
- 13GPP 38.311 NR Radio Resource Control (RRC) protocol specification_3gpp ts 38.331
- 2鸿蒙迎来纯血版本,你还不来学习一下
- 3千万流量秒杀系统-过载保护:如何通过熔断和限流解决流量过载问题?_微服务过载保护
- 4android ubuntu 桌面快捷方式,[转] 给ubuntu中的软件设置desktop快捷方式(以android studio为例)...
- 5netty实现webSocket握手处理并添加响应头_netty websocket 握手
- 6Windows安装DVWA(全过程)_windows搭建dvwa
- 7图像处理代码编写三:基于C++的高斯滤波程序实现_高斯滤波c++代码
- 8用通俗易懂的方式讲解:一文搞懂大模型 Prompt Engineering(提示工程)_prompt engineering 的原理
- 9Android针对视频部分截屏是黑色的解决办法_andorid 截屏视频控件是黑的
- 10限流算法总结:计数器、滑动窗口、漏桶算法、令牌桶算法(抄的)_滑动窗口限流算法
ClickHouse存储结构及索引详解_clickhouse 所有索引
赞
踩
(公司同事新出炉的技术文,虽然除了字都认识外其他看不出个所以然,不妨碍我仰望大神们)
本文作者:擎创 大飞哥
ClickHouse存储结构及索引详解
环境介绍
本文基于ClickHouse 20.8.5.45版本编写,操作系统使用的是CentOS 7.5,主要介绍MergeTree表引擎的存储结构以及索引过程,希望通过本文能够让大家对ClickHouse的底层有个更详细的了解。
创建表
创建语句
CREATE TABLE test_merge_tree ( `Id` UInt64, `Birthday` Date, `Name` String ) ENGINE = MergeTree() PARTITION BY toYYYYMM(Birthday) ORDER BY (Id, Name) SETTINGS index_granularity = 2
语句介绍
- ENGINE,表引擎。ClickHouse支持很多种表引擎,本文主要讲解MergeTree,所以选用合并树。
- PARTITION BY,分区键。用于指定数据以何种方式分区,合理使用分区可以有效减少查询时文件的扫描范围。
- ORDER BY,排序键。用于指定数据以何种方式排序,默认情况下排序键和主键相同。
- SETTINGS,配置。创建MergeTree Table时使用的配置,可选的配置有很多,这里只介绍index_granularity。index_granularity表示索引粒度,代表每隔多少行数据生成一条索引,默认值是8192。默认值需要的数据量很大,不方便本文展示数据文件,所以这里我把它调小了。
文件结构
刚刚创建的表只在数据目录下生成了一个名为test_merge_tree文件夹(具体路径为data/default/test_merge_tree),并没有任何数据,接下来往该表里面插入一条数据,看看会生成哪些文件。
INSERT INTO test_merge_tree VALUES(1, '2000-02-01', 'Fly li')
在test_merge_tree目录下使用tree命令可以看到刚刚的那条命令生成了一个名为200002_1_1_0的文件夹。

分区目录命名规则
在介绍这些文件之前先介绍一下20000211_0这个目录的命名规则
PartitionId_MinBlockNum_MaxBlockNum_Level
- PartitionId,分区Id。其值是由创建表时所指定的分区键决定的,由于我们创建表时使用的分区键为toYYYYMM(Birthday),即生日的年月,而插入的Birthday为2000-02-01,所以其值为200002。
- MinBlockNum、MaxBlockNum,最小最大数据块编号。其值在单张表内从1开始累加,每当新创建一个分区目录其值就会加1,且新创建的分区目录MinBlockNum和MaxBlockNum相等,只有当分区目录发生合并时其值才会不等。由于这是该表第一次插入数据,所以MinBlockNum和MaxBlockNum都为1。
- Level,分区被合并的次数。level和MinBlockNum以及MaxBlockNum不同,它不是单张表内累加的,而是单张表中的单个分区内累加的。每当新创建一个分区目录其值均为0,只有当分区目录发生合并时其值才会大于0。
当分区发生合并时,新的分区目录名称命名规则将会在接下来介绍,这里不做详述。
文件介绍

存储结构
修改min_compress_block_size
在介绍这部分之前,需要先将min_compress_block_size配置改小,以方便分析mrk2和bin文件,其默认值为65535。
修改方法为在users.xml文件的profiles里面增加以下配置
<min_compress_block_size>24</min_compress_block_size>
修改完后重启clickhouse-server服务,然后再用以下命令查看是否修改成功

