
热门标签
热门文章
- 1Python爬虫天津景点数据可视化和景点推荐系统 开题报告
- 2腾讯云服务器Centos,Docker中安装RabbitMQ_腾讯云搭建rabbitmq
- 3图片情感识别_图片的情感分类模型
- 4动态网页数据获取实战_wininet动态网站数据
- 5【Linux】Linux第一个程序-进度条_linux shell 进度条
- 6Ubuntu20.04 配置安装运行 Dave (水下SLAM 仿真环境)_project dave
- 7进阶玩法丨如何用ChatGPT,1小时写一本10万字小说!(实操教程)_gpt如何处理长10万字
- 8浅谈自然语言处理(NLP)学习路线(二):N-Gram模型,一文带你理解N-Gram语言模型
- 9too many connections 解决方法_c#连接 1040 too many connections
- 10Docker容器化实战第三课 dockerfile介绍、容器安全与监控讲解_run ln -sf
当前位置: article > 正文
PEFT(参数高效微调)_参数高效微调(peft)
作者:weixin_40725706 | 2024-04-05 10:21:29
赞
踩
参数高效微调(peft)
- PEFT现在的方法总览
-
- Seletive
- Adapter
-
- LoRA: Low-Rank Adaptation of Large Language Models(低秩微调大模型) (ICLR 2022)
-
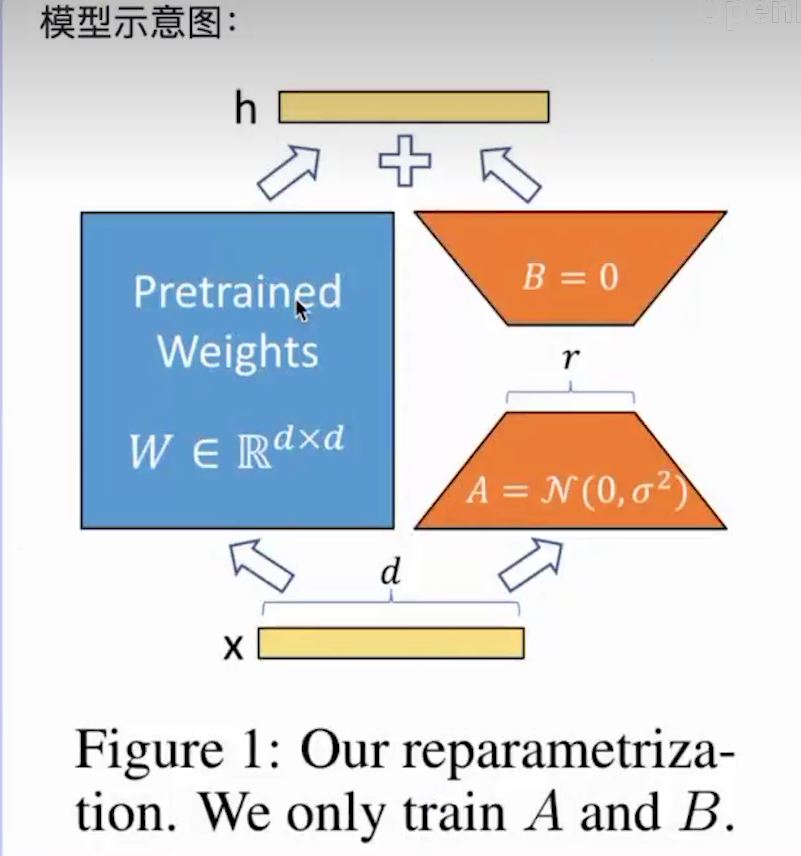
-

-
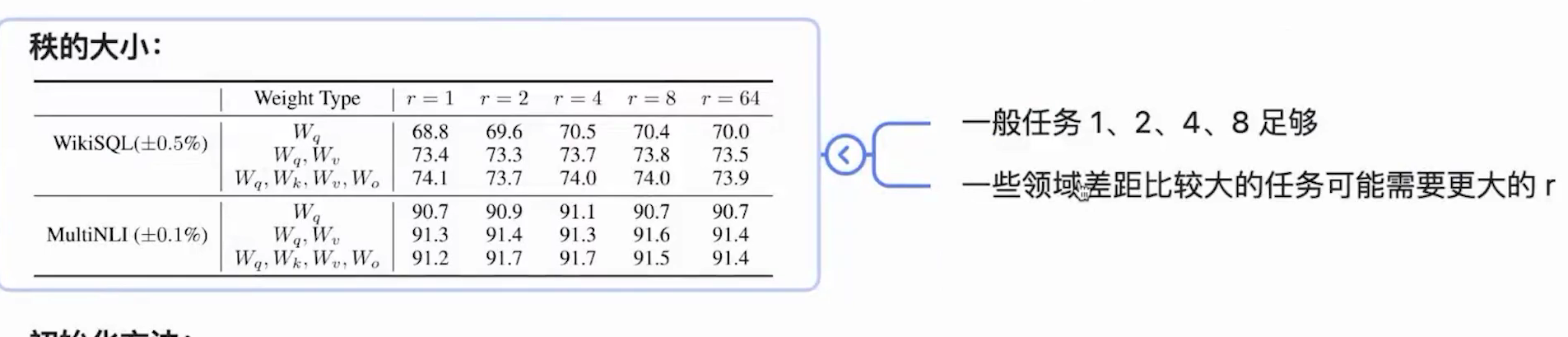
