
- 1线程中task取消_第四节:Task启动以及Task、TaskFactory线程等待和延续解决方案
- 2用VS Code配置Python开发环境(最简便的步骤教程)_vscode配置python环境
- 3ubuntu无法更新的问题,提示错误Err http://mirrors.163.com trusty Release.gpg Could not resolve ‘mirrors.163.com
- 4【AI白身境】深度学习中的数据可视化_深度学习与可视化的联系
- 5opencv编译带cuda_opencv cuda 编译
- 6Ionic文件选择插件filechooser选择图片上传的问题_window['filepath'].resolvenativepath 不存在
- 7OpenCV安装报错 libgio-2.0.so.0: undefined reference to `g_source_set_static_name‘_libgio-2.0.so.0 undefined system:g_uri_join
- 8计算机三级网络技术考过指南_计算机三级 网络技术过级
- 9华为手机使用谷歌play点击登录时,显示无法连接此网络_华为手机下载gool play后显示设备未连接到网络
- 10解决Qt6在线安装时出现掉线问题_qt6安装失败
Latent Diffusion Models / Stable Diffusion(LDM)
赞
踩
High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022)
https://arxiv.org/abs/2112.10752
latent-diffusion
stable-diffusion
cross-attention(用于多模态任务)
Cross-attention vs Self-attention:Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列,也就是所谓的输入不同,但是除此之外,基本一致。
假设有文本数据和图像数据:
1.文本通过一个Transformer编码器处理,输出作为查询q向量。
2.图像通过CNN处理,输出经过线性变换生成键k和值v向量。
3.计算文本查询向量q与图像键向量k的点积,得到注意力分数。
4.使用这些分数对图像的值向量v进行加权,生成最终输出。
DDPM和LDM的区别和共同点

LDM基本思路:【论文将这个方法称之为感知压缩(Perceptual Compression)】:在AutoEncoder的编码器 E 对图片进行压缩 ==> 然后在潜在表示空间上做diffusion操作 ==> 最后再用解码器 D 恢复到原始像素空间
回顾DDPM:Diffusion Model(DDPM)训练过程就是训练UNet预测每一步的noise,从而逐步还原原始图像。原始图像空间的Diffusion Model目标函数如下:
共同点:这里函数 的参数使用神经网络UNet拟合,UNet在DDPM和LDM中的作用都是预测噪声。
区别:
1. 加入Autoencoder(上图中左侧红色部分),使得扩散过程在latent space下,提高图像生成的效率;
2. 加入条件机制,能够使用其他模态的数据控制图像的生成(上图中右侧灰色部分),其中条件生成控制通过Attention(上图中间部分QKV)机制实现。
论文贡献
- Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
- 相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
- 论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
- 论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
使用Autoencoder减少需要的算力(感知压缩)
为了降低训练扩散模型的算力,LDMs使用一个Autoencoder去学习能尽量表达原始image space的低维空间表达(latent embedding),这样可以大大减少需要的算力。
自编码器的方法有几个优点:
- 通过离开高维图像空间,获得计算效率高得多的diffusion models,因为采样是在低维空间上进行的。
- 利用了从其UNet架构[71]继承而来的diffusion models的归纳偏差,这使它们对具有空间结构的数据特别有效,从而减轻了对之前方法所要求的激进的、降低质量的压缩水平的需求。
- 得到了通用的压缩模型,其潜空间可用于训练多个生成模型,也可用于其他下游应用,如单图像片段引导的合成。
Latent Diffusion Models整体框架如上图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器 D )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
下面我们针对感知压缩、扩散模型、条件机制的具体细节进行展开。
条件图像生成器
DDPM的UNet可以根据当前采样的t预测noise,但没有引入其他额外条件。但是LDM实现了“以文生图”,“以图生图”等任务,就是因为LDM在预测noise的过程中加入了条件机制,即通过一个编码器(encoder)将条件和Unet连接起来。
将条件嵌入UNet中
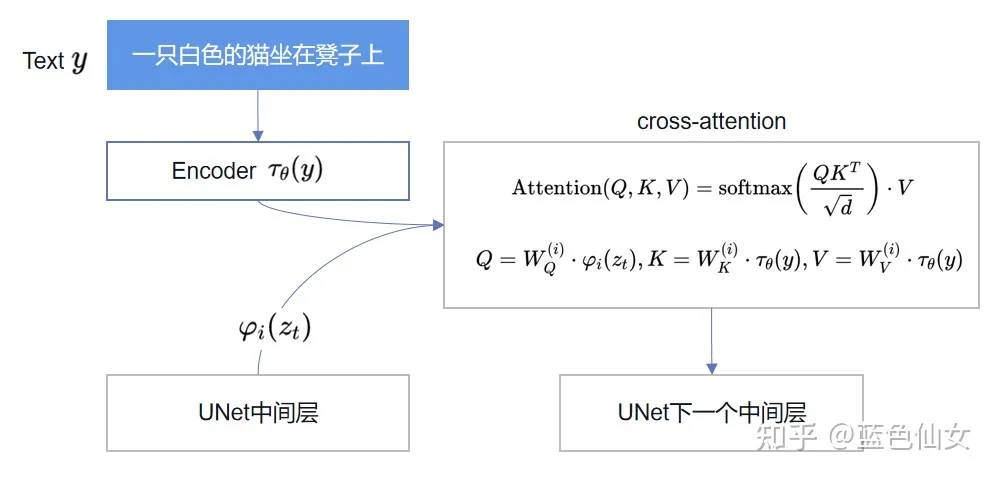
这里引入一个新的encoder E(这个是用于条件编码的encoder,和上面提到的用于降维的是不同的)来将条件 y 映射到 T(y)
LDM训练阶段
训练阶段每个模块之间的交互如图:

LDM推理阶段