插入数据
刚刚已经插入了一条数据,但是那一条数据不具有代表性,所以这次决定多插入几条数据再来分析。
INSERT INTO test_merge_tree VALUES(3, '2000-02-03', 'Lisa'),(4, '2000-02-03', 'Lilei'),(6, '2000-02-08', 'Meimei'),(12, '2000-02-03', 'paker'),(31, '2000-02-07', 'vincent')
上面这条命令产生了个新的分区目录200002_2_2_0,此目录下的文件前面已经讲过,现在重点分析以下几个文件的存储格式
primary.idx
MergeTree表会按照主键字段生成primary.idx,用于加快表查询。前面创建表时使用的是(Id, Name)两个字段作为主键,所以每隔index_granularity行数据就会取(Id, Name)的值作为索引值,由于index_granularity被设置为2,所以每隔两行数据就会生成一个索引。也就是说会使用(3,'Lisa'), (6,'Meimei'), (31,'vincent')作为索引值。
这里我只介绍第一个索引(3,'Lisa')的存储格式,剩下的可以自己去梳理。Id是UInt64类型的,所以使用8字节来存储。从上图可以看出前8个字节为0x03,以小端模式来存储,接下来我们可以看到其它文件都是以小端模式来存储。Name是String类型,属于变长字段,所以会先使用1个字节来描述String的长度,由于Lisa的长度是4,所以第9个字节为0x04,再接下来就是Lisa的ASCII码。
Id.mrk2
mrk2文件格式比较固定,primary.idx文件中的每个索引在此文件中都有一个对应的Mark,Mark的格式如下图所示:

- Offset in compressed file,8 Bytes,代表该标记指向的压缩数据块在bin文件中的偏移量。
- Offset in decompressed block,8 Bytes,代表该标记指向的数据在解压数据块中的偏移量。
- Rows count,8 Bytes,行数,通常情况下其等于index_granularity。
通过primary.idx中的索引寻找mrk2文件中对应的Mark非常简单,如果要寻找第n(从0开始)个index,则对应的Mark在mrk2文件中的偏移为n*24,从这个偏移处开始读取24 Bytes即可得到相应的Mark。
Id.bin
bin文件由若干个Block组成,由上图可知Id.bin文件中包含两个Block。每个Block主要由头部的Checksum以及若干个Granule组成,Block的格式如下图所示: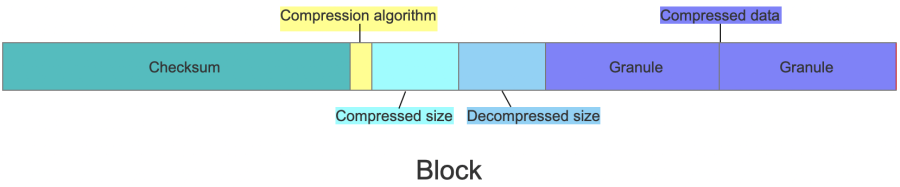
- Checksum,16 Bytes,用于对后面的数据进行校验。
- Compression algorithm,1 Byte,默认是LZ4,编号为0x82。
- Compressed size,4 Bytes,其值等于Compression algorithm + Compressed size + Decompressed size + Compressed data的长度
- Decompressed size,4 Bytes,数据解压缩后的长度。
- Compressed data,压缩数据,长度为Compressed size - 9。
每个Block都会包含若干个Granule,具体有多少个Granule是由参数min_compress_block_size控制,每次Block中写完一个Granule的数据时,它会检查当前Block Size是否大于等于min_compress_block_size,如果满足则会把当前Block进行压缩然后写到磁盘中,不满足会继续等待下一个Granule。结合上面的INSERT语句,当插入第一个Granule(3, 4)时,数据的的size为16,由于16 < 24所以会等第二个Granule,当插入第二个Granule(6, 12)后数据的size为32,由于32 > 24所以会把(3, 4, 6, 12)压缩放到第一个Block里面。最后面的那个31由于是最后一条数据,就放到第二个Block里面。
partition.dat![]()
partition.dat文件里面存放的是分区表达式的值,该分区表达式生成的值为200002,UInt32类型,转换成16进制就是0x00030d42。
minmax_Birthday.idx![]()
minmax文件里面存放的是该分区里分区字段的最小最大值。分区字段Birthday的类型为Date,其底层由UInt16实现,存的是从1970年1月1号到现在所经过的天数。通过上面的INSERT语句我们可以知道Birthday的最小值为2000-02-03,最大值为2000-02-08。这两个时间转换成天数分别为10990和10995,再转换成16进制就是0x2aee和0x2af3。
分区合并
属于同一个分区的不同目录,ClickHouse会在分区目录创建后的一段时间自动进行合并,合并之后会生成一个全新的目录,以前老的分区目录不会立马删除,而是在合并后过一段时间再删除。新的分区目录名称遵循以下规则:
- PartitionId,分区Id不变。
- MinBlockNum,取该分区中最小的MinBlockNum。
- MaxBlockNum,取该分区中最大的MaxBlockNum。
- Level,取该分区中最大的Level值加1。
所以上面的两个分区目录200002_1_1_0和200002_2_2_0在过一段时间后最终会变成一个新的分区目录200002_1_2_1。由此可见如果你频繁插入数据会产生很多分区目录,在合并的时候会占用很多资源。所以最好一次插入很多条数据,尽量降低插入的频率。
索引过程
通过上面的介绍相信大家已经对ClickHouse的索引结构有所了解,接下来用一张图简要描述Id字段的索引过程。

其它列的索引过程类似,这里就不一一赘述了,有兴趣的朋友可以自己去研究。
总结
本文通过一个简单的例子来分析ClickHouse的存储结构,整个逻辑力求简洁明了,希望通过本文能够让喜欢ClickHouse的朋友对它的索引有个清晰的认识。
#ClickHouse# #存储结构#