- 差距大的任务,增大rank可能带来性能提升
-
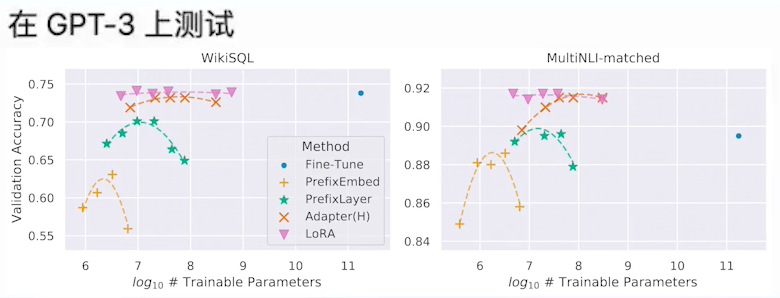
- 优点
- +稳定
- +可以同时用LoRA+adaptor etc
-
- prompt tuning
- 1.介绍
- 背景

- 何为prompt tuning
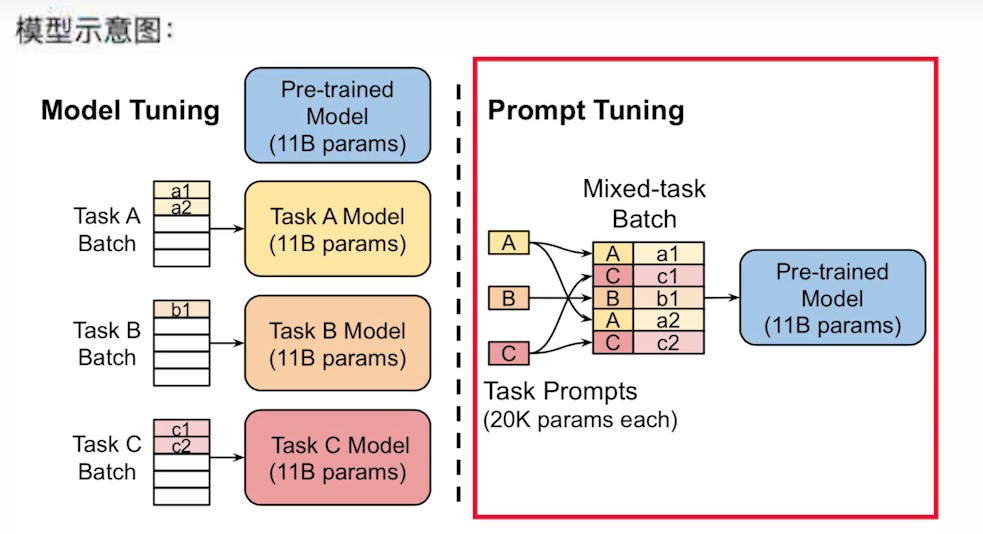
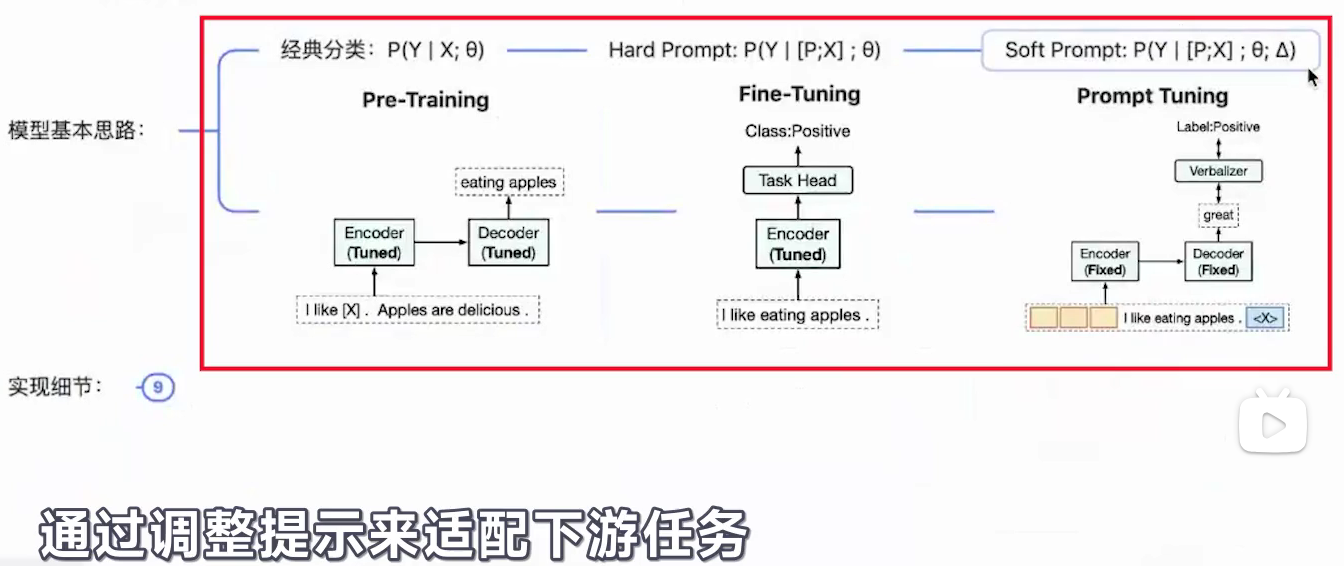
- 背景
- 2. 编写prompt(prompt design) 2个原则
- 2.1 编写明确提示
- 2.1.1长的clear的指令>短的指令
- 2.1.2分隔符


- 2.1.3结构化输出(JSON和HTML)
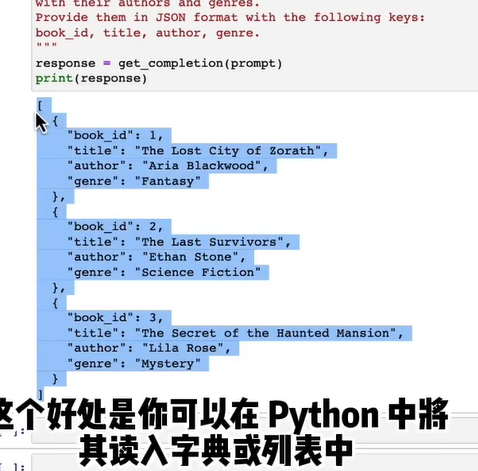
