
- 1mysql字符串位数不够前面补0_mysql位数不足补0
- 2亚马逊云科技 | Bedrock尝鲜全新Claude3(附免费体验名额)_亚马逊云claude3
- 3学习axios必知必会(2)~axios基本使用、使用axios前必知细节、axios和axios实例对象区别、axios拦截器、axios取消请求_axios response config 能做标识符
- 4毕业设计选题基于Java的考研学习交流系统的设计与实现_考研学习交流系统设计与实现
- 5探索VSCode新宠:AI小助手,让你编程如虎添翼!_vscode ai助手
- 620240401 每日AI必读资讯
- 7OSError: cannot write mode RGBA as JPEG解决办法
- 8CSS的@media与@media screen,媒体查询_css @media screen
- 9Spring项目所需的Maven依赖_org.springframework.util.base64utils 哪个maven依赖
- 10NLP机器翻译全景:从基本原理到技术实战全解析_机器翻译原理 词典
中文对话数据集预处理_50w中文闲聊语料
赞
踩
本文按照模型https://github.com/yangjianxin1/GPT2-chitchat提供的数据预处理方法,从环境配置、预处理方法、结果展示两个方面介绍中文对话数据集的预处理方法。
一、数据集介绍
本文采用50w中文闲聊语料作为预处理数据集百度网盘【提取码:4g5e】 ,中文闲聊语料的内容样例如下:
谢谢你所做的一切
你开心就好
开心
嗯因为你的心里只有学习
某某某,还有你
这个某某某用的好你们宿舍都是这么厉害的人吗
眼睛特别搞笑这土也不好捏但就是觉得挺可爱
特别可爱啊今天好点了吗?
一天比一天严重
吃药不管用,去打一针。别拖着
二、环境配置
python 3.6
pytorch 1.7.0
transfomers 4.4.2
