
- 1构建知识体系(1):知识体系是什么?_知识库体系结构
- 2ResNet从理论到实践(一)ResNet原理
- 3C语言-函数(详尽版)_c语言函数
- 4Edge加载weTab扩展,实现ChatGPT应用_wetab插件chatgpt怎么打开
- 5如何评估 RAG 应用的质量?最典型的方法论和评估工具都在这里了_langchain评估rag
- 6git merge使用(--no-ff)_git merge --no-commit --no-ff
- 7Android唤醒锁实现_wakelock.setreferencecounted
- 8【开题报告】基于SpringBoot的宠物电商社区系统的设计与实现_宠物用品交易平台设计开题报告
- 910.一篇文章带你理解及使用CSS(前端邪术-化妆术)
- 10【免费题库】华为OD机试 - 文件缓存系统(Java & JS & Python & C & C++)
2021年自然语言处理 (NLP) 算法学习路线!
赞
踩
在过去几年时间里,NLP领域取得了飞速的发展,这也推动了NLP在产业中的持续落地,以及行业对相关人才的需求。
但这里我们要面对的现实是,行业上90%以上的NLP工程师是“不合格的”。在过去几个月时间里,我们其实也面试过数百名已经在从事NLP的工程师,但明显发现绝大部分对技术深度和宽度的理解是比较薄弱的,大多还是只停留在调用现有工具比如BERT、XLNet等阶段。
我们一直坚信AI人才的最大壁垒是创造力,能够持续为变化的业务带来更多的价值。但创造的前提一定是对一个领域的深度理解和广度认知,以及不断对一个事物的追问比如不断问自己为什么。
对于二分类,我应该选择交叉熵还是Hinge Loss?BERT模型太大了,而且效果发现不那么好比如next sentence prediction, 能不能改一改? 为什么CRF要不HMM在不少NLP问题上效果更好? 文本生成效果不太好,如何改造Beam Search让效果更好呢?训练主题模型效率太慢了,如果改造吉布斯采样在分布式环境下运行呢? 数据样本里的标签中有一些依赖关系,能不能把这些信息也加入到目标函数里呢?
另外,有必要保持对前沿技术的敏感性,但事实上,很多人还是由于各种原因很难做到这一点。基于上述的目的,贪心学院一直坚持跑在技术的最前线,帮助大家不断地成长。贪心学院这次重磅推出了《自然语言处理高阶研修》。
01 课程大纲
课程内容上做了大幅度的更新,课程覆盖了从预训练模型、对话系统、信息抽取、知识图谱、文本生成所有必要的技术应用和学术前沿。课程采用全程直播授课模式。带你全面掌握自然语言处理技术,能够灵活应用在自己的工作中;深入理解前沿的技术,为后续的科研打下基础;通过完成一系列课题,有可能成为一个创业项目或者转换成你的科研论文。

第一章:预训练模型基础
| 预训练模型基础、语言模型回顾
| N-gram、Neural语言模型回顾
| 预训练方法的发展历程
| 预训练和transfer learning
| Pre-BERT时代的transfer learning
| word2vec,transfer learning in NER
| Post-BERT时代的transfer learning
| Pre-train fine-tune范式
第二章:ELmo与BERT
| Elmo、Transformer、BERT
| 更强的BERT:RoBERTa
| 基于Elmo和BERT的NLP下游任务
| Huggingface Transformers库介绍
| 构建基于BERT的情感分类器
第三章: GPT系列模型
| GPT、GPT2、GPT3
| 基于GPT的fine-tuning
| 基于GPT的Zero-shot learning
| 基于GPT模型的文本生成实战
| Top-k + Top-p 采样
| 基于给定Prompt生成续写文本
第四章: Transformer-XL与XLNet
| 处理长文本
| Transformer-XL
| 相对位置编码
| Permutation Language Model
| Two-stream attention
| XLNet
| 更进阶的预训练任务:MPNet
第五章:其他前沿的预训练模型
| 考虑知识的预训练模型:ERINE
| 对话预训练模型:PLATO2, DialoGPT
| SpanBERT
| MASS,UniLM
| BART,T5
| 实现基于T5的文本分类模型
第六章: 低计算量下模型微调和对比学习
| 低计算量情况下的预训练模型微调
| Adapter-based fine-tuning,
| Prompt-search,P-tuning
| 基于对比学习的预训练
| 对比学习目标:Triplet Loss,InfoNCE Loss
| 对比学习在NLP中的前沿应用:SimCSE
第七章:多模态预训练和挑战
| 多模态预训练模型
| 多模态匹配模型:CLIP,文澜
| VQ-VAE
| 多模态生成模型:DALLE,CogView
| 预训练模型面临的挑战及其前沿进展
| 模型并行带来的挑战
| 对于Transformer的改进:Reformer

