
- 1Unity开发(四) AssetBundle最小依赖树资源打包导出_最小依赖树算法
- 2Android_studio入门之Linearlayout+基本初级语法_androidstudio常用的语句
- 3安卓进阶必备,《Flutter Dart 语言编程入门到精通》
- 4推荐三款常用接口测试工具!
- 5朱晔的互联网架构实践心得S1E7:三十种架构设计模式(上)
- 6Git push 代码时出现 FETCH_HEAD = [up to date] release -> origin/release hint: You have divergent branches_branch v1.4.5 -> fetch_head = [up to date] v1.4.5
- 7如何关闭eslint_eslint如何关闭
- 8NLP《GPT》_nlp gpt
- 9Curl学习之使用
- 10ICRA2024
计算机二级python经典真题_python二级真题
赞
踩
计算机二级python经典考题
1、键盘输入正整数n,按要求把n输出到屏幕,格式要求:宽度为20个字符,减号字符,右填充,右对齐,带千位分隔符。如果输入正整数超过20位,则按照真实长度输出
例如:键盘输入正整数n为1234,屏幕输出---------------1,234

n = eval(input("请输入正整数:"))
print("{:->20,}".format(n))
- 1
- 2
2、a和b是两个列表变量,列表a为[3,6,9]已给定,键盘输入列表b,计算a中元素与b中对应元素乘积的累加和。
例如:键盘输入列表b为[1,2,3],累加和为1*3+2*6+3*9=42,因此,屏幕输出计算结果为42

a = [3, 6, 9]
b = eval(input("请输入一个数组:"))
s = 0
for i in range(len(a)):
s += a[i] * b[i];
print(s)
- 1
- 2
- 3
- 4
- 5
- 6
3、以123为随机数种子,随机生成10个在1(含)到999(含)之间的随机数,每个随机数后跟随——个逗号进行分隔,厅幕输出这10个随机数。

import random
random.seed(123)
for i in range(10):
print(random.randint(1,999), end=",")
- 1
- 2
- 3
- 4
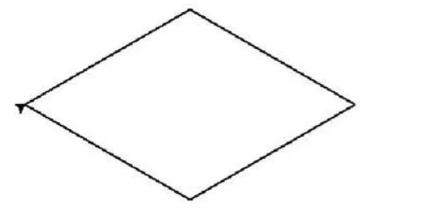
4、使用turtle的 turtle.rght()函数和turtle.fd()函数绘制个菱形,边长为200像素,4个内角度数为2个60度和2个120度,效果如图所示

import turtle
turtle.right(-30)
turtle.fd(200)
turtle.right(60)
turtle.fd(200)
turtle.right(120)
turtle.fd(200)
turtle.right(60)
turtle.fd(200)
turtle.right(120)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4、键盘输入一组人员的姓名、性别、年龄等信息,信息间采用空格分隔,每人一行,空行回车结束录入,示例格式如下:
张三 男 23
李四 女 21
王五 男 18
计算并输出这组人员的平均年龄(保留2位小数)和其中男性人数,格式如下:
平均年龄是20.67 男性人数是2

data = input()
num = 0
age = 0
maleNum = 0
while data:
num += 1
infoArr = data.split(" ");
age += int(infoArr[2])
if infoArr[1] == "男":
maleNum += 1
data = input()
age = age / num;
print("平均年龄{:.2f} 男性人数是{}".format(age, maleNum))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5、《命运》是著名科幻作家倪匡的作品。这里给出《命运》的一个网络版本文件,文件名为“命运.txt”
-
问题1(5分): 对“命运.txt"文件进行字符频次统计,输出频次最高的中文字符(不包含标点符号)及其频次,字符与频次之间采用英文冒
号”:"分隔,示例格式如下:理:224

