
- 1新书周榜:机器学习、Python、Linux成为最闪亮的星_linux设备驱动开发 刘寿永
- 2《ChatGPT原理与架构:大模型的预训练、迁移和中间件编程 》
- 3Azure系列2.1.11 —— CloudBlobContainer
- 43.15国际消费者权益日:消费者隐私威胁与保护
- 5获取docker镜像内文件_docker镜像提取文件
- 6浅谈集群和分布式的区别和联系_做了分布式部署还有必要做集群吗?
- 7MAC(适用于M1,M2芯片)下载Java8(官方 ARM64 JDK1.8)安装、配置环境,支持动态切换JDK_mac jdk1.8下载
- 8org/apache/commons/logging/LogFactory
- 9常见软件发布版本编号解释
- 10模拟电子技术------半导体_为什么 电子漂移运动是不利现象
基于内容的图像检索技术综述-CNN方法_图像检索综述
赞
踩
基于内容的图像检索技术综述-CNN方法
manyi-管永来
传统方法在图像检索技术上一直表现平平。比如传统方法常用的SIFT特征,它对一定程度内的缩放、平移、旋转、视角改变、亮度调整等畸变,都具有不变性,是当时最重要的图像特征提取方法之一。然而SIFT这类算法提取的特征还是有局限性的,在ImageNet ILSVRC比赛的最好结果的错误率也有26%以上,而且常年难以产生突破。而图像检索的发展目标是希望模型又快又准,因此兴起了基于CNN的方法,从原来AlexNet、VGGnet,到体积小一点的Inception、Resnet系列,再到DenseNet系列无不体现出了这一趋势。和传统方法一样,CNN方法也是对图片提取特征,比如CNN网络中的一个feature map就可以看做是一个类似SIFT的向量。
计算机视觉比赛ILSVRC(ImageNet Large Scale Visual Recognition Competition)使用的数据都来自ImageNet,该项目于2007年由斯坦福大学华人教授李飞飞创办。ImageNet拥有1500万张标注过的高清图片,总共拥有22000类,其中约有100万张标注了图片中主要物体的定位边框。每年度的ILSVRC比赛数据集中大概拥有120万张图片,以及1000类的标注,是ImageNet全部数据的一个子集。比赛一般采用top-5和top-1分类错误率作为模型性能的评测指标。
和SIFT等算法类似,CNN训练的模型同样对缩放、平移、旋转等畸变具有不变性,有着很强的泛化性。CNN的最大特点在于卷积的权值共享结构,可以大幅减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度。
一、AlexNet
论文:ImageNet Classification with Deep Convolutional Neural Networks1[1]
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet。其官方提供的数据模型,准确率达到57.1%,这项对于传统的机器学习分类算法而言,已经相当的出色。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层,图中可以看到,AlexNet还用了11×11和5×5的大卷积核,具体的网络参数可以参考这里:https://blog.csdn.net/guoyunfei20/article/details/78122504,网络结构如下图所示:
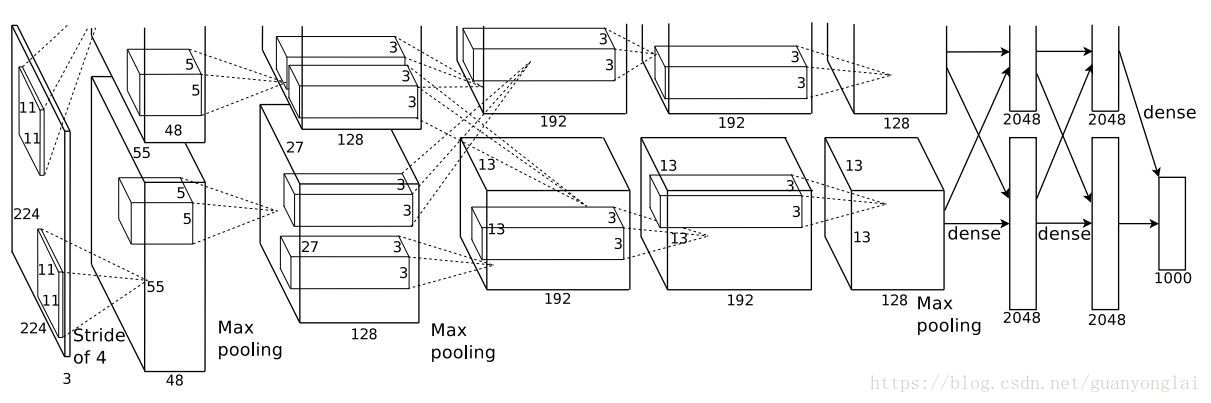
图1 AlexNet网路结构
二、VGG(Visual Geometry Group)
论文:Very deep convolutional networks for large-scale image recognition[2]