- 2.2给LLM足够时间思考
- 2.2.1指定完成任务的步骤(Chain-of thought)
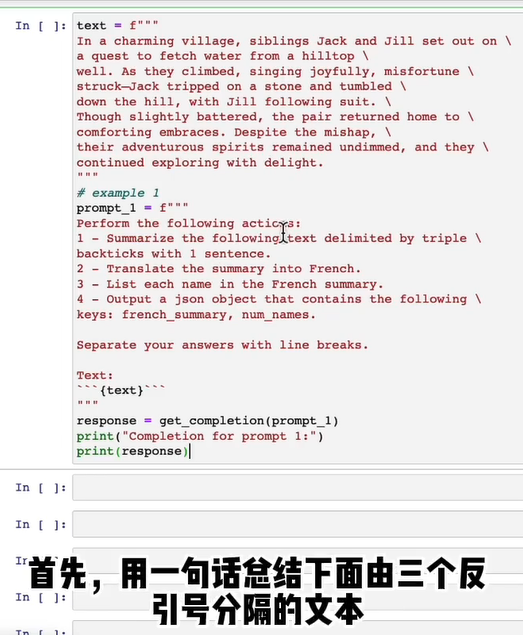

- 2.2.2 在让模型做出决策前先思考 自己的解决方案


- 2.2.3给定指定的示例,few-shot

- 2.3.1幻觉 (由于并没有记住每一个话,所以会有合理但不正确真实的回答)
比如模型会创造一个相当逼真的虚构的产品名称描述- 追溯文档可以减少幻觉
- 2.3.1幻觉 (由于并没有记住每一个话,所以会有合理但不正确真实的回答)
- 2.2.4 角色扮演

- 2.2.1指定完成任务的步骤(Chain-of thought)
- 弊端
- 多数偏差和最近偏差
- 幻象
- 2.1 编写明确提示
- 3.学习prompt(prompt tuning)
- 只调propmt的文本 (Tuning-free prompting)
-
- 把prompt embed之后,训练prompt的词向量 (现在prompt tuning基本上是这种 )
-
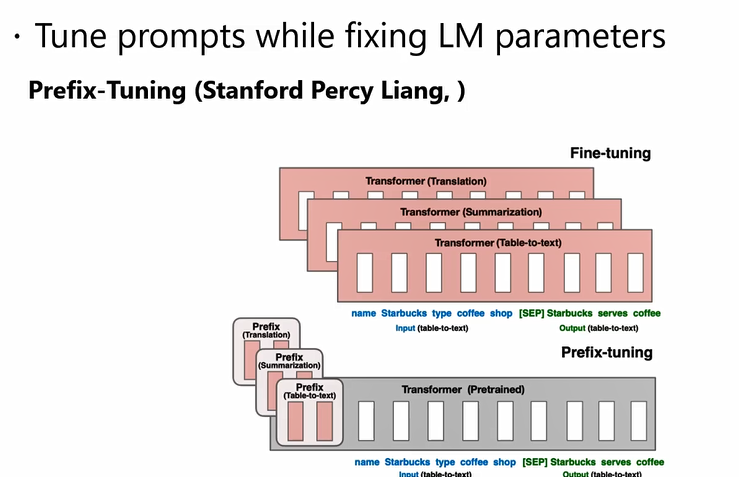
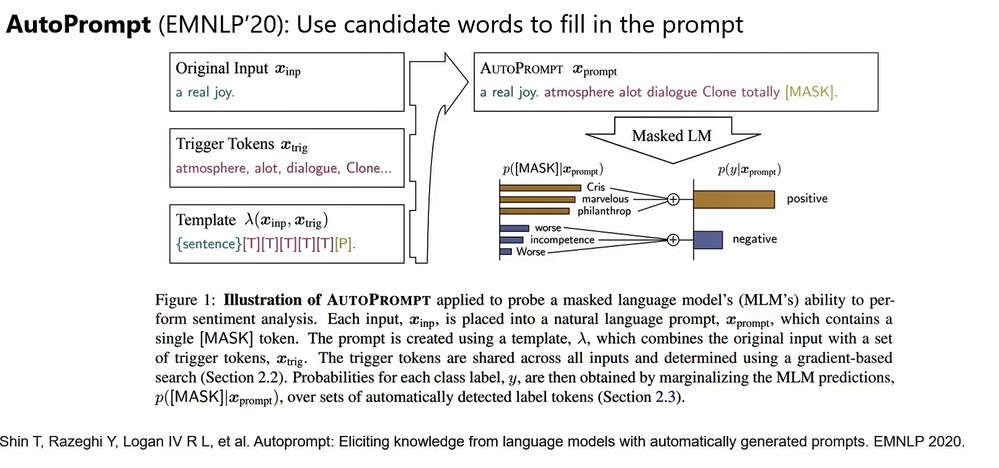
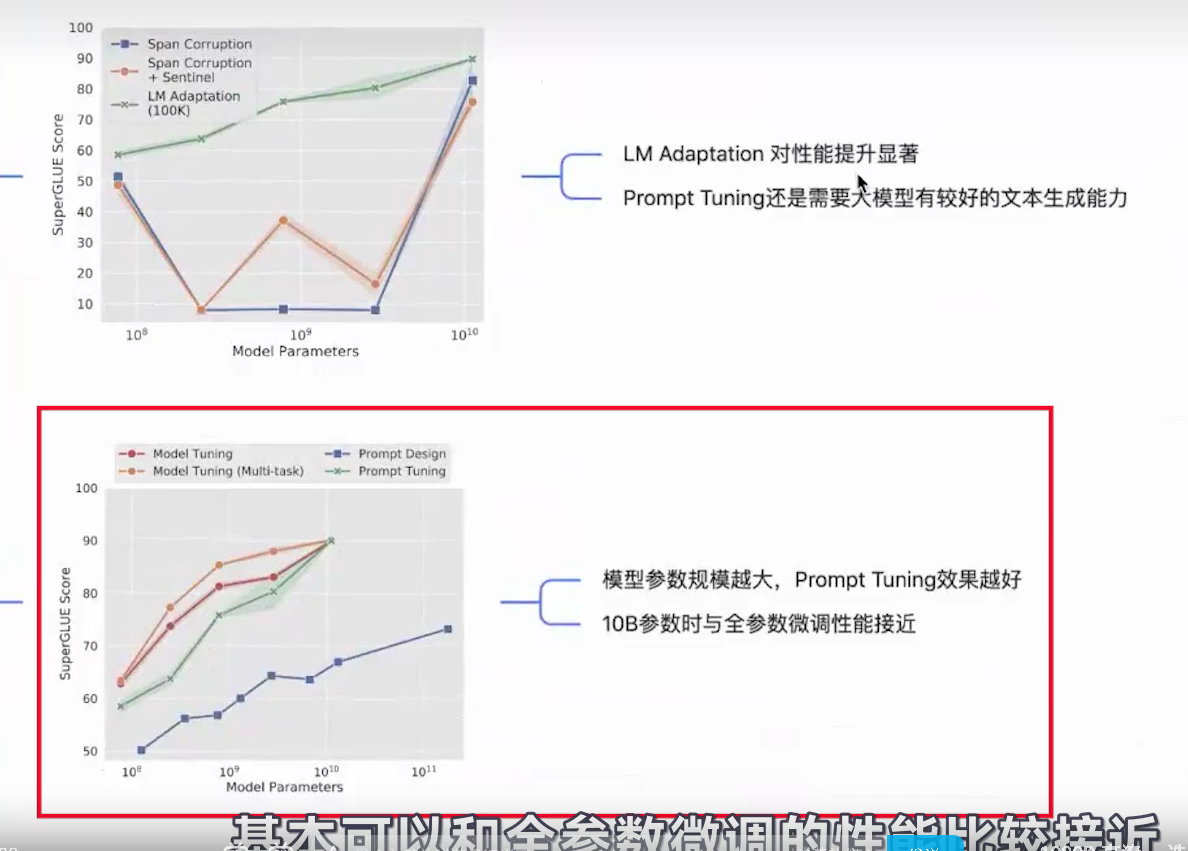
- Pre-trained Prompt Tuning for Few-shot Learning (ACL 2022) 、The Power of Scale for Parameter-Efficient Prompt Tuning (EMNLP 2021)
- 效果
-
- Soft prompt和hard prompt

- 所以 有按任务做不同的预训练prompt(用作初始化)
- 预训练prompt的具体方法

- 效果
-
- 视觉的visual prompt tuning
-
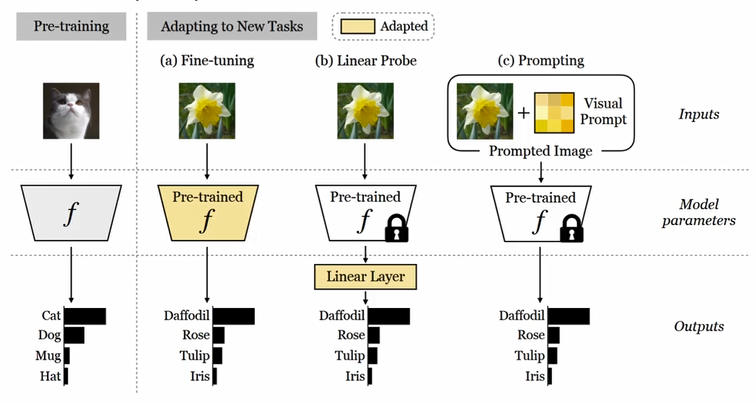
- VPT:就是NLP中加前缀Prefix,然后只用训练前缀。的给定一个预先训练好的Transformer,在Embed层后的输入空间引入一组d维的p连续embedding。在微调过程中,只有prompt会被更新,主干将会冻结,
-
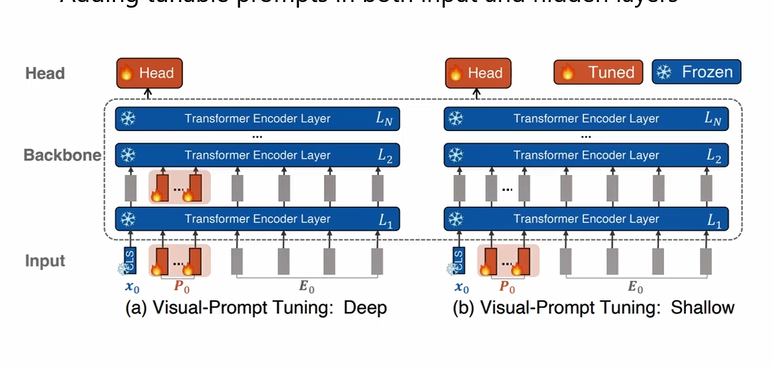
- 加像素),结果比传统的fine_tuning即Linear probe甚至full fine-tuning好,参数量和adapter差不多(

-
-
- 视觉-文本多模态prompt
- CoOp: Learning to Prompt for Vision-Language Models
- 用到再说了
- CoOp: Learning to Prompt for Vision-Language Models
- 只调propmt的文本 (Tuning-free prompting)
- 1.介绍
- 三种PRFT方法的实现
- 总结:
-


- +LoRA可以合用
-
- 留坑:CoT,ToT,GoT的prompt方法
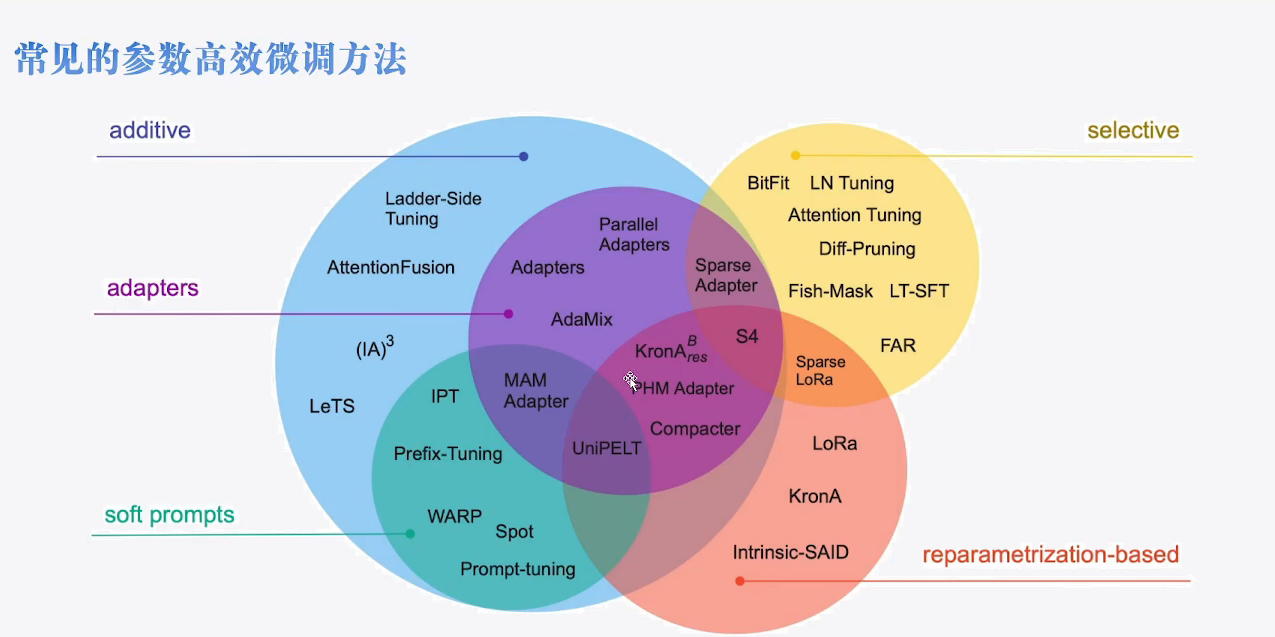
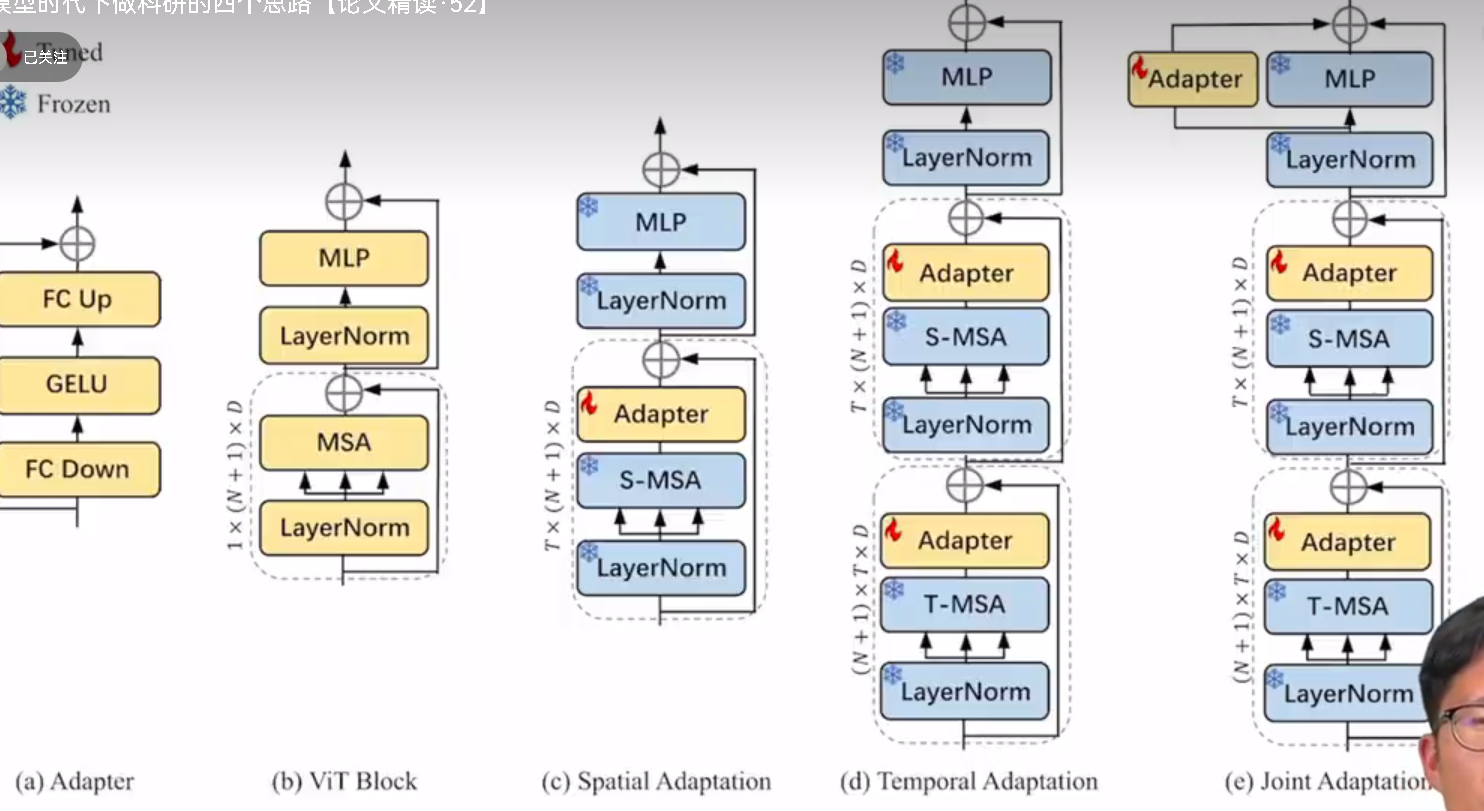
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/365031
推荐阅读

相关标签