第一章:对话系统综述
| 对话系统发展历程
| 对话系统的主要应用场景
| 常见的对话系统类别以及采用的技术
| 对话系统前沿的技术介绍
| 基础:语言模型
| 基础:基于神经网络的语言模型
第二章:对话系统综述
| 任务型对话系统的总体架构
| 案例:订票系统的搭建
| 自然语言理解模块简介
| 对话管理模块技术
| 对话生成模型技术
| 基于神经网络的文本分类和序列标注
第三章:自然语言处理理解模块
| 自然语言理解模块面临的挑战
| NLU模型中意图和槽位的联合识别
| 考虑长上下文的NLU
| NLU中的OOD检测
| NLU模型的可扩展性和少样本学习
| 少样本学习方法介绍
| 孪生网络、匹配网络、原型网络
第四章:对话管理和对话生成
| 对话状态追踪
| 对话策略详解
| POMDP技术
| 对话管理的最新研究进展
| 基于RL的对话管理
| 对话生成技术
| 端到端的对话系统
| 基于预训练模型的DST
第五章:闲聊对话系统
| 闲聊对话系统基础技术
| 基于检索的闲聊对话系统
| 基于生成的闲聊对话系统
| 融合检索和生成的闲聊对话系统
| Protoype rewriting, Retrieval augmented generation
| 闲聊对话系统的主要应用场景
| 闲聊对话系统技术所面临的主要挑战
| FAQ系统实战,实现一个自己的FAQ系统
| 基于RNN/Transformer/BERT的文本匹配模型
第六章:对话系统进阶
| 情感/共情对话系统
| 生成带情绪的回复
| 个性化对话生成
| 生成符合特定个性人设的回复
| 风格化对话生成
| 对话回复的多样性
| Label Smoothing, Adaptive label smoothing
| Top-K Sampling, Nuclear Sampling
| Non-autoregressive 算法在生成模型中的应用
| 基于Transformer的对话生成模型
| TransferTransfo
第七章:开源对话系统架构RASA详解
| RASA的主要架构
| 基于RASA搭建自己的对话系统
| 多模态对话、VQA
| 考虑图像模态的对话回复检索和生成
| 基于预训练模型的对话系统
| 基于GPT模型的对话模型
| Meena,PLA

第一章:知识图谱与图数据模型
| 知识图谱:搜索引擎,数据整合,AI
| 实体抽取、关系抽取、词向量
| graph embedding
| 图数据模型:RDF, Cyper
| 结构化数据的关系抽取
| 介绍关系抽取的基本方法
| 介绍结构化数据的信息过滤
第二章:知识图谱的设计
| RDF和Property graph的设计
| 创建KG:数据处理、文本和图像
| 推断用到的基本方法
| Path detection
| Centrality and community Detection
| 图结构嵌入方法
| 重要性的基本方法:node,edge
第三章:关系抽取和预测
| Hand-built patterns
| Bootstrapping methods
| Supervised methods
| Distant supervision
| Unsupervised methods
| 实体识别的基本方法
第四章:低资源信息抽取和推断
| Low-resource NER
| Low-resource structured models
| Learning multi-lingual Embeddings
| Deepath
| DIVA
| Generic Statistical Relational Entity Resolution in Knowledge Graphs
第五章:结构化预测模型
| Sequence labeling
| 结构化数据类别:Dependency,constituency
| Stack LSTM
| Stack RNNS
| Tree-structure LSTM
第六章:图挖掘的热门应用
| 基本图概念
| Link Prediction
| Recommendation system
| Anomaly detection
| Gated Graph Sequence Neural Networks