图片的预处理就是每一个像素减去了均值,算是比较简单的处理。然后缩放图像最小边到256或者384,然后裁剪得到输入数据是224*224进行训练。网络有5个最大池化层,整体使用的卷积核都比较小(3x3),3x3是可以表示「左右」、「上下」、「中心」这些模式的最小单元了,VGG16的网络缩略图如下所示:
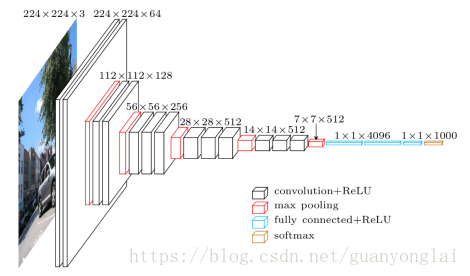
图2 VGG16网络结构图
VGG是最早利用2个3×3卷积核的组合代替1个5×5卷积核的网络,使用多个较小卷积核代替一个较大的卷积核,一方面可以减少参数,另一方面作者认为相当于是进行了更多的非线性映射,可以增加网络的拟合/表达能力。还有比较特殊的1x1的卷积核(Inception-v1也有这个东西),可看做是空间的线性映射。前面几层是卷积层的堆叠,后面几层是全连接层,最后是softmax层。所有隐层的激活单元都是ReLU,论文中介绍好几个网络结构,只有其中一个应用了局部响应归一化层(Local Response Normalisation)。

图3 A-E的VGG网路结构对比
上图列出了6种VGG网络结构图,其中VGG16和VGG19较为常见,也是性能最好的两个网络结构,下面是对A-E的网络性能进行分析:
A与A-LRN比较:A-LRN结果没有A好,说明LRN作用不大;
A与B, C, D, E比较,A是这当中layer最少的,相比之下A效果不如B,C,D,E,说明Layer越深越好;
B与C比较:增加1x1filter,增加了额外的非线性提升效果;
C与D比较:3x3 的filter(结构D)比1x1(结构C)的效果好。
总结了下VGG网络的结构,可以发现以下趋势:
①可以看到VGG网络中共有5个池化层,所以可以把卷积部分视为5个部分,和AlexNet一样,只不过每一个部分他用了不止一层卷积层;
②所有卷积层都是同样大小的filter!尺寸3x3,卷积步长Stirde = 1,填充Padding = 1;
③卷积层变多了。结构E有16层卷积层,加上全连接层共19层。这也是对深度学习继续往深处走的一个推动。因为深度神经网络的参数特别多(可以达到上亿,目前已经可以支持到万亿参数)。参数多,表示模型的搜索空间就越大,必须有足够的数据才能更好地刻画出模型在空间上的分布。
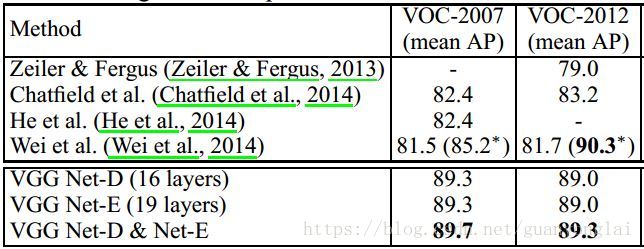
图4 VGG网络性能比较
三、Incepetion V1
论文:Going deeper with convolutions[3]
在 ILSVRC 2014 取得了最好的成绩的 GoogLeNet,及其核心结构是Inception,传统的网络中,计算机软硬件对非均匀稀疏数据的计算效率很差,故AlexNet又重新启用了全连接层,目的是为了更好地优化并行运算。所以,现在考虑有没有一种既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能的方法。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
Incepetion V1总共有22层layers,只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
Incepetion V1有一个重要的特点:每层使用多个卷积核。传统的层叠式网络,基本上都是一个个卷积层的堆叠,每层只用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3卷积层。事实上,同一层feature map可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,谷歌的GoogleNet,或者说Inception系列的网络,就使用了多个卷积核的结构:
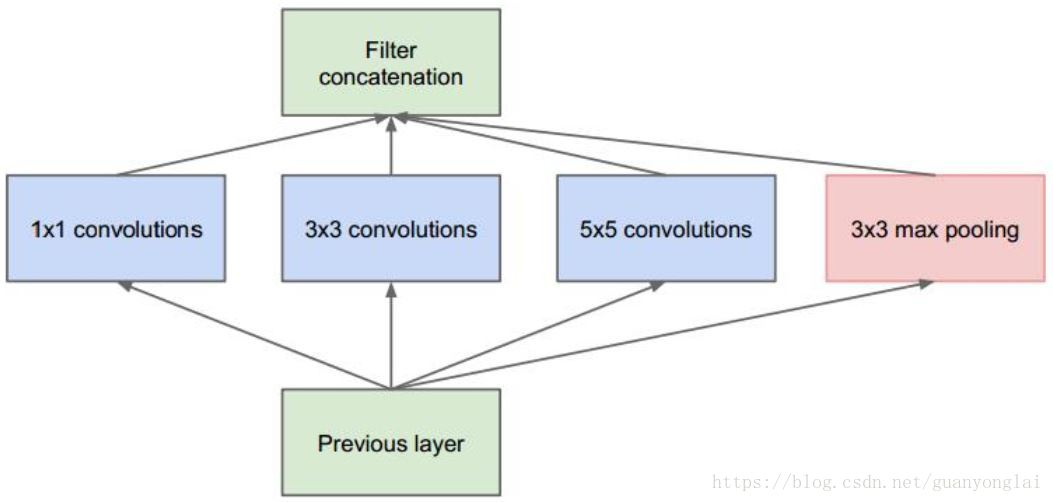
图5 Incepetion V1的多尺度卷积层
如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如图所示:
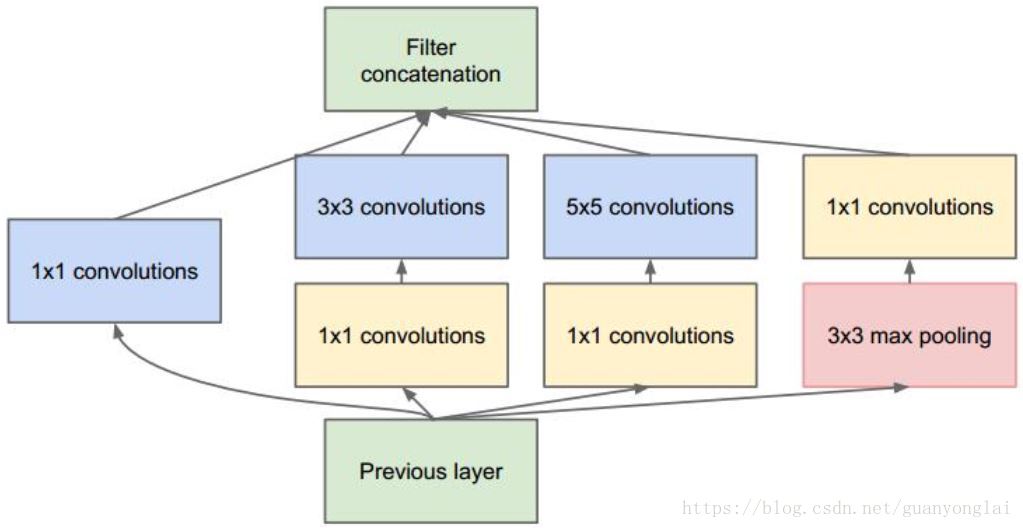
图6 Incepetion V1引入1×1卷积核
1×1的卷积核能降低计算量,如下图所示,左图表示引入1×1的卷积核之前的网络,其参数量为256×3×3×256=589824,右图表示引入1×1的卷积核之后的网络,其参数量为256×1×1×64+64×3×3×256+64×1×1×256=69632,参数量几乎减少了一个数量级。1×1卷积核也被认为是影响深远的操作,往后大型的网络为了降低参数量都会应用上1×1卷积核,引入1×1的卷积核能达到降维和升维的目的。
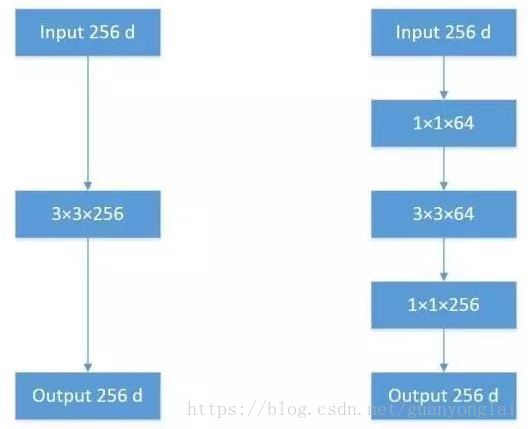
图7 引入1×1卷积核前后对比
四、Incepetion V2
论文:Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift
下面的准则来源于大量的实验,因此包含一定的推测,但实际证明基本都是有效的:
1 . 避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map基本都会逐渐变小,但是一下子就变得很小显然不合适。 另外输出的维度channel,一般来说会逐渐增多,否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
Inception V2 学习了 VGG 用两个3×3的卷积代替一个5×5的大卷积,在降低参数的同时建立了更多的非线性变换,使得 CNN 对特征的学习能力更强:
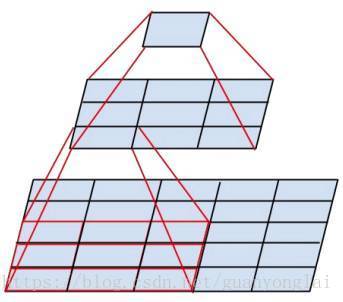
图8 替换5×5的卷积核
另外Inception V2还提出了著名的 Batch Normalization(简称BN)方法。BN 是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN 在用于神经网络某层时,会对每一个 mini-batch 数据的内部进行标准化处理,使输出规范化到 N(0,1) 的正态分布,减少了内部神经元分布改变的影响。
其相对于传统神经网络的差别是:传统神经网络只是在将样本输入层之前对样本进行标准化处理(减均值,除标准差),以降低样本间的差异性。BN是在此基础上,不仅仅只对输入进行标准化,还对每个隐藏层的输入进行标准化。
BN 的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用 BN 之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有之前的1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终取得远超于 Inception V1 模型的性能: top-5 错误率 4.8%,远低于Inception V1的6.7%,已经优于人眼水平。因为 BN 某种意义上还起到了正则化的作用,所以可以减少或者取消 Dropout 和 LRN,简化网络结构。
五、Incepetion V3
论文:Rethinking the Inception Architecture for Computer Vision[5]
一是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7x7卷积拆成1x7卷积和7x1卷积,或者将3x3卷积拆成1x3卷积和3x1卷积,另外也使用了将5x5 用两个 3x3 卷积替换,7x7 用三个 3x3 卷积替换,如下图所示。一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
