
- 1【Android Studio程序开发】常用布局--线性布局LinearLayout_android studio linearlayout布局
- 2基础课5——垂直领域对话系统架构_垂直领域问答对话实现方法
- 3WPF RichTextBox的常用方法和属性(内容的读取/导入等)_wpf richtextbox 中超链接获取输入的值
- 4SI,SIS,SIR,SEIRD模型_si模型
- 5simpleitk打开dicom文件
- 6diffusion model原理和算法伪代码_diffusion loss
- 7国产中间件概述
- 8solidity Dapp ERC20添加即空投合约_erc20代币能不能加入联盟链
- 9自动化机器学习AutoML之flaml:利用flaml框架自动寻找最优算法及其对应最佳参数python
- 10速递|AI搜索引擎Perplexity AI再获融资7000万美元,估值达5.2亿美元
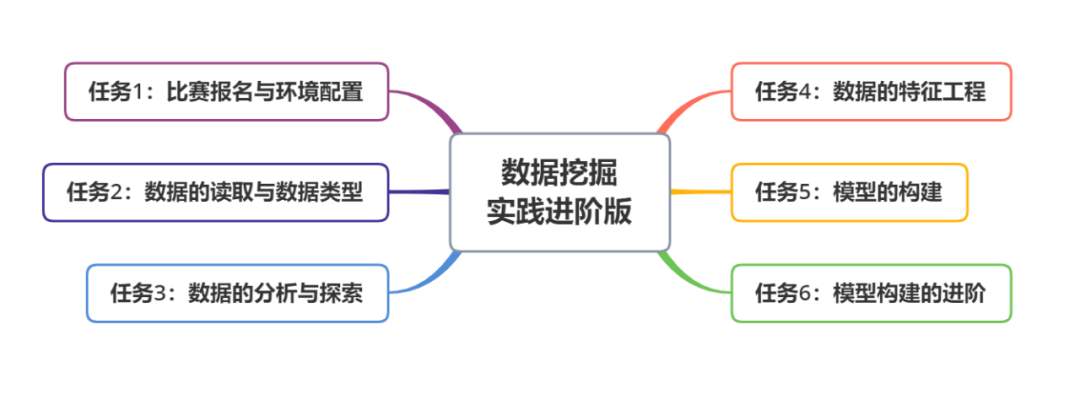
《如何打一场数据挖掘赛事》进阶版
赞
踩
Datawhale干货
贡献者:牧小熊、Datawhale幕后贡献者
经过上一篇的入门学习,大家已经熟悉如何去打一场比赛,并能训练经典的机器学习算法模型,去解决实际的问题。如果你还不了解,可以先学习《如何打一个数据挖掘比赛》 入门版,然后再进行本节的学习。
这个比赛是一个医疗领域的数据挖掘实践,赛事的任务是构建一种模型,该模型能够根据患者的测试数据来预测这个患者是否患有糖尿病。这种类型的任务是典型的二分类问题(患有糖尿病 / 不患有糖尿病)。本文将以任务学习和启发性思考的方式,帮助大家深入学习。
获取进阶版PDF教程,公众号后台回复:进阶
赛事背景:
本次比赛是一个医疗领域数据挖掘赛,需要选手通过训练集数据构建模型,对验证集数据进行预测,并将预测的结果提交到科大讯飞数据竞赛平台中,得到排名反馈。
报名地址:
https://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-gzh02
教程说明:
本教程共有6个任务,任务难度逐渐增加。每个任务中分为不同的模块,具体要求如下:
主线任务需要学习者独立完成
支线任务为学有余力的同学独立完成
思考为学习者提供了可以思考的方向,可通过讨论或搜索获得结果
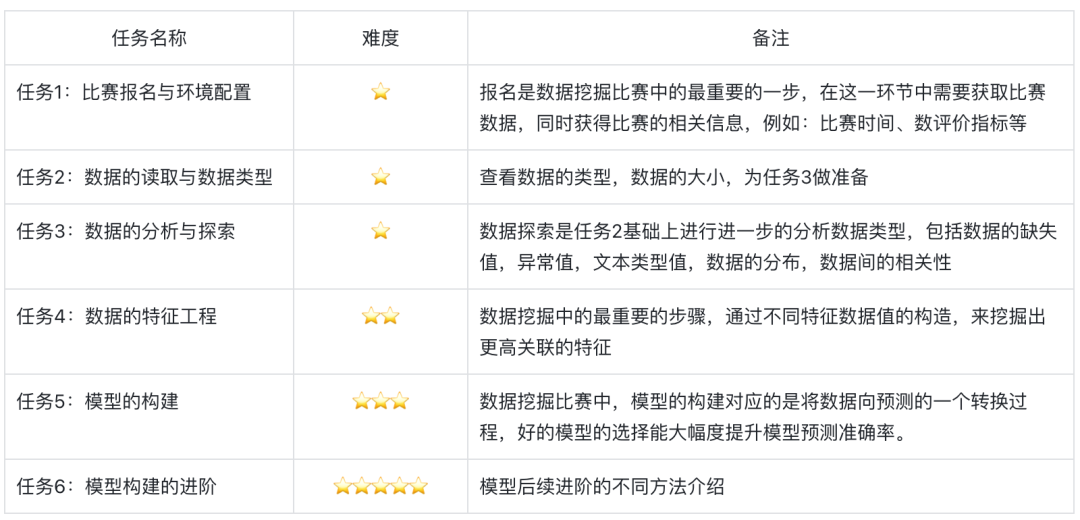
任务1:比赛报名与环境配置
主线任务:
访问糖尿病遗传风险检测挑战赛网页,并注册相关账号
点击页面中赛事概要,了解比赛的赛事背景、赛事任务、提交说明、评估指标等相关信息
安装并配置好python的编程环境
思考:
为什么要了解比赛的相关信息?
比赛的评估指标有哪几种?本次比赛中为什么使用F1-score,相比其他评估指标有什么优势?
任务2:数据的读取与数据类型
主线任务:
解压比赛数据,使用pandas读取比赛数据,并查看训练集和测试集数据大小
查看训练集和测试集的数据类型
思考:
为什么要查看训练集和测试集的大小?
为什么查看训练集和测试集的数据类型?
参考代码:
- import pandas as pd
- train_df=pd.read_csv('比赛训练集.csv',encoding='gbk')
- test_df=pd.read_csv('比赛测试集.csv',encoding='gbk')
-
- print('训练集的数据大小:',train_df.shape)
- print('测试集的数据大小:',test_df.shape)
- print('-'*30)
- print('训练集的数据类型:')
- print(train_df.dtypes)
- print('-'*30)
- print(test_df.dtypes)
任务3:数据的分析与探索
主线任务:
查看训练集和测试集的缺失值,并比训练集和测试集的缺失值分布是否一致
使用.corr()函数查看数据间的相关性
对训练集和测试集数据进行可视化统计
思考:
数据中的缺失值产生的原因?
怎么查看数据间的相关性?如果相关性高说明了什么?

