
- 1Android Studio日志过滤_android studio 如何排除某些日志
- 2端口映射和端口转发
- 3STM32 CUBEMX系列——flash的使用_cubemx flash
- 4FreeGPT-WebUI(CPP)
- 5vue 表格嵌套表格 实现上移下移置顶置底_嵌套表怎么挪位置
- 6小白跟做江科大51单片机之红外遥控
- 7计算机网络之网络层ARP协议、DHCP协议、ICMP协议及其IPv6【408_2】_arp/dhcp
- 8常见的数据库面试题含答案
- 9[从0到1,从零在liunx服务器上搭建一个java项目]_java在linux程序开发流程
- 10php中的图像处理(七)_imagecreatefrompng(): gd-png: fatal libpng error:
AI医药论文笔记-DREAM: Drug-drug interaction extraction with enhanced dependency graph and attention mechan_drug-drug interaction extraction,ddie
赞
踩
DREAM:增强依赖图和注意机制的药物相互作用提取
DREAM: Drug-drug interaction extraction with enhanced dependency graph and attention mechanism
目录
1.ABSTRACT
药物相互作用(DDI)旨在描述两种或多种药物组合产生的效应关系。在药物警戒和临床研究等生物信息学领域,它是一项重要的语义处理任务。最近,图神经网络被应用于依赖图,以更好的语义表示来提高DDI提取的性能。然而,目前的方法更多地关注于一阶依赖关系,无法正确区分连接节点。为了更好地融合依赖关系并改进表示,我们在本工作中提出了一种新的DDI提取方法,即增强依赖图和注意机制的药物-药物相互作用提取。具体而言,利用一些潜在的长程词来增强依赖图,以完成语义信息并适应图神经网络的聚合过程。采用图关注机制,通过根据特定任务区分连接节点,进一步改进单词表示。DDIExtraction 2013语料库(该领域的基准语料库)的数值实验证明了我们提出的方法的优越性。
2.Introduction
事实上,注意一些长距离单词和辨别邻居的能力对于提取DDI很重要。由于自动提取的依赖关系图仅描述单词之间的一阶修饰关系。仅使用这些直接连接的词来生成GNN的表示可能会导致语义不完整并丢失一些关键信息。此外,每个单词中包含的信息都是多种多样的,并不是所有这些信息都是表示毒品所必需的。平等对待它们,没有适当的区分,不能为下面的交互分类提供语义突出的表示。