1、创建新的环境(eg.gpt)
conda create -n your_name python==3.6
2、激活环境并进入
conda activate gpt
3、使用conda安装pytorch1.7.0(CPU版本)
conda install pytorch==1.7.0 torchvision torchaudio cpuonly -c pytorch
4、安装transfomers4.4.2
pip3 install transfomers
报错:
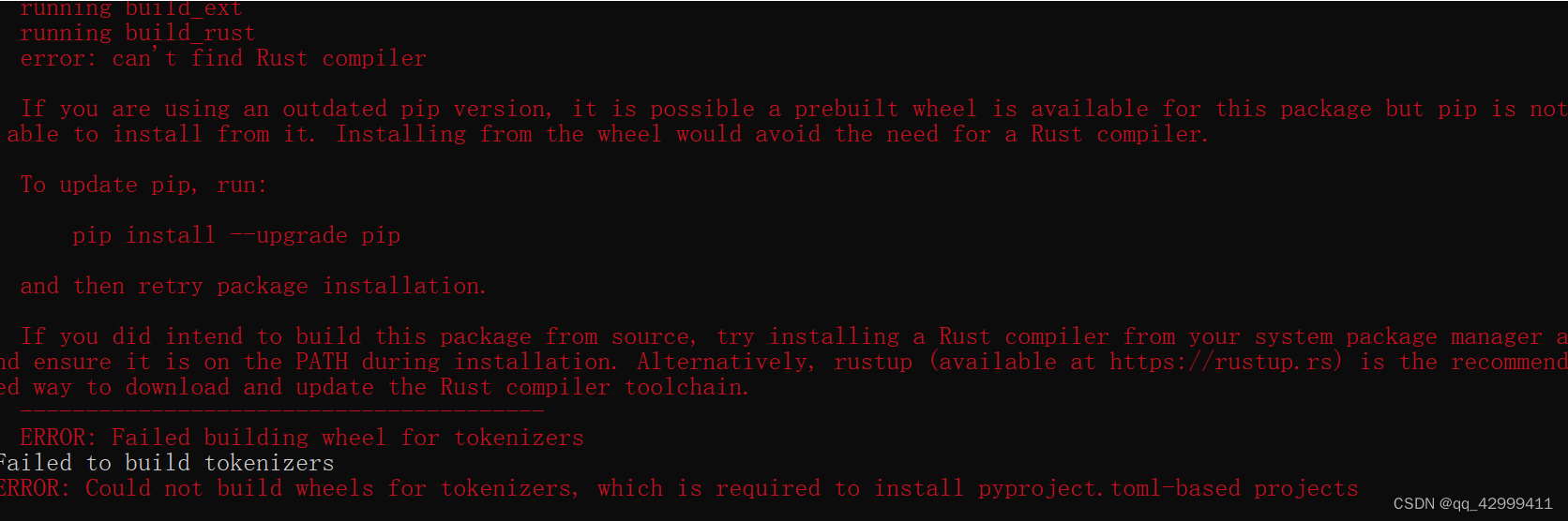
->安装wheel包
pip install wheel
->重新安装transfomers4.4.2
pip3 install transfomers==4.4.2
三、运行preprocess.py
python preprocess.py --train_path data/train.txt --save_path data/train.pkl
报错:
 ->安装pandas包
->安装pandas包
pip install pandas
报错:
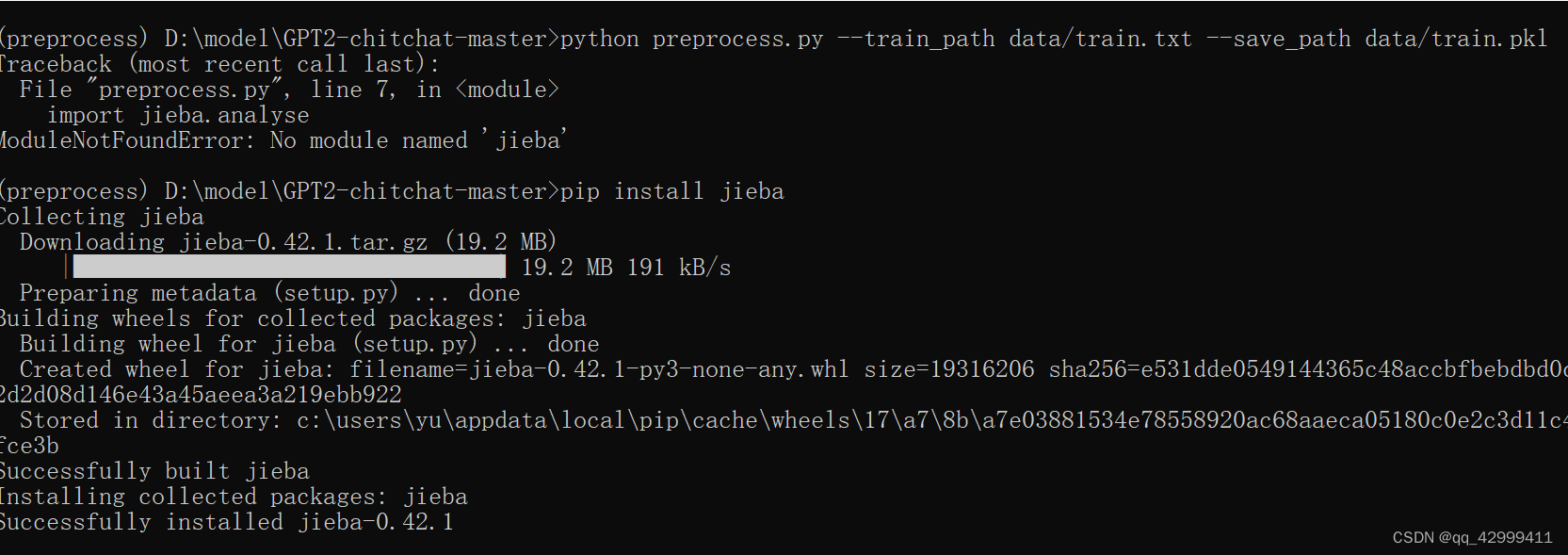
->安装jieba 包
pip install jieba
继续尝试运行,成功。

四、结果展示
数据预处理后的文件格式为.pkl,想要查看预处理后的文件
- # show_pkl.py
-
- import pickle
-
- path = 'D:/model/GPT2-chitchat-master/train.pkl'
-
- # path='/root/……/aus_openface.pkl' pkl文件所在路径
-
- f = open(path, 'rb')
-
- data = pickle.load(f)
-
- print(data)
-
- print(len(data))

