
- 1解决:Error creating bean with name 'elasticsearchClient', AvailableProcessors is already set to [4]_elasticsearchclient is already set to 64
- 2论坛上的所有泡MM技巧_摩天轮论坛
- 3自动化测试之JUnit单元测试框架_junit框架
- 4Android studio:打开应用程序闪退的问题_androidstudio打开工程闪退崩溃
- 5【Java异常处理】java.lang.NoClassDefFoundError: org/jaxen/JaxenException
- 6Python requests模块安装及使用教程图解_安装requests模块
- 7【城南】如何识别AI生成图?视觉AIGC伪造检测技术综述_aigc检测技术
- 8Linux虚拟内存
- 9CSS实现8种炫酷按钮_css按钮立体效果
- 10【微信小程序】制作个人信息页面_微信小程序个人信息页面
OpenMMLab 实战营打卡 - 第 四 课 目标检测算法基础_特征图输入所述检测头网络后,通过所述检测头网络进入分类、回归、中心点、角度四
赞
踩
(四)计算机视觉之目标检测算法基础
目录
4.非极大值抑制 Non-Maximum Suppression
5.边界框回归 Bounding Box Regression
4.特征金字塔网络 Feature Pyramid Network (2016)
2.YOLO: You Only Look Once (2015)
3.SSD: Single Shot MultiBox Detector (2016)
六、无锚框目标检测算法 Anchor-free Detectors
2.FCOS, Fully Convolutional One-Stage (2019)
前言
OpenMMLab AI实战营第四课!目标检测是计算机视觉中最重要,也是最热门的工作,它的主要任务是用方框标出图片中的“猫”。课程链接:4 目标检测算法基础_哔哩哔哩_bilibili
一、目标检测是什么?
给定一张图片,框出所有兴趣目标同时预测目标类别。

