
- 1mysql Navicat通过代理链接数据库
- 2【OpenHarmony应用开发】eTS装饰器 @BuilderParam与@Styles
- 3一次使用 CesiumLab、ArcGIS Pro、SuperMap 11i 处理倾斜摄影数据的对比
- 4android+深度文件恢复工具,深度数据恢复神器
- 5Android 约束布局(ConstraintLayout)的使用_app:layout_constraintright_torightof
- 6iOS——MJRefresh的使用_mjrefresh 导入
- 7蓝桥杯 基础练习 十六进制转十进制 JAVA_蓝桥杯java 十六进制转十进制
- 8【自动化测试入门】用Airtest - Selenium对Firefox进行自动化测试(0基础也能学会)_selenium firefox502
- 9python—通讯录程序_python通讯录程序代码
- 10[面试题]无序数组中找到左侧比他小右侧比他大的数
深度学习设计-基于机器学习的心血管疾病分析与预测
赞
踩
概要
在国富民强的今天,医疗卫生事业快速发展,平均人口寿命也逐年上升,随之而来的是人口老龄化问题,而心 血管疾病是近年来发病率极高的老年性疾病。其发病率和死亡率均有所上升,已然成为当今威胁人类健康的重大疾 病之一。因此,对心血管疾病的危险因素分析,并根据分析结果有计划的预防疾病的发生有着深远意义。
首先在Kaggle网站上收集到了心血管疾病的数据集,之后在anaconda3上进行数据的处理以及预测工作。从而实 现对心血管疾病的影响因素进行分析,并通过算法实现对心血管疾病的预测,输入病人信息后,可根据相关信息进 行预测其是否患有先血管疾病。首先,采用可视化分析对数据集中的一些变量进行可视化分析,使其能够更加直 观。其次,采用逻辑回归算法、K近邻算法、决策树算法、随机森林算法和随机梯度下降算法进行预测,并利用 Python语言实现预测模型算法。最后,使用混淆矩阵和ROC-AUC曲线进行对预测模型进行评判,并用投票法对几种预 测模型进行融合,从而提升预测准确率。
关键词:心血管疾病预测;逻辑回归;K近邻模型;随机森林;决策树
一、研究背景与意义
随着我国人口老龄化问题的不断加重,心血管病作为老年人的常发性疾病,已经成为威胁我国甚至是全世界人 民生命和健康的重大公共卫生问题[1-2]。改革开放以来,人们的生活质量有了明显提高,医疗卫生事业也有了明天 的提升,但因为饮食不规律,运动少等因素,心血管疾病的发病率也逐渐提升,并有着年轻化的趋势。现如今,心 血管疾病已然成为了中国甚至是世界上致死率最高的疾病。因此,建立心血管疾病的发病率预测模型具有深远的意 义。本章首先阐述了心血管疾病研究的背景和意义,然后对目前心血管疾病研究的国内外现状进行了研究说明,最 后简要介绍了本文的组织结构。
1.1选题背景
