
- 1CF1038E Maximum Matching_e. maximum matching
- 2lstm预测模型_Python实现多变量序列堆叠式LSTM模型,并实现未来多时刻预测
- 3计算机网络 网络层_ip地址转物理地址
- 4微软TTS延迟因素分析
- 5超赞的kafka可视化客户端工具,让你嗨皮起来_kafka可视化客户端界面
- 6Vector | Graph:蚂蚁首个开源 Graph RAG 框架设计解读_ai 知识图谱 开源
- 7前端代码规范-2分钟教会你在nodejs中使用eslint定制团队代码规范_nodejs eslint
- 8Transformers 4.37 中文文档(九)_huggenface trainer
- 9中国碳纤维市场现状调研与投资前景预测分析报告2022-2028年_中国碳纤维行业十四五前景预测与发展规划分析报告2023-2028年版
- 102024年中小企业数据安全如何保障?对比华为云与其他云计算大厂_阿里云的waf和华为云
Coze插件发布!PDF转Markdown功能便捷集成,打造你的专属智能体
赞
踩

近日,TextIn开发的PDF转Markdown插件正式上架Coze。
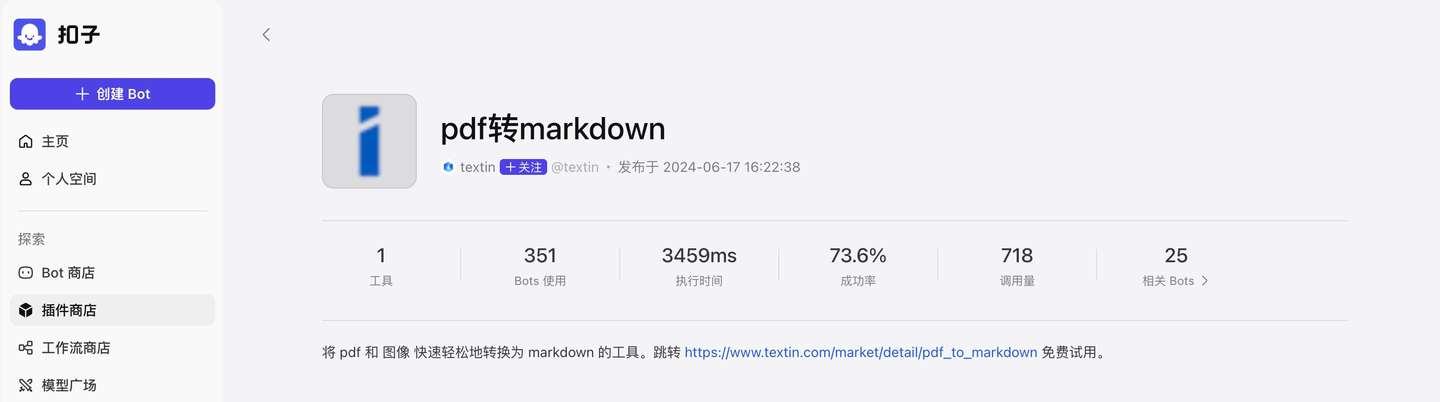
