
- 1chatGPT看图写小作文
- 2Android--sharepreference总结_android sharepreference优缺点 site:blog.csdn.net
- 3TCP和UDP_协议any和tcp udp
- 4arcgis批量操作 动态生成表格并导出地图_arcgis批量出图动态表格
- 5「玩转Palworld/幻兽帕鲁」:一文搞懂Palworld/幻兽帕鲁服务器搭建
- 6HarmonyOS元服务端云一体化开发快速入门(下)_端云一体化已经集成以下哪些服务sdk
- 7阿里云服务器部署vscode-server,实现在iPad上打代码_vscode ipad 阿里云
- 83D点云语义分割篇——PointNet++_基于pointnet++的点云分割
- 9android 读取pdf,如何在我的Android应用程序中读取pdf?
- 10selenium高级应用
逆天语言模型GPT-2最新开源:345M预训练模型和1.5B参数都来了
赞
踩
铜灵 发自 凹非寺
量子位 出品 | 公众号 QbitAI

逆天的语言模型GPT-2又有最新开源进展了!
GPT-2,这个造假新闻编故事以假乱真,能完成阅读理解、常识推理、文字预测、文章总结等多种任务的AI模型,从诞生开始就引起大量关注。
但因一开始只放出了117M的小型预训练模型,OpenAI还被网友调侃为“ClosedAI”。OpenAI表示,不是不开源,而是时候未到。
刚刚,OpenAI宣布将其345M的预训练模型开源,外加其Transformer的1.5B参数。
这一次,你也可以将最强语言模型,用到自己的项目中了。
称霸各大语言建模任务
语言模型GPT-2在语言建模任务中,简直是逆天般的存在。
作为一个没有经过任何领域数据专门训练的模型,它的表现比那些专为特定领域打造的模型还要好,横扫各大语言建模任务。
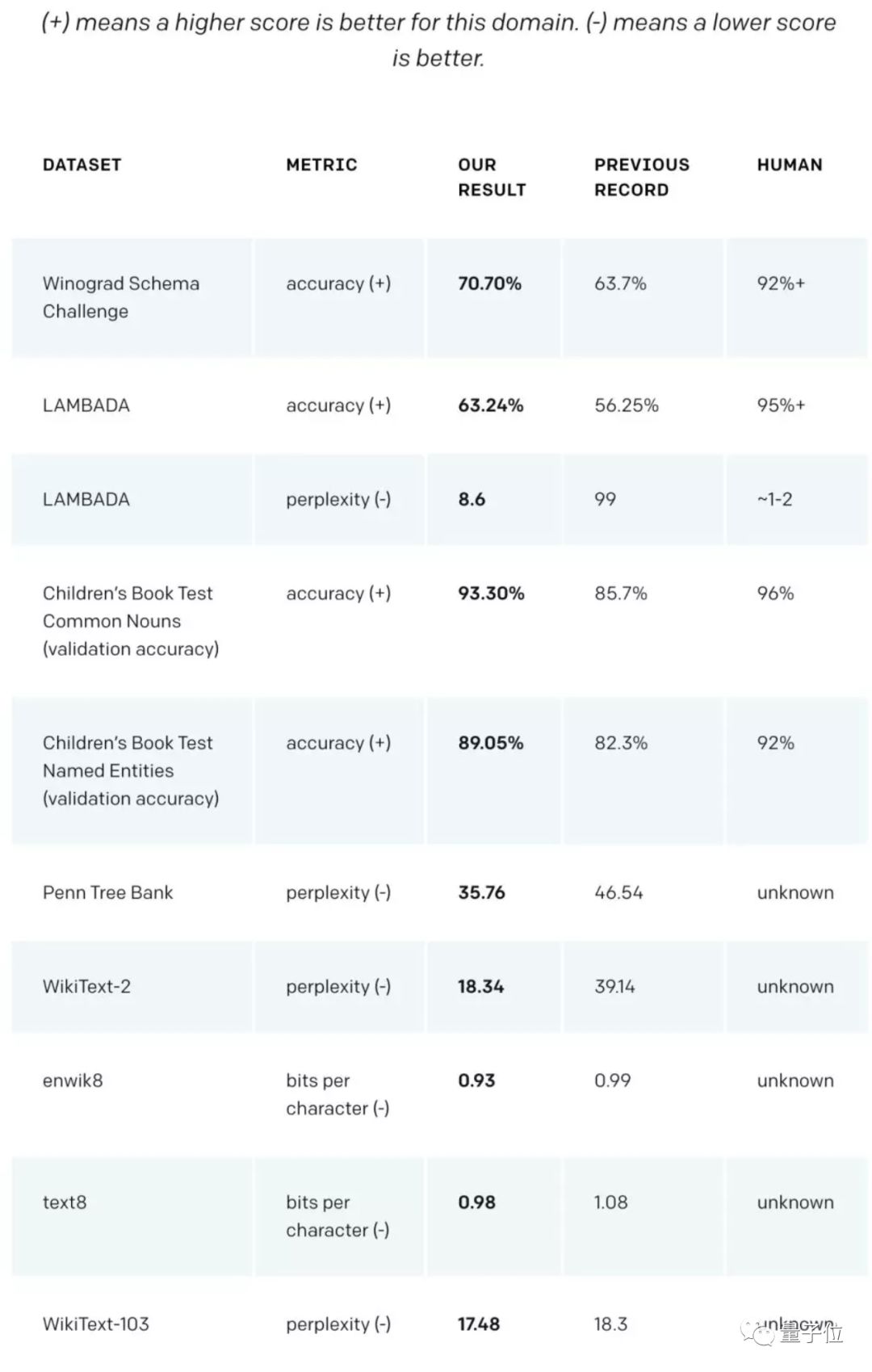
