX的dds,可以直接被显卡渲染,即降低内存又能减少包大小,提升加载速度(JPG等格式虽然压缩比高但是需要解压成32位色再渲染,增加加了内存和显存还有额外的解压开销)。需要注意以下几点:
(1)如果压缩效果不好还可以减成16位色。
(2)关Mipmap:UI或者俯视角游戏不需要Mipmap可以关闭减小1/3的体积
(3)如果使用ETC,PVR压缩贴图必须是2的幂,处于渲染效率和显存碎片的考虑贴图的大小建议最大1024,最小64,最大不能超过2048。
(4)使用九宫,对称贴图:提高贴图复用率
(5)、Shader:利用Shader合并贴图通道,实现灰度图等。Alpha通道存alphatest和高光,贴图一个通道存阴影一个通道存ao等,alpha通道存在贴图的其他通道便于压缩等等。这点在做轩辕传奇的时候大幅使用。
(6)压缩动画减少关键帧:前面有介绍
(7)及时卸载:在进出场景时,或者打开UI界面等对性能不敏感的时候,卸载资源并调用Resource.UnloadAsset清理引用资源和destroy,System.GC.Collect清理系统资源,前面有介绍。AssetBundle加载时生成、卸载时销毁,这也是比较大的一个坑:)
(8)在代码级别上避免不必要的堆内存分配:可以通过静态代码分析检查,另有一篇文章详细介绍。
(9)避免频繁New Class:使用内存池。
(10)String连接:减少字符串拼接,使用StringBuilder等等。
(11)delegate:因为内部的链表和装箱拆箱操作,使用频率较高时GC也很高。
(12)合理的使用Lambda表达式:例如Unity的粒子系统5.6版本以前GC较高就是这个原因。
(13)频繁的临时变量或者list生成,建议定义一个全局的list每次都用该list来计算。
(14)需要注意的是类申请在堆上,结构申请在栈上,有时可以使用结构。
(15)内存泄露: Unity是基于引用计数的,一般内存泄漏是资源被Hold住无法释放,内存增长趋势明显、反复切换场景内存膨胀。针对这种情况可以自己写工具输出每个场景的资源日志。也可以使用XCode分析一段时间的内存。
(16)表数据。表一般不会卸载。建议使用二进制反序列化使用不要直接使用字符串,并且不在内存中做多份缓存,表数据非常巨大的情况下可以考虑使用完删除。
(17)冗余顶点数据:UI贴图Mesh把color,normal等不适用都导出,静态合并会导致内存增大。
(18)抗锯齿/Rendertexture:开了抗锯齿会增大内存,高分辨率会增大内存,后期处理可以交换使用Rendertexture不要创建多份。
(19)GameObject数量:小于1w,节点书过多也会导致加载更新缓慢内存膨胀
四、闪存
具体表现在包大小,资源加载速度等。闪存的优化和内存大部分共同,但是也有例外,例如使用jpg就是减少包大小增大内存消耗CPU的方法。压缩和内存一样。贴图,动画,导表等等。
(1)在移动平台上可以打开code strip功能来减少代码带来的内存和容量消耗。对于使用了反射的类,可以使用link.xml配置解决。code strip是Unity提供的一个优化功能,他会预判断代码的执行路径,将没有使用的函数去掉。

(2)部分SDK很大,可以和第三方协商减少重复包含的库。
(3)l2cpp 中会包含 ARMv7 和 ARM64 位两个版本的代码,因此,会有两份代码的体积。
(4)动态下载:类似微端。但在手机上并不推荐,可能会导致使用玩家流量。
(5)冗余资源:导出包的时候利用插件或者自己写的工具分析资源。
(6)贴图mesh动态生成:对于一些规则画贴图和模型可以通过计算生成出来,例如以前使用过的著名的substance,还有之前端游优化地形的时候只保存地形的高度,通过多留的方式在GPU中还原成地形信息,可以减少1/3等等。
五、网络
1、减小包体和压缩:在二进制上进行一些重用和合并减小包体,对协议包做压缩。
2、合包:按一定频率进行合包操作,把几个包合并在一起降低发送频率,减小包头。
六、耗电
1、CPG,GPU优化,网络优化,
2、限帧,手游一般会限帧30帧。
3、降低画质和效果,降低更新频率和LOD等

