
- 1在Ubuntu 24.04上安装ollama报curl: (28) Failed to connect to github.com port 443的解决方法_ubuntu 24.04 ollama
- 2CGI(Common Gateway Interface)介绍
- 3链动 2+1 模式小程序 AI 智能名片商城源码培训邀约策略研究_链动2+1 源码
- 4dreamStudio试用教程【AI绘画】_dreamstudio ai绘画
- 5【Docker项目实战篇】Docker部署PDF多功能工具Stirling-PDF
- 6python 压力测试脚本
- 7safari android 模拟,Selenium模拟移动设备(iOS,Android,etc)浏览器
- 8mysql profile 调试sql_MySQL使用profile分析SQL执行状态
- 92024年上半年信息系统项目管理师——综合知识真题题目及答案(第1批次)(1)_信息系统项目管理2024真题
- 10使用人工智能与大模型技术构建智能问答系统_大模型智能问答优势
给 「大模型初学者」 的 LLaMA 3 核心技术剖析_llama3技术报告
赞
踩
编者按: 本文旨在带领读者深入了解 LLaMA 3 的核心技术 —— 使用 RMSNorm 进行预归一化、SwiGLU 激活函数、旋转编码(RoPE)和字节对编码(BPE)算法。RMSNorm 技术让模型能够识别文本中的重点,SwiGLU 激活函数则如同“神笔”,让模型生成的文本更加突出重点且易于理解;RoPE 赋予了模型处理序列中词语位置的灵活性,而 BPE 算法则有效提升了模型处理长文本的能力。
从开发环境配置到项目逻辑梳理,各组件的介绍与构建,再到模型组件的整合,本文将带你一步步走过从文本数据分词到创建嵌入、从注意力机制到多头注意力实现的全过程。仅需具备一定的 Python 编程基础,并对神经网络和 Transformer 架构有基本的认识,便能跟随本文的指引,观察 LLaMA 3 如何根据输入生成输出,见证它如何基于输入生成连贯且有意义的文本。
本文作者提供了完整的代码示例和详细的指导文档,无需 GPU ,仅需 17 GB RAM 即可开始实践。无论是希望深化理论认识还是渴望实践技能提升,本文都将是不可多得的优质内容。
作者 | Fareed Khan
编译 | 岳扬

LLaMA 3[1] 是继 Mistral[2] 之后最有前途的开源模型之一,具备应对多种任务的强大能力。早前,我曾发布过一篇文章,详述了如何基于 LLaMA 架构,从头构建一个参数量超 230 万的大语言模型(LLM)。目前 LLaMA-3 已经发布,我们将以更加简便的方法重新构建这一模型。
在本篇博客中无需使用 GPU,但需要不少于 17 GB 的 RAM,因为我们将加载数个超过 15 GB 的文件。
为便于实践,我已在 GitHub 上创建了一个代码仓库[3],内含全部操作代码及详细指南的 notebook 文件,避免了逐行从本博客复制粘贴的繁琐。
想了解如何从零构建一个参数量超过 230 万的大语言模型(LLM)吗?请参考这篇指南[4],带你从零开始踏入大模型创建之旅。
目录
01 预备知识概览
02 LLaMA 2 与 LLaMA 3 的区别
03 LLaMA 3 架构探秘
- 使用 RMSNorm 进行预归一化
- SwiGLU 激活函数
- 旋转编码 (RoPE)
- 字节对编码 (BPE) 算法
04 配置开发环境
05 理清项目组织逻辑
06 对输入数据进行分词
07 为每个 token 创建嵌入
08 使用 RMSNorm 进行归一化
09 注意力头(Query,Key,Values)
10 实现 RoPE
11 实现 Self Attention
12 实现 Multi-Head Attention
13 实现 SwiGLU 激活函数
14 整合上述模型组件
15 见证模型如何基于输入生成输出
01 预备知识概览
本文不涉及面向对象编程(OOP),仅需掌握简单的 Python 语法即可。不过,要想顺畅阅读这篇博客,具备对神经网络和 Transformer 架构的基本认识是必不可少的前提。这两点便是学习本文的全部要求。
02 LLaMA 2 与 LLaMA 3 的区别
在探讨相关技术的细枝末节之前,需要了解的一点是,LLaMA 3的架构设计与 LLaMA 2 相同。因此,即便你尚未深入了解 LLaMA 3 的技术细节,阅读这篇博客也没有啥问题。即便不了解 LLaMA 2 的架构也别着急,我们也会对其技术细节进行概述,尽力确保所有感兴趣的读者都能阅读本文。
以下是有关 LLaMA 2 与 LLaMA 3 的几个核心要点:

03 LLaMA 3 架构探秘
在着手编写代码之前,了解 LLaMA 3 架构非常重要。为了帮助各种读者更形象地理解这一概念,特附上一张对比图,直观展示原始 Transformer 架构与 LLaMA 2/3 及 Mistral 之间的异同。
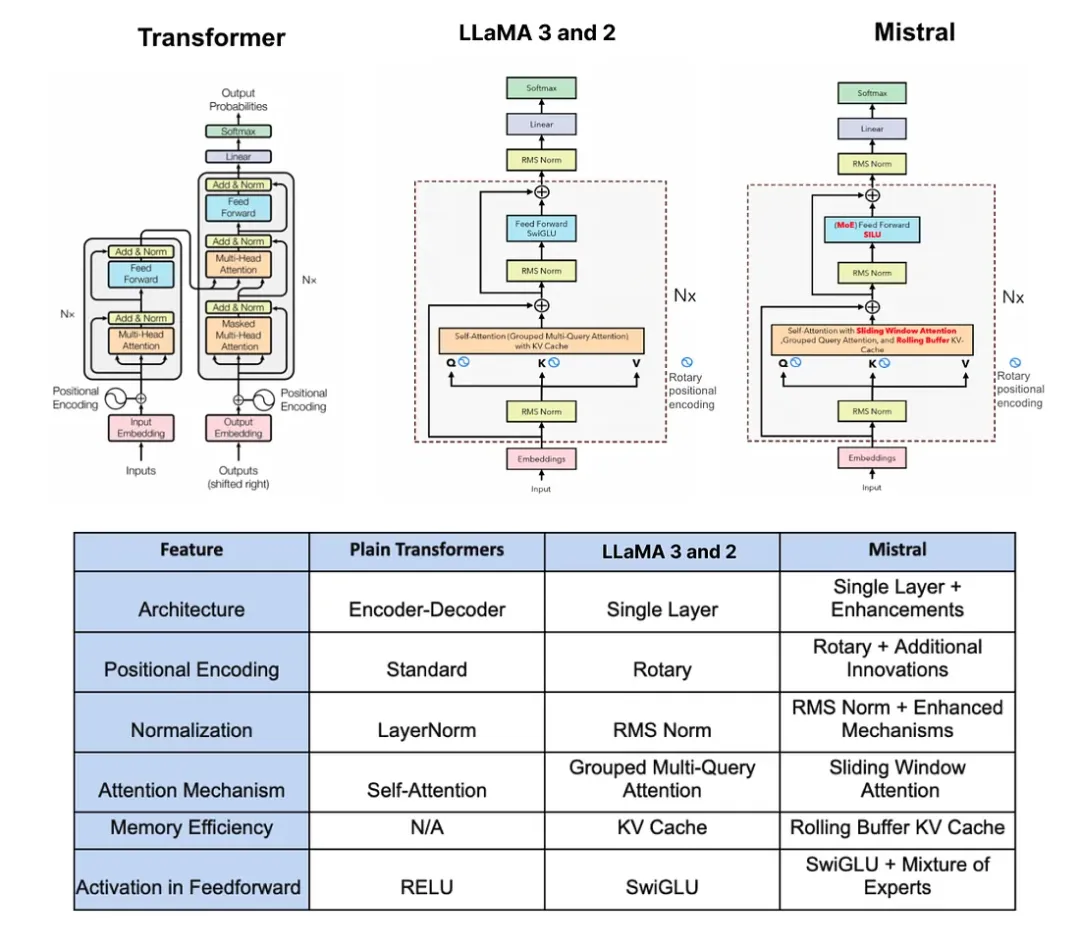
From Rajesh Kavadiki
现在,让我们深入了解一下 LLaMA 3 中几个核心要素的细节:
3.1 使用 RMSNorm 进行预归一化
沿袭 LLaMA 2 的做法,LLaMA 3 采取了一项名为 RMSNorm 的技术,来对每一个 Transformer 子层的输入数据进行归一化处理(normalizing)。
设想一下,你正在备战一场大型考试,手边是一本“大部头”教科书,内容分成了多个章节。每一章都覆盖了不同知识点,但其中某些章节对理解整本书的主题更为重要。在通读整本教科书之前,你决定评估一下每一章的重要性,你不想在每一章节上都花同样多的时间,而是希望将精力更多地集中在那些核心章节上。
类比到像 ChatGPT 这样的大语言模型(LLMs),使用 RMSNorm 进行预归一化就如同依据内容的重要性为各章节“加权”。对理解书籍主题至关重要的章节会获得更高的“权重”,而次要章节则反之。
因此,在深入学习之前,我们会根据各章节的重要性调整学习计划。在权重较高的章节上分配更多时间与精力,确保全面而深刻地掌握其核心概念。

《Root Mean Square Layer Normalization》(https://arxiv.org/abs/1910.07467)
与此类似,采用 RMSNorm 技术进行预归一化能帮助大语言模型(LLMs)识别出文本中哪些部分对于理解上下文及其语义更为重要。它通过为关键要素赋予更高权重、非关键要素赋予较低权重的方式,引导模型将注意力集中于那些对上下文的准确解读最需要的地方。对此感兴趣的读者可在此处[5]深入了解 RMSNorm 的具体实现方式。
3.2 SwiGLU 激活函数
LLaMA 从 PaLM 模型中汲取灵感,引入了 SwiGLU 激活函数。
想象一下,假如你是一名教师,正试图向学生解释一个复杂的话题。有一块大白板,你在上面写下了一些要点,并绘制图像尽量使得内容讲解更为清晰。但有时,你的字迹可能不太工整,或者图像可能画得不够完美。这会大大增加学生理解教材的难度。
假如你拥有一支“神笔”,它能够根据每个要点的重要性自动调整字的大小和样式。如若某一要点非常重要,这支笔就会把它写得更大、更清晰,让其更加显眼。如果不那么重要,这支“神笔”就会把字写得小一些,但仍清晰可辨识。
SwiGLU 对于像 ChatGPT 这样的大语言模型(LLMs)来说就像那支“神笔”。在生成文本之前,SwiGLU 会根据每个单词(word)或短语(phrase)与上下文的相关性(relevance)调整其重要性(importance)。就像“神笔”会调整你写字✍️时的字体大小和风格一样,SwiGLU 也会调整每个词或短语的重要程度。
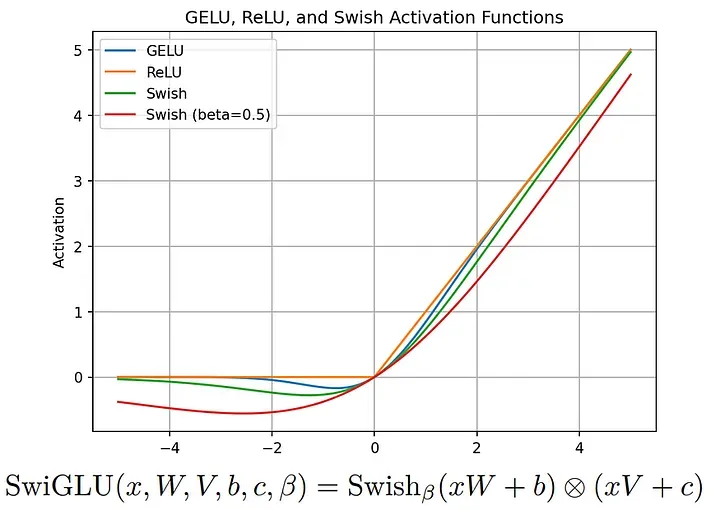
《SwiGLU: GLU Variants Improve Transformer》(https://kikaben.com/swiglu-2020/)
这样,当大语言模型生成文本时,就可以更加突出重要部分,并确保这些内容对文本的整体理解贡献更大。这样,SwiGLU 就能帮助大语言模型生成更清晰、更易于理解的文本,就像“神笔”能够帮助你在白板上为学生创造更为清晰的内容讲解一样。若想进一步了解 SwiGLU 的相关细节,请查阅相关论文[6]。
3.3 旋转编码 (RoPE)
旋转编码(Rotary Embeddings),简称 RoPE ,是 LLaMA 3 中采用的一种位置编码方式(position embedding)。
想象一下,你正在教室里组织小组讨论,需要为学生们分配座位。常规做法是按行和列安排座位,每位学生都有一个固定的座位。但在某些情况下,我们可能希望设计一种更为灵活的座位布局安排,让学生们能更自如地走动与交流。
RoPE 就像一种特别的座位布局方案,它让每位学生既能旋转又能改变位置,同时还能保持与其他学生的相对位置不变。学生们不再受制于某一个固定的位置,而是能做圆周运动(circular motion),从而实现更加顺畅的互动。
在这种情况下,每一位学生都代表着文本序列里的一个词语或 token ,他们的位置与他们在序列中的位置相对应。如同 RoPE 让学生们能旋转与改变位置一样,RoPE 也允许文本序列中各词语的位置编码(positional embeddings)能够根据彼此间的相对位置进行动态调整。
因此,在处理文本的过程中,RoPE 并未简单地将位置编码视作固定、静态的(fixed and static)元素,而是巧妙地融入了旋转(rotational)这一概念,使得表示方式更加灵活、多样化,能够更精准地把握文本序列内词语间的变化关系。 这种灵活性赋予了 ChatGPT 等模型更强的能力,使其能更深刻地理解和生成自然流畅、逻辑连贯的文本内容,就如同在教室中采用动态座位布局(dynamic seating arrangement)能够激发更多互动式的讨论一样。若想深入了解其背后的数学原理,可查阅 RoPE 的相关论文[7]。
3.4 字节对编码 (BPE) 算法
LLaMA 3 采用由 OpenAI 推出的 tiktoken 库中的字节对编码(Byte Pair Encoding, BPE),而 LLaMA 2 的 BPE 分词机制基于 sentencepiece 库。两者虽有微妙差异,但目前的首要任务是理解 BPE 究竟是什么。
先从一个简单的例子开始:假设有一个文本语料库(text corpus),内含 “ab”, “bc”, “bcd”, 和 “cde” 这些词语。我们将语料库中所有单词拆分为单个字符纳入词汇表,此时的词汇表为 {“a”, “b”, “c”, “d”, “e”}。
接下来,计算各字符在文本语料库中的出现次数。在本例中,统计结果为 {“a”: 1, “b”: 3, “c”: 3, “d”: 2, “e”: 1}。
- 随后,进入核心环节 —— 合并阶段(merging process)。重复执行以下操作直至词汇表达到预定规模:第一步,找出频次最高的连续字符组合。 在本例中,频次最高的一对字符是“bc”,频次为 2。然后,我们将这对字符合并,生成新的子词单元(subword unit)“bc”。合并后,更新字符频次,更新后的频次为 {“a”: 1, “b”: 2, “c”: 2, “d”: 2, “e”: 1, “bc”: 2}。我们将新的子词单元 “bc” 加入词汇表,使之扩充至 {“a”, “b”, “c”, “d”, “e”, “bc”}。
- 重复循环这一过程。 下一个出现频次最高的词对是“cd”,将其合并生成新的子词单元 “cd”,并同步更新频次。更新后为 {“a”: 1, “b”: 2, “c”: 1, “d”: 1, “e”: 1, “bc”: 2, “cd”: 2}。然后我们将 “cd” 加入词汇表,得到 {“a”, “b”, “c”, “d”, “e”, “bc”, “cd”}。
- 延续此流程,下一个频繁出现的词对是 “de”,将其合并为子词单元 “de”,并将频次更新至 {“a”: 1, “b”: 2, “c”: 1, “d”: 1, “e”: 0, “bc”: 2, “cd”: 1, “de”: 1}。然后将 “de” 添加到词汇表中,使其更新为 {“a”, “b”, “c”, “d”, “e”, “bc”, “cd”, “de”}。
- 接下来,我们发现 “ab” 是出现频次最高的词对,将其合并为子词单元 “ab”,同步更新频次为 {“a”: 0, “b”: 1, “c”: 1, “d”: 1, “e”: 0, “bc”: 2, “cd”: 1, “de”: 1, “ab”: 1}。再将 “ab” 添加至词汇表中,使其扩容至 {“a”, “b”, “c”, “d”, “e”, “bc”, “cd”, “de”, “ab”}。
- 再往后,“bcd”成为了下一个出现频次最高的词对,将其合并为子词单元 “bcd”,更新频次至 {“a”: 0, “b”: 0, “c”: 0, “d”: 0, “e”: 0, “bc”: 1, “cd”: 0, “de”: 1, “ab”: 1, “bcd”: 1}。将 “bcd” 添入词汇表,使其升级为 {“a”, “b”, “c”, “d”, “e”, “bc”, “cd”, “de”, “ab”, “bcd”}。
- 最后,出现频次最高的词对是 “cde”,将其合并为子词单元 “cde”,更新频次至 {“a”: 0, “b”: 0, “c”: 0, “d”: 0, “e”: 0, “bc”: 1, “cd”: 0, “de”: 0, “ab”: 1, “bcd”: 1, “cde”: 1}。将 “cde” 添加入词汇表,这样词汇表就变为了 {“a”, “b”, “c”, “d”, “e”, “bc”, “cd”, “de”, “ab”, “bcd”, “cde”}。
此方法能够显著提升大语言模型(LLMs)的性能,同时能够有效处理生僻词及词汇表之外的词汇。TikToken BPE 与 sentencepiece BPE 的主要区别在于:TikToken BPE 不会盲目将已知的完整词汇分割。 比如,若 “hugging” 已存在于词汇表中,它会保持原样,不会被拆解成 [“hug”,“ging”]。
04 环境配置
我们将使用到少量 Python 库,为了防止出现 “no module found” 的错误,建议运行下面这行命令提前安装好这些库。

安装完所需库后,下一步是下载相关文件。因为我们要复现的是 llama-3-8B 模型的架构,所以我们需要在 HuggingFace 平台上注册一个账户。另外,鉴于 llama-3 是一款使用受限的模型,访问模型内容前需同意其使用条款。
具体步骤如下:
- 点击此处[8]注册 HuggingFace 账户
- 点击此处[9]同意 llama-3-8B 的使用条款
完成以上两个步骤后,接下来就会下载一些必要的文件。要实现此目的,有两条途径可选:
- 手动下载 (Option 1: Manual) :通过此链接[10]进入 llama-3–8B 的 HuggingFace 目录,逐一手动下载以下三个文件。
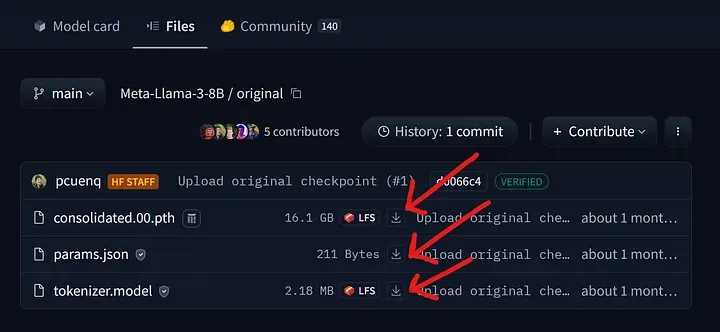
LLaMA-3 配置文件下载
- 通过编程的方式下载 (options 2: Coding) :使用之前安装的 hugging_face 库,我们可以一键下载所有必需的文件。不过,在此之前,需要先用 HF Token 在当前工作环境中登录HuggingFace Hub。你可以创建一个新 token ,或直接通过此链接[11]获取。
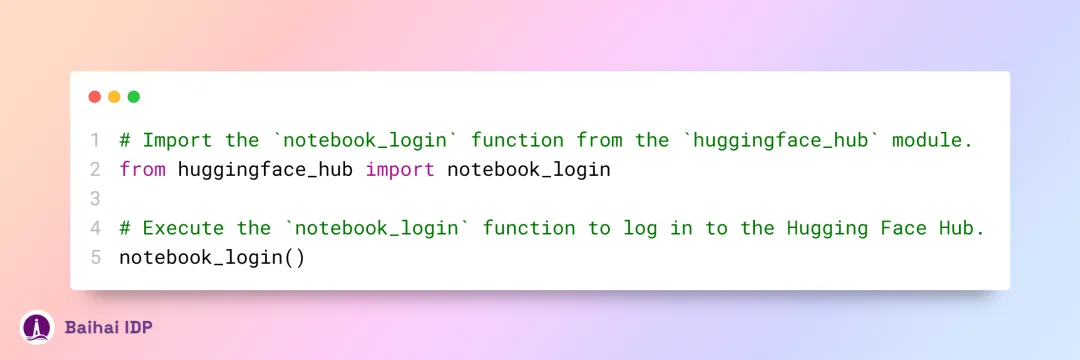
当我们运行该代码单元时,系统会要求我们输入 token 。如若登录过程中遇到问题,请重试,但一定要记得取消选中 “token as git credential” 这一选项。随后,我们仅需运行一段简单的 Python 脚本代码,便能顺利下载 llama-3-8B 架构的三个主要文件。

下载完所有必要文件后,我们需要导入本博客中将要使用的 Python 库。

接下来,我们需要了解所下载的每个文件的具体用途。
05 理清项目组织逻辑
由于我们的目标是精确复制 llama-3 ,这意味着无论输入的文本是什么,都应当获得有实际意义的输出。举例来说,当我们输入“太阳的颜色是什么?(the color of the sun is?)”这样的问题时,期望的回答自然是“白色(white)”。然而,要达成这一目标,通常需要在海量数据集上训练大语言模型(LLMs),而这往往对计算资源的要求极高,因此对于我们来说并不可行。
不过,Meta 已经公开发布了他们的 llama-3 架构文件(或者更确切地说,是他们预训练模型权重)供公众使用。我们刚刚下载的正是这些文件,这意味着我们无需自行训练模型或搜集庞大的数据集,这样就可以复制它们的架构。一切准备工作都已就绪,接下来,我们只需确保在恰当的位置正确地运用这些组件。
现在,让我们逐一了解这些文件及其各自的重要作用:
tokenizer.model —— 如前文所述,LLaMA-3 采用的是 tiktoken 库中的字节对编码(BPE)分词技术,这项技术是在一个包含了 15 万亿个 tokens 的超大数据集上训练得来的,比 LLaMA-2 使用的数据集足足大了7倍之多。现在,让我们加载这个文件,一探究竟,看看它背后藏着哪些奥秘。

length 这一属性代表的是词汇表的总体规模,具体指代的是训练数据中的所有不同(唯一)字符的总数。而 tokenizer_model 本身,则是一种字典类型的数据结构。
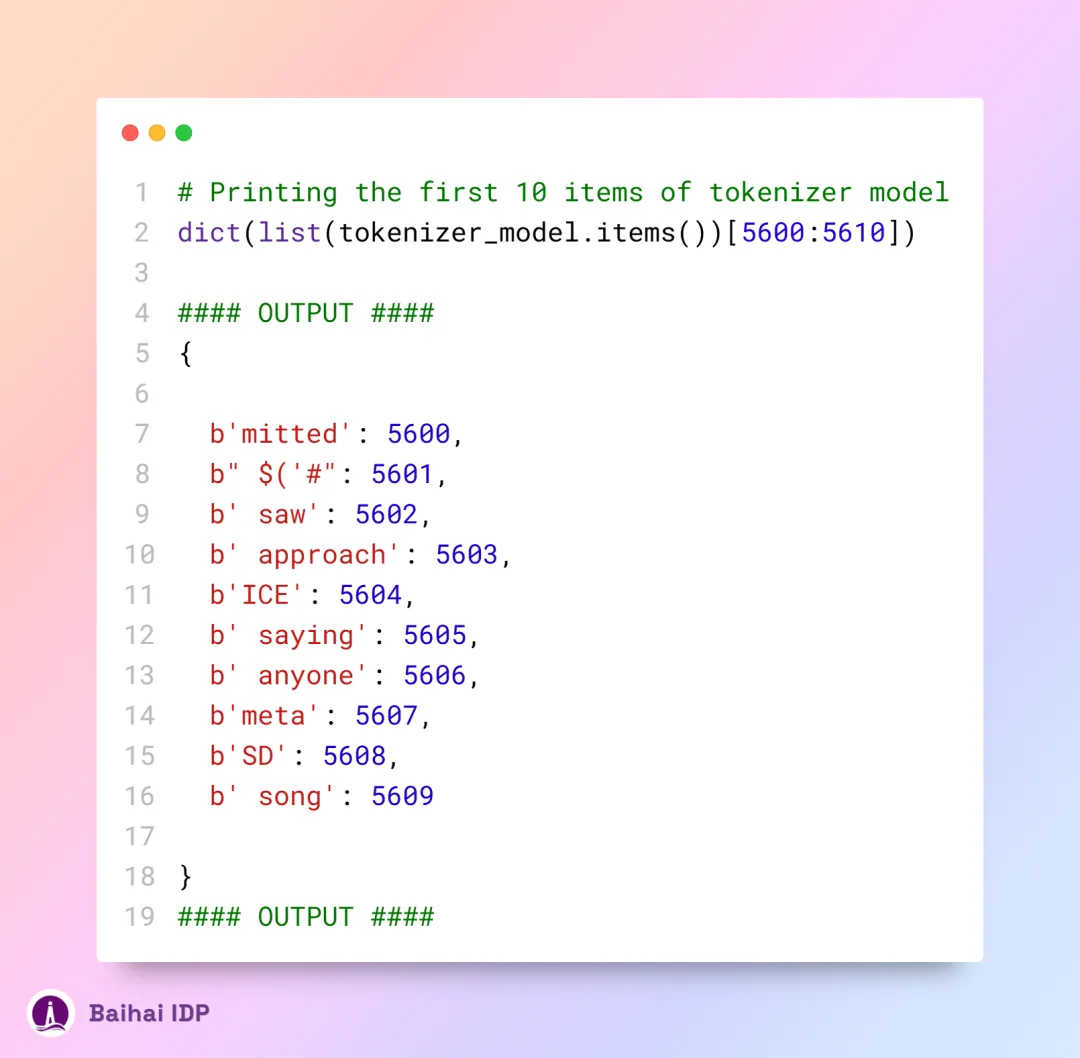
当我们随机抽取并展示其中的 10 项内容,会注意到,这些内容都是通过 BPE 算法精心构造的字符串,与我们之前探讨的示例颇为相似。此处的字典键(key)代表着 BPE 算法训练过程中的字节序列(Byte sequences),而字典值(values)则反映了依据出现频率确定的合并排序级别(merge ranks)。
consolidated.00.pth —— 这个文件内藏玄机,它保存了 Llama-3-8B 模型在训练过程中学到的所有参数,即所谓的模型权重。这些参数深度揭示了模型的工作机制,比如它如何对 tokens 进行编码、如何计算注意力权重、如何执行前馈神经网络的转换,以及最终如何对输出结果进行归一化处理,等等。

对于熟悉 transformer 架构的人来说,诸如查询(query)、键(key)矩阵等概念一定不会陌生。稍后,我们在 Llama-3 的体系结构中借助这些模型层/权重构建出相应的矩阵。
params.json —— 这个文件内容丰富,记录了各类参数的具体数值,包括但不限于:
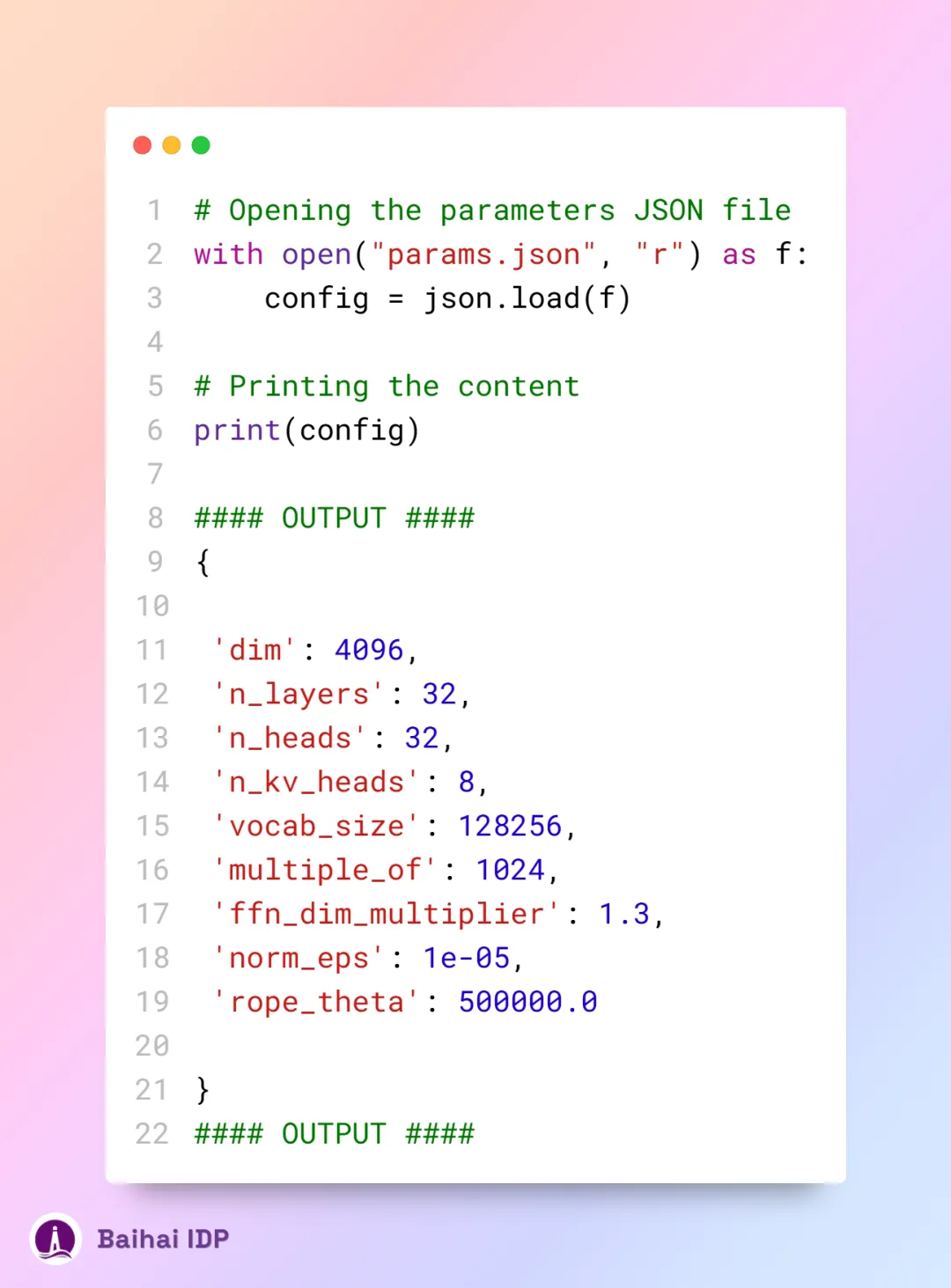
这些数值将帮助我们一步步复制 Llama-3 架构,它们详细记录了模型架构中的关键参数,比如注意力头的数量、嵌入向量的维度等。
现在,让我们妥善保存这些数据值,以备后续环节中调用使用。
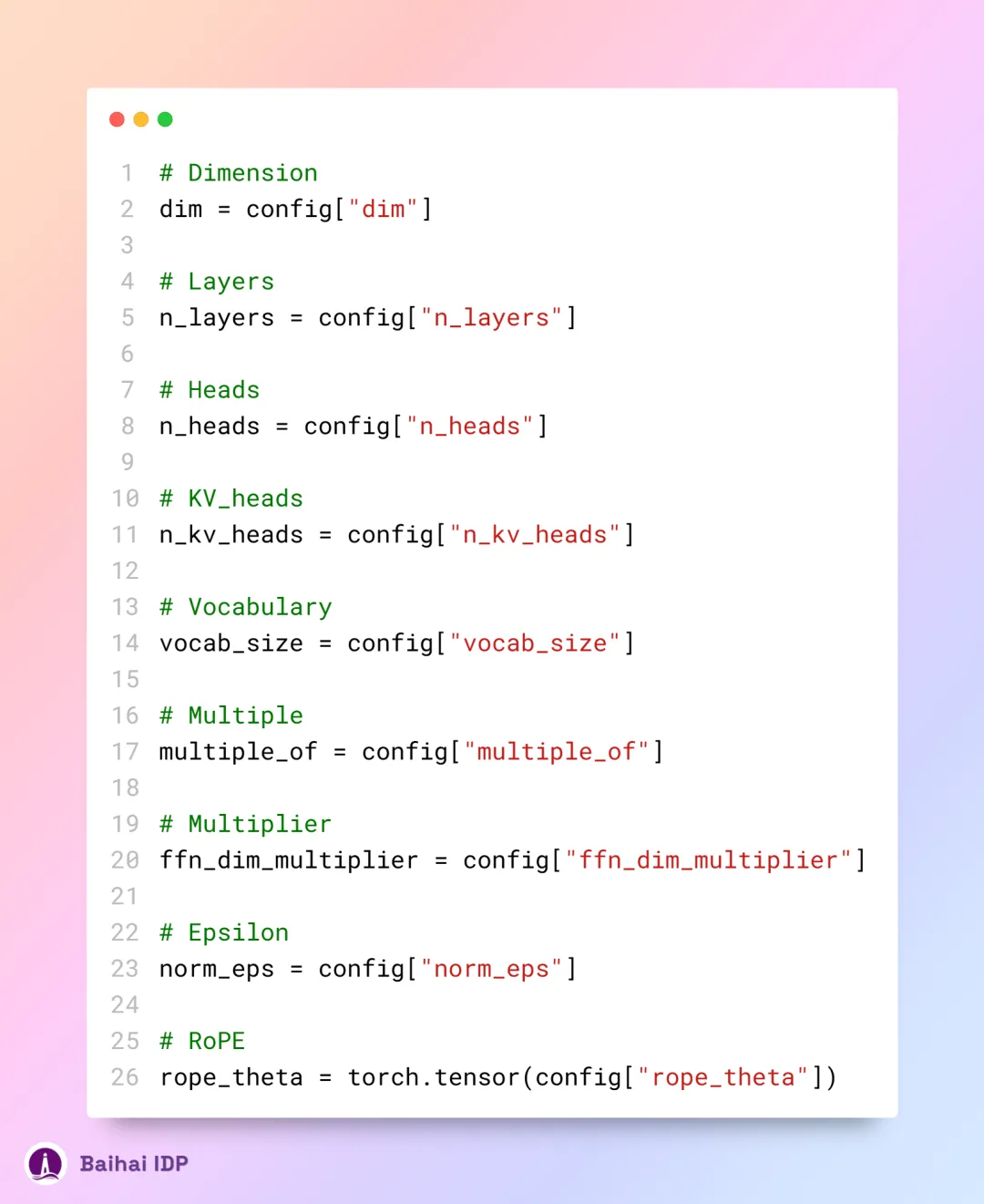
有了分词模型(tokenizer model)、载有关键权重的架构模型(architecture model containing weights)以及详尽的配置参数(configuration parameters)在手,万事俱备,只欠东风。现在,让我们满怀热情,从最基础的部分做起,动手搭建属于我们自己的 Llama-3 模型吧!
06 对输入数据进行分词
该步骤的首要任务是将输入的文本信息转化为词元形式,而这一步骤的关键在于,我们必须先生成一系列特殊词元(token)。这些特殊词元如同导航标,镶嵌在分词之后的文本中,它们赋予分词器识别与处理特定条件或指令的能力,是整个流程中不可或缺的一环。

接下来,我们可以通过设定不同的模式来识别输入文本中各种类型的子字符串,以此来制定文本分割规则。让我们来看看具体操作方法。

此工具能够从输入文本中提取单词(words)、缩写(contractions)、数字(numbers)(最多三位数) ,以及由非空白字符组成的字符序列,我们可以根据自身需求对其进行个性化设置。
我们需利用 TikToken 的 BPE 算法来编写一个简易的分词函数,该函数接收三项参数:t0okenizer_model 、 tokenize_breaker 和 special_tokens 。该函数会按照需求对输入文本进行相应的编码或解码处理。
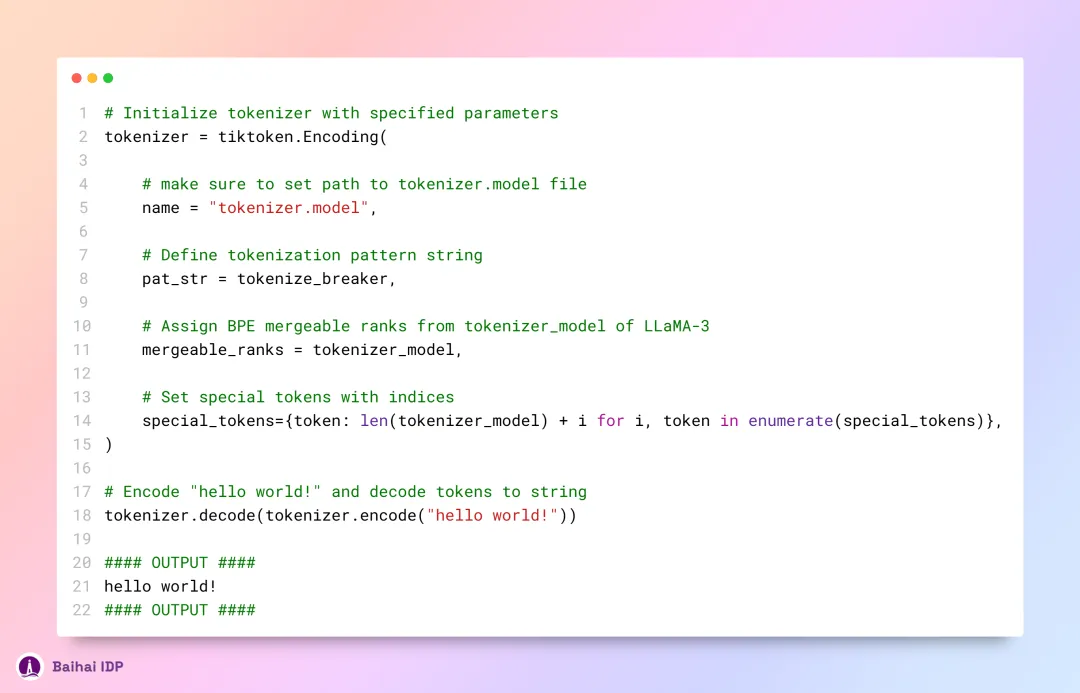
为了验证该编码函数是否能够正常工作,我们先以“Hello World”作为测试文本传入该函数处理。首先,该函数将文本编码,将其转化为一系列数字。随后,再将这些数字解码回原始文本,最终得到 “hello world!” —— 这一过程证明了函数功能正常。现在,让我们开始对输入内容进行分词处理。

我们从一个特殊词元(译者注:此处应当为<|begin_of_text|>)开始,对输入文本 “the answer to the ultimate question of life, the universe, and everything is ” 进行编码处理。
07 为每个 token 创建嵌入
如果我们检查输入向量的长度,其长度应为:
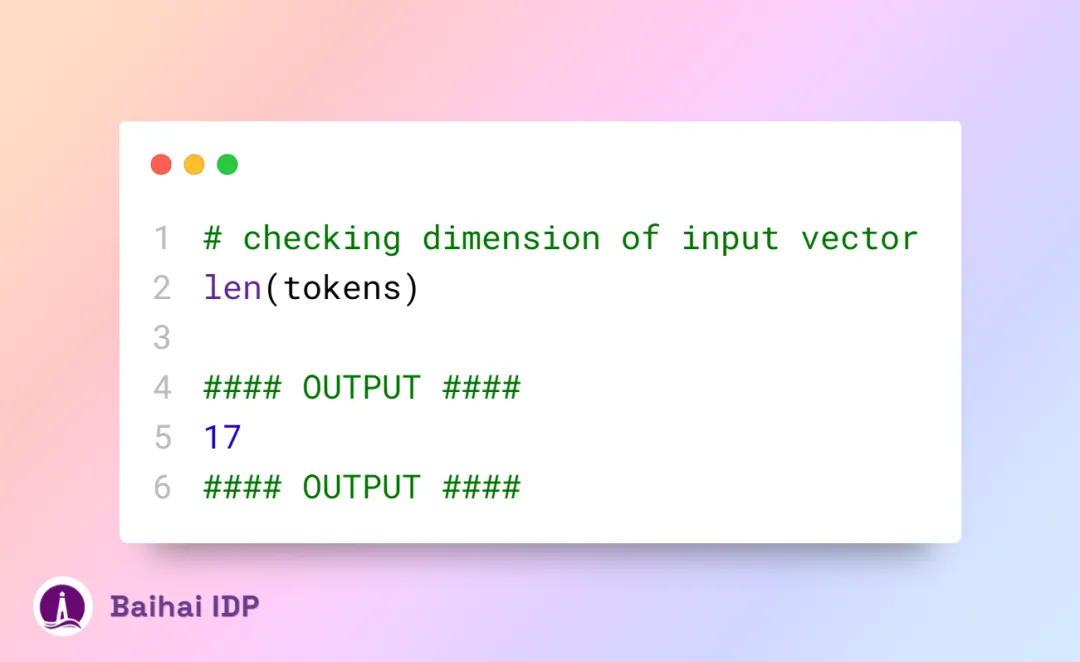

目前,输入向量的维度为 (17x1) ,下一步需要将每个经过分词后的单词转换为其对应的嵌入表征。这样一来,原本的 (17x1) token 将扩展为 (17x4096) 维度的嵌入矩阵,即每个 token 都将拥有一个长度为 4096 的嵌入向量。

有一点需要注意,这些嵌入向量并未经过归一化处理,若不对其进行归一化处理,可能会产生严重负面影响。在下一节,我们将着手对输入向量进行归一化操作。
08 使用 RMSNorm 进行归一化
为了确保输入向量完成归一化,我们将采用前文的 RMSNorm 公式来进行处理。

《Root Mean Square Layer Normalization》 (https://arxiv.org/abs/1910.07467)

我们将使用来自 layers_0 的注意力权重,对尚未归一化的嵌入向量进行归一化处理。选择 layer_0 的原因在于,我们正着手构建 LLaMA-3 transformer 架构的第一层。

由于我们仅对向量进行归一化处理,并不涉及其他操作,所以向量的维度并不会发生变化。
09 注意力头(Query,Key,Values)
首先,我们从模型中加载 query、key、value 和 output 向量。

从向量的维度上可以看出,我们下载的模型权重并非为单独的注意力头设计,因为采用了并行处理或并行训练的方式,可以同时服务于多个注意力头。不过,我们能够分解这些矩阵,让它们只适用于单个注意力头。

在此,32 代表 LLama-3 中注意力头的数量,128 是查询向量的维度大小,4096 则是 token 嵌入的维度大小。
我们可以通过以下方式,获取到第一层中首个注意力头的 query 权重矩阵:
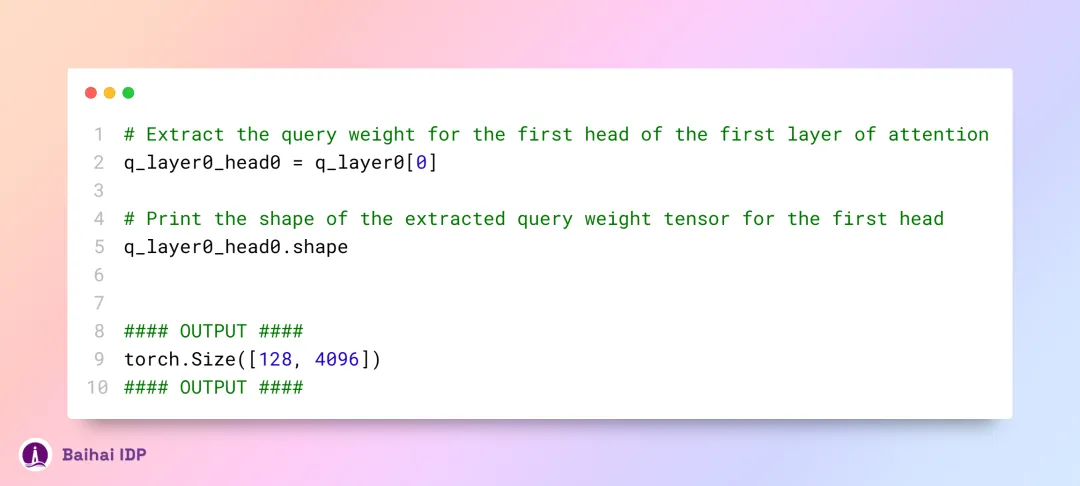
要计算每个 token 对应的 query 向量,我们需要将该 token 的嵌入向量与 query 权重进行相乘运算。

由于 query 向量本身无法识别自己在提示词文本中的具体位置,因此我们将借助 RoPE 技术,让这些向量能够感知其所在位置。
10 实现 RoPE
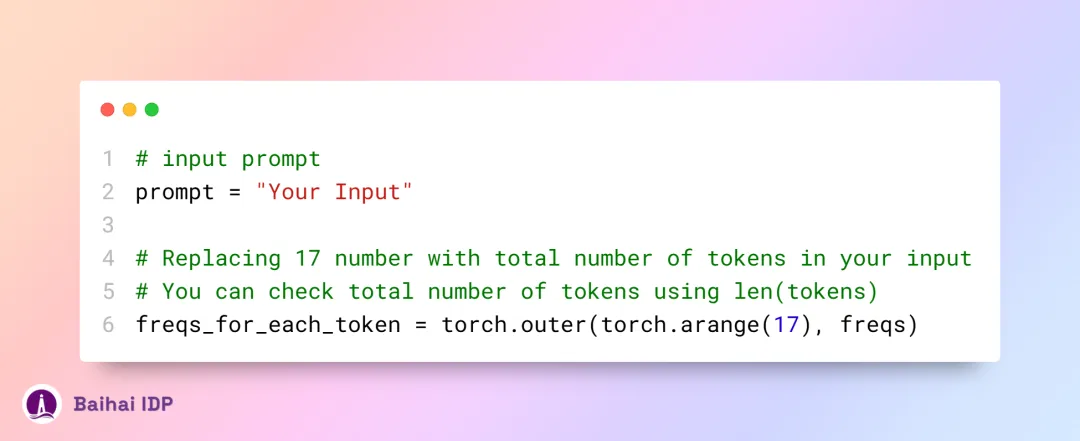
我们将 query 向量分成两个一组,接着对每一组实施旋转角度(rotational angle)的调整,以此来区分它们。
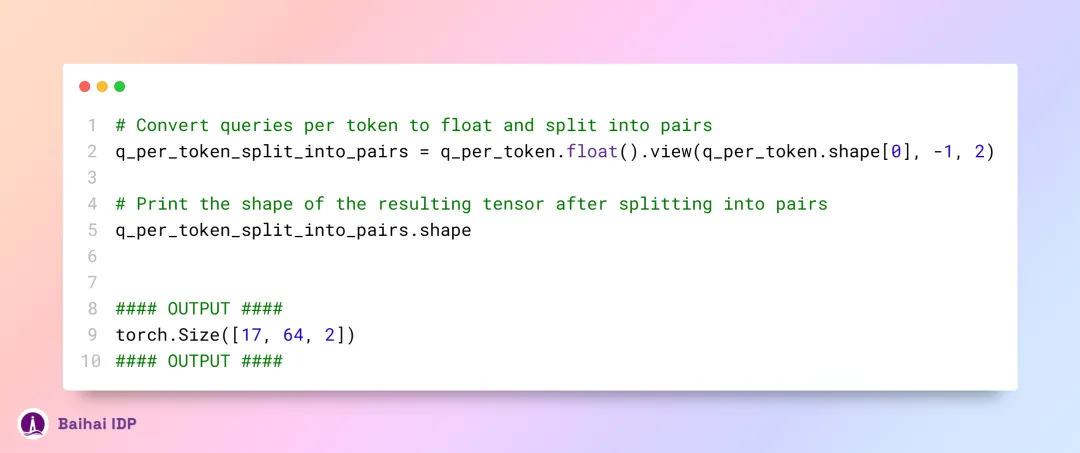
此处要处理的是一个大小为 [17x64x2] 的向量,其实质是将每个提示词内的 128 个长度单位(128-length) 的 query 信息,划分成 64 对。每一个 query 对都将依据 m*θ 角度进行旋转,这里的 m 即为 token 在序列中的位置。
为了实现向量的旋转操作,我们会采用复数点积(the dot product of complex numbers)的计算方法。
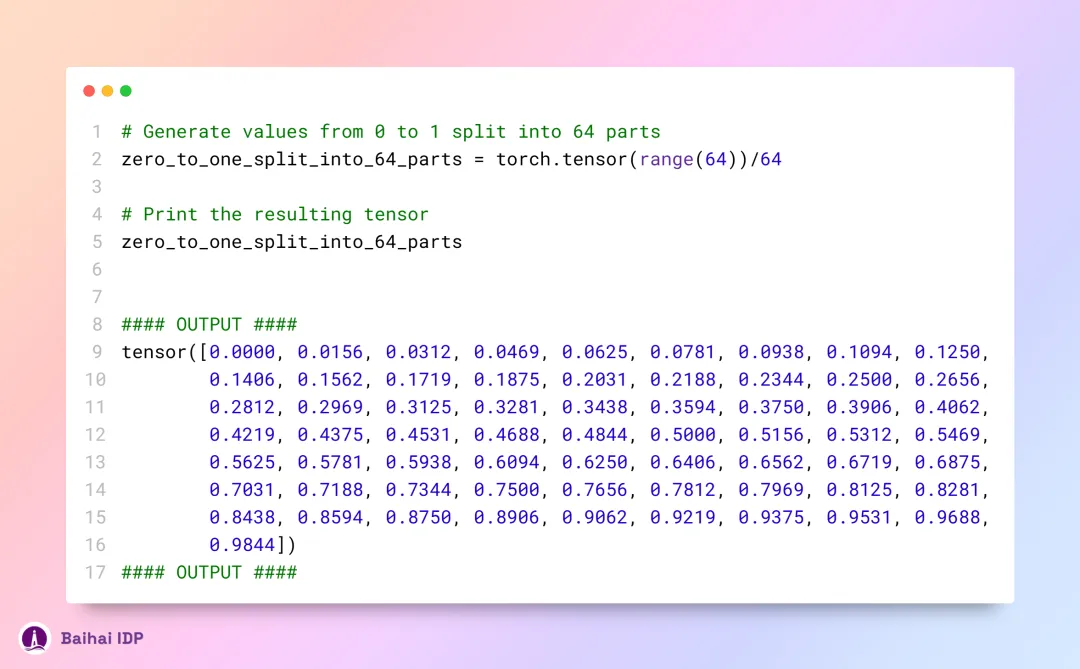
完成分割过程后,接下来我们将对分割后的数据进行频率计算。
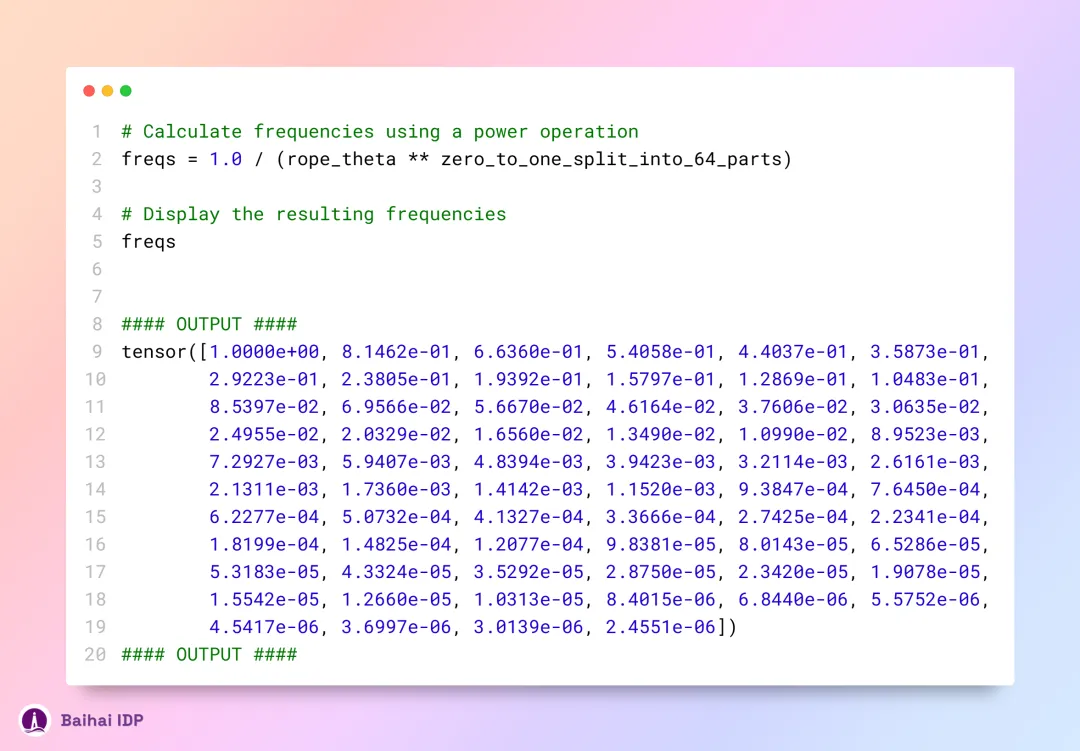
现在,我们已经为每个 token 的 query 部分赋予了对应的复数值。接下来,我们就可以把这些 query 转换为复数,再依据它们各自在序列中的位置,运用点积运算实现旋转处理。
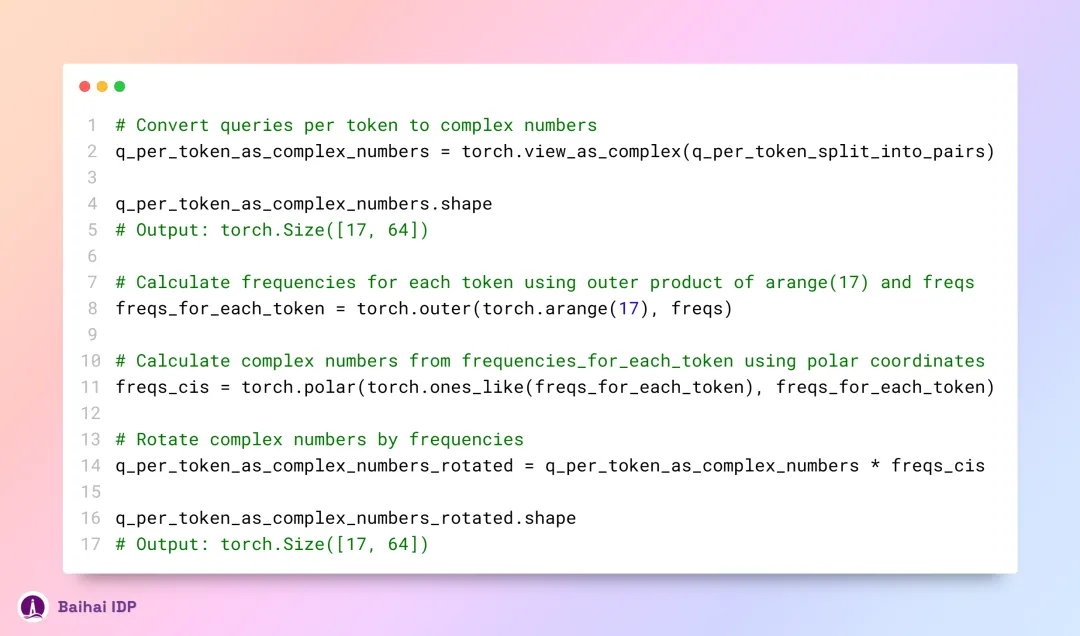
得到旋转后的向量后,我们可以通过将之前的复数重新解释为实数,从而恢复到最初以配对形式表示的 query 向量。