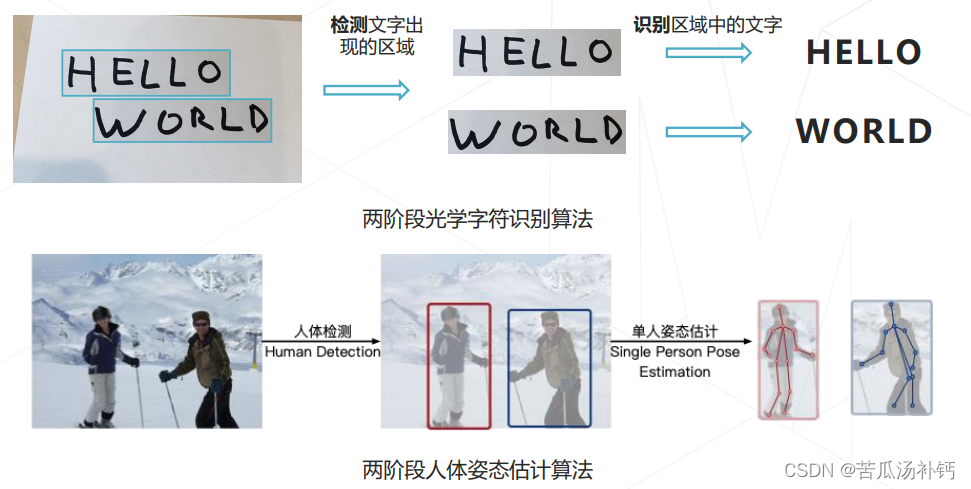
目标检测的应用:人脸识别,身份识别、属性分析等;智慧城市,垃圾检测(保持城市干净整洁)、非法占道检测、违章停车检测、自动服务等;自动驾驶,环境感知-->路径规划与控制;下游视觉任务,光学字符识别(定位+识别)、人体姿态识别等。
1.目标检测VS图像分类
检测,是在一般的场景,目标所在位置、数量、大小均不固定。
分类,是一个更受限的环境,通常情况下,只有一个物体、位于图像中央、占据主要面积。
目标检测与图像分类共同点就是,需要算法“理解”图像的内容-->深度神经网络实现。同样都需要模型对数据、图像中的内容进行一个理解。深度神经网络在图像分类上从AlexNet开始取得了非常和的成绩,目标检测遵循相同套路。

2.检测最朴素方法——滑窗 Sliding Window
首先设定一个固定大小的窗,然后拿这个窗去图像上去扫,有点像算卷积那样。然后我们扫到的位置,把窗内的这个块给抠下来,送到一个神经网络去预测里面的物体是什么(类别)。预测完一个位置后,再滑动10像素预测其他位置,重复操作。在网络训练好的前提下,遍历图像所有位置后,可以找到所有物体的位置并识别类别。

为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口扫描图片。
(1)滑窗的效率问题
效率是滑窗Sliding Window的致命问题,考虑1000x600大小的图像,设定100x100的窗口,每滑动20像素分类一次。仅推理一张图片,需要对46x26将近1200个窗口进行分类。若使用不同大小的窗口,分类次数成倍增加。所以有着不可接受的计算成本,实用性太低。
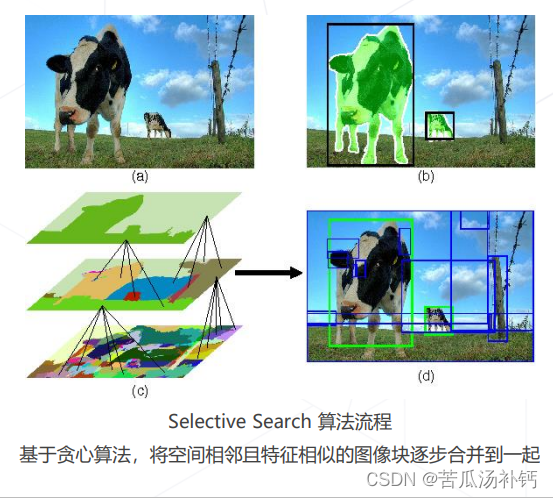
改进思路1:使用启发式算法替换暴力遍历。例如R-CNN,Fast R-CNN中使用Selective Search 产生提议框依赖外部算法,系统实现复杂,不能训练,难以联合优化性能。
改进思路2:减少冗余计算,使用卷积网络实现密集预测目前普遍采用的方式。实际上,卷积本身也是一种滑窗,而且有一个参数共享的理念,所以更容易优化。
(2)改进