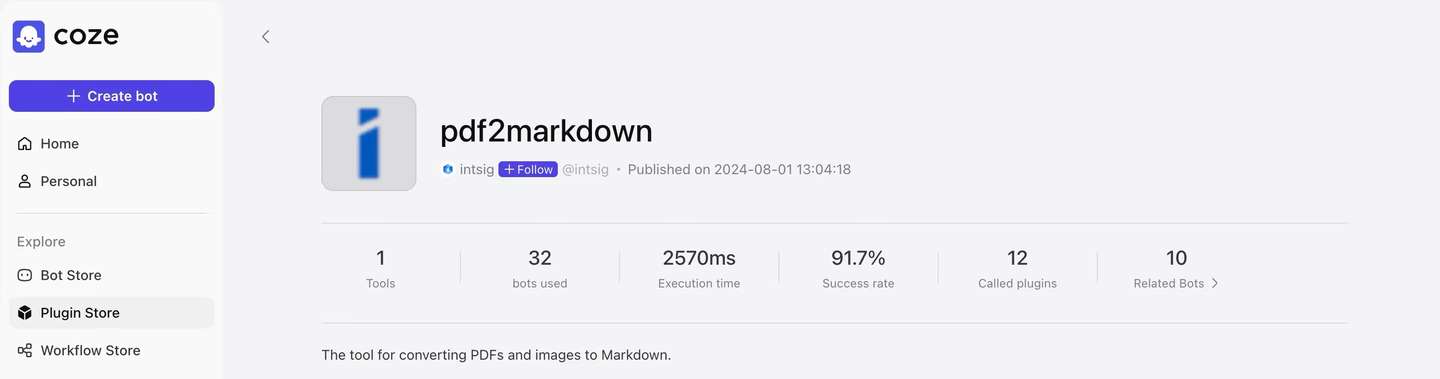
在扣子搜索“pdf转markdown”,或在Coze搜索“pdf2markdown”
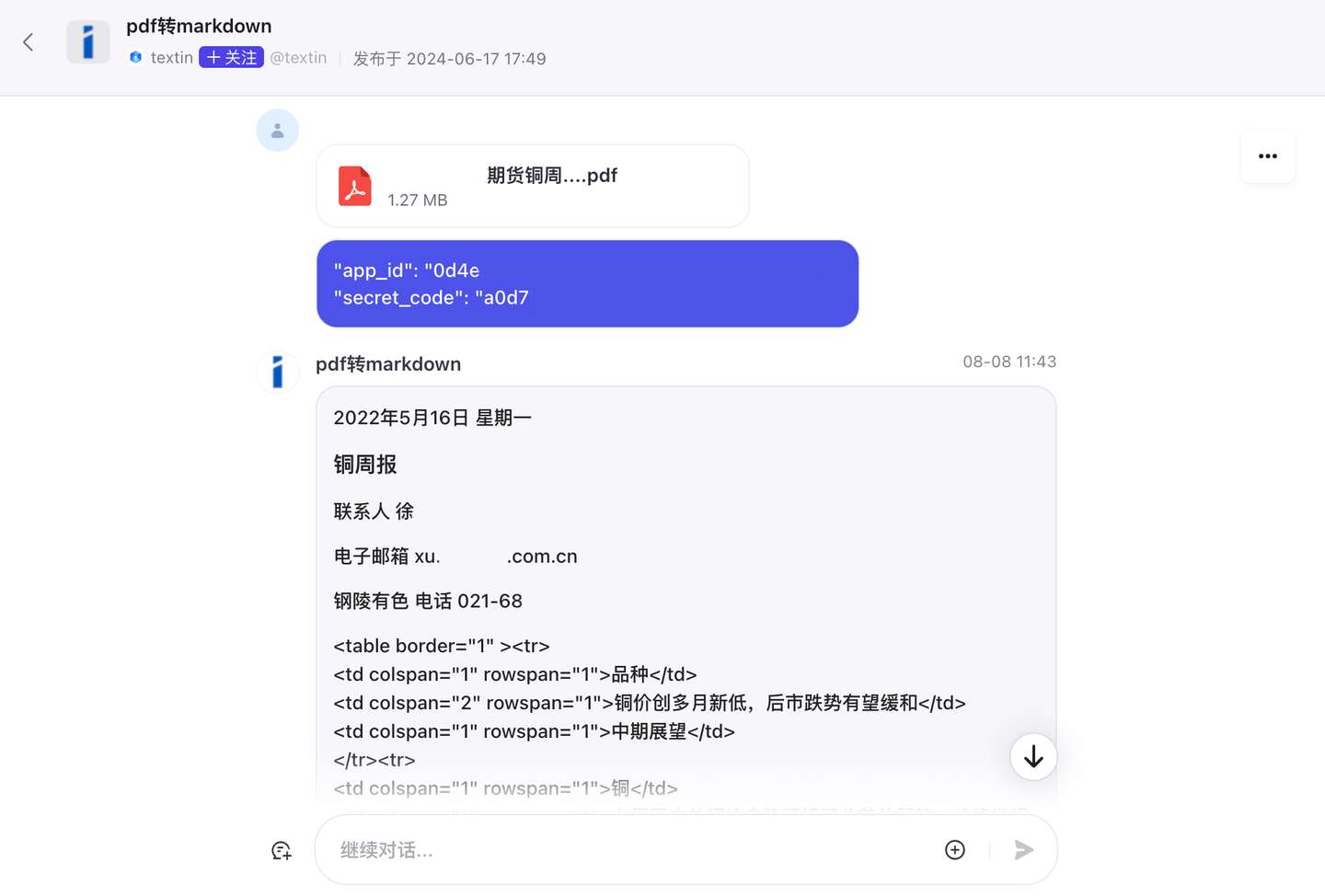
即可找到插件,在你的专属智能体中便捷使用文档解析功能。 如果想测试解析插件在你需要的场景下表现如何,可以直接对话bot,试用pdf转markdown效果。
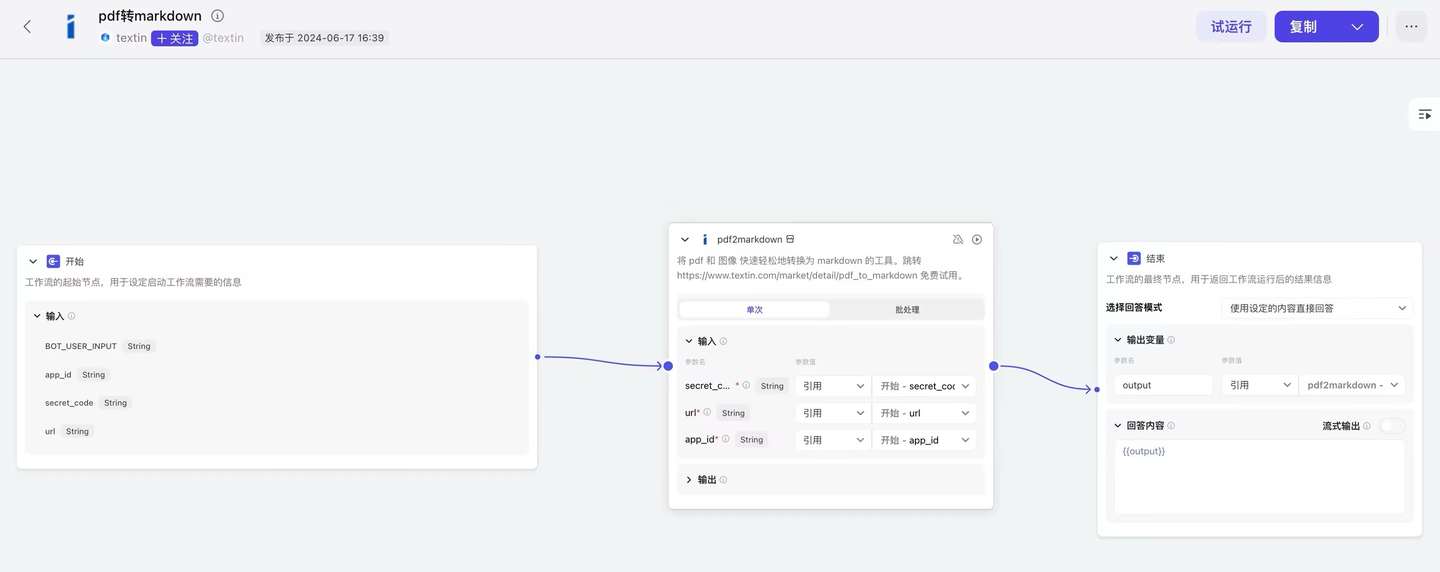
同时,TextIn团队提供了简单的Workflow示例供参考,有搭建工作流需要的朋友也可直接复制使用。
现在,“pdf转markdown”插件可以为Coze用户提供与TextIn网页端、API调用同等的优质服务:
-
大文件:目前同步接口文件最大可达500MB,未来将进一步提高
-
长文件:目前支持最长1000页,开发计划已将目标定在5000页
-
高速度:快速解析百页级pdf,无需长时间等待
同时,每位用户可免费享有1000页额度,实现小体量解析“额度自由”。
“pdf转markdown”插件的上架为有PDF文件处理需求的用户提供了一个可靠的优选工具。