第一章:Seq2Seq模型与机器翻译
| Seq2seq 模型与机器翻译任务
| 机器翻译中未登录词UNK与subword
| 文本生成coverage
| length normalization
| 低资源语言生成
| 多任务学习
| Tearch Force Model
第二章:文本摘要生成(1)
| 摘要生成技术类别
| 生成式摘要生成技术
| 抽取式摘要生成技术
| 基于CNN的文本生成
| 基于RNN的文本生成
第三章:文本摘要生成(2)
| Pointer Network 及其应用
| CopyNet 于工业界的落地
| Length Normalization
| Coverage Normalization
| Text summarization 前沿研究
第四章:Creative Writing
| 可控性文本生成
| Story Telling 与预先训练GPT
| 诗词,歌词,藏头诗等文本生成
| 创作性文本生成技巧
第五章:多模态文本生成
| ResNet
| Inception 等预训练图片特征抽取模型
| Image Caption 及其应用
| Table2text
| 图神经网络与文本生成
第六章:对抗式文本生成与NL2sql
| 对抗生成网络 GAN模型
| 强化学习基础
| 基于 Policy Gradient 的强化学习
| SeqGAN
| NL2sql :自然语言转SQL
如果对课程感兴趣,请联系
添加课程顾问小姐姐微信
报名、课程咨询
????????????

02 部分案例和项目
学员可以选择每个模块完成我们提供的固定项目(以个人为单位),或者以小组为单位完成一个开放式项目(capstone),当然你也可以提出你自己的项目。从项目的立项、中期验收到最终答辩,在这个过程中我们的导师团队会给你建议、并辅助你完成课题, 该课题最终很有可能成为你的创业项目或科研论文!
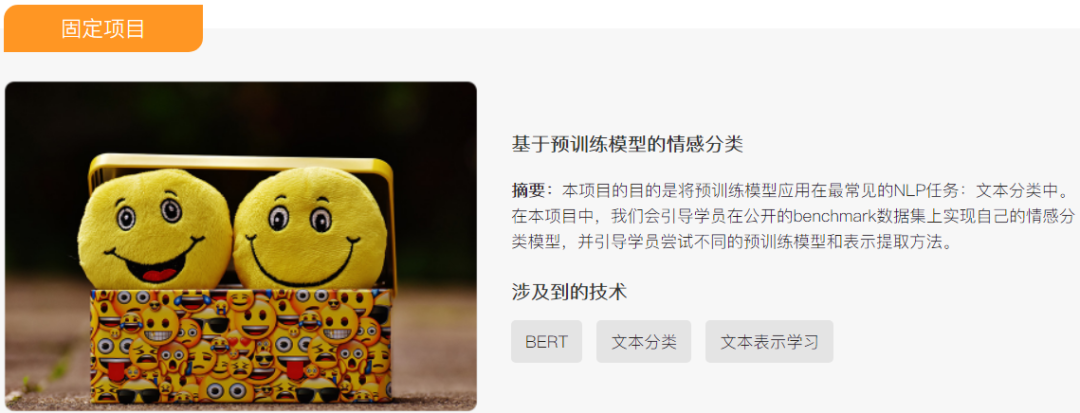
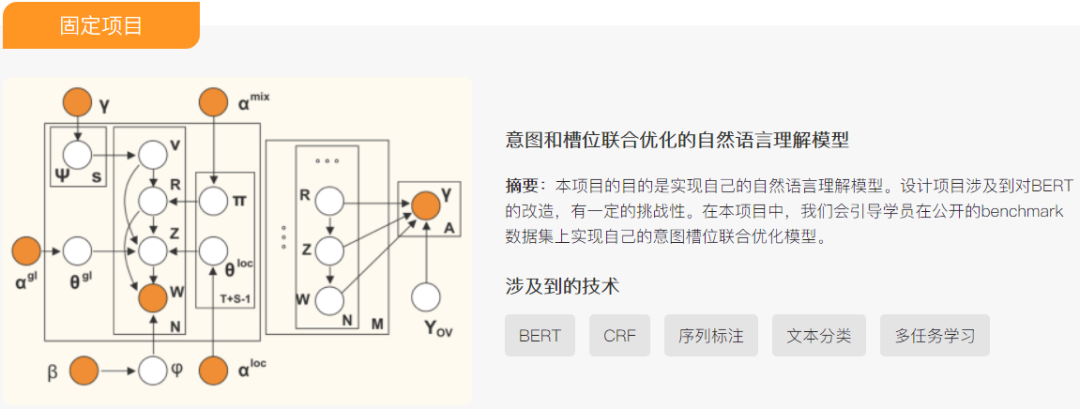