中国从改革开放开始到如今,经过40年的不断发展。我国的经济和社会发展迅速,人民的生活质量和祖国经济 都发生了巨大而深刻的变化,取得了举世瞩目的伟大成就。中国在经济发展迅速的同时,医疗卫生事业也在不断地 进步,人口平均寿命也有所提升,随之而来的是人口老龄化严重问题,而心脑血管疾病(CVD)是全球人群的头号杀 手,心血管病常见于临床,是指人体心脏及全身血管的疾病[3]。心血管疾病因其有着高发病率和高死亡率的特点, 现如今已经成为了我国的重大的公共卫生问题。随近年来,心血管疾病的发病率和死亡率均有所上升,已然成为当 今威胁人类健康的重大疾病之一。
随着社会经济的发展,国民生活方式的改变,我国心血管疾病患病率及死亡率持续上升,我国心血管疾病死亡 率居各种疾病之首,居民疾病死亡构成在农村为44.6%,在城市为42.51%[4]。有数据显示,2008年,全世界死亡人 数为5800多万人,而因心血管疾病死亡的人数高达1730万人,因心血管疾病死亡的人数占全部死亡的30.1%,由此可 见,心血管疾病已然成为威胁人们身体健康的重大疾病。预计到2030年,全球因CVD死亡人数将达2360万人[5]。根 据《心血管疾病报告2018》报告显示,目前,我国有2.9亿人患有心血管疾病,其中脑卒中病人为1300万,冠心病病人为1100万,肺源性心脏病为500万,心力衰竭患者为450万,风湿性心脏病患者为250万,先天性心脏病患者为200 万,高血压病人2.45亿[6]。据报告显示,心血管疾病的死亡率从2000年以来就一直位居我国首位,远远超过了肿瘤 等疾病,严重威胁着我国国民健康的同时,也给国家造成了巨大的经济负担,建立健康生活方式不仅能预防80%的心 血管疾病,还能预防40%的恶性肿瘤[7],因此对心血管疾病的早期预防成为了至为关键的一步。治病不如防病,防病不如不生病。心血管疾病作为老年常见性疾病,导致其发生的因素有很多,如家族遗传、 性别、年龄、身高、体重、血脂异常、吸烟、饮酒、不运动、饮食结构不合理等[8]。在心血管疾病患病率逐渐上升 的今天,做好预防工作,减少心血管疾病发病率是我们努力的方向。
1.2 研究目的及意义
治病不如防病,对心血管疾病进行分析主要目的就是为之后的预防提供依据。自古以来,我国医学家就提出了 预防疾病的重要性,并且一直致力于对疾病预防的研究,从未止步。从两千多年前《黄帝内经》中的“上医治未 病,中医治欲病,下医治已病”,到著名的扁鹊三兄弟的故事,再到《伤寒杂病论》中的“上工治未病”,都可看 出对疾病提前预防的重要性。在掌握了可能导致疾病发生的危险因素后,可在疾病发生之前对危险因素主动干预, 尽量避免疾病的发生,防患于未然,。 有很多导致心血管疾病发生的危险因素,其中主要包括吸烟、饮酒、高血压、胆固醇和缺乏体育运动等。对心 血管疾病进行危险因素的分析,并根据分析结果有计划的预防疾病的发生有着深远意义
二、预测心血管疾病的算法
心血管疾病分析的相关方法和技术,包括用于预测心血管疾病的逻辑回归算法、K近邻算法、随机森林、决策树
和随机梯度下降,在最后用投票法进行模型的融合,提升预测的准确率。
2.1 逻辑回归算法
逻辑回归又称logistic回归分析,它是一种广义的线性模型,在实际应用中逻辑回归算法经常用于分类,此算法既可以用于2分类,也可以用于有多种分类,但是更普遍用于2分类。
(1)逻辑回归算法主要流程
逻辑回归算法对问题的处理经过为,第1步,构建预测函数,根据数据确定模型函数,是线性还是非线性;第2
步,构建损失函数,用于检测真实值和预测值间的差距,两者之间的差距越小,预测的效果越好;第3步,计算参
数,在计算参数时选择的是梯度下降法对参数通过迭代的方式来逐渐降低损失函数的值。但是,在数据量很大时,
梯度下降算法执行起来会较慢,因此出现了随机梯度下降等算法进行优化。求解出最优的模型参数,得出参数之
后,带入预测函数就可以进行预测了,然后测试验证我们这个求解的模型的好坏。
(2)逻辑回归的优点
1)该算法因为计算量较小,所以有着训练速度快的优点。
2)该算法可以占用比较小的内存资源,将各个维度的特征值进行存储即可。
3)模型可解释性好,简单易于理解。
4)计算的成本低,易于实现。
5)适用于连续型和类别型自变量。
(3)逻辑回归的缺点
任何算法都存在着缺点,逻辑回归也不例外。
1)对多重共线性问题较为敏感。
2)因为该算法的精度不高,所以容易产生欠拟合现象。
3)数据不平衡的问题较难处理。
2.2 K近邻算法
KNN是K-Nearest Neighbor算法的简称,该算法还被叫做为K近邻算法,它在机器学习中可以算是最简单、最基础的算法之一。该算法就是通过选取k个最近邻的点,选取到的K个点属于哪一类的个数最多,那么该点就属于哪一类。KNN既能用于分类,也可以用于回归,是一种监督学习算法。KNN算法一般采用欧式距离来计算测试数据到每个训练数据的距离,除此之外,还有曼哈顿距离和马氏距离。
欧式距离为:
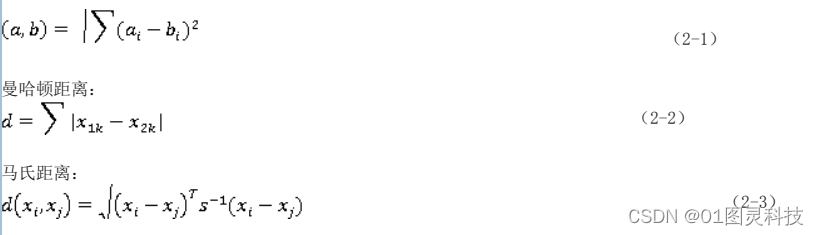
KNN算法虽然有着算法简单、精度高等优点,但是也有着计算复杂度高等缺点,KNN算法的优缺点主要有以下几点:
KNN的优点:
(1)理论成熟,思想简单,既可以用来做分类也可以用来做回归
(2)算法简单,易于理解,易于实现
(3)对异常值不敏感
(4)适合处理多分类问题
KNN的缺点:
(1)属于懒惰算法,时间复杂度较高
(2)样本平衡度依赖性高,当出现极端情况样本不平衡时,分类绝对会出现偏差,可以调整样本权值改善
(3)相比决策树模型,KNN模型的可解释性不强
(4)样本空间太大不适合,因为计算量太大,预测缓慢
2.3 随机森林
随机森林是一种有监督的学习,该算法是一种通过多棵决策树进行优化决策的算法。它通过自助法重采样技术,从原始训练样本集N中有放回地重复随机抽取样本生成新的训练样本集合来训练决策树,然后按照以上步骤生成多棵决策树组成随机森林。
随机森林的优点:
(1)可以在一定程度上避免过拟合
(2)具有很好的抗噪能力,性能稳定
(3)可以处理高维度的数据,并且不用做特征选择
(4)既可以用于分类也可以用于回归
(5)实现简单
随机森林的缺点:
(1)参数复杂
(2)模型训练和测试比较慢
2.4 决策树
决策树由决策节点、分支和叶子节点三部分组成。它是一种利用树形结构进行决策的预测模型,对样本中的数据根据已知的条件或者是特征进行分叉,最终来建立一棵树,树的叶子节点标识最终决策。树的叶子节点表示对象所属的预测结果。决策树采用了自顶向下的递归方法,以信息熵为度量去构造一棵熵值下降最快的树,到叶子节点处熵值为0。决策树的生成过程:
(1)特征选择:应选择基尼指数增益值最大的特征作为该结点分裂的条件。