另一方面,Inception V3 优化了 Inception Module 的结构,网络输入从224x224变为了299x299,现在 Inception Module 有35×35、17×17和8×8三种不同结构。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8×8的结构中),可以说是Network In Network In Network。最终取得 top-5 错误率 3.5%的效果。
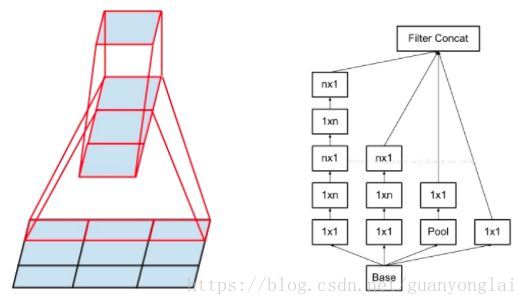
图9 使用一维卷积核代替二维卷积核
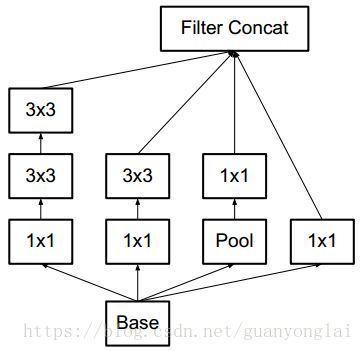
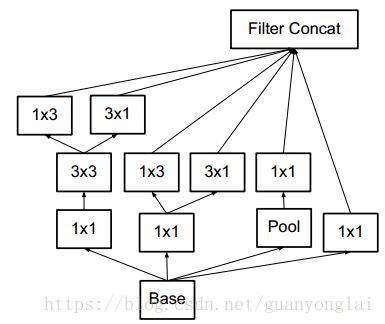
图10 使用1×3代替3×3卷积核
六、Incepetion V4
论文:Inception v4-Inception-ResNet and the Impact of Residual Connections on Learning[6]
Inception V4相比V3主要是结合了微软的 ResNet,将错误率进一步减少到 3.08%。V4研究了Inception模块结合Residual Connection能不能有改进,发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception V4模型,能达到与Inception-ResNet v2相媲美的性能,inception V4总体的网络结构为:
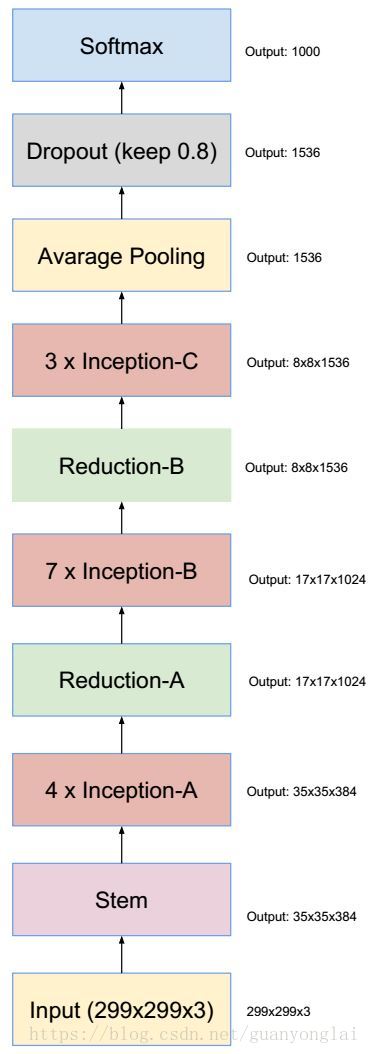
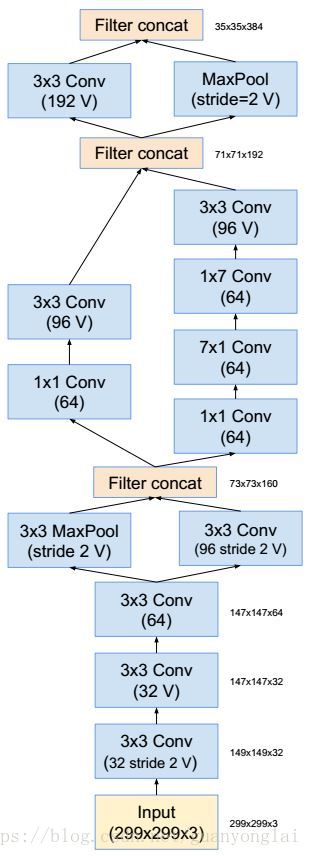
图11 Inception v4总体结构和Stem部分
其他部分的结构如下:
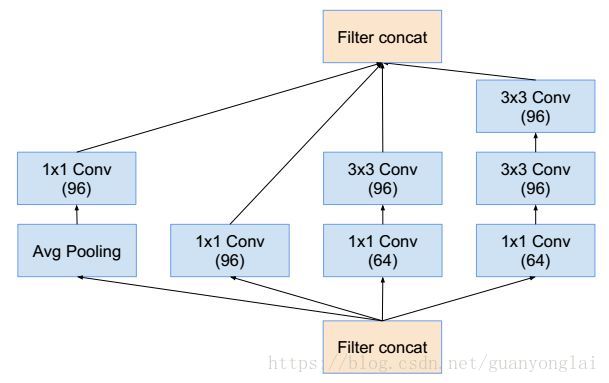
图12 Inception A
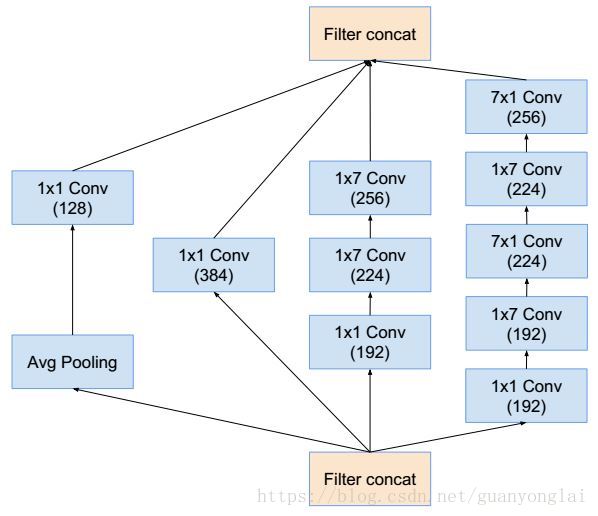
图13 Inception B
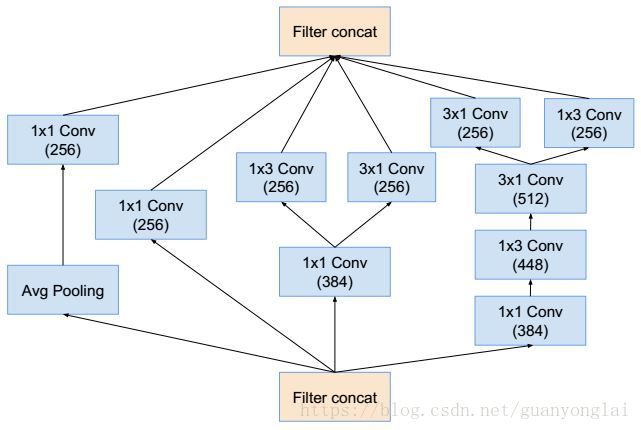
图14 Inception C
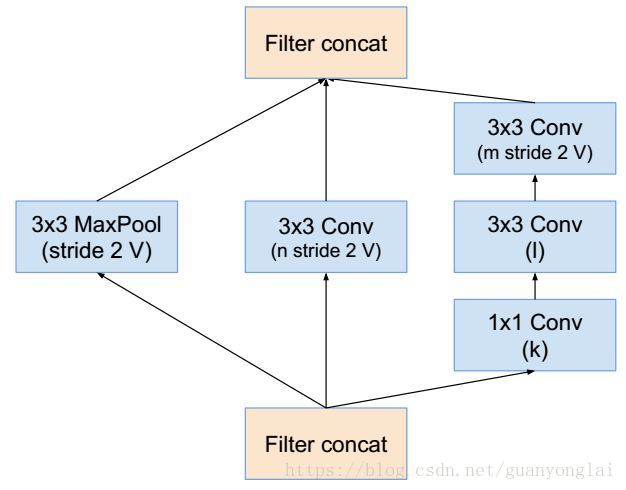
图15 Reduction A
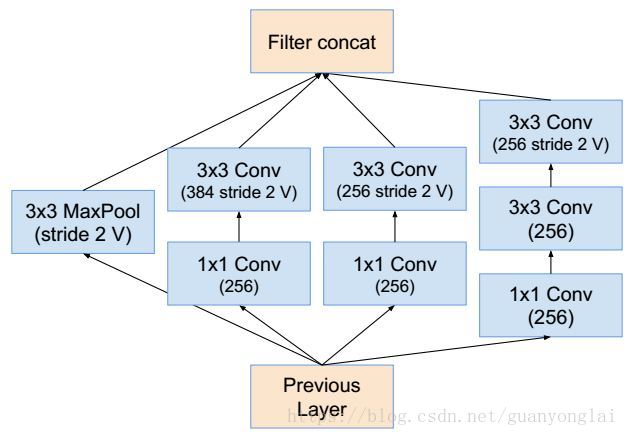
图16 Reduction B
同时作者在该篇论文中还提出了Inception-ResNet-v1和Inception-ResNet-v2。Inception-V4是纯粹的Inception变体,没有剩余连接,具有与Inception-ResNet-v2大致相同的识别性能。几种网络在Single crop - single下的识别结果为:
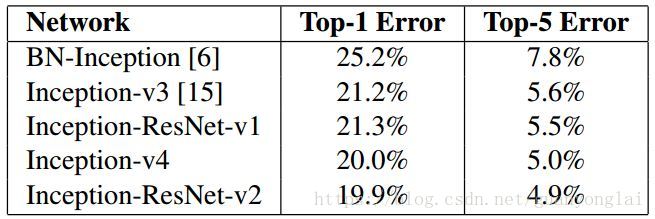
图17 Inception-V4性能对比
七、ResNet
论文:Deep residual learning for image recognition[7]
如果说 googlLeNet、AlexNet、VGG 奠定了经典神经网络的基础,Inception 和ResNet 则展示了神经网络的新范式,在这两个范式的基础上,发展创新并相互借鉴,有了 Inception 流派的 Inception v2 到 v4、Inception-ResNet v1 和 v2,以及 ResNet 流派的DenseNet等。
ResNet的输入是在图片上随机裁剪224×224的像素块,网络中没有采用dropout。
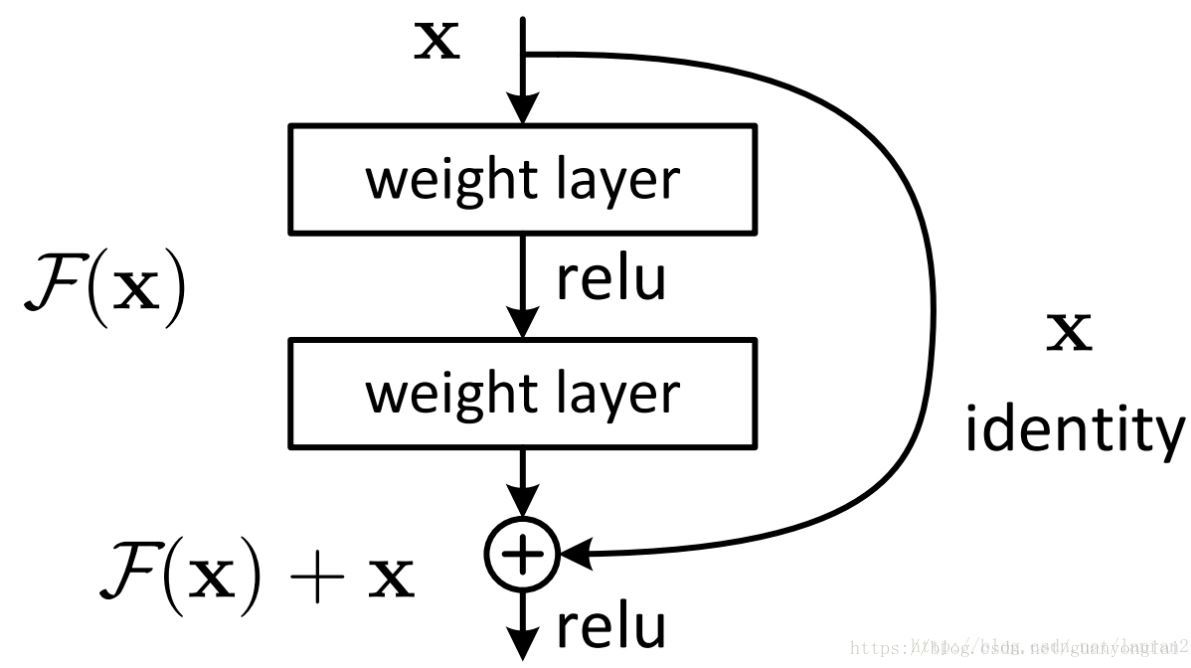
图18 Residual网络模型
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能地加深,其中引入了全新的结构如上图所示。