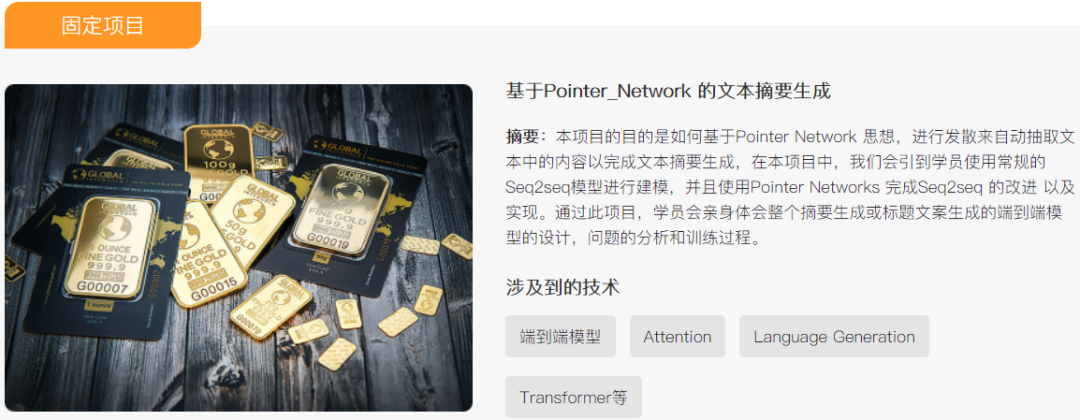
如果对课程感兴趣,请联系
添加课程顾问小姐姐微信
报名、课程咨询
????????????

03直播授课,现场推导演示
区别于劣质的PPT讲解,导师全程现场推导,让你在学习中有清晰的思路,深刻的理解算法模型背后推导的每个细节。更重要的是可以清晰地看到各种模型之间的关系!帮助你打通六脉!