(2)决策树生成:根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可继续分化,决策树即停止生长。
(3)剪枝:剪枝的目的是缩小树的结构,从而缓和过拟合,降低决策树过拟合程度。剪枝技术分为预剪枝和后剪枝两种。预剪枝是提前就结束决策树的生长,所以相对来说,后剪枝的效果会更好。
决策树算法的优点:
(1)计算复杂度不高,容易解释、容易理解
(2)对中间值的确实不敏感
(3)可处理具有不相关特征的数据
决策树算法的缺点:
(1)可能会产生过度匹配问题
(2)不容易处理缺失数据
(3)容易过拟合
三、数据及数据处理工具介绍
对心血管疾病数据的来源进行了介绍,并且介绍了数据集中一些数据属性。最后对收集来的数据进行了预处理操作。
3.1 数据平台介绍
本文数据从Kaggle平台获取,该平台是一个主要为数据科学家进行学习竞赛、代码分享的平台。发布者可以在该平台上提供一些数据、发布一些任务,来寻找解决问题的方法。参赛者可以以组队的形式来参与项目,优秀的方案可获得奖金,所以对于参赛者来说,不仅可以锻炼自己的实际操作能力,还有可能获得丰厚的奖金。除此以外,Kaggle平台每年还会举办大规模的竞赛,奖金高达一百万美金,从而吸引了许多人参与其中。
网址为https://www.kaggle.com/。
3.2 数据介绍
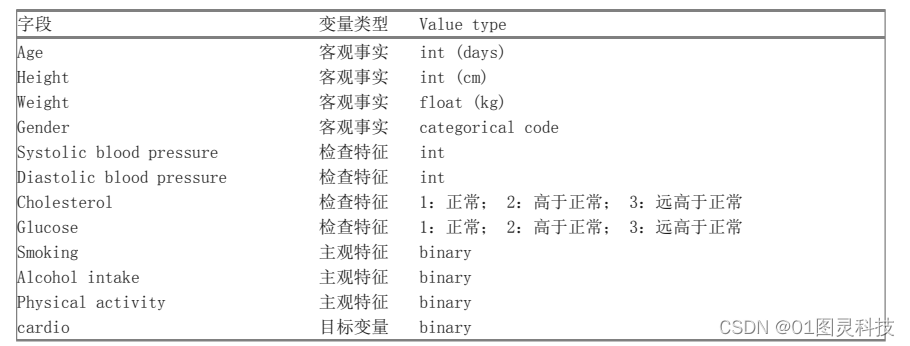
本文研究的是心血管疾病的分析与预测,采用了kaggle中的7万条有关心血管疾病的数据,如图3-1所示。数据包含13个属性,分别为id、年龄、身高、体重、性别、收缩压、舒张压、胆固醇、葡萄糖、吸烟、饮酒、体育活动、有无心血管疾病。
(1)患者id,格式为整型。
(2)年龄,格式为整型。
(3)身高,格式为整型。
(4)体重,格式为浮点型。
(5)性别,格式为分类代码,数字0和1表示男性还是女性。
(6)收缩压,格式为整型。
(7)舒张压,格式为整型。
(8)胆固醇,取值为{1,2,3} 其中1表示正常,2表示高于正常,3表示远高于正常。
(9)葡萄糖,取值为{1,2,3} 其中1表示正常,2表示高于正常,3表示远高于正常。
(10)吸烟,格式为二进制,0表示不吸烟,1表示吸烟。
(11)饮酒,格式为二进制,0表示不饮酒,1表示饮酒。
(12)体育活动,格式为二进制,0代表不运动,1代表运动。
(13)是否患有心血管疾病,有心血管疾病时,cardio为1,没有心血管疾病,则为0。
表3-1 数据集相关属性
3.3 数据的预处理
将数据集导入到Spyder中进行数据清洗
(1)处理缺失值
将数据导进软件中,进行缺失值的查看与处理,根据结果可看出并无缺失值,无需进行缺失值的处理。
相关代码如下:
df.info()
print(df.isnull().values.any())
- 1
- 2
(2)异常值处理
看数据集中是否存在异常值。通过结果可以看出在此数据集中,最低的身高是55厘米,最低的体重是10公斤,最低的年龄是10798天,等于29岁,最高的身高为250厘米,最高的体重为200公斤。由此可以看出身高体重存在着异常值,为了处理这些错误,减少对预测结果产生影响,对这些数据进行了删除操作。此外,在某些情况下,舒张压高于收缩压,并且血压出现了负值,这也是不正确的,要对这些数据进行删除。
相关代码如下:
print(df.describe()) #清理数据 df.drop(df[(df['height'] > df['height'].quantile(0.975)) | (df['height'] < df['height'].quantile (0.025))].index,inplace=True) df.drop(df[(df['weight'] > df['weight'].quantile(0.975)) | (df['weight'] < df['weight'].quantile (0.025))].index,inplace=True) print("Diastilic pressure is higher than systolic one in {0} cases".format(df[df['ap_lo']> df ['ap_hi']].shape[0])) df.drop(df[(df['ap_hi'] > df['ap_hi'].quantile(0.975)) | (df['ap_hi'] < df['ap_hi'].quantile (0.025))].index,inplace=True) df.drop(df[(df['ap_lo'] > df['ap_lo'].quantile(0.975)) | (df['ap_lo'] < df['ap_lo'].quantile (0.025))].index,inplace=True) blood_pressure = df.loc[:,['ap_lo','ap_hi']] sns.boxplot(x = 'variable',y = 'value',data = blood_pressure.melt()) print("Diastilic pressure is higher than systolic one in {0} cases".format(df[df['ap_lo']> df ['ap_hi']].shape[0]))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
四、心血管疾病具体分析
对心血管疾病进行分析,首先用可视化分析对数据集中的变量进行了单变量分析、双变量分析以及多变量分析,使数据可以更加直观的展示。然后用逻辑回归算法、K近邻算法、随机森林算法、决策树算法和随机梯度下降5个算法对患者是否患病进行预测并且用投票法进行投票,从而提升预测的准确率。
4.1 变量分析
对数据集中的一些变量进行可视化分析,可以更加直观的看到每个变量之间的关系。本节分别从单一变量、双变量和多变量进行分析,并画出相应的图,使其可以更加直观的展示。
4.1.1 单变量分析
(1)查看患者年龄的分布情况,可从图中明显的看出什么年龄患有心血管疾病的人数超过没有心血管疾病的人数,如图4-1,可以更加直观的看到患有心血管疾病的年龄分布,60岁时患病人数最多,并且可看出基本上随着年龄的增长,患病人数也逐渐增长。