其中ResNet提出了两种mapping:一种是identity mapping(恒等映射),指的就是上图中弯弯的曲线,另一种residual mapping,指的就是除了曲线外的那部分,所以最后的输出是 y=F(x)+x,identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。 如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了,但实际上,identify mapping一般不是最优的。
这其中要注意一个问题,就是在y=F(x)+x的时候要保证F(x)和x的维度相同,若他们的维度不同,就需要对x乘一个对应的权重,即:y=F(x)+Ws*x,以此来保证F(x)和x具有相同的维度。用来学习残差的网络层数应当大于1,否则退化为线性。文章实验了layers = 2或3,更多的层也是可行的。
ResNet在运算效率的准确率方面都有所提升,比如ResNet34的运算量只有VGG19的18%,VGG19需要进行196亿次浮点运算,而ResNet34只需要进行36亿次浮点运算,效率大大提升,下图从左到右依次为VGG19、plain-networks34和ResNet34的结构图:
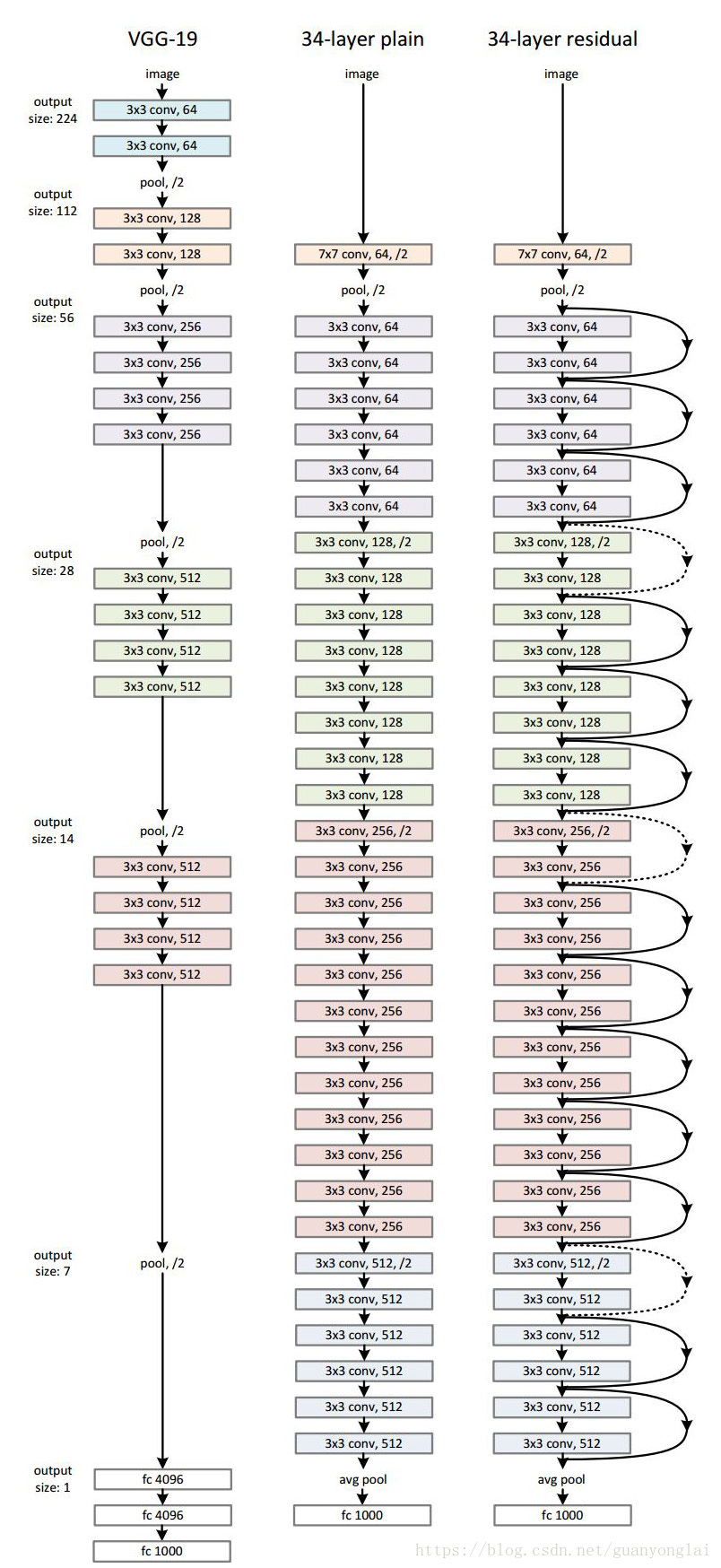
图19 VGG19、plain-networks34和ResNet34结构图
对于plain-networks,随着网络层数的加深,错误率反而会上升,因为增加深度会带来网络退化问题,使训练集上的准确率饱和甚至下降,并且深层网络容易产生梯度消失或爆炸,而加了identity的网络就不会存在这样的问题,因为残差网络更容易优化,能够通过单纯地增加网络深度,来提高网络性能。
为什么网络的加深很重要呢?因为CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
八、DenseNet
论文:Densely Connected Convolutional Networks[8]
DenseNet的思想启发来源:
DenseNet 的想法很大程度上源于作者2016年发表在 ECCV 上的一个叫做随机深度网络(Deep networks with stochastic depth)工作。当时作者提出了一种类似于 Dropout 的方法来改进ResNet。发现在训练过程中的每一步都随机地扔掉(drop)一些层,可以显著的提高 ResNet 的泛化性能。这个方法的成功带来以下两点启发:
1)首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,还可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第 l 层被扔掉之后,第 L+1 层就被直接连到了第 L-1 层;当第 2 到了第 L 层都被扔掉之后,第 L+1 层就直接用到了第 1 层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的 DenseNet。
2)其次,在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNet 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,将训练好的 ResNet 随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别窄,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,就不可能把网络设计得太窄,否则训练会出现欠拟合现象,即使 ResNet 也是如此。
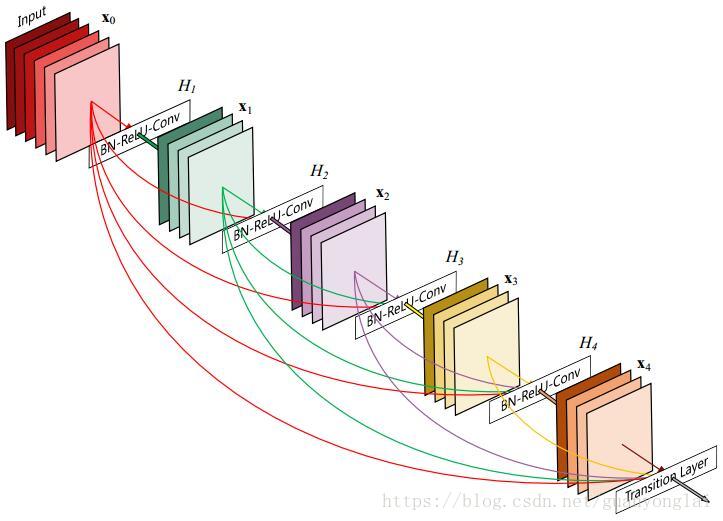
