
热门标签
热门文章
- 1java开发工具和开发平台区别_重新认识一下当红应用开发工具——低代码开发平台...
- 2【力扣hot100】25 K个一组反转链表(c++)解析
- 3GitLab 详细安装及使用教程
- 4基于遗传算法实现无人机三维路径规划_三维路径规划算法如何生成初始种群
- 5【linux基础(七)】Linux中的开发工具(下)--make/makefile和git_make linux
- 6EdgeOne 边缘函数 - 如何实现“防盗”与访问控制
- 7旅游卡系统搭建小程序
- 8docker inspect --format 详解
- 9电力线路故障检测:机器学习应用于电力系统维护和故障预测_机器学习与水电机组故障检修的结合
- 10文件操作(c++)_c++写文件 ios
当前位置: article > 正文
注意力机制Attention、CA注意力机制_ca attention
作者:weixin_40725706 | 2024-04-01 08:30:52
赞
踩
ca attention
一、注意力机制
产生背景: 大数据时代,有很多数据提供给我们。对于人来说,可以利用重要的数据,过滤掉不重要的数据。那对于模型来说(CNN、LSTM),很难决定什么重要、什么不重要,因此,注意力机制产生了。
注意力机制——把焦点聚焦在比较重要的事物上。
原理:
看查询对象Q和被查询对象K的相似度。
一般使用点乘的方式。点乘其实就是求内积。
Q,K = k1,k2,k3 … …
通过点乘,计算Q和K里的每一个事物的相似度,拿到Q和k1的相似值s1,Q和k2的相似值s2 。。。
做一层softmax(s1,s2,...,sn) 就可以得到概率a1,a2,…,an
(进而就可以找出哪个对Q更重要)
那么a就代表数据的权重,v是数据本身,a*v就是处理之后的数据。
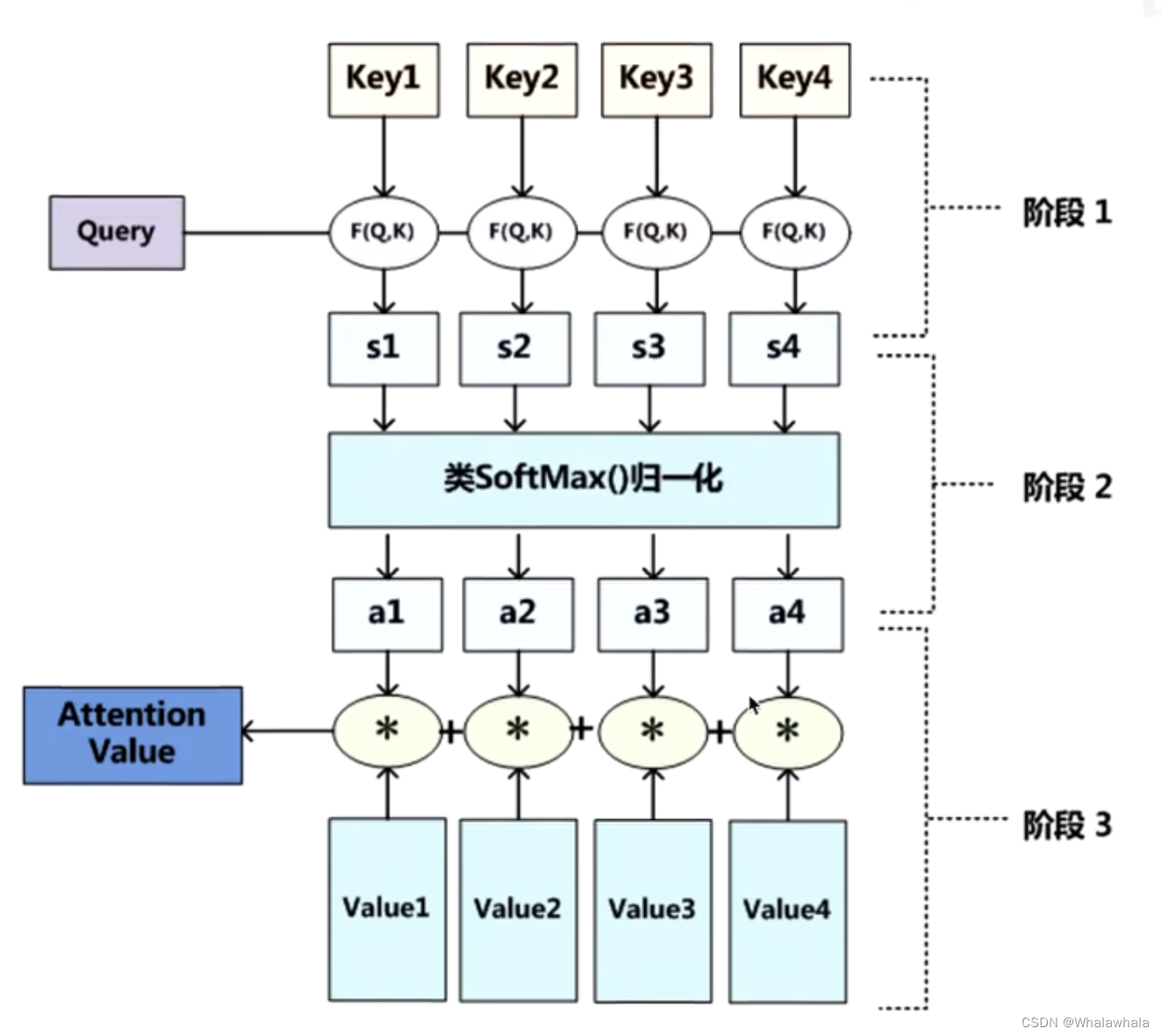 注意力机制教程
注意力机制教程
二、CA注意力机制Coord Attention
产生背景: 现有的注意力机制其通道的处理一般是采用全局最大池化/平均池化,这样会损失掉物体的空间信息。
优势: CA注意力机制可以把位置信息嵌入到通道注意力中。
注:图中第三行r是一个缩减系数,可以减少整个注意力机制的参数量。
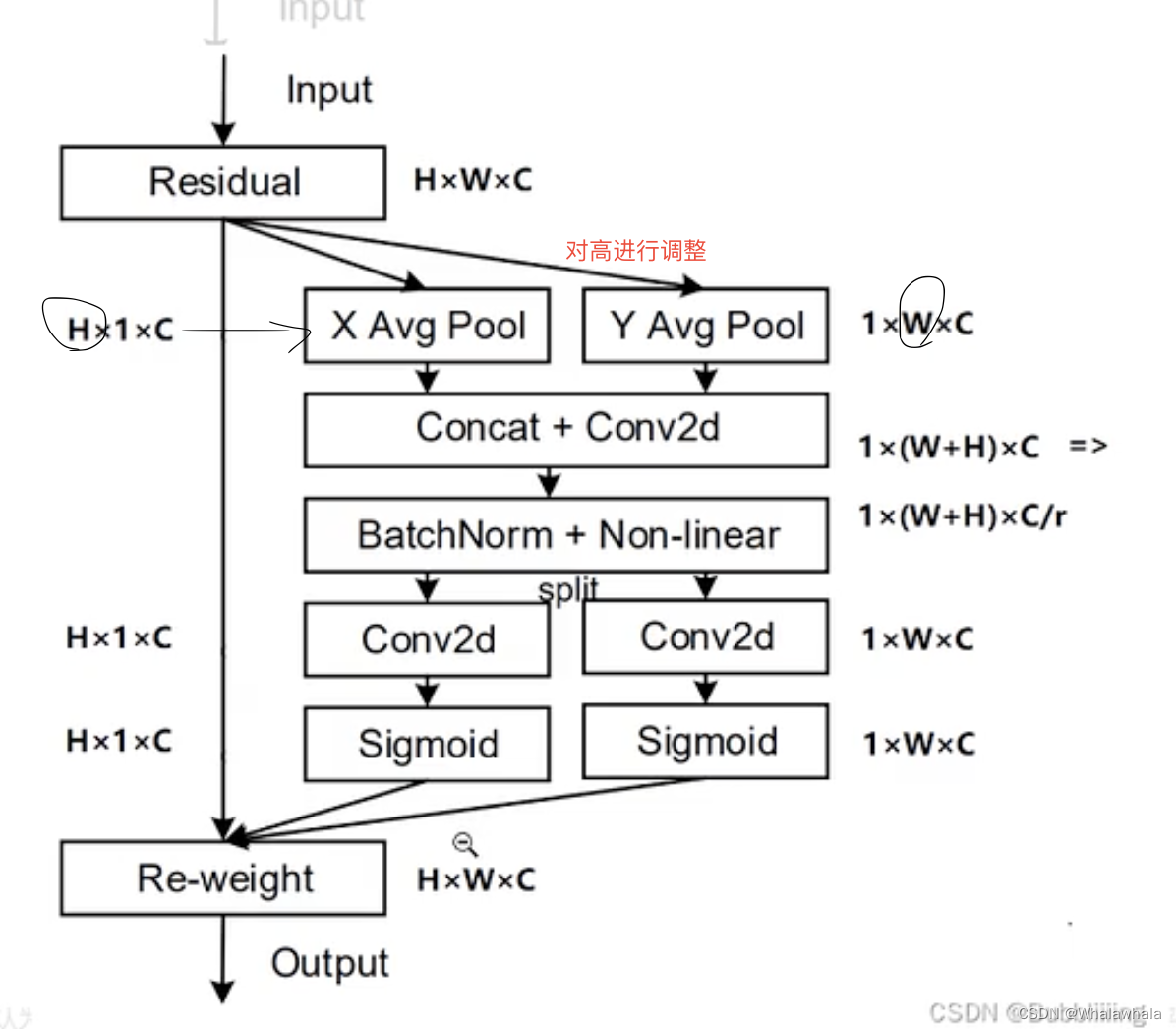 P2 在pytorch中如何实现
P2 在pytorch中如何实现