▲源自:LDA模型讲解

▲源自:Convex Optimization 讲解

▲源自:Convergence Analysis 讲解
04 科学的课程安排
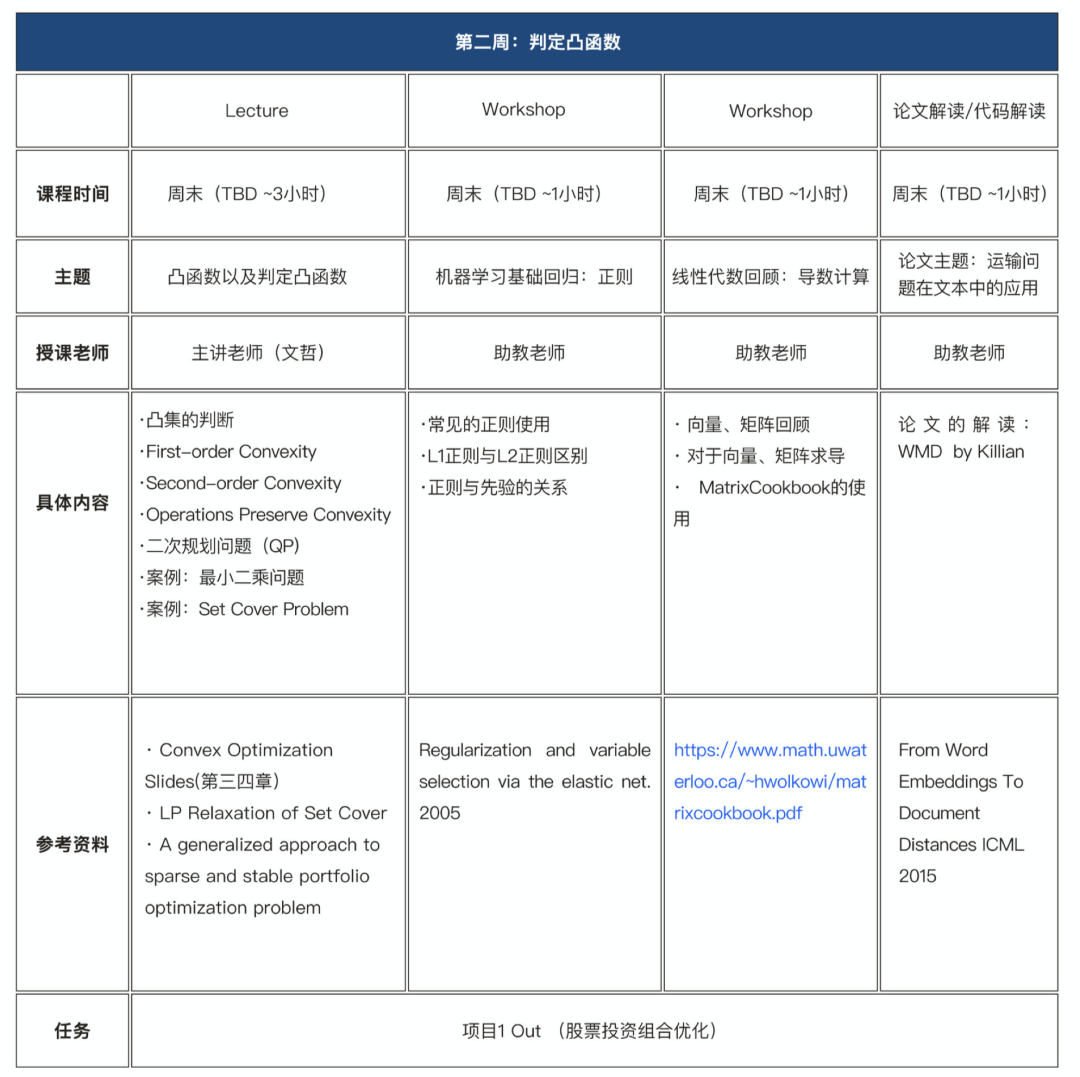
采用直播的授课方式,每周3-4次直播教学,包含核心理论课、实战课、复习巩固课以及论文讲解课。教学模式上也参考了美国顶级院校的教学体系。以下为其中一周的课程安排,供参考。
02 项目讲解&实战帮助
训练营最终的目的是帮助学员完成项目,理解项目中包含核心知识技能,训练营中会花大量的时间帮助学员理解项目以及所涉及到的实战讲解。
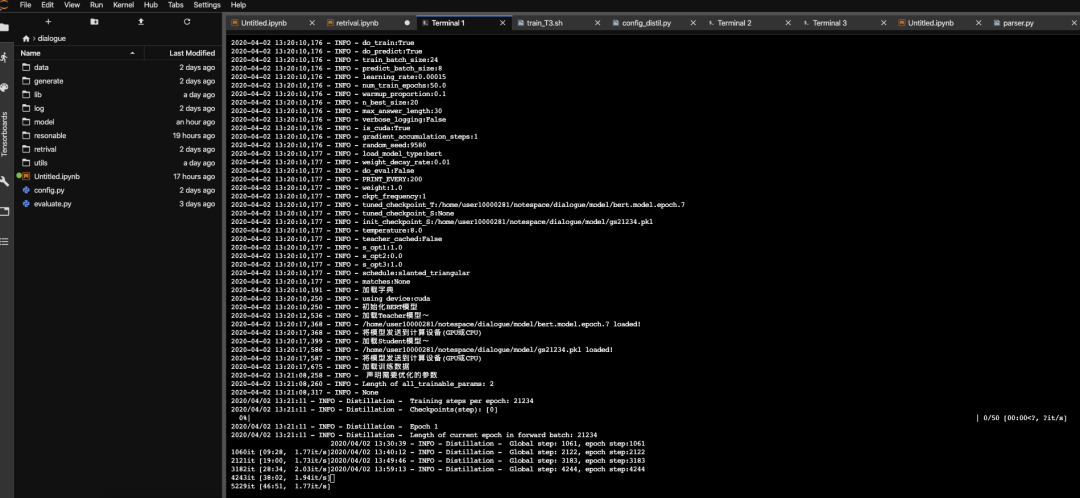
▲节选往期部分课程安排
03 专业的论文解读
作为AI工程师,阅读论文能力是必须要的。在课程里,我们每1-2周会安排一篇经典英文文章供学员阅读,之后由老师帮助解读。