file = open("命运.txt", "r", encoding="utf-8") info = file.read() d = {} for s in info: if s not in ",。?《》!【】“”‘’、": d[s] = d.get(s, 0 ) + 1 arr = list(d.items()) arr.sort(key=lambda item:item[1], reverse=True) file.close() print("{}:{}".format(arr[0][0],arr[0][1]))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
问题2(5分): 对“命运.txt”文件进行字符频次统计,按照频次由高到低,屏幕输出前10个频次最高的字符,不包含回车符,字符之间无间
隔,连续输出,示例格式如下:理斯卫…G后略,共10个字符)

file = open("命运.txt", "r", encoding="utf-8") info = file.read() d = {} for s in info: if s not in "\n": d[s] = d.get(s, 0) + 1 file.close() ls = list(d.items()) ls.sort(key=lambda item:item[1], reverse=True) for i in range(10): print("{}".format(ls[i][0]), end="")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
问题3(10分): 对“命运.txt”文件进行字符频次统计,将所有字符按照频次从高到低排序,字符包括中文、标点、英文等符号,但不包含
空格和回车。将排序后的字符及频次输出到考生文件夹下,文件名为"命运-频次排序.txt”。字符与频次之间采用英文冒号″:"分隔,各字符之间釆用英文逗号″,″分隔理:224,斯:120,卫:100