区域提议,基于图像颜色或底层特征,找出可能含有物体的区域,再送给神经网络识别。相比于普通滑窗,减少框的个数且保证召回率。
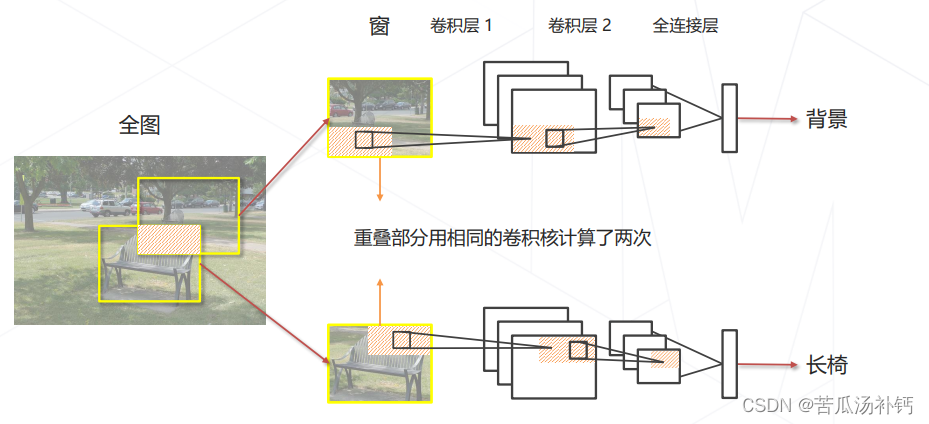
分析滑窗中的重复计算,假设用于分类的卷积网络只有2层:
我们去分析两个框的重合部分。在第一张图里预测的时候被卷积核扫过得到第一层特征,然后又扫了一遍得到第二层特征。而在第二张图里,只有位置改变,网络实际上相同,我们用相同网络的相同卷积扫了相同的部分图像,只不过在不同位置说生成了相同的特征,这部分实际上是冗余的。于是,我们考虑从这个卷积网络的的计算上设计某种算法把重复的去除。
改进思路:用卷积一次性计算所有特征,再取出对应位置的特征完成分类。
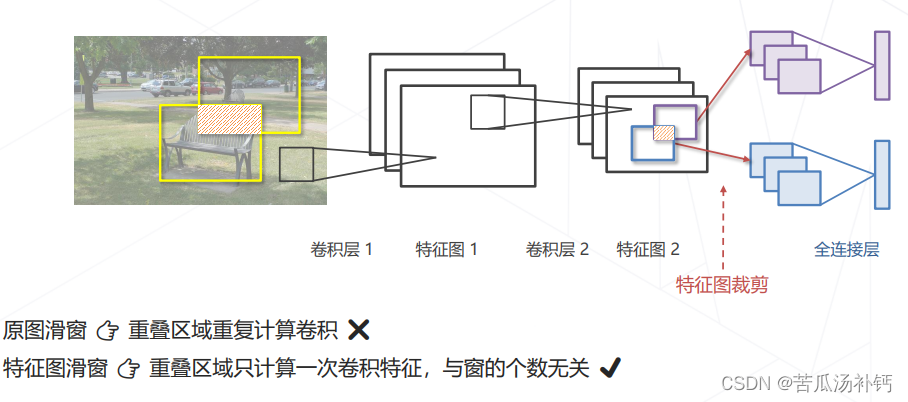
在特征图上进行密集预测,密集预测实际上是一种隐式的滑窗方法,计算效率远高于滑窗。这里的窗并非我们手动设置的,而是网络去定义的。

3.目标检测的基本范式
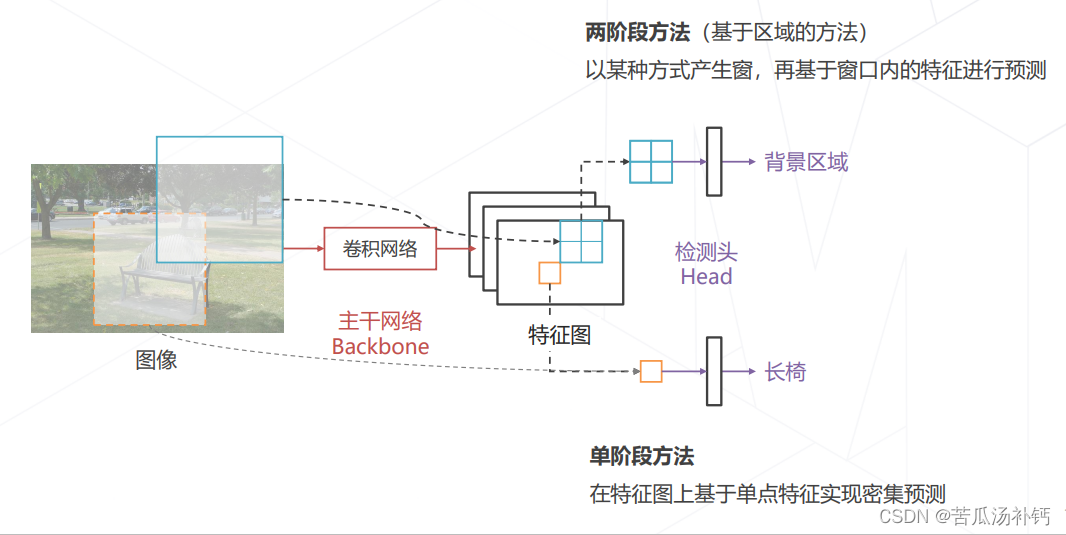
主干网络Backbone,输入图像产生一个多通道的特征图。基于特征图的特征去产生类别预测的,叫检测头Head。
4.目标检测技术的演练
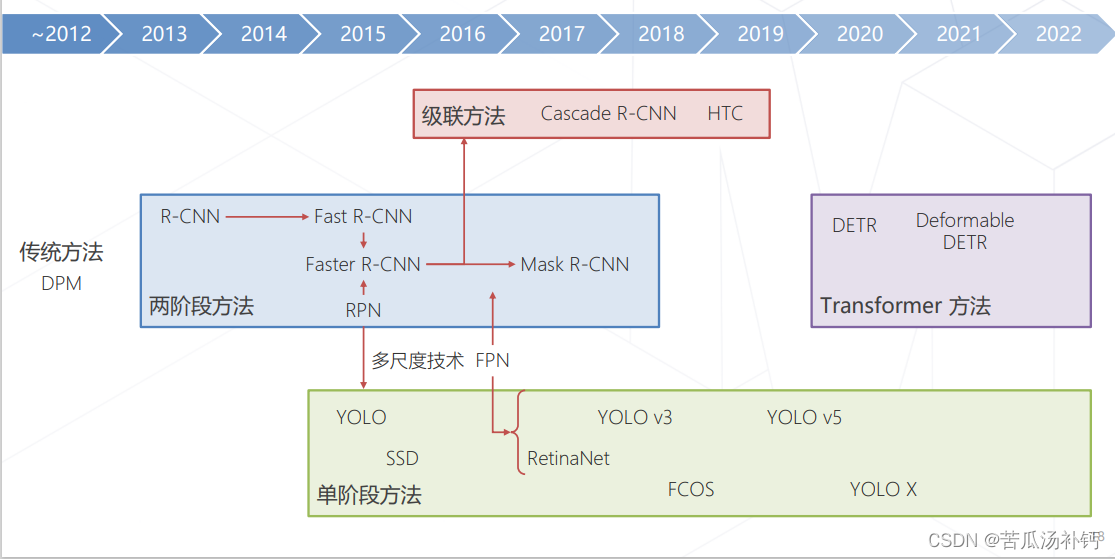
深度学习出现以前,目标检测巅峰算法叫DPM(Deformable Part Model)。深度学习出来以后,2012 年卷积神经网络(Convolutional Neural Networks, CNN)的提出开始,不断有基于深度学习的目标检测算法被提出,分单阶段检测和两阶段检测算法。两阶段精度高但速度慢,单阶段速度快但精度稍逊。近几年随着Transformer算法的兴起,基于Transformer的一些优秀算法陆续出现。

二、基础知识
1.框,边界框(Bounding Box)
框泛指图像上的矩形框,边界横平竖直。描述一个框需要4个像素值:方式①左上右下边界坐标(l,t,r,b);方式②中心坐标和框的长宽(x,y, w, h)。
边界框通常指紧密包围感兴趣物体的框,检测任务要求为图中出现的每个物体预测一个边界框。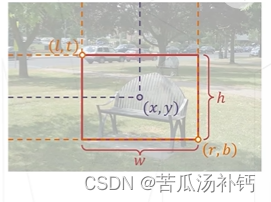
框相关的概念:
- 区域(Region):框的同义词。
- 区域提议(Region Proposal,Proposal) 指算法预测的可能包含物体的框,某种识别能力不强的算法的初步预测结果。
- 感兴趣区域(Region of Interest,RoI) 当我们谈论需要进一步检测这个框中是否有物体时,通常称框为感兴趣区域。
- 锚框(Anchor Box,Anchor) 图中预设的一系列基准框,类似滑窗,一些检测算法会基于锚框预测边界框。
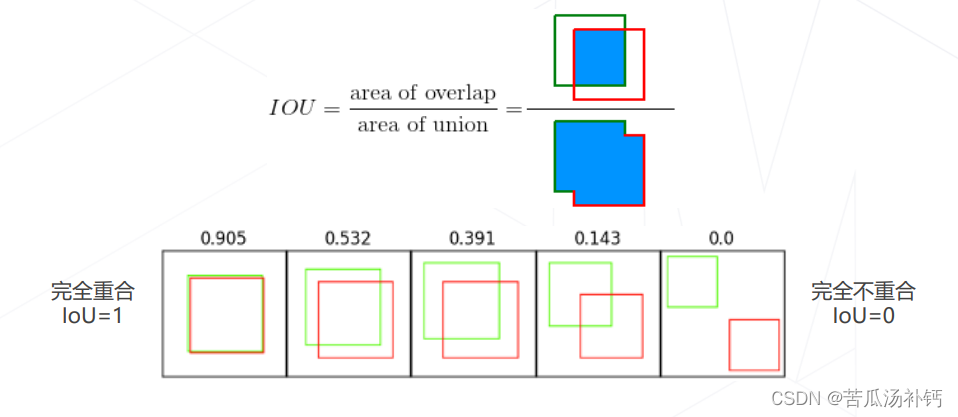
2.交互比Intersection Over Union
交互比(Intersection Over Union,IoU),定义为两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标,是模型产生的目标窗口与原来标记窗口的交叠率。
3.置信度Confidence Score
置信度(Confidence Score):模型认可自身预测结果的程度,通常需要为每个框预测一个置信度。大部分算法取分类模型预测物体属于特定类别的概率,部分算法让模型独立于分类单独预测一个置信度。我们倾向认可置信度高的预测结果。

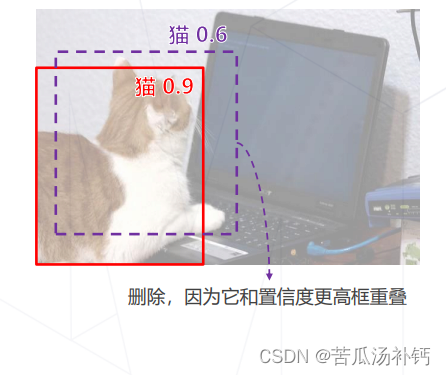
4.非极大值抑制 Non-Maximum Suppression
滑窗类算法通常会在物体周围给出多个相近的检测框。这些框实际指向同一物体,只需要保留其中置信度最高的。通过非极大值抑制(NMS)算法实现:

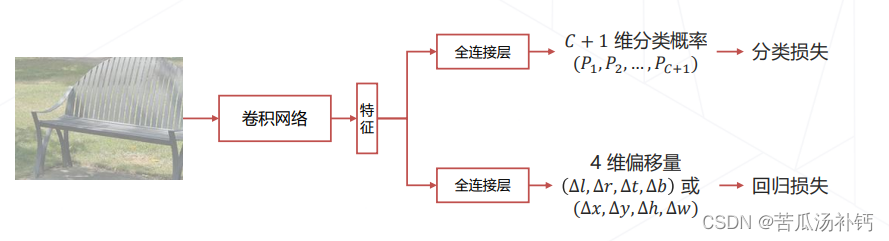
5.边界框回归 Bounding Box Regression
问题:滑窗(或其他方式产生的基准框)与物体精准边界通常有偏差。
处理方法:让模型在预测物体类别同时预测边界框相对于滑窗的偏移量
6.边界框编码 Bbox Coding
边界框的绝对偏移量在数值上通常较大,不利于神经网络训练,通常需要对偏移量进行编码,作为回归 模型的预测目标。

三、两阶段目标检测Two-stage Detectors
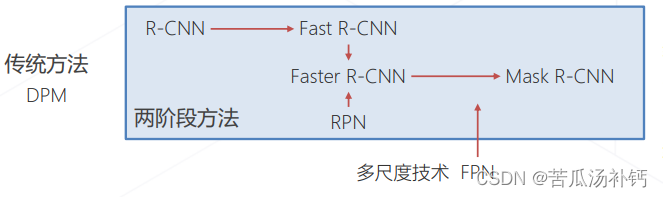
1.两阶段算法概述
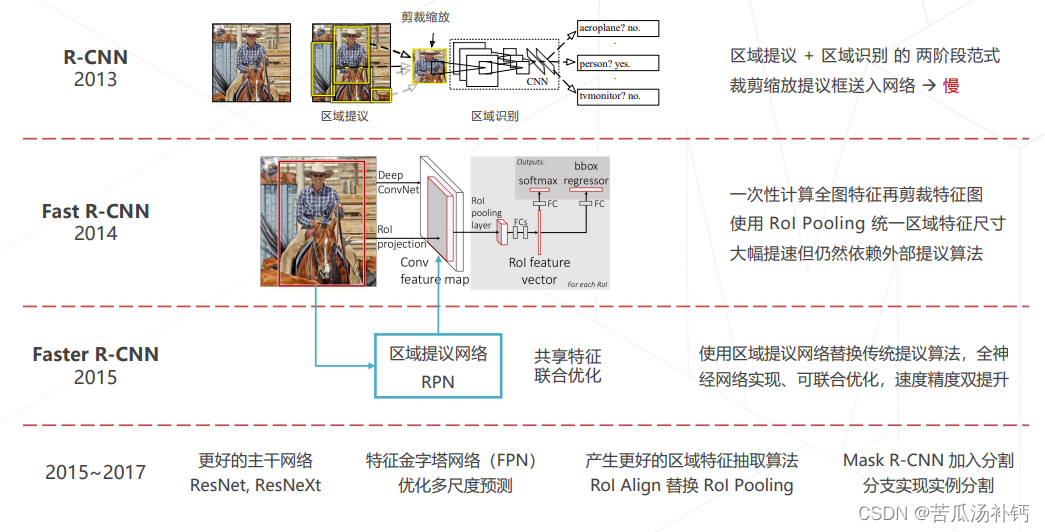
两阶段的检测范式最早由 R-CNN 确立,因包含区域提议和区域识别两个阶段得名。经历一些列发展到 Faster R-CNN 和 Mask R-CNN 逐渐成熟。结合比较先进的主干网络和多尺度技术可以达到 比较优越的检测精度,使用广泛。近几年(2020~)随着单阶段算法精度和速度的 提高逐渐被取代。
2.Region-based CNN (2013)
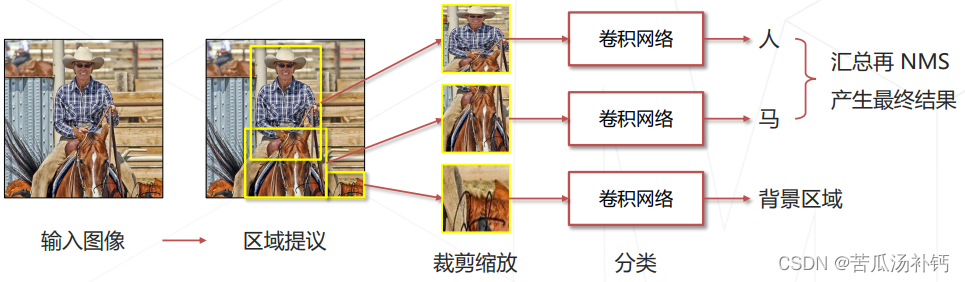
Stage 1 产生提议框
使用传统视觉算法,推测可能包含物体的框(约2000个) ✔️不漏:真正包含物体的框通常会被选中 ❌不准:大部分大部分提议框并不包含物体
Stage 2 识别提议框
将提议框内的图像缩放至固定大小(原始论文 227×227) ,送入卷积网络进一步识别,得到准确结果。
(1)R-CNN 的训练
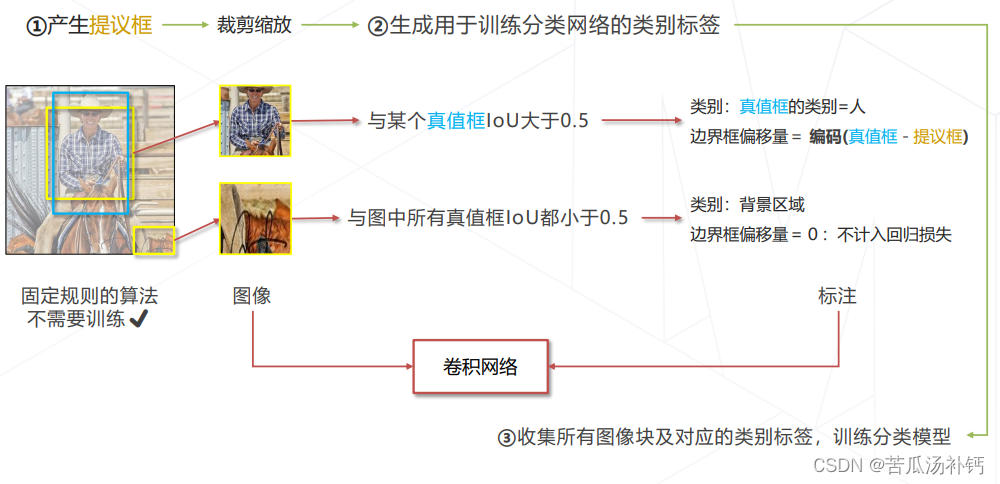
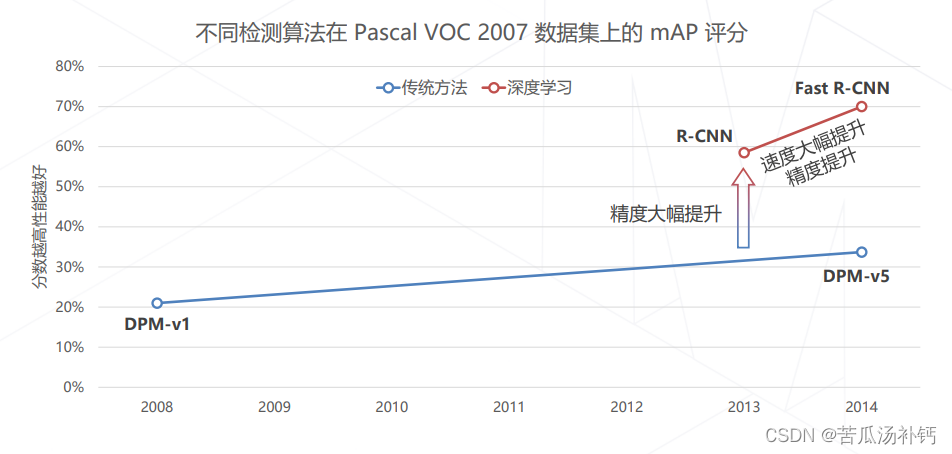
(2)R-CNN 相比于传统方法的提升
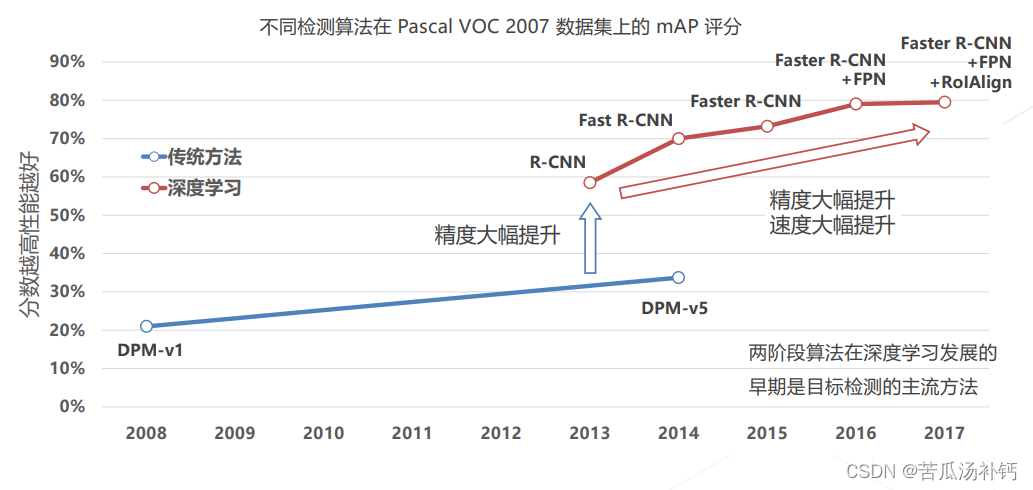
不同检测算法在 Pascal VOC 2007 数据集上的 mAP 评分(分数越高性能越好)。
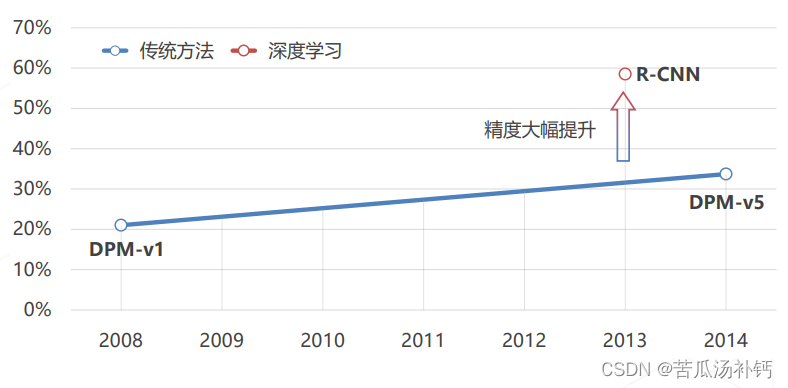
(3)R-CNN 的问题
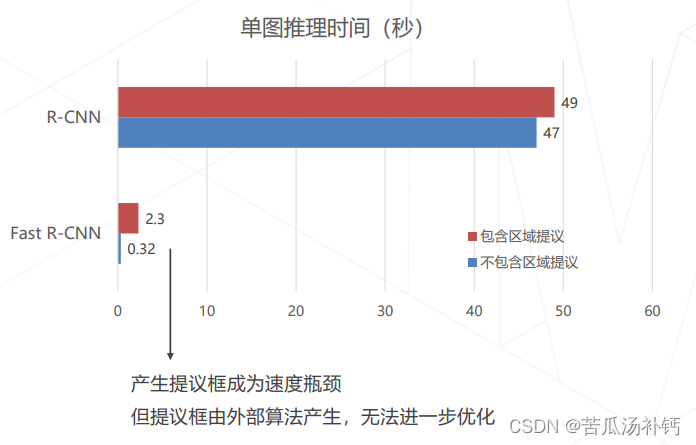
慢 :区域提议一般产生 2000 个框,每个框都需要送入 CNN 前传,推理一张图要几秒至几十秒。
3.Fast R-CNN (2014)
改进 R-CNN:减少重复计算✔️
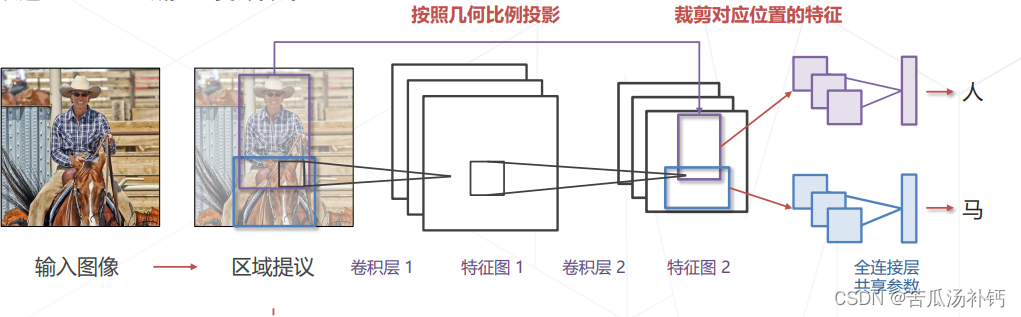
Stage 1 产生提议框 仍然依赖传统CV方法
Stage 2 识别提议框
- 卷积层应用于全图,一次性计算所有位置的图像特征
- 剪裁提议框对应的特征图送入全连接层计算分类
问题:提议框大小不同,需要处理成固定尺寸才能送入全连接层。
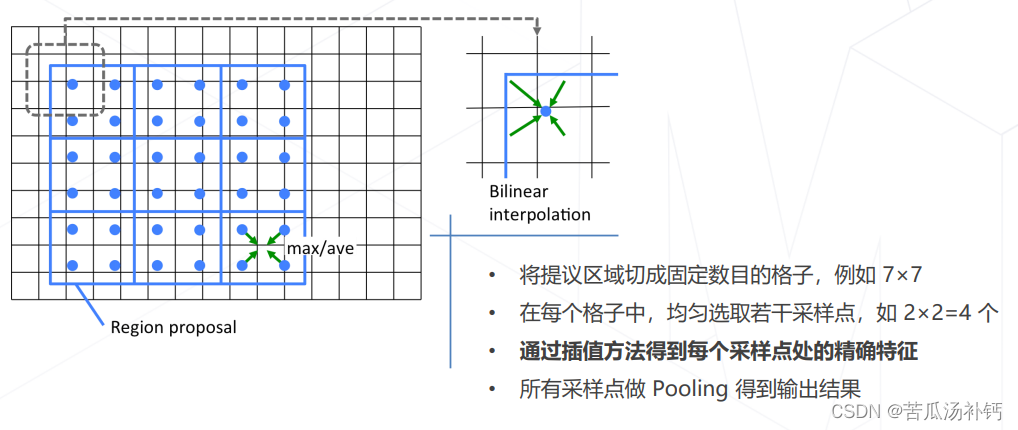
(1)RoI Pooling
目标:将不同尺寸的提议框处理成相同尺寸,使之可以送入后续的全连接层计算分类和回归。算法:
- 将提议框切分成固定数目的格子(上图中 2×2,实际常用 7×7,对齐ResNet等经典结构)。
- 如果格子边界不在整数坐标,则膨胀至整数坐标。
- 在每个格子内部池化,得到固定尺寸的输出特征图。
(2)RoI Align
RoI Align 比 RoI Pooling 在位置上更精细。
(3)Fast R-CNN 的训练
多任务学习、端到端训练

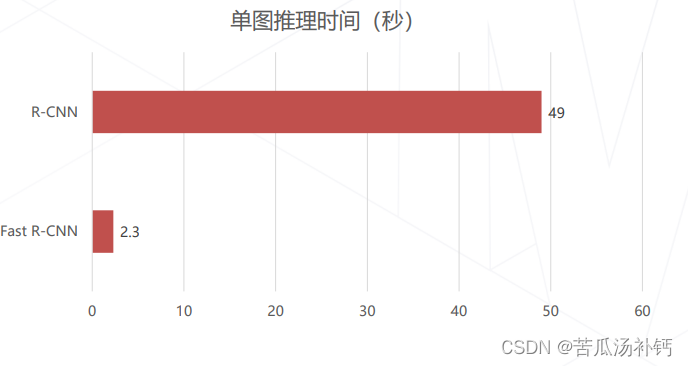
(4)Fast R-CNN 的速度提升
相比 R-CNN 速度大幅提升。
(5)Fast R-CNN 的精度提升
(6)Fast R-CNN 的速度瓶颈
(8)降低区域提议的计算成本
区域提议→在图中找到包含物体的框→不需要区分类别的检测问题
特定位置的特征包含其感受野内图像的信息,且已达到足够的抽象层级。基于特征做二分类就可以预测感受野内是否包含物体,从而实现区域提议。
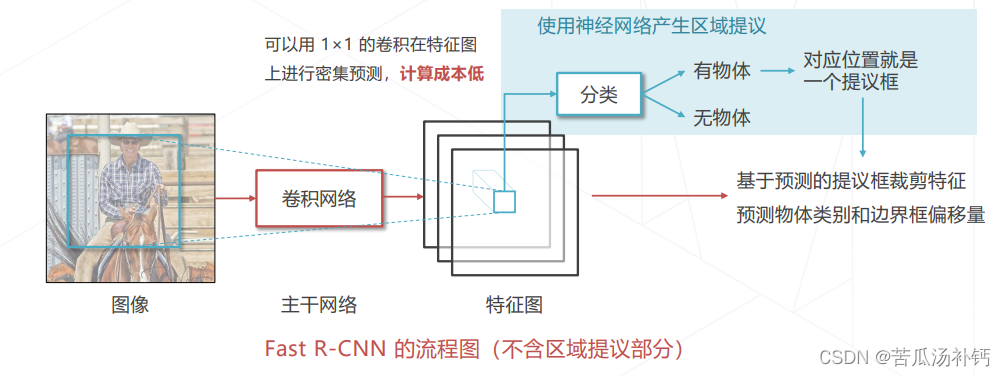
朴素方法的局限:图中有不同大小的物体,区域提议算法需要产;物体可能有一定程度重合,区域提议算法要有生不同尺寸的提议框,以适应不同尺寸的物体能力在同一位置产生不同尺寸的提议框,以适应重合的情况。
(9)锚框Anchor
从2012以后,不断有基于深度学习的目标检测算法被提出,其主要有两条技术发展路线:Anchor-based和Anchor-free方法。锚框Anchor是在图像上设定好的不同大小、长宽比例的参照框。在原图上设置不同尺寸的基准框,称为锚框Anchor,基于特征独立预测每个锚框中是否包含物体。可以生成不同尺寸的提议框,可以在同一位置生成多个提议框覆盖不同物体。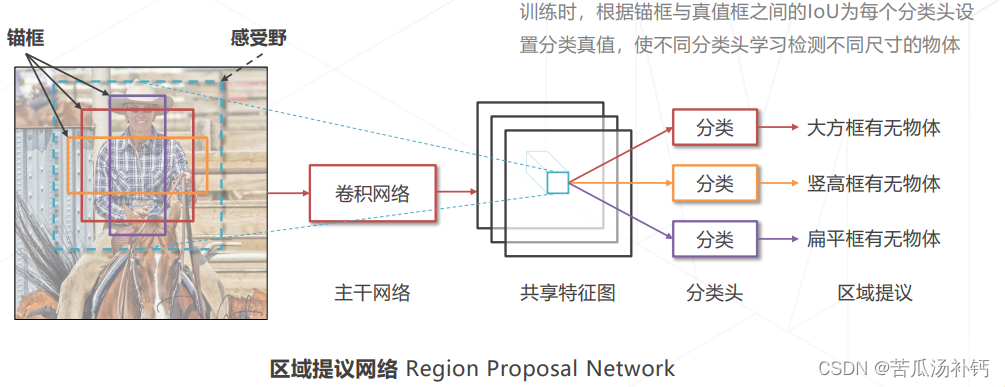