由于PDF文件的视觉编码特性,其中的内容难以被提取或二次编辑。长期以来,PDF经常成为知识“沉睡”的终点。大模型时代,打造“聪明”的AI需要的“基建”除了算力之外,还有高质量的语料。中文语料缺口已成为业内的关注重点之一,现阶段,大量的高质量中文语料数据存在于书籍、论文、研报、企业文档等文档之中,复杂的版面结构制约了大模型的训练语料处理及大模型文档问答的应用能力。
文档解析技术让机器能够识别文档中的多种元素,更好地处理文本、表格、图像等多类型数据,还原文档阅读顺序,服务各类AI应用、智能体的开发。
通过物理版面分析与逻辑版面分析技术,TextIn文档解析能够准确识别文档中的各个元素,并理解其之间的逻辑关系。物理版面分析侧重于视觉特征、文档布局,主要任务是把相关性高的文字聚合到一个区域,比如一个段落,一个表格等等,并选用目标检测任务进行建模,使用基于回归的单阶段检测模型进行拟合,从而获得文档中各种各样的布局方式;逻辑版面分析侧重于对语义特征的分析,主要任务是把不同的文字块根据语义建模,例如通过语义的层次关系,形成一个目录树结构。
TextIn在文档智能领域拥有深厚的技术积累,在文字、表格识别OCR技术的基础上,开发版面分析能力。随着深度学习技术的发展,版面分析的能力得到了显著提升,使得处理复杂文档布局成为可能。
TextIn版面分析技术利用深度神经网络,对文档页面的布局和结构进行自动分析和理解。
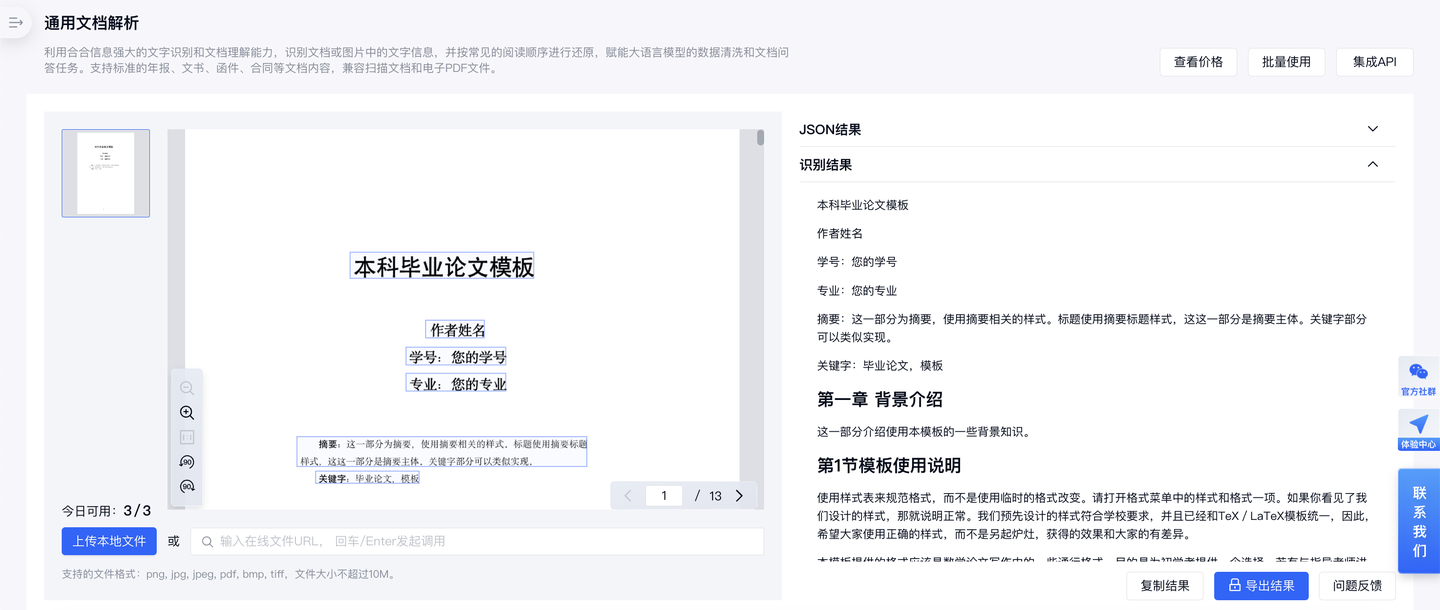
