
热门标签
热门文章
- 126个人工智能和机器学习大厂面试常见问题_教师面试问题:人工智能
- 2FlinkCDC简介_flink cdc
- 3五款最热低代码平台推荐!_低代码平台 驰骋 jeecg
- 4Flutter中清空栈的方式(fluro和Flutter原生)_flutter 路由清空栈
- 5Python数据分析与挖掘实战(数据预处理)_使用python语言对一组数据进行数据挖掘,具体为对数据进行预处理并进行机器学习模
- 6对象存储(OSS)--MinIO--使用/教程/实例_开源oss
- 7CVPR 2019 | 旷视研究院提出Meta-SR:单一模型实现超分辨率任意缩放因子
- 8AMD CPU在虚拟机VMWare中安装黑苹果macOS 14 Sonoma记录_amd cpu能否支持mac 14
- 9大模型算法工程师的面试题来了(附答案)_模型如何判断回答的知识是训练过的已知的知识,怎么训练这种能力
- 10信息安全 - uboot, TEE, ATF, trustzone, SHE,HSM, HIS, Evita, ISO 21434, CC认证(Common Criteria)_evita 标准
当前位置: article > 正文
基于时域特征和频域特征组合的敏感特征集,再利用CNN进行轴承故障诊断(python编程)_时域频域特征指标作为训练集
作者:weixin_40725706 | 2024-03-27 20:01:34
赞
踩
时域频域特征指标作为训练集
1.文件夹介绍(使用的是CWRU数据集)