图20 Dense Block模拟图
上图是一个详细的Dense Block的模拟,其中层数为5,即具有5个BN+Relu+Conv(3*3)这样的layer,网络增长率k为4,简单的说就是每一个layer输出的feature map的维度为k。即:第L层网络的输入为k × (L- 1) + k0 ,这里的k0为原始输入的通道数,然后把k × (L- 1) + k0降维为k,再把这个k加上前面所有的连接作为L+1层的输入,即第L+1层网络的输入为k× L + k0。由于DenseNet的每一个Dense Block模块都利用到了该模块中前面所有层的信息,即每一个layer都和前面的layer有highway的稠密连接。假设一个具有L层的网络,那么highway稠密连接数目为L*(L+1)/2。和Resnet不同的是,这里的连接方式得到的feature map做的是concat操作,而resnet中做的是elementwise操作。
现在回到论文上,作者在论文中提出的DenseNet的网络结构为:
1)三个block,每一个block具有相等个数的layers,如下图所示;
2)所有卷积层都使用3×3的卷积核;
3)用zeros-padding和2×2的average pooling来调整feature map的大小使之固定到同一尺寸;
4)最后一个block的输出后面接一个全局average pooling和一个softmax 分类器;
5)feature map 的尺寸在三个block里面分别为32× 32、16×16、8×8;
6)网络增长率k和block里面的layers层数有两种方案:k = 12,L=40, 以及k = 24,L=100。

图21 DenseNet的三个block
DenseNet在识别率上的表现也非常不错,在同一识别率的情况下,DenseNet的参数复杂度约为ResNet的一半。
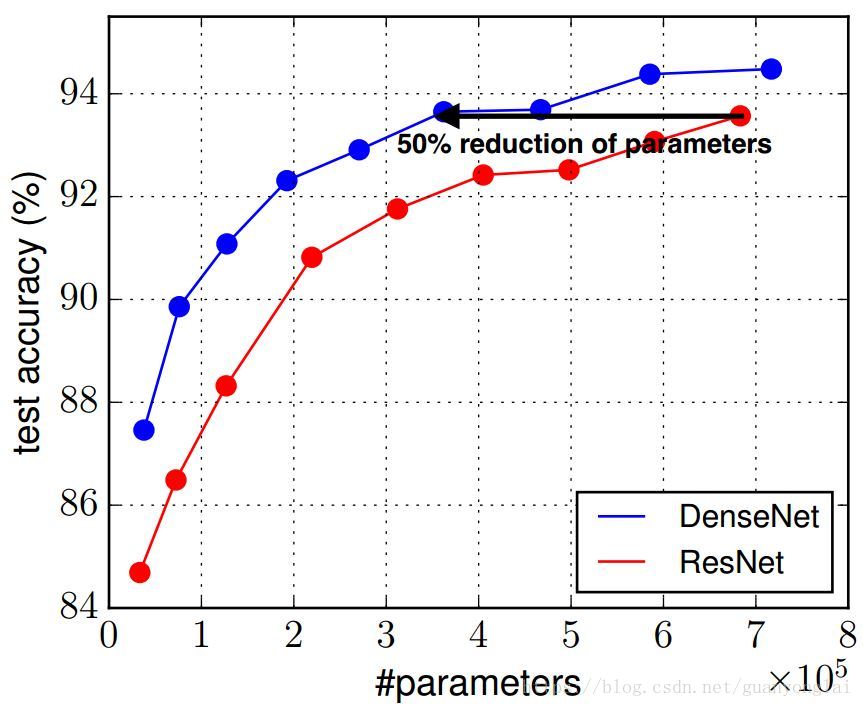
图22 DenseNet和ResNet的参数复杂度对比
DenseNet计算量小的原因:DenseNet和ResNet相比的一个优点是设置很小的k值,使得网络更窄从而参数更少。在 dense block中每个卷积层的输出feature map的数量k都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。另外论文还观察到这种denseblock有正则化的效果,因此对于过拟合有一定的抑制作用,可能是因为网络通道更窄使得参数减少了,所以过拟合现象减轻。
九、SENet
论文:Squeeze-and-Excitation Networks[9]
SENet是基于特征通道之间的关系提出的,下图是SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入和输出,这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(称为Squeeze过程),输出是一个1x1xC的数据,再经过两级全连接(称为Excitation过程),最后用sigmoid把输出限制到[0,1]的范围,把这个值作为scale再乘到U的C个通道上,作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
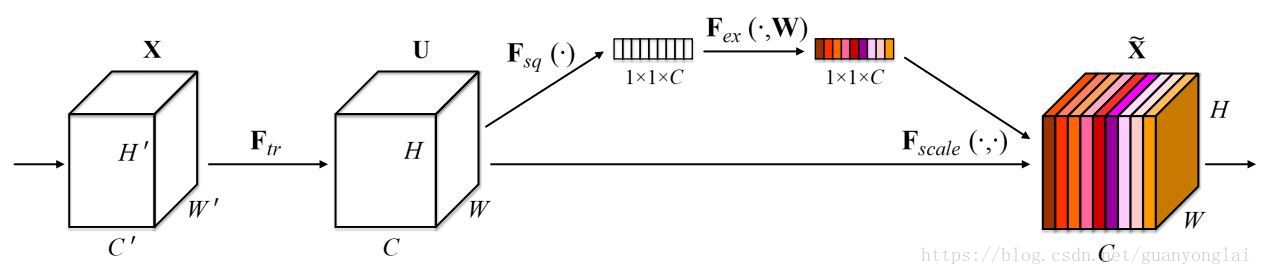
图23 SENet的Squeeze-Excitation block
下图是把SENet模型分别用于Inception网络和ResNet网络,下图左边部分是原始网络,右边部分是加了SENet之后的网络,分别变成SE-Inception和SE-ResNet。网络中的r是压缩参数,先通过第一个全连接层把1x1xC的数据压缩为1x1xC/r,再通过第二个全连接层把数据扩展到1x1xC,