4.Faster R-CNN (2015)
Faster R-CNN = RPN + Fast R-CNN 二者共享主干网络和特征。
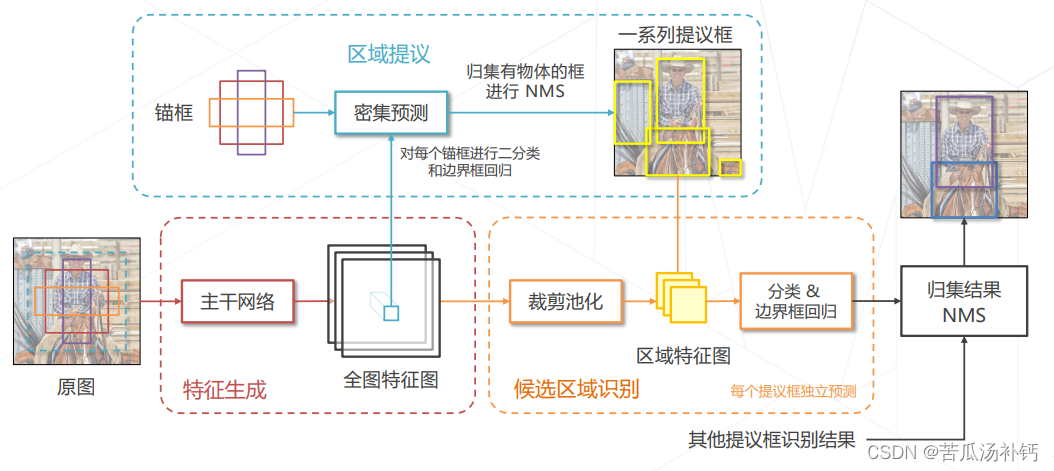
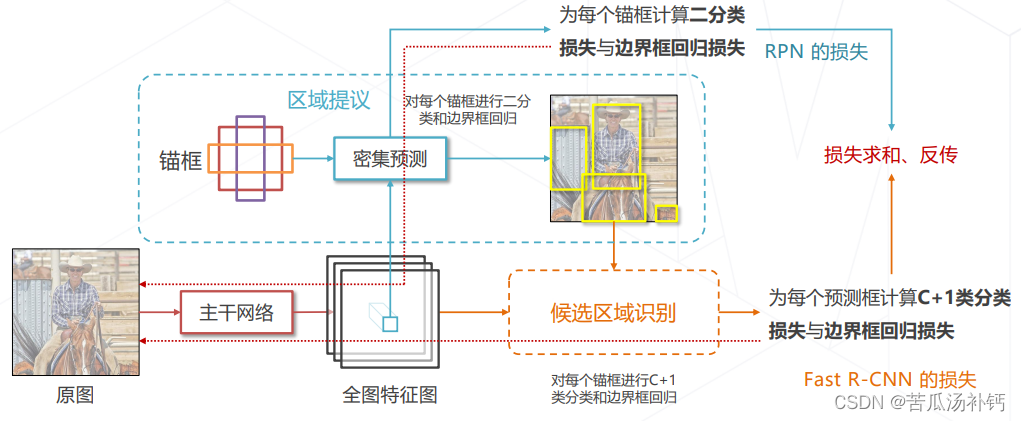
Faster R-CNN 的训练
联合学习 RPN 与 Fast R-CNN。为锚框和预测框产生分类和回归真值的方法与 R-CNN 相同,即基于 IoU 为锚框和预测框匹配真值框。
5.两阶段方法的发展与演进 (2013~2017)
四、多尺度检测技术
1.多尺度检测必要性
图像中物体大小可能有很大差异 (10 px ~ 500 px) 。多尺度技术出现之前,模型多基于单级特征图进行预测,通常为主干网络的倒数第二层,受限于结构 (感受野)和锚框的尺寸范围,只擅长中等大小的物体。另一方面,高层特征图经过多次采样,位置信息逐层丢失,小物体检测能力较弱,定位精度较低。

2.图像金字塔 Image Pyramid
将图像缩放到不同大小,形成图像金字塔。检测算法在不同大小图像上即可检测出不同大小物体。优势:算法不经改动可以适应不同尺度的物体。劣势:计算成本成倍增加。可用于模型集成等不在意计算成本的情况。

3.层次化特征
基于主干网络自身产生的多级特征图产生预测结果。由于不同层的感受大小不同,因此不同层级的特征天然适用于检测不同尺寸的物体。优势:计算成本低。劣势:低层特征抽象级别不够,预测物体比较困难。改进思路:高层次特征包含足够抽象语义信息。将高层特征融入低层特征,补充低层特征的语义信息。
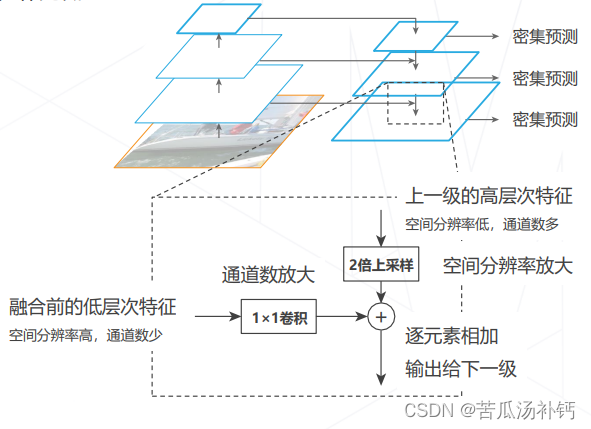
4.特征金字塔网络 Feature Pyramid Network (2016)
改进思路:高层次特征包含足够抽象语义信息。将高层特征融入低层特征,补充低层特征的语义信息。融合方法:特征求和。
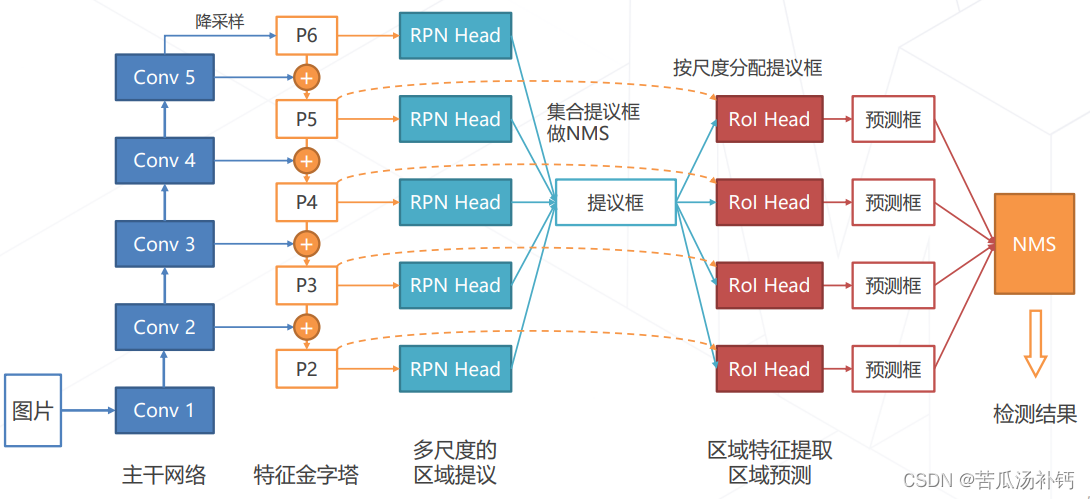
5.在 Faster R-CNN 模型中使用 FPN
五、单阶段目标检测One-stage Detectors
1.单阶段算法概述
单阶段算法直接通过密集预测产生检测框,相比于两阶段算法,模型结构简单、速度快,易于在设备上部署。
早期由于主干网络、多尺度技术等相关技术不成熟,单阶段算法在性能上不如两阶段算法,但因为速度和简洁的优势仍受到工业界青睐。
随着单阶段算法性能逐渐提升,成为目标检测的主流方法
2.YOLO: You Only Look Once (2015)
最早的单阶段算法之一
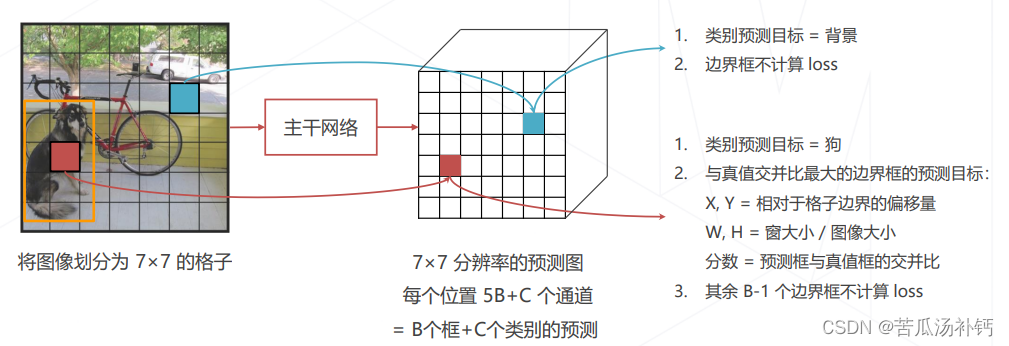
主干网络:自行设计的 DarkNet 结构,产生 7×7×1024 维的特征图。检测头:2 层全连接层产生 7×7 组预测结果,对应图中 7×7 个空间位置上物体的类别和边界框的位置。
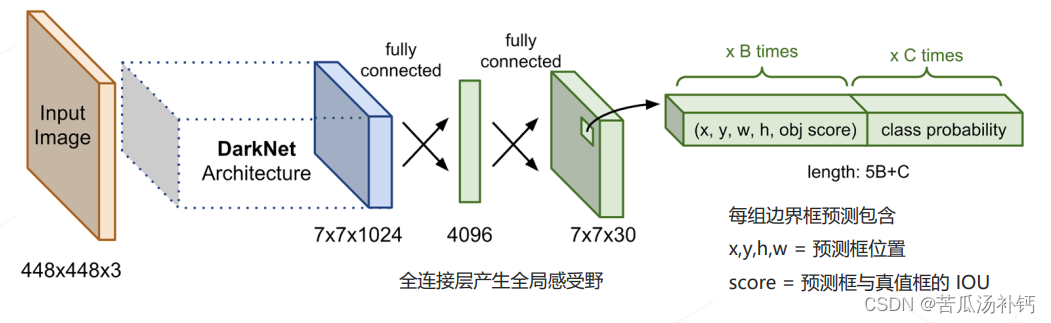
(1)YOLO 的分类和回归目标
将原图切分成 S×S 大小的格子,对应预测图上 S×S 个位置。如果原图上某个物体的中心位于某个格子内,则对应位置的预测值应给出物体类别和B组边界框位置,其余位置应预测为背景类别,不关心边界框预测结果。
(2) YOLO 的损失函数
多任务学习:回归、分类共同计入损失函数,通过 λ 控制权重。

(3)YOLO 的优点和缺点
快!在Pascal VOC 数据集上,使用自己设计的 DarkNet 结构可以达到实时速度,使用相同的 VGG可以达到 3 倍于 Faster R-CNN 的速度。
由于每个格子只能预测1个物体,因此对重叠物体、尤其是大量重叠的小物体容易产生漏检。直接回归边界框有难度,回归误差较大,YOLO v2开始使用锚框。
3.SSD: Single Shot MultiBox Detector (2016)
主干网络:使用 VGG + 额外卷积层,产生 11 级特征图。检测头:在 6 级特征图上,使用密集预测的方法,产生所有位置、不同尺度、所有锚框的预测结果。
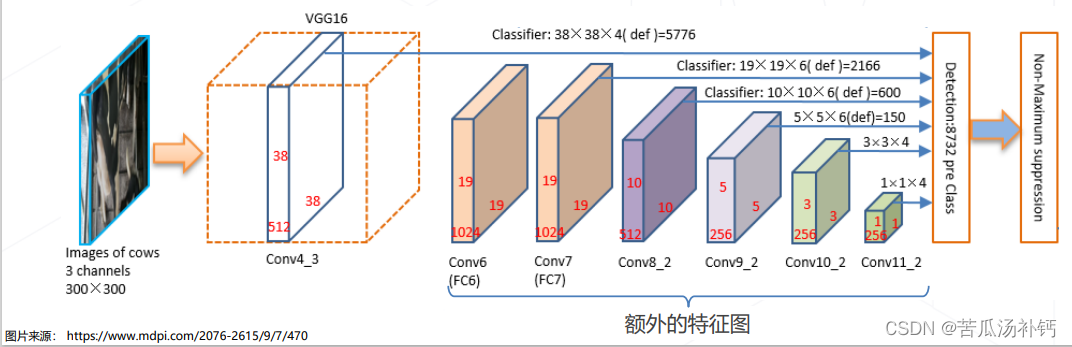
特征图分辨率×锚框数目,对所有特征图求和 = 8732 个检测框。
SSD 的损失函数
训练
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