0HP-3HP四个文件夹装载不同工况下的内圈故障、外圈故障、滚动体故障和正常轴承数据。
2.模型
按照1024的长度分割样本,构建内圈故障、外圈故障、滚动体故障和正常轴承样本集
2.1.计算11种时域特征值
-
- # 计算时域特征
- def calculate_time_domain_features(signal):
- features = []
-
- # 均值
- features.append(np.mean(signal))
-
- # 标准差
- features.append(np.std(signal))
-
- # 方根幅值
- features.append(np.sqrt(np.mean(np.square(signal))))
-
- # 均方根值
- features.append(np.sqrt(np.mean(np.square(signal))))
-
- # 峰值
- features.append(np.max(signal))
-
- # 波形指标
- features.append(np.mean(np.abs(signal)) / np.sqrt(np.mean(np.square(signal))))
-
- # 峰值指标
- features.append(np.max(np.abs(signal)) / np.mean(np.abs(signal)))
-
- # 脉冲指标
- features.append(np.max(np.abs(signal)))
-
- # 裕度指标
- features.append(np.max(np.abs(signal)) / np.sqrt(np.mean(np.square(signal))))
-
- # 偏斜度
- features.append(skew(signal))
-
- # 峭度
- features.append(kurtosis(signal))
-
- return features
-

2.2.计算12种频域特征值
-
-
- # 计算频域特征
- def calculate_frequency_domain_features(signal, sample_rate):
- features = []
-
- # 快速傅里叶变换
- spectrum = fft(signal)
- spectrum = np.abs(spectrum)[:len(spectrum)//2] # 取一半频谱
-
- #频域指标1
- features.append(np.mean(spectrum))
-
- # 频域指标2
- features.append(np.var(spectrum))
-
- # 频域指标3
- features.append(np.sqrt(np.mean(np.square(spectrum))))
-
- # 频域指标4
- features.append(np.max(spectrum) / np.sqrt(np.mean(np.square(spectrum))))
-
- # 频域指标5
