
- 1HarmonyOS列表组件_harmonyos list列表
- 2在ensp中三层交换机(划分vlan)和vrrp案例_ensp三层交换机
- 3【精选】Spring框架介绍及Spirng各个版本的特性_spring版本
- 4linux录制pcm音频的命令,如何在Linux上使用ffmpeg录制音频?
- 5高并发下接口幂等性解决方案_高并发接口
- 62023年我劝你不要在入行软件测试了......._千万不要做软件测试员
- 7fastboot使用_fastboot falsh boot_a
- 8QML动画(其他的动画)_qt qml animation结束信号
- 9双非计算机学子保研(推免)985高校历程_蓝桥杯国二可以保本吗
- 10决策树分类算法以及python实现_创建决策树的基本原则就是简单的就是最好的,只要能实现同样的功能,决策树越简单越好。
维特比(Viterbi)算法_维特比算法
赞
踩
维特比算法 (Viterbi algorithm) 是机器学习中应用非常广泛的动态规划算法,在求解隐马尔科夫、条件随机场的预测以及seq2seq模型概率计算等问题中均用到了该算法。实际上,维特比算法不仅是很多自然语言处理的解码算法,也是现代数字通信中使用最频繁的算法。在介绍维特比算法之前,先回顾一下隐马尔科夫模型,进而介绍维特比算法的计算步骤。
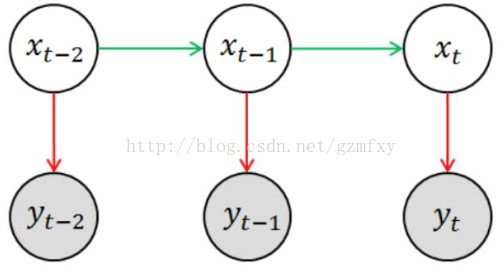
以下为一个简单的隐马尔科夫模型,如下图所示:
其中x = (x1, x2, ..., xN) 为隐状态序列,y = (y1, y2, ..., yN) 为观测序列,要求的预测问题为:
依据马尔科夫假设,上式等价于:
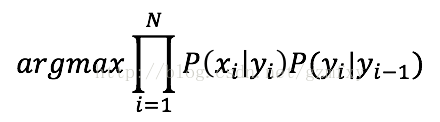
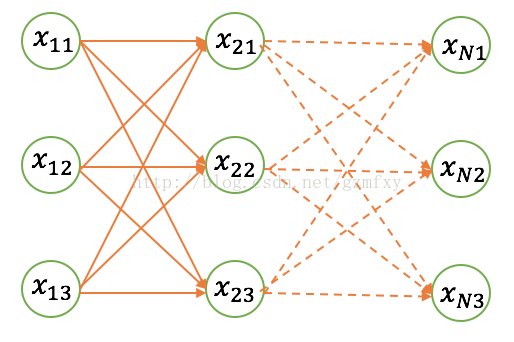
在隐马尔科夫链中,任意时刻t下状态的值有多个,以拼音转汉字为例,输入拼音为“yike”可能有的值为一棵,一刻或者是一颗等待,用符号xij表示状态xi的第j个可能值,将状态序列按值展开,就得到了一个篱笆网了,这也就是维特比算法求解最优路径的图结构:
隐马尔科夫的预测问题就是要求图中的一条路径,使得该路径对应的概率值最大。 对应上图来讲,假设每个时刻x可能取的值为3,如果直接求的话,有3^N的组合数,底数3为篱笆网络宽度,指数N为篱笆网络的长度,计算量非常大。维特比利用动态规划的思想来求解概率最大路径(可理解为求图最短路径),使得复杂度正比于序列长度,复杂度为O(N⋅D⋅D), N为长度,D为宽度,从而很好地解决了问题的求解。
维特比算法的基础可以概括为下面三点(来源于吴军:数学之美):
1、如果概率最大的路径经过篱笆网络的某点,则从开始点到该点的子路径也一定是从开始到该点路径中概率最大的。
2、假定第i时刻有k个状态,从开始到i时刻的k个状态有k条最短路径,而最终的最短路径必然经过其中的一条。
3、根据上述性质,在计算第i+1状态的最短路径时,只需要考虑从开始到当前的k个状态值的最短路径和当前状态值到第i+1状态值的最短路径即可,如求t=3时的最短路径,等于求t=2时的所有状态结点x2i的最短路径加上t=2到t=3的各节点的最短路径。
为了纪录中间变量,引入两个变量sigma和phi,定义t时刻状态为i的所有单个路径 (i1, i2, ..., it) 中最大概率值(最短路径)为(前文小修已经有介绍隐马尔科夫相关的概念,如果不清楚可以看一下前面的详解隐马尔可夫模型 (HMM) ):
其中it表示最短路径,Ot表示观测符号,lamda表示模型参数,根据上式可以得出变量sigma的递推公式:
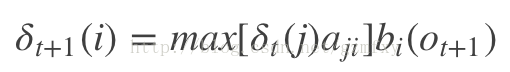
其中i = 1, 2, ..., N; t = 1, 2, ... , T-1,定义在时刻t状态为i的所有单个路径 (i1, i2, ..., it, i) 中概率最大的路径的第t-1个结点为:

根据上面的两个定义下面给出维特比算法具体内容:
输入为模型和观测状态分别为:
,
输出为求出最优路径:
步骤为:(1) 初始化各参数:
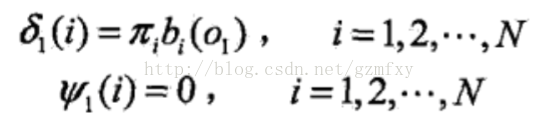
(2) 根据上式进行递推,对t=2, 3, ..., T
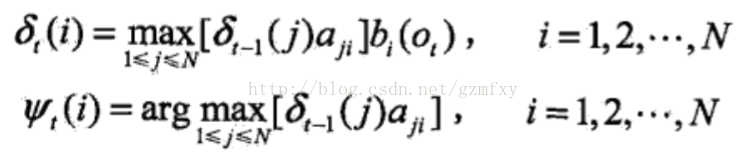
(3) 最后计算终止状态:

最优路径的回溯,对t=T-1, T-2,..., 1
最后求得最优路径:
以上就是维特比算法的主要过程和内容,下面介绍一个个例子。在自然语言处理技术中的seq2seq模型中,如下图所示:
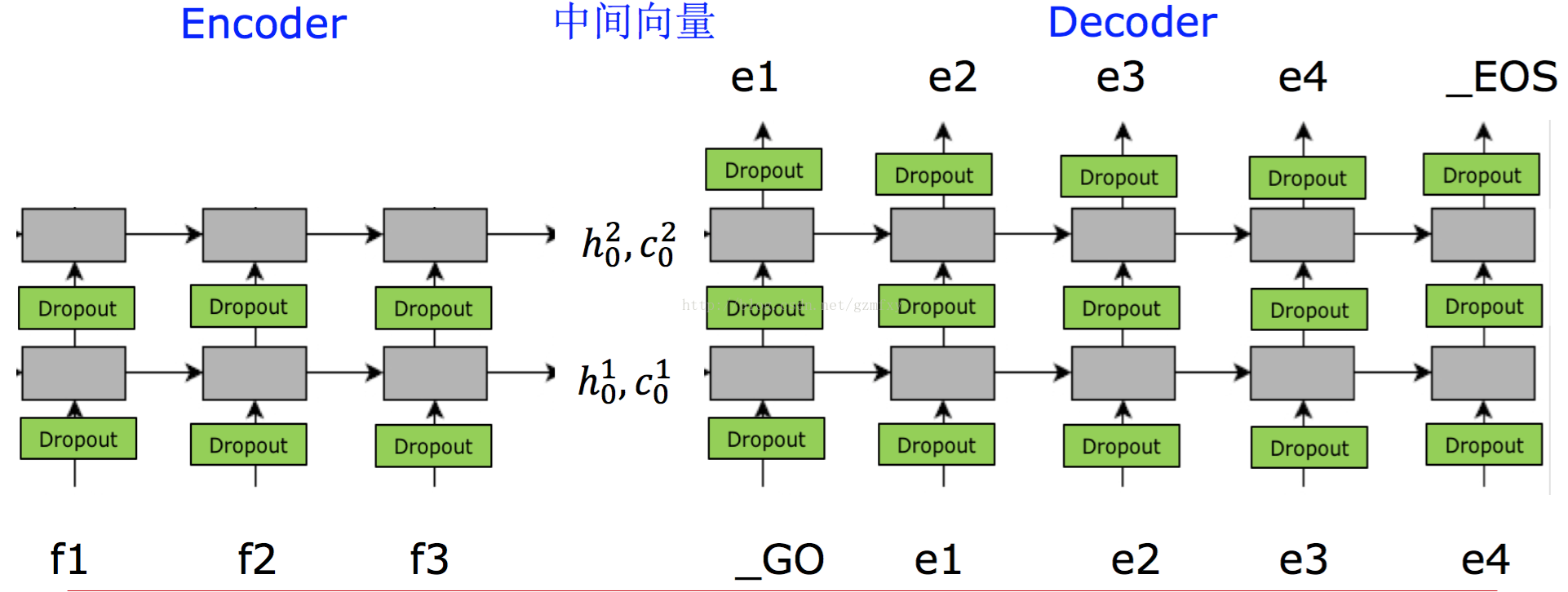
其实seq2seq模型的核心就是:
其中e和f就是相应的输出和输入序列,在进行解码的时候,如果词袋中的个数为V个,那么那么输出长度为N的序列,则需要的总共搜索V^N次,如果N的个数非常之大,这样的搜索非常耗时间,那么这个时候使用维特比算法就会大大的降低搜索的时间。这里假设词袋中只有a和b,而且它们之间的转变概率为:
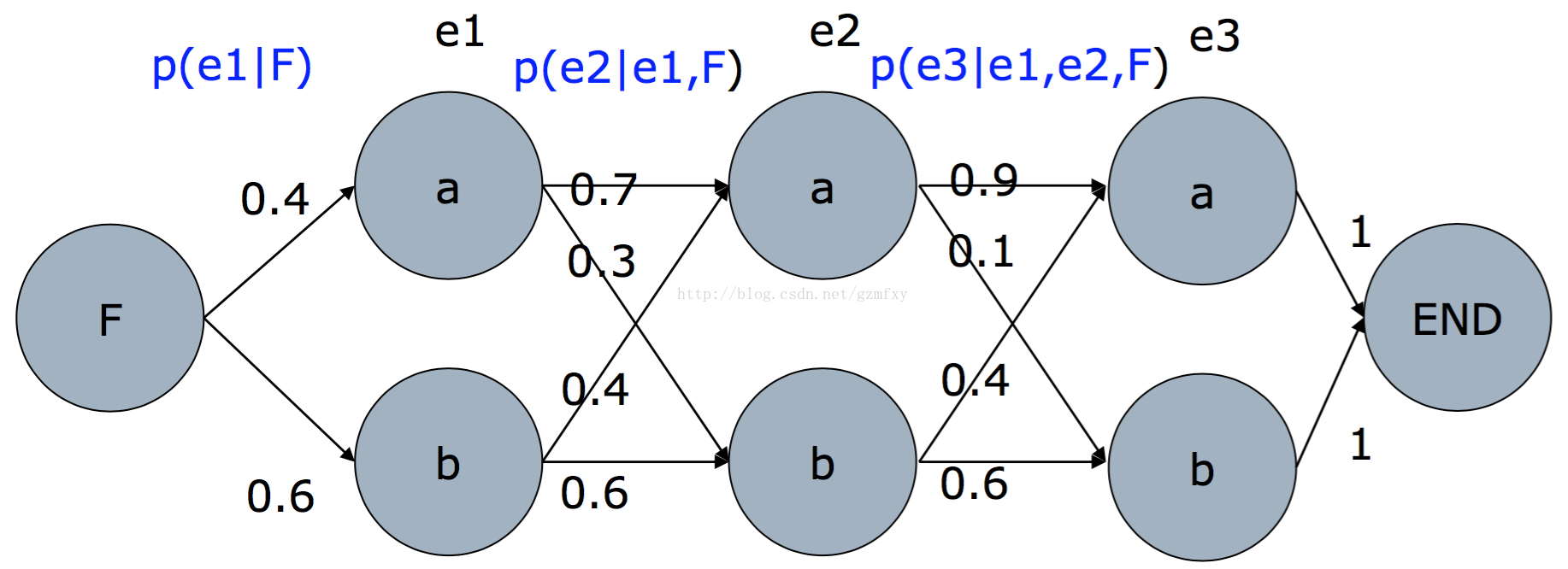
在这时使用维特比算法,其主要的思想为:

其中s(v,n) 表示的是以v结尾的最大概率的序列的概率,t(i, j, n)为第n-1步从i跳到第n步的j的概率。根据算法可以得到:


因此最终输出的序列为bba,
在这里最后说一点就是,其实对于seq2seq有相应的算法对整个序列的输出进行搜索计算 (beam search算法),其思想和维特比算法非常相似,这里不做介绍,下次有机会给大家介绍。
参考书目:
[1] 统计学习方法,李航
---------------------
作者:lovive
来源:CSDN
原文:https://blog.csdn.net/gzmfxy/article/details/78712878
版权声明:本文为博主原创文章,转载请附上博文链接!