file1 = open("命运.txt", "r", encoding="utf-8") file2 = open("命运-频次排序.txt", "w", encoding="utf-8") info = file1.read() d = {} for s in info: if s not in "\n\t": d[s] = d.get(s, 0) + 1 ls = list(d.items()) ls.sort(key=lambda item:item[1], reverse=True) data = "" for item in ls: data += str(item[0])+":"+str(item[1])+"," data = data[0:len(data)-1:1] file2.write(data) file1.close() file2.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在叙述《命运》这个故事之前,先说说命运。 甚么?《命运》不是说命运的吗?“命运”是这个故事的题名,可以说命运,和命运有关的种种;也可以不是。究竟《命运》说的是甚么样的故事?还是那句老话:看下去,自然知道。 不论怎样,先来说说命运。 世界上,宇宙间,奇妙的事虽然多到不可胜算,但是决不会比命运更奇妙。 命运存在吗?彷佛又虚无缥缈,不可捉摸。命运不存在吗?却又彷佛世上所有的人,都受着命运的左右。 (不但人受命运的左右,所有的生物,有生命的,也都有“命运”。甚至没有生命的物质,也有它们的命运,每一种生物或物质,都有命运在播弄。) 任何人最关心的,当然是自己的命运,尤其是想解答一个问题:我将来会怎么样? 也就是说,人最关心的,是自己将来的命运。 将来会怎么样呢?在生命历程中,会发生甚么事?是不是可以通过某种方法,预先知道自己的生命历程中将来的事? 这是第一层次的问题群,这一连串的问题,答案也很难确定。 若说没有,古今中外,不知有多少方法传下来,可以推算一个人的未来命运,单是在古老的中国,方法之多,层出不穷,有看相(面相、手相、身相、骨相等等)、有排八字(根据一个人的出生时刻推算未来),还有各种各样的推算法、占卜求签,大方法中变出各种小方法,真要统计一下,子平、紫微、梅花神数……至少可以数出一百种以上。 方法是有的,这一点可以肯定。有的方法且十分复杂,不但需要相当高深的学识,而且也需要玄学上的灵感和才能,有的方法十分秘密,不是谙此术者,根本不能窥其门径,连边都沾不到。 但是问题又来了,根据这一切方法,推算出来的未来命运,准吗?算出来如此就如此? 于是,问题群进入了第二层次。 未来的事,就是还未曾发生的事。 一件事,不论多么简单,那都是表面现象。事实上,一件再简单的事,都极复杂,和千千万万的因素有关,千千万万的因素,结合起来,才产生一件简单之极的事情。 举一个例子:走进快餐店,买一只汉堡包,把这只汉堡包吃下肚子去,那是多么平常简单的一件事!每天都不知有多少人在做,很少有人从那么简单的事情中,去深一层想想这其实是多么复杂的一件事。 汉堡包用面粉制成,面粉是由甚么人制造出来?麦子是在甚么样的情形之下种出来?牛肉的来源又怎么样?洋葱自然来自农田,但如果恰有一只害虫,蛀蚀了那只洋葱,自然会被抛掉,当然你还可以吃到一只汉堡包,但也已经不是那一只了,有了微小的不同。 微小的不同,就是有变化,必须承认这一点。 也就是说,这只汉堡包,到你的口中,是上亿个因素结合起来形成,只要其中一个因素不同,整件事就不同了,虽然同与不同之间,相差可能极微,但不同就是不同! 再举一个例子,若干年前,在香港的半山区,在一个暴风雨之夜,山泥崩泻,以惊人的破坏力,把一幢十二层高的大厦,彻底摧毁,造成了巨大的灾害,有不少人,惨被埋在倒坍了的大厦和崩泻的山泥之中,丧失了生命。 不幸罹难的人,自然命运差极。但是也有很幸运地逃过了巨灾的人在。逃过了灾劫的人,看来是不应该逃过的,而不幸死亡的人,其实应该是可以逃得过的。 两个小故事,可以使关心自己未来命运的人感到兴趣,看了之后,也可以好好想一想。 第一个是遭了难的:一位年轻人,约了女朋友外出,可是临时,由于风雨实在太大,就临时取消了约会,逗留在家里。结果,大厦倾坍,遭了不幸。 他推辞约会之前,一定曾考虑过,当时外出还是不外出,决定于一念之间,而一念之间,就决定了他的一生命运。因素也不是在他一个人那方面,若是他的女朋友坚持一下,也就可以影响他的决定,那么,他未来的命运,就又是另外一回事了。 暴风雨不可测,形成一场暴风雨,不知有多少因素,自然的因素,再加上人的因素,种种因素凑合起来:就是那么巧。 第二个故事的主角,是一个幸运的少妇。这位少妇当时正有孕在身,在暴风雨之夜,忽然想起要吃某种食品(据说是一种面包),于是就驾车离家,去购买这种面包。当她冒着风雨,买了面包,再驾车回去时,整座大厦已经消失,而她虽然震愕绝伦,却也逃过了被压死的噩运。 她决定是不是要冒着风雨去买面包,一定也曾考虑过,而决定去还是不去,也只不过是一念之间的事,可就是这一念之间,决定了她一生未来的命运。 或许有一句老话可以套用:“命不该绝”。这是承认命运存在的说法,说起来相当玄:命不该绝的,自然会在一念之间,决定外出,命里该绝的,就会留下来。 但是,为甚么呢?没有答案,有,也还是一句老话:命里注定。 这种命里注定的说法,忽略了众多因素的存在,是一种太过简单的说法。像那位少妇,她忽然想起了要吃某种食物,自然是因为她怀孕,那是孕妇某种生活上的特徵之一。如果她未曾怀孕?自然一切都改变了,而就算是生理正常的男女,怀孕也是一个复杂无比的过程,她恰好怀孕了,命运就不同,如果她没有怀孕,自然又不同。 所谓前因后果,前因有千千万万,恰好是那样,才有那样的结果,前因稍有一项变动,结果就不同。 所以在理论上说,要藉不论是哪一种方法,推算未来的命运,都必须把所有的前因,全部正确无误地推算出来,才能达到唯一的正确结果。 前因既然牵涉的范围如此之广,有可能一一了解清楚吗?更何况每一个前因的形成,又有上亿的形成这个前因的因素在,牵扯开去,若用数值来表示,简直就是无穷大,实在无法计算——那便在理论上,也无法确立可以计算的可能! 好了,就算有某种方法,真可以囊括一切,推算未来;或者,像我在《天书》中记述的那样,地球上在进行的一切,只不过是一种“镜子反射”,早已在遥远的其他地方发生过的,那自然也可以藉着早已发生过的纪录,来知道将来发生的事。 好了,就算未来命运真可以推算出来,那又怎么样?接下来的,自然进入了问题的第三层次。那就是:知道了未来的命运,能改变吗?若是不能改变,知道了又怎么样? 再用上面那两个例子,那位青年,若是通过了某种方法,早已知道他会在倾坍的大厦中被压死,他自然不会再在那晚上留在家中,谁也不会明知要压死而还留在那里等死。 所以,他会离开。 所以,大厦倾坍时,他不会被压死。 结果是:他没有死在那次灾难之中。 那么,就是推算不准确了,因为推算,算到他要死在那次灾难之中。这是一个相当有趣的逻辑问题:如果算出来的结果可以改变,那么算出来的结果,就绝不准确,不但不准确,而在大多数的情形之下,还会截然相反。 而如果推算出来的结果准确无误,那就不会更改,不能变动。然而,那就是对一个已知道了自己未来命运的人最痛苦的煎熬。在《丛林之神》这个故事中,就曾对一个有预知能力的人的痛苦,作了一句传神的描写:“生活就像是在看一张翻来覆去、不知看了多少遍的旧报纸,乏味到了极点!” 既然,预知未来命运,只有两个可能:(一)不准确!(二)准确,但痛苦莫名。 那么,为甚么还是有那么多人,几乎是所有人,都那么焦急地想知道自己的将来。 将来终归会来,任何人,走完自己的生命历程,都可以清清楚楚知道有甚么事曾发生。 但是,所有人,古代的、现代的,焦急地要提早知道。 关于人的未来命运,是否可知,大体上的情形,就如上述。 我记述的故事,很少有那么长的前言。这洋洋数千字的前言,是我一次和若干大学生的谈话:受过高等现代教育的年轻人,对玄学上的事发生兴趣,想听听我的意见,所以才有了这一次谈话。当时所举的例子还要多,但现在为了急于记述《命运》这个故事,所以从略。 那次谈话结束,有一位青年问:“那么,卫斯理先生,你的结论是甚么呢?” 我的回答,可能不能使发问者感到满意,但是那是我唯一的答案。 我的答案是:“我没有结论。我的意见已经简单地表达了出来,大家也不能在我的意见之中,得出任何的结论。” 那位青年又道:“那么——“ 我打断了他的话头:“是的,那么,甚么是命运,命运是怎么一回事,我没有结论。” 谈话结束之后不多几天,就开始发生了我如今名之为《命运》,要记述下来的那个故事。 以下,才真正是《命运》的开始。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
6、随机选择—个手机品牌屏幕输出。

import random brandlist = ['华为', '苹果', '诺基亚', 'OPPO', '小米'] random.seed(0) name = brandlist[random.randint(0, len(brandlist))] print(name)- 1
- 2
- 3
- 4
- 5
7、请写代码替换橫线,键盘输入一段文本,保存在一个字符串变量s中,分别用Python内置函数及jieba库中已有函数计算字符串s
的中文字符个数及中文词语个数。注意中文字符包含中文标点符号
例如,键盘输入:
俄罗斯举办世界杯
屏幕输出:
中文字符数为8,中文词语数为3

import jieba
s = input("请输入一个字符串:")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为:{},中文词数为:{}".format(n,m))
- 1
- 2
- 3
- 4
- 5
8、某商店出售某品牌运动鞋,每双定价160,1双不打折,2双(含)到4双(含)打九折,5双(含)到9双(含)打八折,10双(含)以上打七折,键盘输入购买数量,屏幕输出总额(保留整数)。示例格式如下
输入:1
输出:总额为:160

n = eval(input("请输入数量:"))
cost=0;
if n == 1:
cost = 160
elif n >= 2 or n <= 4:
cost = int(n * 160 * 0.9)
elif n >= 5 or n <= 9:
cost = int(n * 160 * 0.8)
elif n >= 10:
const = int(n * 160 * 0.7)
print("总额为:", cost)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
9、键盘输入某班各个同学就业的行业名称,行业名称之间用空格间隔(回车结束输入)。完善 Python代码,统计各行业就业的学生数量按数量从高到低方式输出。
例如输入:交通 金融 计算机 交通 计算机 计算机
输出参考格式如下,其中冒号为英文冒号:
计算机:3
交通:2
金融:1

names = input("请输入各个同学行业名称,行业名称之间用空格间隔:")
nameArr = names.split(" ")
d = {}
for item in nameArr:
d[item] = d.get(item, 0) + 1
ls = list(d.items())
ls.sort(key= lambda item:item[1], reverse=True)
for k in ls:
print("{}:{}".format(k[0], k[1]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
10、下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为 sensor.txt,其内容示例如下
2016/5/3 10:05, vawelon001,1,1
2016/5/3 10:20, earpa001,1,1
2016/5/3 12:26, earpa001,1,6
…略
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
问题1(10分):修改代码,读入 sensor.txt文件中的数据,提取出传感器编号为 earpa00的所有数据,将结果输出保存到"arpa001.txt"文件。输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/3 17:11, arpa001,2,4
2016/5/3 18:02, arpa001,3,4
2016/5/3 1922, earp001,3,4

file = open("sensor.txt", "r", encoding="utf-8")
fo = open("arpa001.txt", "w", encoding="utf-8")
lines = file.readlines()
for line in lines:
if "arpa00" not in line:
continue
line = line.replace("\n", "")
lineArr = line.split(',')
fo.write('{},{},{},{}\n'.format(lineArr[0],lineArr[1],lineArr[2],lineArr[3]))
fo.close()
file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
问题2(10分)在PY301-2.py文件中修改代码,读入" arpa001.txt文件中的数据,统计 arpa001对应的职员在各楼层和区域出现的次数,保存到"eapa001_count.txt"文件,每条记录一-行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。参考格式如下。
1-1,5
1-4,3
含义如下:
第1行“1-1,5"中1-1表示1楼1号区域,5表示出现5次
第2行“1-4,3"中1-4表示1楼4号区域,3表示出现3次

file = open("arpa001.txt", "r", encoding="utf-8")
fo = open("eapa001_count.txt", "w", encoding="utf-8")
lines = file.readlines()
d = {}
for line in lines:
line = line.replace("\n", "")
lineArr = line.split(",")
s = lineArr[2]+"-"+lineArr[3]
d[s] = d.get(s, 0) + 1
ls = list(d.items())
ls.sort(key= lambda item:item[1], reverse=True)
for item in ls:
fo.write("{},{}\n".format(item[0], item[1]))
fo.close()
file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
11、从键盘输入4个数字,各数字采用空格分隔,对应为变量x0,y0,x1,y1。计算两点(x0,y0)和(x1,y1)之间的距离,屏幕输出这个距离,保留2位小数
例如:键盘输入: 0 1 3 5
屏幕输出: 500

ntxt = input("请输入4个数字(空格分隔):")
nls = ntxt.split(" ")
x0 = eval(nls[0])
y0 = eval(nls[1])
x1 = eval(nls[2])
y1 = eval(nls[3])
r = pow(pow(x1-x0, 2) + pow(y1-y0, 2), 0.5)
print("{:.2f}".format(r))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
12、键盘输入一段中文文本,不含标点符号和空格,命名为变量s,采用jieba库对其进行分词,输出该文本中词语的平均长度,保留1位小数
例如:键盘输入:吃葡萄不吐葡萄皮
屏幕输出:1.6

import jieba
txt = input("请输入一段文本:")
ls = jieba.lcut(txt)
print("{:.1f}".format(len(txt)/len(ls)))
- 1
- 2
- 3
- 4
13、键盘输入一个9800到9811之间的正整数n,作为 Unicode编码,把n-1、n和n+1三个 Unicode编码对应字符按照如下格式要求输出到屏幕:宽度为11个字符,加号字符+填充,居中。
例如:键盘输入:9802
屏幕输出:++++???++++