版面分析技术主要包括以下几个关键步骤:
-
元素检测:利用深度学习模型,如目标检测模型(如Faster R-CNN、YOLO、SSD等),对文档图像中的各种元素进行检测和定位。这些元素可以包括文字、图像、表格、标题等。通过元素检测,可以确定文档中不同元素的位置和边界框,为后续的分析和处理提供基础。
-
元素分类:对检测到的元素进行分类,区分文字、图像、表格等不同类型的元素。这一步骤可以采用深度学习中的图像分类模型或目标分类模型,对每个元素进行识别和分类,以便后续的结构解析和语义理解。
-
结构解析:在元素检测和分类的基础上,进行文档的结构解析,识别文档中不同元素之间的关系和层次结构。这包括文本段落与标题的对应关系、表格中不同字段的关系等。深度学习模型可以通过对文档布局和语义信息的分析,实现对文档结构的自动解析和理解。
-
版面校正:对检测到的文档元素进行版面校正,使其在整体文档中的位置和排布更加合理和统一。这一步骤可以包括文本对齐、图像矫正、表格对齐等操作,以提高文档的可读性和美观性。
目前,“pdf转markdown”Coze插件连通TextIn迭代最新版解析技术,支持各类Bot开发,Copy链接
马上试用https://www.coze.cn/store/plugin/7381354890590814208?from=plugin_card