为了解决这些问题,我们建议在增强的依赖图上采用图关注机制,以生成用于DDI提取任务的药物的更精确表示。具体而言,在整个句子上采用双向长短记忆(BiLSTM),首先从顺序方面学习每个单词的表示。然后,将最著名的图分析方法PageRank应用于整个依赖图,为每个单词生成更合适的表示集,该方法已被证明是有效的。之后,采用在表示和可解释性方面突出的注意机制,进一步区分相关词,并从图形方面生成表示。最后,通过最大池层获得的整个句子和两种目标药物的表示被连接并馈送到Softmax分类器中,用于DDI分类。在DDIExtraction 2013语料库上进行了数值实验。与以前的DDI提取模型的比较结果证明了我们的新方法的优越性。性能研究证明了在DDI提取任务中关注长距离单词和辨别邻居的有效性。
我们工作的主要贡献可以总结如下:
•我们提出了一种基于GNN的DDI提取新框架,名为药物-药物相互作用extraction with Enhanced Dependency Graph and Attention Mechanism(DREAM)。
•为了捕获更关键的语义信息,我们建议使用PageRank发现的长距离潜在单词来增强依赖关系图。
•为了正确区分连接词,我们建议根据下游任务通过图关注机制区分增强依赖图中的连接节点。
•我们对DDIExtraction 2013语料库进行了广泛的实验。结果表明,DREAM有效地提高了DDI提取的性能。
3.方法
DREAM的框架:主要由四个部分组成,即顺序表示生成模块、依赖图增强模块、图表示生成模块和关系分类模块。【DREAM的输入是一个包含目标药物实体对的句子,其中预先标记了目标药物。DREAM的输出是预测的药物之间的相互作用。】
首先,使用BiLSTM从序列信息的角度生成单词表示。接下来,通过一些长程潜在词来增强依赖图中词之间的依赖关系。然后,将图关注机制应用于增强依赖图,以从图信息的角度生成表示。最后,将目标药物的表示和整个句子连接起来,进行最终的关系分类。DREAM中每个模块的详细信息如下所述。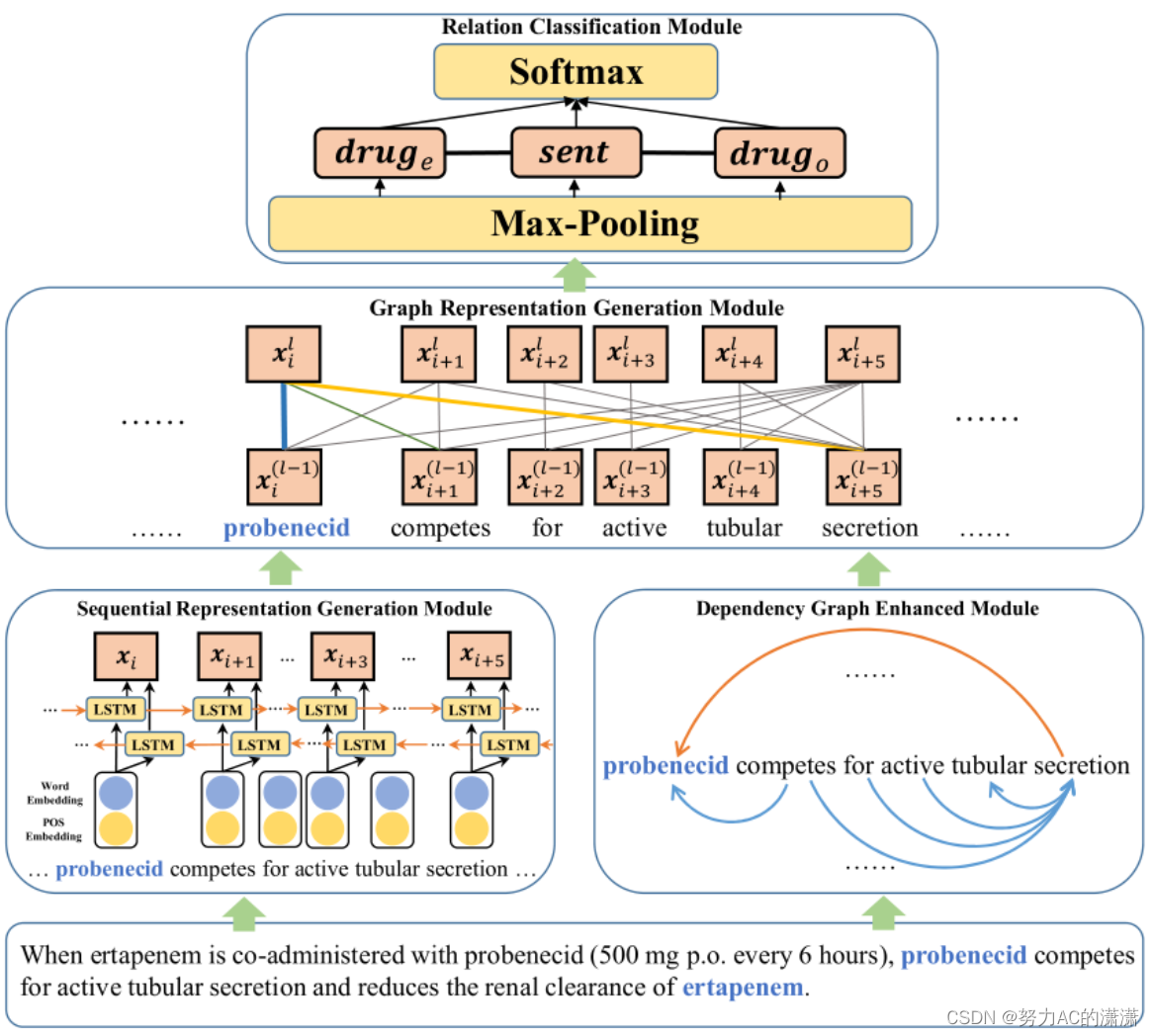
当埃塔培南与丙磺舒(每6小时500 mg P.O.)联合使用时。丙磺舒能有效分泌肾小管,降低肾清除率。
蓝色单词“probenecid”和“ertapenem”是关系提取的目标单词。在通过预先训练的单词嵌入模型进行初始化之后,首先通过序列信息来丰富单词的表示。同时,根据依存结构的分析,选择长距离词“分泌”来增强“丙磺舒”的语义信息。通过更新来自邻居和所选潜在单词的药物表示,最终表示被馈送到分类模块以获得关系