n = eval(input("请输入一个数字:"))
print("{:+^11}".format(chr(n-1)+chr(n)+chr(n+1)))
- 1
- 2
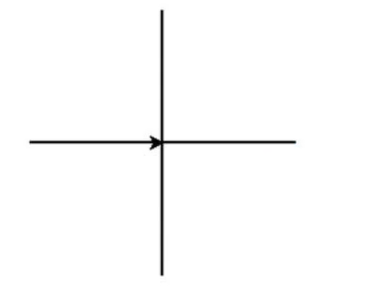
14、使用 turtle库的 turtle fd0函数和 turtle. seth0函数绘制个每方向为100像素长度的十字形,效果如图所示

import turtle
for i in range(4):
turtle.fd(100)
turtle.fd(-100)
turtle.seth((i+1)*90)
- 1
- 2
- 3
- 4
- 5
15、键盘输入一组我国高校所对应的学校类型,以空格分隔,共一行,示例格式如下
综合 理工 综合 综合 综合 师范 理工
统计各类型的数量,从数量多到少的顺序屏幕输出类型及对应数量,以英文冒号分隔,每个类型一行,输出参考格式如下
综合:4
理工:2
师范:1
 `
`
txt = input("请输入类型序列:")
txtArr = txt.split(" ")
d = {}
for item in txtArr:
d[item] = d.get(item, 0) + 1
ls = list(d.items())
ls.sort(key=lambda item:item[1], reverse=True)
for k in ls:
print("{}:{}".format(k[0], k[1]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
16、《论语》是儒家学派的经典著作之一,主要记录了孔子及其弟子言行。这里给出了—个网络版本的《论语》,文件名称为“论语.txt”,其内容采用逐句“原文”与逐句“注释”相结合的形式组织,通过【原文】标记《论语》原文内容,通过【注释】标记《论语》注释内容,具体文件格式框架请参考“论语.txt”文件。
问题1(10分):提取“论语txt”文件中的原文内容,输出保存到考生文件夹下,文件名为“论语-原文.txt”。具体要求:仅保留“论语.txt”文件中所有【原文】标签下面的内容,不保留标签,并去掉每行行首空格及行尾空格,无空行。原文小括号及内部数字是源文件中注释项的标记,请保留。

fi = open("论语.txt","r",encoding="utf-8") fo = open("论语-原文.txt", "w", encoding="utf-8") flag = False for line in fi: if "【原文】" in line: flag = True continue if "【注释】" in line: flag = False line = line.strip("\n") line = line.lstrip().rstrip() if flag: print(line) if line: fo.write(line+"\n") fo.close() fi.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
问题2(10分):对“论语-原文.txt”或“论语.txt”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论文-提纯原文.txt”文件。

fi = open("论语-原文.txt", "r", encoding="utf-8")
fo = open("论语-原文提纯.txt", "w", encoding="utf-8")
for line in fi:
for i in range(10):
line = line.replace("("+str(i)+")", "")
fo.write(line)
fo.close()
fi.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
in line:
flag = True
continue
if “【注释】” in line:
flag = False
line = line.strip("\n")
line = line.lstrip().rstrip()
if flag:
print(line)
if line:
fo.write(line+"\n")
fo.close()
fi.close()
问题2(10分):对“论语-原文.txt”或“论语.txt”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论文-提纯原文.txt”文件。 [外链图片转存中...(img-plWp4u4W-1632611145598)] ```python fi = open("论语-原文.txt", "r", encoding="utf-8") fo = open("论语-原文提纯.txt", "w", encoding="utf-8") for line in fi: for i in range(10): line = line.replace("("+str(i)+")", "") fo.write(line) fo.close() fi.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