attention.py中的forward部分如下
def forward(self,x): # x的参数有 batch_size, c, h, w _, _, h, w = x.size() # batch_size, c, h, w => batch_size, c, h, 1 => batch_size, c, 1, h x_h = torch.mean(x, dim = 3, keepdim = True).permute(0,1,3,2) #提取高方向上的信息。 # mean压缩,压缩第三个维度的值,也就是给w的值变成1。permute调换维度顺序。 x_w = torch.mean(x, dim = 2, keepdim = True) # batch_size, c, 1, w cat batch_size, c, 1, h => batch_size , c, 1, w+h # batch_size , c, 1, w+h => batch_size, c/r, 1, w+h x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3)))) # batch_size, c/r, 1, w+h => batch_size, c/r, 1, h 和 batch_size, c/r, 1, w x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu([h,w],3) # batch_size, c/r, 1, h =>batch_size, c/r, h, 1 => batch_size, c, h, 1 s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0,1,3,2))) s_w = self.sigmoid_h(self.F_h(x_cat_conv_split_w) #s_h 在宽方向上拓展回来,s_w同理 out = x*s_h.expand_as(x)*s_w.expand_as(x) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
P3 如何在网络中应用也还没学,挖坑
CA注意力机制教程
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/347928
推荐阅读
相关标签