△ GPT-2在不同语言建模任务上的测试结果(从左到右:数据集名称、指标类型、GPT-2测试结果、此前最好结果、人类水平)
一经问世就获得了Hinton等大牛的强推和关注。
简单来说,GPT-2就是基于Transformer架构的大规模模型。
GPT-2是GPT算法“进化版”,比GPT参数扩大10倍,达到了15亿个,数据量扩大10倍,使用了包含800万个网页的数据集,共有40GB。
这个庞大的算法使用语言建模作为训练信号,以无监督的方式在大型数据集上训练一个Transformer,然后在更小的监督数据集上微调这个模型,以帮助它解决特定任务。
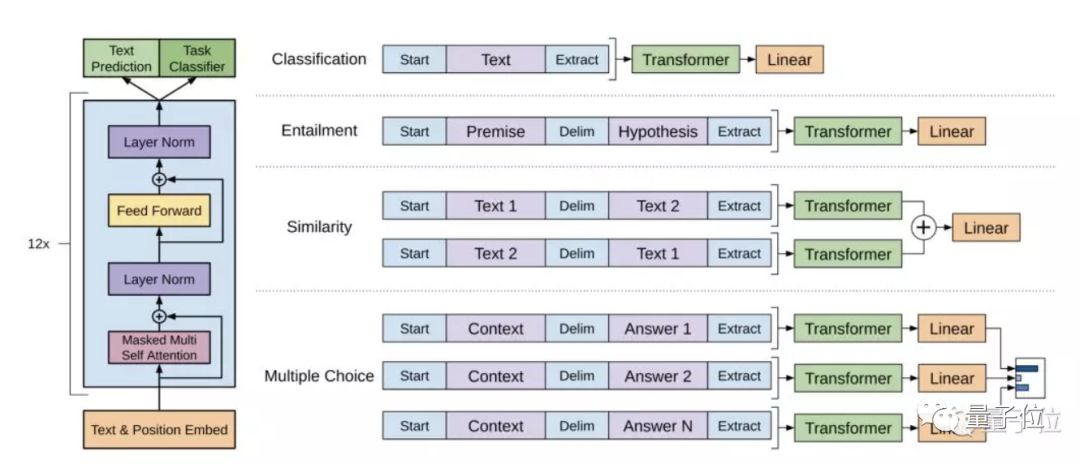
上图左部分,是研究中使用的Transformer架构以及训练目标。右边部分,是针对特定任务进行微调。将所有结构化输入转换为token序列,由预训练模型处理,然后经过线性+softmax层处理。
就GPT-2而言,它的训练目标很简单:根据所有给定文本中前面的单词,预测下一个单词。
几天前,在此架构基础上改进得到的模型MuseNet,也能预测一段音乐中下一个音符是什么了,还用贝多芬的曲风续写阿黛尔的Someone Like You,让莫扎特续写披头士。
不来了解一下?
让莫扎特“续写”披头士的音乐,OpenAI的新AI作曲能力强丨Demo可玩
传送门
最后,附上GitHub代码地址:
https://github.com/openai/gpt-2
GPT-2数据集地址:
https://github.com/openai/gpt-2-output-dataset
OpenAI介绍主页:
https://openai.com/blog/better-language-models/#update
— 完 —
小程序|get更多AI资讯与资源
加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !

