
- 1cmd输入python打开应用商店解决方法_输入python打开微软商店
- 2元宇宙游戏领跑,AI助力,XR发展,谁能率先如何破局?
- 3从SVN导出项目出现的乱码问题_svn拉的代码乱码
- 4windows自带远程桌面及账户设置,Linux如何远程控制windows_xfwrpd
- 5Android:启动页设置以及动态权限跳转_android 跳转权限设置
- 6Nagios check_snmp_int.pl 监控交换机端口状态和流量_nagios监控锐捷交换机
- 7【pytorch】网络模型的保存与读取_torch.save第一种保存方法读取时候要网络
- 8用YOLO玩「吃鸡」?搭载AI的自瞄外挂来了!一枪爆头!又快又准...
- 9openssl安装及使用_重新下载openssl
- 10【Error】 perl:Can‘t locate open.pm in @INC (you may need to install the open module) (@INC contains_can't locate open.pm in @inc (you may need to inst
【推荐系统】方法论 | 数据驱动 | 深度学习RS_深度学习数据驱动
赞
踩
【前沿RS的三大问题】可扩展性、稀疏性、冷启动
一、引言
- 推荐系统从搜索引擎借鉴了不少技术,如内容推荐,由亚马逊基于用户(user-based)和基于物品(item-based)的协同过滤,从内容延伸到协同关系。后来Netflix出现矩阵分解为代表的评分预测算法。
- 协同过滤评分预测,这里即通过用户历史打分记录进行训练模型,但是注意现实中隐式行为更多,即获得打分数据其实不容易(而且可能存在伪造评分、评分分布不稳定等现象),一般损失函数为均方根误差MSE。
- 如小厂只使用矩阵分解作为第一版算法,可以使用Quora 开源的 QMF 工具。能在一台 32 核、244G、640G 固态硬盘的服务器上用 20 分钟完成 10 亿非零元素,千万用户和物品的矩阵分解。
- 得到隐因子向量之后,可以用faiss等稠密向量相似计算库来搜索近邻,类似的库还有annoy,kgraph,nmslib。
- 近5年,则是深度学习和强化学习技术为主流。世界万物都倾向于相互连接构成复杂网络,少数节点聚集大量连接(马太效应),如社交网络粉丝数、网页链接引用量、电商网站商品销量等等,推荐系统就是要用技术对抗这种不平等。
- 企业中什么时候需要建立推荐系统:
- 业务有流动和转化的用户,同时内容是持续稳定的增长,且用户和内容都有一定的存量,但具体的增长速度和存量的规模需要结合自己的业务进行判断,这个东西目前还没有办法进行量化,
- 前期可以使用一些简单的推荐策略进行推荐,然后随着业务发展可以慢慢进行策略到算法的迭代,继而搭建推荐架构,为推荐算法进行服务。
- 常见的线上业务指标:点击率、GMV、用户停留时长等
二、推荐算法工程师
2.1 推荐团队
(1)团队分工
- 算法工程师,承担的是数据科学家和机器学习工程师的双重职责,主要职责是清洗数据,训练离线推荐模型,开发算法接口,评估指标。
- 软件开发工程师,承担算法之外的开发任务,例如数据库的搭建维护,API 接口的开发,日志的收集,在线系统的高可用等,当然“有下限的团队”可以适当简陋些,不用考虑高性能。
- 其他非技术角色,如果是“有下限团队”的话,这一项也可以省略,如果涉及了跨部门合作,或者你不幸被老板提出各种“推得不准”的伪 Bug,那么你就需要一个这样的角色去充当工程师港湾,来阻挡外界的风雨。
(2)推荐算法工程师的核心素质:
- 有较强的工程能力,能快速交付高效率少 Bug 的算法实现,虽然项目中不一定要写非常大量的代码;
- 有较强的理论基础(如数学的高数统计概率线代、信息论等),能看懂最新的论文,虽然不一定要原创出漂亮的数学模型;
- 有很好的可视化思维,能将不直观的数据规律直观地呈现出来(如python的matplotlib、R语言中的ggplot2、linux命令中的Gnuplot、windows中的excel等),向非工程师解释清楚问题所在,原理所在。
- 学习能力,沟通能力,表达能力。
(3)推荐算法工程师的工作流程:
- 问题提出 : 清楚领导提出的问题,或者自己发现问题。
- 数据和业务探索 : 在动手解决这个问题之前,我们一定要花时间弄清楚业务的相关逻辑,并且动手用一些脚本程序弄清楚自己可利用数据的数据量、数据特点、提取出一些特征并分析特征和标签之间的相关性。
- 初始解决方案 : 根据探索结果提出初始解决方案。
- 解决方案调优 :在初始解决方案之上,进行技术选型和参数调优,确定最终的解决方案。
- 工程落地调整 :针对工程上的限制调整技术方案,尽量做到能简勿繁,能稳定不冒险。
- 生产环境上线 : 进行最终的调整之后,在生产环境上线。
- 迭代与复盘 : 根据生产环境的结果进行迭代优化,并复盘这个过程,继续发现问题,解决问题。
- 不迷信所谓的权威模型,不试图寻找万能的参数,从业务出发,从用户的真实行为出发,才能够构建出最适合你业务场景的推荐模型 。
- 寻找到最合适的参数,并且可以完成生产环境的工程实现。

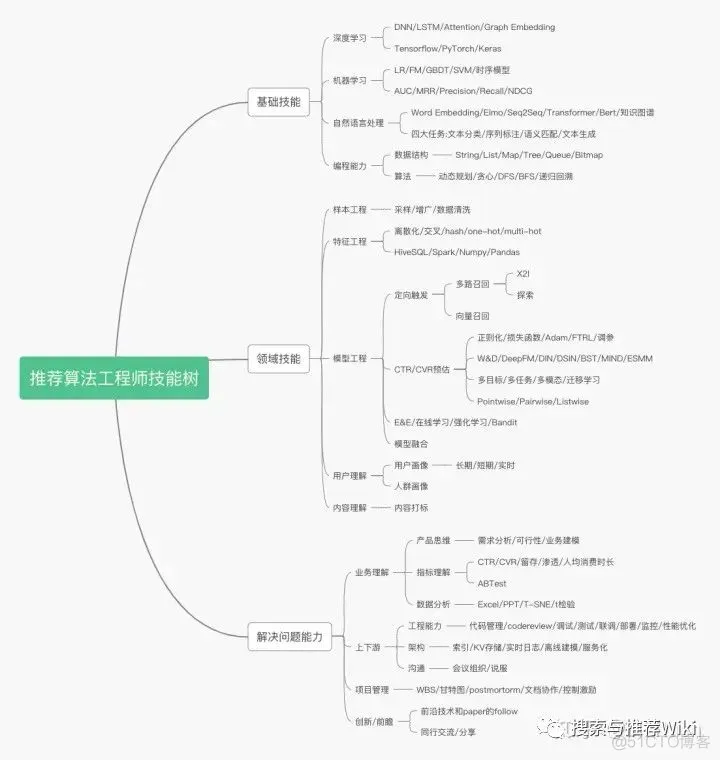
2.2 中小厂中避免重复造轮子
大厂业务场景复杂、数据量大,很多时候挖地基开始研发RS,中小厂则是以先做出来、快速达到baseline后迭代为主要目标,选择开源项目需要选择自己熟悉的语言、大公司背书的、有成功实施过的、有活跃社区氛围等。
2.3 目标思维和不确定思维
两个思维模式:目标思维和不确定思维:
- 目标思维:量化指标,如机器学习/深度学习模型中的AUC指标等。
- 传统的软件是一个信息流通管道,从信息生产端到信息消费端的通道,比如一款内容 App,写内容的可以正常记录,读内容的可以流畅加载,无论多大的并发量都扛得住,这就是一个正常的产品了。
- 推荐系统看做一个函数,这个函数的输入有很多:UI、UE、数据、领域知识、算法等等,输出则是我们关注的指标:留存率、新闻的阅读时间、电商的 GMV、视频的 VV 等等。
- 不确定性思维:概率眼光看待结果
- 大多数推荐算法都是概率算法,无法得到确切精准推荐结果,如出现某个不合适推荐,老板们会问“为什么会出现这个”,而不确定思维则是“出现这个的可能性是多大”。
- 本身出现意外的推荐也是有益的,可以探索用户的新兴趣,这属于推荐系统的一个经典问题:EE 问题。
三、推荐系统的轮子
3.1 内容分析
基于内容的推荐,主要工作集中在处理文本,或者把数据视为文本去处理。文本分析相关的工作就是将非结构化的文本转换为结构化。主要的工作就是三类:主题模型、词嵌入、文本分类。

这其中 FastText 的词嵌入和 Word2vec 的词嵌入是一样的,但 FastText 还提供分类功能,这个分类非常有优势,效果几乎等同于 CNN,但效率却和线性模型一样,在实际项目中久经考验。LightLDA 和 DMWE 都是微软开源的机器学习工具包。
3.2 协同过滤和矩阵分解
虽然是深度学习时代了,但是传统协同过滤和矩阵分解很成熟。基于用户、基于物品的协同过滤,矩阵分解,都依赖对用户物品关系矩阵的利用,常用的有:
KNN 相似度计算;SVD 矩阵分解;SVD++ 矩阵分解;ALS 矩阵分解;BPR 矩阵分解;低维稠密向量近邻搜索。
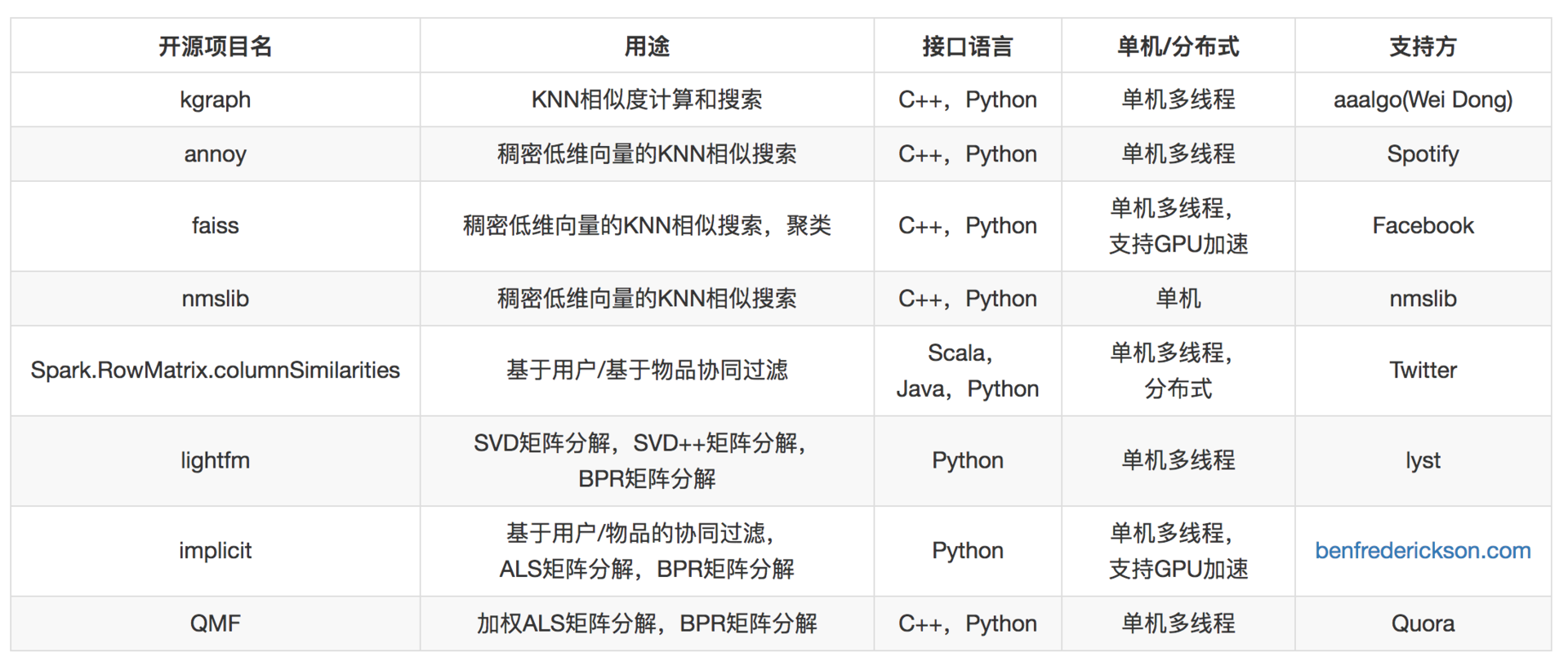
- 基础协同过滤算法,通过计算矩阵的行相似和列相似得到推荐结果。
- 矩阵分解,得到用户和物品的隐因子向量,是低维稠密向量,进一步以用户的低维稠密向量在物品的向量中搜索得到近邻结果,作为推荐结果,因此需要专门针对低维稠密向量的近邻搜索。
3.3 模型融合
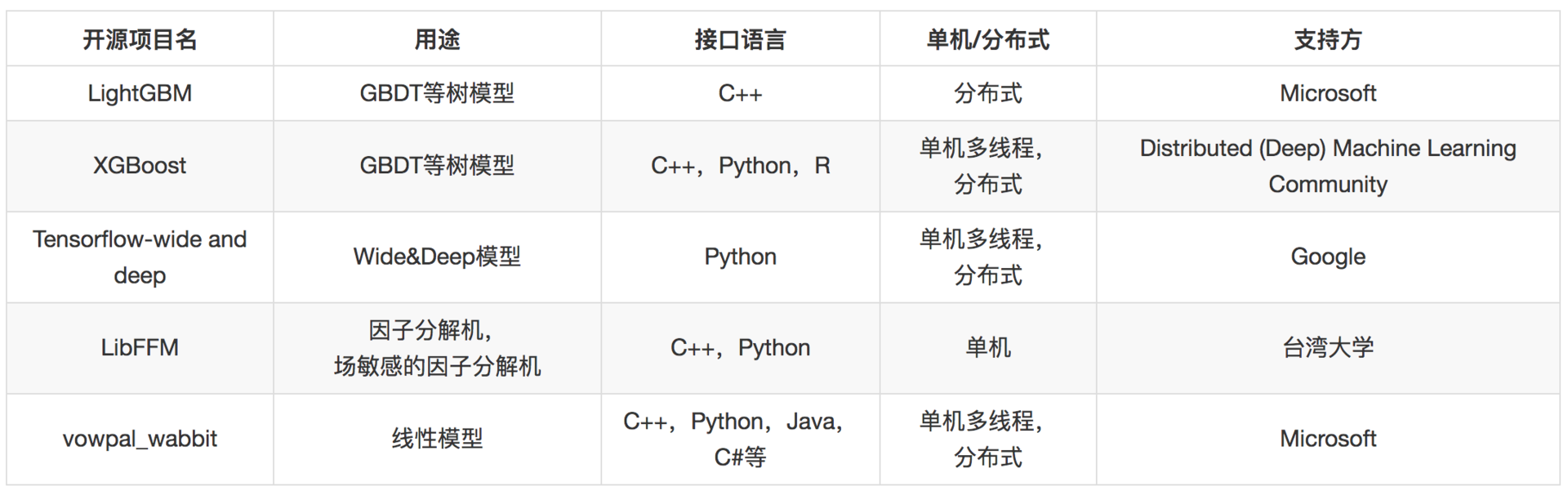
- 线性模型复杂在模型训练部分,这部分可以离线批量进行,而线上预测部分则比较简单,可以用开源的接口,也可以自己实现。
- 另外还有GBDT+LR(通过GBDT构建非线性特征,即,然后送入LR进行做CTR)等。
- 比如说,有一天你发现“ID 为 233 的用户喜欢买各种钢笔”这个事实,它可以有两个特征组合出来,一个是“ID 为 233”,是一个布尔特征,另一个是“物品为钢笔”,也是一个布尔特征,显然构造一个新特征,叫做“ID 为 233 且物品为钢笔”,即非线性特征。
3.4 深度学习
最初的鼻祖算法是ALS+MLP,即用户向量和物品向量分别经过全连接层(dense layer,线性层+非线性层)后的结果,进行点乘且sigmoid运算,通过损失函数计算后反向传播更新参数,进行评分的预测。
- 召回:各种embedding嵌入技术,如item2vec、GNN embedding等。
- 排序:CTR点击率预估(deepfm、等)、多任务学习模型等,还有时间序列上的深度学习模型,如transformer系列。在TensorFlow上甚至能直接调用wide&deep的模型API,参考官方文档:tf.keras.experimental.WideDeepModel。
- 增强学习在模型更新、工程模型一体化方向上的应用,它让推荐系统可以在实时性层面更强。

(1)用户理解

(2)召回
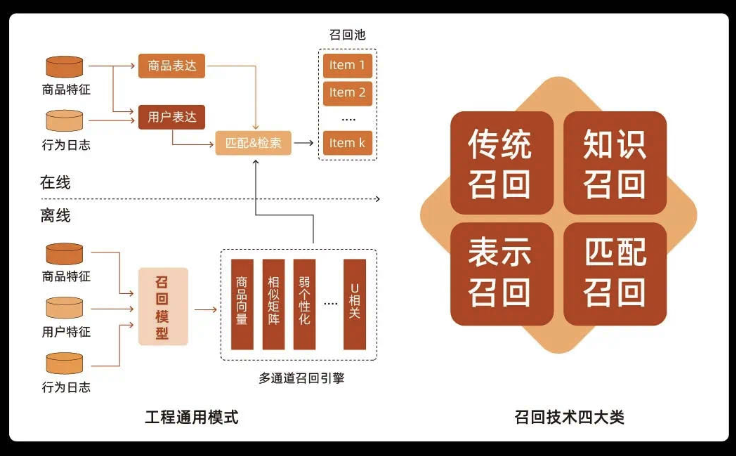
1)传统召回

2)知识召回
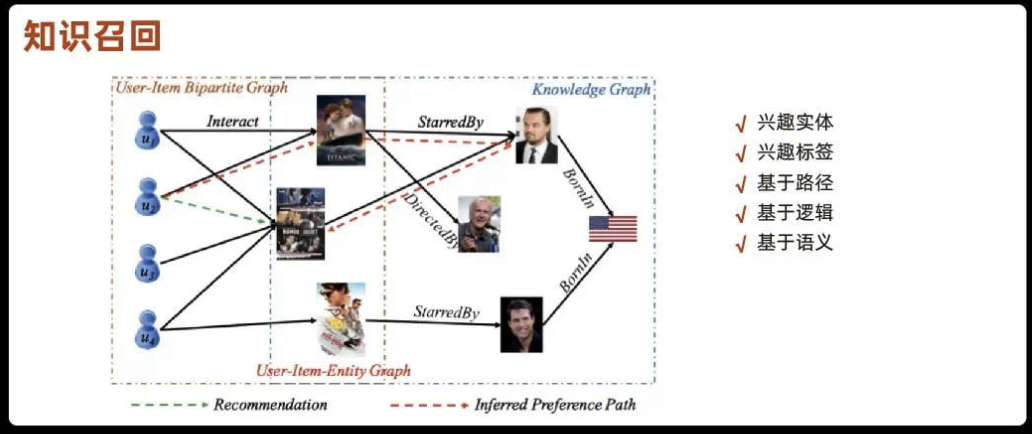
可以结合知识图谱 社交网络的推荐:

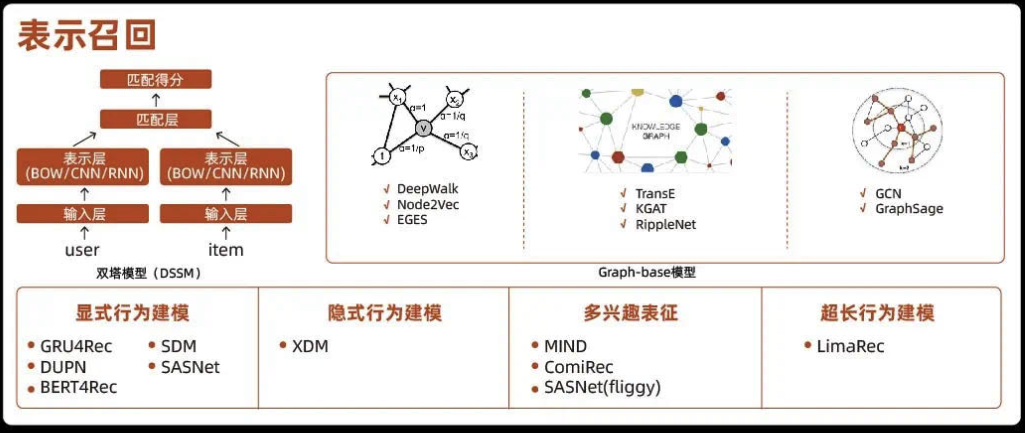
3)表示召回
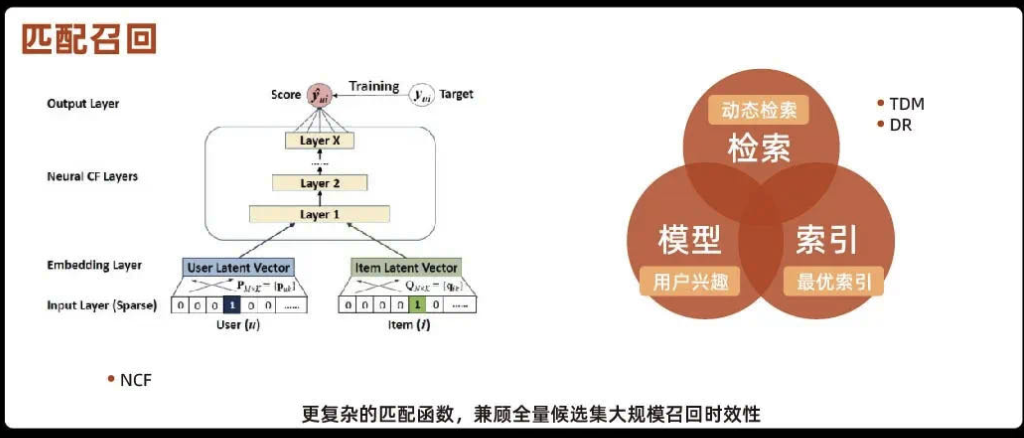
4)匹配召回
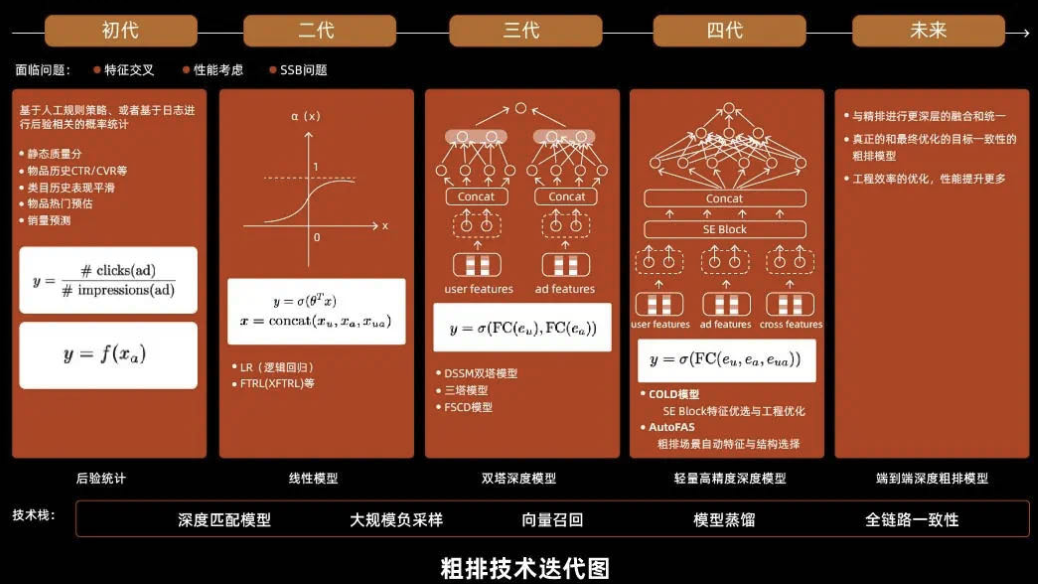
(3) 排序
促排技术迭代图:
精排模型迭代图:
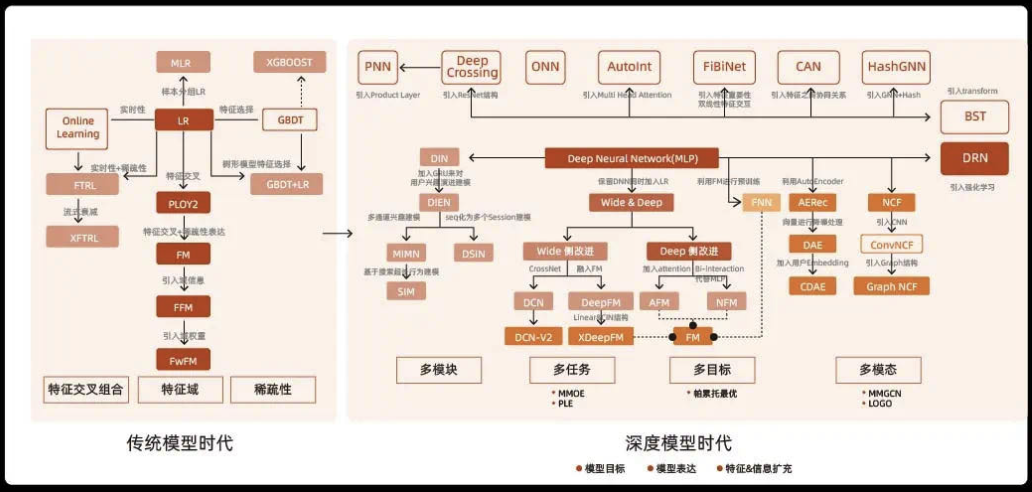
(4)其他技术方向
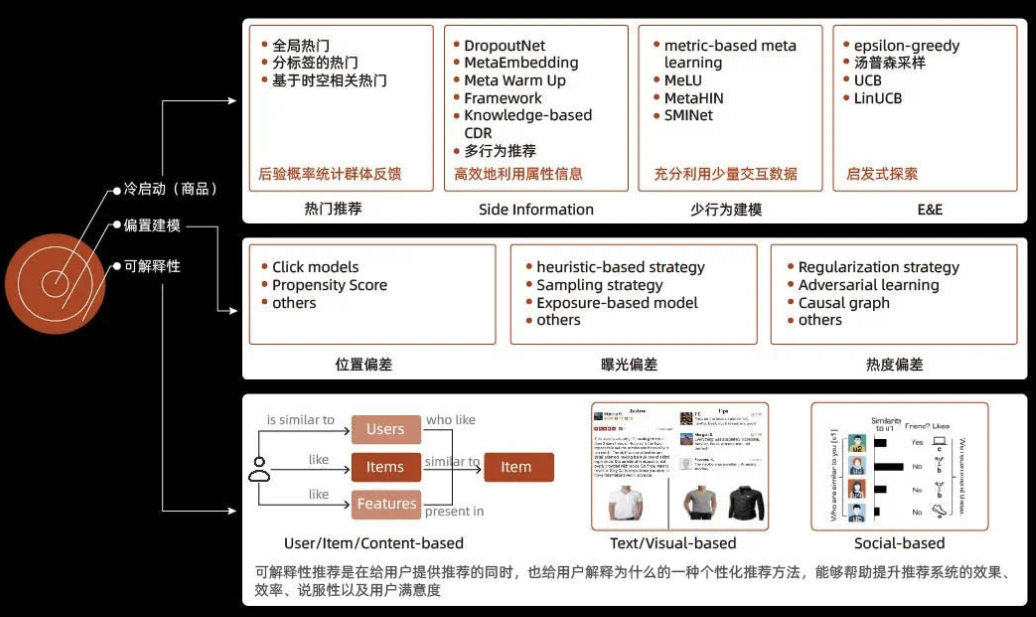
3.5 完整推荐系统
(1)完整指的是包含推荐算法实现、存储、接口。可以选择各个模块的开源项目,再将其组合成自己的推荐系统,便于诊断错误。

(1)两个常见的推荐模块:
1)猜你喜欢:各种召回方法,多路召回策略。
2)个性推荐:CTR排序,主流是基于深度学习方法,如下图所示:
- 一般先用spark进行大数据处理和特征工程,得到的线上特征存入redis;训练样本则送入TensorFlow进行离线模型训练(一些模型可以用spark进行模型训练);
- 训练并导出了 如NeuralCF 的模型文件。然后使用 TensorFlow Serving 载入模型文件,建立线上模型服务 API(TensorFlow serving API)。
- 推荐服务器的排序层从 Redis 中取出用户特征和物品特征,组装好 JSON 格式的特征数据,发送给 TensorFlow Serving API;
- 根据返回的预估分数进行排序,最终生成“猜你喜欢”的推荐列表。

上图的Java jetty推荐服务器内部专门开发特征加工模块,进行一些人工的处理。比如点击率特征,实际上“点击”会包含多种点击行为,各种行为如何融合,需要灵活配置。既不能放在离线存(更新不便),也不能放在tf serving里(逻辑多了太慢)
- 1、tf serving只负责简单的模型运算;
- 2、离线redis等负责通用特征数据的存储;
- 3、推荐系统服务器进行数据加工
(2)系统的整体评估

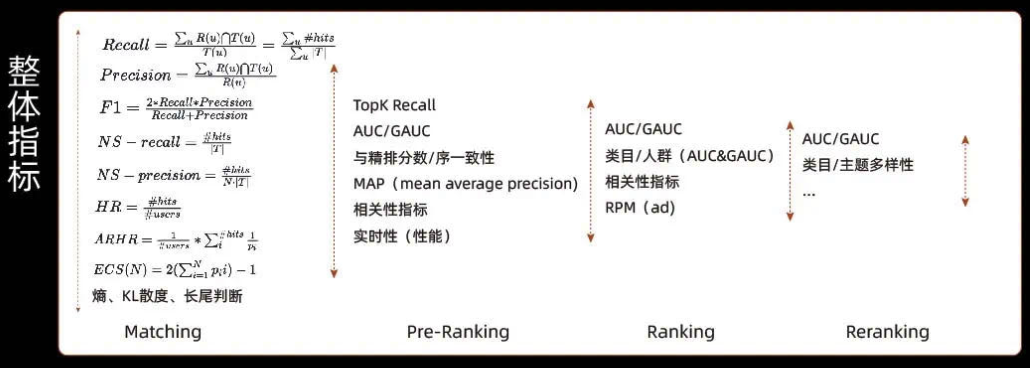
四、数据驱动
4.1 数据用途
数据采集,分为三种用途:
- 报表统计:为了统计一些核心的产品指标,例如次日留存,七日留存等,一方面是为了监控产品的健康状况,另一方面是为了对外秀肌肉。
- 数据分析:用于指导产品设计、指导商业推广、指导开发方式。走到这一步的数据采集,数据驱动产品。
- 机器学习:数据用以训练模型。
4.2 数据采集(推荐系统收集日志)

包括数据模型、数据存储、元素、怎么收集、质量检验等部分。

4.3 Netflix的推荐技术架构
Netflix(一家流媒体公司) 的推荐系统的经典架构图,判断哪些是数据部分,哪些是模型部分。

- 数据部分:event distribution, hadoop, query results, netflex.hermes, user event queue, netflix.manhattan.
- 模型部分:model training, models, online computation, online service, algorithm service.
- nearline computation也属于数据部分,正中央的evcache等几个数据库可以看作数据部分和模型部分的接口。
五、内容推荐
5.1 构建用户画像
很多高大上ppt会介绍用户画像,用标签云绘制人形状,周围列出若干人口统计学属性,以表达用户画像概念,看似炫酷但没啥用。在算法角度,用户向量化后的结果即user profile(user embedding)。一般全量item很多,无法为每个用户计算对全部item的评分,所以需要先召回后排序,user embedding一般用在召回。
5.2 基于文本数据构建用户画像
用户这一端比如说有:注册资料中的姓名、个人签名;发表的评论、动态、日记等;聊天记录(不要慌,我举个例子而已,你在微信上说的话还是安全的)。
物品这一端比如说有:物品的标题、描述;物品本身的内容(一般指新闻资讯类);物品的其他基本属性的文本。文本数据是互联网产品中最常见的信息表达形式,数量多、处理快、存储小。
(1)结构化文本
- 关键词提取:最基础的标签来源,也为其他文本分析提供基础数据,常用 TF-IDF 和 TextRank
- 实体识别:人物、位置和地点、著作、影视剧、历史事件和热点事件等,常用基于词典的方法结合 CRF 模型。
- 内容分类:将文本按照分类体系分类,用分类来表达较粗粒度的结构化信息。
- 文本 :在无人制定分类体系的前提下,无监督地将文本划分成多个类簇也很常见,别看不是标签,类簇编号也是用户画像的常见构成。
- 主题模型:从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况,也很实用,其实这也是一种聚类思想,主题向量也不是标签形式,也是用户画像的常用构成。
- 嵌入:“嵌入”也叫作 Embedding,从词到篇章,无不可以学习这种嵌入表达。嵌入表达是为了挖掘出字面意思之下的语义信息,并且用有限的维度表达出来。
(2)标签选择
- 最常用的2个方法:卡方检验(CHI)和信息增益(IG)。
- 基本思想是:把物品的结构化内容看成文档;把用户对物品的行为看成是类别;每个用户看见过的物品就是一个文本集合;在这个文本集合上使用特征选择算法选出每个用户关心的东西。
5.3 超越标签的内容推荐系统

Reference
[1] GBDT+LR原论文:http://quinonero.net/Publications/predicting-clicks-facebook.pdf
[2] 推荐系统 贝壳算法负责人.陈开江
[3] Bag of Tricks for Efficient Text Classification.Facebook(fasttext训练词嵌入向量)
[4] The Learning Behind Gmail Priority Inbox.Google(介绍早期Gmail基于文本和用户行为建模思路)
[5] Recommender Systems Handbook(第三章,第九章)
[6] 《文本上的算法: 深入浅出自然语言处理》
[7] LDA 数学八卦.Rickjin(@靳志辉)
[8] Amazon.com recommendations: item-to-item collaborative filtering
[9] Slope One Predictors for Online Rating-Based Collaborative Filtering(Slope One算法)
[10] Item-Based Collaborative Filtering Recommendation Algorithms
[11] Matrix Factorization and Collaborative Filtering
[12] BPR- Bayesian Personalized Ranking from Implicit Feedback(更关注推荐结果的排序好坏)
[13] Collaborative Filtering for Implicit Feedback Datasets.Yifan Hu(处理隐式反馈行为的CF模型)
[14] Matrix Factorization Techniques For Recommender Systems
[15] Adaptive Bound Optimization for Online Convex Optimization(FTRL,CTR优化)
[16] Introduction to Bandits- Algorithms and Theory Part 1- Bandits with small sets of actions
[17] An Empirical Exploration of Recurrent Network Architectures
[18] TencentRec:Real-time Stream Recommendation in Practice
[19] Pattern Recognization and Machine Learning
[20] 对象存储 S3 在分布式文件系统中的应用
[21] System Architectures for Personalization and Recommendation
[22] 回顾经典,Netflix的推荐系统架构.王喆
[23] paddle.在工业实践中的推荐系统

