- 1windows下使用vscode远程连接Linux服务器进行开发_vs code 远程开发 切换目录
- 2Kafka日志文件格式及刷写清理策略_kafka logs 文件夹过大
- 3CEF-概述和常用功能介绍(GeneralUsage翻译)
- 4C#从入门到精通_c#学习
- 5鸿蒙 DevEco-Studio 运行创建模拟器过程_deveco studio没有模拟器怎么创建
- 6C#中使用Socket实现简单Web服务器
- 7pycharm部署ssh连接_pycharm ssh
- 8虚拟磁盘discard在qemu中的应用_discard='unmap
- 9Unix系统 - 进程管理_unix查看进程命令
- 10『RabbitMQ』入门指南(安装,配置,应用)_laravel rabbitmq 只作为 消费端 怎么配置?
Linux 中的机器学习:Whisper——自动语音识别系统_ubuntu whisper 8gb 显存配置
赞
踩
Whisper 是一种自动语音识别 (ASR) 系统,使用从网络收集的 680000 小时多语言和多任务数据进行训练,Whisper 由深度学习和神经网络提供支持,是一种基于 PyTorch 构建的自然语言处理系统,这是免费的开源软件。
安装Whisper
我们用 Ubuntu 22.04 LTS 测试了 Whisper,为避免污染您的系统,我们建议使用 Anaconda 或 Miniconda 安装 Whisper。
使用 wget 下载并安装 Anaconda。
$ wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh
- 1
下载中的截图:

运行shell脚本:
$ bash Anaconda3-2022.10-Linux-x86_64.sh
- 1
接受 Anaconda 的许可证,然后通过运行 conda init 来初始化 Anaconda3,要使更改生效,请关闭并重新打开当前的 shell。
创建一个 conda 环境,并激活它。
$ conda create --name whisper
$ conda activate whisper
- 1
- 2
现在我们准备好使用 pip 安装 Whisper,pip 是 Python 的包管理器。
$ pip install -U openai-whisper
- 1
这是运行该命令的输出。
Successfully built openai-whisper
Installing collected packages: tokenizers, huggingface-hub, transformers, openai-whisper
Successfully installed huggingface-hub-0.12.1 openai-whisper-20230124 tokenizers-0.13.2 transformers-4.26.1
- 1
- 2
- 3
运行whisper
whisper 是从命令行运行的,项目中没有花哨的图形用户界面。
该软件带有一系列不同大小的预训练模型,可用于检查 Whisper 的缩放属性:
- tiny.en
- tiny
- base.en
- base
- small.en
- small
- medium.en
- medium
- large-v1
- large-v2
- large
我们可以使用在 MP3 文件(也支持 FLAC 和 WAV)上使用媒体模型试用该软件,第一次使用模型时,会下载该模型。
如果我们不指定带有标志的语言,–language软件会自动检测使用最多前 30 秒的语言。我们可以告诉软件语言,避免自动检测的开销,一共支持 100 多种语言。
我们想要使用媒体模型转录 audio.mp3 文件,我们会告诉软件这个文件是英语语言。
$ whisper audio.mp3 --model medium --language English
- 1
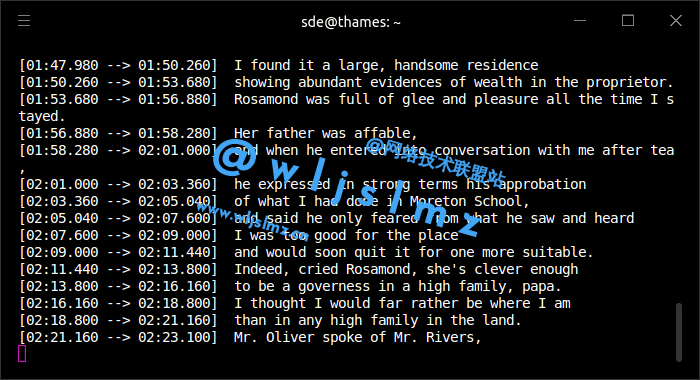
下图显示正在进行的转录。
我们验证此转录正在使用我们的 GPU。
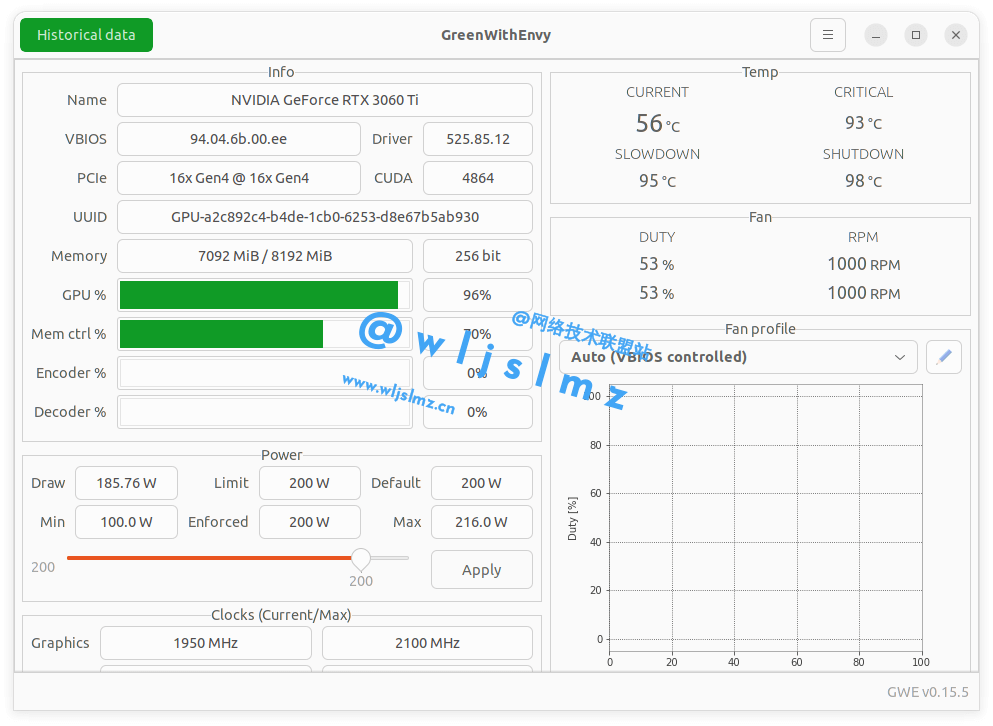
你可以看到我们的 GPU 有 8GB 的VRAM,请注意,大型模型无法在此 GPU 上运行,因为它需要超过 8GB 的VRAM。
有大量可用的选项,比如$ whisper --help
总结
Whisper 还是蛮不错的,从我们的测试来看,转录的准确性非常接近人类水平的稳健性和准确性。
Whisper 没有图形界面,也不能录制音频。它只能获取现有的音频文件和输出文本文件,Whisper 已经积累了超过 25000 个 GitHub 星,还是非常受欢迎的。
代码仓库地址:https://github.com/openai/whisper。