rcParams['figure.figsize'] = 11, 8
df['years'] = (df['age'] / 365).round().astype('int')
sns.countplot(x='years', hue='cardio', data = df, palette="Set2")
- 1
- 2
- 3
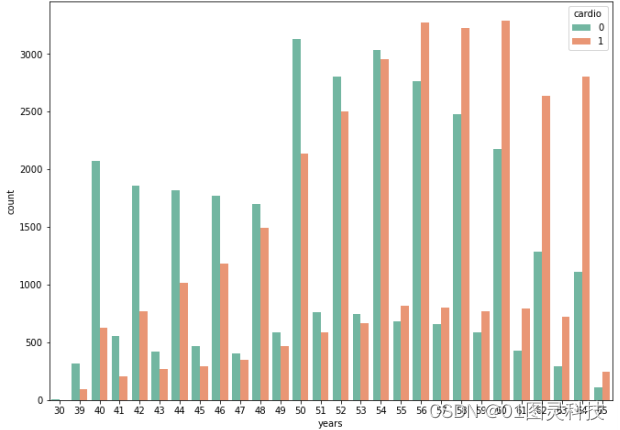
图4-1 年龄分布
(2)查看数据集中的分类变量及其分布情况,由图4-2可看出胆固醇含量、葡萄糖含量、吸烟、饮酒和体育运动在数据集中的分布。图4-2中,0代表不吸烟、不喝酒、不运动;1代表吸烟、喝酒、进行体育运动;其中1还代表着胆固醇含量和葡萄糖含量正常;2代表高于正常;3代表远高于正常相关代码如下:
df_categorical = df.loc[:,[‘cholesterol’,‘gluc’, ‘smoke’, ‘alco’, ‘active’]]
sns.countplot(x=“variable”, hue=“value”,data= pd.melt(df_categorical))
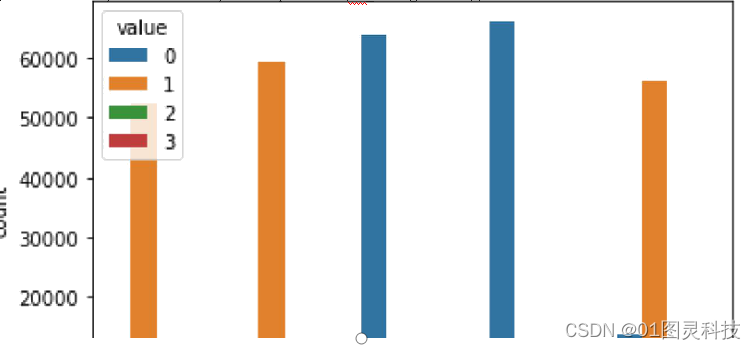 图4-2 变量分布
图4-2 变量分布
4.1.2 双变量分析
查看胆固醇含量、葡萄糖含量、吸烟、饮酒和体育运动对患有心血管疾病的影响,由图4-3中可看出胆固醇含量的高低、葡萄糖含量的高低对患有心血管疾病有着很大影响,胆固醇含量高,患有心血管疾病的可能性就高;其次,影响较大的是葡萄糖含量,葡萄糖含量高,患病几率就大;吸烟和饮酒对患病有着一定的影响,但是总体来看,影响不是很大;而运动情况从图中来看对患病的影响不大。
相关代码如下:
df_long = pd.melt(df, id_vars=['cardio'], value_vars=['cholesterol','gluc', 'smoke', 'alco',
'active'])
sns.catplot(x="variable", hue="value",col="cardio",data=df_long,kind="count")
- 1
- 2
- 3
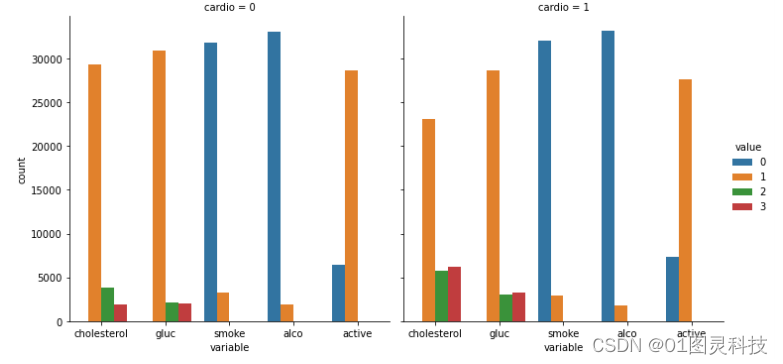 图4-3
图4-3
4.1.3 多变量分析
可通过画出的热力图查看数据集中多个特征两两的相似度,从图4-4右侧的颜色带可看出,颜色越深,特征之间的相似度就会越高。
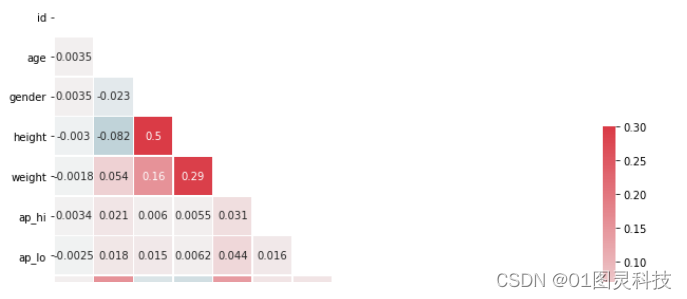
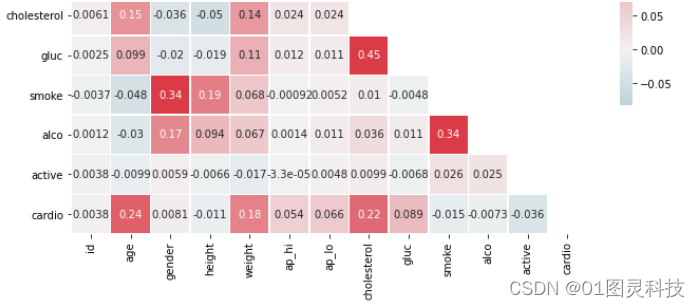
图4-4 热力图
4.2 心血管疾病分析预测的实现
心血管疾病的预测采用了逻辑回归、K近邻、随机森林、决策树、随机梯度下降进行分析预测,并用投票法将几个算法进行投票,用于提高预测的准确率。
此次用于分析的数据包含70000条数据,在预测算法中,首先会将数据集按照8:2的比例划分为训练数据和测试数据。在整体的预测过程中先使用划分好的训练数据来训练出预测模型,之后再将测试数据输入到已经训练好的机器模型中,用于实现对心血管疾病的预测。最后通过生成的混淆矩阵和ROC-AUC曲线来对预测效果进行评价。以下是数据划分的核心代码,其中包含了数据标准化处理。
y = df.cardio.values
X = df.drop(['cardio'], axis = 1)
X.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
#数据标准化
standardScaler = StandardScaler()
standardScaler.fit(X_train)
X_train = standardScaler.transform(X_train)
X_test = standardScaler.transform(X_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
总结
本文运用的算法有逻辑回归、K近邻、随机森林、决策树和随机梯度下降,使用以上算法对心血管疾病进行预测,具体内容如下。
首先,对心血管疾病研究的现状与发展等情况进行了详细的了解,对心血管疾病研究与预测的背景、目的与意义、国内外研究现状以及对文章的组织结构进行了介绍。
其次,对预测心血管疾病的相关算法——逻辑回归算法、K近邻算法、随机森林算法、决策树算法、随机梯度下降算法和投票法进行了详细的阐述。
然后,简要的介绍了一下数据的属性,和数据集的来源。并对数据集进行了缺失值的处理和异常值的处理等预处理操作。
最后,用Python的集成环境anaconda对收集到的数据进行处理与分析。首先,对数据进行了一些可视化的变量分析;其次,使用逻辑回归算法、K近邻算法、随机森林算法、决策树算法和随机梯度下降算法进行预测,最后用投票法将几个算法的结果进行投票得到了最终的预测结果。
五、 目录
目 录
基于机器学习的心血管疾病分析与预测1
第1章 绪论1
1.1 选题背景1
1.2 研究目的及意义2
1.3 国内外研究现状2
第2章 预测心血管疾病的算法4
2.1 逻辑回归算法4
2.2 K近邻算法5
2.3 随机森林5
2.4 决策树6
2.5 随机梯度下降6
2.6 投票法7
2.7 模型评判标准7
2.7.1 混淆矩阵7
2.7.2 ROC曲线8
第3章 数据及数据处理工具介绍9
3.1 数据平台介绍9
3.2 数据介绍9
3.3 数据的预处理10
第4章 心血管疾病具体分析12
4.1 变量分析12
4.1.1 单变量分析12
4.1.2 双变量分析13
4.1.3 多变量分析14
4.2 心血管疾病分析预测的实现15
4.2.1 逻辑回归15
4.2.2 K近邻18
4.2.3 决策树20
4.2.4 随机森林23
4.2.5 随机梯度下降25
4.2.6 投票28
4.3 本章小结28
第5章 针对预防心血管疾病的分析与建议29
5.1 心血管疾病分析29
5.2 提出建议29
5.3 本章小结30
第6章 总结与展望31
6.1 全文总结31
6.2 展望31
参考文献33
致 谢36
附录 代码37