- features.append(kurtosis(spectrum))
-
- # 频域指标6
- features.append(skew(spectrum))
-
- # 频域指标7
- features.append(np.max(spectrum))
-
- # 频域指标8
- features.append(np.min(spectrum))
-
- # 频域指标9
- features.append(np.max(spectrum) - np.min(spectrum))
-
- # 频域指标10
- features.append(np.max(np.abs(spectrum)) / np.mean(np.abs(spectrum)))
-
- # 频域指标11
- features.append(np.max(np.abs(spectrum)) / np.sqrt(np.mean(np.square(spectrum))))
-
- # 频域指标12
- peak_index = np.argmax(spectrum)
- peak_frequency = peak_index * sample_rate / len(spectrum)
- features.append(peak_frequency)
-
- return features
2.3.构建评价指标,从时域和频域一共23个指标中选出对故障特征最敏感的前4个特征,这里用的是方差评价指标,也可以选用其它的评价指标
-
-
- # 选择前4个敏感特征
- import numpy as np
- from sklearn.model_selection import train_test_split
-
- # 将特征集转换为NumPy数组
- feature_set = np.array(feature_set)
-
- # 计算评价指标(这里以方差为例)
- scores = np.var(feature_set, axis=0)
-
- # 选出最敏感的4个特征
- selected_indices = np.argsort(scores)[-4:]
- selected_features = feature_set[:, selected_indices]
最后选出 的敏感特征集
2.4.将每个样本的这4个特征输入CNN模型进行分类(也可以输入给SVM或KNN等分类器)
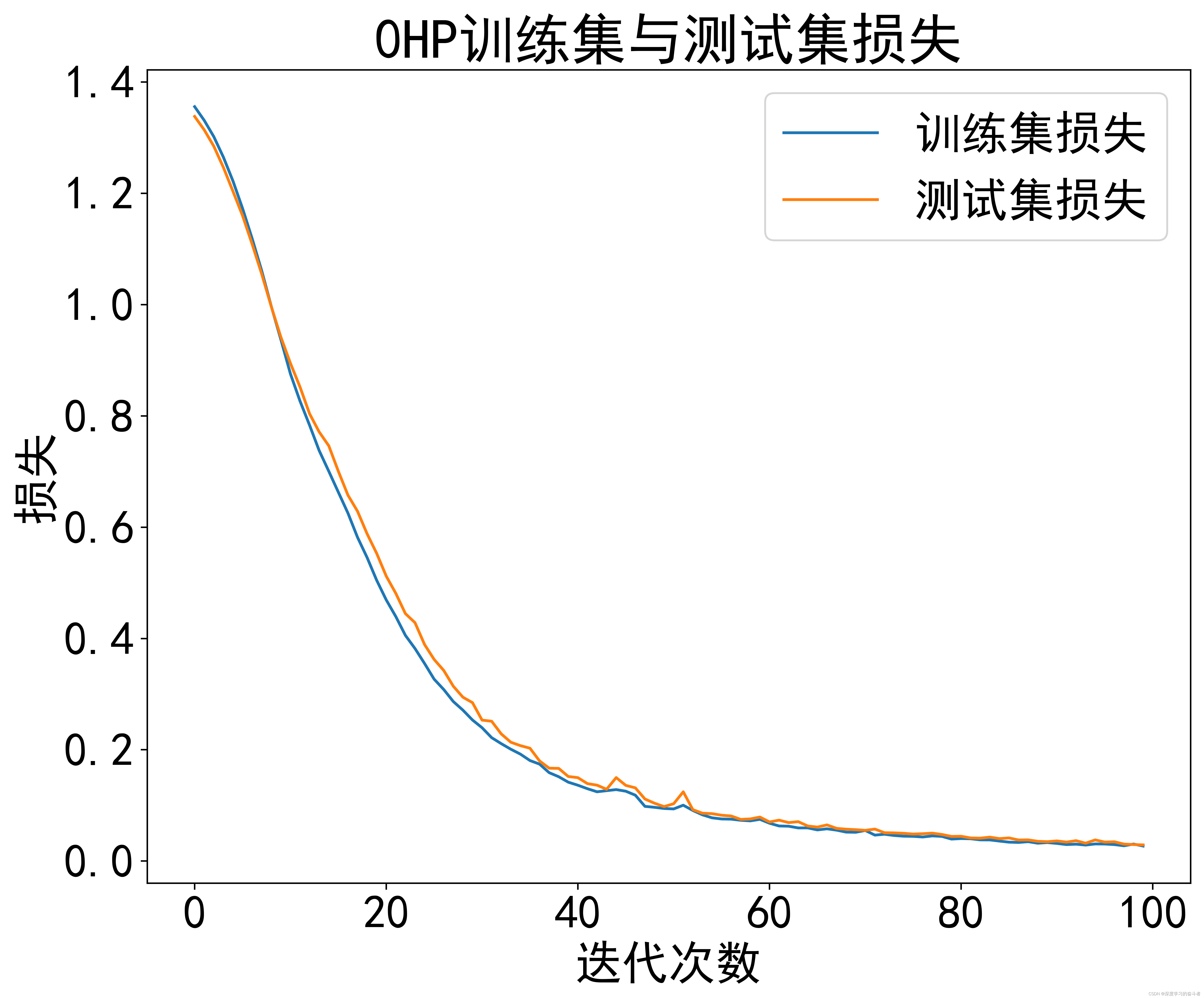
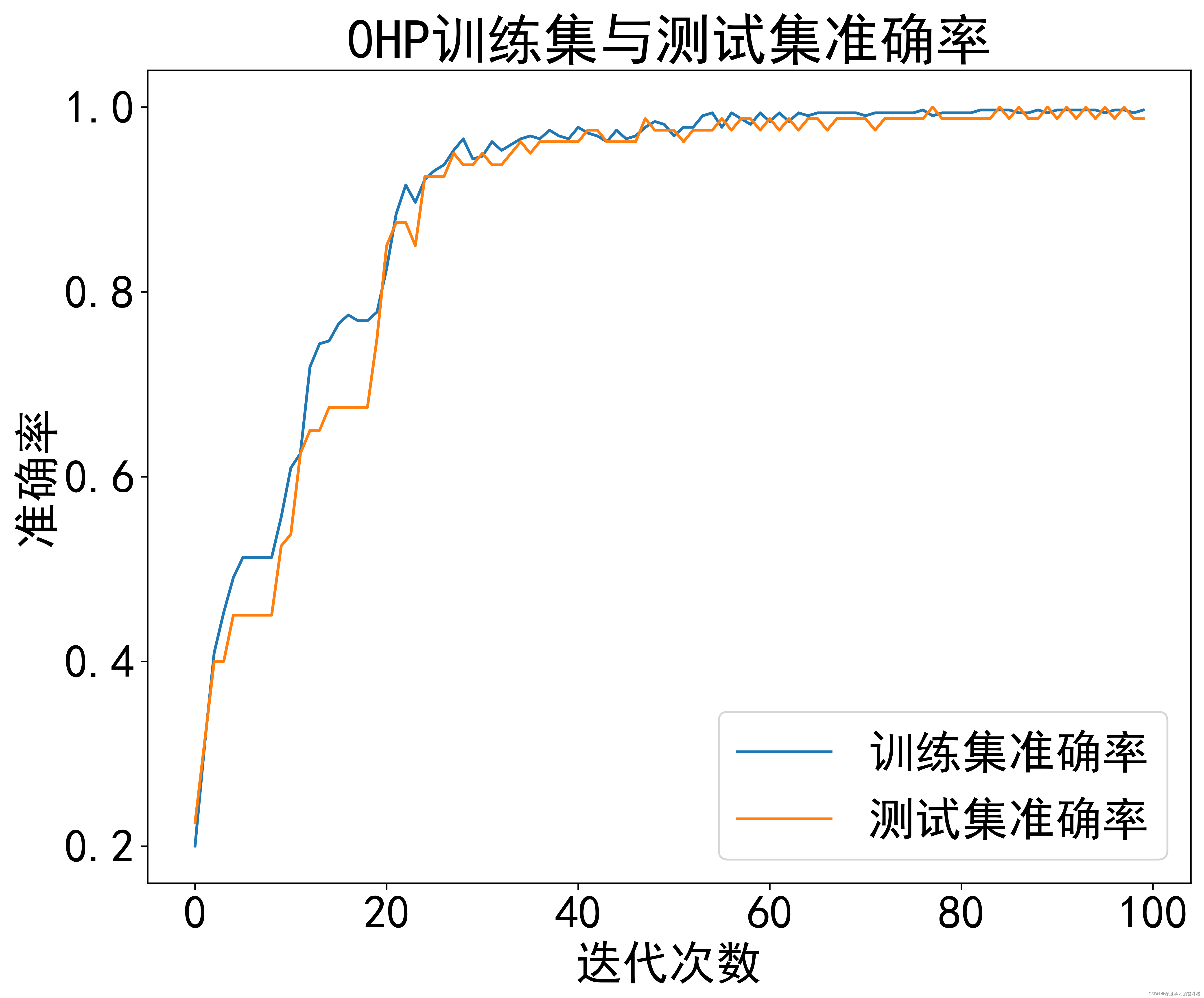
3.效果
0HP数据集
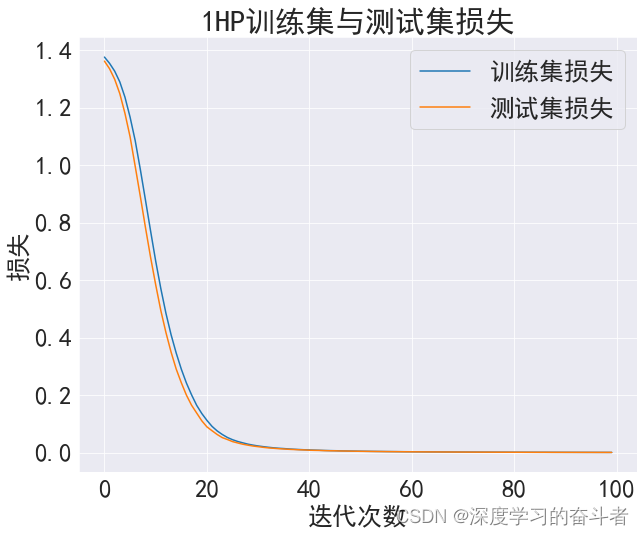
1HP数据集

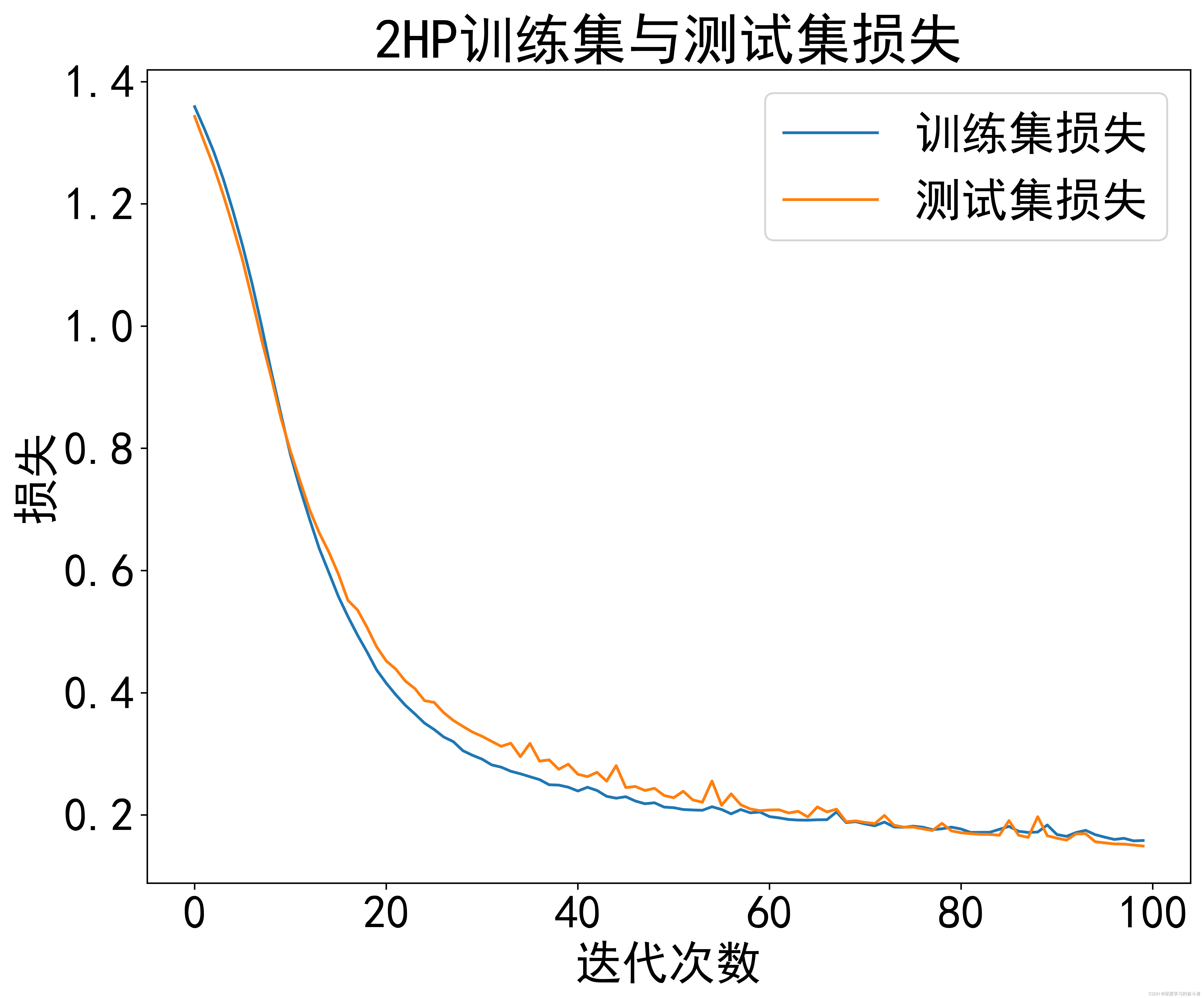
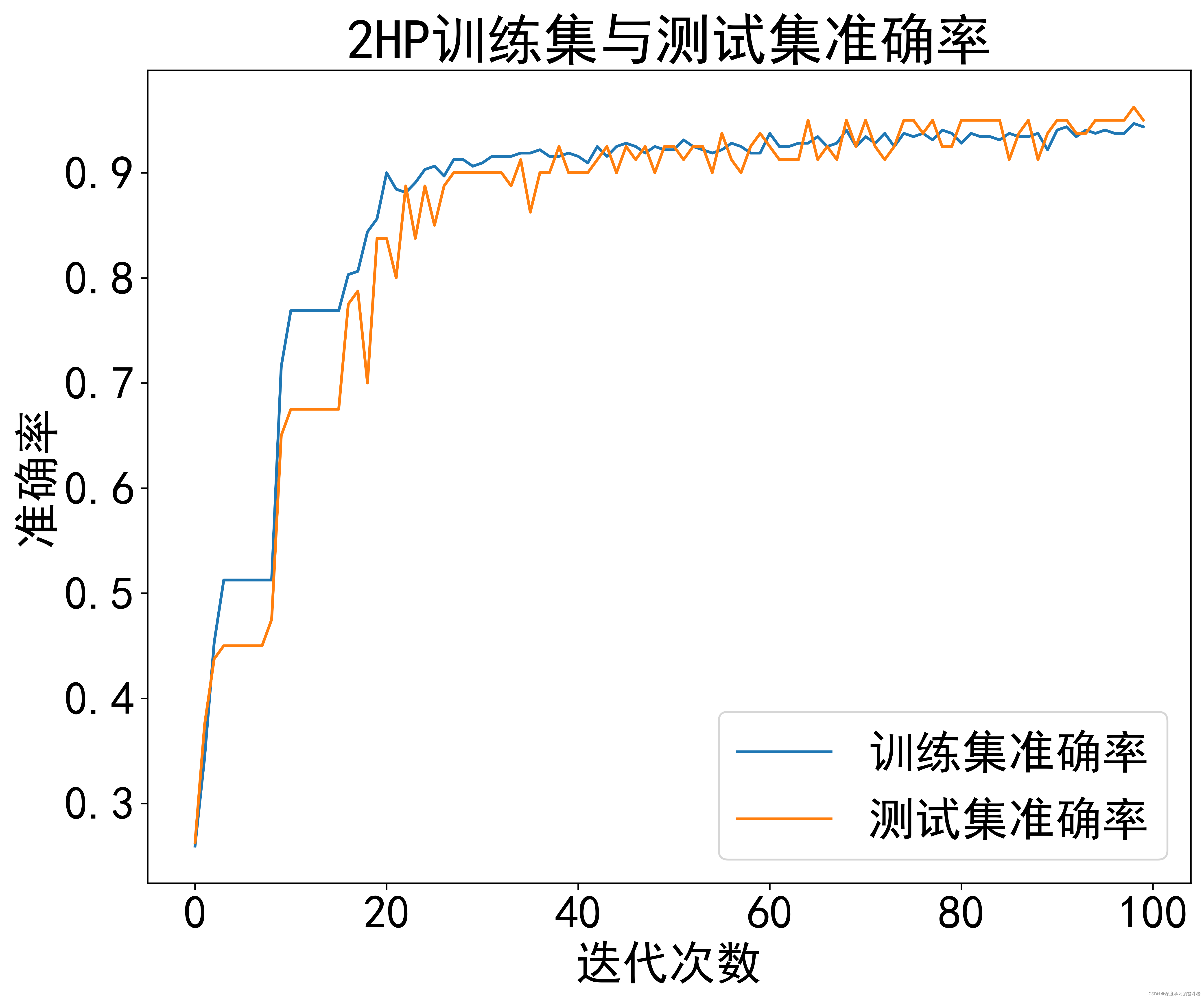
2HP数据集
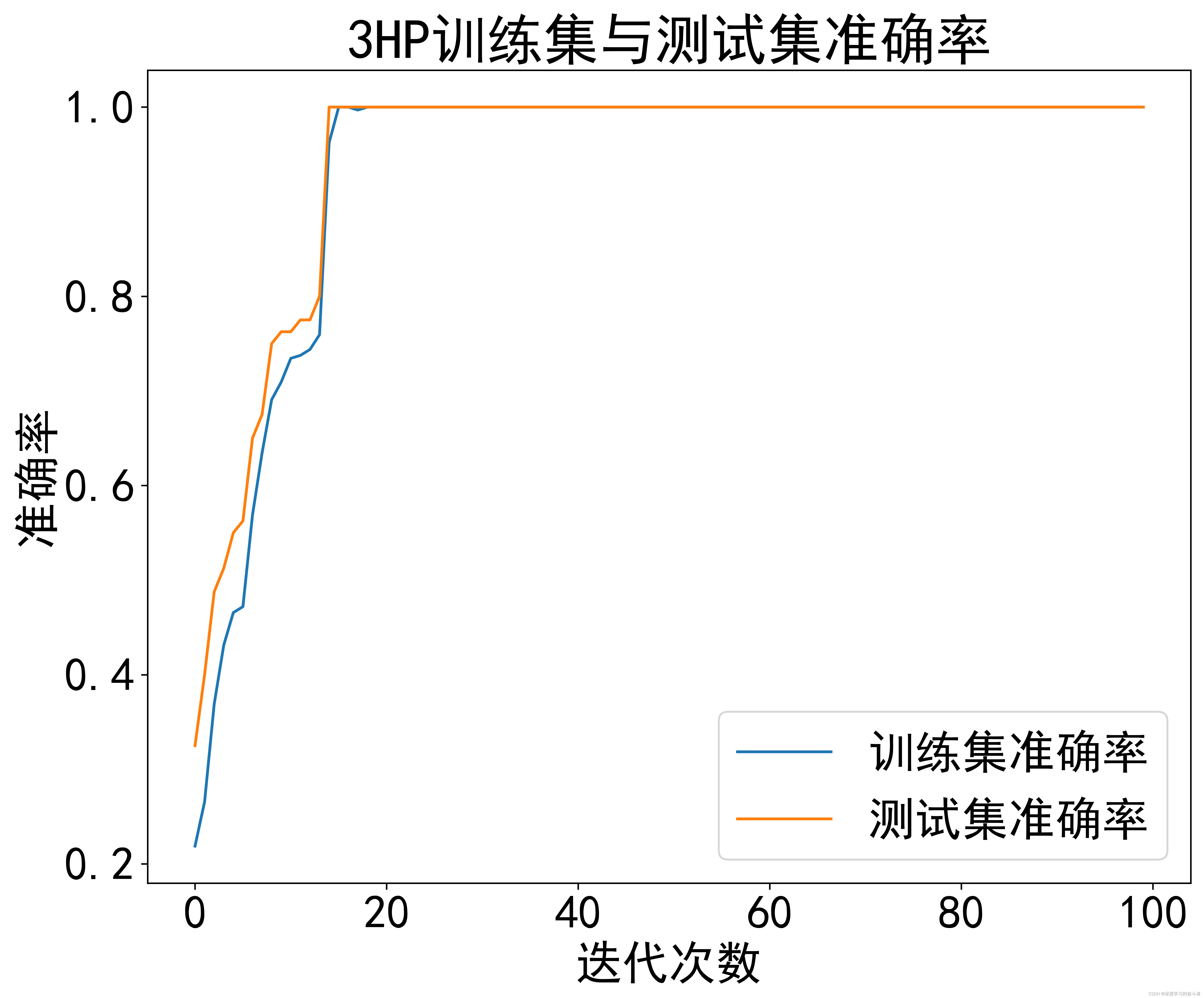
3HP数据集

总的代码和数据集放在了压缩包里
- plt.rcParams['font.size'] = 25
- # 绘制损失曲线
- plt.figure(figsize=(10, 8))
- plt.plot(train_loss, label='训练集损失')
- plt.plot(test_loss, label='测试集损失')
- plt.xlabel('迭代次数')
- plt.ylabel('损失')
- plt.title('1HP训练集与测试集损失')
- plt.legend()
- plt.savefig('0.png', dpi=600,bbox_inches = "tight")
- plt.show()
- # 绘制准确率曲线
- plt.figure(figsize=(10, 8))
- plt.plot(train_accuracy, label='训练集准确率')
- plt.plot(test_accuracy, label='测试集准确率')
- plt.xlabel('迭代次数')
- plt.ylabel('准确率')
- plt.title('1HP训练集与测试集准确率')
- plt.legend()
- plt.savefig('1.png', dpi=600,bbox_inches = "tight")
- plt.show()
- #可以关注:https://mbd.pub/o/bread/ZJuXmZtt
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/326595
推荐阅读

相关标签