▲仅供参考
04 代码解读&实战
对于核心的模型如BERT,XLNet都会精心安排代码解读和实战课,帮助学员深入理解其细节并有能力去实现。

▲BERT模型代码实战讲解
05 行业案例分享
训练营过程中会邀请合作的专家来分享行业案例以及技术解决方案,如知识图谱的搭建、保险领域的客服系统等。

▲专家分享
《Google YouTube 基于深度学习的视频推荐》
嘉宾简介:曾博士
计算机视觉,机器学习领域专家
先后在CVPR,ACMMM,TPAMI,SCI 期刊,EI 会议等发表超过30篇论文
06 日常社群答疑
为了帮助解决学员遇到的问题,专业助教会提供全天社群答疑服务。我们的助教均来来自于一线AI公司和国内外名校,扎实的理论和工业界应用也是我们选拔助教老师的重要标准,拒绝空谈理论。
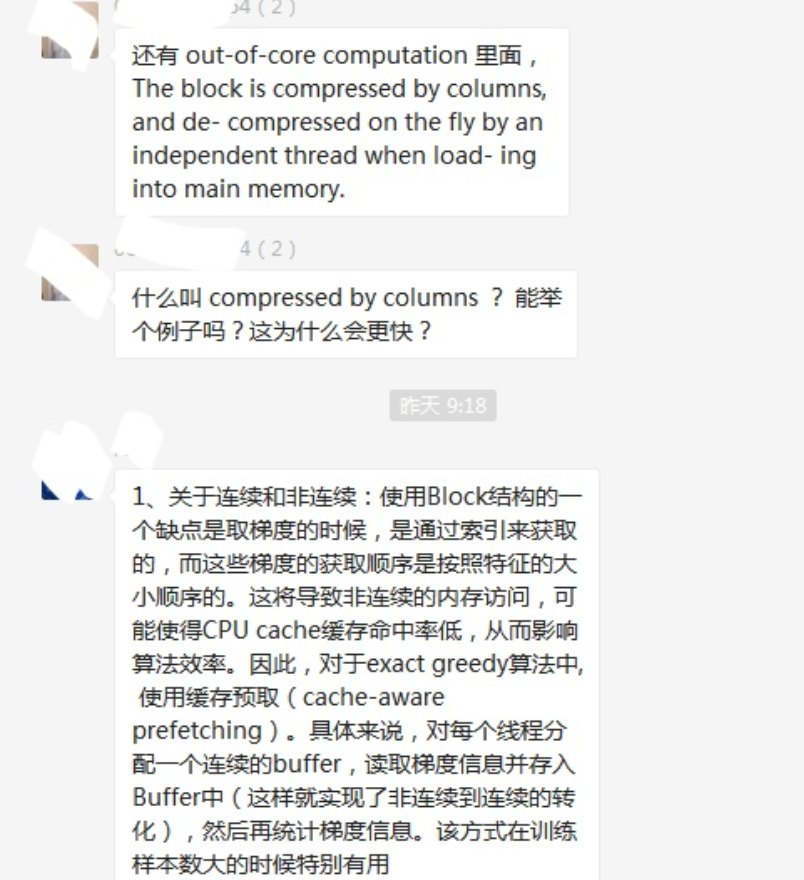

▲社群内老师专业的解答
07 日常作业&讲解
为了巩固对一些核心知识点,学员除了大项目,也需要完成日常的小作业。之后助教会给出详细的解答。

▲课程学习中的小作业

适合什么样的人来参加呐?
从事AI行业多年,但技术上感觉不够深入,遇到了瓶颈;
停留在使用模型/工具上,很难基于业务场景来提出新的模型;
对于机器学习背后的优化理论、前沿的技术不够深入;
计划从事尖端的科研、研究工作、申请AI领域研究生、博士生;
打算进入顶尖的AI公司如Google,Facebook,Amazon, 阿里等;
读ICML,IJCAI等会议文章比较吃力,似懂非懂,无法把每个细节理解透。
05 报名须知
1、本课程为收费教学。
2、本期招收学员名额有限。
3、品质保障!学习不满意,可在开课后7天内,无条件全额退款。
4、学习本课程需要具备一定的机器学习基础和Python编程基础。
●●●
如果对课程感兴趣,请联系
添加课程顾问小姐姐微信
报名、课程咨询
????????????

- article2<em>0</em>21-<em>0</em>8-<em>0</em>2_本题要求<e<em>m</em>>编写程序</e<em>m</em>><e<em>m</em>>,</e<em>m</em>>现在<e<em>m</em>>,</e<em>m</em>>给定两个整数<e<em>m</em>>n</e<em>m</em>>和<em>m</em><e<em>m</em>>,</e<em>m</em>><em>0</em><<e<em>m</em>>n</e<em>m</em>><=<em>m</em><=2<em>0</em><em>0</em><e<em>m</em>>,</e<em>m</em>>计算第<e<em>m</em>>n</e<em>m</em>>个...