3.1.顺序表示生成模块
单词嵌入是所有NLP任务的关键部分。因此,我们首先为句子中的每个单词生成一个初步嵌入。
给定包含目标药物实体对(druge,drugo)的句子S={w1,w2,…,wn},使用专门为生物医学领域设计的单词嵌入预训练模型来初始化每个单词[36]。此外,由于词性(POS)也是单词的一个重要特征,斯坦福CoreNLP工具包[37]用于标记句子P={p1,p2,…,pn}的POS标签序列。然后,对于wi∈ S,将相应的标记pi进一步转换为低维密集向量,并结合wi的嵌入作为后续过程的最终初始表示xi。
为了获得特定句子中每个单词的准确表示,采用BiLSTM从顺序的角度更新单词嵌入。它主要包括两个部分:正向 LSTM⟶ 和反向LSTM⟵ , 它可以从两个方向学习序列信息,其详细过程可以表示为:
3.2.依赖图增强模块
依赖关系描述了句子中单词之间的修饰关系,对语义理解至关重要。通过将这些关系结合到单词嵌入中,额外的语义依赖信息将有效地改进药物的表示,并促进以下分类的性能。
为了获得句子S={w1,w2,…,wn}中存在的依赖关系,使用斯坦福CoreNLP工具包[37]中的依赖解析器来提取其整个依赖图。通过将依赖图视为无向图,可以将其转换为对称依赖矩阵D∈ Rn×n。具体来说,如果单词wi和单词wj之间存在依赖关系, 在相依图中,Dij和Dji的值被赋值为1。相应地,如果两个词之间没有关系,则相依矩阵D中它们的值被赋值为0。
在获得记录在依赖矩阵D中的依赖关系之后,如何将这些结构信息集成到单词的最终表示中成为下一个需要解决的问题。GNN可以同时聚合结构信息和特征信息,是最佳选择。但是依赖矩阵D不能直接输入GNN模型。因为GNN是选择最相关的节点作为信息源来生成目标节点的表示。但依赖图中的边只表示特定的一阶修饰关系,而不是GNN通常采用的完整相关关系。大多数与目标词相关的完整语义信息不能仅仅通过两个连接词的信息和它们之间的一阶修饰关系来全面描述。缺少结构信息,尤其是图中关键节点中的结构信息,将对聚合效果产生很大影响。因此,依赖关系图中的一些多跳邻居可能会向目标词传递更合适的语义信息,并且对于其表示是必不可少的。
为了解决这个问题,在表示过程中,为了使每个目标词的信息源完成一些关键的语义信息,我们建议通过扩展一些潜在的相关多跳邻居来增强依赖矩阵D,这些邻居具有较高的信息传递性。PageRank[38]作为最著名和最有效的图形分析方法,适合于信息可传递性评估。通过从图中的邻居接收消息并不断更新表示直到达到稳定点,PageRank可以根据不同节点的独特结构信息为其赋予适当的分数。结合具体的应用场景,PageRank的上述过程可以表述为:
其中PRl(wi)表示第l次迭代中wi的PageRank分数,n表示句子中包含的单词数,d表示阻尼系数,Ni表示与wi相连的单词集。通过连续迭代直到最终收敛,每个节点根据其自身的依赖结构获得一致且可比较的分数。PageRank得分的最终值向量表示为PR。PR的分量越大,对应单词在依赖图中的信息传递能力越强。因此,我们首先选择PageRank得分最高的前t个单词top(PR,t)作为潜在信息源的候选。
随着链路数量的增加,节点之间的影响将逐渐减弱,尽管一些节点具有很高的信息传递能力,但它们几乎不可能将自己的信息传递给远处的一些节点。也就是说,由于GNN中的聚合是基于本地消息传递的,因此应该通过考虑节点之间的信息传输路径来个性化潜在的信息源选择。因此,为了确保候选词与目标词的相关程度,我们进一步设置了k-hop等词的有效影响范围。也就是说,在依赖图中PageRank得分最高的Top(PR,t)中的这t个单词中,只有在目标的k跳邻居内的单词将被附加到信息源中。完整的扩展策略可以表示为:
3.3.图表示生成模块
除了用一些可能包含重要语义信息的长距离词来增强依赖图之外,正确区分不同的连接词对于不同词的表示和后续交互分类任务也很重要。与GNN一样,拓扑结构揭示了消息传递的方式,而每个节点的特性揭示了消息的内容。不同的词对目标词的表达有不同的贡献,因为它们所携带的各种信息。因此,在表示过程中,哪些连接词应该被更多地关注,这高度依赖于它们的信息和下游任务。
为此,采用基于自注意的图形注意机制来区分连接词,并且相应的注意系数表示关联度。具体地,对于句子S中目标词wi的每个连接词wj,wj到wi的关注系数α(wi,wj)计算如下
然后,还进行了多头策略,以捕获目标词与其连接词之间的更多模式,如下所示:
为了将具有不同系数的连接词的信息合并在一起,我们对最后一个周期求平均,以获得最终表示Ywi: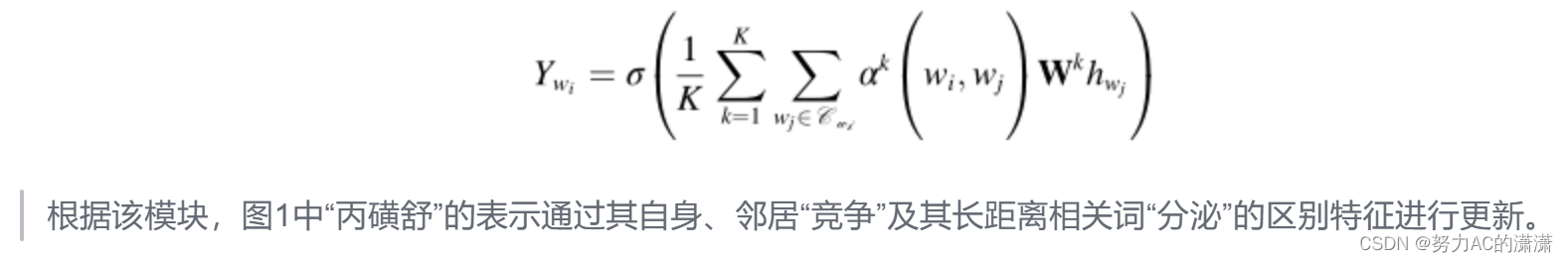
3.4.关系分类模块
到目前为止,句子S={w1,w2,…,wn}中包含的包括药物的单词的所有嵌入都从句子的顺序和整个依赖图的结构两方面进行了更新。由于我们观察到一些药物包含不止一个标记,例如,druge={we1,we2,…,wep}和drugo={wo1,wo2,……,woq},为了统一药物的所有表示形式,我们有:
考虑到DDI提取本质上是与两种药物组合相关的分类任务,药物实体对可以表示为: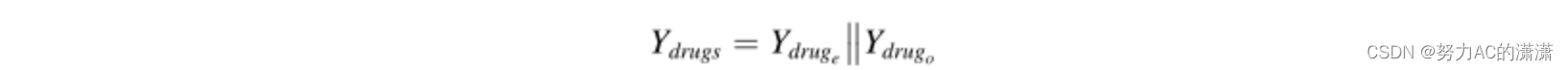
此外,句子的语义在交互作用的分类中也是不可或缺的,可以通过以下方法获得:(Ysend句子表示)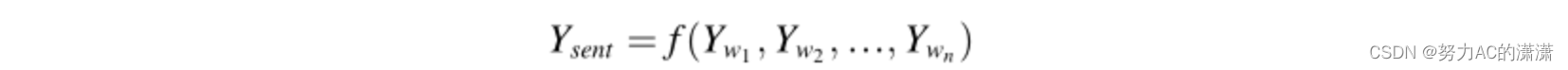 为了预测最终的DDI相互作用,句子和药物实体的表示(例如,“probenecid”、“ertapenem”和图1中的相应句子)被连接起来,并使用Softmax分类器计算所有类别的概率分布:
为了预测最终的DDI相互作用,句子和药物实体的表示(例如,“probenecid”、“ertapenem”和图1中的相应句子)被连接起来,并使用Softmax分类器计算所有类别的概率分布: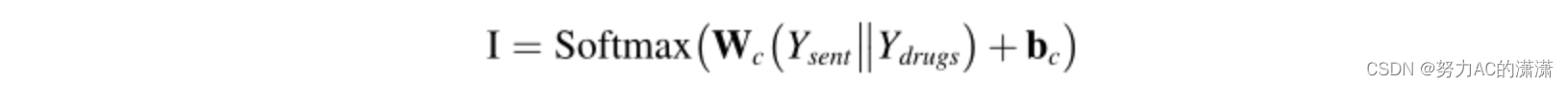
4.实验
4.1数据集
为了验证我们提出的DREAM的有效性,选择了基准数据集DDIExtraction 2013语料库,其中包括来自DrugBank数据库的792个文档和来自MEDLINE的233个摘要。在这个精细的语料库中,共注释了18502种药理物质和5028种药物之间的相互作用,包括药代动力学和药效学相互作用。该数据集中包含4种有效的DDI类型:Advice、Effect、Int、Mechanism。药物实体对之间的关系,不属于前面提到的任何四种DDI,被注释为否定的,并且明显多于肯定的例子。为了缓解类不平衡问题,通过先前工作中采用的负实例过滤策略过滤掉尽可能多的负实例[8,22,23]。为了确保实验结果在其他基线模型中大体上具有可比性,我们遵循[19]的划分。表1总结了统计数据和分类。
4.2 对比实验
由于DDIExtraction 2013任务是一个多分类问题,我们采用标准的微平均精度、召回率和F1分数来评估性能,公式如下: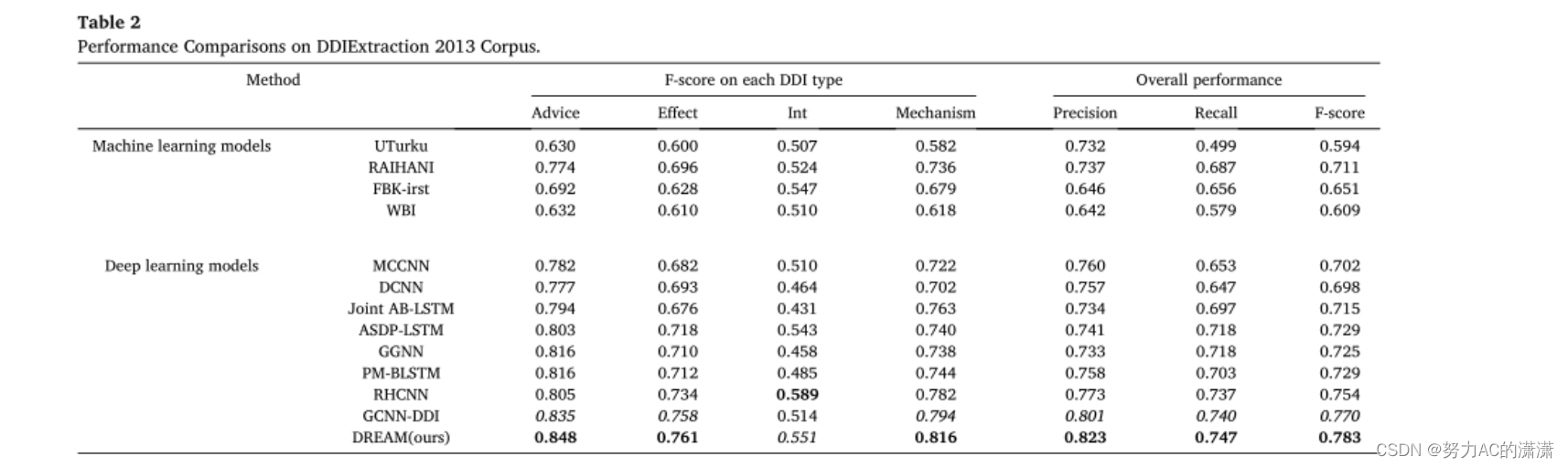
结论
在本文中,我们提出了DREAM,一种新的基于GNN的DDI提取任务框架。具体地说,首先采用BiLSTM从句子序列信息的角度对句子中每个单词的上下文信息进行编码。然后,通过基于PageRank的模块发现的一些潜在的长距离单词来增强依赖关系图。之后,还采用图关注机制来正确地区分连接词,并从依赖结构信息的角度更新每个词的表示。最后,通过将药物实体的连接表示和句子输入Softmax分类器,获得药物实体之间的交互。在DDI提取2013语料库上与多个基线进行的广泛比较实验证明了我们提出的DREAM的优越性,并验证了在DDI抽取任务中关注长距离单词和正确识别连接单词的有效性。
未来可以考虑对DREAM进行一些潜在的改进和扩展。首先,我们的模型在Int交互分类中的性能不令人满意,将探索一些改进小训练样本性能的策略。依赖关系图中包含的特定修饰语关系没有得到充分利用,如何将这些信息有效地融入到单词表示中也是一个有趣且具有挑战性的话题