现在,旋转后的数据将进行合并处理,然后得到一个全新的 query 向量(rotated query vector),其 shape 为 [17x128] 。此处的数字 17 代表 token 总数,而 128 则是 query 向量的维度大小。
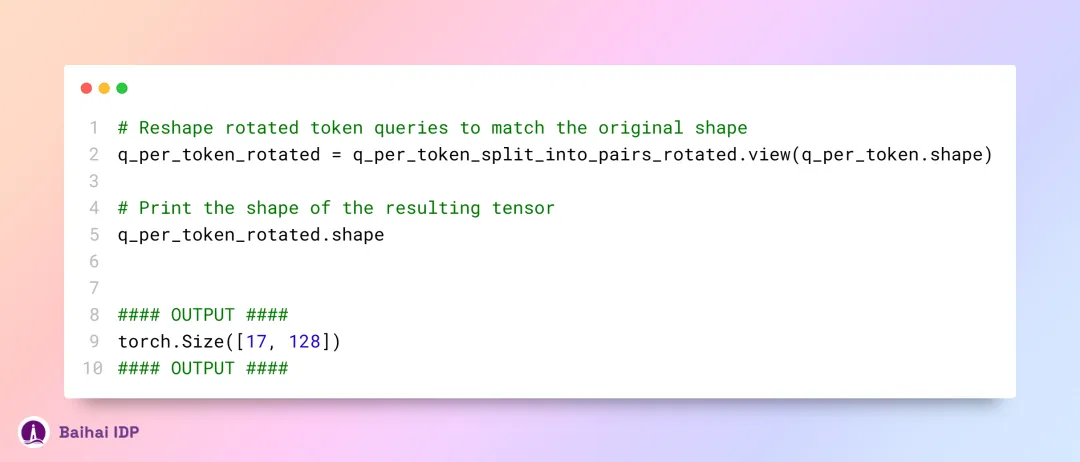
处理 key 向量的方式与 query 向量的处理方式相似,不过要记得,key 向量也是 128 维的。由于 key 向量的权重在 4 个注意力头(head)间共享,以尽量减少运算量,因此其权重数量仅是 query 向量的四分之一。就像 query 向量一样,key 向量也会通过旋转(rotated)来融入位置信息(positional information),以此增强模型对序列位置的理解。

现在,我们已经获得了每个 token 对应的旋转查询向量与键向量(rotated queries and keys),其大小均为 [17x128] 。
11 实现 Self Attention
通过将 query 矩阵与 key 矩阵相乘,我们会得到一组 score(相似性分数),这些 score 对应着每个 token 与其他 token 之间的关联度。具体来说,这些 score 表示每个 token 的 query 向量与其 key 向量之间的相互关系。
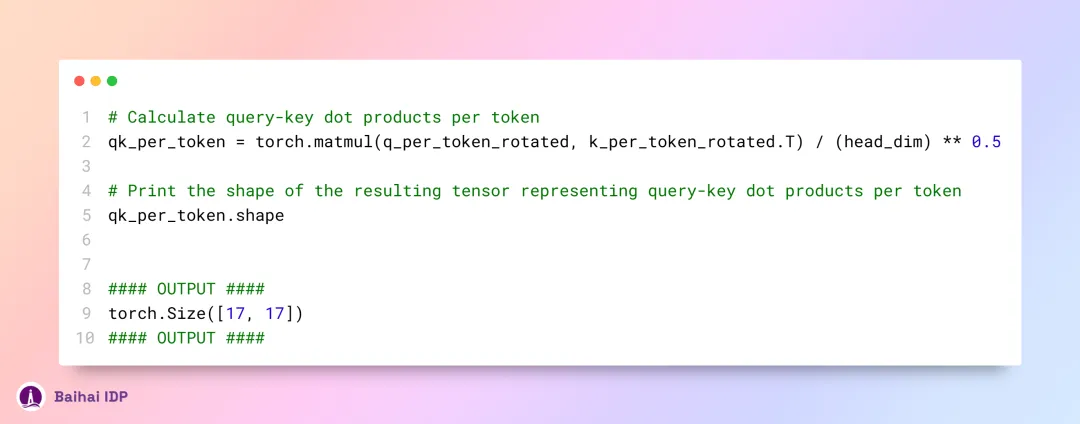
[17x17] 这个 Shape 表示的是注意力分数(qk_per_token),其中数字 17 指的是提示词文本中包含的 token 数量。
我们有必要对 query-key scores (译者注:此处应当指在计算注意力权重时,Query 矩阵和 Key 矩阵之间的匹配程度或相关性得分。)进行屏蔽处理。在模型训练阶段,为了确保模型仅利用历史信息进行预测,我们会屏蔽掉未来 token 的 query-key scores。这一策略导致我们在进行推理时,会将所有未来 token 的 query-key scores 值都设定为零。
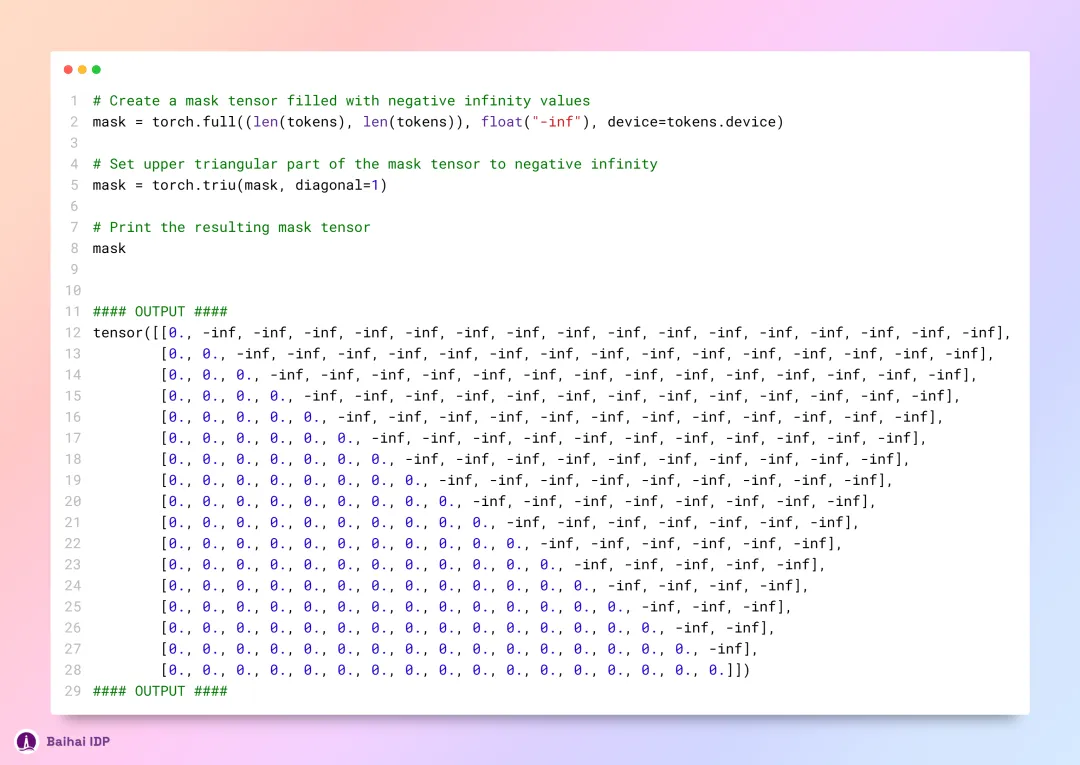
现在,我们需对每个 token 的 query 向量和 key 向量实施遮掩操作。接着,我们打算在此之上应用 softmax 函数,将得到的分数转化为概率值。这样做有利于从模型的词汇表(vocabulary)中挑选出可能性最高的 tokens 或 token 序列,进而让模型的预测结果更易于理解,也更适用于语言生成、分类等应用场景。
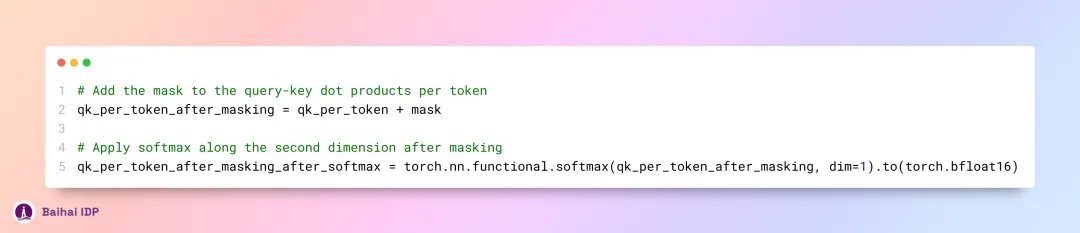
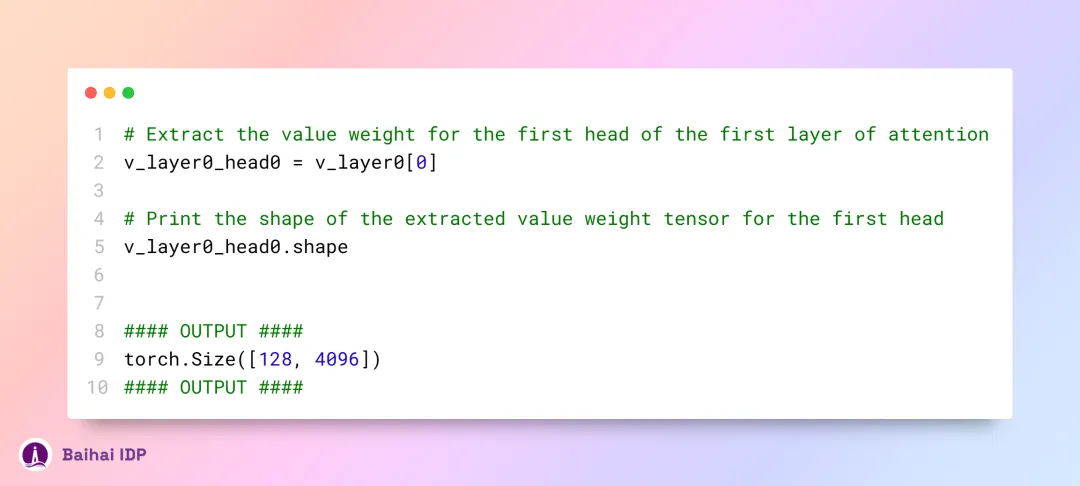
在 value 矩阵这里,自注意力机制告一段落。为了节约计算资源,类似地,value 矩阵权重在每四个注意力头中被共享。最终,value 权重矩阵呈现出的 shape 为 [8x128x4096]。

与 query 矩阵和 key 矩阵类似,我们可以通过特定方法得到第一层及首个注意力头的 value 矩阵。
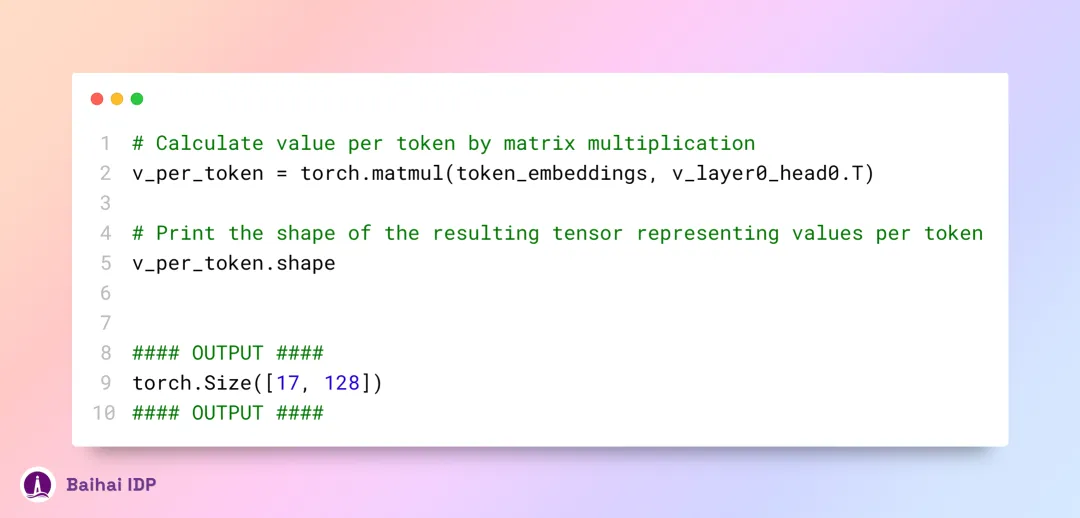
通过值矩阵权重,我们计算出每一个 token 的注意力值,最终得到一个 shape 为 [17x128] 的矩阵。这里,17 指的是提示词文本中的 token 总数,128 则是单个 token 的值向量维度。
要获取最终的注意力矩阵,我们只需进行如下所示的乘法操作:
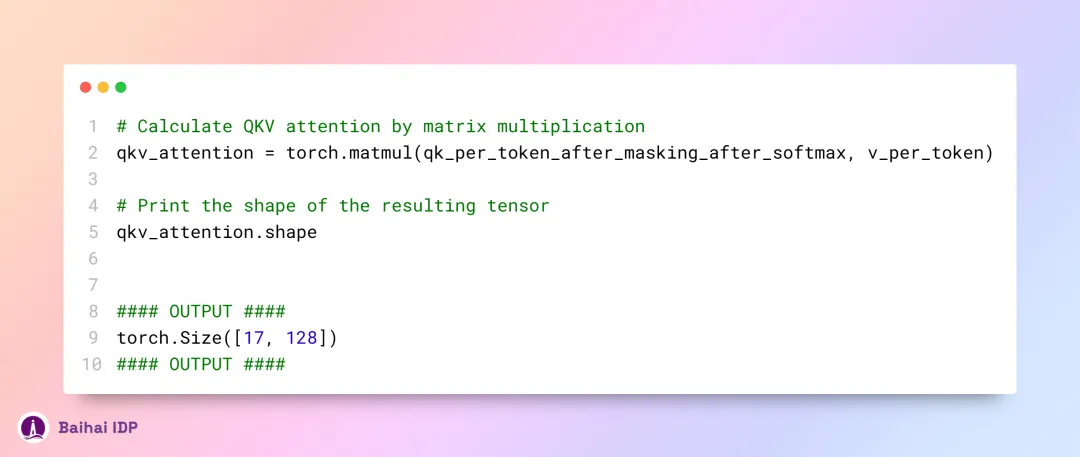
我们现在已经获得了第一层和第一个注意力头的注意力值,这实际上就是所谓的自注意力值(self attention)。
12 实现 Multi-Head Attention
接下来将通过一个循环过程,对第一层中的所有注意力头重复进行上述的计算步骤。

现在,第一层的所有 32 个注意力头中的 QKV 注意力矩阵都已被计算出来,接下来,这些注意力分数将被整合进一个大小为 [17x4096] 的大矩阵中。
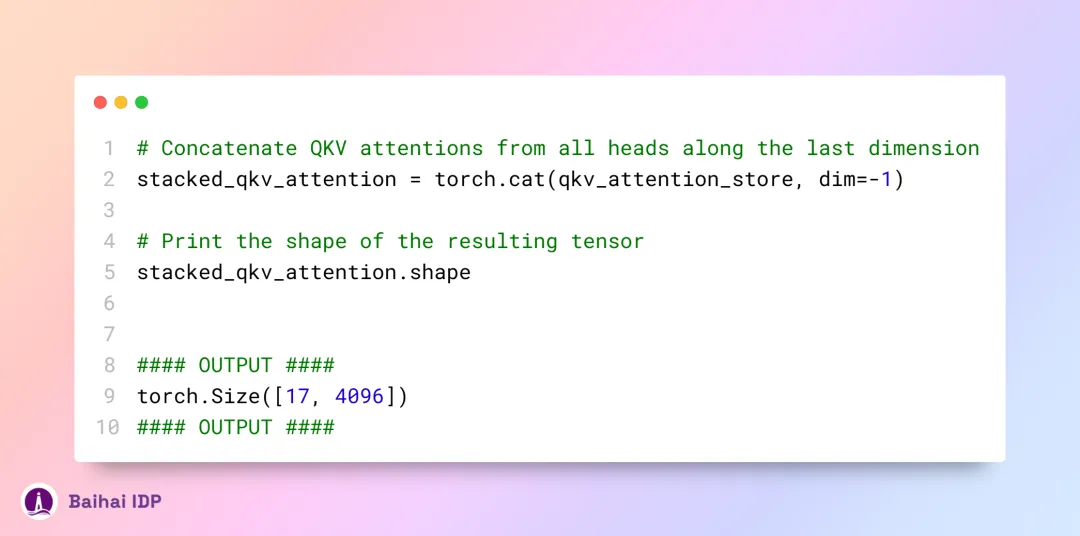
在 layer 0 attention (译者注:可能是整个 Transformer 模型理解和处理序列这一过程的第一步)中,收尾步骤是使用权重矩阵(weight matrix)去乘以堆叠起来的 QKV 矩阵。
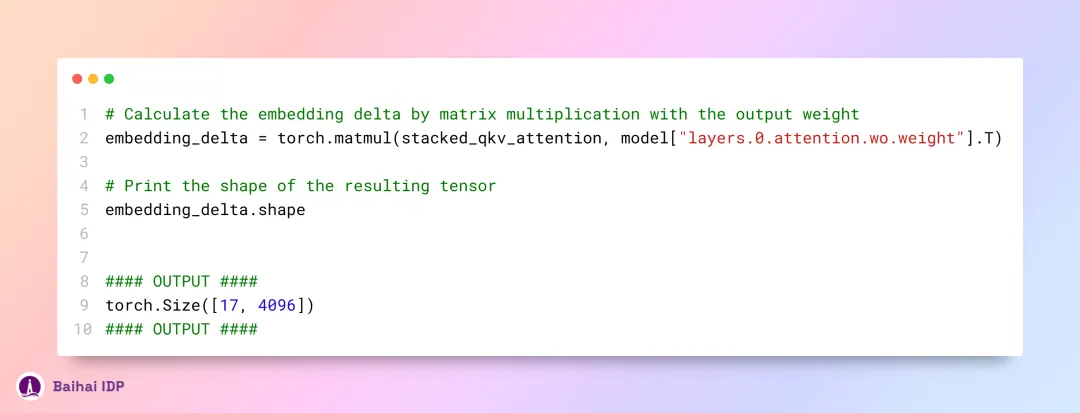
我们现在已经得到了应用注意力机制处理之后的嵌入值(embedding values),这些变化应当被添加至原先的词元嵌入(token embeddings)上。

接下来,我们会对嵌入值的变化进行归一化处理,然后将其送入前馈神经网络(feedforward neural network)中进一步加工。
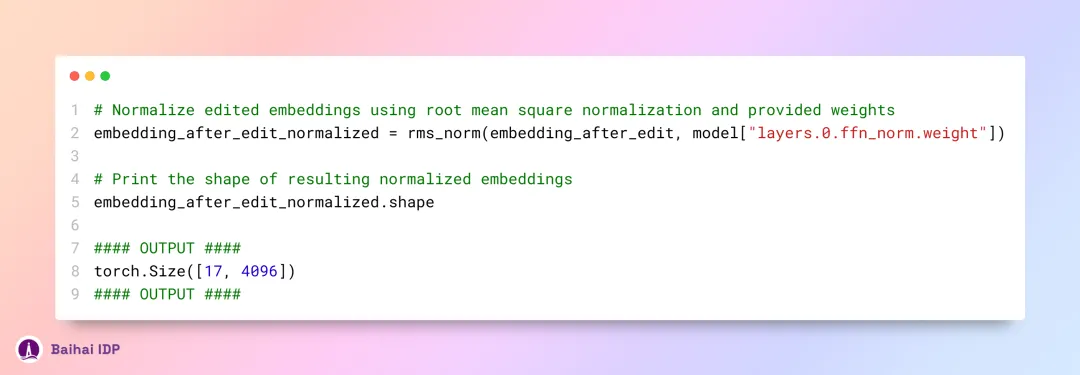
13 实现 SwiGLU 激活函数
由于我们已经对前文介绍的 SwiGLU 激活函数有所了解,现在我们将把之前探讨的那个公式运用到这里。

SwiGLU: GLU Variants Improve Transformer (https://kikaben.com/swiglu-2020/)
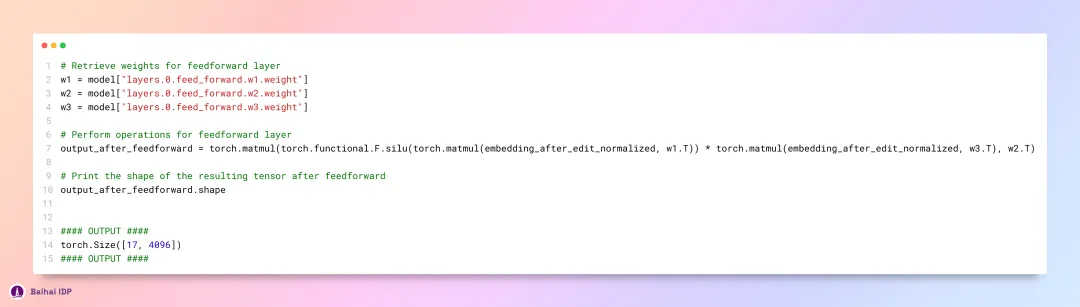
14 整合上述模型组件
现在一切准备就绪,我们需要合并代码,从而构建另外 31 个模型层。

15 见证模型如何基于文本输入生成输出
现在,我们已经得到了最终的嵌入表征,这是模型预测下一个词元(token)的依据。这一嵌入的结构与普通的词元嵌入(token embeddings)一致,为 [17x4096] ,意味着由 17 个 token 构成,每个 token 的嵌入向量维度为 4096 。

接下来,我们可以把得到的嵌入表征转换回具体的 token 值,完成从抽象表征到文本内容的解码过程。

在预测后续内容时,我们会使用上一个 token 的嵌入表征作为依据,以此推理出最可能的下一个 token 值。

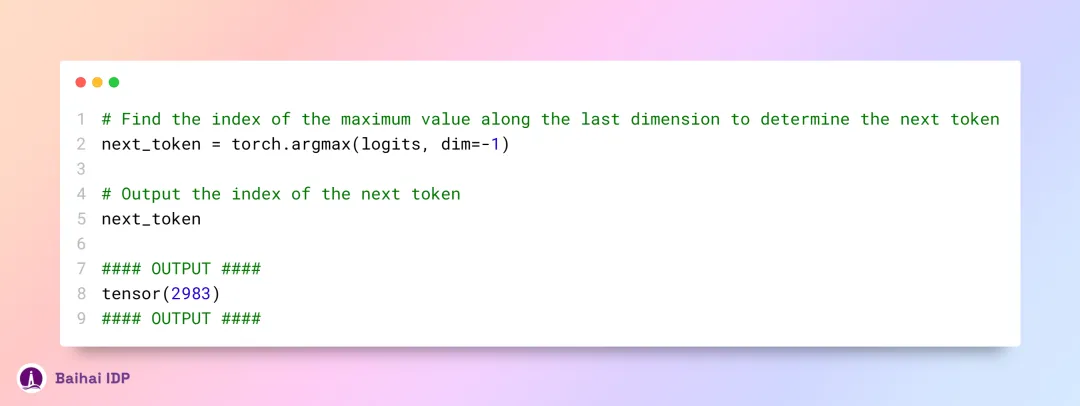
为了将一串 token IDs 转换成可读的文本,我们需要进行生成文本的解码过程,将 token IDs 对应到具体的字符或词汇上。

所以,我们输入的是“the answer to the ultimate question of life, the universe, and everything is(“生命、宇宙以及万物的终极问题的答案是”)”,而得到的模型输出正是“42”,这正是正确答案。
各位读者可以尝试各种不同的提示词文本,进行各种各样的实验。在整个程序中,只需修改这两行代码即可,其他部分可保持不变!
Thanks for reading! Hope you have enjoyed and learned new things from this blog!
Fareed Khan
MSc Data Science, I write on AI
https://www.linkedin.com/in/fareed-khan-dev/
END
参考资料
[1]https://llama.meta.com/llama3/
[2]https://mistral.ai/
[3]https://github.com/FareedKhan-dev/Building-llama3-from-scratch
[4]https://levelup.gitconnected.com/building-a-million-parameter-llm-from-scratch-using-python-f612398f06c2
[5]https://github.com/bzhangGo/rmsnorm/blob/master/rmsnorm_torch.py
[6]https://arxiv.org/pdf/2002.05202v1.pdf
[7]https://arxiv.org/pdf/2104.09864v4.pdf
[8]https://huggingface.co/join?next=%2Fmeta-llama%2FMeta-Llama-3-8B
[9]https://huggingface.co/meta-llama/Meta-Llama-3-8B
[10]https://huggingface.co/meta-llama/Meta-Llama-3-8B/tree/main/original
[11]https://huggingface.co/settings/tokens
原文链接:
https://levelup.gitconnected.com/building-llama-3-from-scratch-with-python-e0cf4dbbc306