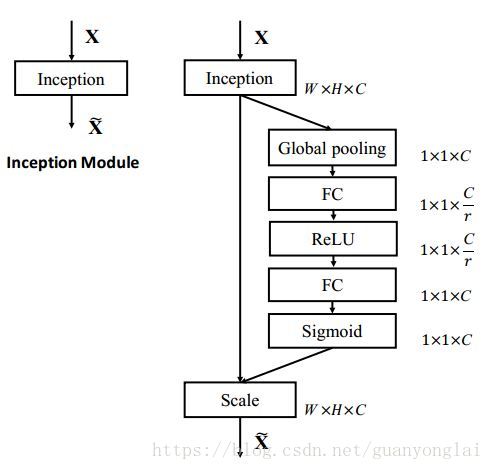
图24 SE-Inception
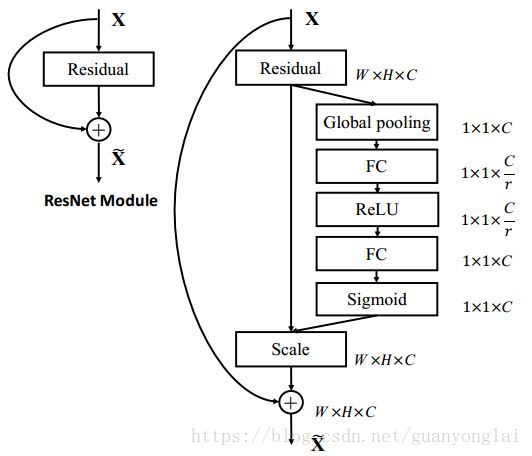
图25 SE-ResNet
十、netVLAD
相对于传统的人工设计特征,CNN已经在图像特征提取上显示出了强大的功力。在图像检索问题中,目前有基于全局和基于局部两种卷积神经网络特征表示方法。基于全局的方法直接使用卷积神经网络提取整幅图像的特征,作为最终的图像特征。但是因为卷积神经网络主要对全局空间信息进行编码,导致所得特征缺乏对图像的尺度、旋转、平移等几何变换和空间布局变化的不变性,限制了其对于高度易变图像检索的鲁棒性。对于基于局部的方法,使用卷积神经网络提取图像局部区域的特征(这里的局部区域特征好比经典方法的SIFT特征),然后聚合这些区域特征生成最终的图像特征。虽然这些方法考虑到了图像的局部信息,但仍有一些缺陷。例如使用滑动窗口来得到图像区域时,由于没有考虑到图像的颜色、纹理、边缘等视觉内容,会产生大量无语义意义的区域,为之后的聚合过程带来冗余和噪声信息。另外,区域特征融合通常所使用的最大池化算法,因只保留了特征的最大响应而没有考虑特征间的关联,丢失大量信息,降低了所得的最终图像特征的区分性。
因此有学者提出netVLAD的方法。首先去掉CNN的最后一层,把它作为描述子,输出是 H×W×D 的向量,可以将其看作一个D维的描述子,总共有 H×W 个。相当于在整个图像上提取H×W 个D维描述子,然后对这H×W 个D维的描述子进行VLAD聚类,可以看做在CNN网络后面直接接一个netVLAD网络,如下图所示:
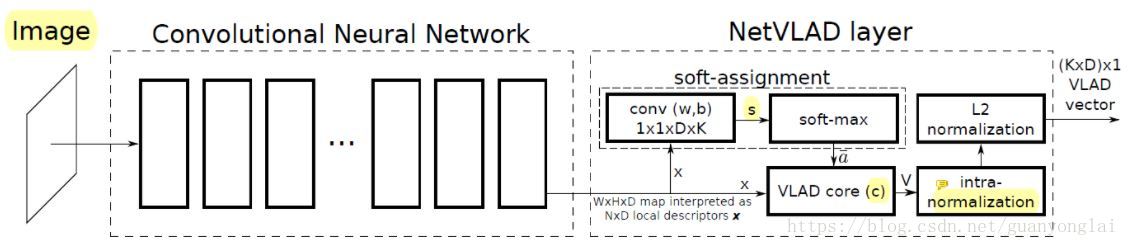
图26 CNN接netVLAD网络
还有学者提出基于对象的方法来解决以上问题。在生成图像区域时,使用基于内容的无监督对象生成方法,即通过图像颜色、纹理、边缘等视觉信息以聚类的方式来生成图像区域。常用方法有Selective search,如下图所示,Selective search在一张图片中提取1000-10000个bounding box,使之尽可能覆盖所有的物体,试验也证明,它的覆盖率能达到96%以上,足以提取丰富的局部区域特征。其特征描述也具有更高的区分性,同时基于对象特征进行融合,所得最终特征对场景中对象的空间布局变化也具有很好的鲁棒性。在聚合特征的过程时,采用上篇提到的VLAD算法,先将图像的局部区域特征进行聚类,然后统计一幅图像中所有区域特征与其相近聚类中心的累积残差来表示最终的图像特征。相对于最大池化算法,该方法考虑了区域特征间关联的同时对图像的局部信息有更细致的刻画,使得得到的最终图像特征对各类图像变换具有更高鲁棒性。

图27 Selective search示意图
十一、Loss函数优化
在传统的分类网络中,一般是对大类如猫、狗、鸟等类别进行分类,但其对于个体级别的细粒度识别上略显不足,而tripletloss和contrastive loss等算法就更注重于高细粒度同类样本和不同样本之间的损失计算。
(一)triplet loss
triplet loss具有以下优秀属性:端到端、简单直接、自带聚类属性、特征高度嵌入,triplet loss的具体操作步骤为:
首先从数据集N中随机取一个样本,记为Xa,然后再取一个同类样本Positive记为Xp,和一个不同类样本Negative记为Xn。Xa、Xp和Xn就构成了一个三元组,我们把三个样本的特征分别记为:,和。triplet loss的目的就是通过学习使Xa和Xp特征之间的距离尽可能小,使Xa和Xn特征之间的距离尽可能大,并且设置一个阈值t,使得Xa、Xp距离和Xa、Xn距离的差值大于该阈值,即:
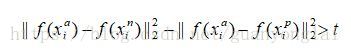
对应的损失函数为:
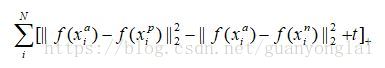
损失函数的含义为:当Xa与Xn之间的距离 小于 Xa与Xp之间的距离加t时,会产生大于0的loss,当Xa与Xn之间的距离 大于 Xa与Xp之间的距离加t时,上式中括号内的值小于0,loss按0计算。
训练的额过程可以用下图表示:
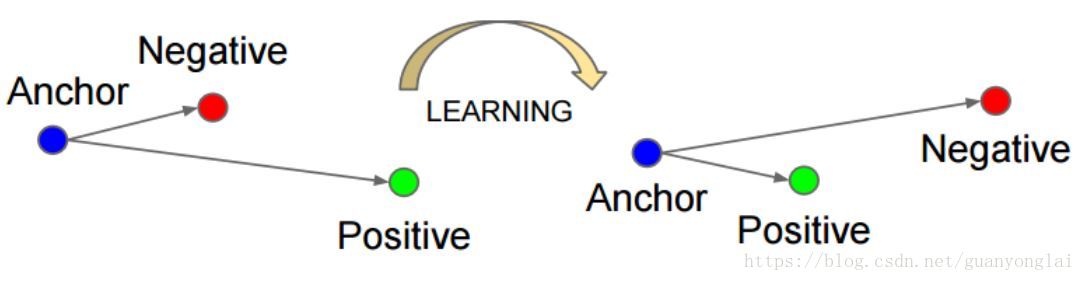
图28 triplet loss训练示意图
(二)Contrastive Loss
contrastive loss的表达式如下:
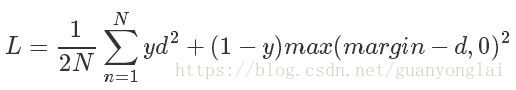
其中,代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相匹配,y=0则代表不匹配,margin为设定的阈值。观察可发现,当样本匹配时y=1,loss变为,此时若d比较大说明模型不好,因此loss也会相应地变大。当样本不匹配时y=0,loss变为,此时若d反而小,也说明模型不好,loss会相应地变大。
十二、特征的哈希变换-CNNH[10]
由于各分类网络直接输出的output特征维度比较高并且都是浮点数,所以该类特征会占用比较大的存储空间,特别是对于海量图搜的问题,存储这么多的图片特征就显得更为费劲,而且读取这些特征并进行特征间距离计算的效率会非常低,所以精简分类网络的output特征就显得尤为重要,因此有学者提出了图片特征的哈希变换。
哈希学习凭借着检索速度快和存储成本低的优点,己经成为图像检索领域最受欢迎和有效的技术之一。但是现有的大部分哈希学习方法都是基于手工提取特征,手工提取特征不一定适用于哈希编码学习,所以有学者提出了深度学习的哈希方法CNNH。
首先对于给定的n张图片,定义他们的相似矩阵为,如果和相似,则的值为1,若他们不相似,则的值为-1。接下来定义一个n行q列的二进制矩阵H,矩阵的第k行表示图片的二进制特征编码,。图片I的哈希码通过学习得到,在学习中使得下列loss取得最小值:
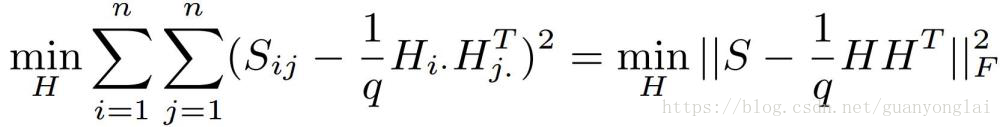
在得到图片的哈希码后通过测量特征之间的汉明距离比较图片相似度。
参考文献
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
- Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
- Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[J]. 2014:1-9.
- Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[J]. 2016.
- Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[J]. 2015:2818-2826.
- Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[J]. 2016.
- He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. 2015:770-778.
- Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[J]. 2016:2261-2269.
- Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[J]. 2017.
- Xia R, Pan Y, Lai H, et al. Supervised hashing for image retrieval via image representation learning[C]// AAAI Conference on Artificial Intelligence. 2014.

